 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Robust Face Recognition with Comprehensive Search
Aug 29, 2022
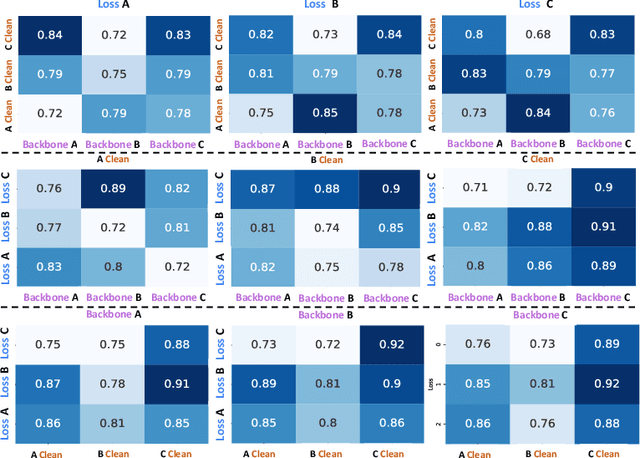
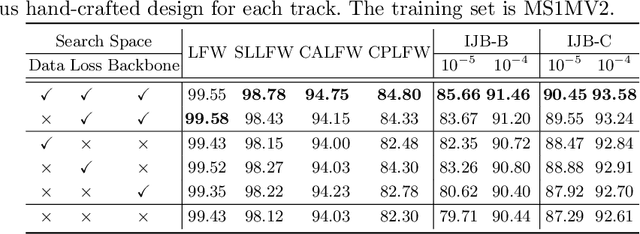
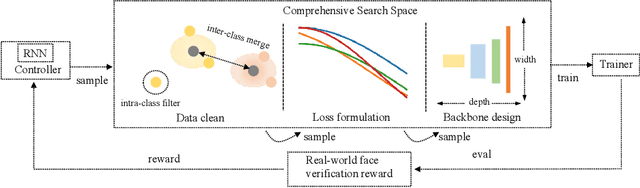
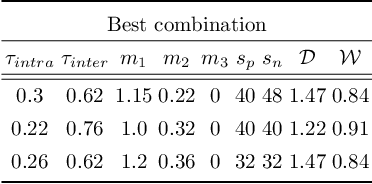
Data cleaning, architecture, and loss function design are important factors contributing to high-performance face recognition. Previously, the research community tries to improve the performance of each single aspect but failed to present a unified solution on the joint search of the optimal designs for all three aspects. In this paper, we for the first time identify that these aspects are tightly coupled to each other. Optimizing the design of each aspect actually greatly limits the performance and biases the algorithmic design. Specifically, we find that the optimal model architecture or loss function is closely coupled with the data cleaning. To eliminate the bias of single-aspect research and provide an overall understanding of the face recognition model design, we first carefully design the search space for each aspect, then a comprehensive search method is introduced to jointly search optimal data cleaning, architecture, and loss function design. In our framework, we make the proposed comprehensive search as flexible as possible, by using an innovative reinforcement learning based approach. Extensive experiments on million-level face recognition benchmarks demonstrate the effectiveness of our newly-designed search space for each aspect and the comprehensive search. We outperform expert algorithms developed for each single research track by large margins. More importantly, we analyze the difference between our searched optimal design and the independent design of the single factors. We point out that strong models tend to optimize with more difficult training datasets and loss functions. Our empirical study can provide guidance in future research towards more robust face recognition systems.
A Modular 1D-CNN Architecture for Real-time Digital Pre-distortion
Nov 18, 2021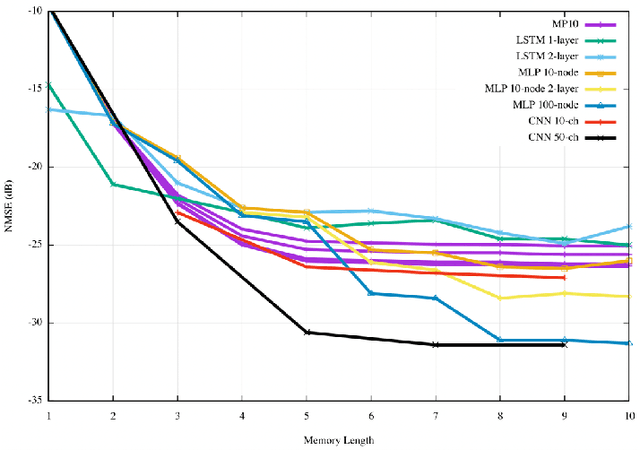
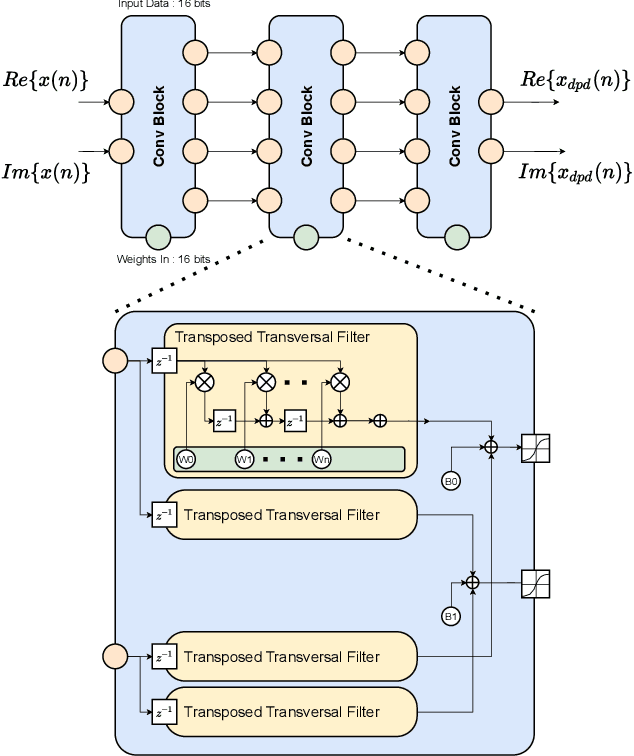
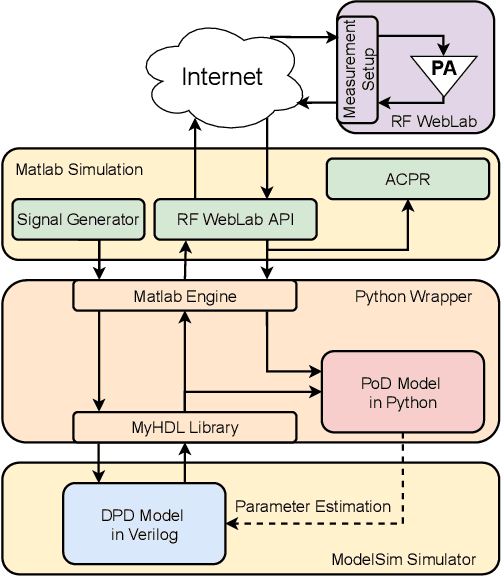
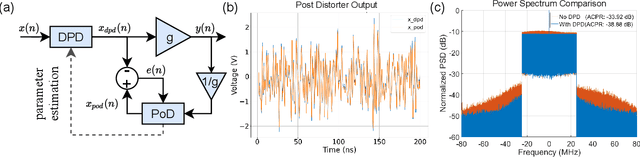
This study reports a novel hardware-friendly modular architecture for implementing one dimensional convolutional neural network (1D-CNN) digital predistortion (DPD) technique to linearize RF power amplifier (PA) real-time.The modular nature of our design enables DPD system adaptation for variable resource and timing constraints.Our work also presents a co-simulation architecture to verify the DPD performance with an actual power amplifier hardware-in-the-loop.The experimental results with 100 MHz signals show that the proposed 1D-CNN obtains superior performance compared with other neural network architectures for real-time DPD application.
Efficient Learning and Decoding of the Continuous-Time Hidden Markov Model for Disease Progression Modeling
Oct 26, 2021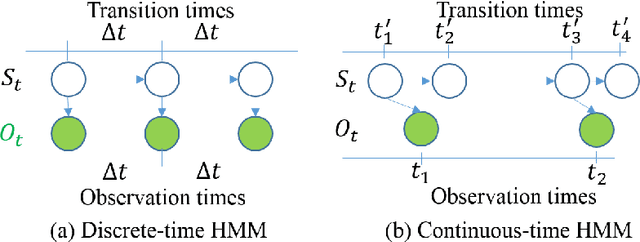

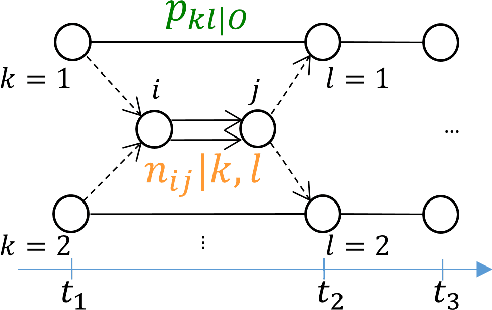
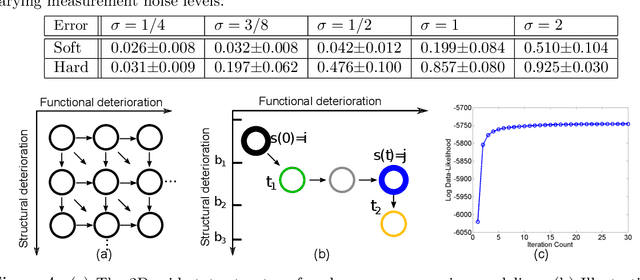
The Continuous-Time Hidden Markov Model (CT-HMM) is an attractive approach to modeling disease progression due to its ability to describe noisy observations arriving irregularly in time. However, the lack of an efficient parameter learning algorithm for CT-HMM restricts its use to very small models or requires unrealistic constraints on the state transitions. In this paper, we present the first complete characterization of efficient EM-based learning methods for CT-HMM models, as well as the first solution to decoding the optimal state transition sequence and the corresponding state dwelling time. We show that EM-based learning consists of two challenges: the estimation of posterior state probabilities and the computation of end-state conditioned statistics. We solve the first challenge by reformulating the estimation problem as an equivalent discrete time-inhomogeneous hidden Markov model. The second challenge is addressed by adapting three distinct approaches from the continuous time Markov chain (CTMC) literature to the CT-HMM domain. Additionally, we further improve the efficiency of the most efficient method by a factor of the number of states. Then, for decoding, we incorporate a state-of-the-art method from the (CTMC) literature, and extend the end-state conditioned optimal state sequence decoding to the CT-HMM case with the computation of the expected state dwelling time. We demonstrate the use of CT-HMMs with more than 100 states to visualize and predict disease progression using a glaucoma dataset and an Alzheimer's disease dataset, and to decode and visualize the most probable state transition trajectory for individuals on the glaucoma dataset, which helps to identify progressing phenotypes in a comprehensive way. Finally, we apply the CT-HMM modeling and decoding strategy to investigate the progression of language acquisition and development.
Few-Shot Learning for Clinical Natural Language Processing Using Siamese Neural Networks
Aug 31, 2022

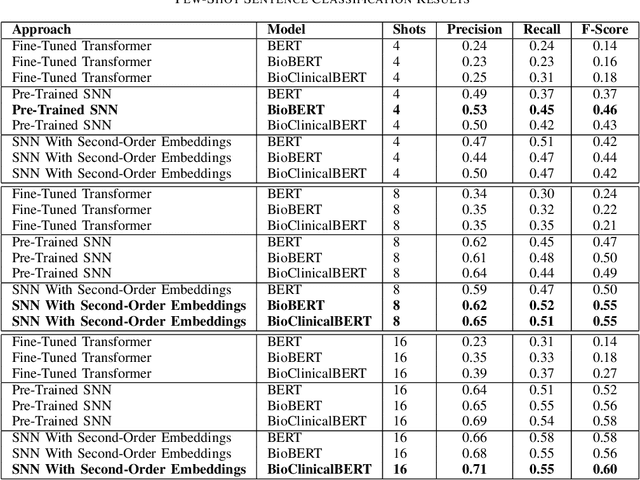
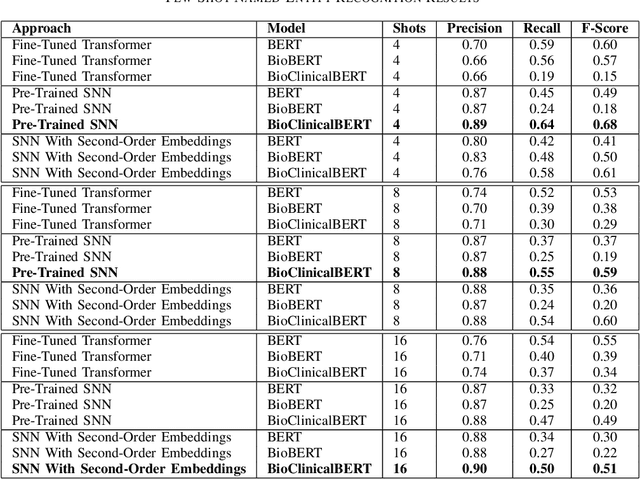
Clinical Natural Language Processing (NLP) has become an emerging technology in healthcare that leverages a large amount of free-text data in electronic health records (EHRs) to improve patient care, support clinical decisions, and facilitate clinical and translational science research. Deep learning has achieved state-of-the-art performance in many clinical NLP tasks. However, training deep learning models usually require large annotated datasets, which are normally not publicly available and can be time-consuming to build in clinical domains. Working with smaller annotated datasets is typical in clinical NLP and therefore, ensuring that deep learning models perform well is crucial for the models to be used in real-world applications. A widely adopted approach is fine-tuning existing Pre-trained Language Models (PLMs), but these attempts fall short when the training dataset contains only a few annotated samples. Few-Shot Learning (FSL) has recently been investigated to tackle this problem. Siamese Neural Network (SNN) has been widely utilized as an FSL approach in computer vision, but has not been studied well in NLP. Furthermore, the literature on its applications in clinical domains is scarce. In this paper, we propose two SNN-based FSL approaches for clinical NLP, including pre-trained SNN (PT-SNN) and SNN with second-order embeddings (SOE-SNN). We evaluated the proposed approaches on two clinical tasks, namely clinical text classification and clinical named entity recognition. We tested three few-shot settings including 4-shot, 8-shot, and 16-shot learning. Both clinical NLP tasks were benchmarked using three PLMs, including BERT, BioBERT, and BioClinicalBERT. The experimental results verified the effectiveness of the proposed SNN-based FSL approaches in both clinical NLP tasks.
Ultron: An Ultimate Retriever on Corpus with a Model-based Indexer
Aug 19, 2022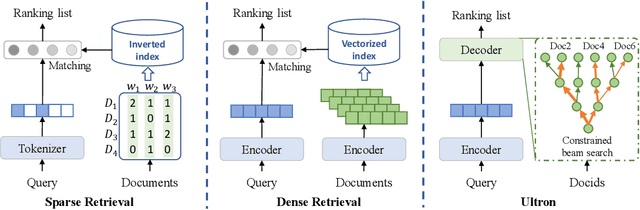
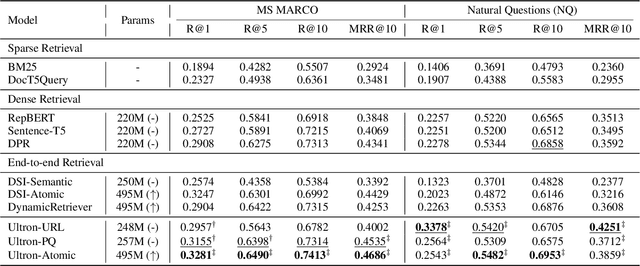
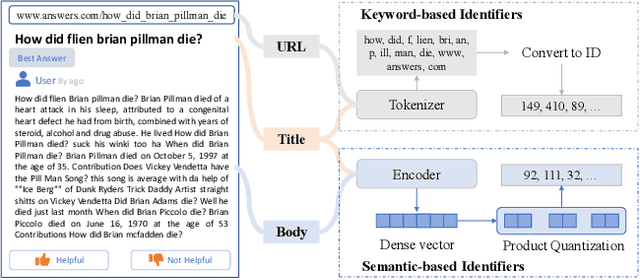
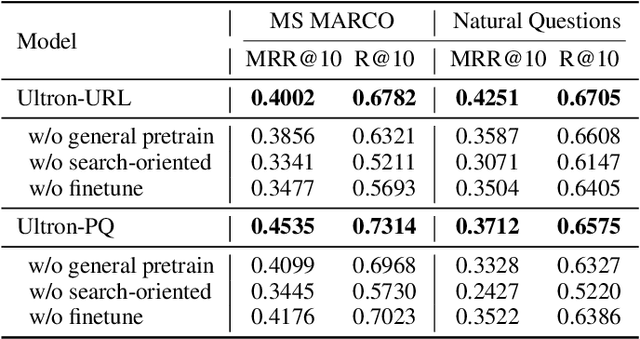
Document retrieval has been extensively studied within the index-retrieve framework for decades, which has withstood the test of time. Unfortunately, such a pipelined framework limits the optimization of the final retrieval quality, because indexing and retrieving are separated stages that can not be jointly optimized in an end-to-end manner. In order to unify these two stages, we explore a model-based indexer for document retrieval. Concretely, we propose Ultron, which encodes the knowledge of all documents into the model and aims to directly retrieve relevant documents end-to-end. For the model-based indexer, how to represent docids and how to train the model are two main issues to be explored. Existing solutions suffer from semantically deficient docids and limited supervised data. To tackle these two problems, first, we devise two types of docids that are richer in semantics and easier for model inference. In addition, we propose a three-stage training workflow to capture more knowledge contained in the corpus and associations between queries and docids. Experiments on two public datasets demonstrate the superiority of Ultron over advanced baselines for document retrieval.
Hierarchical Local-Global Transformer for Temporal Sentence Grounding
Aug 31, 2022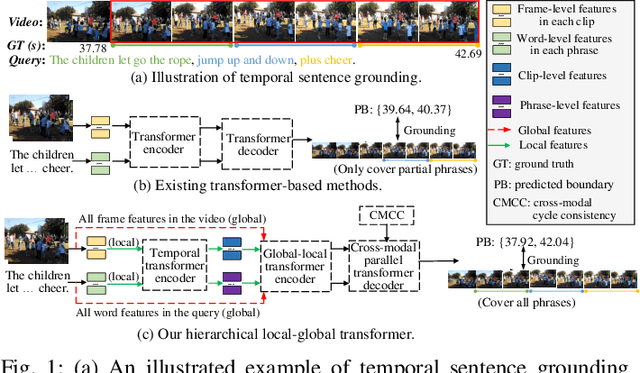
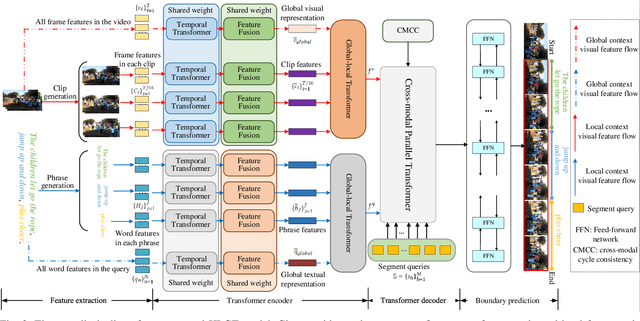
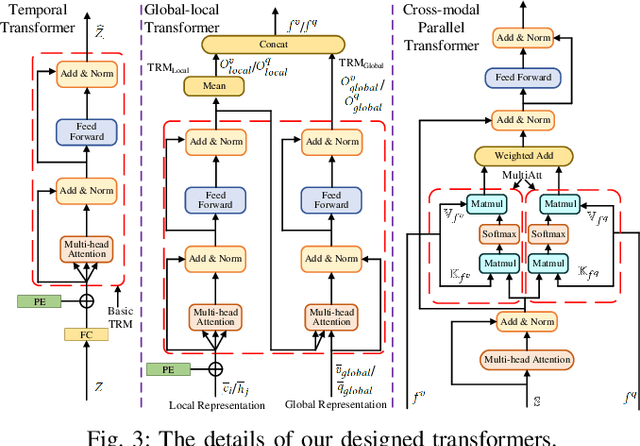
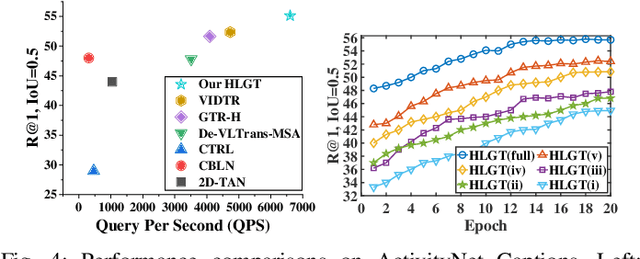
This paper studies the multimedia problem of temporal sentence grounding (TSG), which aims to accurately determine the specific video segment in an untrimmed video according to a given sentence query. Traditional TSG methods mainly follow the top-down or bottom-up framework and are not end-to-end. They severely rely on time-consuming post-processing to refine the grounding results. Recently, some transformer-based approaches are proposed to efficiently and effectively model the fine-grained semantic alignment between video and query. Although these methods achieve significant performance to some extent, they equally take frames of the video and words of the query as transformer input for correlating, failing to capture their different levels of granularity with distinct semantics. To address this issue, in this paper, we propose a novel Hierarchical Local-Global Transformer (HLGT) to leverage this hierarchy information and model the interactions between different levels of granularity and different modalities for learning more fine-grained multi-modal representations. Specifically, we first split the video and query into individual clips and phrases to learn their local context (adjacent dependency) and global correlation (long-range dependency) via a temporal transformer. Then, a global-local transformer is introduced to learn the interactions between the local-level and global-level semantics for better multi-modal reasoning. Besides, we develop a new cross-modal cycle-consistency loss to enforce interaction between two modalities and encourage the semantic alignment between them. Finally, we design a brand-new cross-modal parallel transformer decoder to integrate the encoded visual and textual features for final grounding. Extensive experiments on three challenging datasets show that our proposed HLGT achieves a new state-of-the-art performance.
Go Back in Time: Generating Flashbacks in Stories with Event Temporal Prompts
May 04, 2022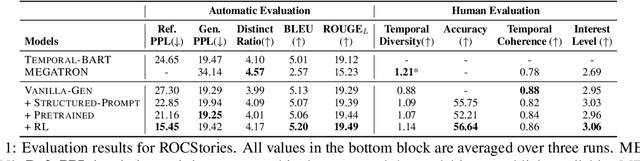
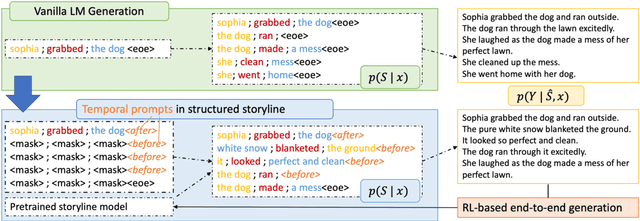

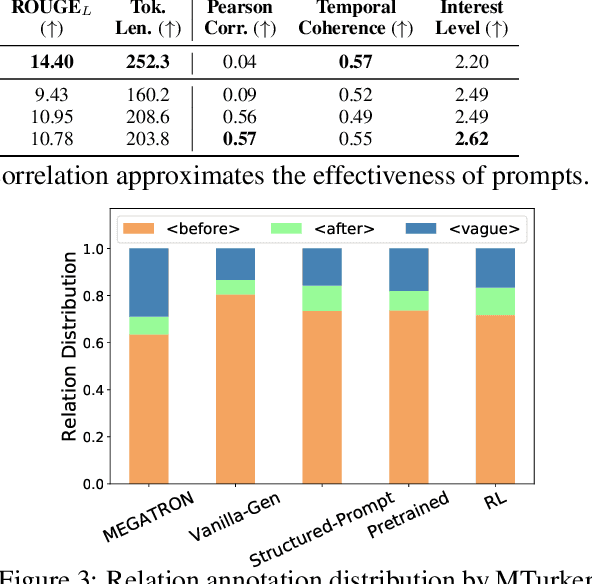
Stories or narratives are comprised of a sequence of events. To compose interesting stories, professional writers often leverage a creative writing technique called flashback that inserts past events into current storylines as we commonly observe in novels and plays. However, it is challenging for machines to generate flashback as it requires a solid understanding of event temporal order (e.g. "feeling hungry" before "eat," not vice versa), and the creativity to arrange storylines so that earlier events do not always appear first in narrative order. Two major issues in existing systems that exacerbate the challenges: 1) temporal bias in pertaining and story datasets that leads to monotonic event temporal orders; 2) lack of explicit guidance that helps machines decide where to insert flashbacks. We propose to address these issues using structured storylines to encode events and their pair-wise temporal relations (before, after and vague) as temporal prompts that guide how stories should unfold temporally. We leverage a Plan-and-Write framework enhanced by reinforcement learning to generate storylines and stories end-to-end. Evaluation results show that the proposed method can generate more interesting stories with flashbacks while maintaining textual diversity, fluency, and temporal coherence.
End-User Puppeteering of Expressive Movements
Jul 25, 2022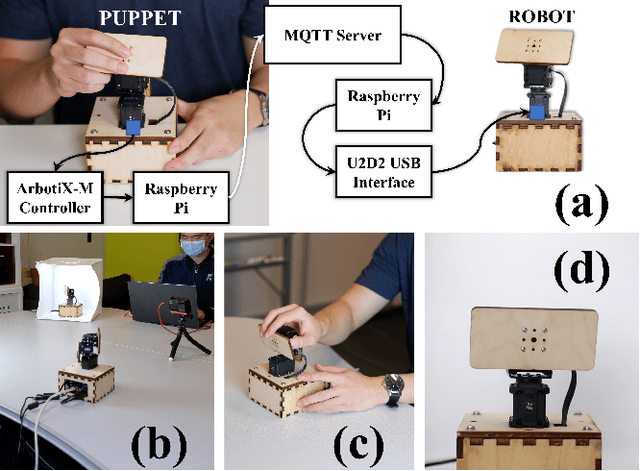
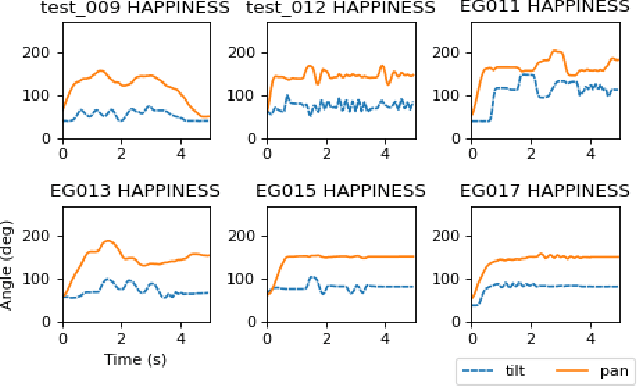
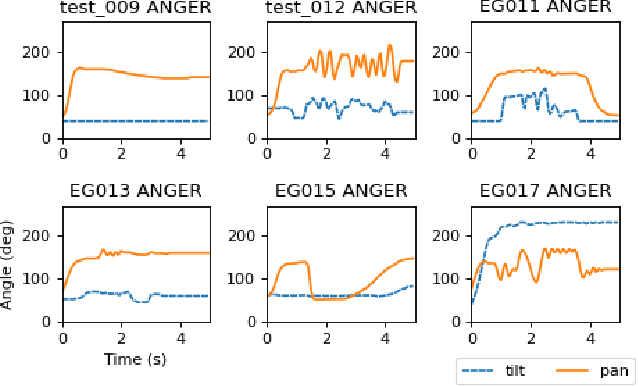
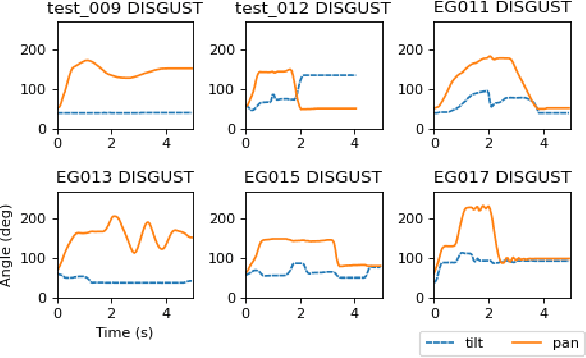
The end-user programming of social robot behavior is usually limited by a predefined set of movements. We are proposing a puppeteering robotic interface that provides a more intuitive method of programming robot expressive movements. As the user manipulates the puppet of a robot, the actual robot replicates the movements, providing real-time visual feedback. Through this proposed interface, even with limited training, a novice user can design and program expressive movements efficiently. We present our preliminary user study results in this extended abstract.
Time Alignment using Lip Images for Frame-based Electrolaryngeal Voice Conversion
Sep 08, 2021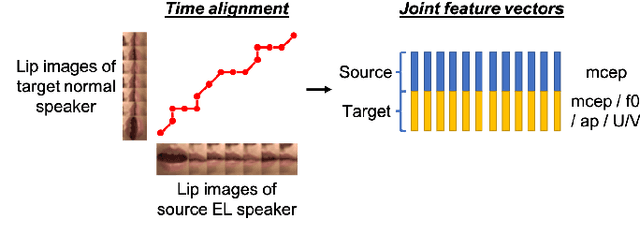
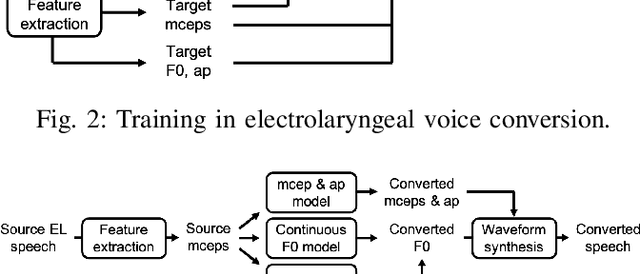
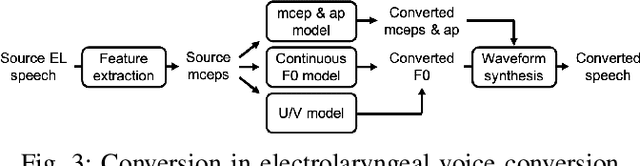
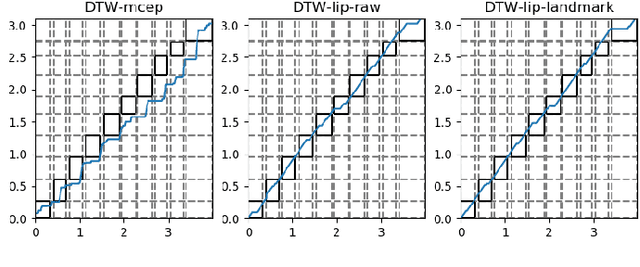
Voice conversion (VC) is an effective approach to electrolaryngeal (EL) speech enhancement, a task that aims to improve the quality of the artificial voice from an electrolarynx device. In frame-based VC methods, time alignment needs to be performed prior to model training, and the dynamic time warping (DTW) algorithm is widely adopted to compute the best time alignment between each utterance pair. The validity is based on the assumption that the same phonemes of the speakers have similar features and can be mapped by measuring a pre-defined distance between speech frames of the source and the target. However, the special characteristics of the EL speech can break the assumption, resulting in a sub-optimal DTW alignment. In this work, we propose to use lip images for time alignment, as we assume that the lip movements of laryngectomee remain normal compared to healthy people. We investigate two naive lip representations and distance metrics, and experimental results demonstrate that the proposed method can significantly outperform the audio-only alignment in terms of objective and subjective evaluations.
Learning Disentangled Representations for Time Series
May 21, 2021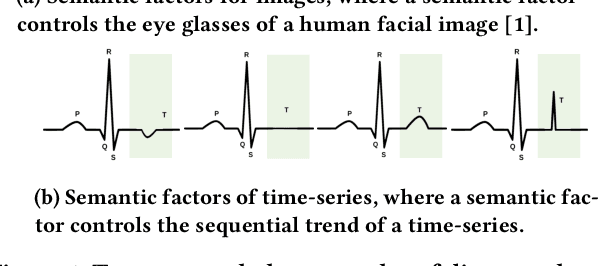
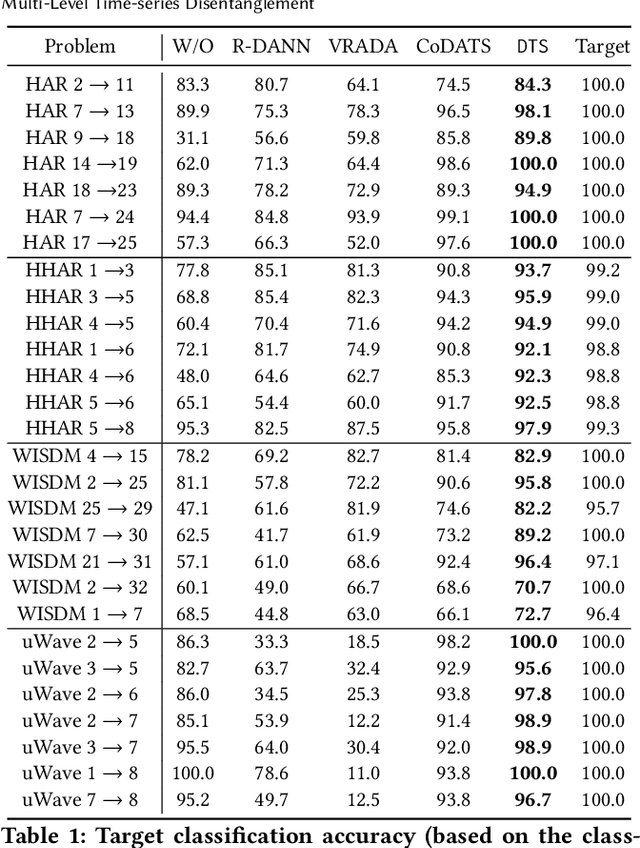
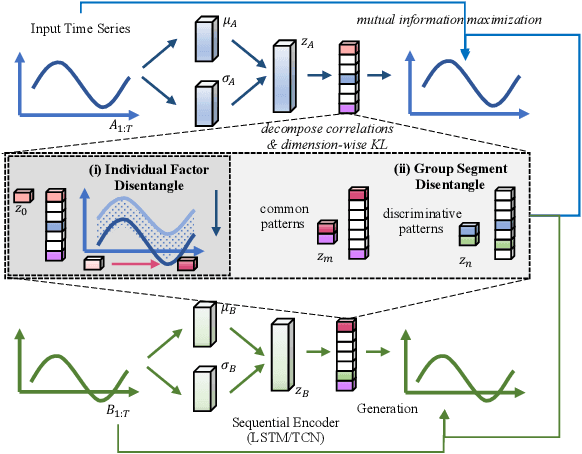
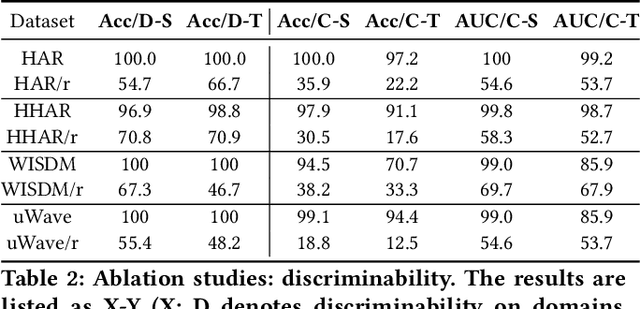
Time-series representation learning is a fundamental task for time-series analysis. While significant progress has been made to achieve accurate representations for downstream applications, the learned representations often lack interpretability and do not expose semantic meanings. Different from previous efforts on the entangled feature space, we aim to extract the semantic-rich temporal correlations in the latent interpretable factorized representation of the data. Motivated by the success of disentangled representation learning in computer vision, we study the possibility of learning semantic-rich time-series representations, which remains unexplored due to three main challenges: 1) sequential data structure introduces complex temporal correlations and makes the latent representations hard to interpret, 2) sequential models suffer from KL vanishing problem, and 3) interpretable semantic concepts for time-series often rely on multiple factors instead of individuals. To bridge the gap, we propose Disentangle Time Series (DTS), a novel disentanglement enhancement framework for sequential data. Specifically, to generate hierarchical semantic concepts as the interpretable and disentangled representation of time-series, DTS introduces multi-level disentanglement strategies by covering both individual latent factors and group semantic segments. We further theoretically show how to alleviate the KL vanishing problem: DTS introduces a mutual information maximization term, while preserving a heavier penalty on the total correlation and the dimension-wise KL to keep the disentanglement property. Experimental results on various real-world benchmark datasets demonstrate that the representations learned by DTS achieve superior performance in downstream applications, with high interpretability of semantic concepts.