 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Novel Actor: Learning a Generalized Animatable Neural Representation for Human Actors
Aug 25, 2022
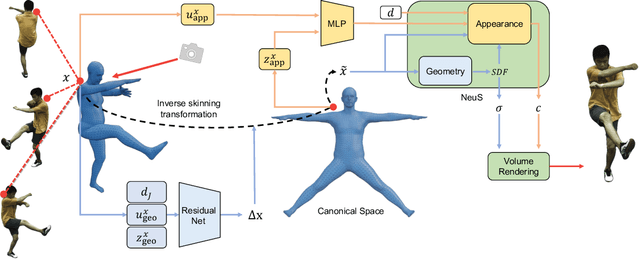

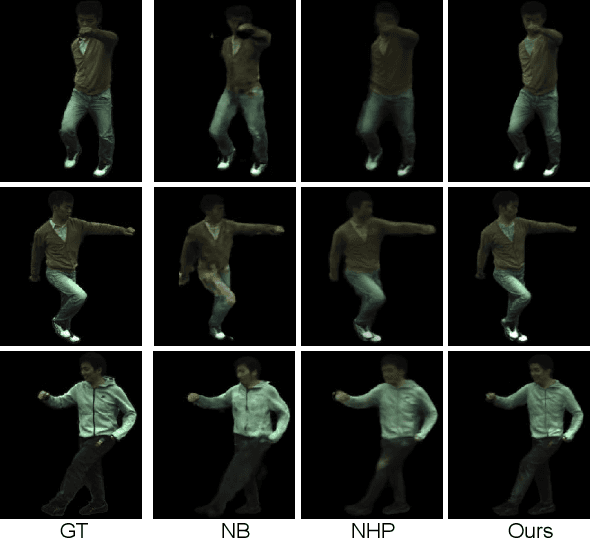

We propose a new method for learning a generalized animatable neural human representation from a sparse set of multi-view imagery of multiple persons. The learned representation can be used to synthesize novel view images of an arbitrary person from a sparse set of cameras, and further animate them with the user's pose control. While existing methods can either generalize to new persons or synthesize animations with user control, none of them can achieve both at the same time. We attribute this accomplishment to the employment of a 3D proxy for a shared multi-person human model, and further the warping of the spaces of different poses to a shared canonical pose space, in which we learn a neural field and predict the person- and pose-dependent deformations, as well as appearance with the features extracted from input images. To cope with the complexity of the large variations in body shapes, poses, and clothing deformations, we design our neural human model with disentangled geometry and appearance. Furthermore, we utilize the image features both at the spatial point and on the surface points of the 3D proxy for predicting person- and pose-dependent properties. Experiments show that our method significantly outperforms the state-of-the-arts on both tasks. The video and code are available at https://talegqz.github.io/neural_novel_actor.
Interference-Limited Ultra-Reliable and Low-Latency Communications: Graph Neural Networks or Stochastic Geometry?
Jul 19, 2022
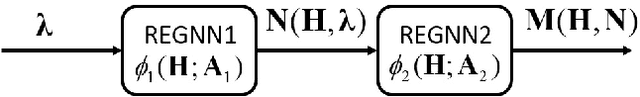
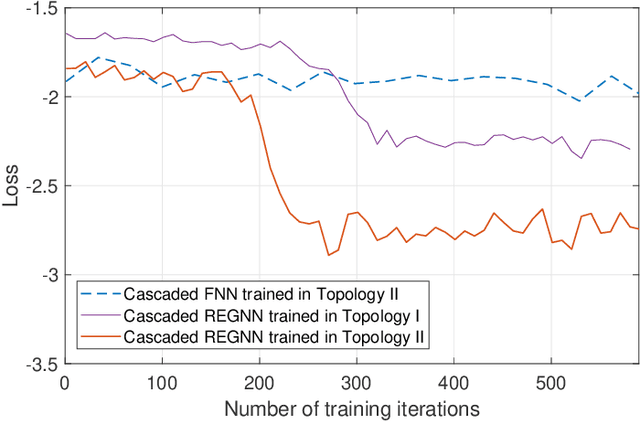
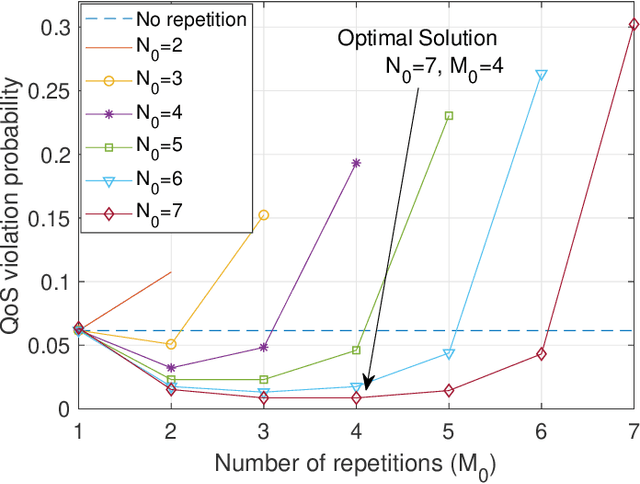
In this paper, we aim to improve the Quality-of-Service (QoS) of Ultra-Reliability and Low-Latency Communications (URLLC) in interference-limited wireless networks. To obtain time diversity within the channel coherence time, we first put forward a random repetition scheme that randomizes the interference power. Then, we optimize the number of reserved slots and the number of repetitions for each packet to minimize the QoS violation probability, defined as the percentage of users that cannot achieve URLLC. We build a cascaded Random Edge Graph Neural Network (REGNN) to represent the repetition scheme and develop a model-free unsupervised learning method to train it. We analyze the QoS violation probability using stochastic geometry in a symmetric scenario and apply a model-based Exhaustive Search (ES) method to find the optimal solution. Simulation results show that in the symmetric scenario, the QoS violation probabilities achieved by the model-free learning method and the model-based ES method are nearly the same. In more general scenarios, the cascaded REGNN generalizes very well in wireless networks with different scales, network topologies, cell densities, and frequency reuse factors. It outperforms the model-based ES method in the presence of the model mismatch.
How Asynchronous Events Encode Video
Jun 09, 2022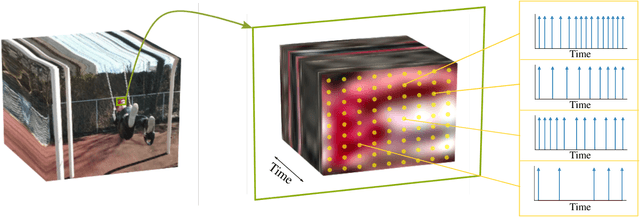
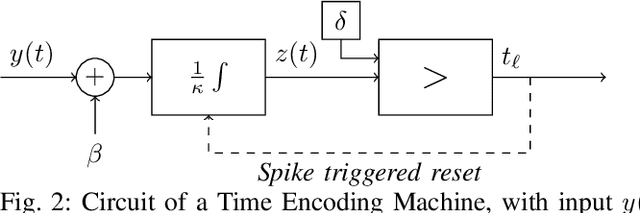
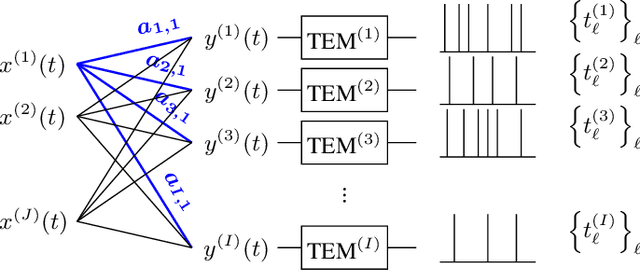
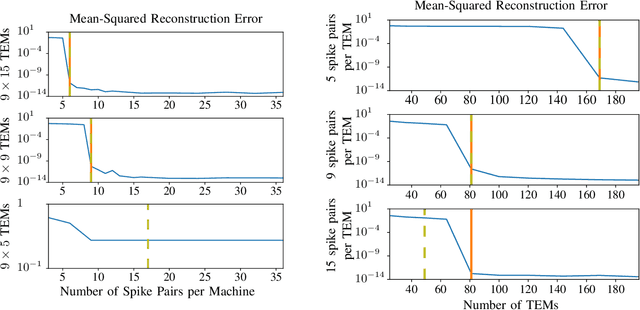
As event-based sensing gains in popularity, theoretical understanding is needed to harness this technology's potential. Instead of recording video by capturing frames, event-based cameras have sensors that emit events when their inputs change, thus encoding information in the timing of events. This creates new challenges in establishing reconstruction guarantees and algorithms, but also provides advantages over frame-based video. We use time encoding machines to model event-based sensors: TEMs also encode their inputs by emitting events characterized by their timing and reconstruction from time encodings is well understood. We consider the case of time encoding bandlimited video and demonstrate a dependence between spatial sensor density and overall spatial and temporal resolution. Such a dependence does not occur in frame-based video, where temporal resolution depends solely on the frame rate of the video and spatial resolution depends solely on the pixel grid. However, this dependence arises naturally in event-based video and allows oversampling in space to provide better time resolution. As such, event-based vision encourages using more sensors that emit fewer events over time.
* 6 pages, 4 figures
The Neural-Prediction based Acceleration Algorithm of Column Generation for Graph-Based Set Covering Problems
Jul 12, 2022
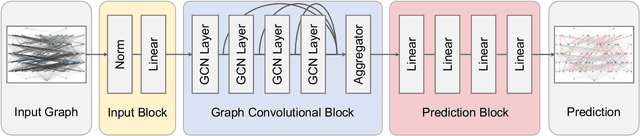
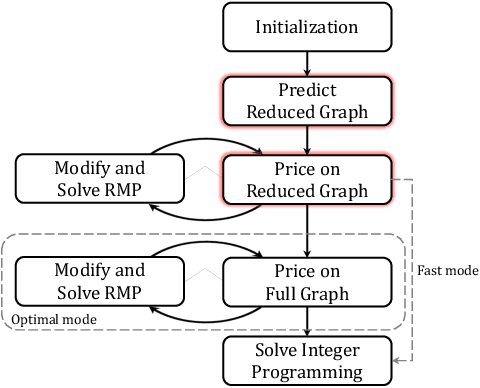
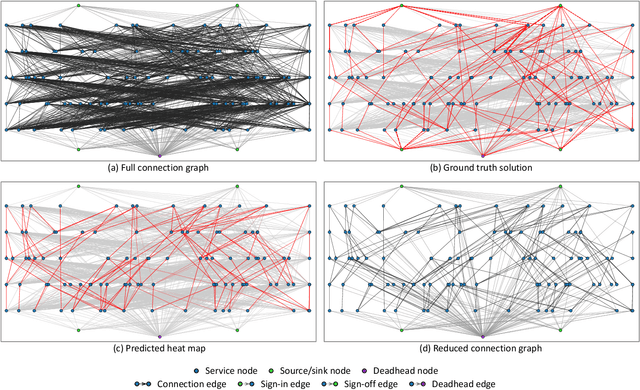
Set covering problem is an important class of combinatorial optimization problems, which has been widely applied and studied in many fields. In this paper, we propose an improved column generation algorithm with neural prediction (CG-P) for solving graph-based set covering problems. We leverage a graph neural network based neural prediction model to predict the probability to be included in the final solution for each edge. Our CG-P algorithm constructs a reduced graph that only contains the edges with higher predicted probability, and this graph reduction process significantly speeds up the solution process. We evaluate the CG-P algorithm on railway crew scheduling problems and it outperforms the baseline column generation algorithm. We provide two solution modes for our CG-P algorithm. In the optimal mode, we can obtain a solution with an optimality guarantee while reducing the time cost to 63.12%. In the fast mode, we can obtain a sub-optimal solution with a 7.62% optimality gap in only 2.91% computation time.
Continuous Sign Language Recognition via Temporal Super-Resolution Network
Jul 03, 2022
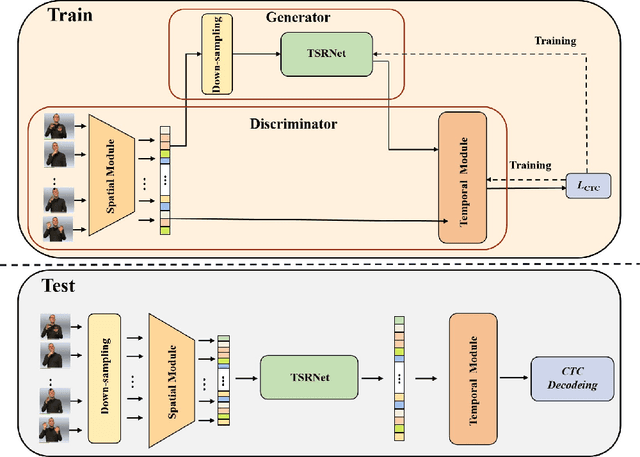
Aiming at the problem that the spatial-temporal hierarchical continuous sign language recognition model based on deep learning has a large amount of computation, which limits the real-time application of the model, this paper proposes a temporal super-resolution network(TSRNet). The data is reconstructed into a dense feature sequence to reduce the overall model computation while keeping the final recognition accuracy loss to a minimum. The continuous sign language recognition model(CSLR) via TSRNet mainly consists of three parts: frame-level feature extraction, time series feature extraction and TSRNet, where TSRNet is located between frame-level feature extraction and time-series feature extraction, which mainly includes two branches: detail descriptor and rough descriptor. The sparse frame-level features are fused through the features obtained by the two designed branches as the reconstructed dense frame-level feature sequence, and the connectionist temporal classification(CTC) loss is used for training and optimization after the time-series feature extraction part. To better recover semantic-level information, the overall model is trained with the self-generating adversarial training method proposed in this paper to reduce the model error rate. The training method regards the TSRNet as the generator, and the frame-level processing part and the temporal processing part as the discriminator. In addition, in order to unify the evaluation criteria of model accuracy loss under different benchmarks, this paper proposes word error rate deviation(WERD), which takes the error rate between the estimated word error rate (WER) and the reference WER obtained by the reconstructed frame-level feature sequence and the complete original frame-level feature sequence as the WERD. Experiments on two large-scale sign language datasets demonstrate the effectiveness of the proposed model.
RIS-Aided Angular-Based Hybrid Beamforming Design in mmWave Massive MIMO Systems
Aug 13, 2022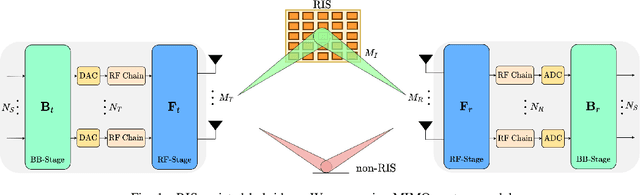
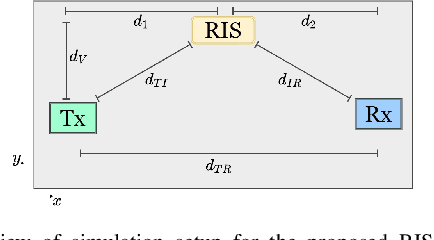
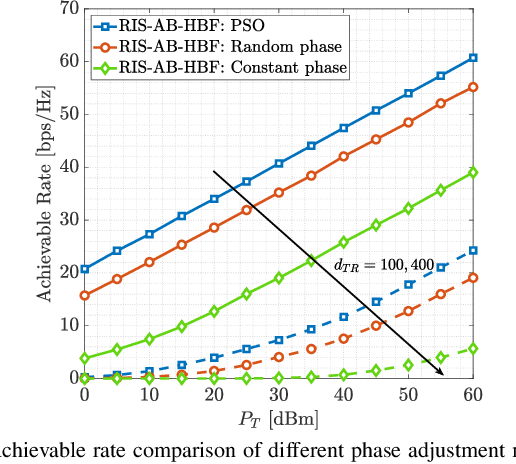
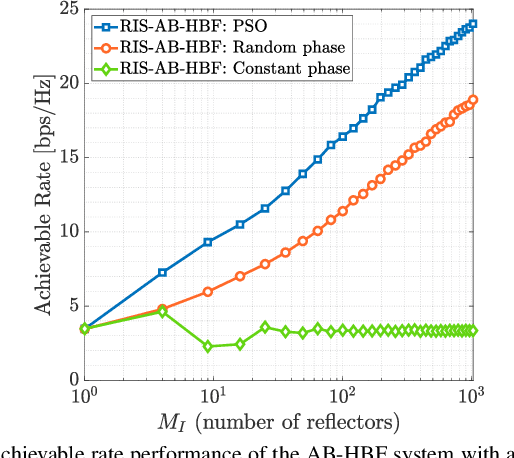
This paper proposes a reconfigurable intelligent surface (RIS)-aided and angular-based hybrid beamforming (AB-HBF) technique for the millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems. The proposed RIS-AB-HBF architecture consists of three stages: (i) RF beamformer, (ii) baseband (BB) precoder/combiner, and (iii) RIS phase shift design. First, in order to reduce the number of RF chains and the channel estimation overhead, RF beamformers are designed based on the 3D geometry-based mmWave channel model using slow time-varying angular parameters of the channel. Second, a BB precoder/combiner is designed by exploiting the reduced-size effective channel seen from the BB stages. Then, the phase shifts of the RIS are adjusted to maximize the achievable rate of the system via the nature-inspired particle swarm optimization (PSO) algorithm. Illustrative simulation results demonstrate that the use of RISs in the AB-HBF systems has the potential to provide more promising advantages in terms of reliability and flexibility in system design.
Detection of Increased Time Intervals of Anti-Vaccine Tweets for COVID-19 Vaccine with BERT Model
Jan 12, 2022The most effective of the solutions against Covid-19 is the various vaccines developed. Distrust of vaccines can hinder the rapid and effective use of this remedy. One of the means of expressing the thoughts of society is social media. Determining the time intervals during which anti-vaccination increases in social media can help institutions determine the strategy to be used in combating anti-vaccination. Recording and tracking every tweet entered with human labor would be inefficient, so various automation solutions are needed. In this study, The Bidirectional Encoder Representations from Transformers (BERT) model, which is a deep learning-based natural language processing (NLP) model, was used. In a dataset of 1506 tweets divided into four different categories as news, irrelevant, anti-vaccine, and vaccine supporters, the model was trained with a learning rate of 5e-6 for 25 epochs. To determine the intervals in which anti-vaccine tweets are concentrated, the categories to which 652840 tweets belong were determined by using the trained model. The change of the determined categories overtime was visualized and the events that could cause the change were determined. As a result of model training, in the test dataset, the f-score of 0.81 and AUC values for different classes were obtained as 0.99,0.91, 0.92, 0.92, respectively. In this model, unlike the studies in the literature, an auxiliary system is designed that provides data that institutions can use when determining their strategy by measuring and visualizing the frequency of anti-vaccine tweets in a time interval, different from detecting and censoring such tweets.
Real-time Online Multi-Object Tracking in Compressed Domain
Apr 05, 2022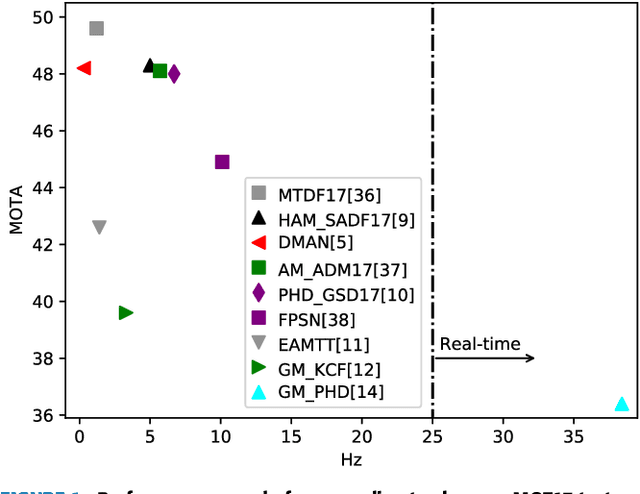

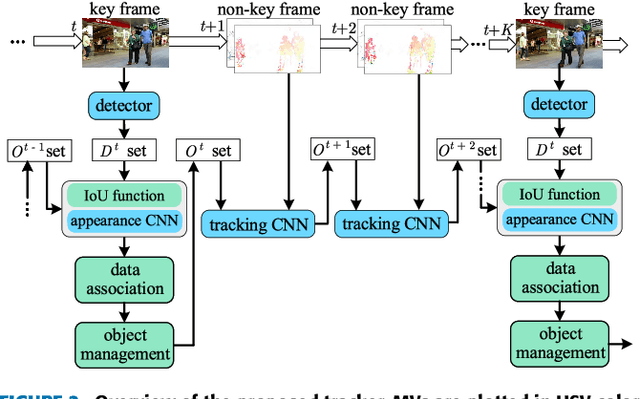
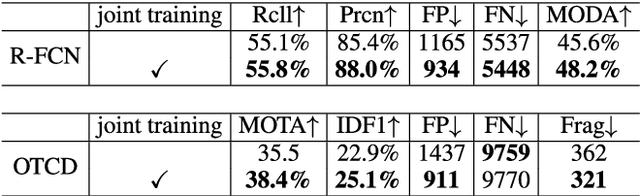
Recent online Multi-Object Tracking (MOT) methods have achieved desirable tracking performance. However, the tracking speed of most existing methods is rather slow. Inspired from the fact that the adjacent frames are highly relevant and redundant, we divide the frames into key and non-key frames respectively and track objects in the compressed domain. For the key frames, the RGB images are restored for detection and data association. To make data association more reliable, an appearance Convolutional Neural Network (CNN) which can be jointly trained with the detector is proposed. For the non-key frames, the objects are directly propagated by a tracking CNN based on the motion information provided in the compressed domain. Compared with the state-of-the-art online MOT methods,our tracker is about 6x faster while maintaining a comparable tracking performance.
Dynamic Ranking and Translation Synchronization
Jul 15, 2022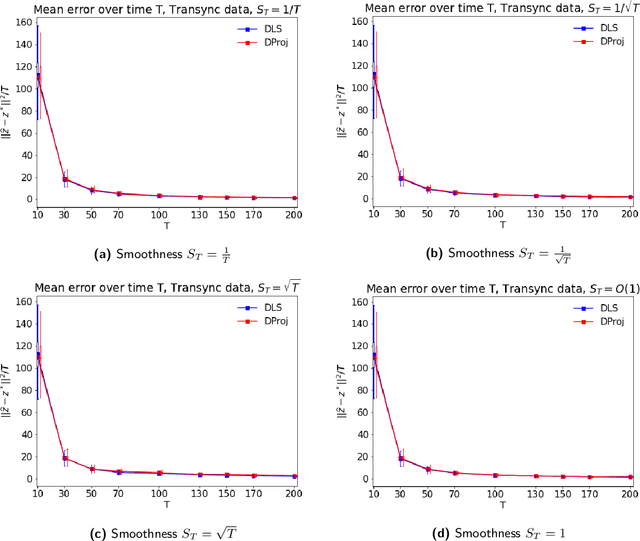

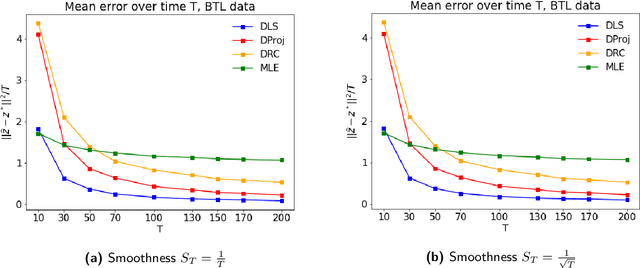
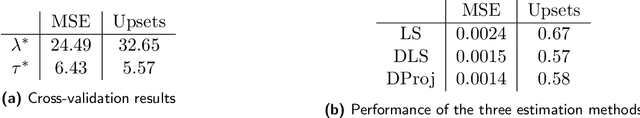
In many applications, such as sport tournaments or recommendation systems, we have at our disposal data consisting of pairwise comparisons between a set of $n$ items (or players). The objective is to use this data to infer the latent strength of each item and/or their ranking. Existing results for this problem predominantly focus on the setting consisting of a single comparison graph $G$. However, there exist scenarios (e.g., sports tournaments) where the the pairwise comparison data evolves with time. Theoretical results for this dynamic setting are relatively limited and is the focus of this paper. We study an extension of the \emph{translation synchronization} problem, to the dynamic setting. In this setup, we are given a sequence of comparison graphs $(G_t)_{t\in \mathcal{T}}$, where $\mathcal{T} \subset [0,1]$ is a grid representing the time domain, and for each item $i$ and time $t\in \mathcal{T}$ there is an associated unknown strength parameter $z^*_{t,i}\in \mathbb{R}$. We aim to recover, for $t\in\mathcal{T}$, the strength vector $z^*_t=(z^*_{t,1},\dots,z^*_{t,n})$ from noisy measurements of $z^*_{t,i}-z^*_{t,j}$, where $\{i,j\}$ is an edge in $G_t$. Assuming that $z^*_t$ evolves smoothly in $t$, we propose two estimators -- one based on a smoothness-penalized least squares approach and the other based on projection onto the low frequency eigenspace of a suitable smoothness operator. For both estimators, we provide finite sample bounds for the $\ell_2$ estimation error under the assumption that $G_t$ is connected for all $t\in \mathcal{T}$, thus proving the consistency of the proposed methods in terms of the grid size $|\mathcal{T}|$. We complement our theoretical findings with experiments on synthetic and real data.
Differentiable Programming for Earth System Modeling
Aug 29, 2022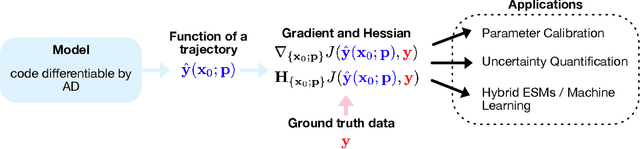
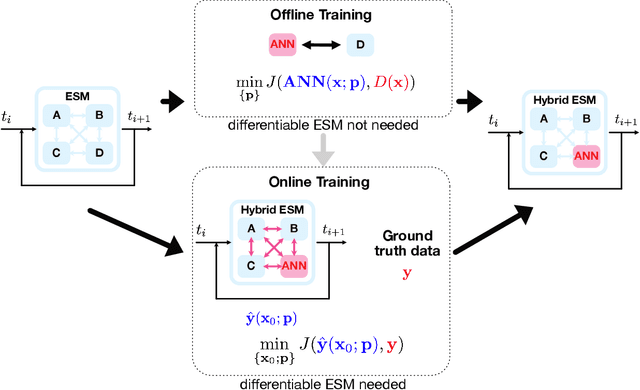
Earth System Models (ESMs) are the primary tools for investigating future Earth system states at time scales from decades to centuries, especially in response to anthropogenic greenhouse gas release. State-of-the-art ESMs can reproduce the observational global mean temperature anomalies of the last 150 years. Nevertheless, ESMs need further improvements, most importantly regarding (i) the large spread in their estimates of climate sensitivity, i.e., the temperature response to increases in atmospheric greenhouse gases, (ii) the modeled spatial patterns of key variables such as temperature and precipitation, (iii) their representation of extreme weather events, and (iv) their representation of multistable Earth system components and their ability to predict associated abrupt transitions. Here, we argue that making ESMs automatically differentiable has huge potential to advance ESMs, especially with respect to these key shortcomings. First, automatic differentiability would allow objective calibration of ESMs, i.e., the selection of optimal values with respect to a cost function for a large number of free parameters, which are currently tuned mostly manually. Second, recent advances in Machine Learning (ML) and in the amount, accuracy, and resolution of observational data promise to be helpful with at least some of the above aspects because ML may be used to incorporate additional information from observations into ESMs. Automatic differentiability is an essential ingredient in the construction of such hybrid models, combining process-based ESMs with ML components. We document recent work showcasing the potential of automatic differentiation for a new generation of substantially improved, data-informed ESMs.