 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DNN-Free Low-Latency Adaptive Speech Enhancement Based on Frame-Online Beamforming Powered by Block-Online FastMNMF
Jul 22, 2022
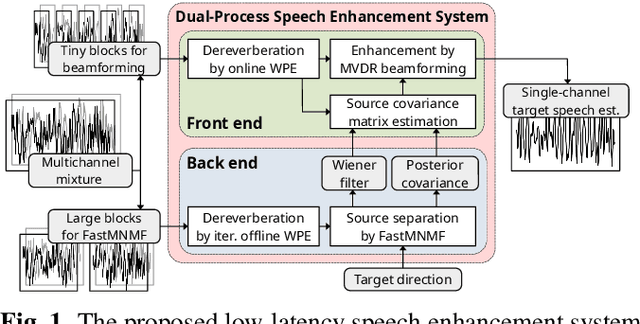
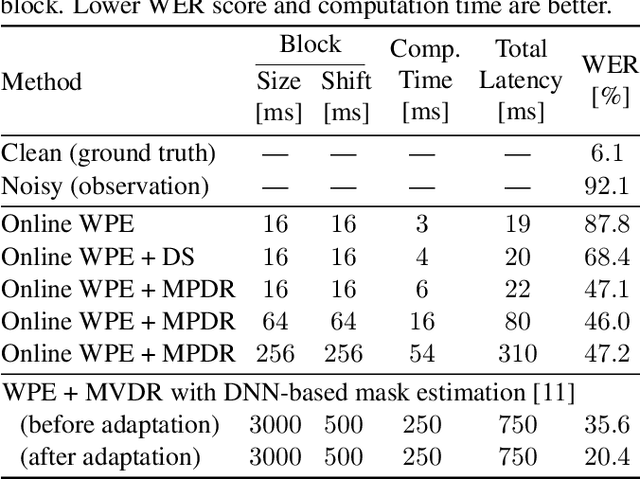

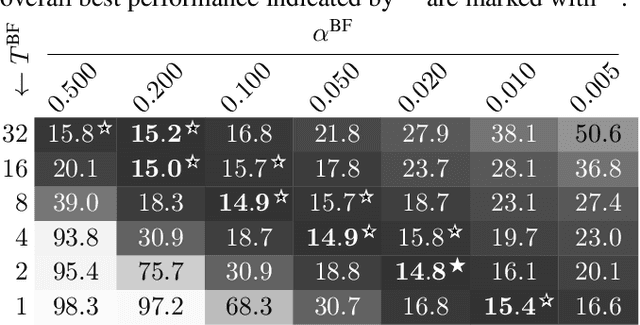
This paper describes a practical dual-process speech enhancement system that adapts environment-sensitive frame-online beamforming (front-end) with help from environment-free block-online source separation (back-end). To use minimum variance distortionless response (MVDR) beamforming, one may train a deep neural network (DNN) that estimates time-frequency masks used for computing the covariance matrices of sources (speech and noise). Backpropagation-based run-time adaptation of the DNN was proposed for dealing with the mismatched training-test conditions. Instead, one may try to directly estimate the source covariance matrices with a state-of-the-art blind source separation method called fast multichannel non-negative matrix factorization (FastMNMF). In practice, however, neither the DNN nor the FastMNMF can be updated in a frame-online manner due to its computationally-expensive iterative nature. Our DNN-free system leverages the posteriors of the latest source spectrograms given by block-online FastMNMF to derive the current source covariance matrices for frame-online beamforming. The evaluation shows that our frame-online system can quickly respond to scene changes caused by interfering speaker movements and outperformed an existing block-online system with DNN-based beamforming by 5.0 points in terms of the word error rate.
Modeling Live Video Streaming: Real-Time Classification, QoE Inference, and Field Evaluation
Dec 05, 2021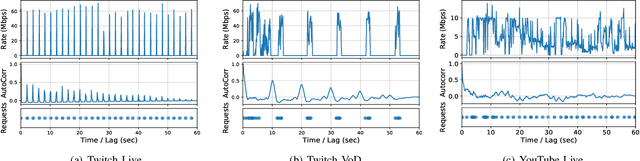
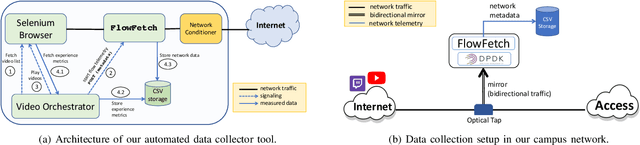
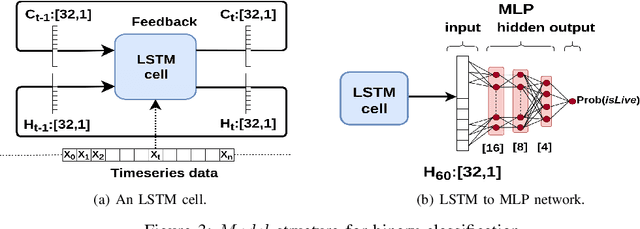
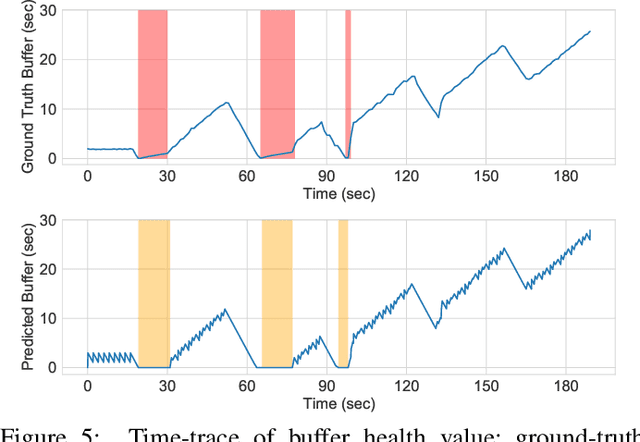
Social media, professional sports, and video games are driving rapid growth in live video streaming, on platforms such as Twitch and YouTube Live. Live streaming experience is very susceptible to short-time-scale network congestion since client playback buffers are often no more than a few seconds. Unfortunately, identifying such streams and measuring their QoE for network management is challenging, since content providers largely use the same delivery infrastructure for live and video-on-demand (VoD) streaming, and packet inspection techniques (including SNI/DNS query monitoring) cannot always distinguish between the two. In this paper, we design, build, and deploy ReCLive: a machine learning method for live video detection and QoE measurement based on network-level behavioral characteristics. Our contributions are four-fold: (1) We analyze about 23,000 video streams from Twitch and YouTube, and identify key features in their traffic profile that differentiate live and on-demand streaming. We release our traffic traces as open data to the public; (2) We develop an LSTM-based binary classifier model that distinguishes live from on-demand streams in real-time with over 95% accuracy across providers; (3) We develop a method that estimates QoE metrics of live streaming flows in terms of resolution and buffer stall events with overall accuracies of 93% and 90%, respectively; and (4) Finally, we prototype our solution, train it in the lab, and deploy it in a live ISP network serving more than 7,000 subscribers. Our method provides ISPs with fine-grained visibility into live video streams, enabling them to measure and improve user experience.
Channel Sounder with Over-the-Air Antenna Synchronization: Absolute Phase and Timing Calibration Using Known Transmitter Locations
Jun 13, 2022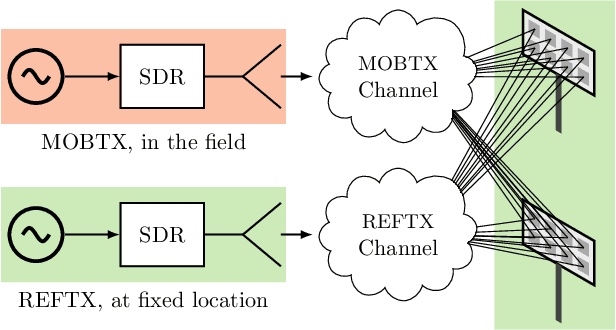
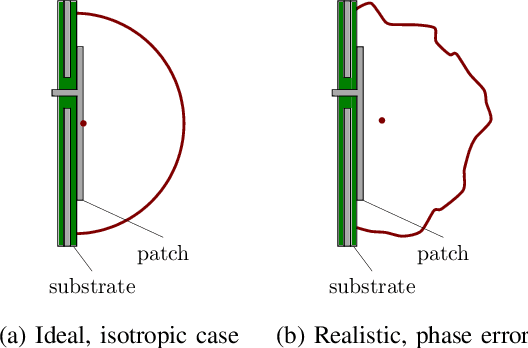
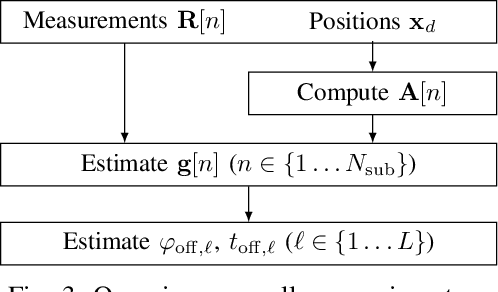
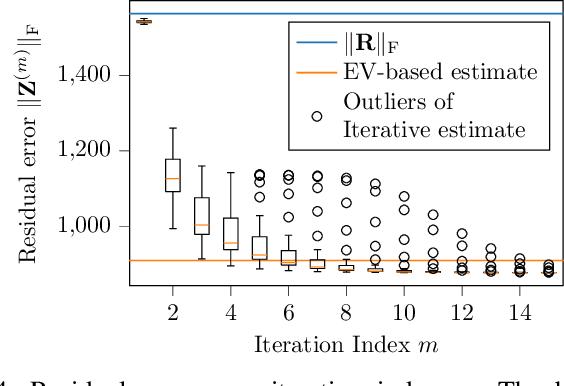
Synchronization of transceiver chains is a major challenge in the practical realization of massive MIMO and especially distributed massive MIMO. While frequency synchronization is comparatively easy to achieve, estimating the carrier phase and sampling time offsets of individual transceivers is challenging. However, under the assumption of phase and time offsets that are constant over some duration and knowing the positions of several transmit and receive antennas, it is possible to estimate and compensate for these offsets even in scattering environments with multipath propagation components. The resulting phase and time calibration is a prerequisite for applying classical antenna array processing methods to massive MIMO arrays and for transferring machine learning models either between simulation and deployment or from one radio environment to another. Algorithms for phase and time offset estimation are presented and several investigations on large datasets generated by an over-the-air-synchronized channel sounder are carried out.
Deep Reinforcement Learning based Robot Navigation in Dynamic Environments using Occupancy Values of Motion Primitives
Aug 17, 2022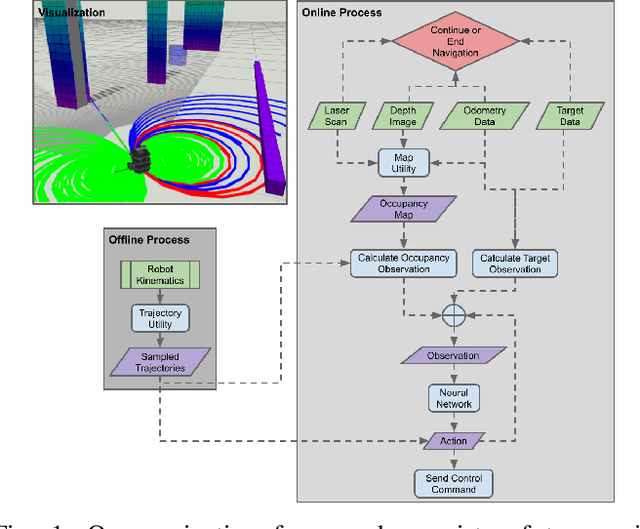
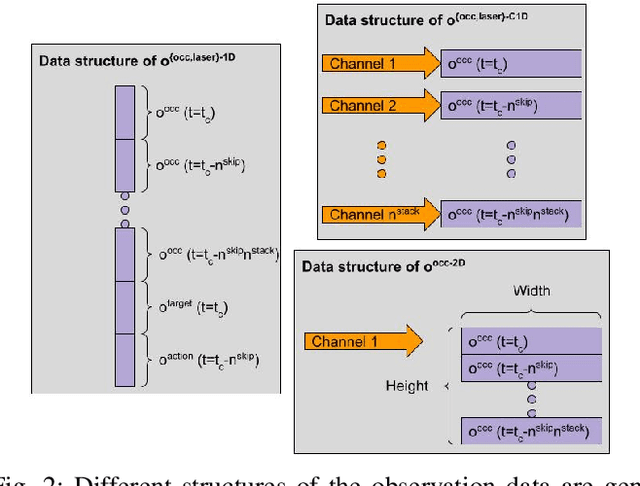
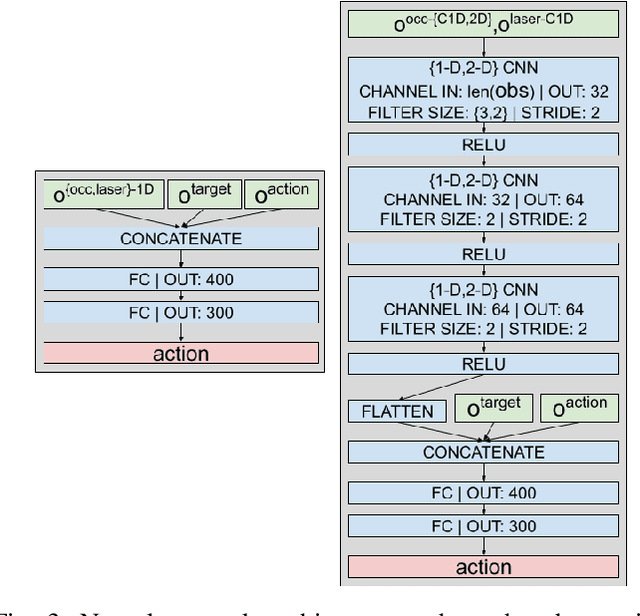
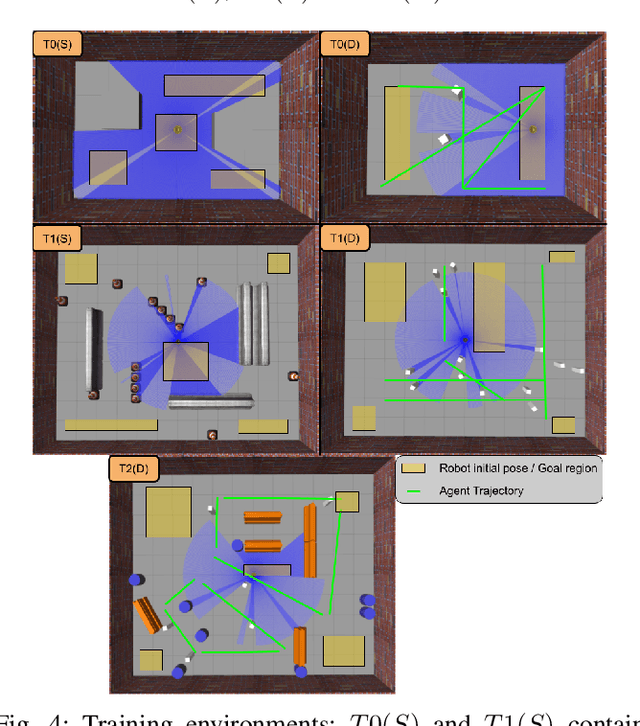
This paper presents a Deep Reinforcement Learning based navigation approach in which we define the occupancy observations as heuristic evaluations of motion primitives, rather than using raw sensor data. Our method enables fast mapping of the occupancy data, generated by multi-sensor fusion, into trajectory values in 3D workspace. The computationally efficient trajectory evaluation allows dense sampling of the action space. We utilize our occupancy observations in different data structures to analyze their effects on both training process and navigation performance. We train and test our methodology on two different robots within challenging physics-based simulation environments including static and dynamic obstacles. We benchmark our occupancy representations with other conventional data structures from state-of-the-art methods. The trained navigation policies are also validated successfully with physical robots in dynamic environments. The results show that our method not only decreases the required training time but also improves the navigation performance as compared to other occupancy representations. The open-source implementation of our work and all related info are available at \url{https://github.com/RIVeR-Lab/tentabot}.
Quantum Multi-Agent Meta Reinforcement Learning
Aug 22, 2022Although quantum supremacy is yet to come, there has recently been an increasing interest in identifying the potential of quantum machine learning (QML) in the looming era of practical quantum computing. Motivated by this, in this article we re-design multi-agent reinforcement learning (MARL) based on the unique characteristics of quantum neural networks (QNNs) having two separate dimensions of trainable parameters: angle parameters affecting the output qubit states, and pole parameters associated with the output measurement basis. Exploiting this dyadic trainability as meta-learning capability, we propose quantum meta MARL (QM2ARL) that first applies angle training for meta-QNN learning, followed by pole training for few-shot or local-QNN training. To avoid overfitting, we develop an angle-to-pole regularization technique injecting noise into the pole domain during angle training. Furthermore, by exploiting the pole as the memory address of each trained QNN, we introduce the concept of pole memory allowing one to save and load trained QNNs using only two-parameter pole values. We theoretically prove the convergence of angle training under the angle-to-pole regularization, and by simulation corroborate the effectiveness of QM2ARL in achieving high reward and fast convergence, as well as of the pole memory in fast adaptation to a time-varying environment.
Symbolic Regression is NP-hard
Jul 05, 2022Symbolic regression (SR) is the task of learning a model of data in the form of a mathematical expression. By their nature, SR models have the potential to be accurate and human-interpretable at the same time. Unfortunately, finding such models, i.e., performing SR, appears to be a computationally intensive task. Historically, SR has been tackled with heuristics such as greedy or genetic algorithms and, while some works have hinted at the possible hardness of SR, no proof has yet been given that SR is, in fact, NP-hard. This begs the question: Is there an exact polynomial-time algorithm to compute SR models? We provide evidence suggesting that the answer is probably negative by showing that SR is NP-hard.
Concurrent Validity of Automatic Speech and Pause Measures During Passage Reading in ALS
Aug 22, 2022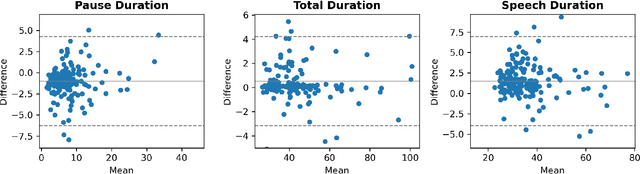
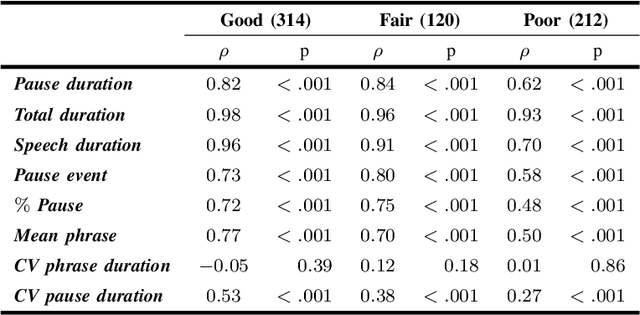
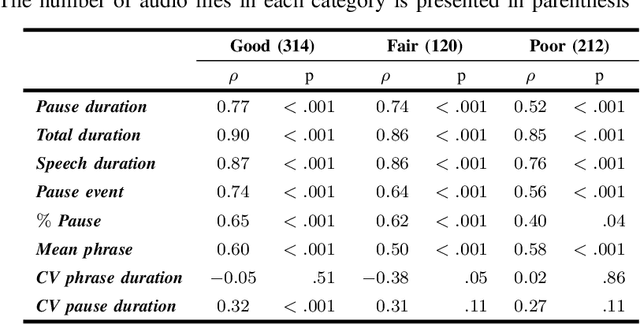
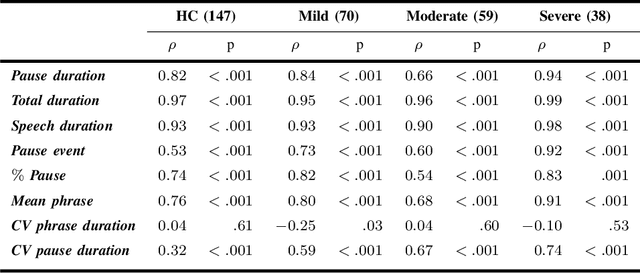
The analysis of speech measures in individuals with amyotrophic lateral sclerosis (ALS) can provide essential information for early diagnosis and tracking disease progression. However, current methods for extracting speech and pause features are manual or semi-automatic, which makes them time-consuming and labour-intensive. The advent of speech-text alignment algorithms provides an opportunity for inexpensive, automated, and accurate analysis of speech measures in individuals with ALS. There is a need to validate speech and pause features calculated by these algorithms against current gold standard methods. In this study, we extracted 8 speech/pause features from 646 audio files of individuals with ALS and healthy controls performing passage reading. Two pretrained forced alignment models - one using transformers and another using a Gaussian mixture / hidden Markov architecture - were used for automatic feature extraction. The results were then validated against semi-automatic speech/pause analysis software, with further subgroup analyses based on audio quality and disease severity. Features extracted using transformer-based forced alignment had the highest agreement with gold standards, including in terms of audio quality and disease severity. This study lays the groundwork for future intelligent diagnostic support systems for clinicians, and for novel methods of tracking disease progression remotely from home.
A Survey and Framework of Cooperative Perception: From Heterogeneous Singleton to Hierarchical Cooperation
Aug 22, 2022
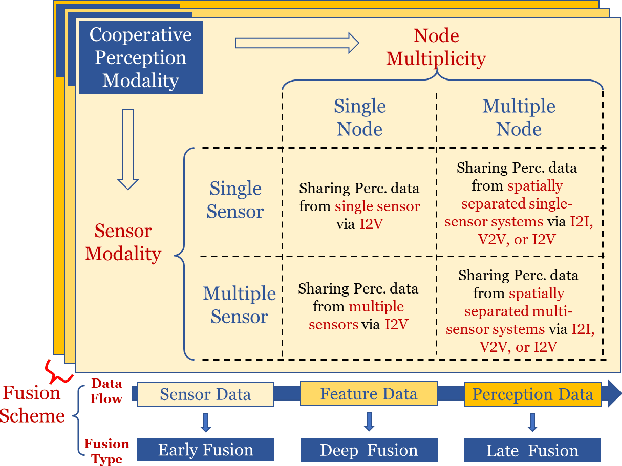
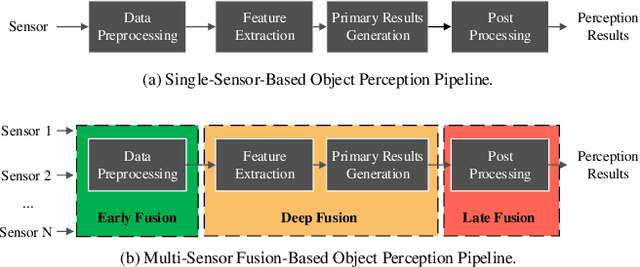
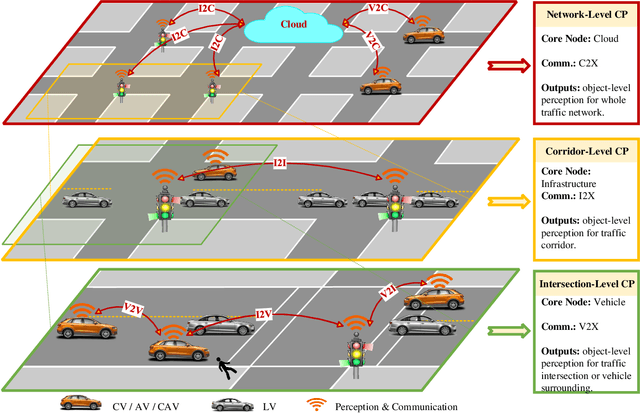
Perceiving the environment is one of the most fundamental keys to enabling Cooperative Driving Automation (CDA), which is regarded as the revolutionary solution to addressing the safety, mobility, and sustainability issues of contemporary transportation systems. Although an unprecedented evolution is now happening in the area of computer vision for object perception, state-of-the-art perception methods are still struggling with sophisticated real-world traffic environments due to the inevitably physical occlusion and limited receptive field of single-vehicle systems. Based on multiple spatially separated perception nodes, Cooperative Perception (CP) is born to unlock the bottleneck of perception for driving automation. In this paper, we comprehensively review and analyze the research progress on CP and, to the best of our knowledge, this is the first time to propose a unified CP framework. Architectures and taxonomy of CP systems based on different types of sensors are reviewed to show a high-level description of the workflow and different structures for CP systems. Node structure, sensor modality, and fusion schemes are reviewed and analyzed with comprehensive literature to provide detailed explanations of specific methods. A Hierarchical CP framework is proposed, followed by a review of existing Datasets and Simulators to sketch an overall landscape of CP. Discussion highlights the current opportunities, open challenges, and anticipated future trends.
NMPC-LBF: Nonlinear MPC with Learned Barrier Function for Decentralized Safe Navigation of Multiple Robots in Unknown Environments
Aug 16, 2022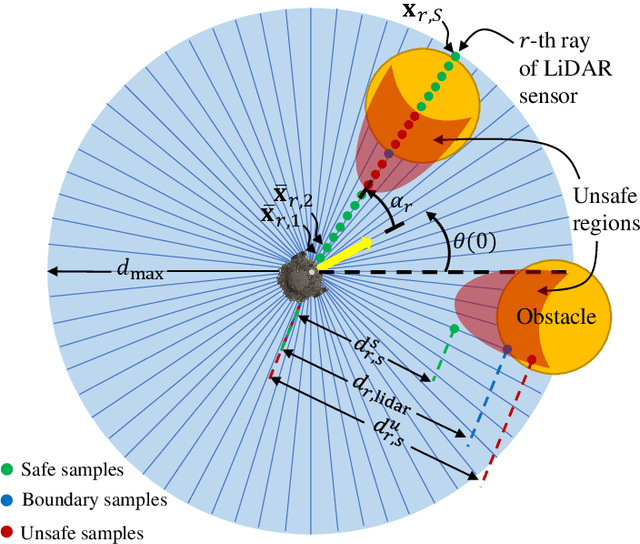
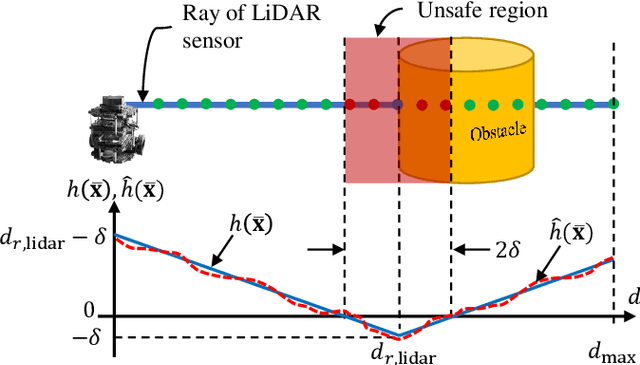
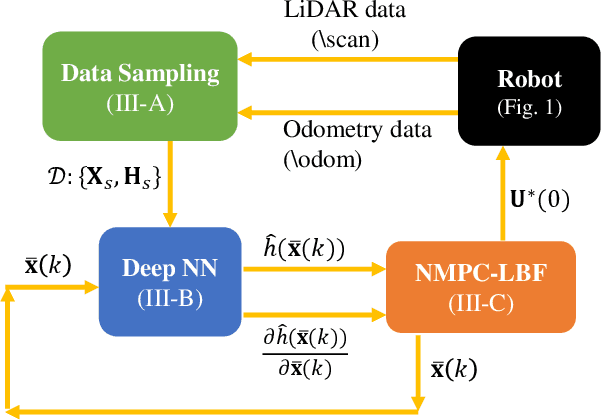
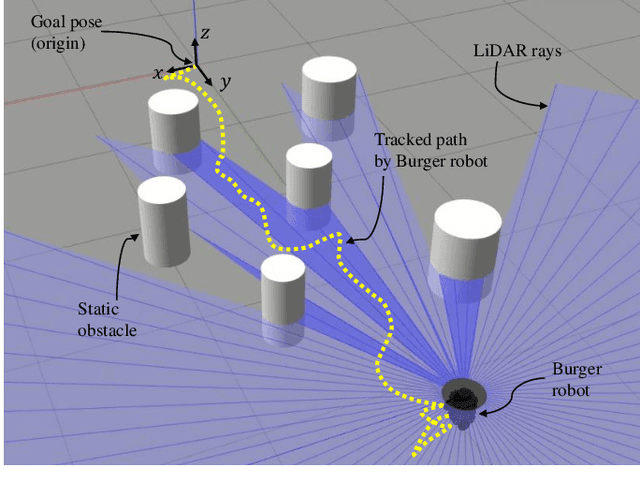
In this paper, we present a decentralized control approach based on a Nonlinear Model Predictive Control (NMPC) method that employs barrier certificates for safe navigation of multiple nonholonomic wheeled mobile robots in unknown environments with static and/or dynamic obstacles. This method incorporates a Learned Barrier Function (LBF) into the NMPC design in order to guarantee safe robot navigation, i.e., prevent robot collisions with other robots and the obstacles. We refer to our proposed control approach as NMPC-LBF. Since each robot does not have a priori knowledge about the obstacles and other robots, we use a Deep Neural Network (DeepNN) running in real-time on each robot to learn the Barrier Function (BF) only from the robot's LiDAR and odometry measurements. The DeepNN is trained to learn the BF that separates safe and unsafe regions. We implemented our proposed method on simulated and actual Turtlebot3 Burger robot(s) in different scenarios. The implementation results show the effectiveness of the NMPC-LBF method at ensuring safe navigation of the robots.
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022



As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.