 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating Sparse Sources from Data Mixtures using Maxima in Phase Space Plots
Aug 17, 2022
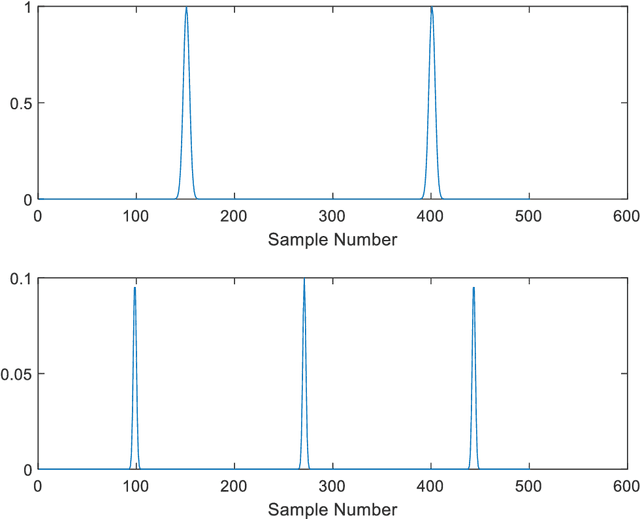
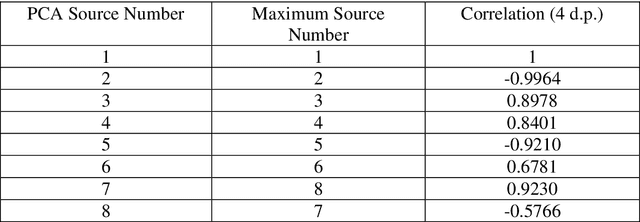
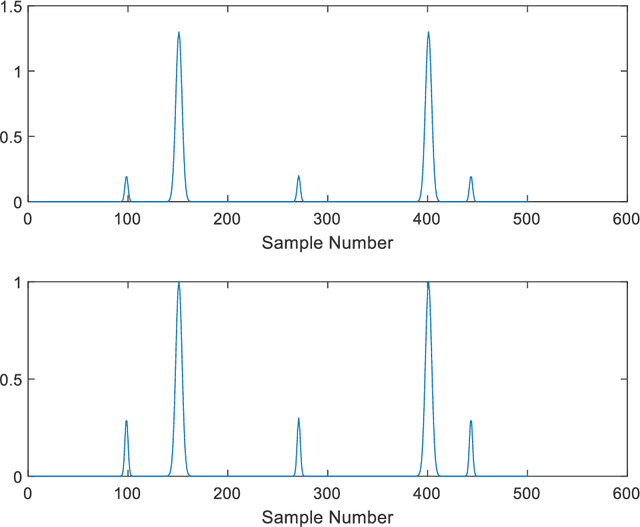
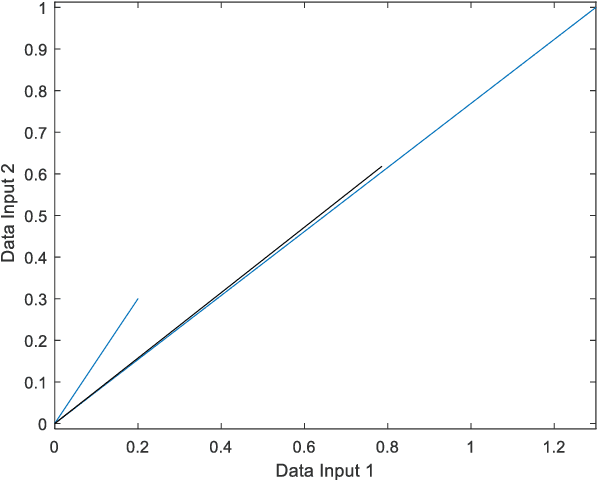
In Blind Source Separation (BSS), one estimates sources from data mixtures where the mixing coefficients are unknown. In the particular case of Sparse Component Analysis (SCA), each underlying source exists for only a finite amount of time when other sources are negligible. In this paper, one approach to SCA is presented where the data are represented using phase space analysis and one estimates the main source from the maximum in the phase plot. Deflation is used to estimate the other sources. The proposed method is tested on simulated data and experimental ECG data taken from an expectant mother. It is shown that, in most cases, the performance of the proposed method is comparable to that of Principal Component Analysis (PCA) and FastICA for clean data. In the case of noisy data, PCA is found to be more robust for higher noise levels. For situations where the sources have coincident peaks, the method breaks down as expected, as the maximum in the phase plot does not correspond to an individual source.
Predicting skull fractures via CNN with classification algorithms
Aug 14, 2022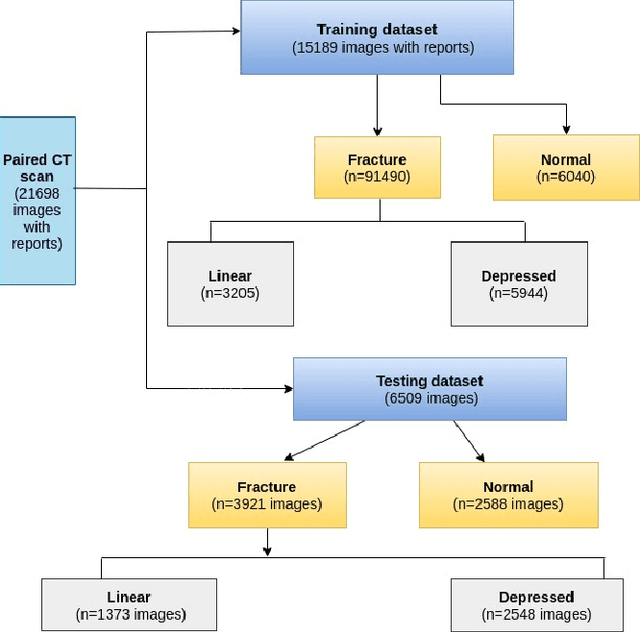
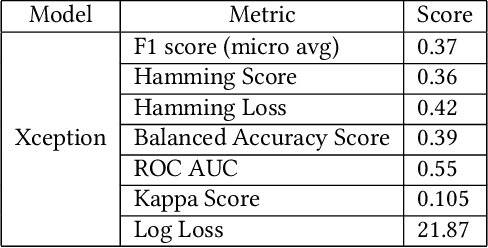
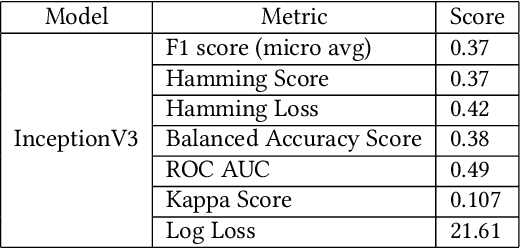
Computer Tomography (CT) images have become quite important to diagnose diseases. CT scan slice contains a vast amount of data that may not be properly examined with the requisite precision and speed using normal visual inspection. A computer-assisted skull fracture classification expert system is needed to assist physicians. Convolutional Neural Networks (CNNs) are the most extensively used deep learning models for image categorization since most often time they outperform other models in terms of accuracy and results. The CNN models were then developed and tested, and several convolutional neural network (CNN) architectures were compared. ResNet50, which was used for feature extraction combined with a gradient boosted decision tree machine learning algorithm to act as a classifier for the categorization of skull fractures from brain CT scans into three fracture categories, had the best overall F1-score of 96%, Hamming Score of 95%, Balanced accuracy Score of 94% & ROC AUC curve of 96% for the classification of skull fractures.
A Gis Aided Approach for Geolocalizing an Unmanned Aerial System Using Deep Learning
Aug 25, 2022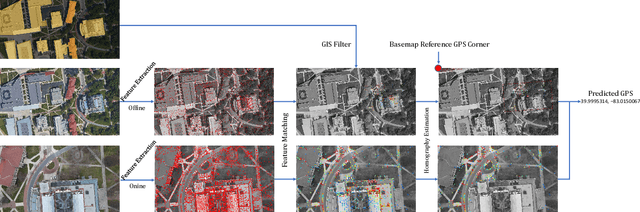
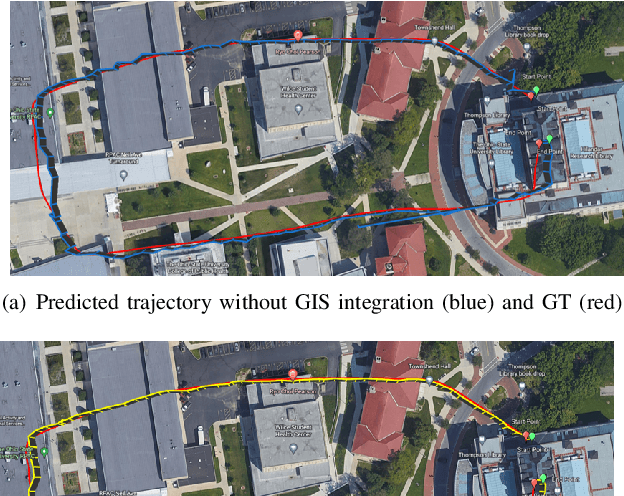
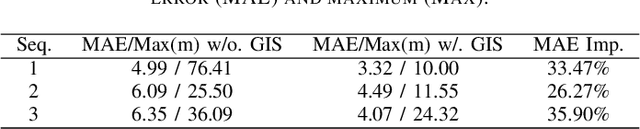
The Global Positioning System (GPS) has become a part of our daily life with the primary goal of providing geopositioning service. For an unmanned aerial system (UAS), geolocalization ability is an extremely important necessity which is achieved using Inertial Navigation System (INS) with the GPS at its heart. Without geopositioning service, UAS is unable to fly to its destination or come back home. Unfortunately, GPS signals can be jammed and suffer from a multipath problem in urban canyons. Our goal is to propose an alternative approach to geolocalize a UAS when GPS signal is degraded or denied. Considering UAS has a downward-looking camera on its platform that can acquire real-time images as the platform flies, we apply modern deep learning techniques to achieve geolocalization. In particular, we perform image matching to establish latent feature conjugates between UAS acquired imagery and satellite orthophotos. A typical application of feature matching suffers from high-rise buildings and new constructions in the field that introduce uncertainties into homography estimation, hence results in poor geolocalization performance. Instead, we extract GIS information from OpenStreetMap (OSM) to semantically segment matched features into building and terrain classes. The GIS mask works as a filter in selecting semantically matched features that enhance coplanarity conditions and the UAS geolocalization accuracy. Once the paper is published our code will be publicly available at https://github.com/OSUPCVLab/UbihereDrone2021.
Adaptation Strategy for a Distributed Autonomous UAV Formation in Case of Aircraft Loss
Aug 04, 2022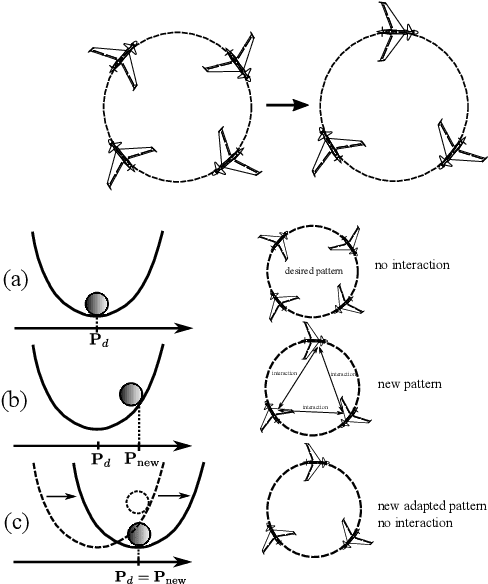
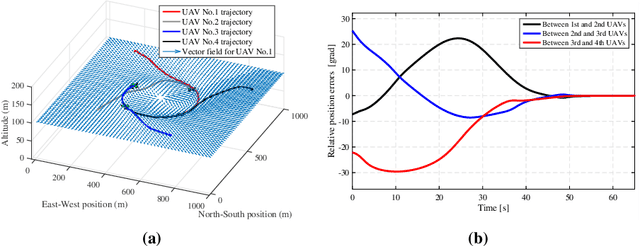
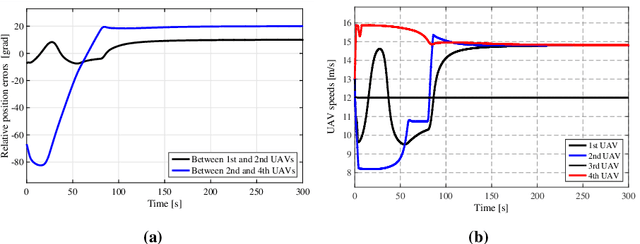
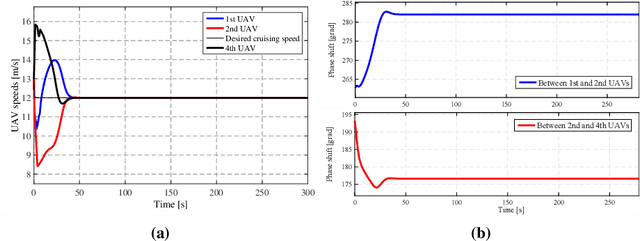
Controlling a distributed autonomous unmanned aerial vehicle (UAV) formation is usually considered in the context of recovering the connectivity graph should a single UAV agent be lost. At the same time, little focus is made on how such loss affects the dynamics of the formation as a system. To compensate for the negative effects, we propose an adaptation algorithm that reduces the increasing interaction between the UAV agents that remain in the formation. This algorithm enables the autonomous system to adjust to the new equilibrium state. The algorithm has been tested by computer simulation on full nonlinear UAV models. Simulation results prove the negative effect (the increased final cruising speed of the formation) to be completely eliminated.
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes
Aug 01, 2022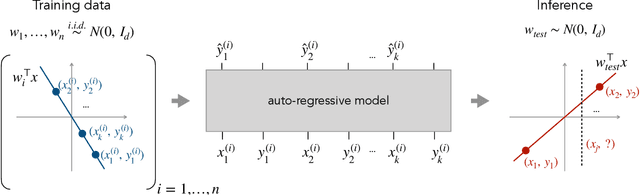
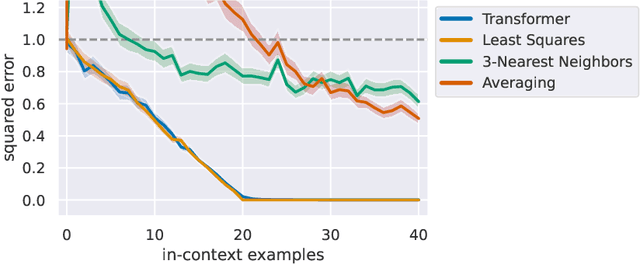
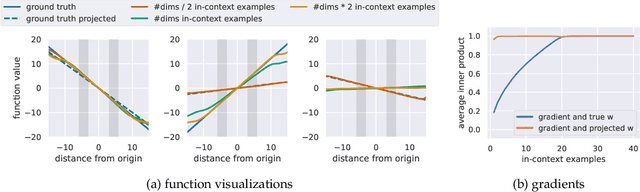
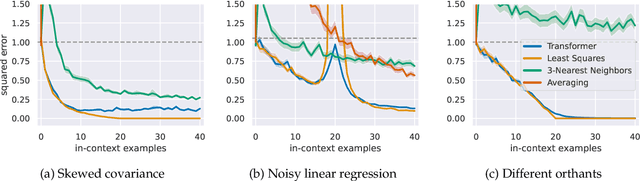
In-context learning refers to the ability of a model to condition on a prompt sequence consisting of in-context examples (input-output pairs corresponding to some task) along with a new query input, and generate the corresponding output. Crucially, in-context learning happens only at inference time without any parameter updates to the model. While large language models such as GPT-3 exhibit some ability to perform in-context learning, it is unclear what the relationship is between tasks on which this succeeds and what is present in the training data. To make progress towards understanding in-context learning, we consider the well-defined problem of training a model to in-context learn a function class (e.g., linear functions): that is, given data derived from some functions in the class, can we train a model to in-context learn "most" functions from this class? We show empirically that standard Transformers can be trained from scratch to perform in-context learning of linear functions -- that is, the trained model is able to learn unseen linear functions from in-context examples with performance comparable to the optimal least squares estimator. In fact, in-context learning is possible even under two forms of distribution shift: (i) between the training data of the model and inference-time prompts, and (ii) between the in-context examples and the query input during inference. We also show that we can train Transformers to in-context learn more complex function classes -- namely sparse linear functions, two-layer neural networks, and decision trees -- with performance that matches or exceeds task-specific learning algorithms. Our code and models are available at https://github.com/dtsip/in-context-learning .
Paint2Pix: Interactive Painting based Progressive Image Synthesis and Editing
Aug 17, 2022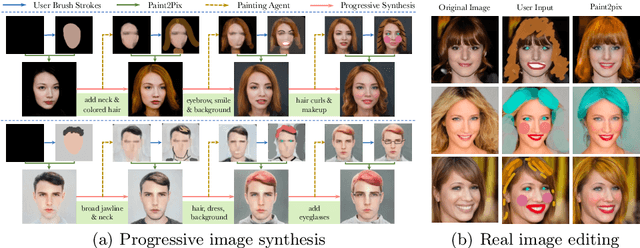
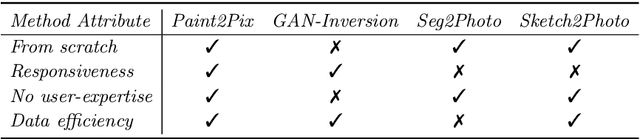
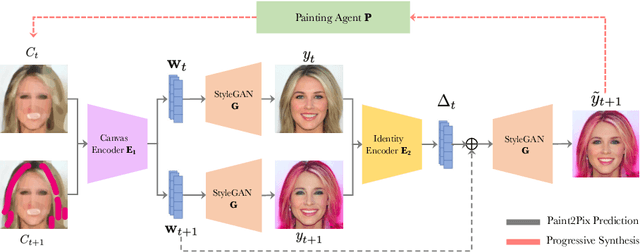
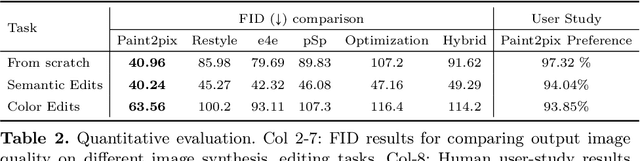
Controllable image synthesis with user scribbles is a topic of keen interest in the computer vision community. In this paper, for the first time we study the problem of photorealistic image synthesis from incomplete and primitive human paintings. In particular, we propose a novel approach paint2pix, which learns to predict (and adapt) "what a user wants to draw" from rudimentary brushstroke inputs, by learning a mapping from the manifold of incomplete human paintings to their realistic renderings. When used in conjunction with recent works in autonomous painting agents, we show that paint2pix can be used for progressive image synthesis from scratch. During this process, paint2pix allows a novice user to progressively synthesize the desired image output, while requiring just few coarse user scribbles to accurately steer the trajectory of the synthesis process. Furthermore, we find that our approach also forms a surprisingly convenient approach for real image editing, and allows the user to perform a diverse range of custom fine-grained edits through the addition of only a few well-placed brushstrokes. Supplemental video and demo are available at https://1jsingh.github.io/paint2pix
* ECCV 2022
AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing
Jul 27, 2022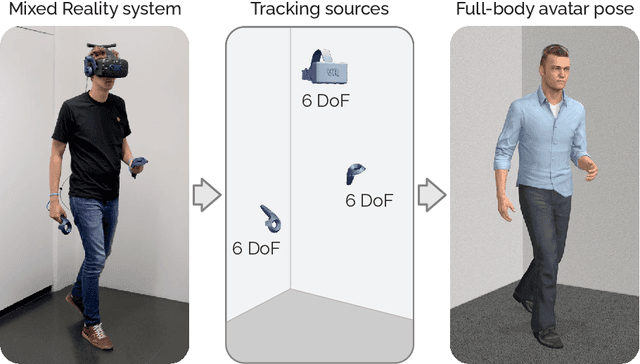
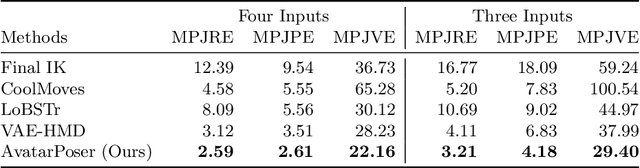
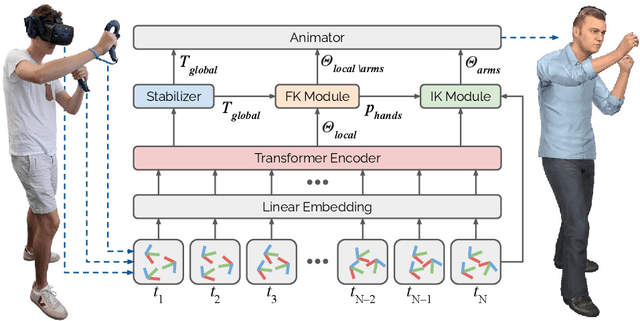
Today's Mixed Reality head-mounted displays track the user's head pose in world space as well as the user's hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users' virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user's head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints' positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method's inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications.
Towards lifelong learning of Recurrent Neural Networks for control design
Aug 08, 2022
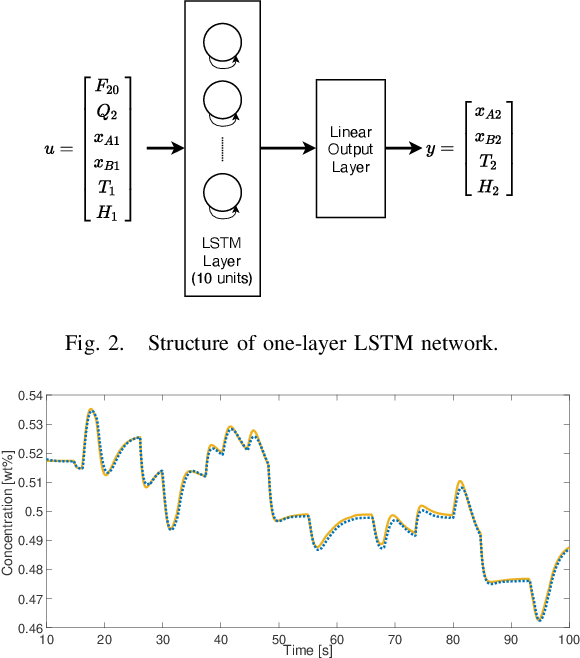
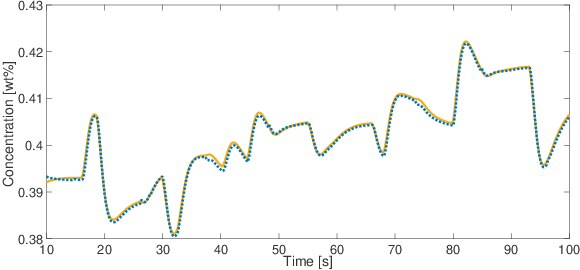
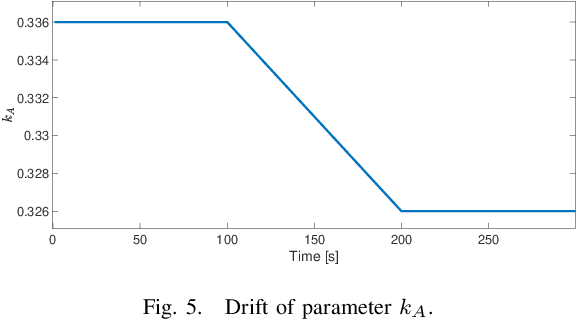
This paper proposes a method for lifelong learning of Recurrent Neural Networks, such as NNARX, ESN, LSTM, and GRU, to be used as plant models in control system synthesis. The problem is significant because in many practical applications it is required to adapt the model when new information is available and/or the system undergoes changes, without the need to store an increasing amount of data as time proceeds. Indeed, in this context, many problems arise, such as the well known Catastrophic Forgetting and Capacity Saturation ones. We propose an adaptation algorithm inspired by Moving Horizon Estimators, deriving conditions for its convergence. The described method is applied to a simulated chemical plant, already adopted as a challenging benchmark in the existing literature. The main results achieved are discussed.
* Copyright 2022 EUCA. This article appears in the Proceedings of the 2022 European Control Conference (ECC'22), July 12-15, 2022, London, pp. 2018-2023
DNN-Free Low-Latency Adaptive Speech Enhancement Based on Frame-Online Beamforming Powered by Block-Online FastMNMF
Jul 22, 2022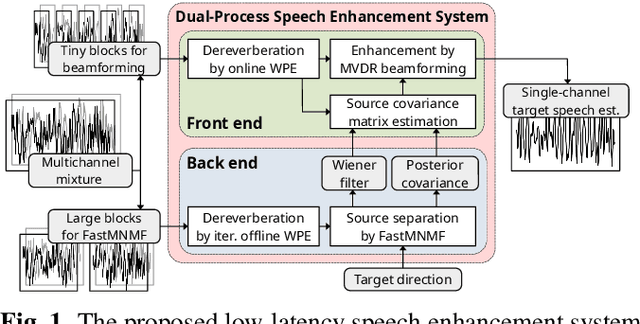
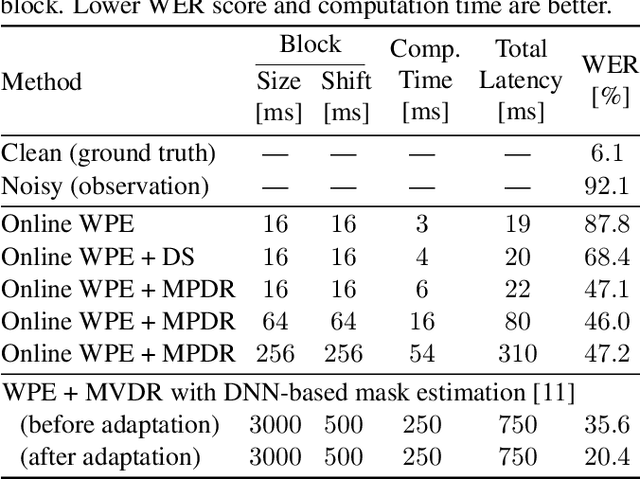

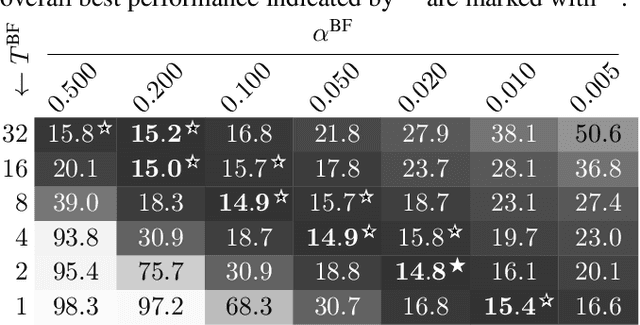
This paper describes a practical dual-process speech enhancement system that adapts environment-sensitive frame-online beamforming (front-end) with help from environment-free block-online source separation (back-end). To use minimum variance distortionless response (MVDR) beamforming, one may train a deep neural network (DNN) that estimates time-frequency masks used for computing the covariance matrices of sources (speech and noise). Backpropagation-based run-time adaptation of the DNN was proposed for dealing with the mismatched training-test conditions. Instead, one may try to directly estimate the source covariance matrices with a state-of-the-art blind source separation method called fast multichannel non-negative matrix factorization (FastMNMF). In practice, however, neither the DNN nor the FastMNMF can be updated in a frame-online manner due to its computationally-expensive iterative nature. Our DNN-free system leverages the posteriors of the latest source spectrograms given by block-online FastMNMF to derive the current source covariance matrices for frame-online beamforming. The evaluation shows that our frame-online system can quickly respond to scene changes caused by interfering speaker movements and outperformed an existing block-online system with DNN-based beamforming by 5.0 points in terms of the word error rate.
Quantum Multi-Agent Meta Reinforcement Learning
Aug 22, 2022Although quantum supremacy is yet to come, there has recently been an increasing interest in identifying the potential of quantum machine learning (QML) in the looming era of practical quantum computing. Motivated by this, in this article we re-design multi-agent reinforcement learning (MARL) based on the unique characteristics of quantum neural networks (QNNs) having two separate dimensions of trainable parameters: angle parameters affecting the output qubit states, and pole parameters associated with the output measurement basis. Exploiting this dyadic trainability as meta-learning capability, we propose quantum meta MARL (QM2ARL) that first applies angle training for meta-QNN learning, followed by pole training for few-shot or local-QNN training. To avoid overfitting, we develop an angle-to-pole regularization technique injecting noise into the pole domain during angle training. Furthermore, by exploiting the pole as the memory address of each trained QNN, we introduce the concept of pole memory allowing one to save and load trained QNNs using only two-parameter pole values. We theoretically prove the convergence of angle training under the angle-to-pole regularization, and by simulation corroborate the effectiveness of QM2ARL in achieving high reward and fast convergence, as well as of the pole memory in fast adaptation to a time-varying environment.