 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Fuzzy Utility Maximization with Remaining Measure
Aug 26, 2022
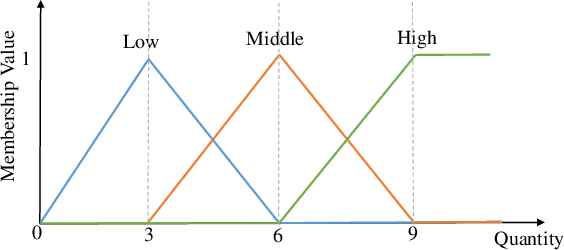
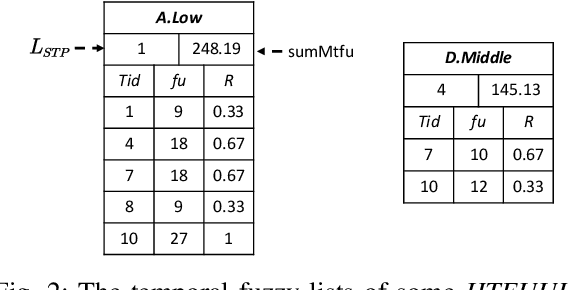
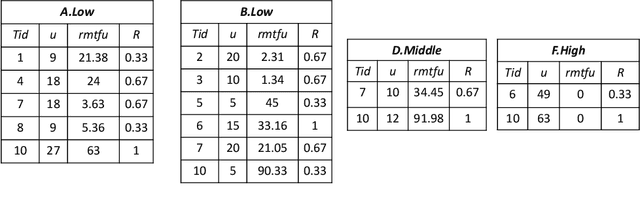
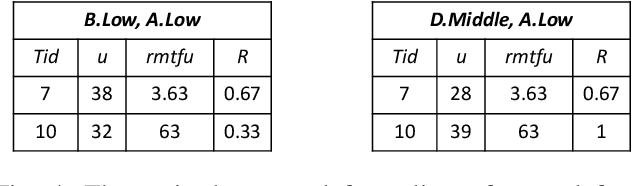
High utility itemset mining approaches discover hidden patterns from large amounts of temporal data. However, an inescapable problem of high utility itemset mining is that its discovered results hide the quantities of patterns, which causes poor interpretability. The results only reflect the shopping trends of customers, which cannot help decision makers quantify collected information. In linguistic terms, computers use mathematical or programming languages that are precisely formalized, but the language used by humans is always ambiguous. In this paper, we propose a novel one-phase temporal fuzzy utility itemset mining approach called TFUM. It revises temporal fuzzy-lists to maintain less but major information about potential high temporal fuzzy utility itemsets in memory, and then discovers a complete set of real interesting patterns in a short time. In particular, the remaining measure is the first adopted in the temporal fuzzy utility itemset mining domain in this paper. The remaining maximal temporal fuzzy utility is a tighter and stronger upper bound than that of previous studies adopted. Hence, it plays an important role in pruning the search space in TFUM. Finally, we also evaluate the efficiency and effectiveness of TFUM on various datasets. Extensive experimental results indicate that TFUM outperforms the state-of-the-art algorithms in terms of runtime cost, memory usage, and scalability. In addition, experiments prove that the remaining measure can significantly prune unnecessary candidates during mining.
Learning dynamical systems from data: A simple cross-validation perspective, part III: Irregularly-Sampled Time Series
Nov 25, 2021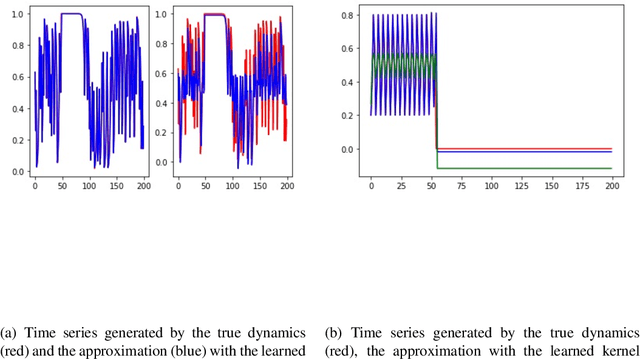
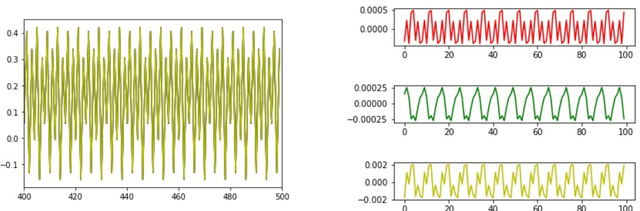
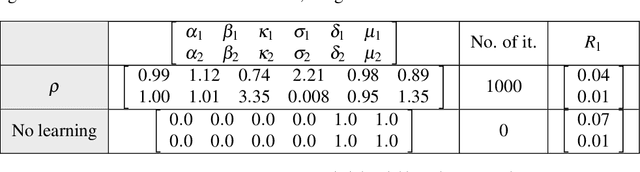

A simple and interpretable way to learn a dynamical system from data is to interpolate its vector-field with a kernel. In particular, this strategy is highly efficient (both in terms of accuracy and complexity) when the kernel is data-adapted using Kernel Flows (KF)~\cite{Owhadi19} (which uses gradient-based optimization to learn a kernel based on the premise that a kernel is good if there is no significant loss in accuracy if half of the data is used for interpolation). Despite its previous successes, this strategy (based on interpolating the vector field driving the dynamical system) breaks down when the observed time series is not regularly sampled in time. In this work, we propose to address this problem by directly approximating the vector field of the dynamical system by incorporating time differences between observations in the (KF) data-adapted kernels. We compare our approach with the classical one over different benchmark dynamical systems and show that it significantly improves the forecasting accuracy while remaining simple, fast, and robust.
Leukocyte Classification using Multimodal Architecture Enhanced by Knowledge Distillation
Aug 17, 2022
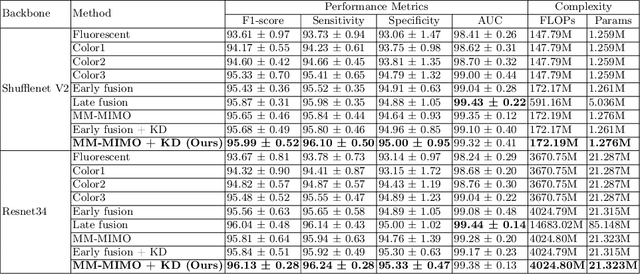
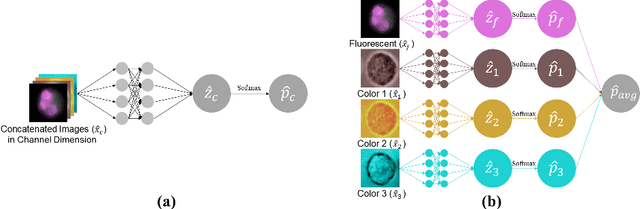
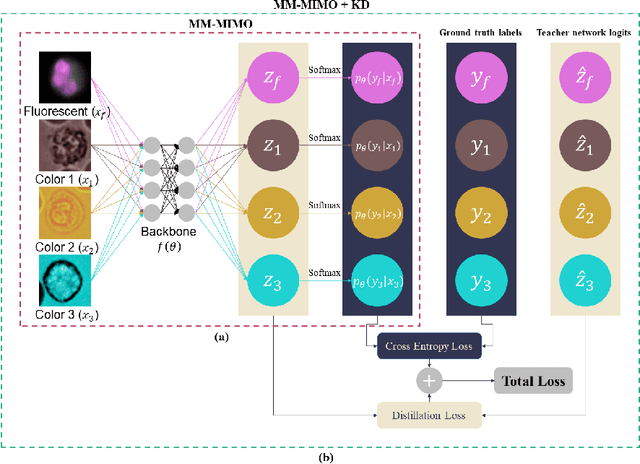
Recently, a lot of automated white blood cells (WBC) or leukocyte classification techniques have been developed. However, all of these methods only utilize a single modality microscopic image i.e. either blood smear or fluorescence based, thus missing the potential of a better learning from multimodal images. In this work, we develop an efficient multimodal architecture based on a first of its kind multimodal WBC dataset for the task of WBC classification. Specifically, our proposed idea is developed in two steps - 1) First, we learn modality specific independent subnetworks inside a single network only; 2) We further enhance the learning capability of the independent subnetworks by distilling knowledge from high complexity independent teacher networks. With this, our proposed framework can achieve a high performance while maintaining low complexity for a multimodal dataset. Our unique contribution is two-fold - 1) We present a first of its kind multimodal WBC dataset for WBC classification; 2) We develop a high performing multimodal architecture which is also efficient and low in complexity at the same time.
Automatic Detection of Noisy Electrocardiogram Signals without Explicit Noise Labels
Aug 08, 2022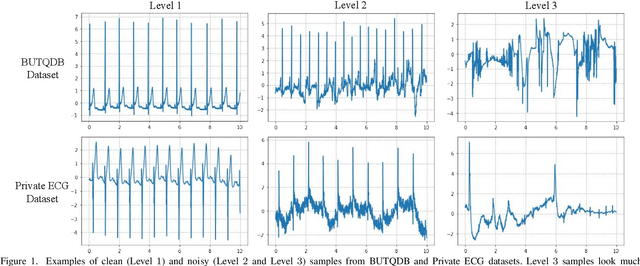
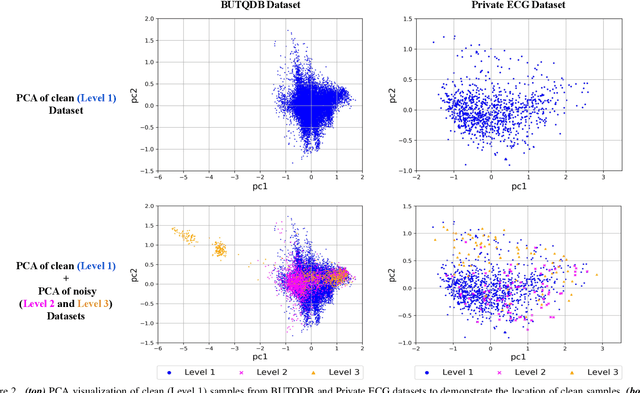
Electrocardiogram (ECG) signals are beneficial in diagnosing cardiovascular diseases, which are one of the leading causes of death. However, they are often contaminated by noise artifacts and affect the automatic and manual diagnosis process. Automatic deep learning-based examination of ECG signals can lead to inaccurate diagnosis, and manual analysis involves rejection of noisy ECG samples by clinicians, which might cost extra time. To address this limitation, we present a two-stage deep learning-based framework to automatically detect the noisy ECG samples. Through extensive experiments and analysis on two different datasets, we observe that the deep learning-based framework can detect slightly and highly noisy ECG samples effectively. We also study the transfer of the model learned on one dataset to another dataset and observe that the framework effectively detects noisy ECG samples.
IDP-PGFE: An Interpretable Disruption Predictor based on Physics-Guided Feature Extraction
Aug 28, 2022
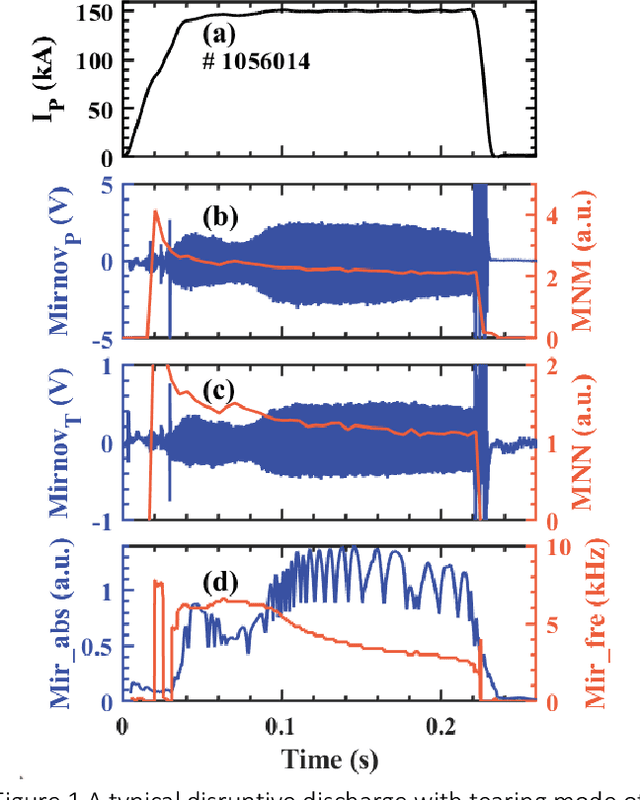
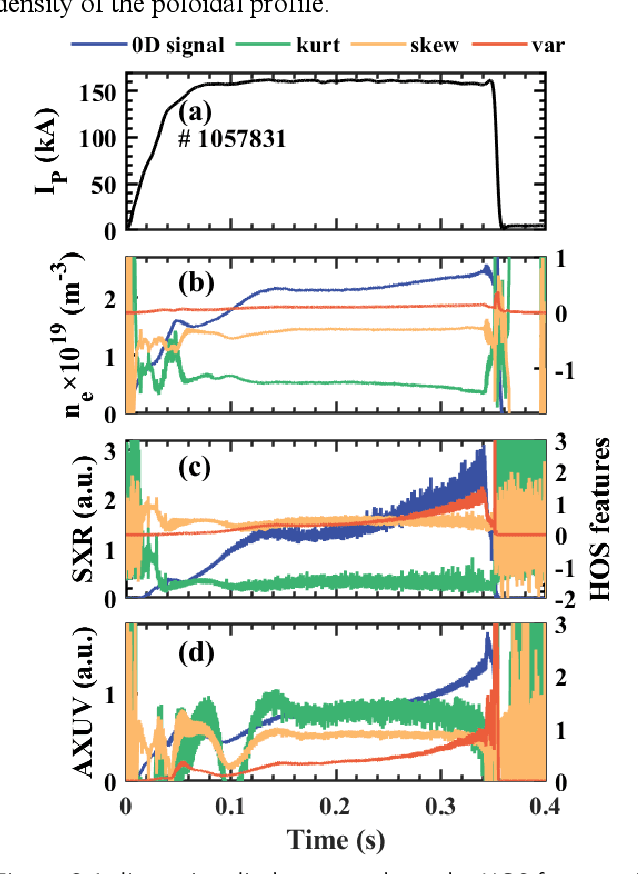

Disruption prediction has made rapid progress in recent years, especially in machine learning (ML)-based methods. Understanding why a predictor makes a certain prediction can be as crucial as the prediction's accuracy for future tokamak disruption predictors. The purpose of most disruption predictors is accuracy or cross-machine capability. However, if a disruption prediction model can be interpreted, it can tell why certain samples are classified as disruption precursors. This allows us to tell the types of incoming disruption and gives us insight into the mechanism of disruption. This paper designs a disruption predictor called Interpretable Disruption Predictor based On Physics-guided feature extraction (IDP-PGFE) on J-TEXT. The prediction performance of the model is effectively improved by extracting physics-guided features. A high-performance model is required to ensure the validity of the interpretation results. The interpretability study of IDP-PGFE provides an understanding of J-TEXT disruption and is generally consistent with existing comprehension of disruption. IDP-PGFE has been applied to the disruption due to continuously increasing density towards density limit experiments on J-TEXT. The time evolution of the PGFE features contribution demonstrates that the application of ECRH triggers radiation-caused disruption, which lowers the density at disruption. While the application of RMP indeed raises the density limit in J-TEXT. The interpretability study guides intuition on the physical mechanisms of density limit disruption that RMPs affect not only the MHD instabilities but also the radiation profile, which delays density limit disruption.
A Monitoring and Discovery Approach for Declarative Processes Based on Streams
Aug 10, 2022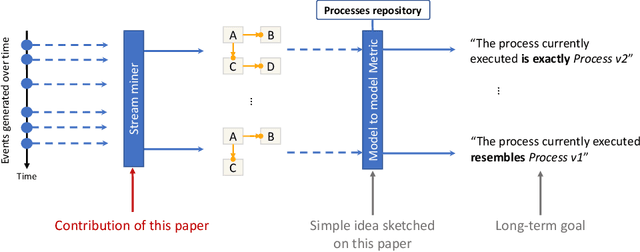
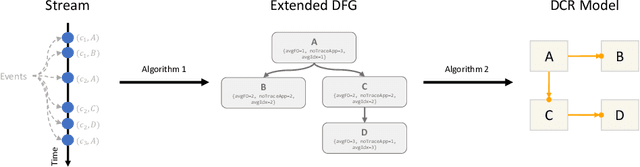
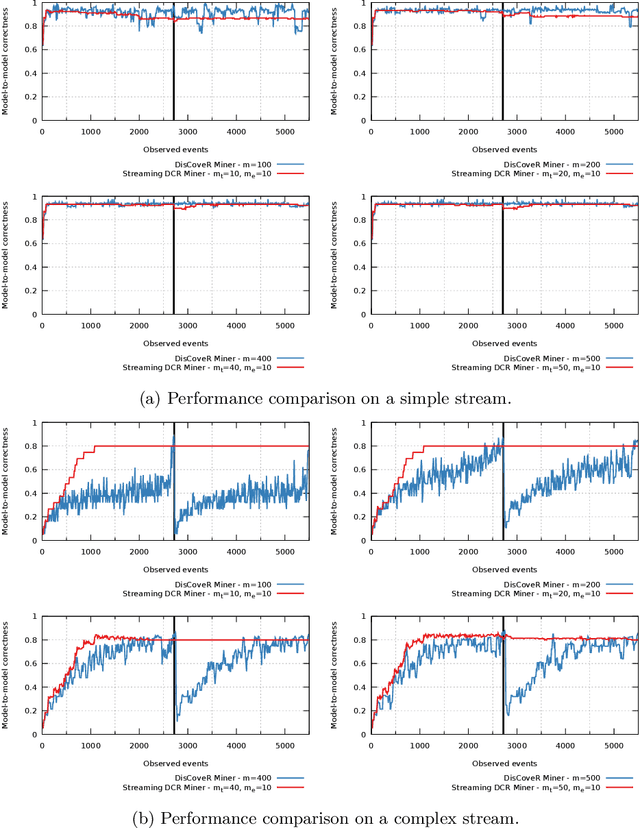
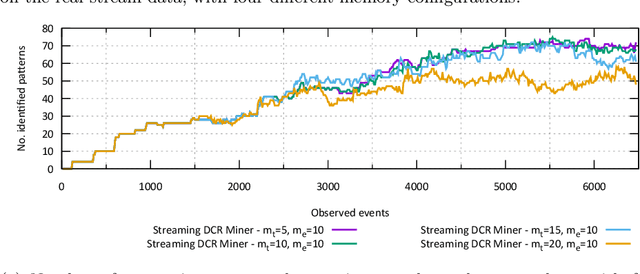
Process discovery is a family of techniques that helps to comprehend processes from their data footprints. Yet, as processes change over time so should their corresponding models, and failure to do so will lead to models that under- or over-approximate behavior. We present a discovery algorithm that extracts declarative processes as Dynamic Condition Response (DCR) graphs from event streams. Streams are monitored to generate temporal representations of the process, later processed to generate declarative models. We validated the technique via quantitative and qualitative evaluations. For the quantitative evaluation, we adopted an extended Jaccard similarity measure to account for process change in a declarative setting. For the qualitative evaluation, we showcase how changes identified by the technique correspond to real changes in an existing process. The technique and the data used for testing are available online.
Network Slicing for eMBB, URLLC, and mMTC: An Uplink Rate-Splitting Multiple Access Approach
Aug 23, 2022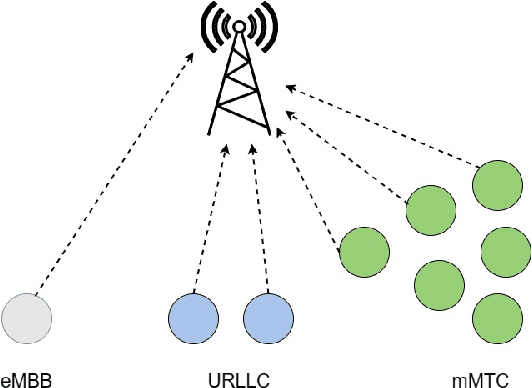
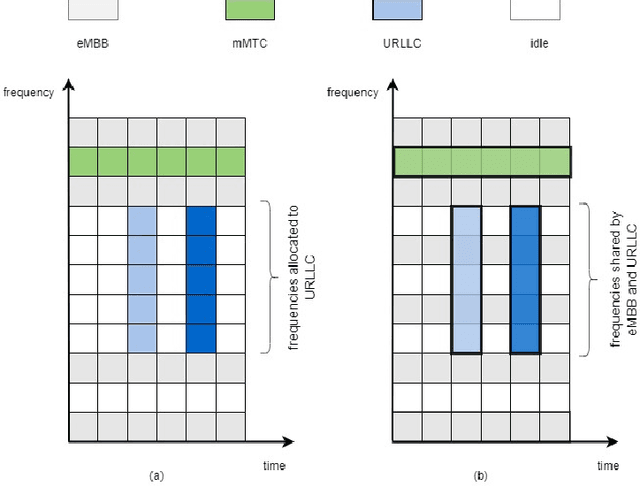
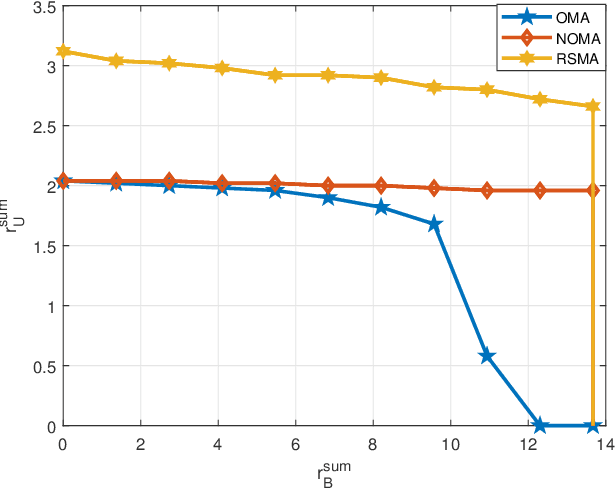
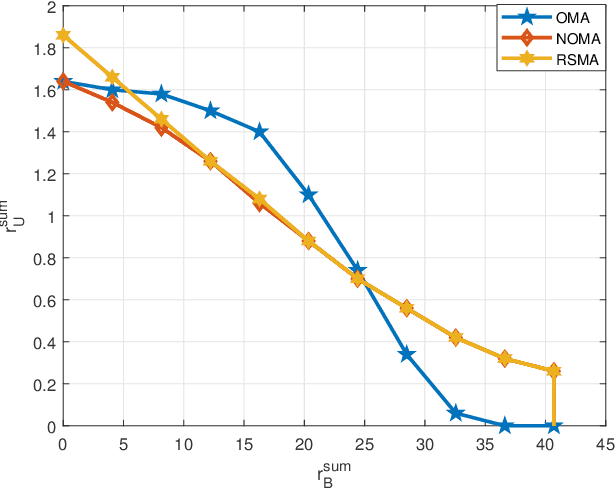
There are three generic services in 5G: enhanced mobile broadband (eMBB), ultra-reliable low-latency communications (URLLC), and massive machine-type communications (mMTC). To guarantee the performance of heterogeneous services, network slicing is proposed to allocate resources to different services. Network slicing is typically done in an orthogonal multiple access (OMA) fashion, which means different services are allocated non-interfering resources. However, as the number of users grows, OMA-based slicing is not always optimal, and a non-orthogonal scheme may achieve a better performance. This work aims to analyse the performances of different slicing schemes in uplink, and a promising scheme based on rate-splitting multiple access (RSMA) is studied. RSMA can provide a more flexible decoding order and theoretically has the largest achievable rate region than OMA and non-orthogonal multiple access (NOMA) without time-sharing. Hence, RSMA has the potential to increase the rate of users requiring different services. In addition, it is not necessary to decode the two split streams of one user successively, so RSMA lets suitable users split messages and designs an appropriate decoding order depending on the service requirements. This work shows that for network slicing RSMA can outperform NOMA counterpart, and obtain significant gains over OMA in some region.
Adaptive Acoustic Flow-Based Navigation with 3D Sonar Sensor Fusion
Aug 23, 2022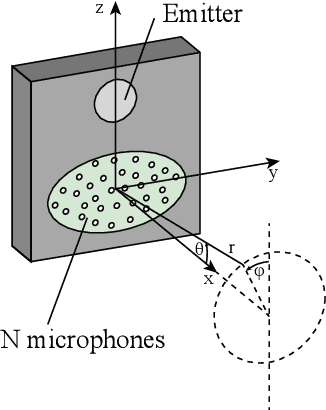
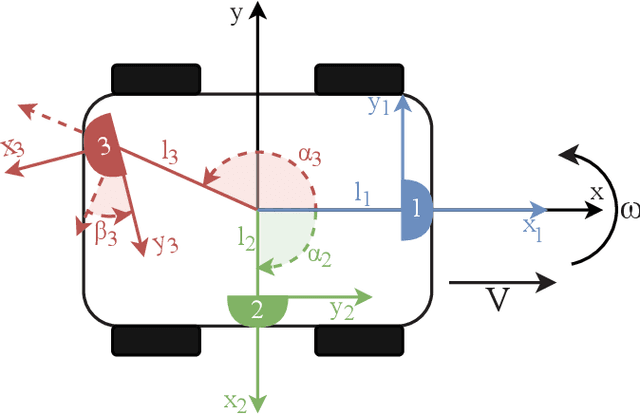
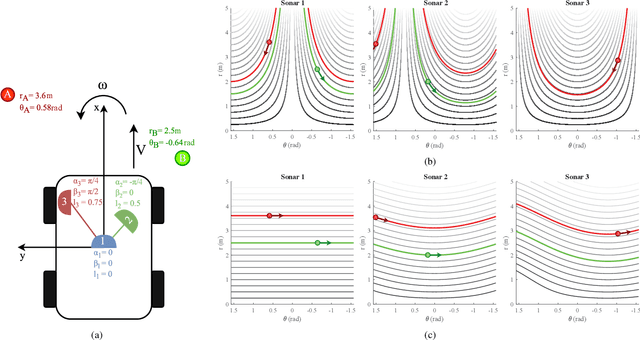
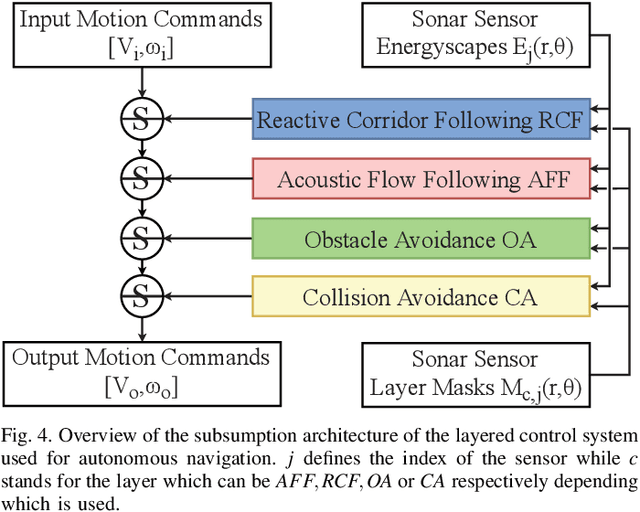
Navigating spatially varied and dynamic environments is one of the key tasks for autonomous agents. In this paper we present a novel method of navigating a mobile platform with one or multiple 3D-sonar sensors. Moving a mobile platform and subsequently any 3D-sonar sensor on it, will create signature variations over time of the echoed reflections in the sensor readings. An approach is presented to create a predictive model of these signature variations for any motion type. Furthermore, the model is adaptive and works for any position and orientation of one or multiple sonar sensors on a mobile platform. We propose to use this adaptive model and fuse all sensory readings to create a layered control system allowing a mobile platform to perform a set of primitive motions such as collision avoidance, obstacle avoidance, wall following and corridor following behaviours to navigate an environment with dynamically moving objects within it. This paper describes the underlying theoretical base of the entire navigation model and validates it in a simulated environment with results that shows the system is stable and delivers expected behaviour for several tested spatial configurations of one or multiple sonar sensors that can complete an autonomous navigation task.
Efficient Aggregated Kernel Tests using Incomplete $U$-statistics
Jun 18, 2022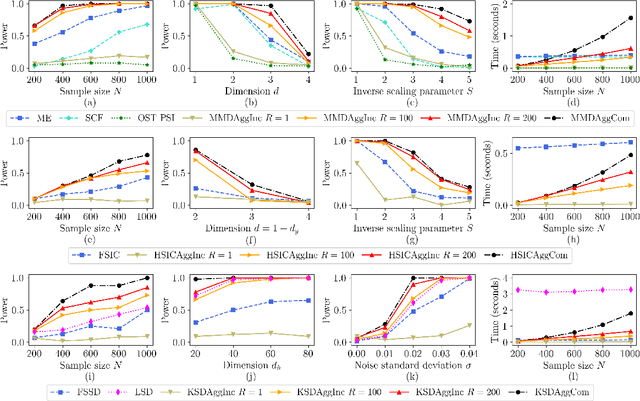
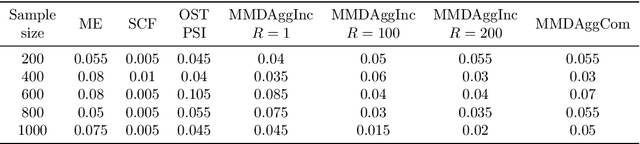


We propose a series of computationally efficient, nonparametric tests for the two-sample, independence and goodness-of-fit problems, using the Maximum Mean Discrepancy (MMD), Hilbert Schmidt Independence Criterion (HSIC), and Kernel Stein Discrepancy (KSD), respectively. Our test statistics are incomplete $U$-statistics, with a computational cost that interpolates between linear time in the number of samples, and quadratic time, as associated with classical $U$-statistic tests. The three proposed tests aggregate over several kernel bandwidths to detect departures from the null on various scales: we call the resulting tests MMDAggInc, HSICAggInc and KSDAggInc. For the test thresholds, we derive a quantile bound for wild bootstrapped incomplete $U$- statistics, which is of independent interest. We derive uniform separation rates for MMDAggInc and HSICAggInc, and quantify exactly the trade-off between computational efficiency and the attainable rates: this result is novel for tests based on incomplete $U$-statistics, to our knowledge. We further show that in the quadratic-time case, the wild bootstrap incurs no penalty to test power over more widespread permutation-based approaches, since both attain the same minimax optimal rates (which in turn match the rates that use oracle quantiles). We support our claims with numerical experiments on the trade-off between computational efficiency and test power. In the three testing frameworks, we observe that our proposed linear-time aggregated tests obtain higher power than current state-of-the-art linear-time kernel tests.
Towards an Error-free Deep Occupancy Detector for Smart Camera Parking System
Aug 17, 2022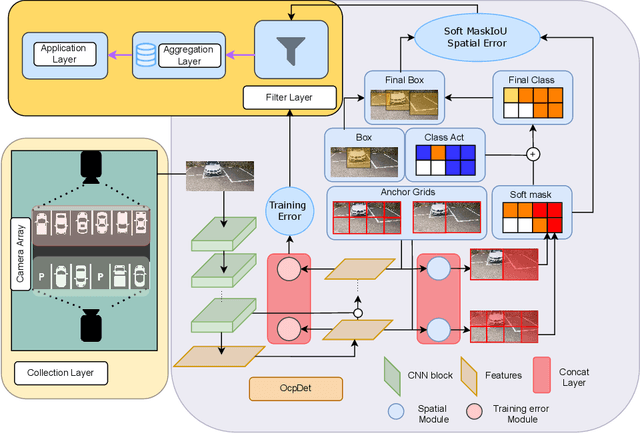


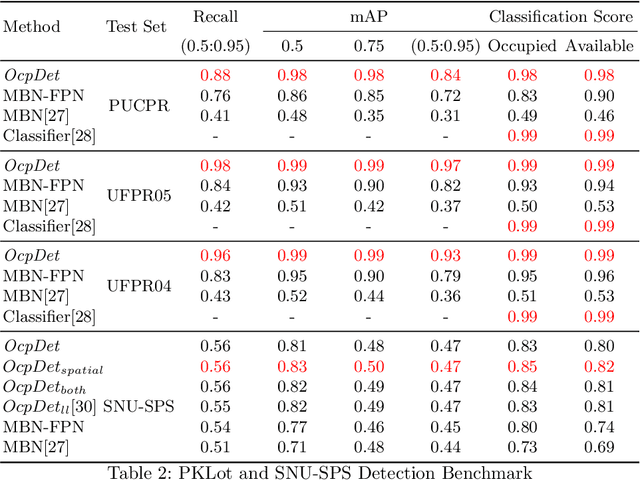
Although the smart camera parking system concept has existed for decades, a few approaches have fully addressed the system's scalability and reliability. As the cornerstone of a smart parking system is the ability to detect occupancy, traditional methods use the classification backbone to predict spots from a manual labeled grid. This is time-consuming and loses the system's scalability. Additionally, most of the approaches use deep learning models, making them not error-free and not reliable at scale. Thus, we propose an end-to-end smart camera parking system where we provide an autonomous detecting occupancy by an object detector called OcpDet. Our detector also provides meaningful information from contrastive modules: training and spatial knowledge, which avert false detections during inference. We benchmark OcpDet on the existing PKLot dataset and reach competitive results compared to traditional classification solutions. We also introduce an additional SNU-SPS dataset, in which we estimate the system performance from various views and conduct system evaluation in parking assignment tasks. The result from our dataset shows that our system is promising for real-world applications.