 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hitless memory-reconfigurable photonic reservoir computing architecture
Jul 13, 2022
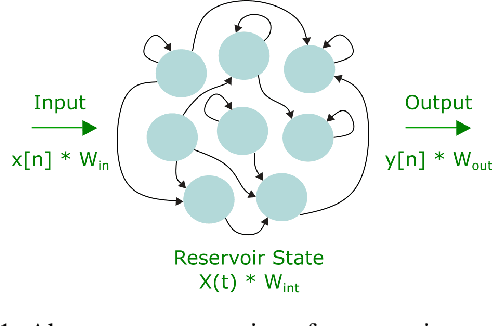
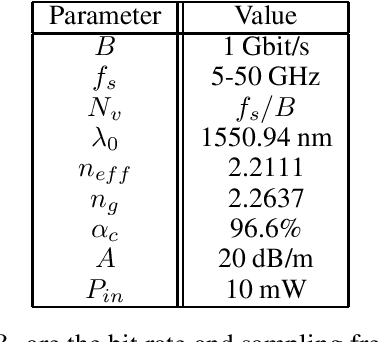
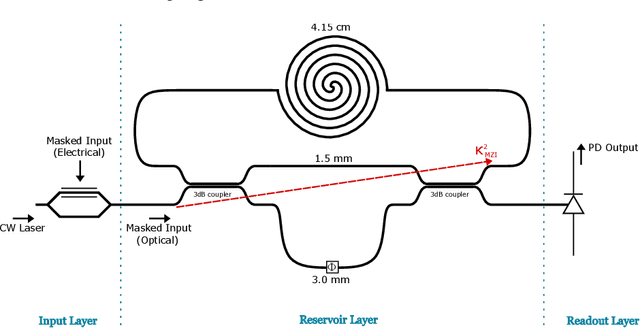

Reservoir computing is an analog bio-inspired computation model for efficiently processing time-dependent signals, the photonic implementations of which promise a combination of massive parallel information processing, low power consumption, and high speed operation. However, most implementations, especially for the case of time-delay reservoir computing (TDRC), require signal attenuation in the reservoir to achieve the desired system dynamics for a specific task, often resulting in large amounts of power being coupled outside of the system. We propose a novel TDRC architecture based on an asymmetric Mach-Zehnder interferometer (MZI) integrated in a resonant cavity which allows the memory capacity of the system to be tuned without the need for an optical attenuator block. Furthermore, this can be leveraged to find the optimal value for the specific components of the total memory capacity metric. We demonstrate this approach on the temporal bitwise XOR task and conclude that this way of memory capacity reconfiguration allows optimal performance to be achieved for memory-specific tasks.
STrajNet: Occupancy Flow Prediction via Multi-modal Swin Transformer
Jul 31, 2022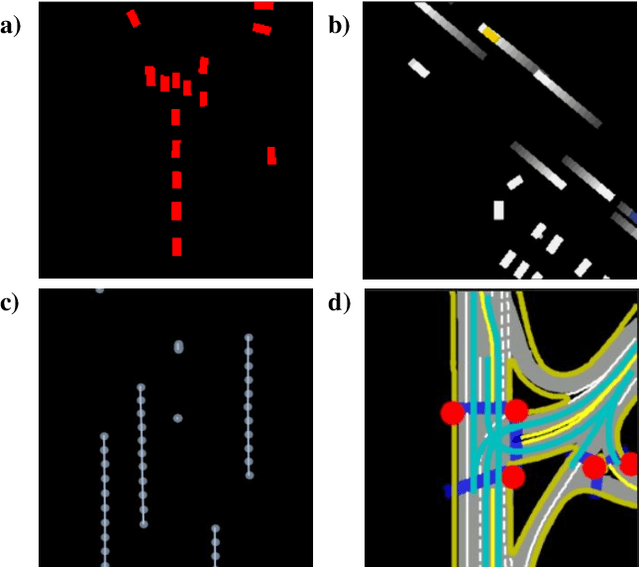

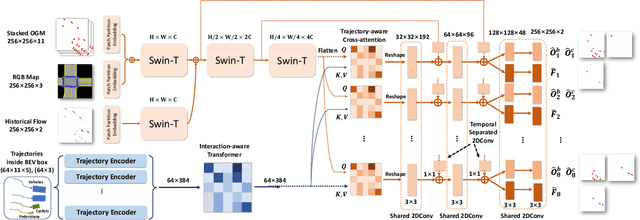
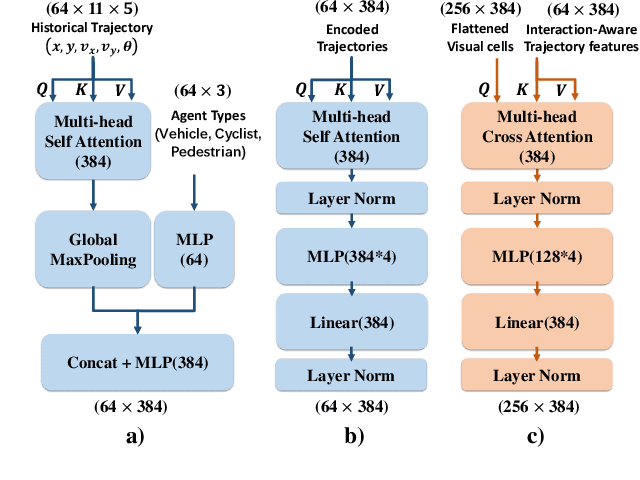
Making an accurate prediction of occupancy and flow is essential to enable better safety and interaction for autonomous vehicles under complex traffic scenarios. This work proposes STrajNet: a multi-modal Swin Transformerbased framework for effective scene occupancy and flow predictions. We employ Swin Transformer to encode the image and interaction-aware motion representations and propose a cross-attention module to inject motion awareness into grid cells across different time steps. Flow and occupancy predictions are then decoded through temporalsharing Pyramid decoders. The proposed method shows competitive prediction accuracy and other evaluation metrics in the Waymo Open Dataset benchmark.
Parabolic Relaxation for Quadratically-constrained Quadratic Programming -- Part I: Definitions & Basic Properties
Aug 07, 2022
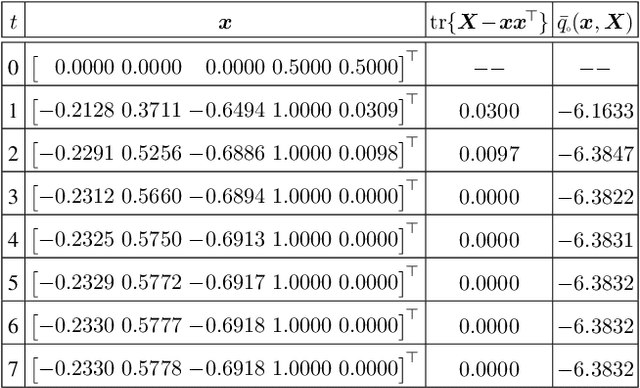
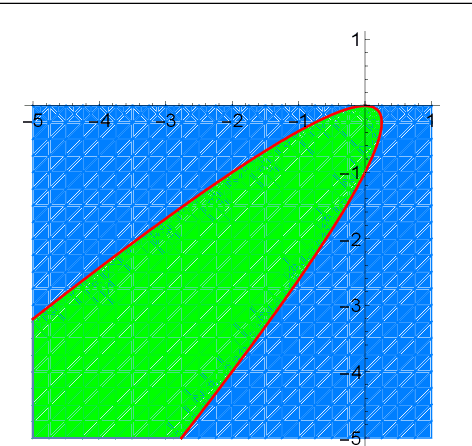
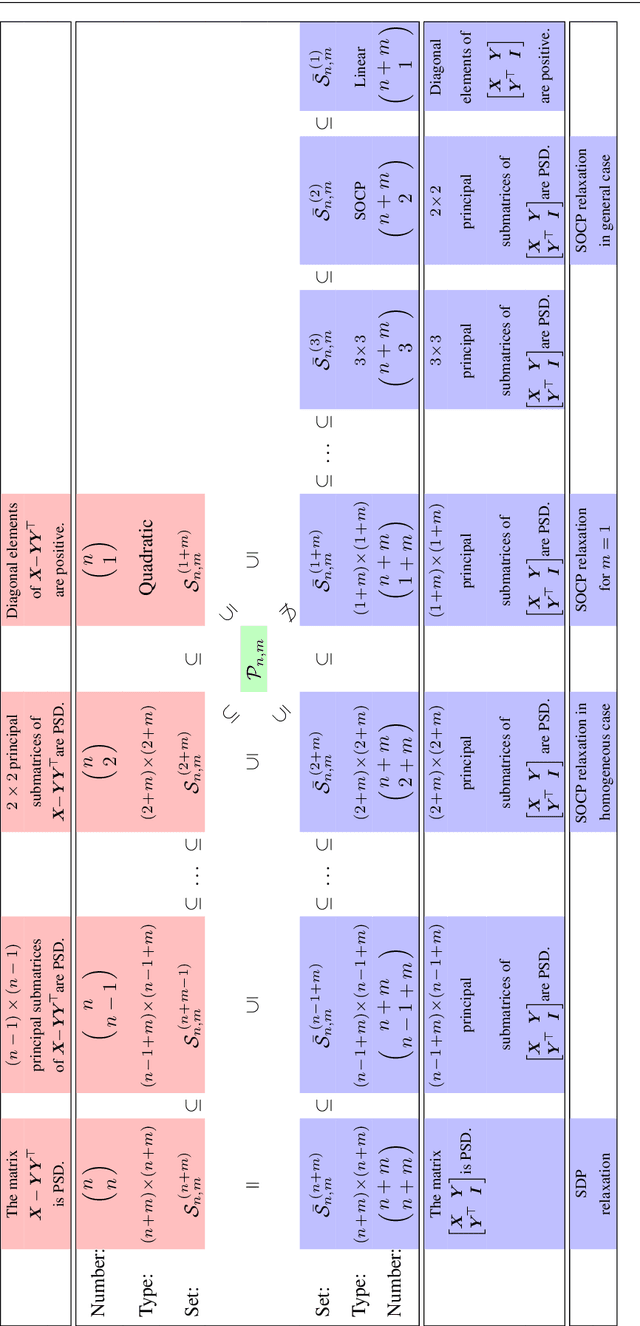
For general quadratically-constrained quadratic programming (QCQP), we propose a parabolic relaxation described with convex quadratic constraints. An interesting property of the parabolic relaxation is that the original non-convex feasible set is contained on the boundary of the parabolic relaxation. Under certain assumptions, this property enables one to recover near-optimal feasible points via objective penalization. Moreover, through an appropriate change of coordinates that requires a one-time computation of an optimal basis, the easier-to-solve parabolic relaxation can be made as strong as a semidefinite programming (SDP) relaxation, which can be effective in accelerating algorithms that require solving a sequence of convex surrogates. The majority of theoretical and computational results are given in the next part of this work [57].
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022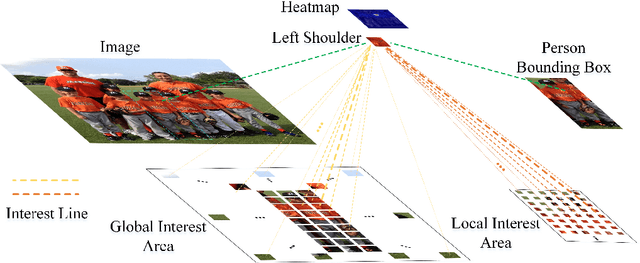
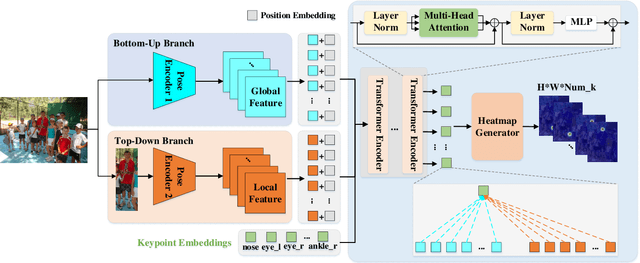
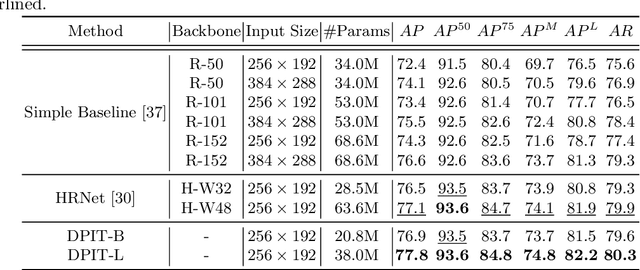
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
Joint Communications and Sensing Employing Optimized MIMO-OFDM Signals
Aug 21, 2022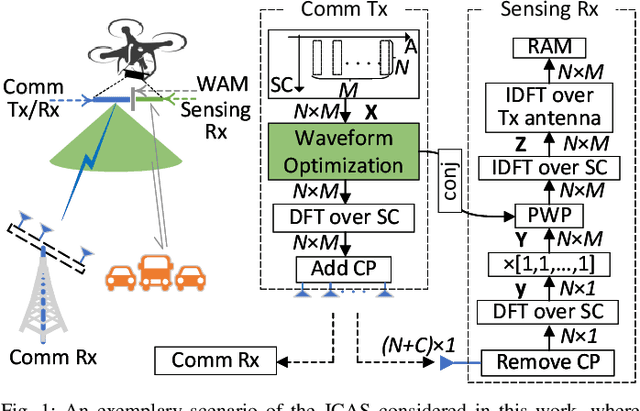
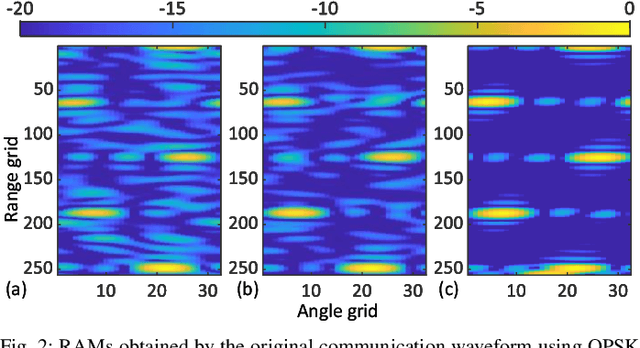
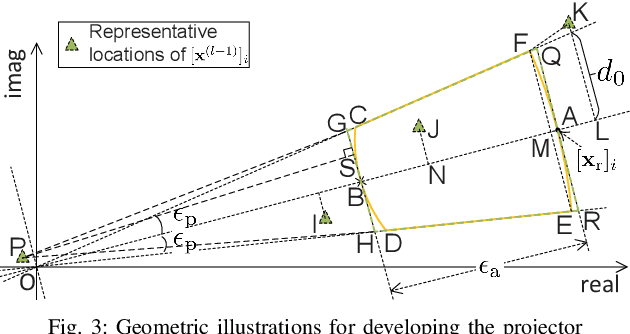
Joint communication and sensing (JCAS) has the potential to improve the overall energy, cost and frequency efficiency of IoT systems. As a first effort, we propose to optimize the MIMO-OFDM data symbols carried by sub-carriers for better time- and spatial-domain signal orthogonality. This not only boosts the availability of usable signals for JCAS, but also significantly facilitates Internet-of-Things (IoT) devices to perform high-quality sensing. We establish an optimization problem that modifies data symbols on sub-carriers to enhance the above-mentioned signal orthogonality. We also develop an efficient algorithm to solve the problem based on the majorization-minimization framework. Moreover, we discover unique signal structures and features from the newly modeled problem, which substantially reduce the complexity of majorizing the objective function. We also develop new projectors to enforce the feasibility of the obtained solution. Simulations show that, compared with the original communication waveform to achieve the same sensing performance, the optimized waveform can reduce the signal-to-noise ratio (SNR) requirement by 3~4.5 dB, while the SNR loss for the uncoded bit error rate is only 1~1.5 dB.
Why Deep Learning's Performance Data Are Misleading
Aug 23, 2022

This is a theoretical paper, as a companion paper of the keynote talk at the same conference. In contrast to conscious learning, many projects in AI have employed deep learning many of which seem to give impressive performance data. This paper explains that such performance data are probably misleadingly inflated due to two possible misconducts: data deletion and test on training set. This paper clarifies what is data deletion in deep learning and what is test on training set in deep learning and why they are misconducts. A simple classification method is defined, called nearest neighbor with threshold (NNWT). A theorem is established that the NNWT method reaches a zero error on any validation set and any test set using Post-Selections, as long as the test set is in the possession of the author and both the amount of storage space and the time of training are finite but unbounded like with many deep learning methods. However, like many deep learning methods, the NNWT method has little generalization power. The evidence that misconducts actually took place in many deep learning projects is beyond the scope of this paper. Without a transparent account about freedom from Post-Selections, deep learning data are misleading.
A New Radar Signal Multiparameter-Based Deinterleaving Method
Aug 21, 2022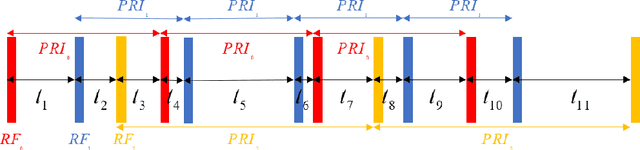
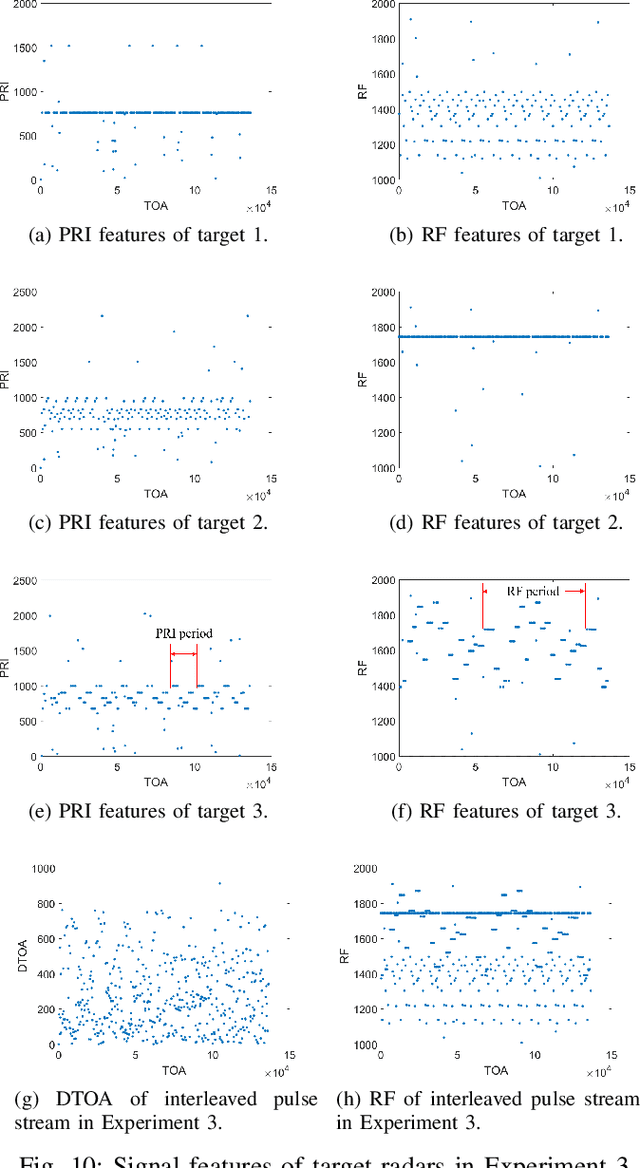
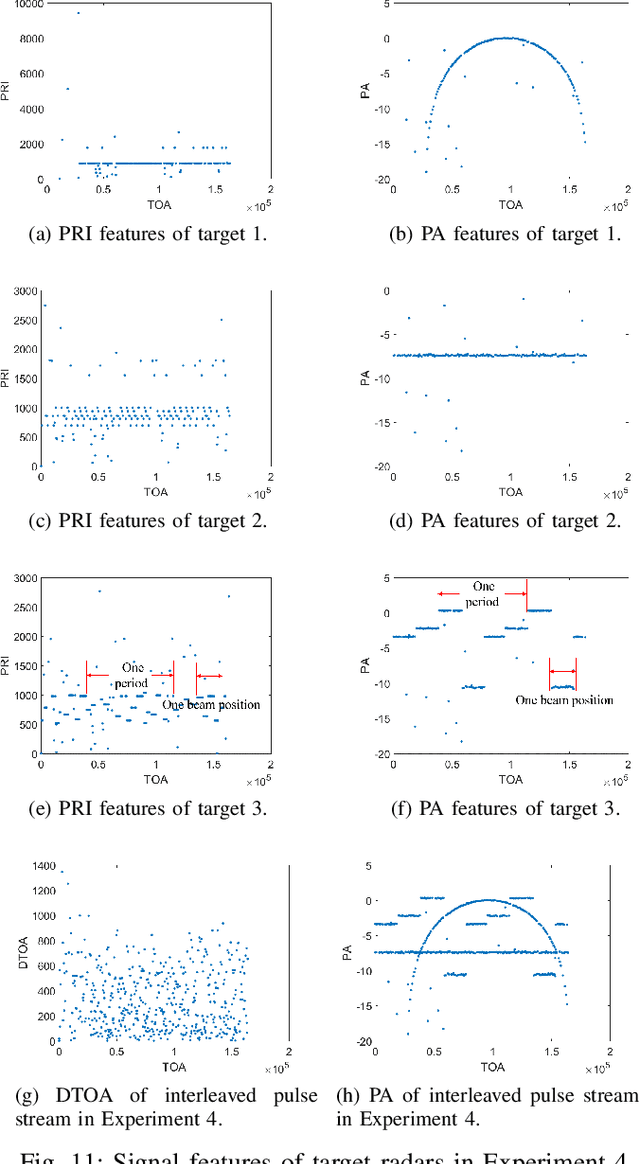
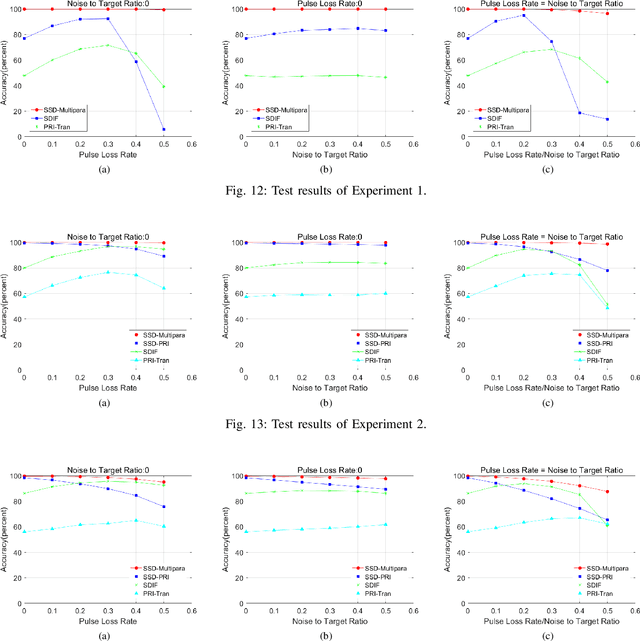
Radar signal deinterleaving has been extensively and thoroughly investigated in the electronic reconnaissance field. In this work, a new radar signal multiparameter-based deinterleaving method is proposed. In this method, semantic information composed of the pulse repetition interval (PRI), pulse width (PW), radio frequency (RF), and pulse amplitude (PA) of a radar signal is used to deinterleave radar signals. A bidirectional gated recurrent unit (BGRU) is employed, and the difference of time of arrival (DTOA)/RF, DTOA/PW, and DTOA/PA of the pulse stream are input into the BGRU. Based on the semantic information contained in different radar signal types, each pulse in the obtained pulse stream is classified according to the semantic information category, and the radar signals are deinterleaved. Compared to the PRI-based deinterleaving methods, the proposed method utilizes the multidimensional information of radar signals. As a result, higher deinterleaving accuracy is achieved. Compared to other existing radar signal multiparameter-based deinterleaving methods, the proposed method can adapt to radar signals with complex parameter features as well as to complex signal environments, and can complete the use of multiparameter in one step.
DeepPicarMicro: Applying TinyML to Autonomous Cyber Physical Systems
Aug 23, 2022

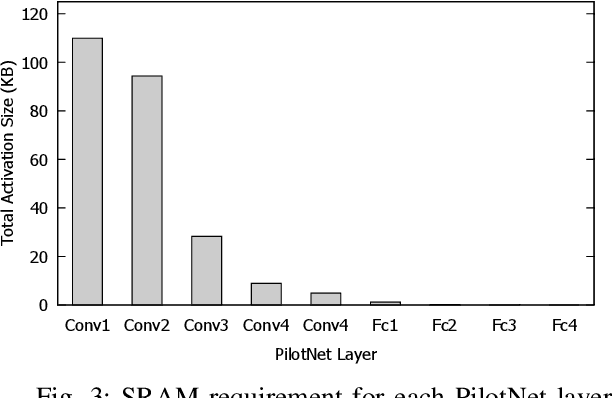
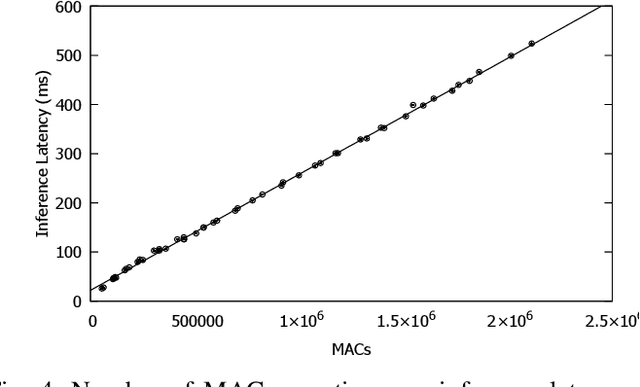
Running deep neural networks (DNNs) on tiny Micro-controller Units (MCUs) is challenging due to their limitations in computing, memory, and storage capacity. Fortunately, recent advances in both MCU hardware and machine learning software frameworks make it possible to run fairly complex neural networks on modern MCUs, resulting in a new field of study widely known as TinyML. However, there have been few studies to show the potential for TinyML applications in cyber physical systems (CPS). In this paper, we present DeepPicarMicro, a small self-driving RC car testbed, which runs a convolutional neural network (CNN) on a Raspberry Pi Pico MCU. We apply a state-of-the-art DNN optimization to successfully fit the well-known PilotNet CNN architecture, which was used to drive NVIDIA's real self-driving car, on the MCU. We apply a state-of-art network architecture search (NAS) approach to find further optimized networks that can effectively control the car in real-time in an end-to-end manner. From an extensive systematic experimental evaluation study, we observe an interesting relationship between the accuracy, latency, and control performance of a system. From this, we propose a joint optimization strategy that takes both accuracy and latency of a model in the network architecture search process for AI enabled CPS.
Detection of Increased Time Intervals of Anti-Vaccine Tweets for COVID-19 Vaccine with BERT Model
Jan 12, 2022The most effective of the solutions against Covid-19 is the various vaccines developed. Distrust of vaccines can hinder the rapid and effective use of this remedy. One of the means of expressing the thoughts of society is social media. Determining the time intervals during which anti-vaccination increases in social media can help institutions determine the strategy to be used in combating anti-vaccination. Recording and tracking every tweet entered with human labor would be inefficient, so various automation solutions are needed. In this study, The Bidirectional Encoder Representations from Transformers (BERT) model, which is a deep learning-based natural language processing (NLP) model, was used. In a dataset of 1506 tweets divided into four different categories as news, irrelevant, anti-vaccine, and vaccine supporters, the model was trained with a learning rate of 5e-6 for 25 epochs. To determine the intervals in which anti-vaccine tweets are concentrated, the categories to which 652840 tweets belong were determined by using the trained model. The change of the determined categories overtime was visualized and the events that could cause the change were determined. As a result of model training, in the test dataset, the f-score of 0.81 and AUC values for different classes were obtained as 0.99,0.91, 0.92, 0.92, respectively. In this model, unlike the studies in the literature, an auxiliary system is designed that provides data that institutions can use when determining their strategy by measuring and visualizing the frequency of anti-vaccine tweets in a time interval, different from detecting and censoring such tweets.
TunaOil: A Tuning Algorithm Strategy for Reservoir Simulation Workloads
Aug 04, 2022
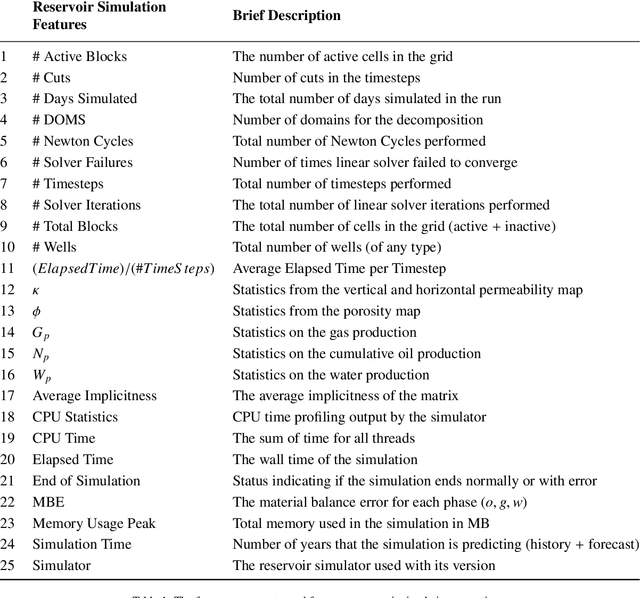
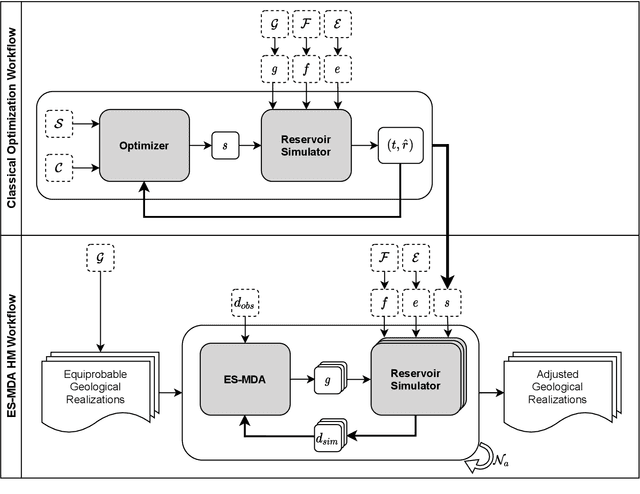
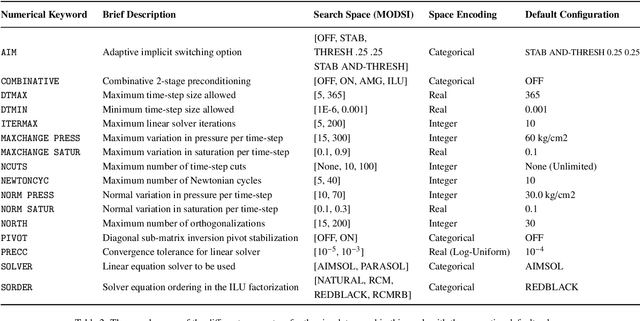
Reservoir simulations for petroleum fields and seismic imaging are known as the most demanding workloads for high-performance computing (HPC) in the oil and gas (O&G) industry. The optimization of the simulator numerical parameters plays a vital role as it could save considerable computational efforts. State-of-the-art optimization techniques are based on running numerous simulations, specific for that purpose, to find good parameter candidates. However, using such an approach is highly costly in terms of time and computing resources. This work presents TunaOil, a new methodology to enhance the search for optimal numerical parameters of reservoir flow simulations using a performance model. In the O&G industry, it is common to use ensembles of models in different workflows to reduce the uncertainty associated with forecasting O&G production. We leverage the runs of those ensembles in such workflows to extract information from each simulation and optimize the numerical parameters in their subsequent runs. To validate the methodology, we implemented it in a history matching (HM) process that uses a Kalman filter algorithm to adjust an ensemble of reservoir models to match the observed data from the real field. We mine past execution logs from many simulations with different numerical configurations and build a machine learning model based on extracted features from the data. These features include properties of the reservoir models themselves, such as the number of active cells, to statistics of the simulation's behavior, such as the number of iterations of the linear solver. A sampling technique is used to query the oracle to find the numerical parameters that can reduce the elapsed time without significantly impacting the quality of the results. Our experiments show that the predictions can improve the overall HM workflow runtime on average by 31%.