 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PSA-GAN: Progressive Self Attention GANs for Synthetic Time Series
Aug 02, 2021
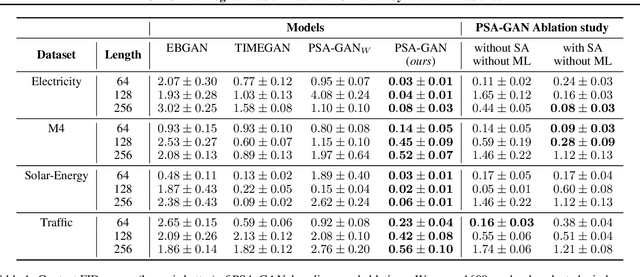

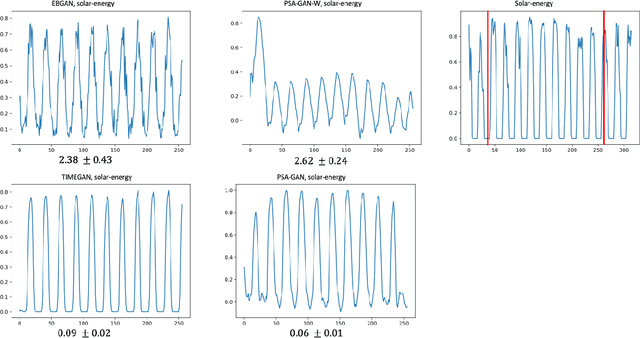
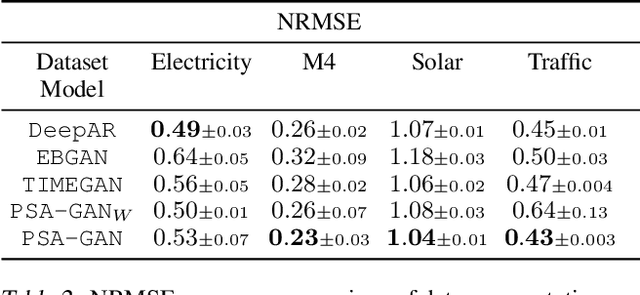
Realistic synthetic time series data of sufficient length enables practical applications in time series modeling tasks, such as forecasting, but remains a challenge. In this paper we present PSA-GAN, a generative adversarial network (GAN) that generates long time series samples of high quality using progressive growing of GANs and self-attention. We show that PSA-GAN can be used to reduce the error in two downstream forecasting tasks over baselines that only use real data. We also introduce a Frechet-Inception Distance-like score, Context-FID, assessing the quality of synthetic time series samples. In our downstream tasks, we find that the lowest scoring models correspond to the best-performing ones. Therefore, Context-FID could be a useful tool to develop time series GAN models.
Interpretable cytometry cell-type annotation with flow-based deep generative models
Aug 11, 2022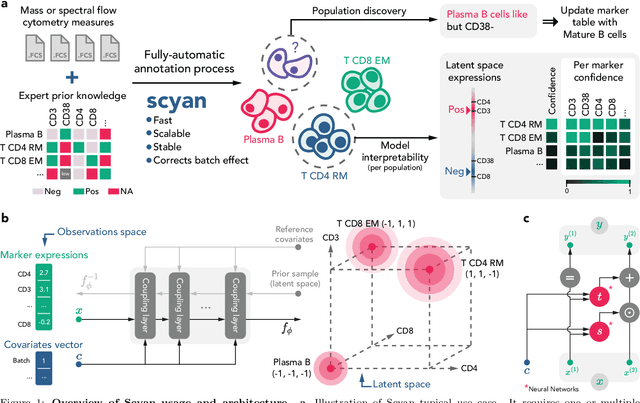
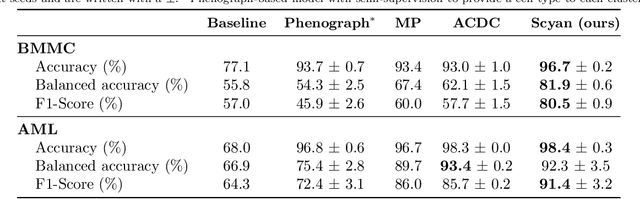
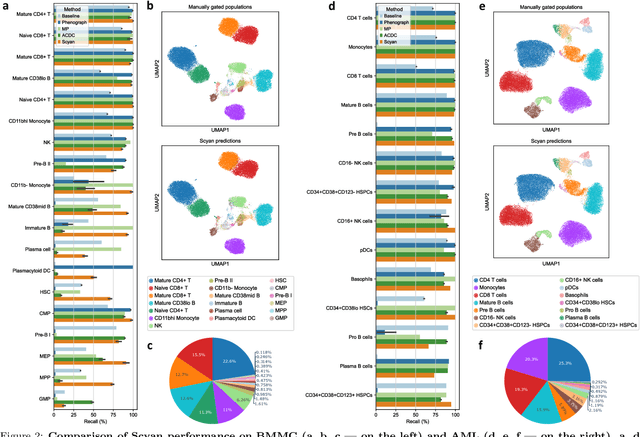

Cytometry enables precise single-cell phenotyping within heterogeneous populations. These cell types are traditionally annotated via manual gating, but this method suffers from a lack of reproducibility and sensitivity to batch-effect. Also, the most recent cytometers - spectral flow or mass cytometers - create rich and high-dimensional data whose analysis via manual gating becomes challenging and time-consuming. To tackle these limitations, we introduce Scyan (https://github.com/MICS-Lab/scyan), a Single-cell Cytometry Annotation Network that automatically annotates cell types using only prior expert knowledge about the cytometry panel. We demonstrate that Scyan significantly outperforms the related state-of-the-art models on multiple public datasets while being faster and interpretable. In addition, Scyan overcomes several complementary tasks such as batch-effect removal, debarcoding, and population discovery. Overall, this model accelerates and eases cell population characterisation, quantification, and discovery in cytometry.
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022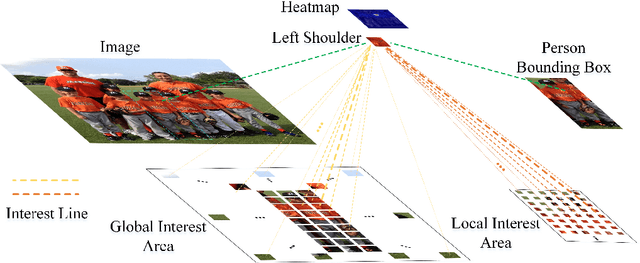
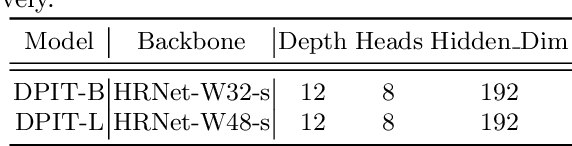
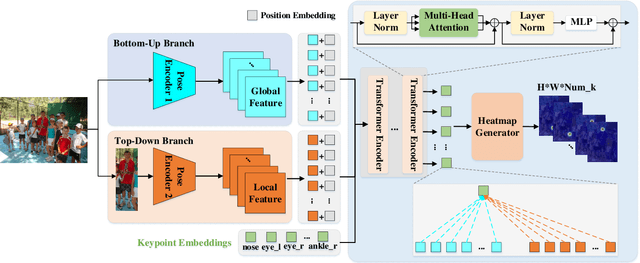
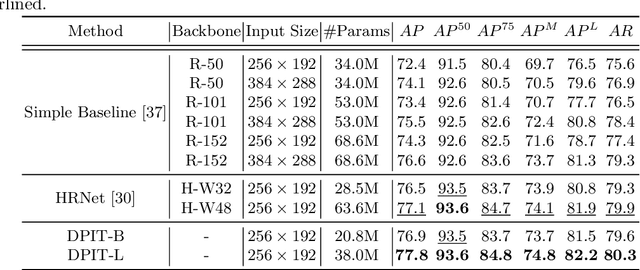
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
IRIS: Integrated Retinal Functionality in Image Sensors
Aug 14, 2022Neuromorphic image sensors draw inspiration from the biological retina to implement visual computations in electronic hardware. Gain control in phototransduction and temporal differentiation at the first retinal synapse inspired the first generation of neuromorphic sensors, but processing in downstream retinal circuits, much of which has been discovered in the past decade, has not been implemented in image sensor technology. We present a technology-circuit co-design solution that implements two motion computations occurring at the output of the retina that could have wide applications for vision based decision making in dynamic environments. Our simulations on Globalfoundries 22nm technology node show that, by taking advantage of the recent advances in semiconductor chip stacking technology, the proposed retina-inspired circuits can be fabricated on image sensing platforms in existing semiconductor foundries. Integrated Retinal Functionality in Image Sensors (IRIS) technology could drive advances in machine vision applications that demand robust, high-speed, energy-efficient and low-bandwidth real-time decision making.
Dynamic optical contrast imaging for real-time delineation of tumor resection margins using head and neck cancer as a model
Mar 10, 2022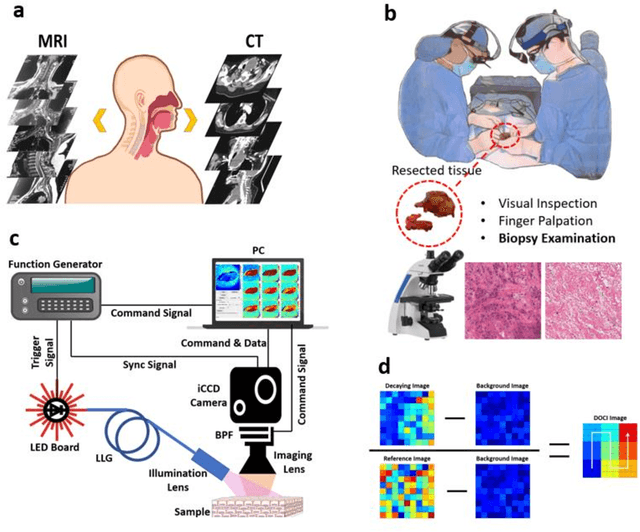
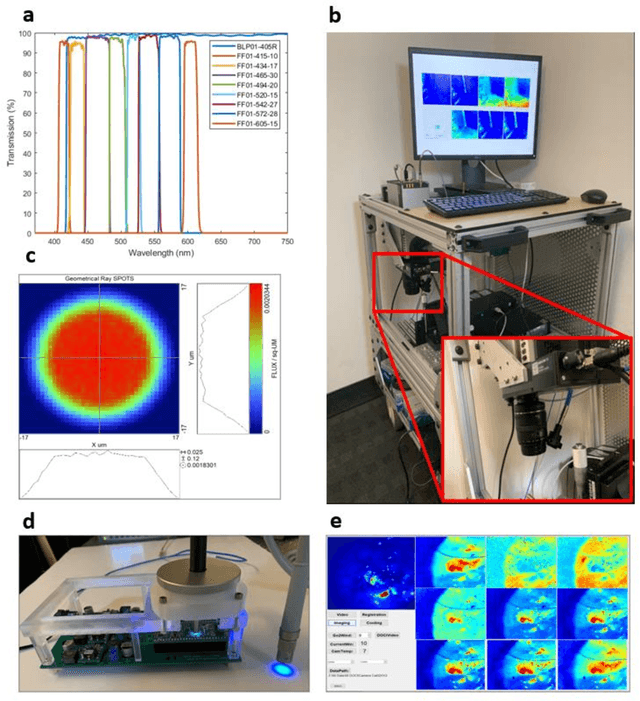
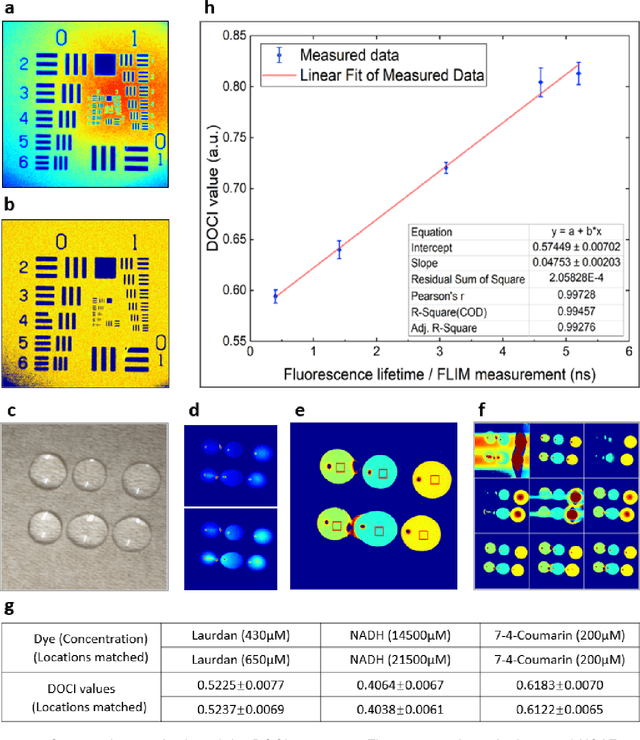
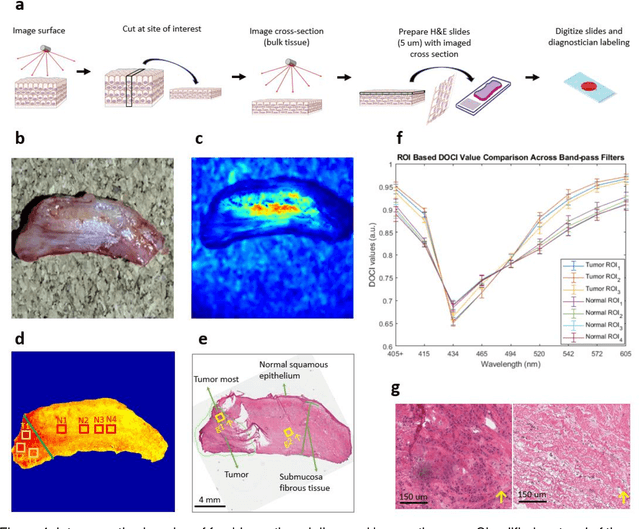
Complete surgical resection of the tumor for Head and neck squamous cell carcinoma (HNSCC) remains challenging, given the devastating side effects of aggressive surgery and the anatomic proximity to vital structures. To address the clinical challenges, we introduce a wide-field, label-free imaging tool that can assist surgeons delineate tumor margins real-time. We assume that autofluorescence lifetime is a natural indicator of the health level of tissues, and ratio-metric measurement of the emission-decay state to the emission-peak state of excited fluorophores will enable rapid lifetime mapping of tissues. Here, we describe the principle, instrumentation, characterization of the imager and the intraoperative imaging of resected tissues from 13 patients undergoing head and neck cancer resection. 20 x 20 mm2 imaging takes 2 second/frame with a working distance of 50 mm, and characterization shows that the spatial resolution reached 70 {\mu}m and the least distinguishable fluorescence lifetime difference is 0.14 ns. Tissue imaging and Hematoxylin-Eosin stain slides comparison reveals its capability of delineating cancerous boundaries with submillimeter accuracy and a sensitivity of 91.86% and specificity of 84.38%.
SCALE: Online Self-Supervised Lifelong Learning without Prior Knowledge
Aug 24, 2022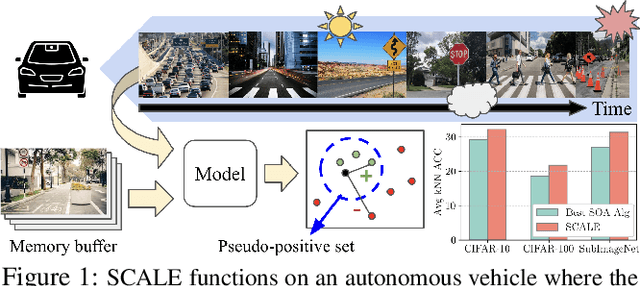
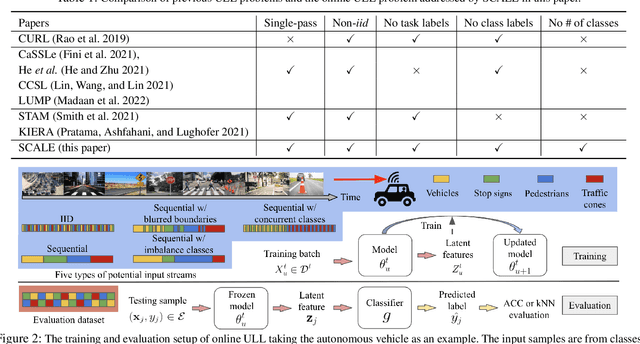
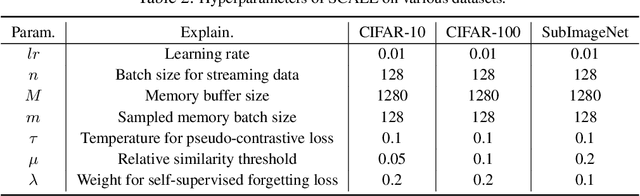
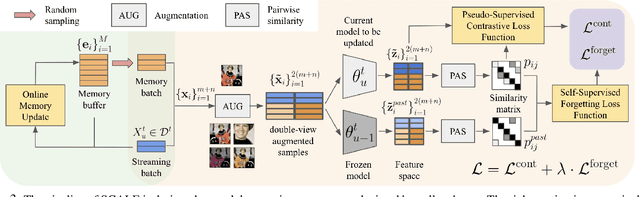
Unsupervised lifelong learning refers to the ability to learn over time while memorizing previous patterns without supervision. Previous works assumed strong prior knowledge about the incoming data (e.g., knowing the class boundaries) which can be impossible to obtain in complex and unpredictable environments. In this paper, motivated by real-world scenarios, we formally define the online unsupervised lifelong learning problem with class-incremental streaming data, which is non-iid and single-pass. The problem is more challenging than existing lifelong learning problems due to the absence of labels and prior knowledge. To address the issue, we propose Self-Supervised ContrAstive Lifelong LEarning (SCALE) which extracts and memorizes knowledge on-the-fly. SCALE is designed around three major components: a pseudo-supervised contrastive loss, a self-supervised forgetting loss, and an online memory update for uniform subset selection. All three components are designed to work collaboratively to maximize learning performance. Our loss functions leverage pairwise similarity thus remove the dependency on supervision or prior knowledge. We perform comprehensive experiments of SCALE under iid and four non-iid data streams. SCALE outperforms the best state-of-the-art algorithm on all settings with improvements of up to 6.43%, 5.23% and 5.86% kNN accuracy on CIFAR-10, CIFAR-100 and SubImageNet datasets.
Model-Based Safe Reinforcement Learning with Time-Varying State and Control Constraints: An Application to Intelligent Vehicles
Dec 18, 2021
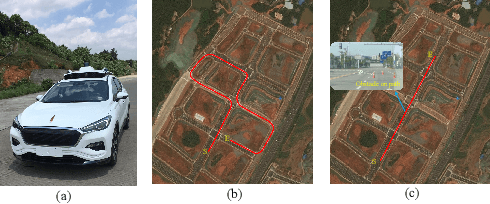
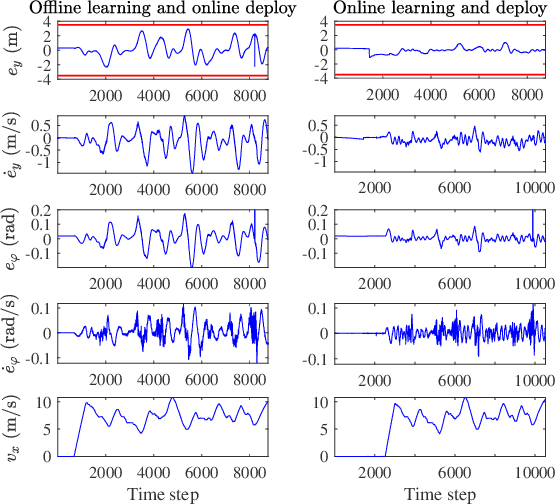
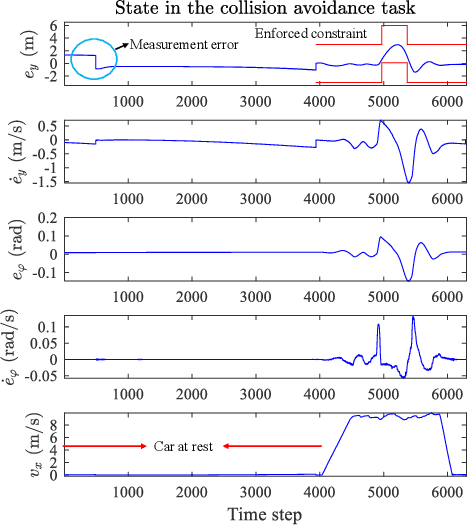
Recently, barrier function-based safe reinforcement learning (RL) with the actor-critic structure for continuous control tasks has received increasing attention. It is still challenging to learn a near-optimal control policy with safety and convergence guarantees. Also, few works have addressed the safe RL algorithm design under time-varying safety constraints. This paper proposes a model-based safe RL algorithm for optimal control of nonlinear systems with time-varying state and control constraints. In the proposed approach, we construct a novel barrier-based control policy structure that can guarantee control safety. A multi-step policy evaluation mechanism is proposed to predict the policy's safety risk under time-varying safety constraints and guide the policy to update safely. Theoretical results on stability and robustness are proven. Also, the convergence of the actor-critic learning algorithm is analyzed. The performance of the proposed algorithm outperforms several state-of-the-art RL algorithms in the simulated Safety Gym environment. Furthermore, the approach is applied to the integrated path following and collision avoidance problem for two real-world intelligent vehicles. A differential-drive vehicle and an Ackermann-drive one are used to verify the offline deployment performance and the online learning performance, respectively. Our approach shows an impressive sim-to-real transfer capability and a satisfactory online control performance in the experiment.
CenterPoly: real-time instance segmentation using bounding polygons
Aug 19, 2021
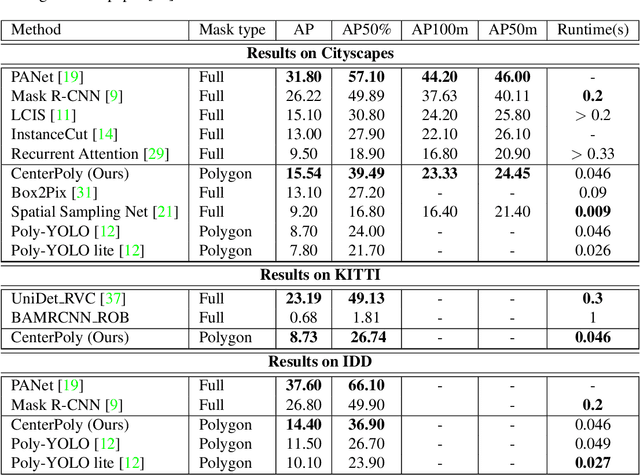
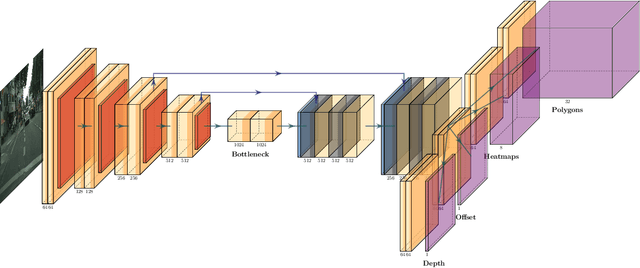
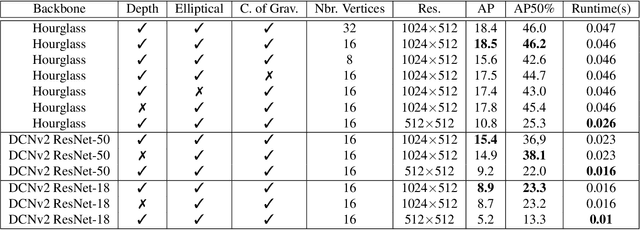
We present a novel method, called CenterPoly, for real-time instance segmentation using bounding polygons. We apply it to detect road users in dense urban environments, making it suitable for applications in intelligent transportation systems like automated vehicles. CenterPoly detects objects by their center keypoint while predicting a fixed number of polygon vertices for each object, thus performing detection and segmentation in parallel. Most of the network parameters are shared by the network heads, making it fast and lightweight enough to run at real-time speed. To properly convert mask ground-truth to polygon ground-truth, we designed a vertex selection strategy to facilitate the learning of the polygons. Additionally, to better segment overlapping objects in dense urban scenes, we also train a relative depth branch to determine which instances are closer and which are further, using available weak annotations. We propose several models with different backbones to show the possible speed / accuracy trade-offs. The models were trained and evaluated on Cityscapes, KITTI and IDD and the results are reported on their public benchmark, which are state-of-the-art at real-time speeds. Code is available at https://github.com/hu64/CenterPoly
Why Deep Learning's Performance Data Are Misleading
Aug 23, 2022

This is a theoretical paper, as a companion paper of the keynote talk at the same conference. In contrast to conscious learning, many projects in AI have employed deep learning many of which seem to give impressive performance data. This paper explains that such performance data are probably misleadingly inflated due to two possible misconducts: data deletion and test on training set. This paper clarifies what is data deletion in deep learning and what is test on training set in deep learning and why they are misconducts. A simple classification method is defined, called nearest neighbor with threshold (NNWT). A theorem is established that the NNWT method reaches a zero error on any validation set and any test set using Post-Selections, as long as the test set is in the possession of the author and both the amount of storage space and the time of training are finite but unbounded like with many deep learning methods. However, like many deep learning methods, the NNWT method has little generalization power. The evidence that misconducts actually took place in many deep learning projects is beyond the scope of this paper. Without a transparent account about freedom from Post-Selections, deep learning data are misleading.
Boost Test-Time Performance with Closed-Loop Inference
Mar 26, 2022
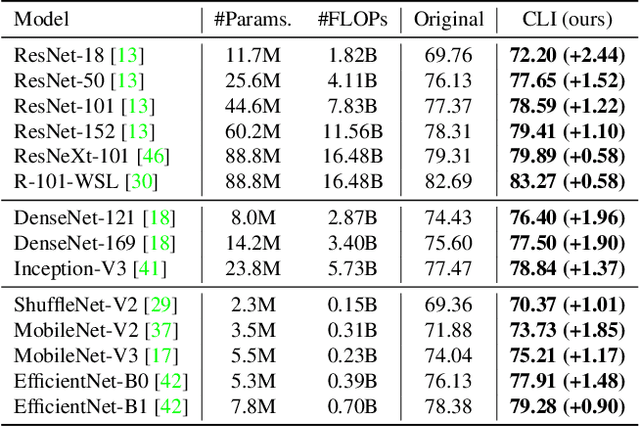
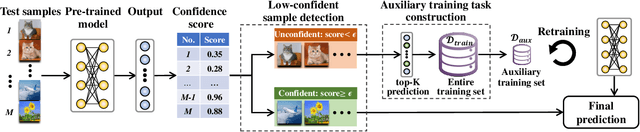
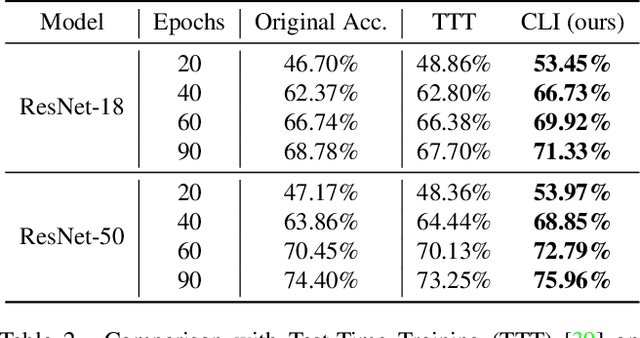
Conventional deep models predict a test sample with a single forward propagation, which, however, may not be sufficient for predicting hard-classified samples. On the contrary, we human beings may need to carefully check the sample many times before making a final decision. During the recheck process, one may refine/adjust the prediction by referring to related samples. Motivated by this, we propose to predict those hard-classified test samples in a looped manner to boost the model performance. However, this idea may pose a critical challenge: how to construct looped inference, so that the original erroneous predictions on these hard test samples can be corrected with little additional effort. To address this, we propose a general Closed-Loop Inference (CLI) method. Specifically, we first devise a filtering criterion to identify those hard-classified test samples that need additional inference loops. For each hard sample, we construct an additional auxiliary learning task based on its original top-$K$ predictions to calibrate the model, and then use the calibrated model to obtain the final prediction. Promising results on ImageNet (in-distribution test samples) and ImageNet-C (out-of-distribution test samples) demonstrate the effectiveness of CLI in improving the performance of any pre-trained model.