 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explaining Time Series Predictions with Dynamic Masks
Jun 09, 2021
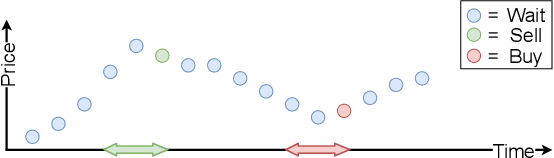

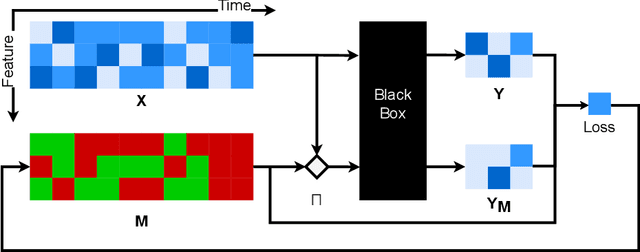
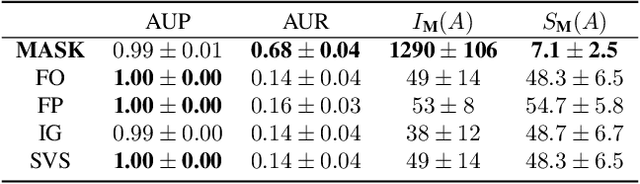
How can we explain the predictions of a machine learning model? When the data is structured as a multivariate time series, this question induces additional difficulties such as the necessity for the explanation to embody the time dependency and the large number of inputs. To address these challenges, we propose dynamic masks (Dynamask). This method produces instance-wise importance scores for each feature at each time step by fitting a perturbation mask to the input sequence. In order to incorporate the time dependency of the data, Dynamask studies the effects of dynamic perturbation operators. In order to tackle the large number of inputs, we propose a scheme to make the feature selection parsimonious (to select no more feature than necessary) and legible (a notion that we detail by making a parallel with information theory). With synthetic and real-world data, we demonstrate that the dynamic underpinning of Dynamask, together with its parsimony, offer a neat improvement in the identification of feature importance over time. The modularity of Dynamask makes it ideal as a plug-in to increase the transparency of a wide range of machine learning models in areas such as medicine and finance, where time series are abundant.
Relighting4D: Neural Relightable Human from Videos
Jul 14, 2022
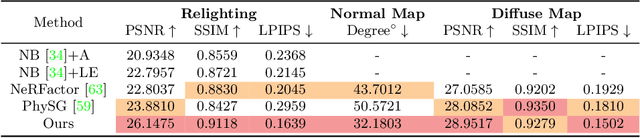
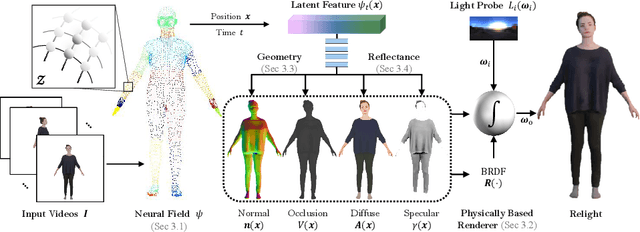
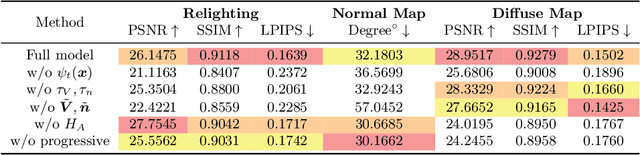
Human relighting is a highly desirable yet challenging task. Existing works either require expensive one-light-at-a-time (OLAT) captured data using light stage or cannot freely change the viewpoints of the rendered body. In this work, we propose a principled framework, Relighting4D, that enables free-viewpoints relighting from only human videos under unknown illuminations. Our key insight is that the space-time varying geometry and reflectance of the human body can be decomposed as a set of neural fields of normal, occlusion, diffuse, and specular maps. These neural fields are further integrated into reflectance-aware physically based rendering, where each vertex in the neural field absorbs and reflects the light from the environment. The whole framework can be learned from videos in a self-supervised manner, with physically informed priors designed for regularization. Extensive experiments on both real and synthetic datasets demonstrate that our framework is capable of relighting dynamic human actors with free-viewpoints.
Out-of-distribution Detection via Frequency-regularized Generative Models
Aug 18, 2022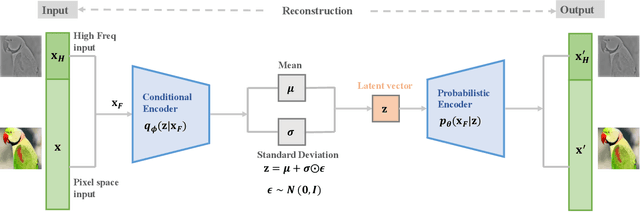
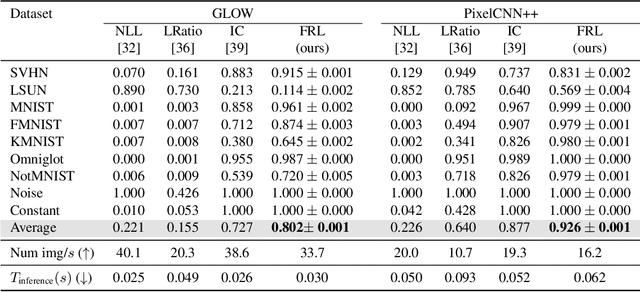

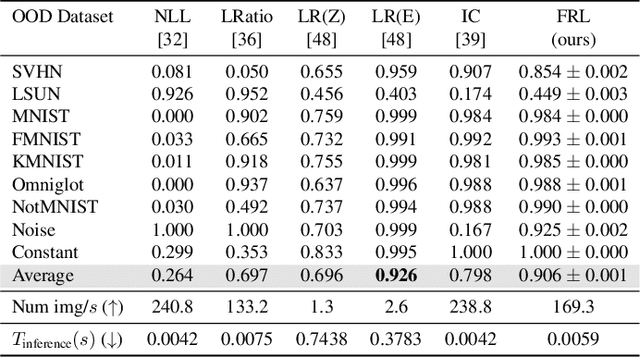
Modern deep generative models can assign high likelihood to inputs drawn from outside the training distribution, posing threats to models in open-world deployments. While much research attention has been placed on defining new test-time measures of OOD uncertainty, these methods do not fundamentally change how deep generative models are regularized and optimized in training. In particular, generative models are shown to overly rely on the background information to estimate the likelihood. To address the issue, we propose a novel frequency-regularized learning FRL framework for OOD detection, which incorporates high-frequency information into training and guides the model to focus on semantically relevant features. FRL effectively improves performance on a wide range of generative architectures, including variational auto-encoder, GLOW, and PixelCNN++. On a new large-scale evaluation task, FRL achieves the state-of-the-art performance, outperforming a strong baseline Likelihood Regret by 10.7% (AUROC) while achieving 147$\times$ faster inference speed. Extensive ablations show that FRL improves the OOD detection performance while preserving the image generation quality. Code is available at https://github.com/mu-cai/FRL.
CenterPoly: real-time instance segmentation using bounding polygons
Aug 19, 2021
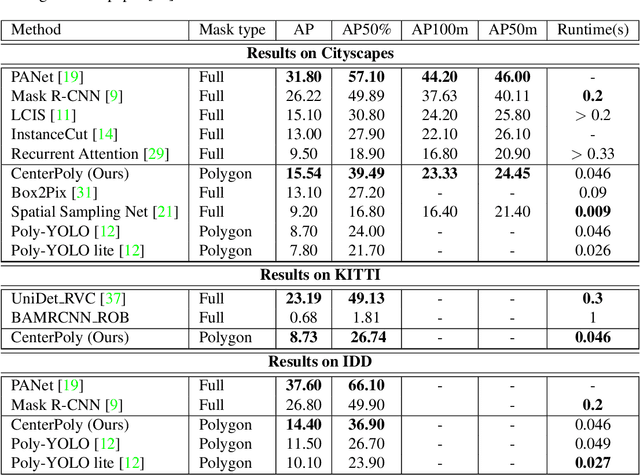
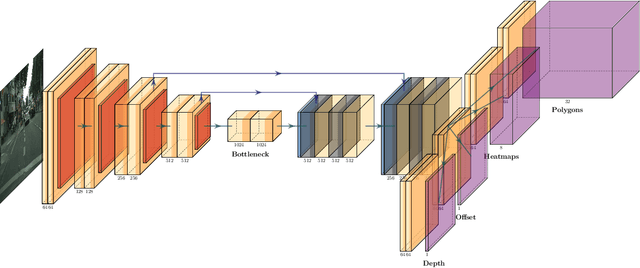
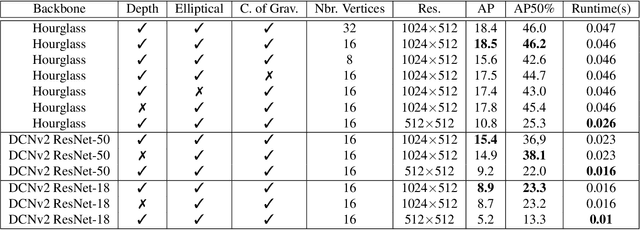
We present a novel method, called CenterPoly, for real-time instance segmentation using bounding polygons. We apply it to detect road users in dense urban environments, making it suitable for applications in intelligent transportation systems like automated vehicles. CenterPoly detects objects by their center keypoint while predicting a fixed number of polygon vertices for each object, thus performing detection and segmentation in parallel. Most of the network parameters are shared by the network heads, making it fast and lightweight enough to run at real-time speed. To properly convert mask ground-truth to polygon ground-truth, we designed a vertex selection strategy to facilitate the learning of the polygons. Additionally, to better segment overlapping objects in dense urban scenes, we also train a relative depth branch to determine which instances are closer and which are further, using available weak annotations. We propose several models with different backbones to show the possible speed / accuracy trade-offs. The models were trained and evaluated on Cityscapes, KITTI and IDD and the results are reported on their public benchmark, which are state-of-the-art at real-time speeds. Code is available at https://github.com/hu64/CenterPoly
Deep neural network based adaptive learning for switched systems
Jul 11, 2022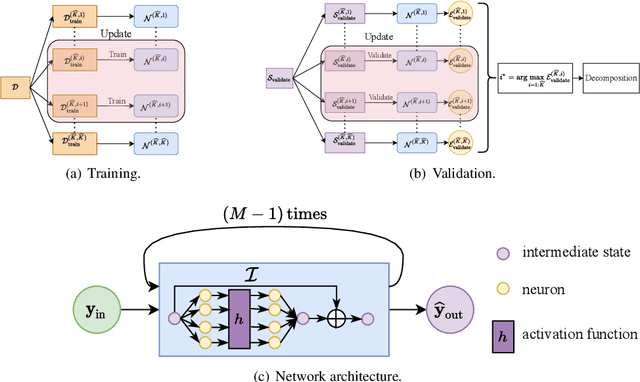

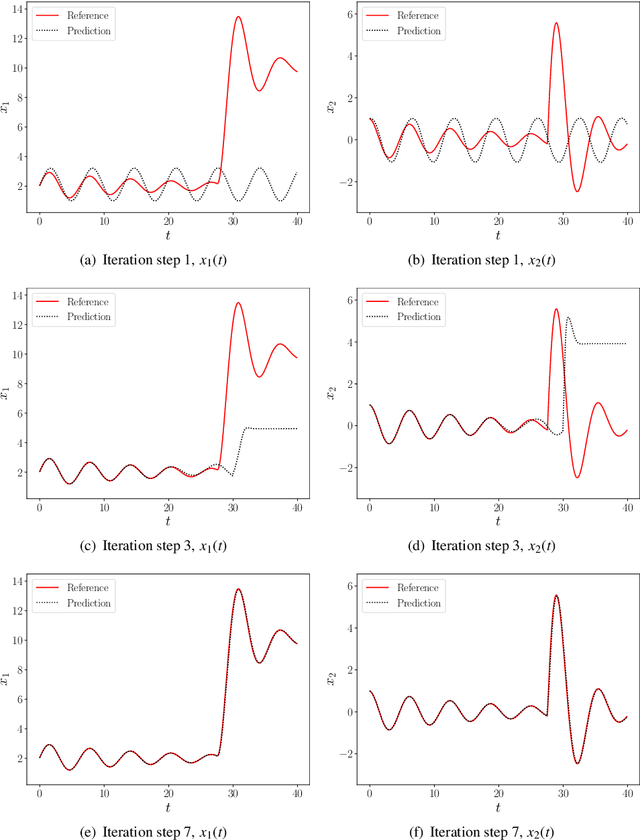
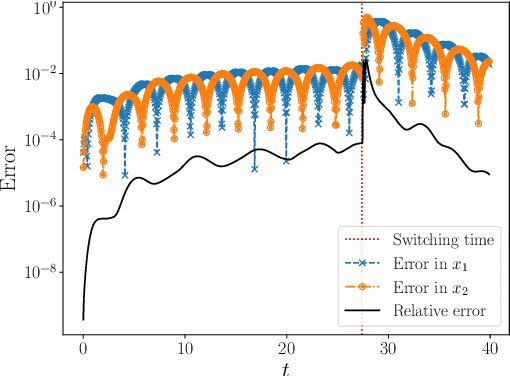
In this paper, we present a deep neural network based adaptive learning (DNN-AL) approach for switched systems. Currently, deep neural network based methods are actively developed for learning governing equations in unknown dynamic systems, but their efficiency can degenerate for switching systems, where structural changes exist at discrete time instants. In this new DNN-AL strategy, observed datasets are adaptively decomposed into subsets, such that no structural changes within each subset. During the adaptive procedures, DNNs are hierarchically constructed, and unknown switching time instants are gradually identified. Especially, network parameters at previous iteration steps are reused to initialize networks for the later iteration steps, which gives efficient training procedures for the DNNs. For the DNNs obtained through our DNN-AL, bounds of the prediction error are established. Numerical studies are conducted to demonstrate the efficiency of DNN-AL.
Progressive Multi-scale Light Field Networks
Aug 13, 2022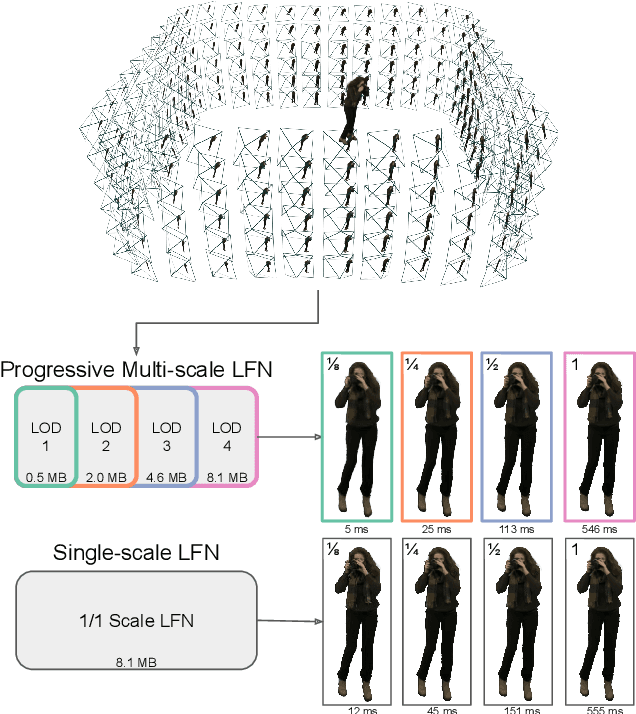


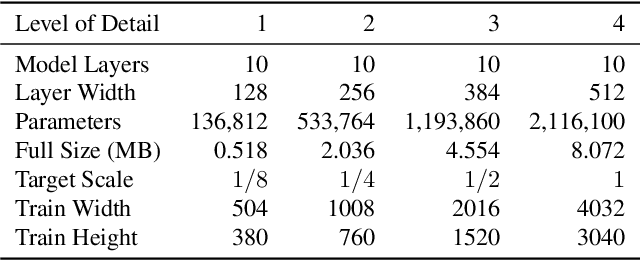
Neural representations have shown great promise in their ability to represent radiance and light fields while being very compact compared to the image set representation. However, current representations are not well suited for streaming as decoding can only be done at a single level of detail and requires downloading the entire neural network model. Furthermore, high-resolution light field networks can exhibit flickering and aliasing as neural networks are sampled without appropriate filtering. To resolve these issues, we present a progressive multi-scale light field network that encodes a light field with multiple levels of detail. Lower levels of detail are encoded using fewer neural network weights enabling progressive streaming and reducing rendering time. Our progressive multi-scale light field network addresses aliasing by encoding smaller anti-aliased representations at its lower levels of detail. Additionally, per-pixel level of detail enables our representation to support dithered transitions and foveated rendering.
Universal expressiveness of variational quantum classifiers and quantum kernels for support vector machines
Jul 12, 2022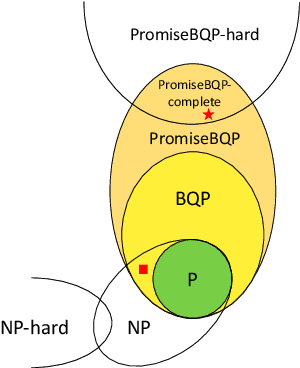
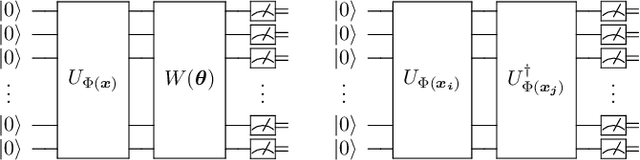
Machine learning is considered to be one of the most promising applications of quantum computing. Therefore, the search for quantum advantage of the quantum analogues of machine learning models is a key research goal. Here, we show that variational quantum classifiers (VQC) and support vector machines with quantum kernels (QSVM) can solve a classification problem based on the k-Forrelation problem, which is known to be PromiseBQP-complete. Because the PromiseBQP complexity class includes all Bounded-Error Quantum Polynomial-Time (BQP) decision problems, our results imply that there exists a feature map and a quantum kernel that make VQC and QSVM efficient solvers for any BQP problem. This means that the feature map of VQC or the quantum kernel of QSVM can be designed to have quantum advantage for any classification problem that cannot be classically solved in polynomial time but contrariwise by a quantum computer.
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 03, 2022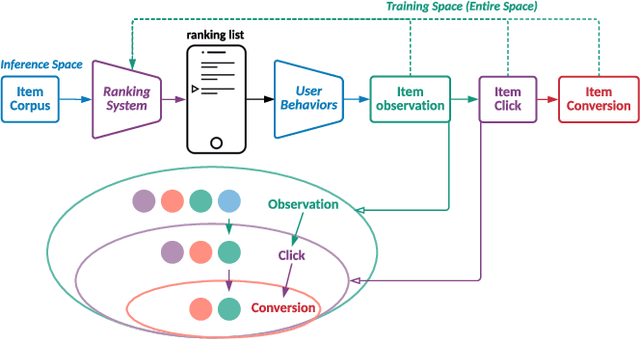

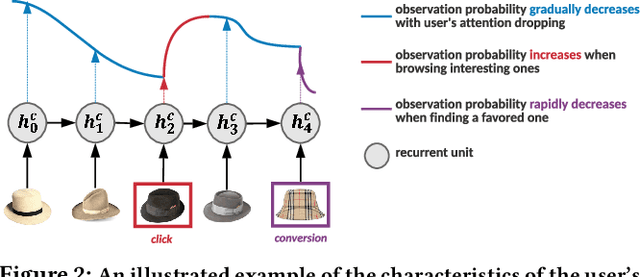
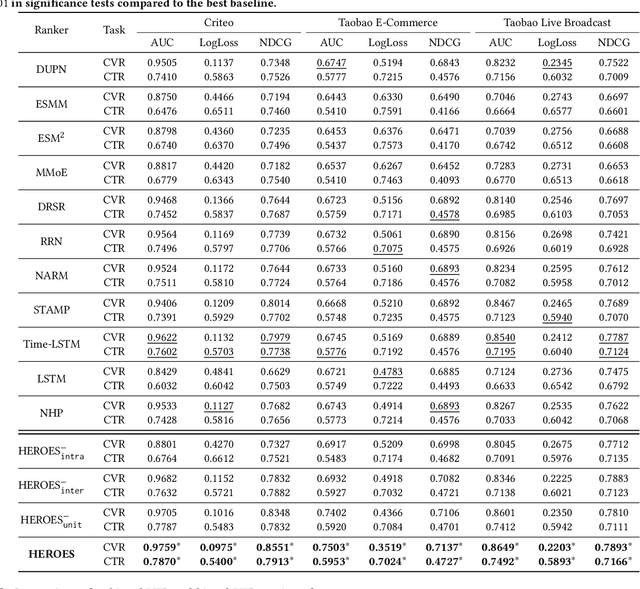
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.
Tragedy Plus Time: Capturing Unintended Human Activities from Weakly-labeled Videos
Apr 28, 2022
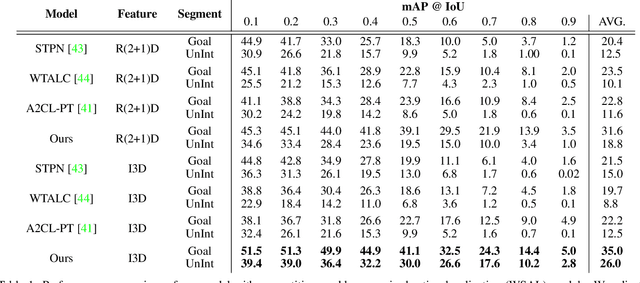
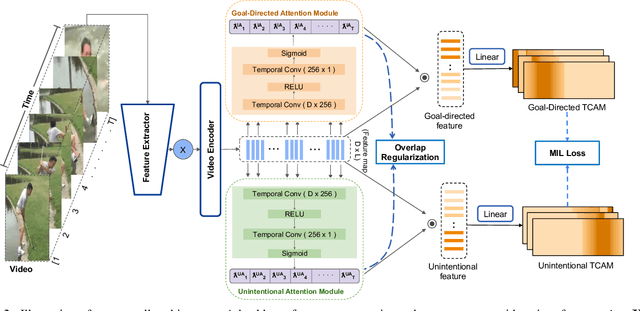
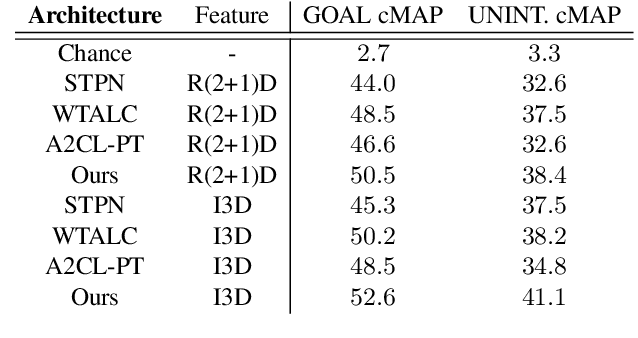
In videos that contain actions performed unintentionally, agents do not achieve their desired goals. In such videos, it is challenging for computer vision systems to understand high-level concepts such as goal-directed behavior, an ability present in humans from a very early age. Inculcating this ability in artificially intelligent agents would make them better social learners by allowing them to evaluate human action under a teleological lens. To validate the ability of deep learning models to perform this task, we curate the W-Oops dataset, built upon the Oops dataset [15]. W-Oops consists of 2,100 unintentional human action videos, with 44 goal-directed and 30 unintentional video-level activity labels collected through human annotations. Due to the expensive segment annotation procedure, we propose a weakly supervised algorithm for localizing the goal-directed as well as unintentional temporal regions in the video leveraging solely video-level labels. In particular, we employ an attention mechanism-based strategy that predicts the temporal regions which contribute the most to a classification task. Meanwhile, our designed overlap regularization allows the model to focus on distinct portions of the video for inferring the goal-directed and unintentional activity while guaranteeing their temporal ordering. Extensive quantitative experiments verify the validity of our localization method. We further conduct a video captioning experiment which demonstrates that the proposed localization module does indeed assist teleological action understanding.
A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation
Jul 15, 2022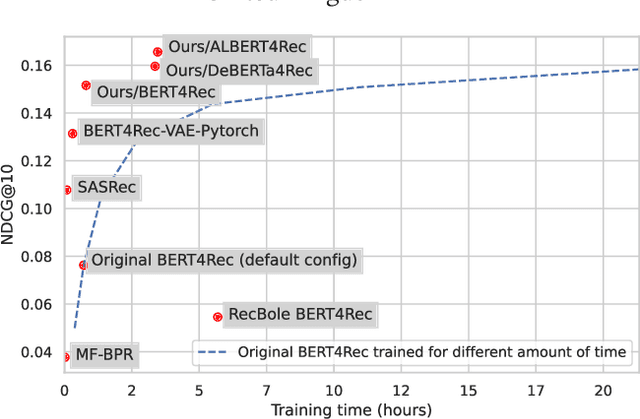
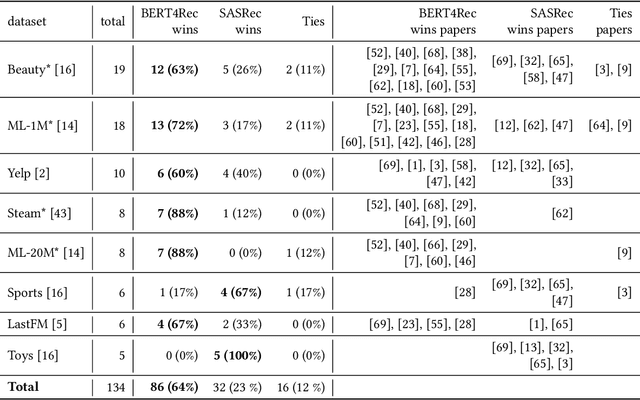
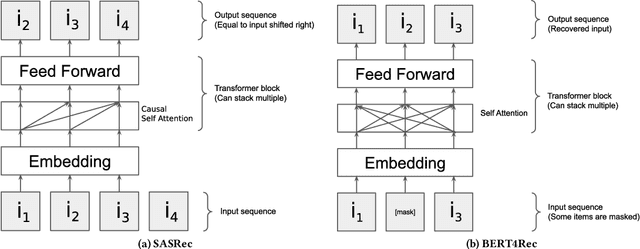

BERT4Rec is an effective model for sequential recommendation based on the Transformer architecture. In the original publication, BERT4Rec claimed superiority over other available sequential recommendation approaches (e.g. SASRec), and it is now frequently being used as a state-of-the art baseline for sequential recommendations. However, not all subsequent publications confirmed this result and proposed other models that were shown to outperform BERT4Rec in effectiveness. In this paper we systematically review all publications that compare BERT4Rec with another popular Transformer-based model, namely SASRec, and show that BERT4Rec results are not consistent within these publications. To understand the reasons behind this inconsistency, we analyse the available implementations of BERT4Rec and show that we fail to reproduce results of the original BERT4Rec publication when using their default configuration parameters. However, we are able to replicate the reported results with the original code if training for a much longer amount of time (up to 30x) compared to the default configuration. We also propose our own implementation of BERT4Rec based on the Hugging Face Transformers library, which we demonstrate replicates the originally reported results on 3 out 4 datasets, while requiring up to 95% less training time to converge. Overall, from our systematic review and detailed experiments, we conclude that BERT4Rec does indeed exhibit state-of-the-art effectiveness for sequential recommendation, but only when trained for a sufficient amount of time. Additionally, we show that our implementation can further benefit from adapting other Transformer architectures that are available in the Hugging Face Transformers library (e.g. using disentangled attention, as provided by DeBERTa, or larger hidden layer size cf. ALBERT).