 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Lensless multicore-fiber microendoscope for real-time tailored light field generation with phase encoder neural network (CoreNet)
Nov 24, 2021
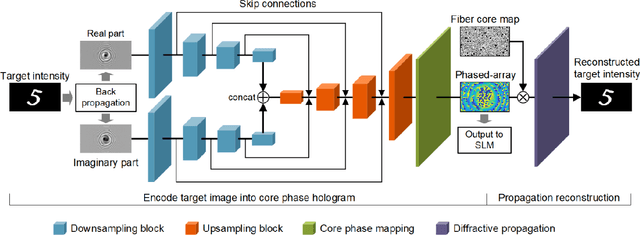

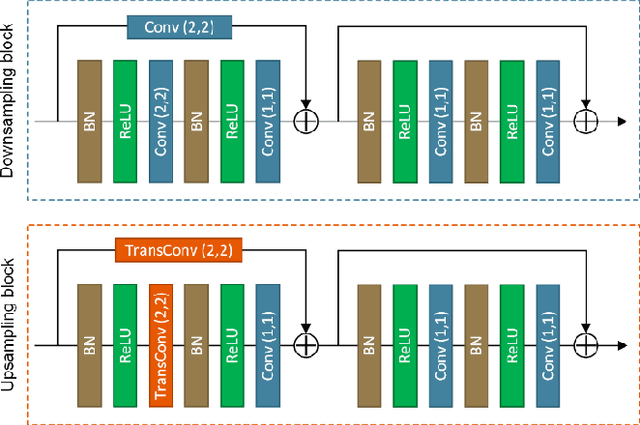

The generation of tailored light with multi-core fiber (MCF) lensless microendoscopes is widely used in biomedicine. However, the computer-generated holograms (CGHs) used for such applications are typically generated by iterative algorithms, which demand high computation effort, limiting advanced applications like in vivo optogenetic stimulation and fiber-optic cell manipulation. The random and discrete distribution of the fiber cores induces strong spatial aliasing to the CGHs, hence, an approach that can rapidly generate tailored CGHs for MCFs is highly demanded. We demonstrate a novel phase encoder deep neural network (CoreNet), which can generate accurate tailored CGHs for MCFs at a near video-rate. Simulations show that CoreNet can speed up the computation time by two magnitudes and increase the fidelity of the generated light field compared to the conventional CGH techniques. For the first time, real-time generated tailored CGHs are on-the-fly loaded to the phase-only SLM for dynamic light fields generation through the MCF microendoscope in experiments. This paves the avenue for real-time cell rotation and several further applications that require real-time high-fidelity light delivery in biomedicine.
The Saddle-Point Accountant for Differential Privacy
Aug 20, 2022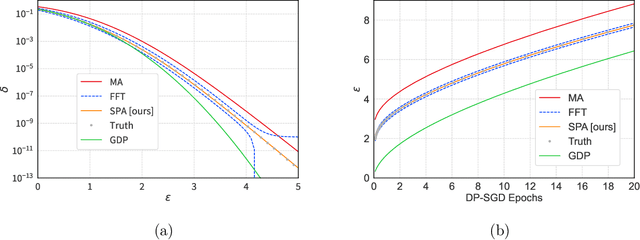
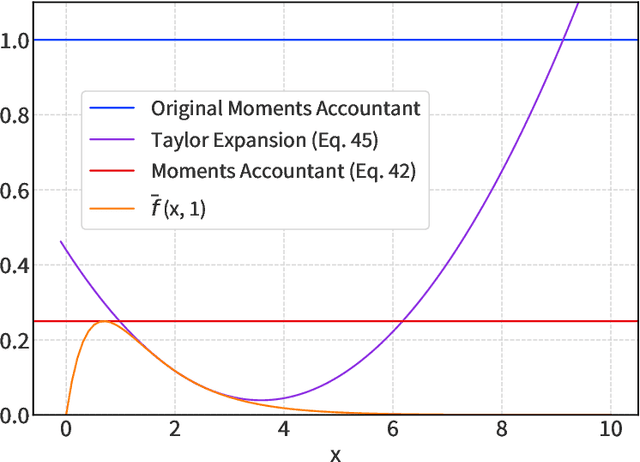
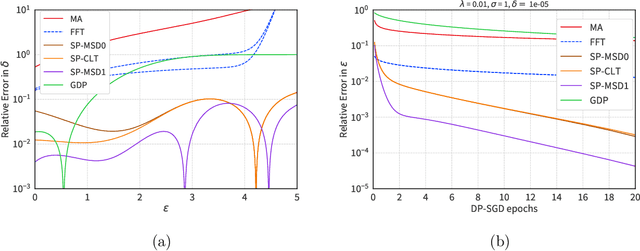
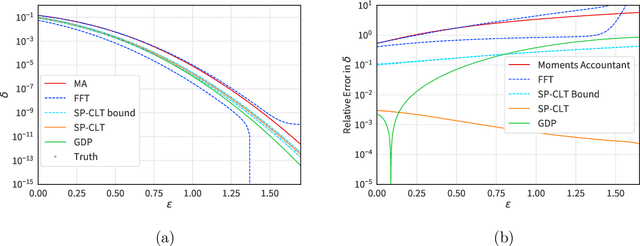
We introduce a new differential privacy (DP) accountant called the saddle-point accountant (SPA). SPA approximates privacy guarantees for the composition of DP mechanisms in an accurate and fast manner. Our approach is inspired by the saddle-point method -- a ubiquitous numerical technique in statistics. We prove rigorous performance guarantees by deriving upper and lower bounds for the approximation error offered by SPA. The crux of SPA is a combination of large-deviation methods with central limit theorems, which we derive via exponentially tilting the privacy loss random variables corresponding to the DP mechanisms. One key advantage of SPA is that it runs in constant time for the $n$-fold composition of a privacy mechanism. Numerical experiments demonstrate that SPA achieves comparable accuracy to state-of-the-art accounting methods with a faster runtime.
Multiscale Causal Structure Learning
Jul 16, 2022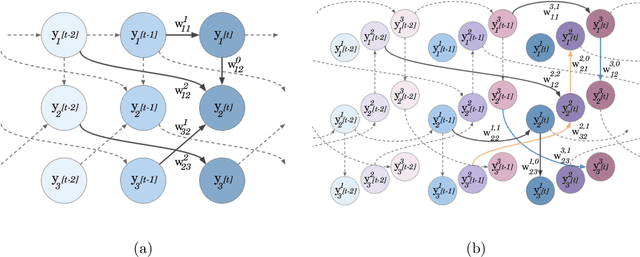
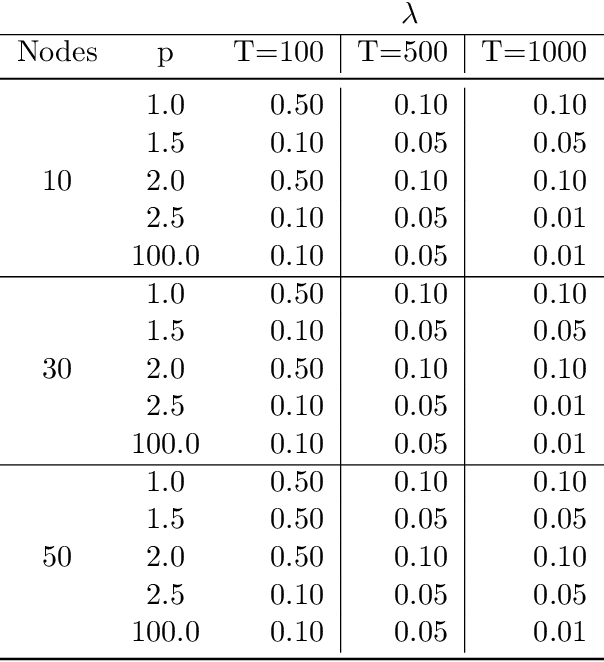
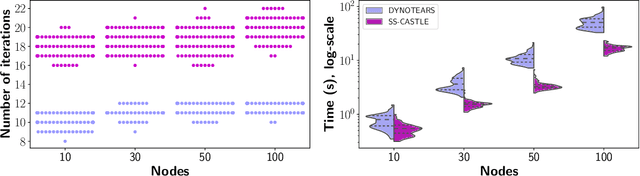
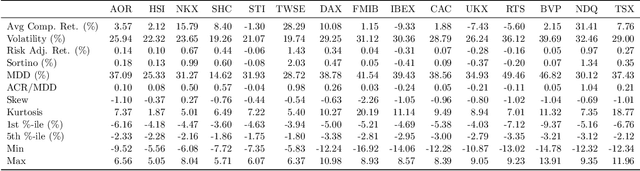
The inference of causal structures from observed data plays a key role in unveiling the underlying dynamics of the system. This paper exposes a novel method, named Multiscale-Causal Structure Learning (MS-CASTLE), to estimate the structure of linear causal relationships occurring at different time scales. Differently from existing approaches, MS-CASTLE takes explicitly into account instantaneous and lagged inter-relations between multiple time series, represented at different scales, hinging on stationary wavelet transform and non-convex optimization. MS-CASTLE incorporates, as a special case, a single-scale version named SS-CASTLE, which compares favorably in terms of computational efficiency, performance and robustness with respect to the state of the art onto synthetic data. We used MS-CASTLE to study the multiscale causal structure of the risk of 15 global equity markets, during covid-19 pandemic, illustrating how MS-CASTLE can extract meaningful information thanks to its multiscale analysis, outperforming SS-CASTLE. We found that the most persistent and strongest interactions occur at mid-term time resolutions. Moreover, we identified the stock markets that drive the risk during the considered period: Brazil, Canada and Italy. The proposed approach can be exploited by financial investors who, depending to their investment horizon, can manage the risk within equity portfolios from a causal perspective.
DTWSSE: Data Augmentation with a Siamese Encoder for Time Series
Aug 23, 2021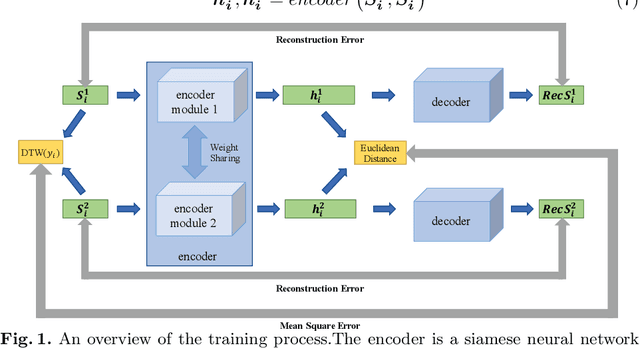
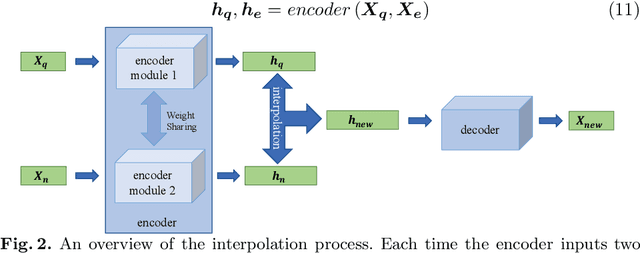
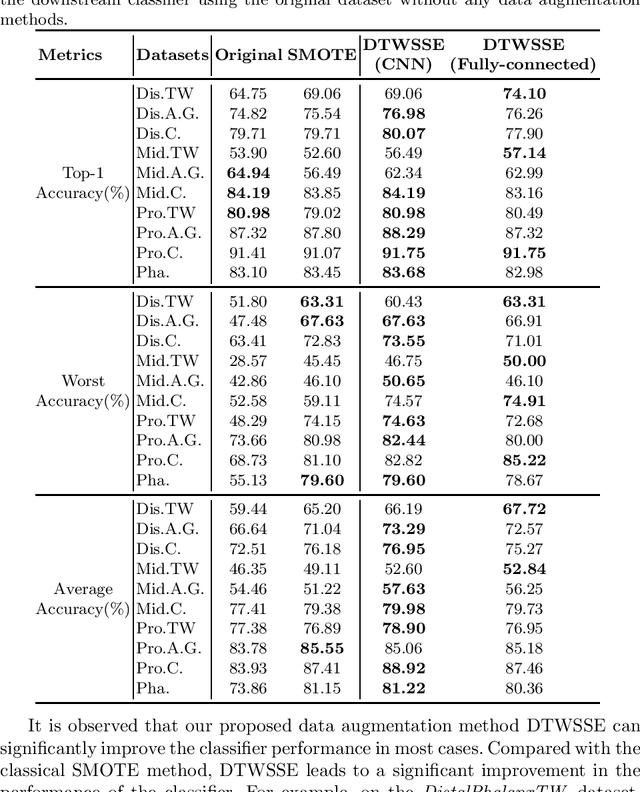
Access to labeled time series data is often limited in the real world, which constrains the performance of deep learning models in the field of time series analysis. Data augmentation is an effective way to solve the problem of small sample size and imbalance in time series datasets. The two key factors of data augmentation are the distance metric and the choice of interpolation method. SMOTE does not perform well on time series data because it uses a Euclidean distance metric and interpolates directly on the object. Therefore, we propose a DTW-based synthetic minority oversampling technique using siamese encoder for interpolation named DTWSSE. In order to reasonably measure the distance of the time series, DTW, which has been verified to be an effective method forts, is employed as the distance metric. To adapt the DTW metric, we use an autoencoder trained in an unsupervised self-training manner for interpolation. The encoder is a Siamese Neural Network for mapping the time series data from the DTW hidden space to the Euclidean deep feature space, and the decoder is used to map the deep feature space back to the DTW hidden space. We validate the proposed methods on a number of different balanced or unbalanced time series datasets. Experimental results show that the proposed method can lead to better performance of the downstream deep learning model.
Enabling Connectivity for Automated Mobility: A Novel MQTT-based Interface Evaluated in a 5G Case Study on Edge-Cloud Lidar Object Detection
Sep 08, 2022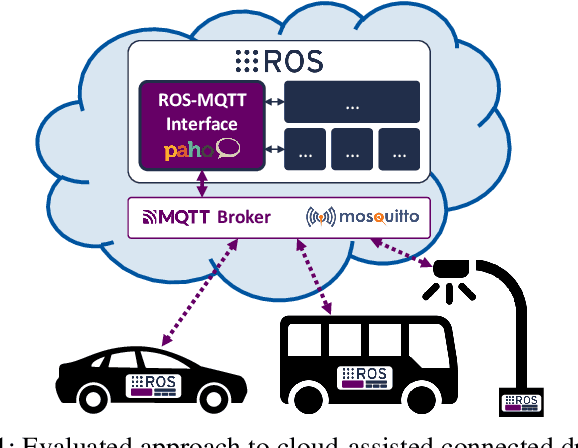


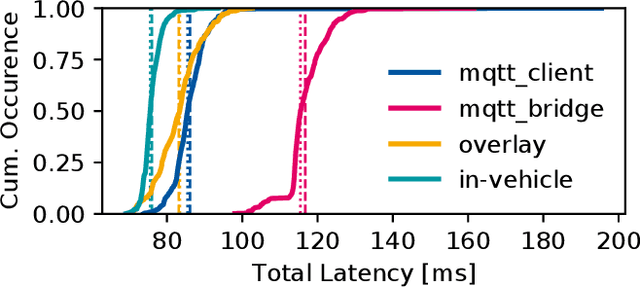
Enabling secure and reliable high-bandwidth lowlatency connectivity between automated vehicles and external servers, intelligent infrastructure, and other road users is a central step in making fully automated driving possible. The availability of data interfaces, which allow this kind of connectivity, has the potential to distinguish artificial agents' capabilities in connected, cooperative, and automated mobility systems from the capabilities of human operators, who do not possess such interfaces. Connected agents can for example share data to build collective environment models, plan collective behavior, and learn collectively from the shared data that is centrally combined. This paper presents multiple solutions that allow connected entities to exchange data. In particular, we propose a new universal communication interface which uses the Message Queuing Telemetry Transport (MQTT) protocol to connect agents running the Robot Operating System (ROS). Our work integrates methods to assess the connection quality in the form of various key performance indicators in real-time. We compare a variety of approaches that provide the connectivity necessary for the exemplary use case of edge-cloud lidar object detection in a 5G network. We show that the mean latency between the availability of vehicle-based sensor measurements and the reception of a corresponding object list from the edge-cloud is below 87 ms. All implemented solutions are made open-source and free to use. Source code is available at https://github.com/ika-rwth-aachen/ros-v2x-benchmarking-suite.
Extracting and Visualizing Wildlife Trafficking Events from Wildlife Trafficking Reports
Jul 17, 2022
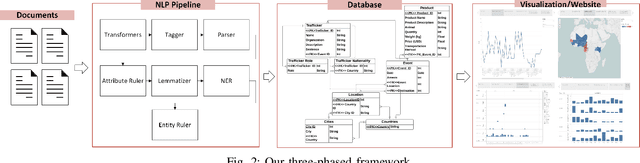

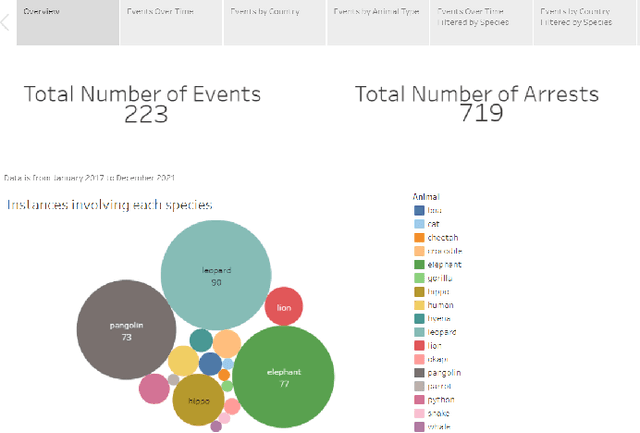
Experts combating wildlife trafficking manually sift through articles about seizures and arrests, which is time consuming and make identifying trends difficult. We apply natural language processing techniques to automatically extract data from reports published by the Eco Activists for Governance and Law Enforcement (EAGLE). We expanded Python spaCy's pre-trained pipeline and added a custom named entity ruler, which identified 15 fully correct and 36 partially correct events in 15 reports against an existing baseline, which did not identify any fully correct events. The extracted wildlife trafficking events were inserted to a database. Then, we created visualizations to display trends over time and across regions to support domain experts. These are accessible on our website, Wildlife Trafficking in Africa (https://wildlifemqp.github.io/Visualizations/).
Credit card fraud detection - Classifier selection strategy
Aug 25, 2022
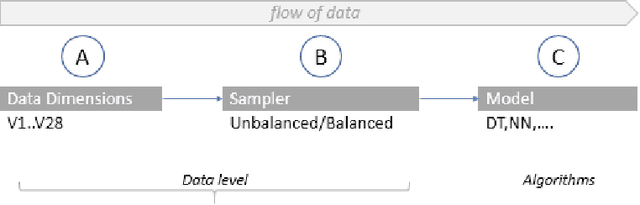

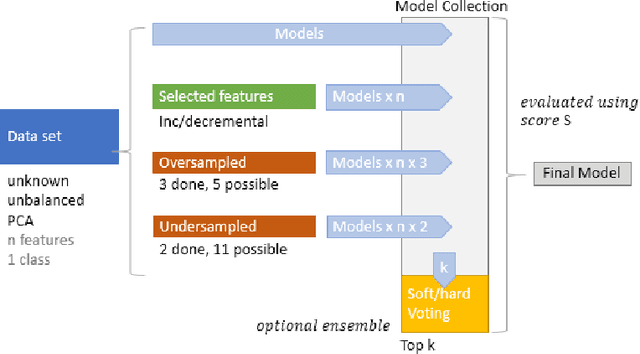
Machine learning has opened up new tools for financial fraud detection. Using a sample of annotated transactions, a machine learning classification algorithm learns to detect frauds. With growing credit card transaction volumes and rising fraud percentages there is growing interest in finding appropriate machine learning classifiers for detection. However, fraud data sets are diverse and exhibit inconsistent characteristics. As a result, a model effective on a given data set is not guaranteed to perform on another. Further, the possibility of temporal drift in data patterns and characteristics over time is high. Additionally, fraud data has massive and varying imbalance. In this work, we evaluate sampling methods as a viable pre-processing mechanism to handle imbalance and propose a data-driven classifier selection strategy for characteristic highly imbalanced fraud detection data sets. The model derived based on our selection strategy surpasses peer models, whilst working in more realistic conditions, establishing the effectiveness of the strategy.
Probabilistic forecasting for geosteering in fluvial successions using a generative adversarial network
Jul 04, 2022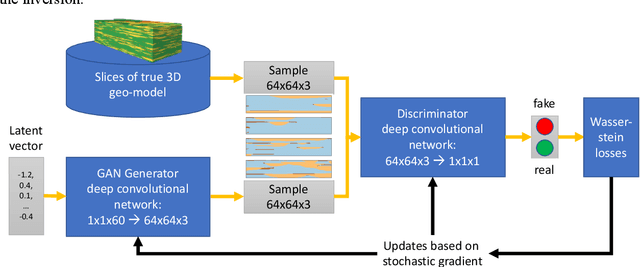
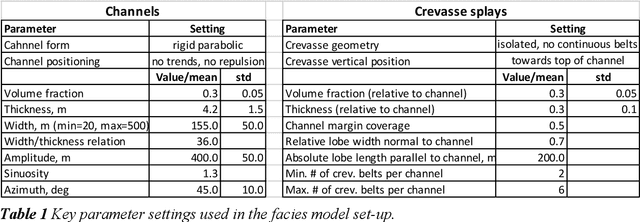
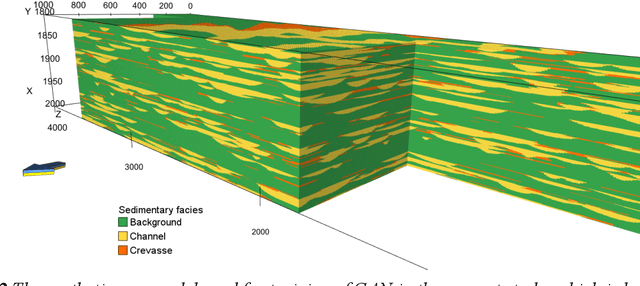
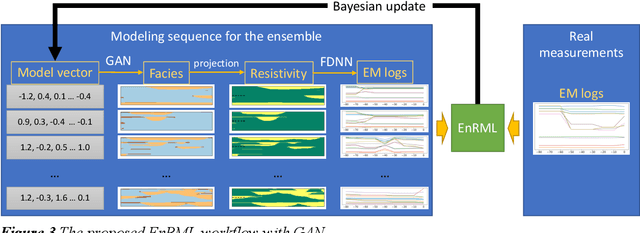
Quantitative workflows utilizing real-time data to constrain ahead-of-bit uncertainty have the potential to improve geosteering significantly. Fast updates based on real-time data are essential when drilling in complex reservoirs with high uncertainties in pre-drill models. However, practical assimilation of real-time data requires effective geological modeling and mathematically robust parameterization. We propose a generative adversarial deep neural network (GAN), trained to reproduce geologically consistent 2D sections of fluvial successions. Offline training produces a fast GAN-based approximation of complex geology parameterized as a 60-dimensional model vector with standard Gaussian distribution of each component. Probabilistic forecasts are generated using an ensemble of equiprobable model vector realizations. A forward-modeling sequence, including a GAN, converts the initial (prior) ensemble of realizations into EM log predictions. An ensemble smoother minimizes statistical misfits between predictions and real-time data, yielding an update of model vectors and reduced uncertainty around the well. Updates can be then translated to probabilistic predictions of facies and resistivities. The present paper demonstrates a workflow for geosteering in an outcrop-based, synthetic fluvial succession. In our example, the method reduces uncertainty and correctly predicts most major geological features up to 500 meters ahead of drill-bit.
Integrated Sensing and Communications with Joint Beam Squint and Beam Split for Massive MIMO
Jul 18, 2022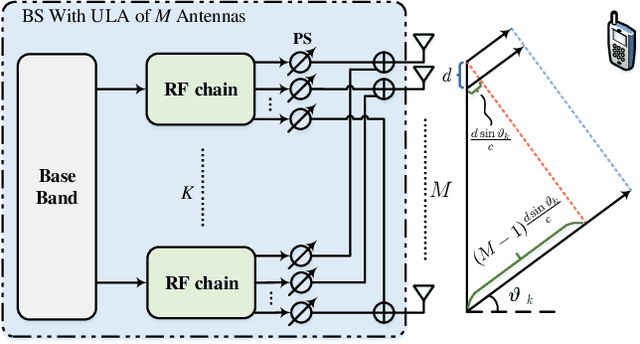
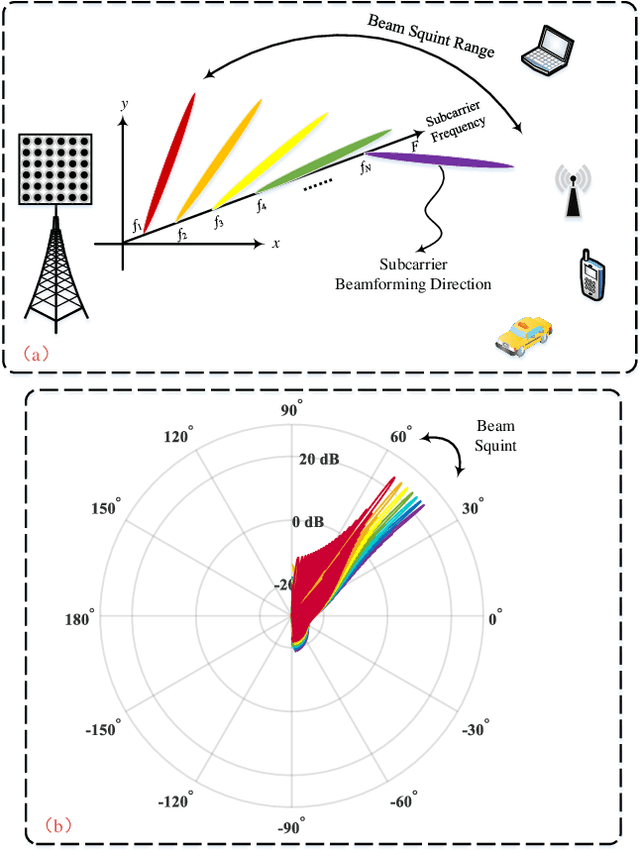
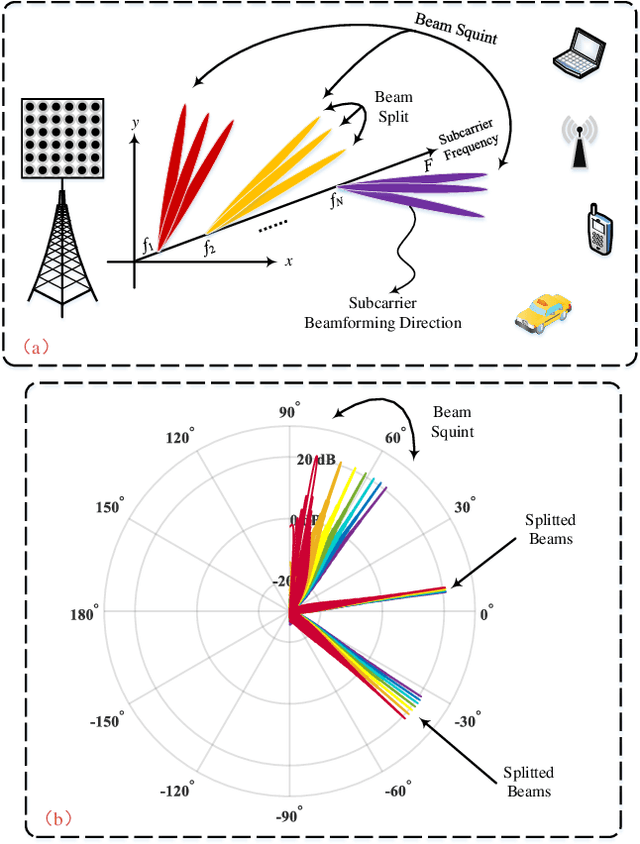
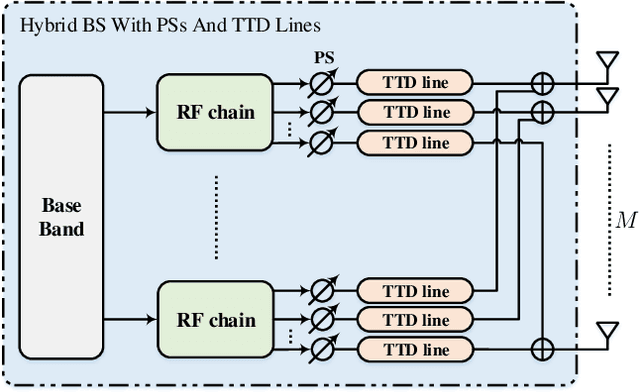
Integrated sensing and communications (ISAC) has attracted tremendous attention for the future 6G wireless communication systems. To improve the transmission rates and sensing accuracy, massive multi-input multi-output (MIMO) technique is leveraged with large transmission bandwidth. However, the growing size of transmission bandwidth and antenna array results in the beam squint effect, which hampers sensing and communications. Moreover, the time overhead of the traditional sensing algorithm is prohibitive for practical systems. In this paper, instead of alleviating the wideband beam squint effect, we take advantage of joint beam squint and beam split effect and propose a novel user directions sensing method integrated with massive MIMO orthogonal frequency division multiplexing (OFDM) systems. Specifically, with the beam squint effect, the BS utilizes the true-time-delay (TTD) lines to make the beams of different OFDM subcarriers steer towards different directions simultaneously. The users feedback the subcarrier frequency with the maximum array gain to the BS. Then, the BS calculates the direction based on the feedback subcarrier frequency. Futhermore, the beam split effect introduced by enlarging the inter-antenna spacing is exploited to expand the sensing range. The proposed sensing method operates over frequency-domain, and the intended sensing range is covered by all the subcarriers simultaneously, which reduces the time overhead significantly. Simulation results have demonstrated the effectiveness as well as the superior performance of the proposed ISAC scheme.
Does Attention Mechanism Possess the Feature of Human Reading? A Perspective of Sentiment Classification Task
Sep 08, 2022
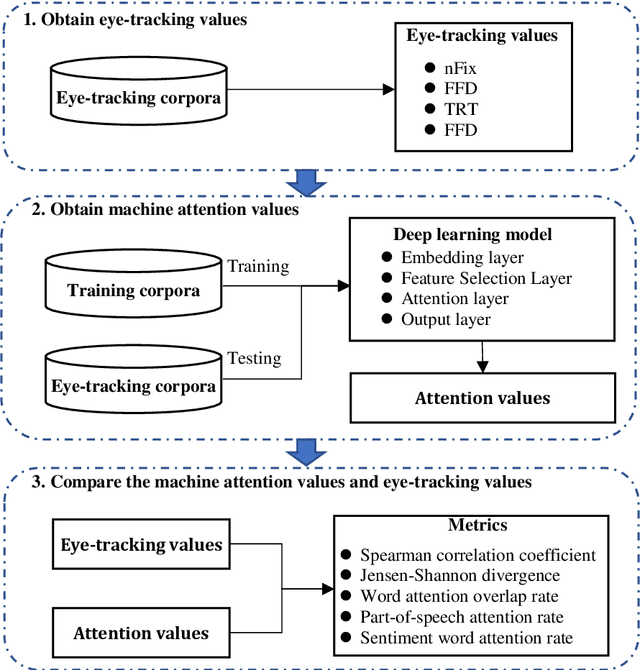
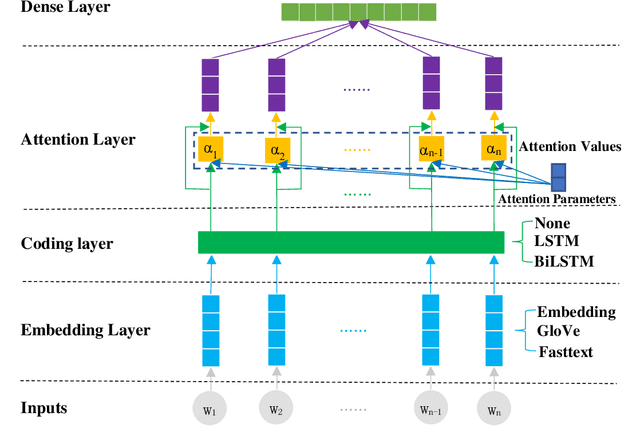
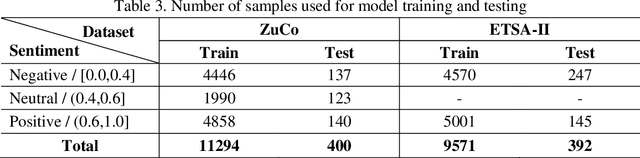
[Purpose] To understand the meaning of a sentence, humans can focus on important words in the sentence, which reflects our eyes staying on each word in different gaze time or times. Thus, some studies utilize eye-tracking values to optimize the attention mechanism in deep learning models. But these studies lack to explain the rationality of this approach. Whether the attention mechanism possesses this feature of human reading needs to be explored. [Design/methodology/approach] We conducted experiments on a sentiment classification task. Firstly, we obtained eye-tracking values from two open-source eye-tracking corpora to describe the feature of human reading. Then, the machine attention values of each sentence were learned from a sentiment classification model. Finally, a comparison was conducted to analyze machine attention values and eye-tracking values. [Findings] Through experiments, we found the attention mechanism can focus on important words, such as adjectives, adverbs, and sentiment words, which are valuable for judging the sentiment of sentences on the sentiment classification task. It possesses the feature of human reading, focusing on important words in sentences when reading. Due to the insufficient learning of the attention mechanism, some words are wrongly focused. The eye-tracking values can help the attention mechanism correct this error and improve the model performance. [Originality/value] Our research not only provides a reasonable explanation for the study of using eye-tracking values to optimize the attention mechanism, but also provides new inspiration for the interpretability of attention mechanism.