 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ILASR: Privacy-Preserving Incremental Learning for AutomaticSpeech Recognition at Production Scale
Jul 19, 2022
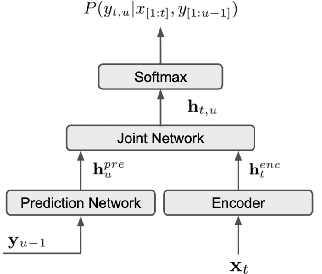
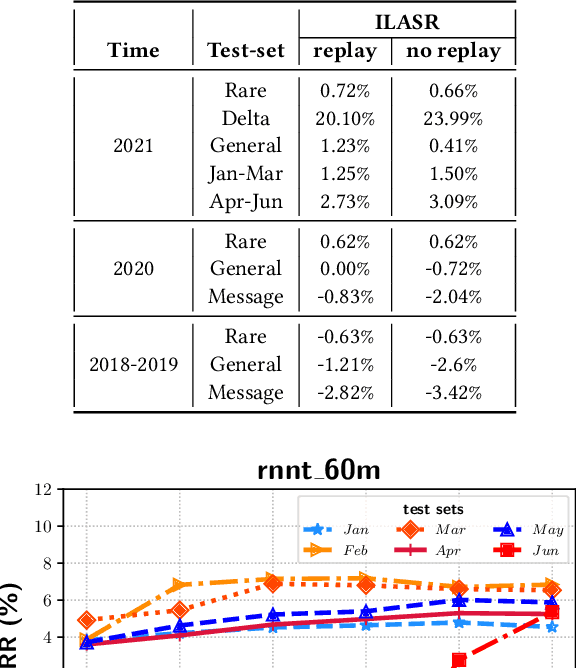
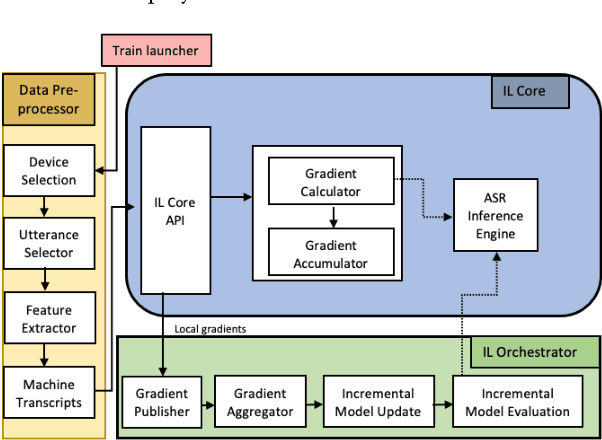
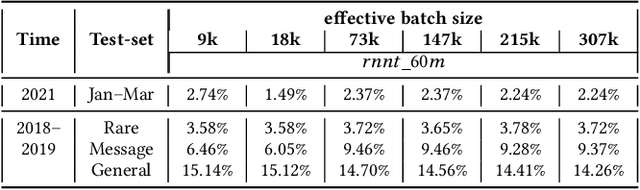
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
Simultaneously Achieving Sublinear Regret and Constraint Violations for Online Convex Optimization with Time-varying Constraints
Nov 15, 2021
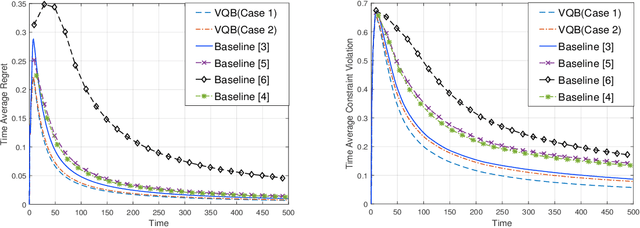

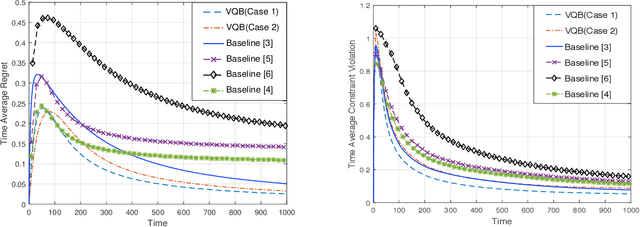
In this paper, we develop a novel virtual-queue-based online algorithm for online convex optimization (OCO) problems with long-term and time-varying constraints and conduct a performance analysis with respect to the dynamic regret and constraint violations. We design a new update rule of dual variables and a new way of incorporating time-varying constraint functions into the dual variables. To the best of our knowledge, our algorithm is the first parameter-free algorithm to simultaneously achieve sublinear dynamic regret and constraint violations. Our proposed algorithm also outperforms the state-of-the-art results in many aspects, e.g., our algorithm does not require the Slater condition. Meanwhile, for a group of practical and widely-studied constrained OCO problems in which the variation of consecutive constraints is smooth enough across time, our algorithm achieves $O(1)$ constraint violations. Furthermore, we extend our algorithm and analysis to the case when the time horizon $T$ is unknown. Finally, numerical experiments are conducted to validate the theoretical guarantees of our algorithm, and some applications of our proposed framework will be outlined.
* 31 pages, it has been accepted at Performance 2021
Transformer Quality in Linear Time
Feb 21, 2022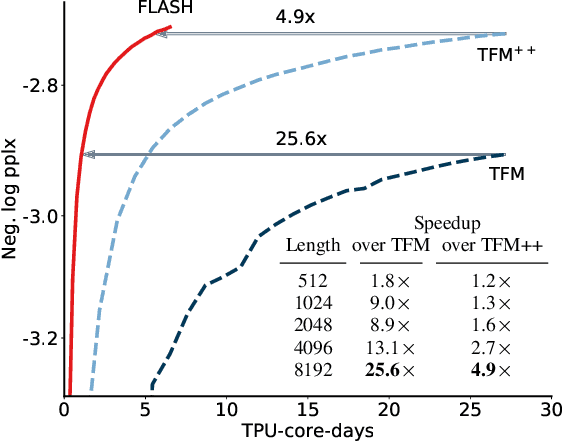
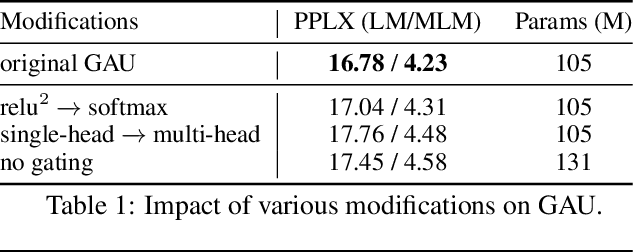
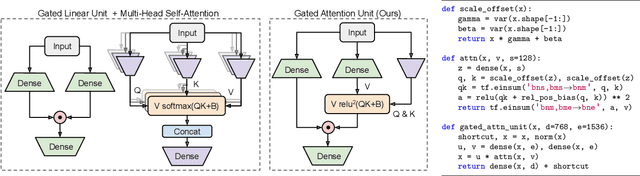

We revisit the design choices in Transformers, and propose methods to address their weaknesses in handling long sequences. First, we propose a simple layer named gated attention unit, which allows the use of a weaker single-head attention with minimal quality loss. We then propose a linear approximation method complementary to this new layer, which is accelerator-friendly and highly competitive in quality. The resulting model, named FLASH, matches the perplexity of improved Transformers over both short (512) and long (8K) context lengths, achieving training speedups of up to 4.9$\times$ on Wiki-40B and 12.1$\times$ on PG-19 for auto-regressive language modeling, and 4.8$\times$ on C4 for masked language modeling.
Phishing URL Detection: A Network-based Approach Robust to Evasion
Sep 03, 2022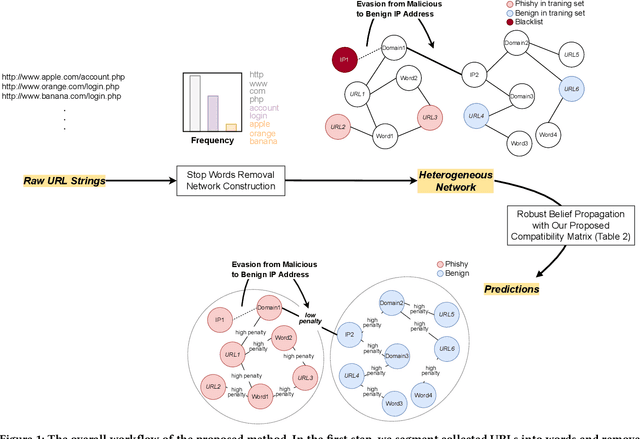

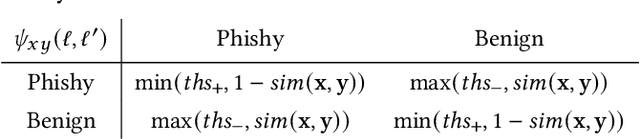
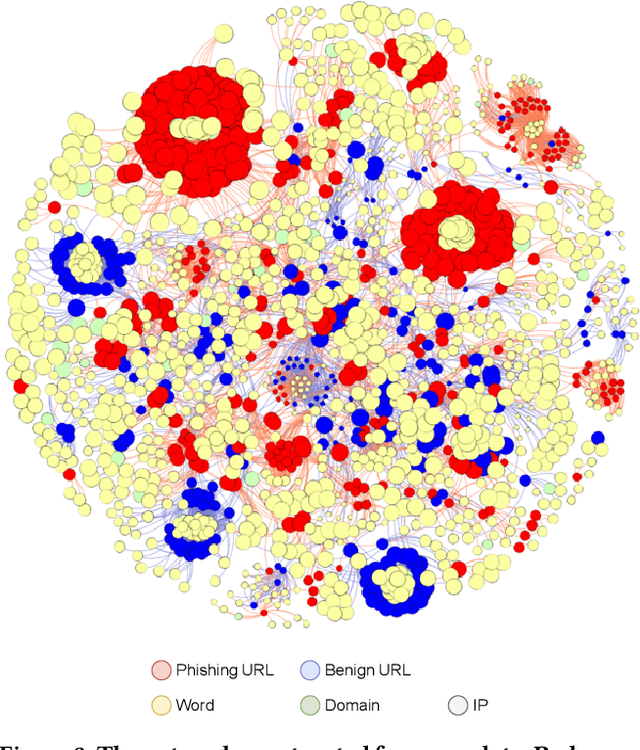
Many cyberattacks start with disseminating phishing URLs. When clicking these phishing URLs, the victim's private information is leaked to the attacker. There have been proposed several machine learning methods to detect phishing URLs. However, it still remains under-explored to detect phishing URLs with evasion, i.e., phishing URLs that pretend to be benign by manipulating patterns. In many cases, the attacker i) reuses prepared phishing web pages because making a completely brand-new set costs non-trivial expenses, ii) prefers hosting companies that do not require private information and are cheaper than others, iii) prefers shared hosting for cost efficiency, and iv) sometimes uses benign domains, IP addresses, and URL string patterns to evade existing detection methods. Inspired by those behavioral characteristics, we present a network-based inference method to accurately detect phishing URLs camouflaged with legitimate patterns, i.e., robust to evasion. In the network approach, a phishing URL will be still identified as phishy even after evasion unless a majority of its neighbors in the network are evaded at the same time. Our method consistently shows better detection performance throughout various experimental tests than state-of-the-art methods, e.g., F-1 of 0.89 for our method vs. 0.84 for the best feature-based method.
GAN Inversion for Consistent Video Interpolation and Manipulation
Aug 23, 2022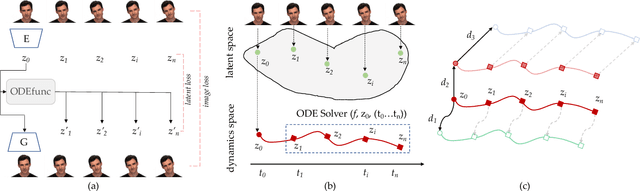

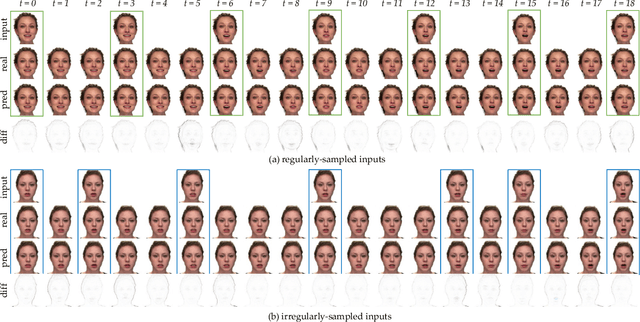
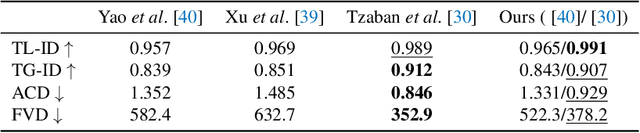
In this paper, we propose to model the video dynamics by learning the trajectory of independently inverted latent codes from GANs. The entire sequence is seen as discrete-time observations of a continuous trajectory of the initial latent code, by considering each latent code as a moving particle and the latent space as a high-dimensional dynamic system. The latent codes representing different frames are therefore reformulated as state transitions of the initial frame, which can be modeled by neural ordinary differential equations. The learned continuous trajectory allows us to perform infinite frame interpolation and consistent video manipulation. The latter task is reintroduced for video editing with the advantage of requiring the core operations to be applied to the first frame only while maintaining temporal consistency across all frames. Extensive experiments demonstrate that our method achieves state-of-the-art performance but with much less computation.
Learning Optimal Solutions via an LSTM-Optimization Framework
Jul 06, 2022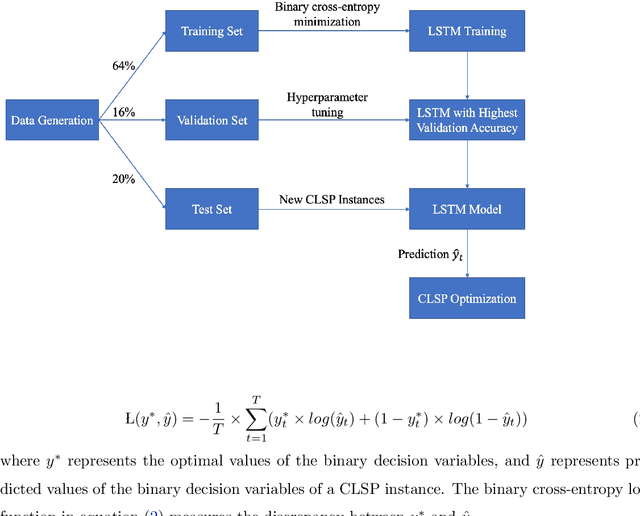
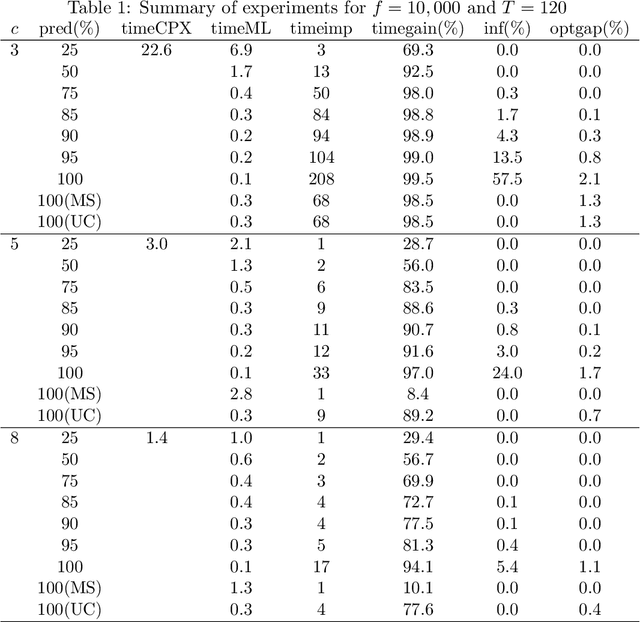
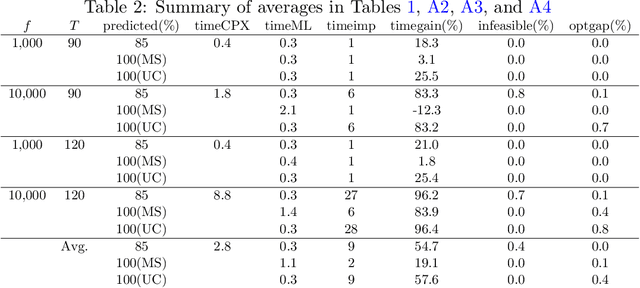
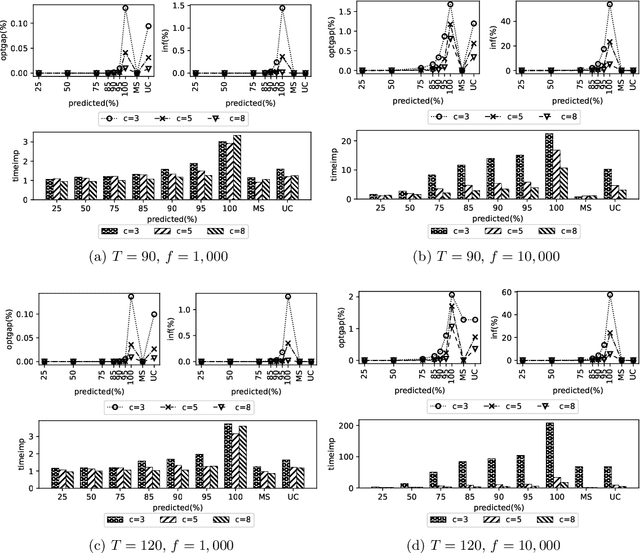
In this study, we present a deep learning-optimization framework to tackle dynamic mixed-integer programs. Specifically, we develop a bidirectional Long Short Term Memory (LSTM) framework that can process information forward and backward in time to learn optimal solutions to sequential decision-making problems. We demonstrate our approach in predicting the optimal decisions for the single-item capacitated lot-sizing problem (CLSP), where a binary variable denotes whether to produce in a period or not. Due to the dynamic nature of the problem, the CLSP can be treated as a sequence labeling task where a recurrent neural network can capture the problem's temporal dynamics. Computational results show that our LSTM-Optimization (LSTM-Opt) framework significantly reduces the solution time of benchmark CLSP problems without much loss in feasibility and optimality. For example, the predictions at the 85\% level reduce the CPLEX solution time by a factor of 9 on average for over 240,000 test instances with an optimality gap of less than 0.05\% and 0.4\% infeasibility in the test set. Also, models trained using shorter planning horizons can successfully predict the optimal solution of the instances with longer planning horizons. For the hardest data set, the LSTM predictions at the 25\% level reduce the solution time of 70 CPU hours to less than 2 CPU minutes with an optimality gap of 0.8\% and without any infeasibility. The LSTM-Opt framework outperforms classical ML algorithms, such as the logistic regression and random forest, in terms of the solution quality, and exact approaches, such as the ($\ell$, S) and dynamic programming-based inequalities, with respect to the solution time improvement. Our machine learning approach could be beneficial in tackling sequential decision-making problems similar to CLSP, which need to be solved repetitively, frequently, and in a fast manner.
Joint optimal beamforming and power control in cell-free massive MIMO
Aug 11, 2022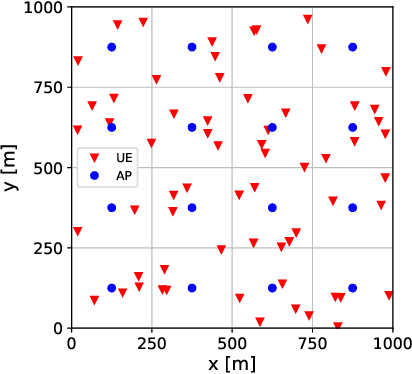
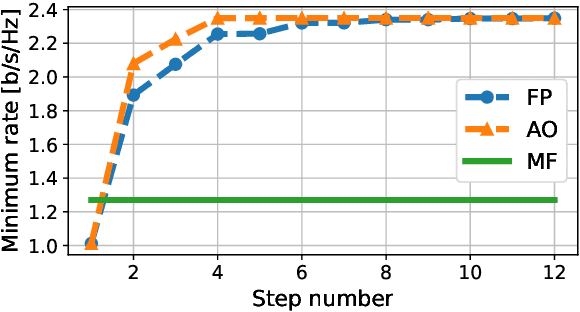
We derive a fast and optimal algorithm for solving practical weighted max-min SINR problems in cell-free massive MIMO networks. For the first time, the optimization problem jointly covers long-term power control and distributed beamforming design under imperfect cooperation. In particular, we consider user-centric clusters of access points cooperating on the basis of possibly limited channel state information sharing. Our optimal algorithm merges powerful power control tools based on interference calculus with the recently developed team theoretic framework for distributed beamforming design. In addition, we propose a variation that shows faster convergence in practice.
The Saddle-Point Accountant for Differential Privacy
Aug 20, 2022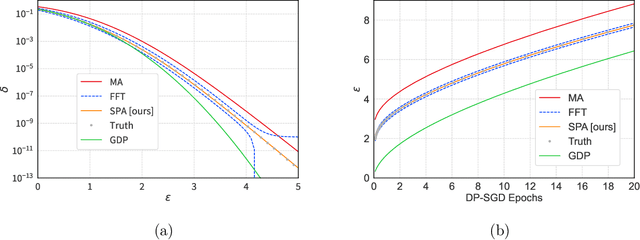
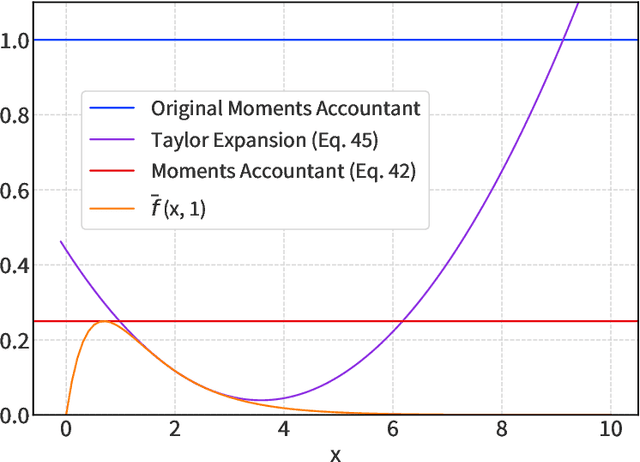
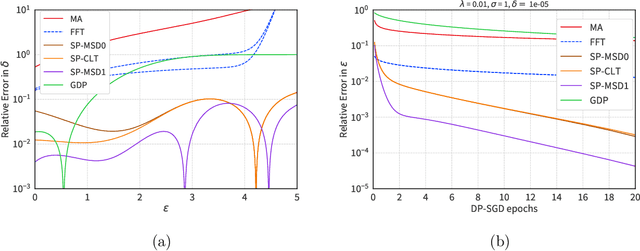
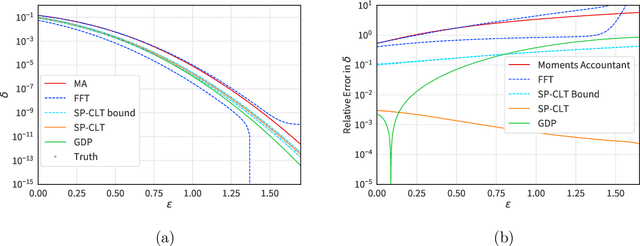
We introduce a new differential privacy (DP) accountant called the saddle-point accountant (SPA). SPA approximates privacy guarantees for the composition of DP mechanisms in an accurate and fast manner. Our approach is inspired by the saddle-point method -- a ubiquitous numerical technique in statistics. We prove rigorous performance guarantees by deriving upper and lower bounds for the approximation error offered by SPA. The crux of SPA is a combination of large-deviation methods with central limit theorems, which we derive via exponentially tilting the privacy loss random variables corresponding to the DP mechanisms. One key advantage of SPA is that it runs in constant time for the $n$-fold composition of a privacy mechanism. Numerical experiments demonstrate that SPA achieves comparable accuracy to state-of-the-art accounting methods with a faster runtime.
Wacky Weights in Learned Sparse Representations and the Revenge of Score-at-a-Time Query Evaluation
Oct 28, 2021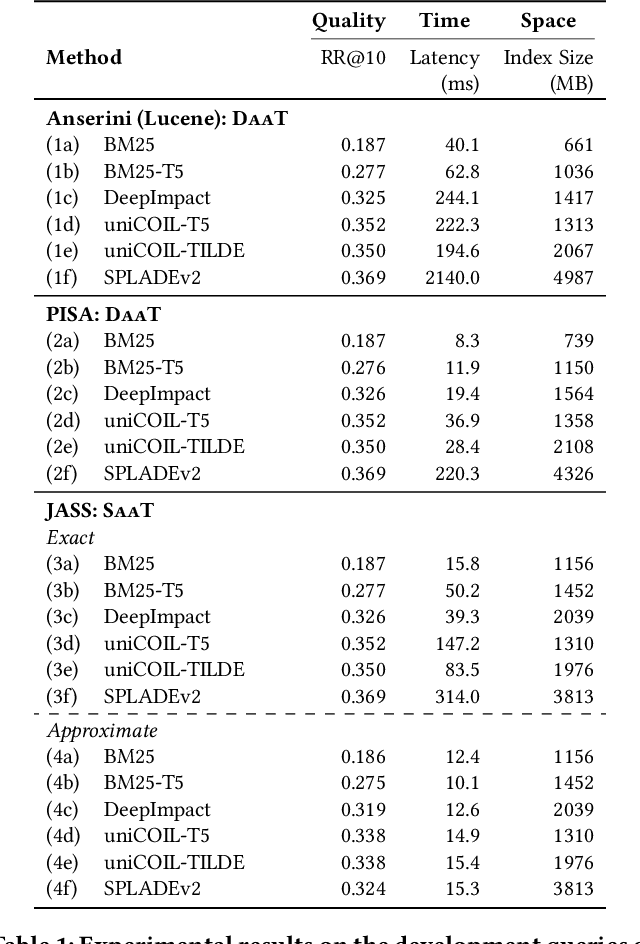
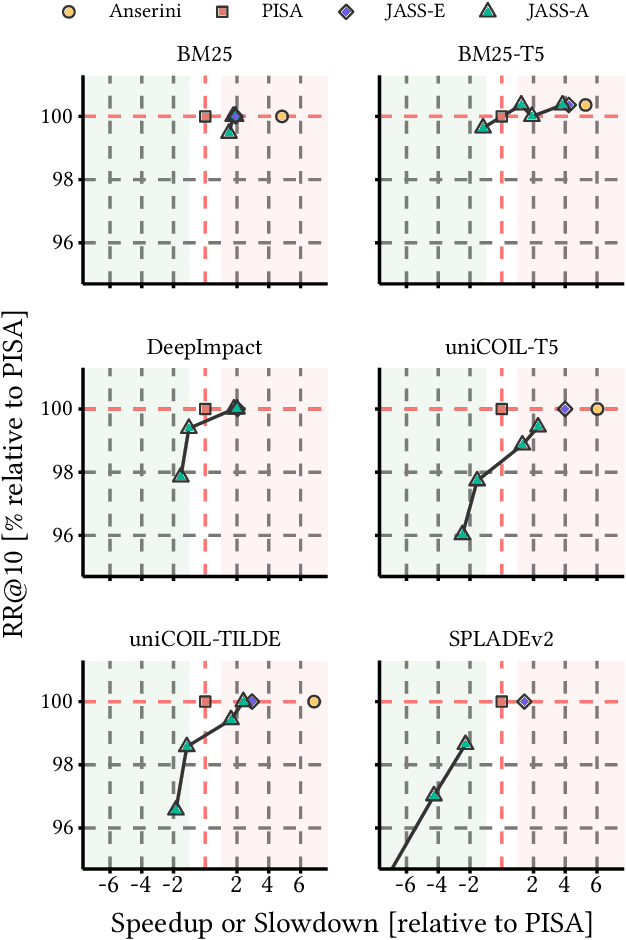
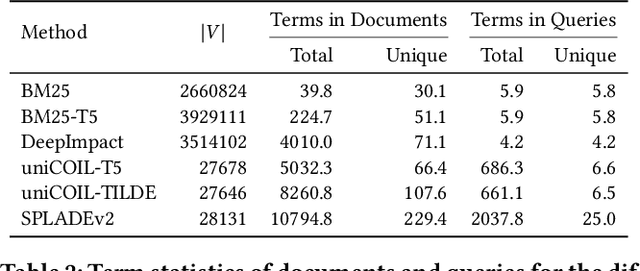
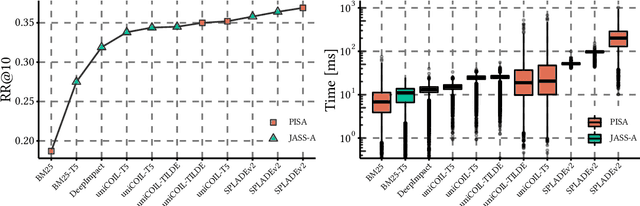
Recent advances in retrieval models based on learned sparse representations generated by transformers have led us to, once again, consider score-at-a-time query evaluation techniques for the top-k retrieval problem. Previous studies comparing document-at-a-time and score-at-a-time approaches have consistently found that the former approach yields lower mean query latency, although the latter approach has more predictable query latency. In our experiments with four different retrieval models that exploit representational learning with bags of words, we find that transformers generate "wacky weights" that appear to greatly reduce the opportunities for skipping and early exiting optimizations that lie at the core of standard document-at-a-time techniques. As a result, score-at-a-time approaches appear to be more competitive in terms of query evaluation latency than in previous studies. We find that, if an effectiveness loss of up to three percent can be tolerated, a score-at-a-time approach can yield substantial gains in mean query latency while at the same time dramatically reducing tail latency.
Little Help Makes a Big Difference: Leveraging Active Learning to Improve Unsupervised Time Series Anomaly Detection
Jan 25, 2022
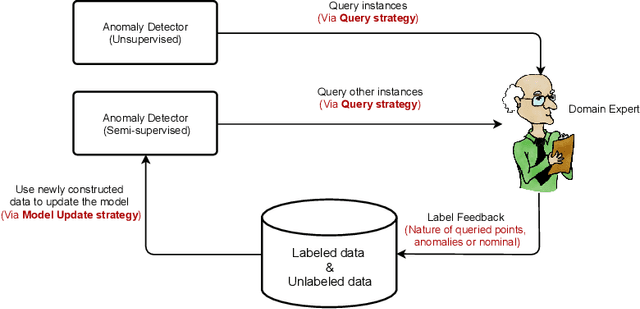
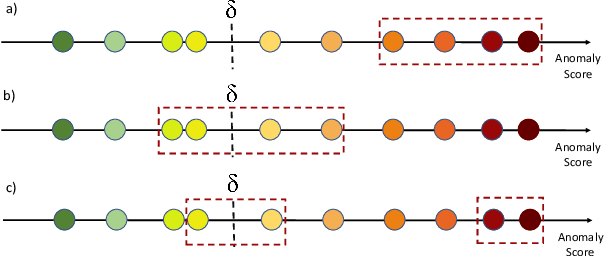

Key Performance Indicators (KPI), which are essentially time series data, have been widely used to indicate the performance of telecom networks. Based on the given KPIs, a large set of anomaly detection algorithms have been deployed for detecting the unexpected network incidents. Generally, unsupervised anomaly detection algorithms gain more popularity than the supervised ones, due to the fact that labeling KPIs is extremely time- and resource-consuming, and error-prone. However, those unsupervised anomaly detection algorithms often suffer from excessive false alarms, especially in the presence of concept drifts resulting from network re-configurations or maintenance. To tackle this challenge and improve the overall performance of unsupervised anomaly detection algorithms, we propose to use active learning to introduce and benefit from the feedback of operators, who can verify the alarms (both false and true ones) and label the corresponding KPIs with reasonable effort. Specifically, we develop three query strategies to select the most informative and representative samples to label. We also develop an efficient method to update the weights of Isolation Forest and optimally adjust the decision threshold, so as to eventually improve the performance of detection model. The experiments with one public dataset and one proprietary dataset demonstrate that our active learning empowered anomaly detection pipeline could achieve performance gain, in terms of F1-score, more than 50% over the baseline algorithm. It also outperforms the existing active learning based methods by approximately 6%-10%, with significantly reduced budget (the ratio of samples to be labeled).