 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Concept Drift Challenge in Multimedia Anomaly Detection: A Case Study with Facial Datasets
Jul 27, 2022
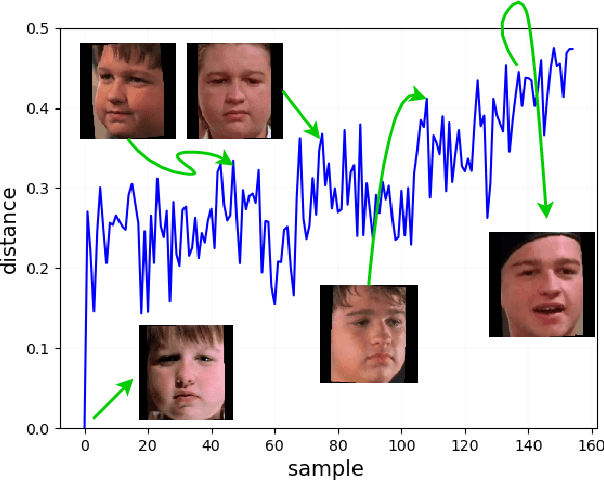
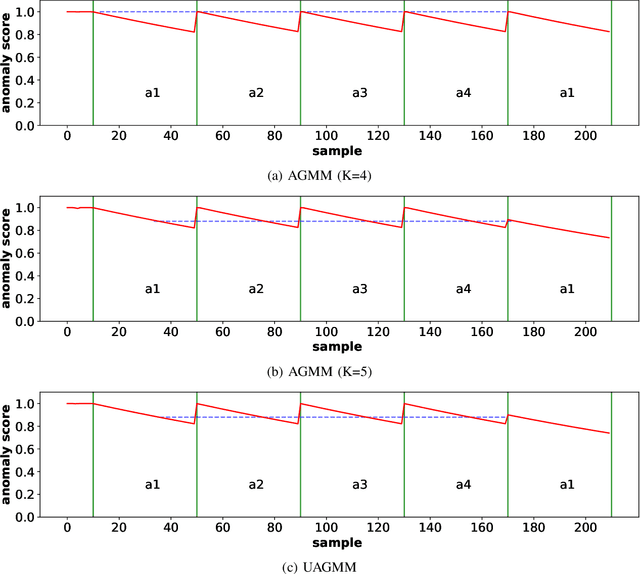
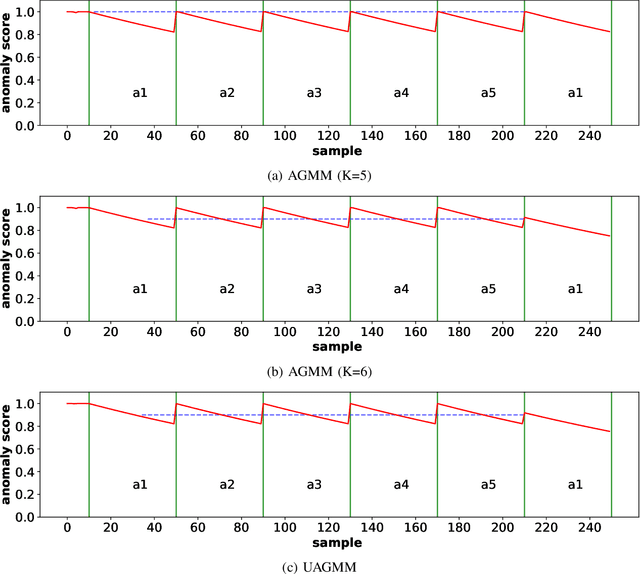
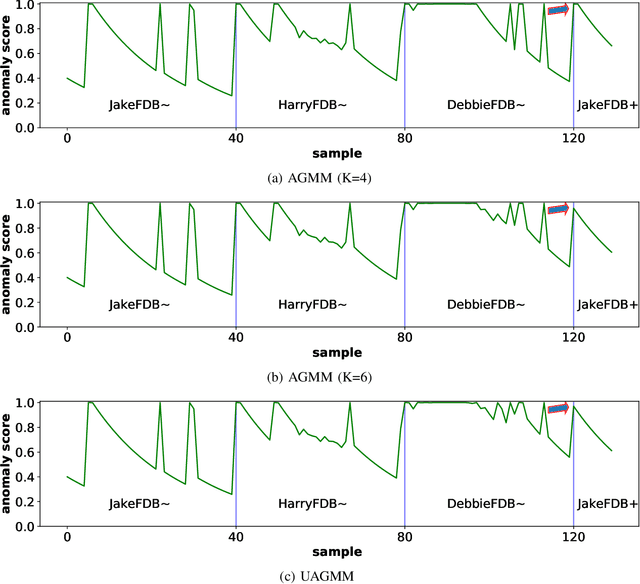
Anomaly detection in multimedia datasets is a widely studied area. Yet, the concept drift challenge in data has been ignored or poorly handled by the majority of the anomaly detection frameworks. The state-of-the-art approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can drift from one class to another in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we systematically investigate the effect of concept drift on various detection models and propose a modified Adaptive Gaussian Mixture Model (AGMM) based framework for anomaly detection in multimedia data. In contrast to the baseline AGMM, the proposed extension of AGMM remembers the past for a longer period in order to handle the drift better. Extensive experimental analysis shows that the proposed model better handles the drift in data as compared with the baseline AGMM. Further, to facilitate research and comparison with the proposed framework, we contribute three multimedia datasets constituting faces as samples. The face samples of individuals correspond to the age difference of more than ten years to incorporate a longer temporal context.
Effective and Efficient Training for Sequential Recommendation using Recency Sampling
Jul 06, 2022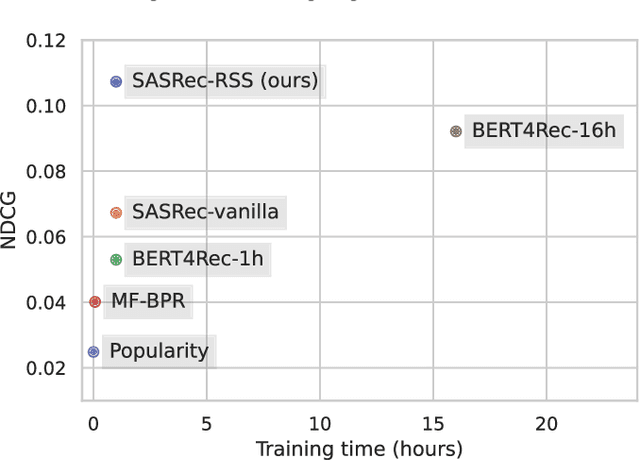
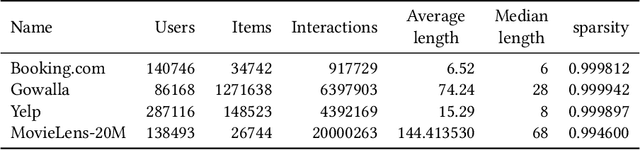

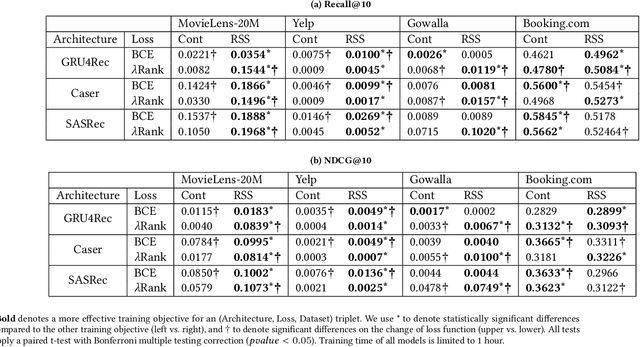
Many modern sequential recommender systems use deep neural networks, which can effectively estimate the relevance of items but require a lot of time to train. Slow training increases expenses, hinders product development timescales and prevents the model from being regularly updated to adapt to changing user preferences. Training such sequential models involves appropriately sampling past user interactions to create a realistic training objective. The existing training objectives have limitations. For instance, next item prediction never uses the beginning of the sequence as a learning target, thereby potentially discarding valuable data. On the other hand, the item masking used by BERT4Rec is only weakly related to the goal of the sequential recommendation; therefore, it requires much more time to obtain an effective model. Hence, we propose a novel Recency-based Sampling of Sequences training objective that addresses both limitations. We apply our method to various recent and state-of-the-art model architectures - such as GRU4Rec, Caser, and SASRec. We show that the models enhanced with our method can achieve performances exceeding or very close to stateof-the-art BERT4Rec, but with much less training time.
A Robust Ensemble Model for Patasitic Egg Detection and Classification
Jul 04, 2022
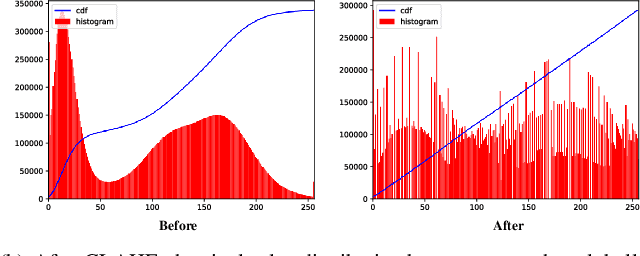
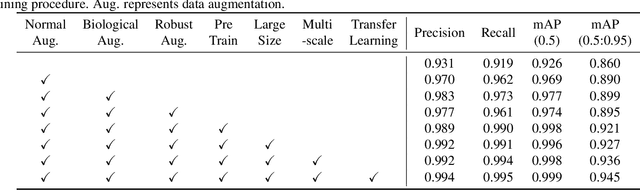
Intestinal parasitic infections, as a leading causes of morbidity worldwide, still lacks time-saving, high-sensitivity and user-friendly examination method. The development of deep learning technique reveals its broad application potential in biological image. In this paper, we apply several object detectors such as YOLOv5 and variant cascadeRCNNs to automatically discriminate parasitic eggs in microscope images. Through specially-designed optimization including raw data augmentation, model ensemble, transfer learning and test time augmentation, our model achieves excellent performance on challenge dataset. In addition, our model trained with added noise gains a high robustness against polluted input, which further broaden its applicability in practice.
Memory-Driven Text-to-Image Generation
Aug 15, 2022
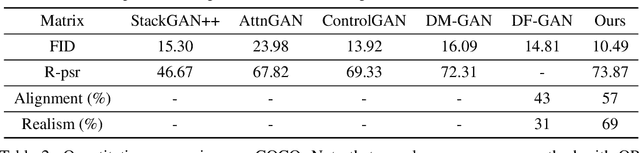

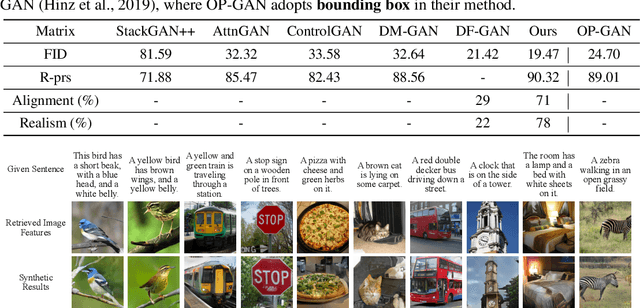
We introduce a memory-driven semi-parametric approach to text-to-image generation, which is based on both parametric and non-parametric techniques. The non-parametric component is a memory bank of image features constructed from a training set of images. The parametric component is a generative adversarial network. Given a new text description at inference time, the memory bank is used to selectively retrieve image features that are provided as basic information of target images, which enables the generator to produce realistic synthetic results. We also incorporate the content information into the discriminator, together with semantic features, allowing the discriminator to make a more reliable prediction. Experimental results demonstrate that the proposed memory-driven semi-parametric approach produces more realistic images than purely parametric approaches, in terms of both visual fidelity and text-image semantic consistency.
Runtime Analysis of the (1+1) EA on Weighted Sums of Transformed Linear Functions
Aug 11, 2022Linear functions play a key role in the runtime analysis of evolutionary algorithms and studies have provided a wide range of new insights and techniques for analyzing evolutionary computation methods. Motivated by studies on separable functions and the optimization behaviour of evolutionary algorithms as well as objective functions from the area of chance constrained optimization, we study the class of objective functions that are weighted sums of two transformed linear functions. Our results show that the (1+1) EA, with a mutation rate depending on the number of overlapping bits of the functions, obtains an optimal solution for these functions in expected time O(n log n), thereby generalizing a well-known result for linear functions to a much wider range of problems.
Randomized K-FACs: Speeding up K-FAC with Randomized Numerical Linear Algebra
Jun 30, 2022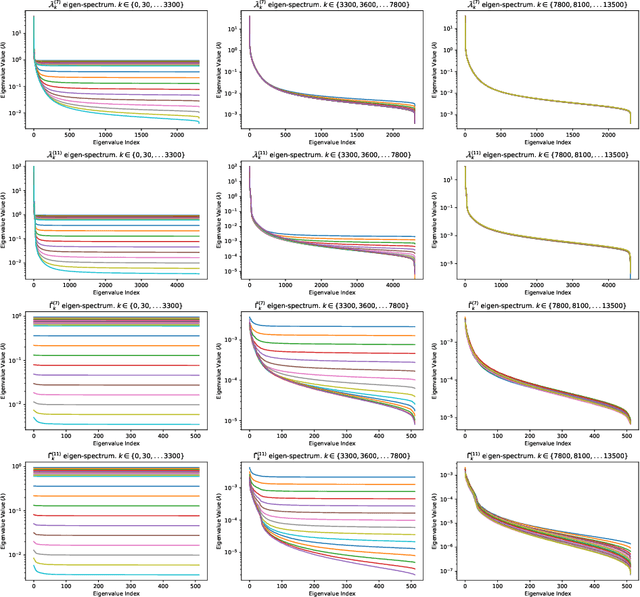

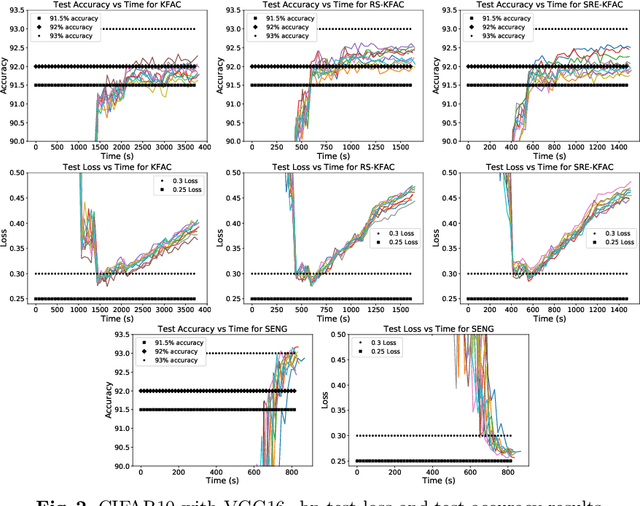
K-FAC is a successful tractable implementation of Natural Gradient for Deep Learning, which nevertheless suffers from the requirement to compute the inverse of the Kronecker factors (through an eigen-decomposition). This can be very time-consuming (or even prohibitive) when these factors are large. In this paper, we theoretically show that, owing to the exponential-average construction paradigm of the Kronecker factors that is typically used, their eigen-spectrum must decay. We show numerically that in practice this decay is very rapid, leading to the idea that we could save substantial computation by only focusing on the first few eigen-modes when inverting the Kronecker-factors. Randomized Numerical Linear Algebra provides us with the necessary tools to do so. Numerical results show we obtain $\approx2.5\times$ reduction in per-epoch time and $\approx3.3\times$ reduction in time to target accuracy. We compare our proposed K-FAC sped-up versions with a more computationally efficient NG implementation, SENG, and observe we perform on par with it.
Microstructure estimation from diffusion-MRI: Compartmentalized models in permeable cellular tissue
Sep 06, 2022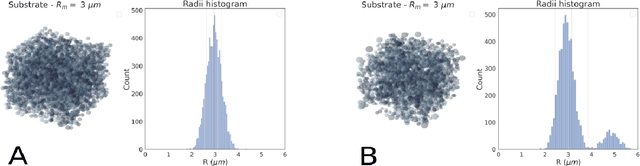

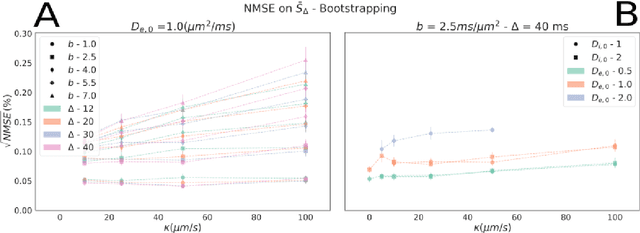

Diffusion-weighted magnetic resonance imaging (DW-MRI) is used to characterize brain tissue microstructure employing tissue-specific biophysical models. A current limitation, however, is that most of the proposed models are based on the assumption of negligible water exchange between the intra- and extracellular compartments, which might not be valid in various brain tissues, including unmyelinated axons, gray matter, and tumors. The purpose of this work is to quantify the effect of membrane permeability on the estimates of two popular models neglecting exchange, and compare their performance with a model including exchange. To this aim, DW-MRI experiments were performed in controlled environments with Monte-Carlo simulations. The DW-MRI signals were generated in numerical substrates mimicking biological tissue made of spherical cells with permeable membranes like cancerous tissue or the brain gray matter. From these signals, the substrates properties were estimated using SANDI and VERDICT, the two compartment-based models neglecting exchange, and CEXI, a new model which includes exchange. Our results show that, in cellular permeable tissue, the model with exchange outperformed models without exchange in the estimation of the tissue properties by providing more stable estimates of cell size, intracellular volume fraction and extracellular diffusion coefficient. Moreover, the model with exchange estimated accurately the exchange time in the range of permeability reported for cellular tissue. Finally, the simulations performed in this work showed that the exchange between the intracellular and the extracellular space cannot be neglected in permeable tissue with a conventional PGSE sequence, to obtain accurate estimates. Consequently, existing compartmentalized models of impermeable tissue cannot be used for microstructure estimation of cellular permeable tissue.
Improving spatial cues for hearables using a parameterized binaural CDR estimator
Jul 17, 2022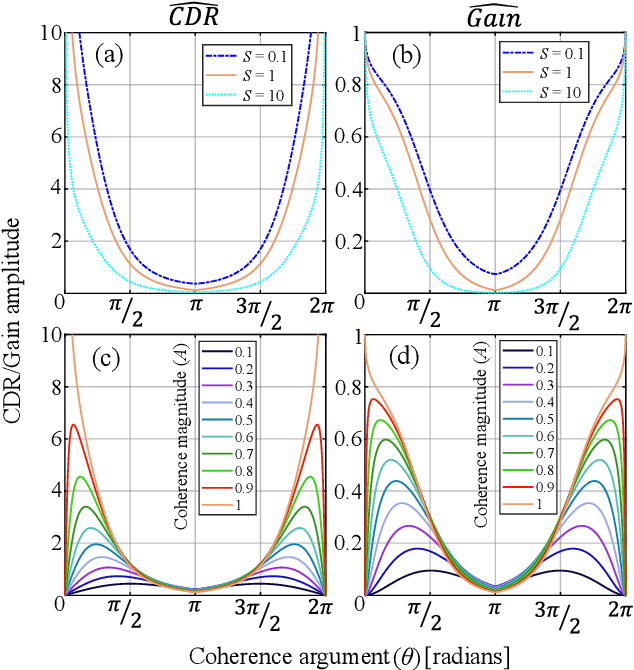
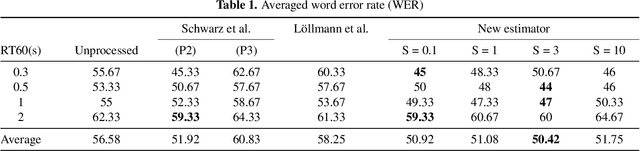
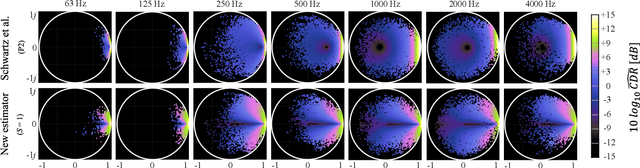
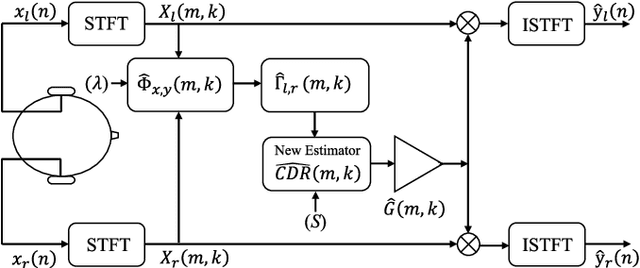
We investigate a speech enhancement method based on the binaural coherence-to-diffuse power ratio (CDR), which preserves auditory spatial cues for maskers and a broadside target. Conventional CDR estimators typically rely on a mathematical coherence model of the desired signal and/or diffuse noise field in their formulation, which may influence their accuracy in natural environments. This work proposes a new robust and parameterized directional binaural CDR estimator. The estimator is calculated in the time-frequency domain and is based on a geometrical interpretation of the spatial coherence function between the binaural microphone signals. The binaural performance of the new CDR estimator is compared with three state-of-the-art CDR estimators in cocktail-party-like environments and has shown improvements in terms of several objective speech quality metrics such as PESQ and SRMR. We also discuss the benefits of the parameterizable CDR estimator for varying sound environments and briefly reflect on several informal subjective evaluations using a low-latency real-time framework.
Multilayer deep feature extraction for visual texture recognition
Aug 22, 2022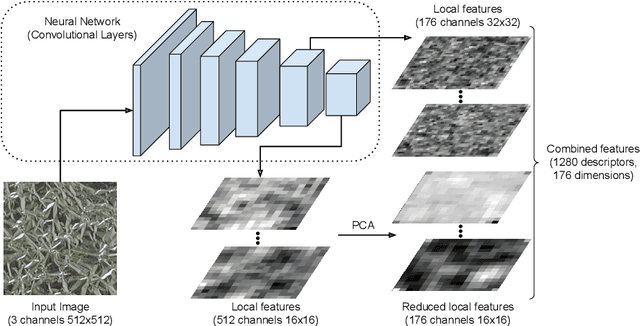
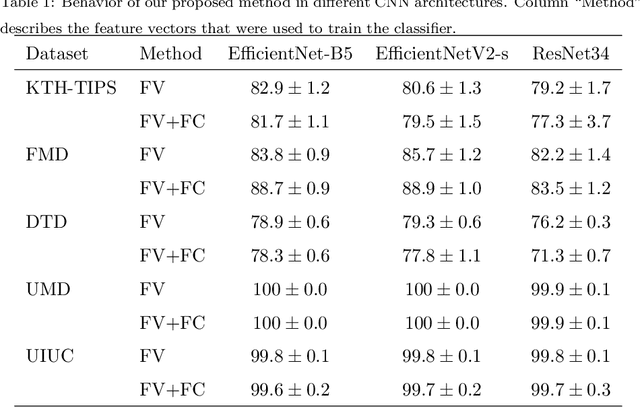
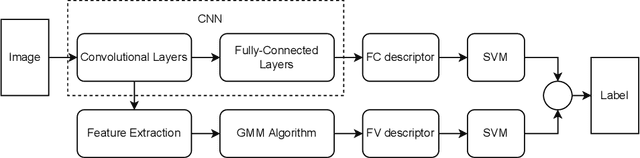
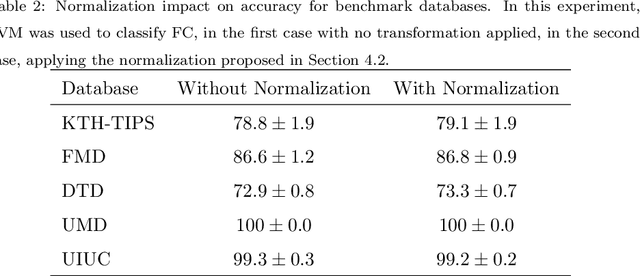
Convolutional neural networks have shown successful results in image classification achieving real-time results superior to the human level. However, texture images still pose some challenge to these models due, for example, to the limited availability of data for training in several problems where these images appear, high inter-class similarity, the absence of a global viewpoint of the object represented, and others. In this context, the present paper is focused on improving the accuracy of convolutional neural networks in texture classification. This is done by extracting features from multiple convolutional layers of a pretrained neural network and aggregating such features using Fisher vector. The reason for using features from earlier convolutional layers is obtaining information that is less domain specific. We verify the effectiveness of our method on texture classification of benchmark datasets, as well as on a practical task of Brazilian plant species identification. In both scenarios, Fisher vectors calculated on multiple layers outperform state-of-art methods, confirming that early convolutional layers provide important information about the texture image for classification.
Application of Convolutional Neural Networks with Quasi-Reversibility Method Results for Option Forecasting
Aug 25, 2022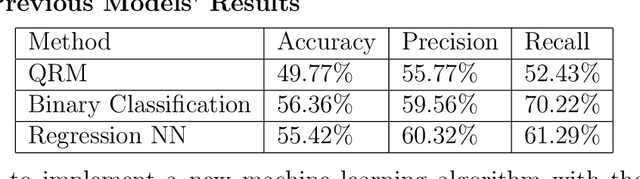
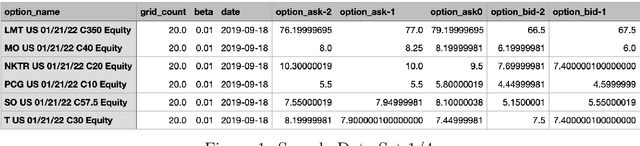
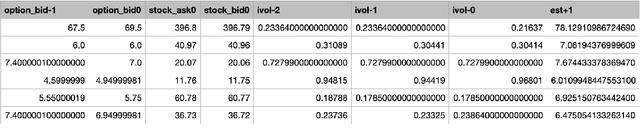
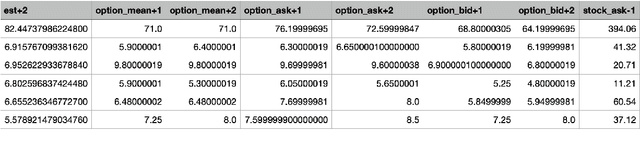
This paper presents a novel way to apply mathematical finance and machine learning (ML) to forecast stock options prices. Following results from the paper Quasi-Reversibility Method and Neural Network Machine Learning to Solution of Black-Scholes Equations (appeared on the AMS Contemporary Mathematics journal), we create and evaluate new empirical mathematical models for the Black-Scholes equation to analyze data for 92,846 companies. We solve the Black-Scholes (BS) equation forwards in time as an ill-posed inverse problem, using the Quasi-Reversibility Method (QRM), to predict option price for the future one day. For each company, we have 13 elements including stock and option daily prices, volatility, minimizer, etc. Because the market is so complicated that there exists no perfect model, we apply ML to train algorithms to make the best prediction. The current stage of research combines QRM with Convolutional Neural Networks (CNN), which learn information across a large number of data points simultaneously. We implement CNN to generate new results by validating and testing on sample market data. We test different ways of applying CNN and compare our CNN models with previous models to see if achieving a higher profit rate is possible.