 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic Interactive Learning for Text Classification: A Constructive Approach for Contextual Interactions
Sep 07, 2022
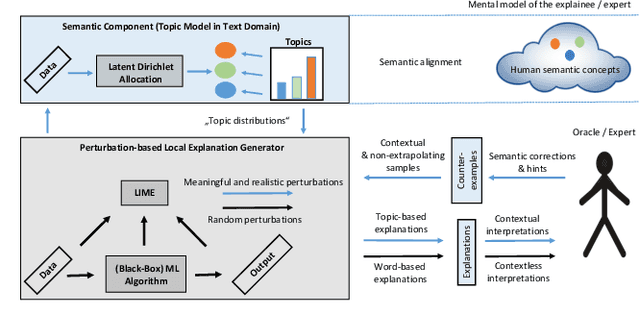
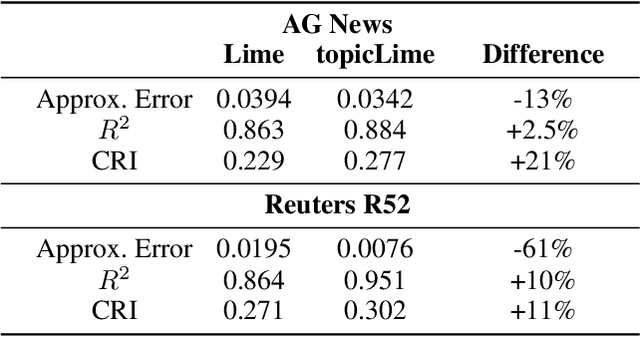
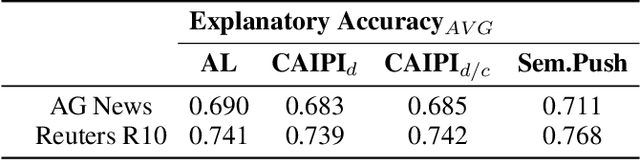
Interactive Machine Learning (IML) shall enable intelligent systems to interactively learn from their end-users, and is quickly becoming more and more important. Although it puts the human in the loop, interactions are mostly performed via mutual explanations that miss contextual information. Furthermore, current model-agnostic IML strategies like CAIPI are limited to 'destructive' feedback, meaning they solely allow an expert to prevent a learner from using irrelevant features. In this work, we propose a novel interaction framework called Semantic Interactive Learning for the text domain. We frame the problem of incorporating constructive and contextual feedback into the learner as a task to find an architecture that (a) enables more semantic alignment between humans and machines and (b) at the same time helps to maintain statistical characteristics of the input domain when generating user-defined counterexamples based on meaningful corrections. Therefore, we introduce a technique called SemanticPush that is effective for translating conceptual corrections of humans to non-extrapolating training examples such that the learner's reasoning is pushed towards the desired behavior. In several experiments, we show that our method clearly outperforms CAIPI, a state of the art IML strategy, in terms of Predictive Performance as well as Local Explanation Quality in downstream multi-class classification tasks.
Real-time Emotion and Gender Classification using Ensemble CNN
Nov 15, 2021

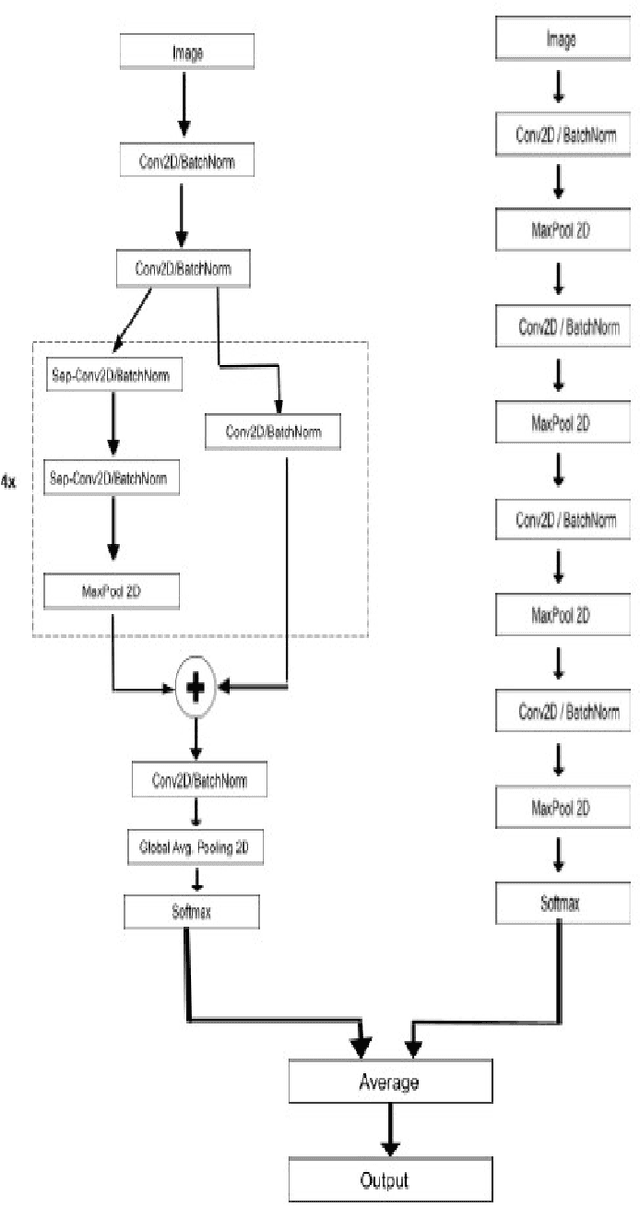
Analysing expressions on the person's face plays a very vital role in identifying emotions and behavior of a person. Recognizing these expressions automatically results in a crucial component of natural human-machine interfaces. Therefore research in this field has a wide range of applications in bio-metric authentication, surveillance systems , emotion to emoticons in various social media platforms. Another application includes conducting customer satisfaction surveys. As we know that the large corporations made huge investments to get feedback and do surveys but fail to get equitable responses. Emotion & Gender recognition through facial gestures is a technology that aims to improve product and services performance by monitoring customer behavior to specific products or service staff by their evaluation. In the past few years there have been a wide variety of advances performed in terms of feature extraction mechanisms , detection of face and also expression classification techniques. This paper is the implementation of an Ensemble CNN for building a real-time system that can detect emotion and gender of the person. The experimental results shows accuracy of 68% for Emotion classification into 7 classes (angry, fear , sad , happy , surprise , neutral , disgust) on FER-2013 dataset and 95% for Gender classification (Male or Female) on IMDB dataset. Our work can predict emotion and gender on single face images as well as multiple face images. Also when input is given through webcam our complete pipeline of this real-time system can take less than 0.5 seconds to generate results.
Object Goal Navigation using Data Regularized Q-Learning
Aug 27, 2022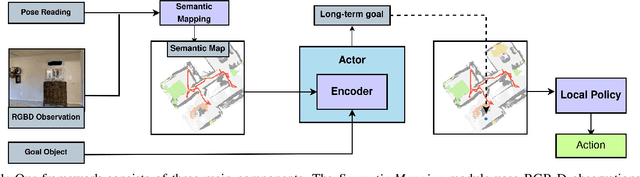
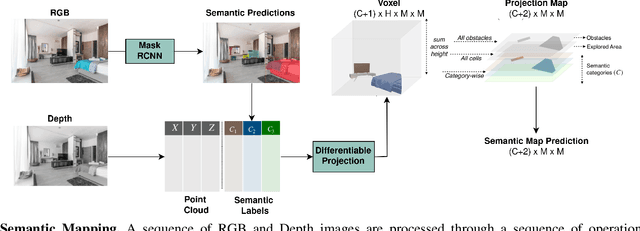
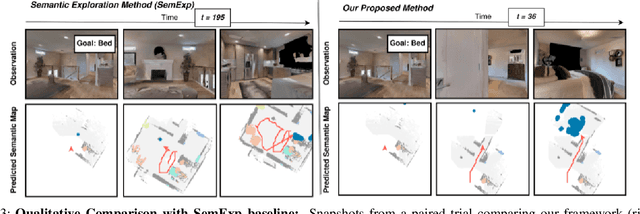

Object Goal Navigation requires a robot to find and navigate to an instance of a target object class in a previously unseen environment. Our framework incrementally builds a semantic map of the environment over time, and then repeatedly selects a long-term goal ('where to go') based on the semantic map to locate the target object instance. Long-term goal selection is formulated as a vision-based deep reinforcement learning problem. Specifically, an Encoder Network is trained to extract high-level features from a semantic map and select a long-term goal. In addition, we incorporate data augmentation and Q-function regularization to make the long-term goal selection more effective. We report experimental results using the photo-realistic Gibson benchmark dataset in the AI Habitat 3D simulation environment to demonstrate substantial performance improvement on standard measures in comparison with a state of the art data-driven baseline.
Anytime-Lidar: Deadline-aware 3D Object Detection
Aug 25, 2022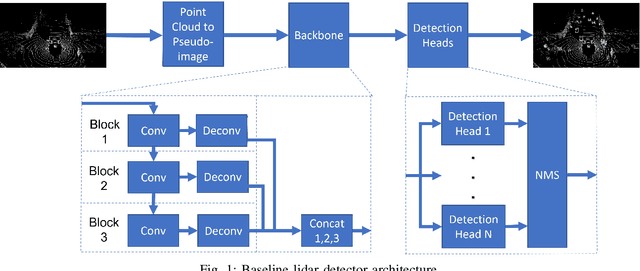
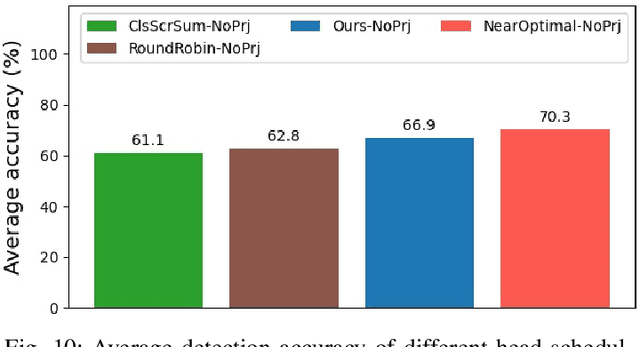
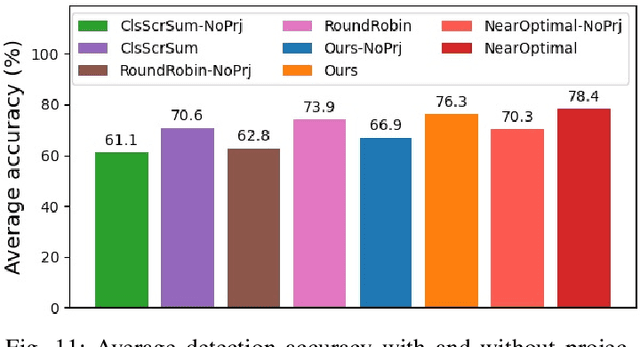
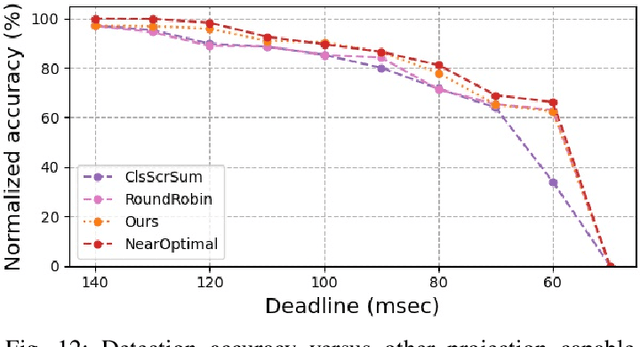
In this work, we present a novel scheduling framework enabling anytime perception for deep neural network (DNN) based 3D object detection pipelines. We focus on computationally expensive region proposal network (RPN) and per-category multi-head detector components, which are common in 3D object detection pipelines, and make them deadline-aware. We propose a scheduling algorithm, which intelligently selects the subset of the components to make effective time and accuracy trade-off on the fly. We minimize accuracy loss of skipping some of the neural network sub-components by projecting previously detected objects onto the current scene through estimations. We apply our approach to a state-of-art 3D object detection network, PointPillars, and evaluate its performance on Jetson Xavier AGX using nuScenes dataset. Compared to the baselines, our approach significantly improve the network's accuracy under various deadline constraints.
Progressive Cross-modal Knowledge Distillation for Human Action Recognition
Aug 17, 2022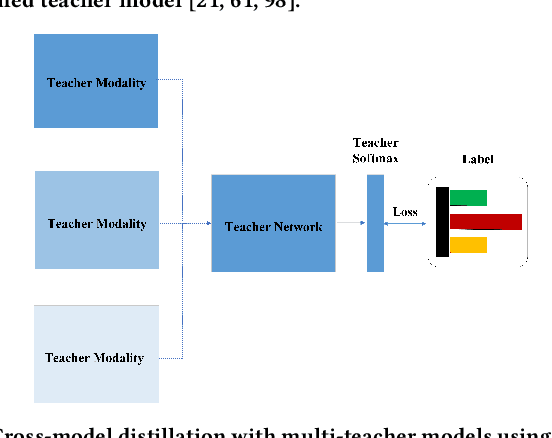
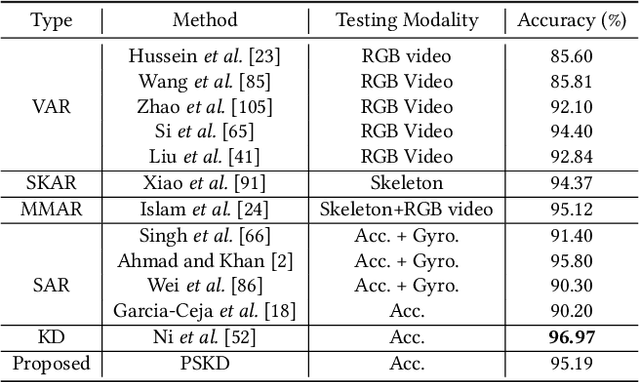
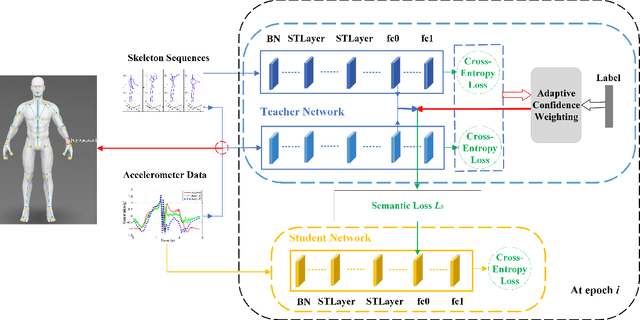
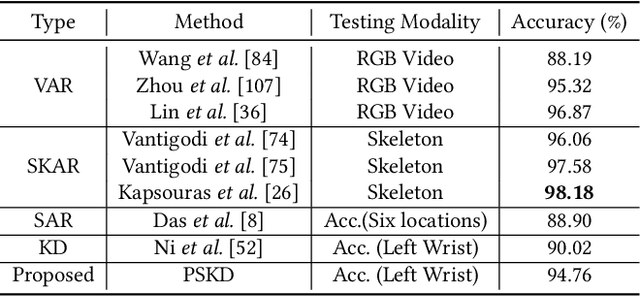
Wearable sensor-based Human Action Recognition (HAR) has achieved remarkable success recently. However, the accuracy performance of wearable sensor-based HAR is still far behind the ones from the visual modalities-based system (i.e., RGB video, skeleton, and depth). Diverse input modalities can provide complementary cues and thus improve the accuracy performance of HAR, but how to take advantage of multi-modal data on wearable sensor-based HAR has rarely been explored. Currently, wearable devices, i.e., smartwatches, can only capture limited kinds of non-visual modality data. This hinders the multi-modal HAR association as it is unable to simultaneously use both visual and non-visual modality data. Another major challenge lies in how to efficiently utilize multimodal data on wearable devices with their limited computation resources. In this work, we propose a novel Progressive Skeleton-to-sensor Knowledge Distillation (PSKD) model which utilizes only time-series data, i.e., accelerometer data, from a smartwatch for solving the wearable sensor-based HAR problem. Specifically, we construct multiple teacher models using data from both teacher (human skeleton sequence) and student (time-series accelerometer data) modalities. In addition, we propose an effective progressive learning scheme to eliminate the performance gap between teacher and student models. We also designed a novel loss function called Adaptive-Confidence Semantic (ACS), to allow the student model to adaptively select either one of the teacher models or the ground-truth label it needs to mimic. To demonstrate the effectiveness of our proposed PSKD method, we conduct extensive experiments on Berkeley-MHAD, UTD-MHAD, and MMAct datasets. The results confirm that the proposed PSKD method has competitive performance compared to the previous mono sensor-based HAR methods.
HW-Aware Initialization of DNN Auto-Tuning to Improve Exploration Time and Robustness
May 31, 2022
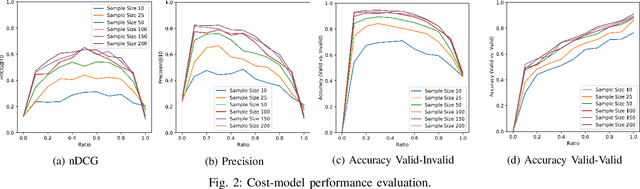
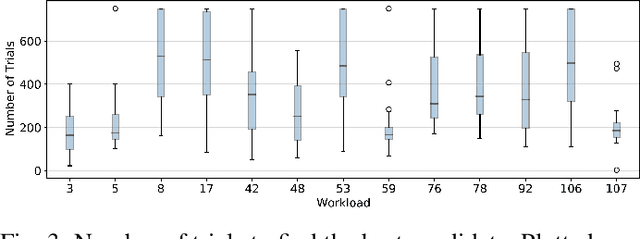
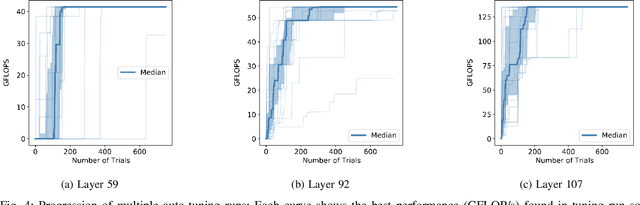
The process of optimizing the latency of DNN operators with ML models and hardware-in-the-loop, called auto-tuning, has established itself as a pervasive method for the deployment of neural networks. From a search space of loop-optimizations, the candidate providing the best performance has to be selected. Performance of individual configurations is evaluated through hardware measurements. The combinatorial explosion of possible configurations, together with the cost of hardware evaluation makes exhaustive explorations of the search space infeasible in practice. Machine Learning methods, like random forests or reinforcement learning are used to aid in the selection of candidates for hardware evaluation. For general purpose hardware like x86 and GPGPU architectures impressive performance gains can be achieved, compared to hand-optimized libraries like cuDNN. The method is also useful in the space of hardware accelerators with less wide-spread adoption, where a high-performance library is not always available. However, hardware accelerators are often less flexible with respect to their programming which leads to operator configurations not executable on the hardware target. This work evaluates how these invalid configurations affect the auto-tuning process and its underlying performance prediction model for the VTA hardware. From these results, a validity-driven initialization method for AutoTVM is developed, only requiring 41.6% of the necessary hardware measurements to find the best solution, while improving search robustness.
Responsible AI Pattern Catalogue: a Multivocal Literature Review
Sep 12, 2022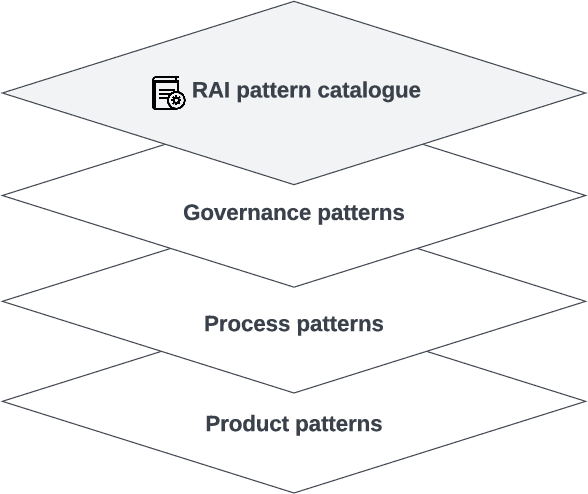

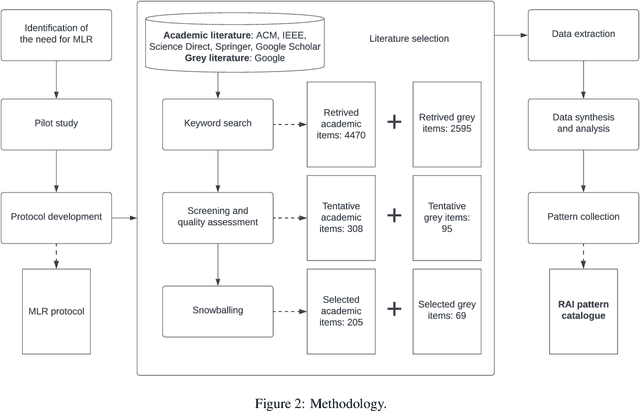
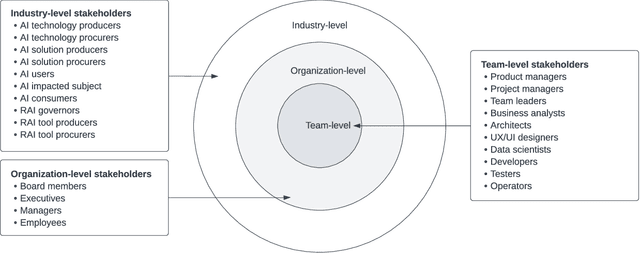
Responsible AI has been widely considered as one of the greatest scientific challenges of our time and the key to unlock the AI market and increase the adoption. To address the responsible AI challenge, a number of AI ethics principles frameworks have been published recently, which AI systems are supposed to conform to. However, without further best practice guidance, practitioners are left with nothing much beyond truisms. Also, significant efforts have been placed at algorithm-level rather than system-level, mainly focusing on a subset of mathematics-amenable ethical principles (such as privacy and fairness). Nevertheless, ethical issues can occur at any step of the development lifecycle crosscutting many AI, non-AI and data components of systems beyond AI algorithms and models. To operationalize responsible AI from a system perspective, in this paper, we adopt a pattern-oriented approach and present a Responsible AI Pattern Catalogue based on the results of a systematic Multivocal Literature Review (MLR). Rather than staying at the ethical principle level or algorithm level, we focus on patterns that AI system stakeholders can undertake in practice to ensure that the developed AI systems are responsible throughout the entire governance and engineering lifecycle. The Responsible AI Pattern Catalogue classifies patterns into three groups: multi-level governance patterns, trustworthy process patterns, and responsible-AI-by-design product patterns. These patterns provide a systematic and actionable guidance for stakeholders to implement responsible AI.
Toward Data-Driven Radar STAP
Sep 07, 2022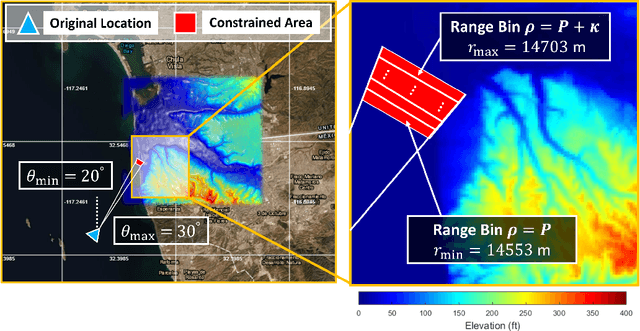
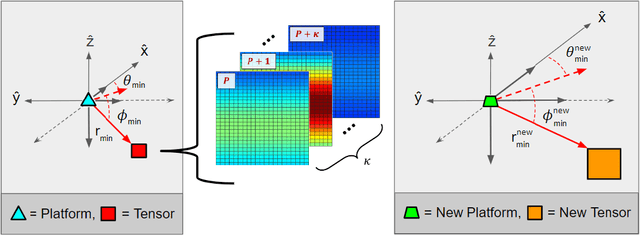
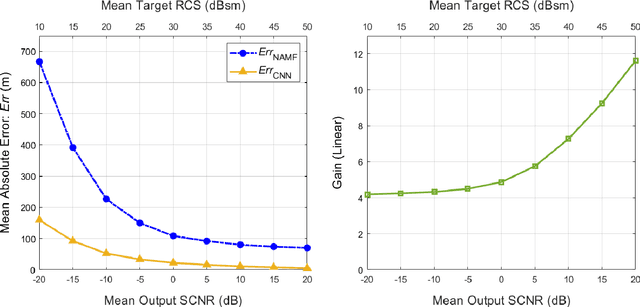
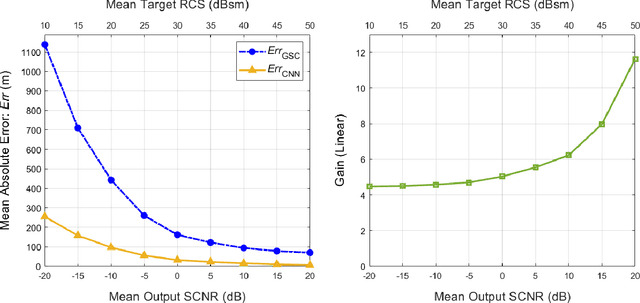
Catalyzed by the recent emergence of site-specific, high-fidelity radio frequency (RF) modeling and simulation tools purposed for radar, data-driven formulations of classical methods in radar have rapidly grown in popularity over the past decade. Despite this surge, limited focus has been directed toward the theoretical foundations of these classical methods. In this regard, as part of our ongoing data-driven approach to radar space-time adaptive processing (STAP), we analyze the asymptotic performance guarantees of select subspace separation methods in the context of radar target localization, and augment this analysis through a proposed deep learning framework for target location estimation. In our approach, we generate comprehensive datasets by randomly placing targets of variable strengths in predetermined constrained areas using RFView, a site-specific RF modeling and simulation tool developed by ISL Inc. For each radar return signal from these constrained areas, we generate heatmap tensors in range, azimuth, and elevation of the normalized adaptive matched filter (NAMF) test statistic, and of the output power of a generalized sidelobe canceller (GSC). Using our deep learning framework, we estimate target locations from these heatmap tensors to demonstrate the feasibility of and significant improvements provided by our data-driven approach in matched and mismatched settings.
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022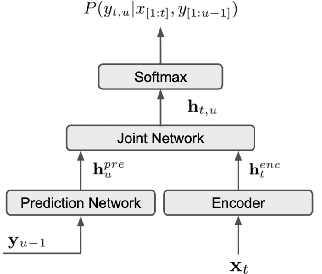
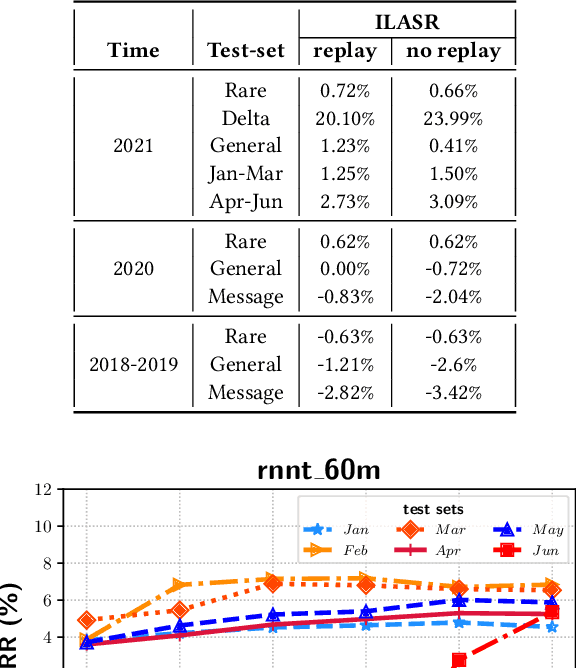
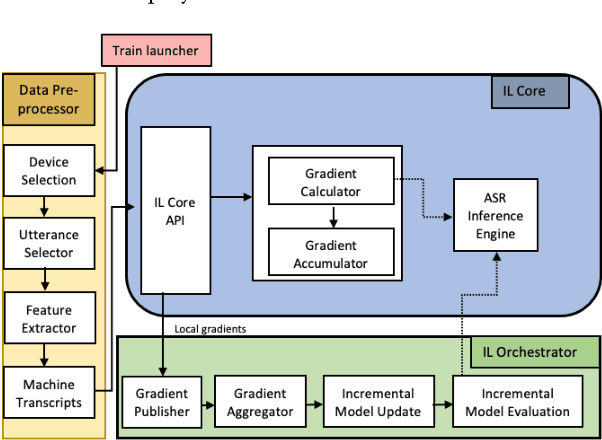
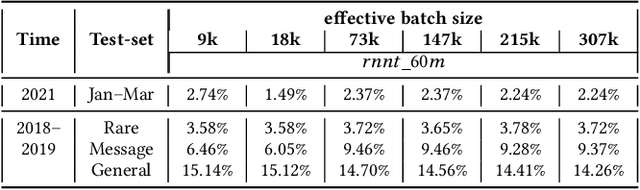
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
A Deep Generative Approach to Oversampling in Ptychography
Jul 28, 2022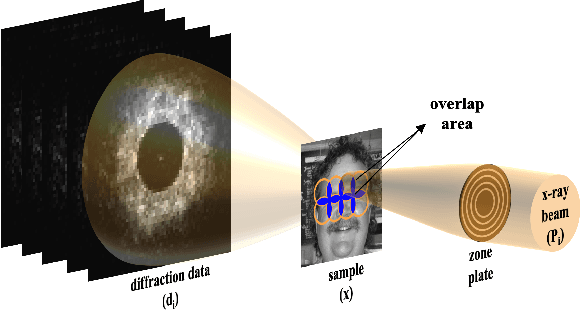

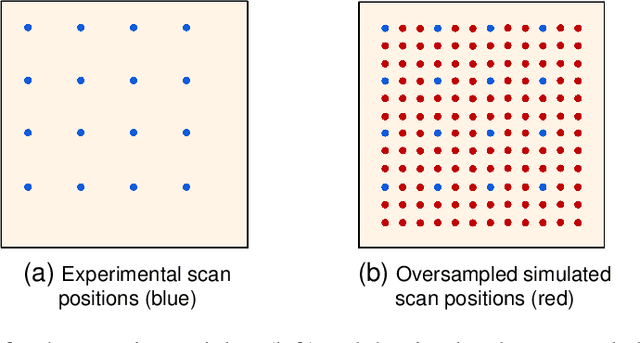

Ptychography is a well-studied phase imaging method that makes non-invasive imaging possible at a nanometer scale. It has developed into a mainstream technique with various applications across a range of areas such as material science or the defense industry. One major drawback of ptychography is the long data acquisition time due to the high overlap requirement between adjacent illumination areas to achieve a reasonable reconstruction. Traditional approaches with reduced overlap between scanning areas result in reconstructions with artifacts. In this paper, we propose complementing sparsely acquired or undersampled data with data sampled from a deep generative network to satisfy the oversampling requirement in ptychography. Because the deep generative network is pre-trained and its output can be computed as we collect data, the experimental data and the time to acquire the data can be reduced. We validate the method by presenting the reconstruction quality compared to the previously proposed and traditional approaches and comment on the strengths and drawbacks of the proposed approach.