 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Variational Mixtures of ODEs for Inferring Cellular Gene Expression Dynamics
Jul 09, 2022
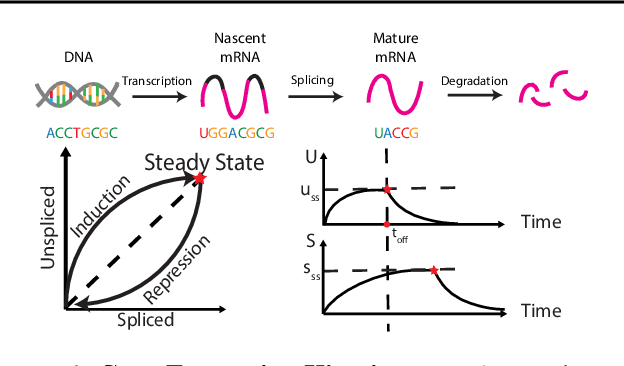
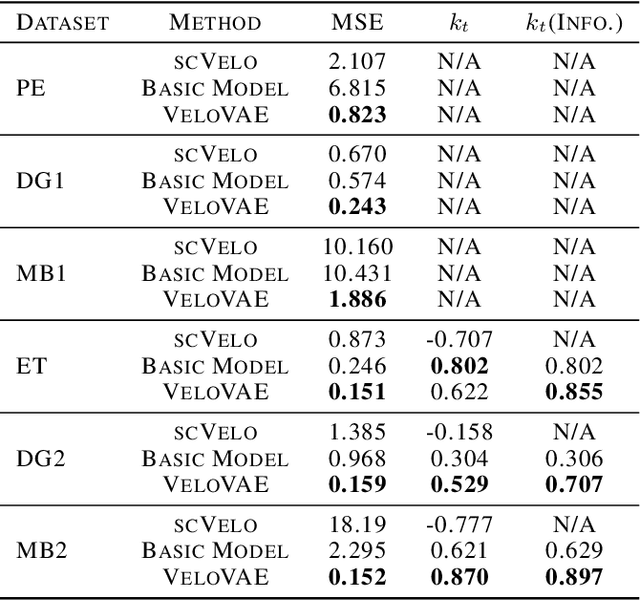
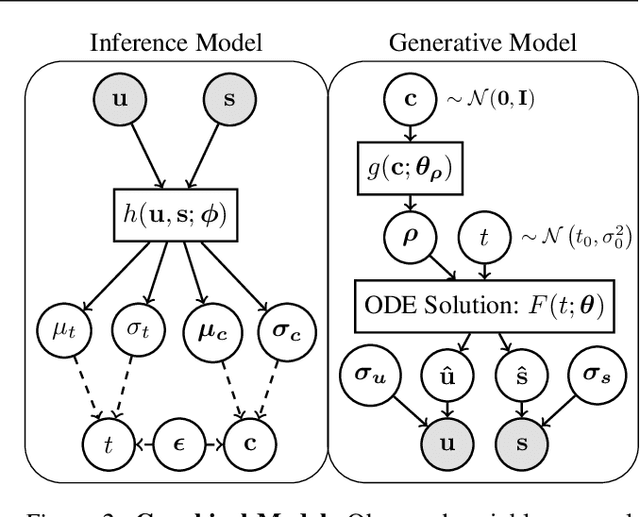

A key problem in computational biology is discovering the gene expression changes that regulate cell fate transitions, in which one cell type turns into another. However, each individual cell cannot be tracked longitudinally, and cells at the same point in real time may be at different stages of the transition process. This can be viewed as a problem of learning the behavior of a dynamical system from observations whose times are unknown. Additionally, a single progenitor cell type often bifurcates into multiple child cell types, further complicating the problem of modeling the dynamics. To address this problem, we developed an approach called variational mixtures of ordinary differential equations. By using a simple family of ODEs informed by the biochemistry of gene expression to constrain the likelihood of a deep generative model, we can simultaneously infer the latent time and latent state of each cell and predict its future gene expression state. The model can be interpreted as a mixture of ODEs whose parameters vary continuously across a latent space of cell states. Our approach dramatically improves data fit, latent time inference, and future cell state estimation of single-cell gene expression data compared to previous approaches.
Online Coreference Resolution for Dialogue Processing: Improving Mention-Linking on Real-Time Conversations
May 21, 2022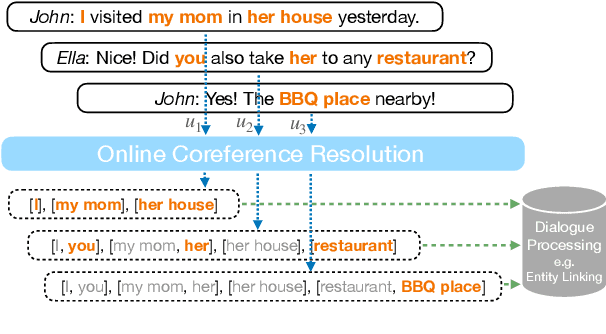
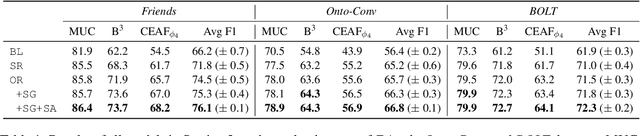
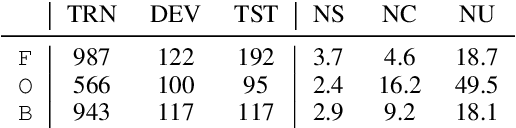
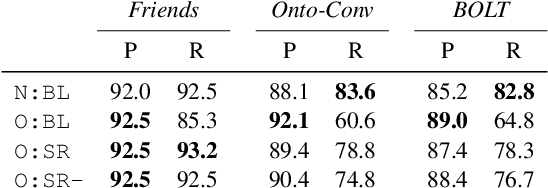
This paper suggests a direction of coreference resolution for online decoding on actively generated input such as dialogue, where the model accepts an utterance and its past context, then finds mentions in the current utterance as well as their referents, upon each dialogue turn. A baseline and four incremental-updated models adapted from the mention-linking paradigm are proposed for this new setting, which address different aspects including the singletons, speaker-grounded encoding and cross-turn mention contextualization. Our approach is assessed on three datasets: Friends, OntoNotes, and BOLT. Results show that each aspect brings out steady improvement, and our best models outperform the baseline by over 10%, presenting an effective system for this setting. Further analysis highlights the task characteristics, such as the significance of addressing the mention recall.
Real-time ground filtering algorithm of cloud points acquired using Terrestrial Laser Scanner (TLS)
Nov 22, 2021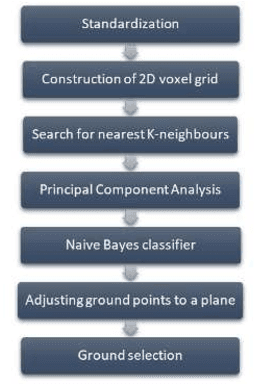
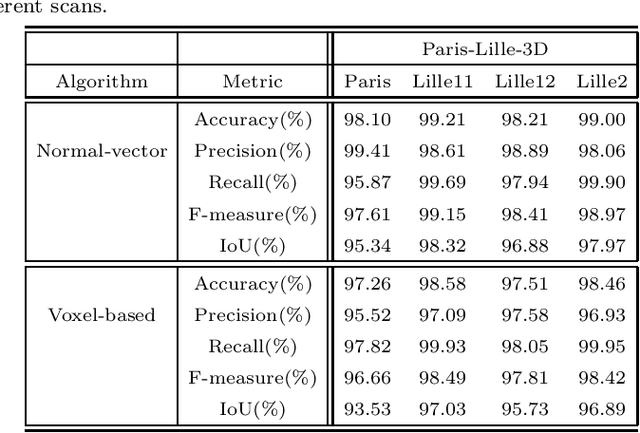
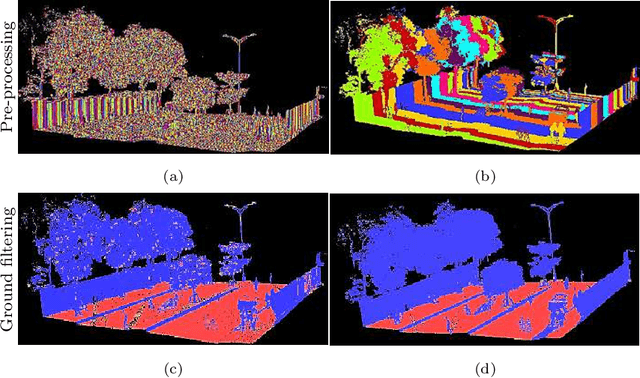
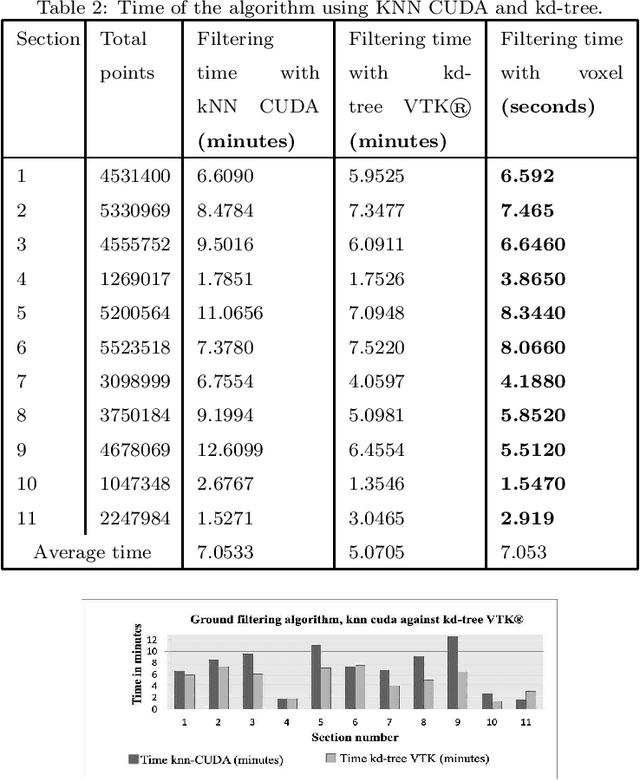
3D modeling based on point clouds requires ground-filtering algorithms that separate ground from non-ground objects. This study presents two ground filtering algorithms. The first one is based on normal vectors. It has two variants depending on the procedure to compute the k-nearest neighbors. The second algorithm is based on transforming the cloud points into a voxel structure. To evaluate them, the two algorithms are compared according to their execution time, effectiveness and efficiency. Results show that the ground filtering algorithm based on the voxel structure is faster in terms of execution time, effectiveness, and efficiency than the normal vector ground filtering.
How important are socioeconomic factors for hurricane performance of power systems? An analysis of disparities through machine learning
Aug 18, 2022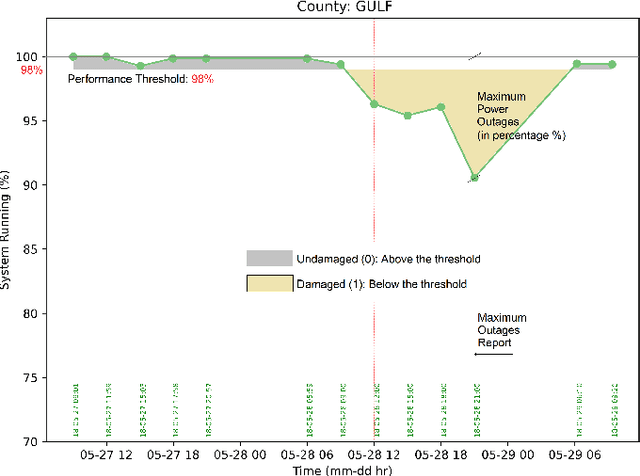
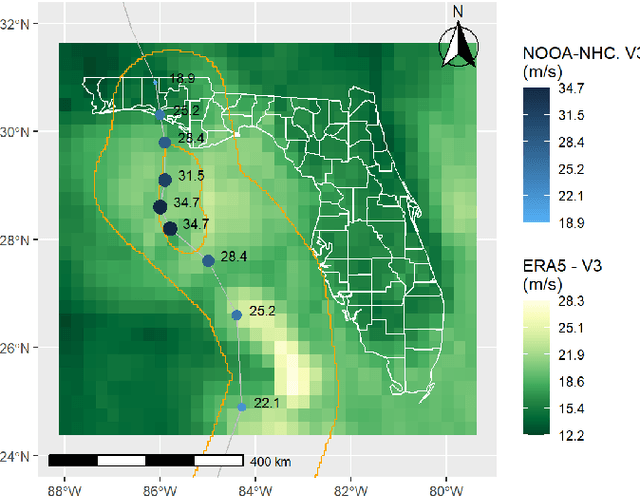
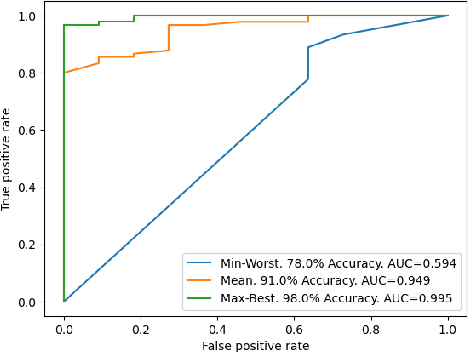
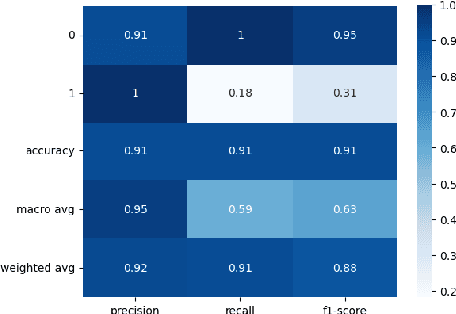
This paper investigates whether socioeconomic factors are important for the hurricane performance of the electric power system in Florida. The investigation is performed using the Random Forest classifier with Mean Decrease of Accuracy (MDA) for measuring the importance of a set of factors that include hazard intensity, time to recovery from maximum impact, and socioeconomic characteristics of the affected population. The data set (at county scale) for this study includes socioeconomic variables from the 5-year American Community Survey (ACS), as well as wind velocities, and outage data of five hurricanes including Alberto and Michael in 2018, Dorian in 2019, and Eta and Isaias in 2020. The study shows that socioeconomic variables are considerably important for the system performance model. This indicates that social disparities may exist in the occurrence of power outages, which directly impact the resilience of communities and thus require immediate attention.
Universality and diversity in word patterns
Aug 23, 2022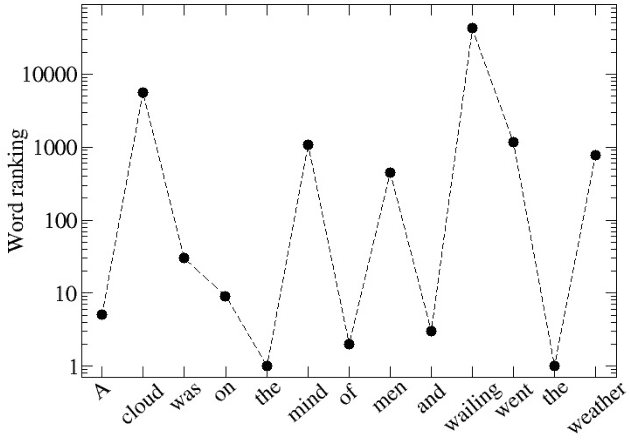
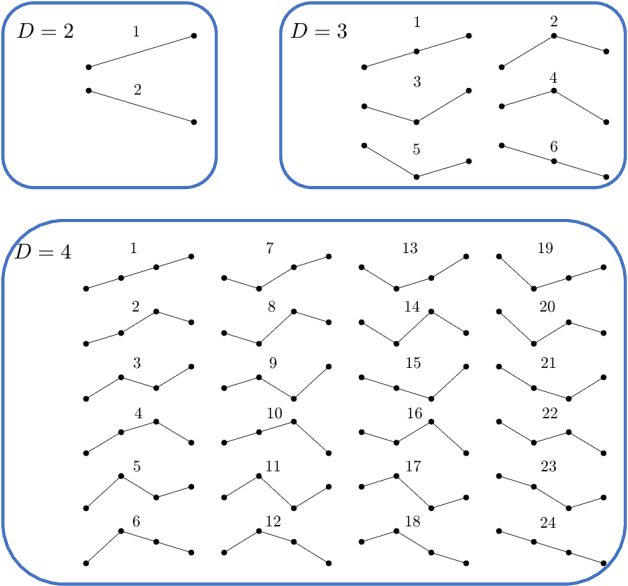
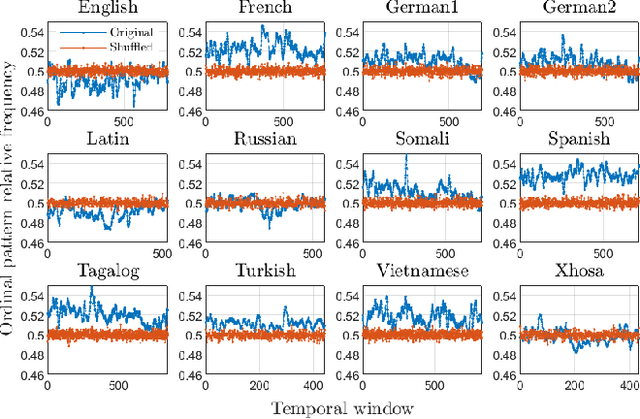
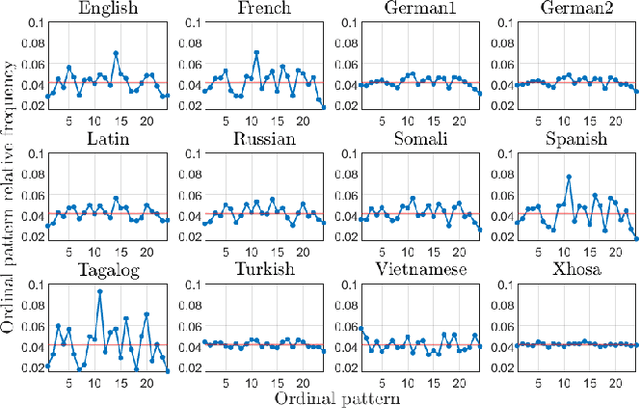
Words are fundamental linguistic units that connect thoughts and things through meaning. However, words do not appear independently in a text sequence. The existence of syntactic rules induce correlations among neighboring words. Further, words are not evenly distributed but approximately follow a power law since terms with a pure semantic content appear much less often than terms that specify grammar relations. Using an ordinal pattern approach, we present an analysis of lexical statistical connections for eleven major languages. We find that the diverse manners that languages utilize to express word relations give rise to unique pattern distributions. Remarkably, we find that these relations can be modeled with a Markov model of order 2 and that this result is universally valid for all the studied languages. Furthermore, fluctuations of the pattern distributions can allow us to determine the historical period when the text was written and its author. Taken together, these results emphasize the relevance of time series analysis and information-theoretic methods for the understanding of statistical correlations in natural languages.
Design of Human Machine Interface through vision-based low-cost Hand Gesture Recognition system based on deep CNN
Jul 11, 2022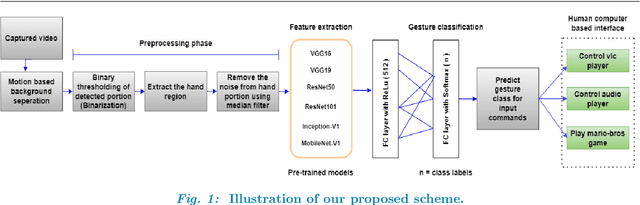
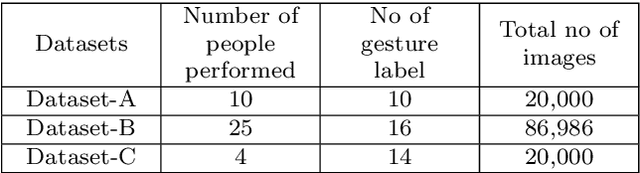

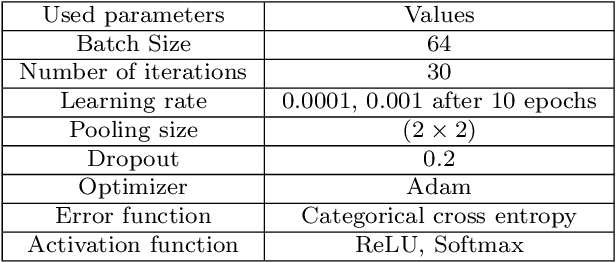
In this work, a real-time hand gesture recognition system-based human-computer interface (HCI) is presented. The system consists of six stages: (1) hand detection, (2) gesture segmentation, (3) use of six pre-trained CNN models by using the transfer-learning method, (4) building an interactive human-machine interface, (5) development of a gesture-controlled virtual mouse, (6) use of Kalman filter to estimate the hand position, based on that the smoothness of the motion of pointer is improved. Six pre-trained convolutional neural network (CNN) models (VGG16, VGG19, ResNet50, ResNet101, Inception-V1, and MobileNet-V1) have been used to classify hand gesture images. Three multi-class datasets (two publicly and one custom) have been used to evaluate the model performances. Considering the models' performances, it has been observed that Inception-V1 has significantly shown a better classification performance compared to the other five pre-trained models in terms of accuracy, precision, recall, and F-score values. The gesture recognition system is expanded and used to control multimedia applications (like VLC player, audio player, file management, playing 2D Super-Mario-Bros game, etc.) with different customized gesture commands in real-time scenarios. The average speed of this system has reached 35 fps (frame per seconds), which meets the requirements for the real-time scenario.
Causal Discovery from Sparse Time-Series Data Using Echo State Network
Jan 09, 2022

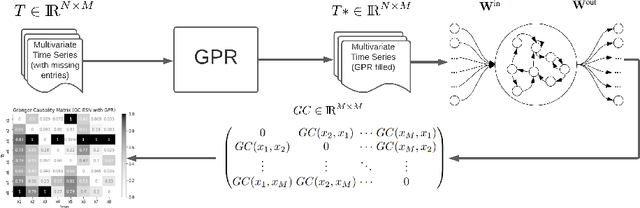
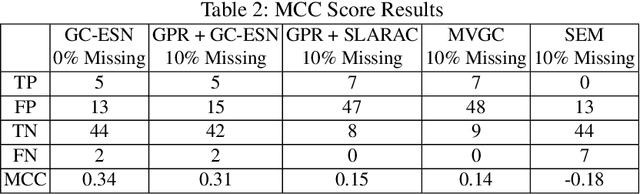
Causal discovery between collections of time-series data can help diagnose causes of symptoms and hopefully prevent faults before they occur. However, reliable causal discovery can be very challenging, especially when the data acquisition rate varies (i.e., non-uniform data sampling), or in the presence of missing data points (e.g., sparse data sampling). To address these issues, we proposed a new system comprised of two parts, the first part fills missing data with a Gaussian Process Regression, and the second part leverages an Echo State Network, which is a type of reservoir computer (i.e., used for chaotic system modeling) for Causal discovery. We evaluate the performance of our proposed system against three other off-the-shelf causal discovery algorithms, namely, structural expectation-maximization, sub-sampled linear auto-regression absolute coefficients, and multivariate Granger Causality with vector auto-regressive using the Tennessee Eastman chemical dataset; we report on their corresponding Matthews Correlation Coefficient(MCC) and Receiver Operating Characteristic curves (ROC) and show that the proposed system outperforms existing algorithms, demonstrating the viability of our approach to discover causal relationships in a complex system with missing entries.
Exploring the Effects of Data Augmentation for Drivable Area Segmentation
Aug 06, 2022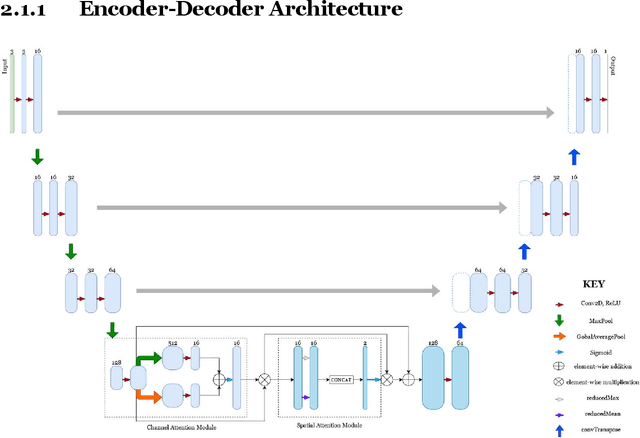
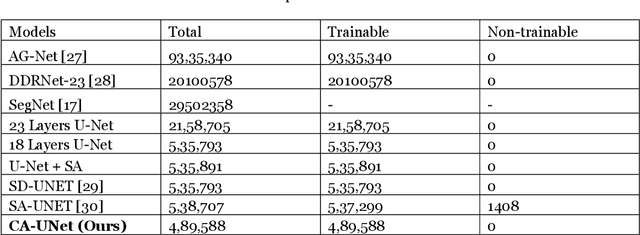
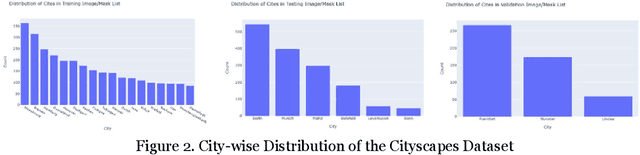
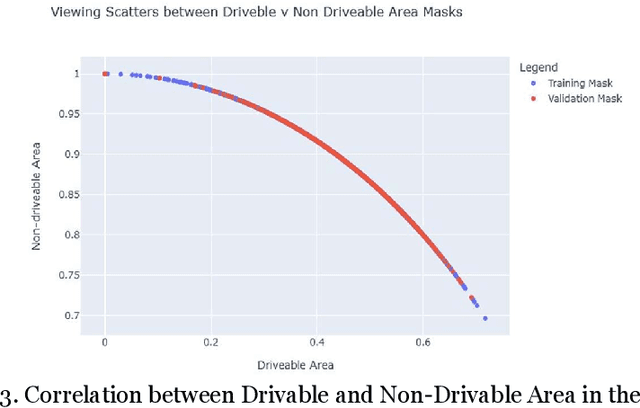
The real-time segmentation of drivable areas plays a vital role in accomplishing autonomous perception in cars. Recently there have been some rapid strides in the development of image segmentation models using deep learning. However, most of the advancements have been made in model architecture design. In solving any supervised deep learning problem related to segmentation, the success of the model that one builds depends upon the amount and quality of input training data we use for that model. This data should contain well-annotated varied images for better working of the segmentation model. Issues like this pertaining to annotations in a dataset can lead the model to conclude with overwhelming Type I and II errors in testing and validation, causing malicious issues when trying to tackle real world problems. To address this problem and to make our model more accurate, dynamic, and robust, data augmentation comes into usage as it helps in expanding our sample training data and making it better and more diversified overall. Hence, in our study, we focus on investigating the benefits of data augmentation by analyzing pre-existing image datasets and performing augmentations accordingly. Our results show that the performance and robustness of existing state of the art (or SOTA) models can be increased dramatically without any increase in model complexity or inference time. The augmentations decided on and used in this paper were decided only after thorough research of several other augmentation methodologies and strategies and their corresponding effects that are in widespread usage today. All our results are being reported on the widely used Cityscapes Dataset.
Visual Analysis of Neural Architecture Spaces for Summarizing Design Principles
Aug 20, 2022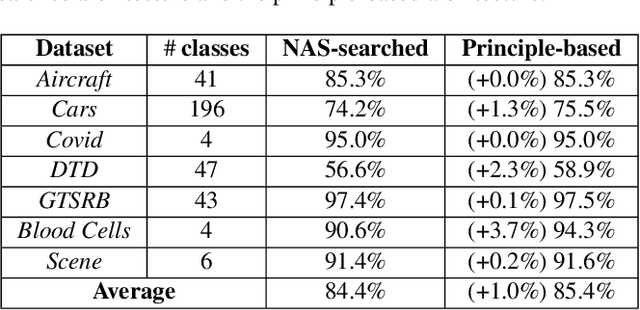
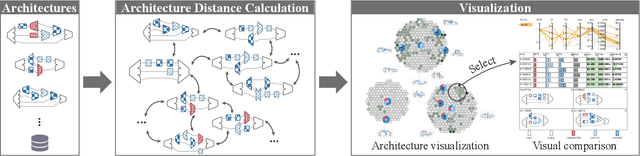
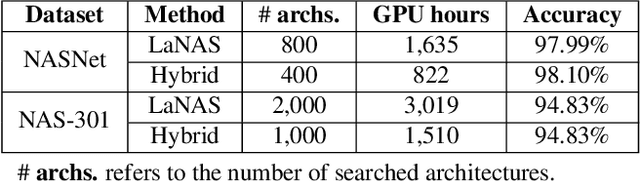
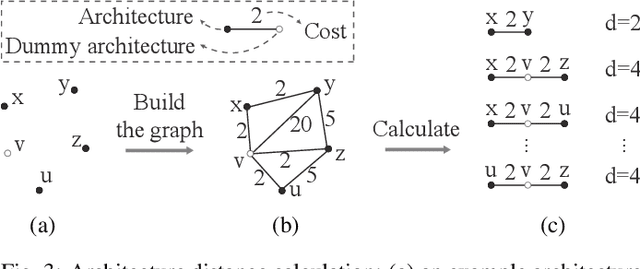
Recent advances in artificial intelligence largely benefit from better neural network architectures. These architectures are a product of a costly process of trial-and-error. To ease this process, we develop ArchExplorer, a visual analysis method for understanding a neural architecture space and summarizing design principles. The key idea behind our method is to make the architecture space explainable by exploiting structural distances between architectures. We formulate the pairwise distance calculation as solving an all-pairs shortest path problem. To improve efficiency, we decompose this problem into a set of single-source shortest path problems. The time complexity is reduced from O(kn^2N) to O(knN). Architectures are hierarchically clustered according to the distances between them. A circle-packing-based architecture visualization has been developed to convey both the global relationships between clusters and local neighborhoods of the architectures in each cluster. Two case studies and a post-analysis are presented to demonstrate the effectiveness of ArchExplorer in summarizing design principles and selecting better-performing architectures.
Deep Learning Closure Models for Large-Eddy Simulation of Flows around Bluff Bodies
Aug 10, 2022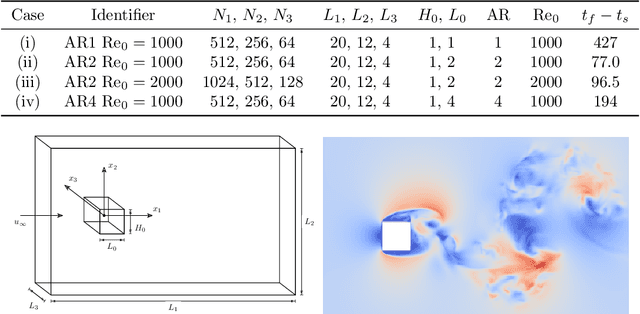
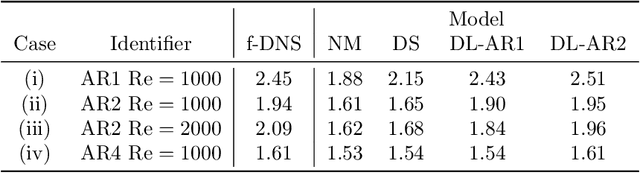
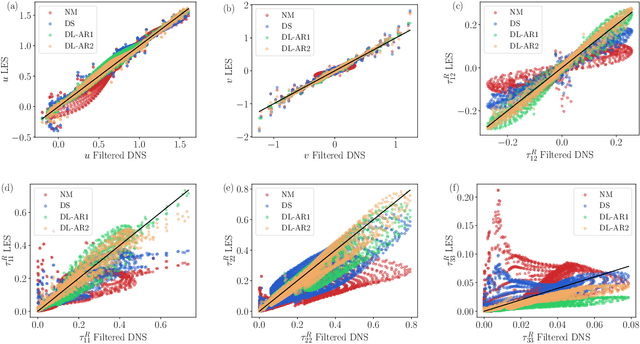
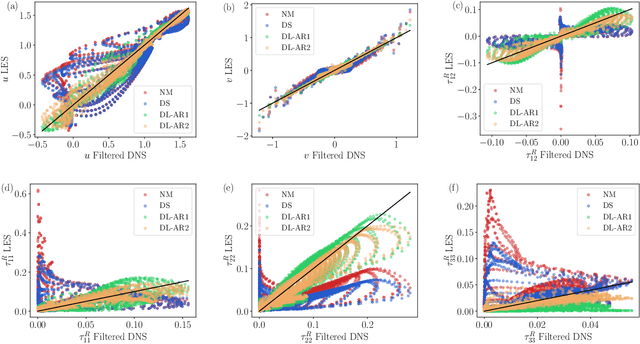
A deep learning (DL) closure model for large-eddy simulation (LES) is developed and evaluated for incompressible flows around a rectangular cylinder at moderate Reynolds numbers. Near-wall flow simulation remains a central challenge in aerodynamic modeling: RANS predictions of separated flows are often inaccurate, while LES can require prohibitively small near-wall mesh sizes. The DL-LES model is trained using adjoint PDE optimization methods to match, as closely as possible, direct numerical simulation (DNS) data. It is then evaluated out-of-sample (i.e., for new aspect ratios and Reynolds numbers not included in the training data) and compared against a standard LES model (the dynamic Smagorinsky model). The DL-LES model outperforms dynamic Smagorinsky and is able to achieve accurate LES predictions on a relatively coarse mesh (downsampled from the DNS grid by a factor of four in each Cartesian direction). We study the accuracy of the DL-LES model for predicting the drag coefficient, mean flow, and Reynolds stress. A crucial challenge is that the LES quantities of interest are the steady-state flow statistics; for example, the time-averaged mean velocity $\bar{u}(x) = \displaystyle \lim_{t \rightarrow \infty} \frac{1}{t} \int_0^t u(s,x) ds$. Calculating the steady-state flow statistics therefore requires simulating the DL-LES equations over a large number of flow times through the domain; it is a non-trivial question whether an unsteady partial differential equation model whose functional form is defined by a deep neural network can remain stable and accurate on $t \in [0, \infty)$. Our results demonstrate that the DL-LES model is accurate and stable over large physical time spans, enabling the estimation of the steady-state statistics for the velocity, fluctuations, and drag coefficient of turbulent flows around bluff bodies relevant to aerodynamic applications.