 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Community-Aware Framework for Social Influence Maximization
Jul 18, 2022
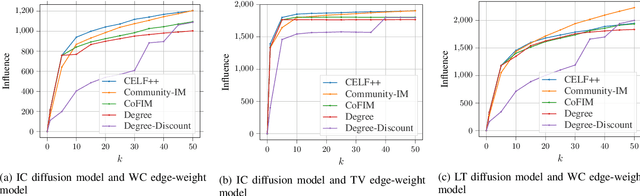
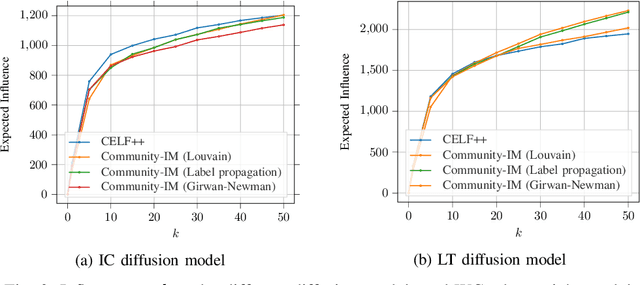
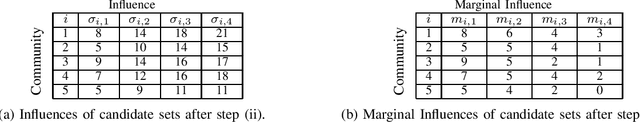
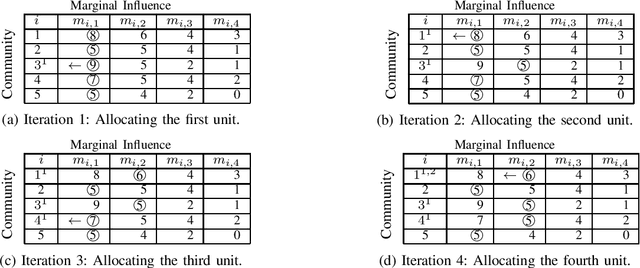
We consider the Influence Maximization (IM) problem: 'if we can try to convince a subset of individuals in a social network to adopt a new product or innovation, and the goal is to trigger a large cascade of further adoptions, which set of individuals should we target'? Formally, it is the task of selecting $k$ seed nodes in a social network such that the expected number of influenced nodes in the network (under some influence propagation model) is maximized. This problem has been widely studied in the literature and several solution approaches have been proposed. However, most simulation-based approaches involve time-consuming Monte-Carlo simulations to compute the influence of the seed nodes in the entire network. This limits the applicability of these methods on large social networks. In the paper, we are interested in solving the problem of influence maximization in a time-efficient manner. We propose a community-aware divide-and-conquer strategy that involves (i) learning the inherent community structure of the social network, (ii) generating candidate solutions by solving the influence maximization problem for each community, and (iii) selecting the final set of individuals from the candidate solutions using a novel progressive budgeting scheme. We provide experiments on real-world social networks, showing that the proposed algorithm outperforms the simulation-based algorithms in terms of empirical run-time and the heuristic algorithms in terms of influence. We also study the effect of the community structure on the performance of our algorithm. Our experiments show that the community structures with higher modularity lead the proposed algorithm to perform better in terms of run-time and influence.
Macroeconomic Predictions using Payments Data and Machine Learning
Sep 02, 2022Predicting the economy's short-term dynamics -- a vital input to economic agents' decision-making process -- often uses lagged indicators in linear models. This is typically sufficient during normal times but could prove inadequate during crisis periods. This paper aims to demonstrate that non-traditional and timely data such as retail and wholesale payments, with the aid of nonlinear machine learning approaches, can provide policymakers with sophisticated models to accurately estimate key macroeconomic indicators in near real-time. Moreover, we provide a set of econometric tools to mitigate overfitting and interpretability challenges in machine learning models to improve their effectiveness for policy use. Our models with payments data, nonlinear methods, and tailored cross-validation approaches help improve macroeconomic nowcasting accuracy up to 40\% -- with higher gains during the COVID-19 period. We observe that the contribution of payments data for economic predictions is small and linear during low and normal growth periods. However, the payments data contribution is large, asymmetrical, and nonlinear during strong negative or positive growth periods.
Optimistic Optimization of Gaussian Process Samples
Sep 02, 2022
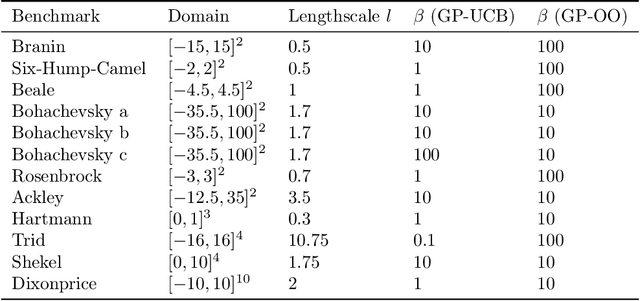
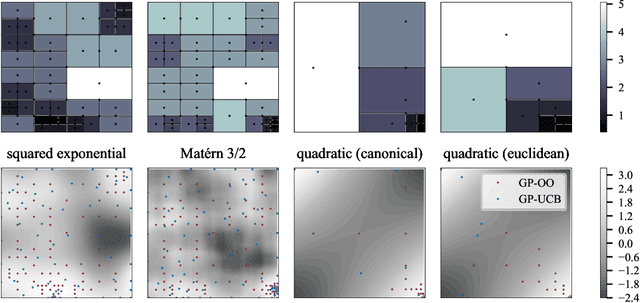
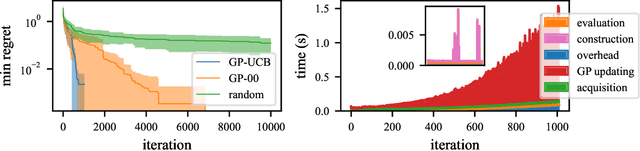
Bayesian optimization is a popular formalism for global optimization, but its computational costs limit it to expensive-to-evaluate functions. A competing, computationally more efficient, global optimization framework is optimistic optimization, which exploits prior knowledge about the geometry of the search space in form of a dissimilarity function. We investigate to which degree the conceptual advantages of Bayesian Optimization can be combined with the computational efficiency of optimistic optimization. By mapping the kernel to a dissimilarity, we obtain an optimistic optimization algorithm for the Bayesian Optimization setting with a run-time of up to $\mathcal{O}(N \log N)$. As a high-level take-away we find that, when using stationary kernels on objectives of relatively low evaluation cost, optimistic optimization can be strongly preferable over Bayesian optimization, while for strongly coupled and parametric models, good implementations of Bayesian optimization can perform much better, even at low evaluation cost. We argue that there is a new research domain between geometric and probabilistic search, i.e. methods that run drastically faster than traditional Bayesian optimization, while retaining some of the crucial functionality of Bayesian optimization.
PrePARE: Predictive Proprioception for Agile Failure Event Detection in Robotic Exploration of Extreme Terrains
Jul 30, 2022
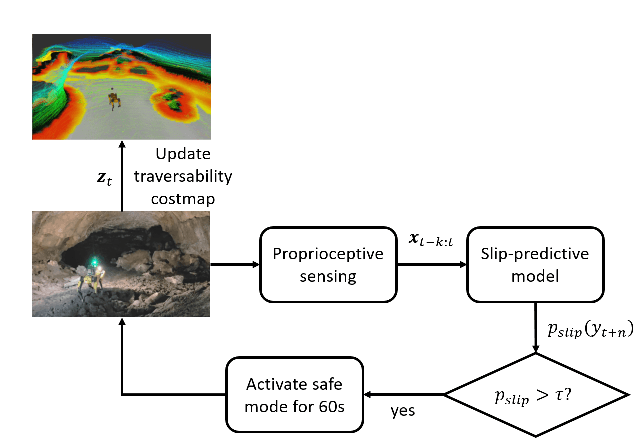

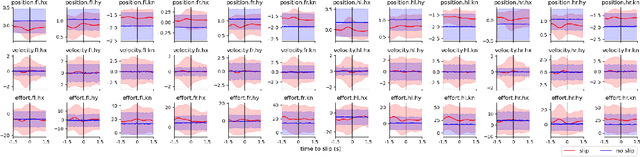
Legged robots can traverse a wide variety of terrains, some of which may be challenging for wheeled robots, such as stairs or highly uneven surfaces. However, quadruped robots face stability challenges on slippery surfaces. This can be resolved by adjusting the robot's locomotion by switching to more conservative and stable locomotion modes, such as crawl mode (where three feet are in contact with the ground always) or amble mode (where one foot touches down at a time) to prevent potential falls. To tackle these challenges, we propose an approach to learn a model from past robot experience for predictive detection of potential failures. Accordingly, we trigger gait switching merely based on proprioceptive sensory information. To learn this predictive model, we propose a semi-supervised process for detecting and annotating ground truth slip events in two stages: We first detect abnormal occurrences in the time series sequences of the gait data using an unsupervised anomaly detector, and then, the anomalies are verified with expert human knowledge in a replay simulation to assert the event of a slip. These annotated slip events are then used as ground truth examples to train an ensemble decision learner for predicting slip probabilities across terrains for traversability. We analyze our model on data recorded by a legged robot on multiple sites with slippery terrain. We demonstrate that a potential slip event can be predicted up to 720 ms ahead of a potential fall with an average precision greater than 0.95 and an average F-score of 0.82. Finally, we validate our approach in real-time by deploying it on a legged robot and switching its gait mode based on slip event detection.
Validation Methods for Energy Time Series Scenarios from Deep Generative Models
Oct 27, 2021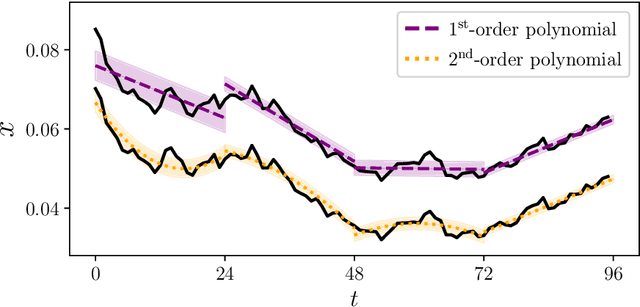
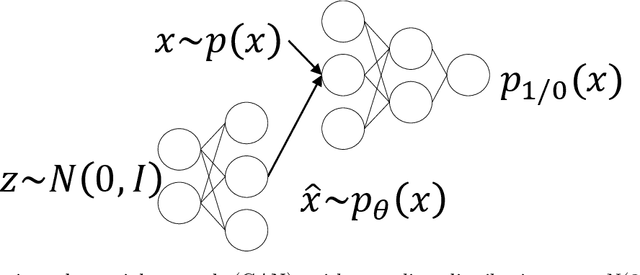
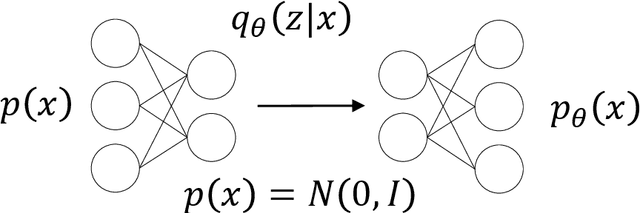
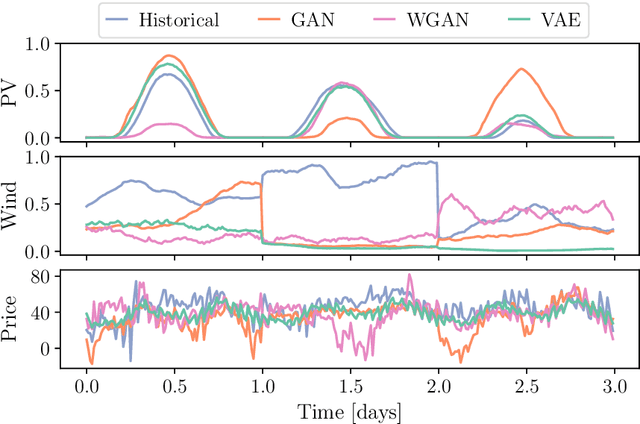
The design and operation of modern energy systems are heavily influenced by time-dependent and uncertain parameters, e.g., renewable electricity generation, load-demand, and electricity prices. These are typically represented by a set of discrete realizations known as scenarios. A popular scenario generation approach uses deep generative models (DGM) that allow scenario generation without prior assumptions about the data distribution. However, the validation of generated scenarios is difficult, and a comprehensive discussion about appropriate validation methods is currently lacking. To start this discussion, we provide a critical assessment of the currently used validation methods in the energy scenario generation literature. In particular, we assess validation methods based on probability density, auto-correlation, and power spectral density. Furthermore, we propose using the multifractal detrended fluctuation analysis (MFDFA) as an additional validation method for non-trivial features like peaks, bursts, and plateaus. As representative examples, we train generative adversarial networks (GANs), Wasserstein GANs (WGANs), and variational autoencoders (VAEs) on two renewable power generation time series (photovoltaic and wind from Germany in 2013 to 2015) and an intra-day electricity price time series form the European Energy Exchange in 2017 to 2019. We apply the four validation methods to both the historical and the generated data and discuss the interpretation of validation results as well as common mistakes, pitfalls, and limitations of the validation methods. Our assessment shows that no single method sufficiently characterizes a scenario but ideally validation should include multiple methods and be interpreted carefully in the context of scenarios over short time periods.
Design and Development of Miniature long distance multi-moving robots for 3D Smart Sensing for underground Pipe Inspection
Aug 22, 2022


Designing an in-pipe climbing robot that manipulates sharp gears to study complex line relationships. Traditional rolling/happening pipe climbing robots tend to slide when exploring pipe curves. The proposed gearbox connects to the farthest ground plane of a standard dual output gearbox. Instrumentation helps achieve a very well-defined deceleration sequence in which the robot slides and pulls as it moves forward. This instrument takes into account the forces exerted on each track within the line relationship and intentionally modifies the robot's track speed, unlocking the key to fine-tuning. This makes the 3 output transmissions take a lot of time. Deflection of the robot on a pipe network with various bearings and non-slip pipe bends demonstrates the integrity of the proposed structure.
Diffusion-based Molecule Generation with Informative Prior Bridges
Sep 02, 2022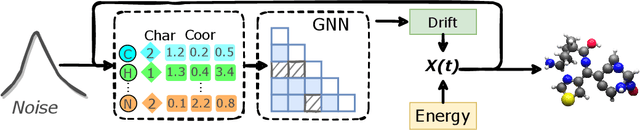
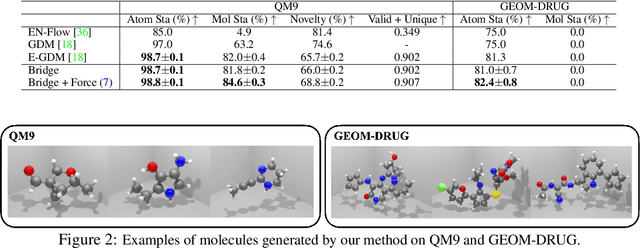


AI-based molecule generation provides a promising approach to a large area of biomedical sciences and engineering, such as antibody design, hydrolase engineering, or vaccine development. Because the molecules are governed by physical laws, a key challenge is to incorporate prior information into the training procedure to generate high-quality and realistic molecules. We propose a simple and novel approach to steer the training of diffusion-based generative models with physical and statistics prior information. This is achieved by constructing physically informed diffusion bridges, stochastic processes that guarantee to yield a given observation at the fixed terminal time. We develop a Lyapunov function based method to construct and determine bridges, and propose a number of proposals of informative prior bridges for both high-quality molecule generation and uniformity-promoted 3D point cloud generation. With comprehensive experiments, we show that our method provides a powerful approach to the 3D generation task, yielding molecule structures with better quality and stability scores and more uniformly distributed point clouds of high qualities.
Adaptive Learning on Time Series: Method and Financial Applications
Oct 21, 2021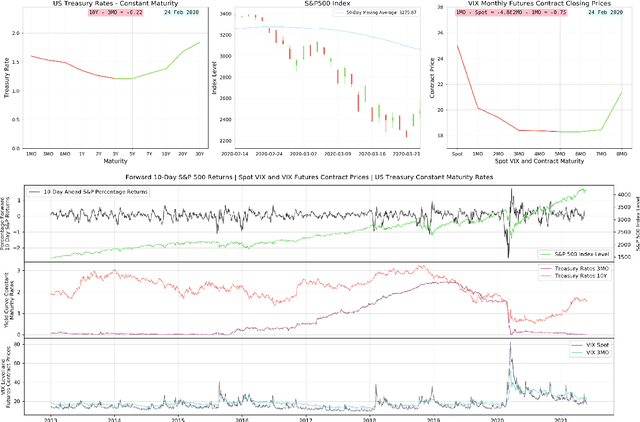
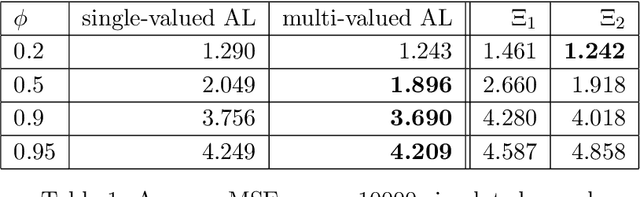
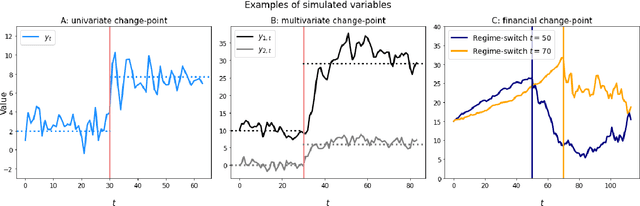
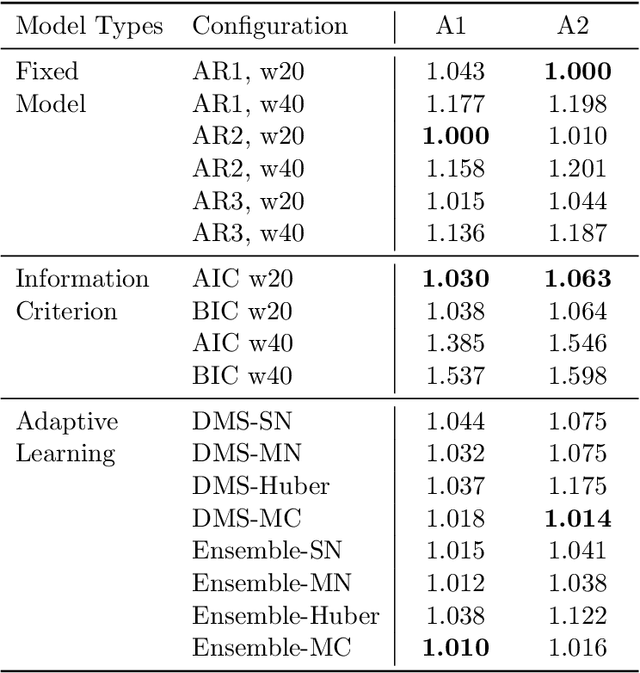
We formally introduce a time series statistical learning method, called Adaptive Learning, capable of handling model selection, out-of-sample forecasting and interpretation in a noisy environment. Through simulation studies we demonstrate that the method can outperform traditional model selection techniques such as AIC and BIC in the presence of regime-switching, as well as facilitating window size determination when the Data Generating Process is time-varying. Empirically, we use the method to forecast S&P 500 returns across multiple forecast horizons, employing information from the VIX Curve and the Yield Curve. We find that Adaptive Learning models are generally on par with, if not better than, the best of the parametric models a posteriori, evaluated in terms of MSE, while also outperforming under cross validation. We present a financial application of the learning results and an interpretation of the learning regime during the 2020 market crash. These studies can be extended in both a statistical direction and in terms of financial applications.
Representation Learning for Non-Melanoma Skin Cancer using a Latent Autoencoder
Sep 05, 2022
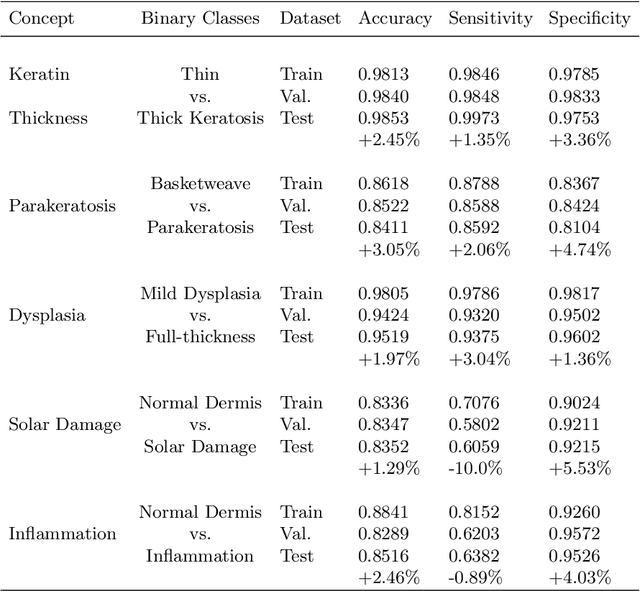
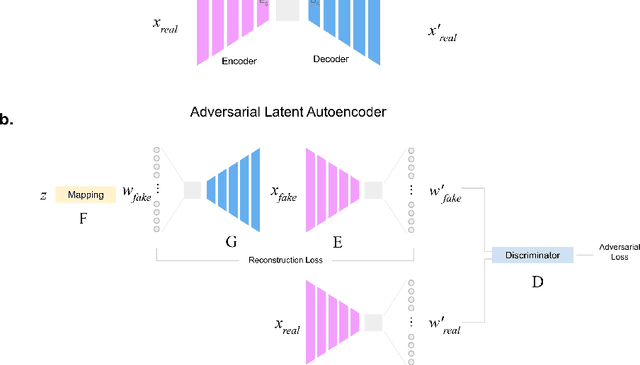
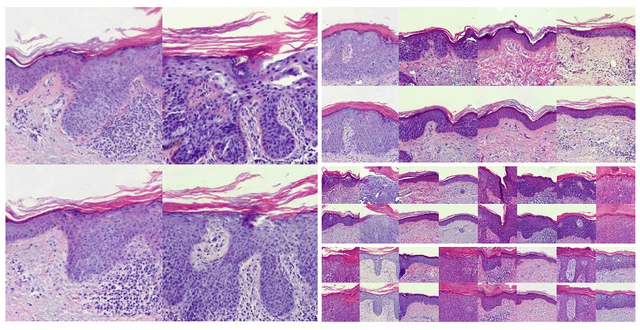
Generative learning is a powerful tool for representation learning, and shows particular promise for problems in biomedical imaging. However, in this context, sampling from the distribution is secondary to finding representations of real images, which often come with labels and explicitly represent the content and quality of the target distribution. It remains difficult to faithfully reconstruct images from generative models, particularly those as complex as histological images. In this work, two existing methods (autoencoders and adversarial latent autoencoders) are combined in attempt to improve our ability to encode and decode real images of non-melanoma skin cancer, specifically intra-epidermal carcinoma (IEC). Utilising a dataset of high-quality images of IEC (256 x 256), this work assesses the result of both image reconstruction quality and representation learning. It is shown that adversarial training can improve baseline FID scores from 76 to 50, and that benchmarks on representation learning can be improved by up to 3%. Smooth and realistic interpolations of the variation in the morphological structure are also presented for the first time, positioning representation learning as a promising direction in the context of computational pathology.
Classify Respiratory Abnormality in Lung Sounds Using STFT and a Fine-Tuned ResNet18 Network
Aug 30, 2022
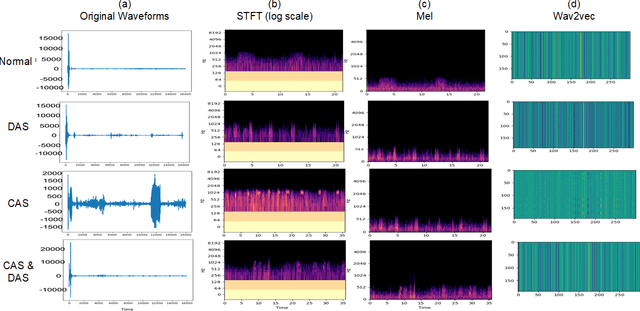
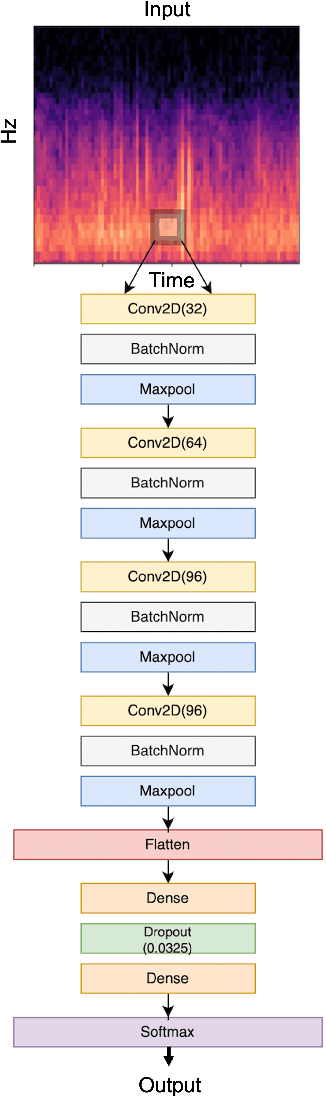
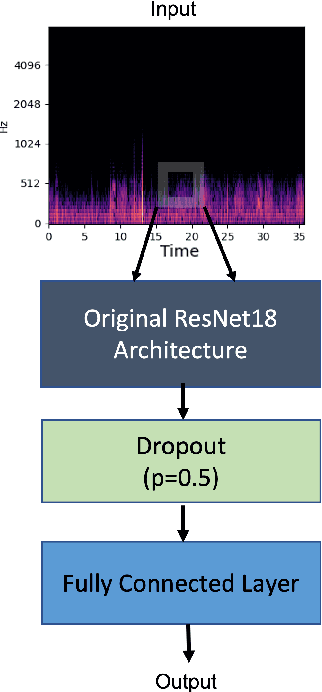
Recognizing patterns in lung sounds is crucial to detecting and monitoring respiratory diseases. Current techniques for analyzing respiratory sounds demand domain experts and are subject to interpretation. Hence an accurate and automatic respiratory sound classification system is desired. In this work, we took a data-driven approach to classify abnormal lung sounds. We compared the performance using three different feature extraction techniques, which are short-time Fourier transformation (STFT), Mel spectrograms, and Wav2vec, as well as three different classifiers, including pre-trained ResNet18, LightCNN, and Audio Spectrogram Transformer. Our key contributions include the bench-marking of different audio feature extractors and neural network based classifiers, and the implementation of a complete pipeline using STFT and a fine-tuned ResNet18 network. The proposed method achieved Harmonic Scores of 0.89, 0.80, 0.71, 0.36 for tasks 1-1, 1-2, 2-1 and 2-2, respectively on the testing sets in the IEEE BioCAS 2022 Grand Challenge on Respiratory Sound Classification.