 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Diagonal Preconditioning: Theory and Practice
Sep 02, 2022

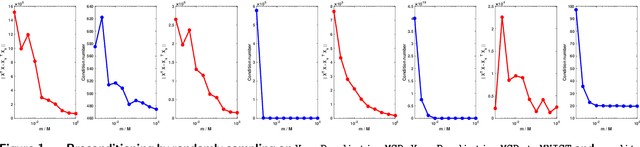
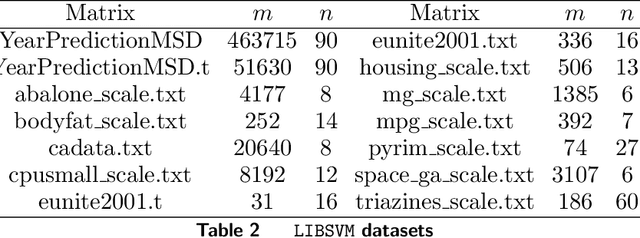

Preconditioning has been a staple technique in optimization and machine learning. It often reduces the condition number of the matrix it is applied to, thereby speeding up convergence of optimization algorithms. Although there are many popular preconditioning techniques in practice, most lack theoretical guarantees for reductions in condition number. In this paper, we study the problem of optimal diagonal preconditioning to achieve maximal reduction in the condition number of any full-rank matrix by scaling its rows or columns separately or simultaneously. We first reformulate the problem as a quasi-convex problem and provide a baseline bisection algorithm that is easy to implement in practice, where each iteration consists of an SDP feasibility problem. Then we propose a polynomial time potential reduction algorithm with $O(\log(\frac{1}{\epsilon}))$ iteration complexity, where each iteration consists of a Newton update based on the Nesterov-Todd direction. Our algorithm is based on a formulation of the problem which is a generalized version of the Von Neumann optimal growth problem. Next, we specialize to one-sided optimal diagonal preconditioning problems, and demonstrate that they can be formulated as standard dual SDP problems, to which we apply efficient customized solvers and study the empirical performance of our optimal diagonal preconditioners. Our extensive experiments on large matrices demonstrate the practical appeal of optimal diagonal preconditioners at reducing condition numbers compared to heuristics-based preconditioners.
Learning with Recoverable Forgetting
Jul 17, 2022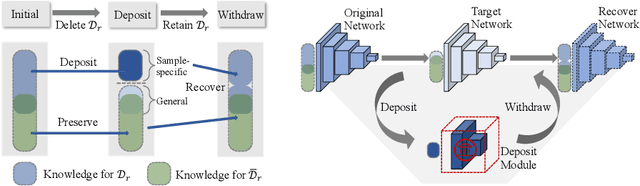
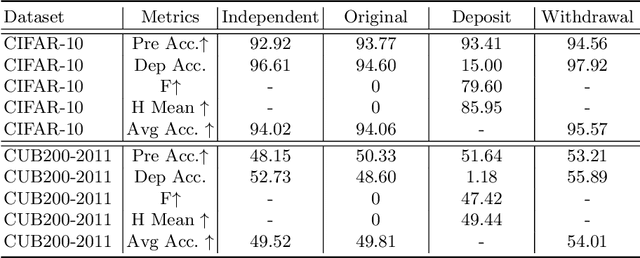
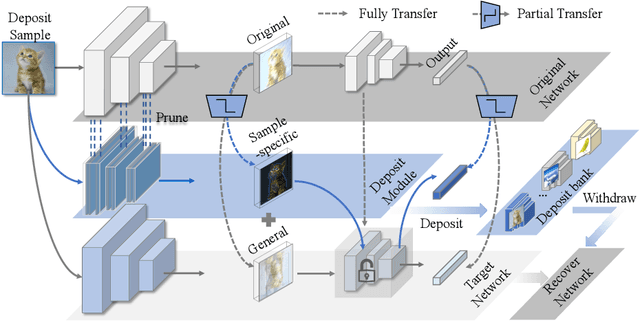
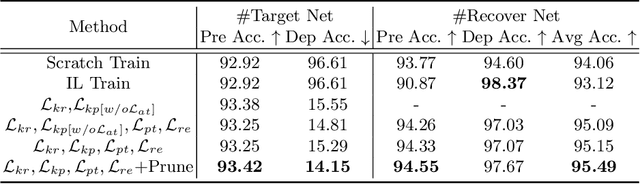
Life-long learning aims at learning a sequence of tasks without forgetting the previously acquired knowledge. However, the involved training data may not be life-long legitimate due to privacy or copyright reasons. In practical scenarios, for instance, the model owner may wish to enable or disable the knowledge of specific tasks or specific samples from time to time. Such flexible control over knowledge transfer, unfortunately, has been largely overlooked in previous incremental or decremental learning methods, even at a problem-setup level. In this paper, we explore a novel learning scheme, termed as Learning wIth Recoverable Forgetting (LIRF), that explicitly handles the task- or sample-specific knowledge removal and recovery. Specifically, LIRF brings in two innovative schemes, namely knowledge deposit and withdrawal, which allow for isolating user-designated knowledge from a pre-trained network and injecting it back when necessary. During the knowledge deposit process, the specified knowledge is extracted from the target network and stored in a deposit module, while the insensitive or general knowledge of the target network is preserved and further augmented. During knowledge withdrawal, the taken-off knowledge is added back to the target network. The deposit and withdraw processes only demand for a few epochs of finetuning on the removal data, ensuring both data and time efficiency. We conduct experiments on several datasets, and demonstrate that the proposed LIRF strategy yields encouraging results with gratifying generalization capability.
MISO Wireless Localization in The Presence of Reconfigurable Intelligent Surface
Aug 19, 2022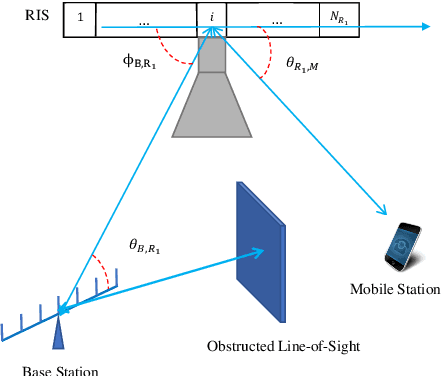
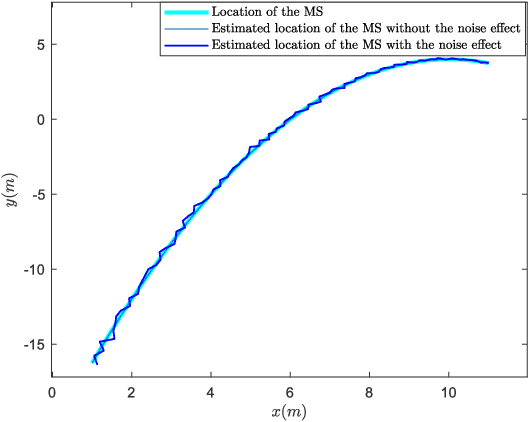
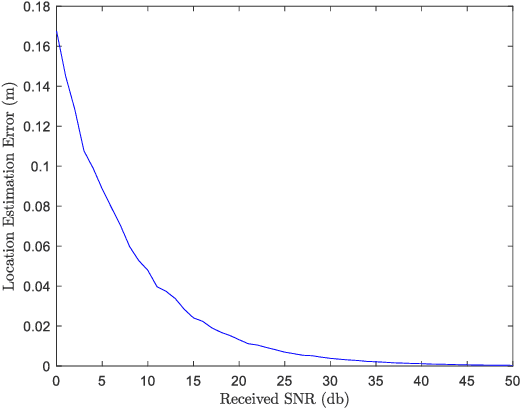
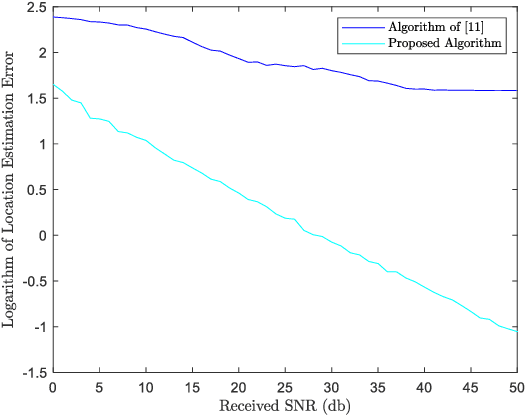
Reconfigurable Intelligent Surface (RIS) plays a pivotal role in the sixth generation networks to enhance communication rate and localization accuracy. In this letter, we propose a positioning algorithm in a RIS-assisted environment, where the Base Station (BS) is multi-antenna, and the Mobile Station (MS) is single-antenna. We show that our method can achieve a high-precision positioning if the line-of-sight (LOS) is obstructed and three RISs are available. We send several known signals to the receiver in different time slots and change the phase shifters of the RISs simultaneously in a proper way, and we propose a technique to eliminate the destructive effect of the angle-of-departure (AoD) in order to determine the distances between each RISs and the MS. The accuracy of the proposed algorithm is better than the algorithms which do not estimate the AoD, shown in the numerical result section.
Multi-Time Attention Networks for Irregularly Sampled Time Series
Jan 25, 2021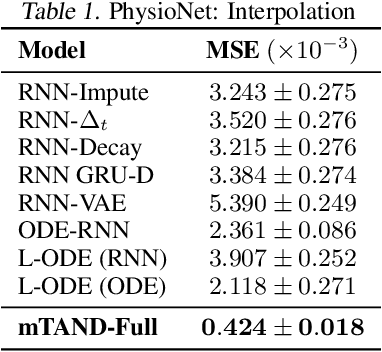
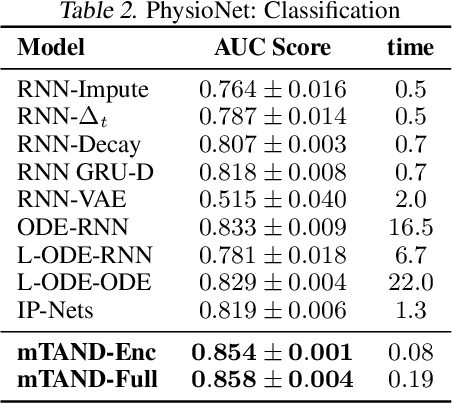
Irregular sampling occurs in many time series modeling applications where it presents a significant challenge to standard deep learning models. This work is motivated by the analysis of physiological time series data in electronic health records, which are sparse, irregularly sampled, and multivariate. In this paper, we propose a new deep learning framework for this setting that we call Multi-Time Attention Networks. Multi-Time Attention Networks learn an embedding of continuous-time values and use an attention mechanism to produce a fixed-length representation of a time series containing a variable number of observations. We investigate the performance of our framework on interpolation and classification tasks using multiple datasets. Our results show that our approach performs as well or better than a range of baseline and recently proposed models while offering significantly faster training times than current state-of-the-art methods.
Single-Stage Broad Multi-Instance Multi-Label Learning (BMIML) with Diverse Inter-Correlations and its application to medical image classification
Sep 06, 2022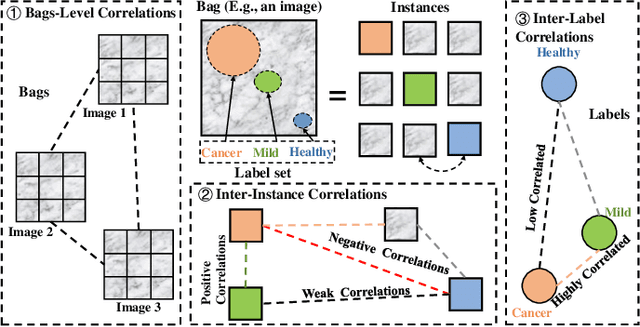
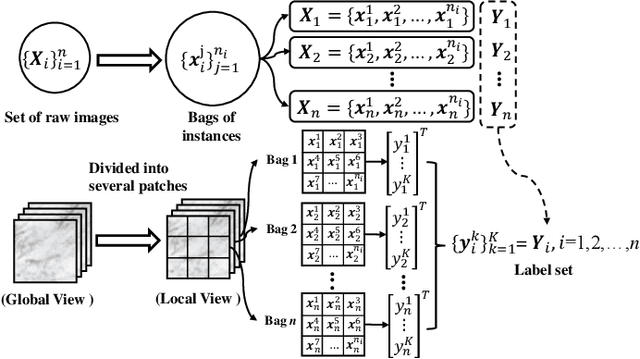
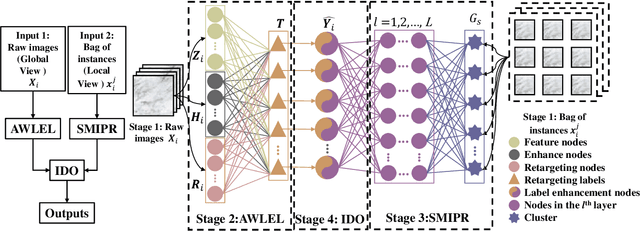
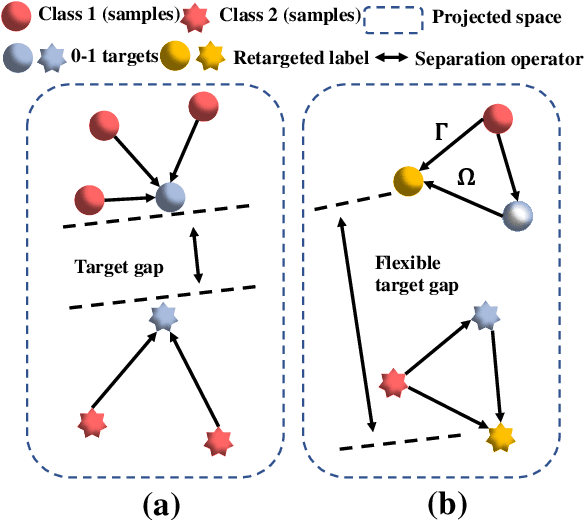
In many real-world applications, one object (e.g., image) can be represented or described by multiple instances (e.g., image patches) and simultaneously associated with multiple labels. Such applications can be formulated as multi-instance multi-label learning (MIML) problems and have been extensively studied during the past few years. Existing MIML methods are useful in many applications but most of which suffer from relatively low accuracy and training efficiency due to several issues: i) the inter-label correlations (i.e., the probabilistic correlations between the multiple labels corresponding to an object) are neglected; ii) the inter-instance correlations cannot be learned directly (or jointly) with other types of correlations due to the missing instance labels; iii) diverse inter-correlations (e.g., inter-label correlations, inter-instance correlations) can only be learned in multiple stages. To resolve these issues, a new single-stage framework called broad multi-instance multi-label learning (BMIML) is proposed. In BMIML, there are three innovative modules: i) an auto-weighted label enhancement learning (AWLEL) based on broad learning system (BLS); ii) A specific MIML neural network called scalable multi-instance probabilistic regression (SMIPR); iii) Finally, an interactive decision optimization (IDO). As a result, BMIML can achieve simultaneous learning of diverse inter-correlations between whole images, instances, and labels in single stage for higher classification accuracy and much faster training time. Experiments show that BMIML is highly competitive to (or even better than) existing methods in accuracy and much faster than most MIML methods even for large medical image data sets (> 90K images).
ORACLE: Occlusion-Resilient And self-Calibrating mmWave Radar Network for People Tracking
Aug 30, 2022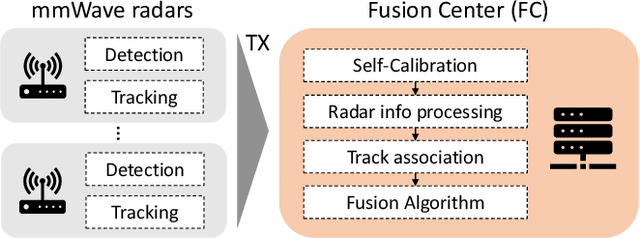
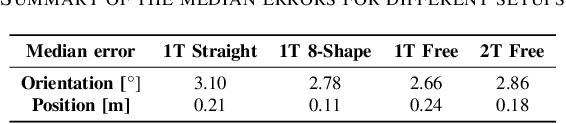
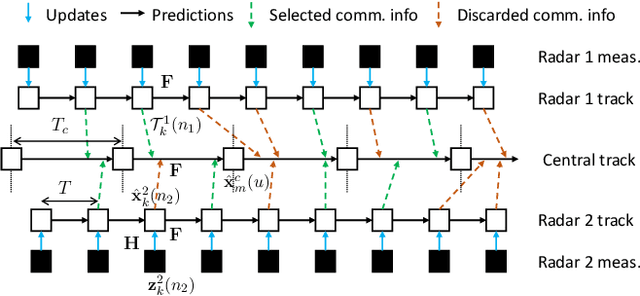
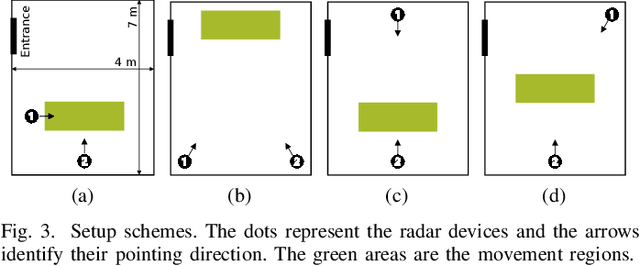
Millimeter wave (mmWave) radars are emerging as valid alternatives to cameras for the pervasive contactless monitoring of industrial environments, enabling very tight human-machine interactions. However, commercial mmWave radars feature a limited range (up to 6-8 m) and are subject to occlusion, which may constitute a significant drawback in large industrial settings containing machinery and obstacles. Thus, covering large indoor spaces requires multiple radars with known relative position and orientation. As a result, we necessitate algorithms to combine their outputs. In this work, we present ORACLE, an autonomous system that (i) integrates automatic relative position and orientation estimation from multiple radar devices by exploiting the trajectories of people moving freely in the radars' common fields of view and (ii) fuses the tracking information from multiple radars to obtain a unified tracking among all sensors. Our implementation and experimental evaluation of ORACLE results in median errors of 0.18 m and 2.86{\deg} for radars location and orientation estimates, respectively. The fused tracking improves upon single sensor tracking by 6%, in terms of mean tracking accuracy, while reaching a mean tracking error as low as 0.14 m. Finally, ORACLE is robust to fusion relative time synchronization mismatches between -20% and +50%.
Standardizing and Centralizing Datasets to Enable Efficient Training of Agricultural Deep Learning Models
Aug 04, 2022
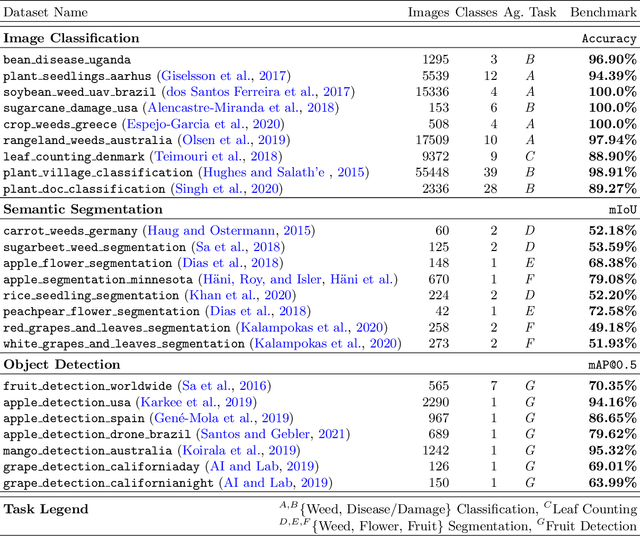

In recent years, deep learning models have become the standard for agricultural computer vision. Such models are typically fine-tuned to agricultural tasks using model weights that were originally fit to more general, non-agricultural datasets. This lack of agriculture-specific fine-tuning potentially increases training time and resource use, and decreases model performance, leading an overall decrease in data efficiency. To overcome this limitation, we collect a wide range of existing public datasets for three distinct tasks, standardize them, and construct standard training and evaluation pipelines, providing us with a set of benchmarks and pretrained models. We then conduct a number of experiments using methods which are commonly used in deep learning tasks, but unexplored in their domain-specific applications for agriculture. Our experiments guide us in developing a number of approaches to improve data efficiency when training agricultural deep learning models, without large-scale modifications to existing pipelines. Our results demonstrate that even slight training modifications, such as using agricultural pretrained model weights, or adopting specific spatial augmentations into data processing pipelines, can significantly boost model performance and result in shorter convergence time, saving training resources. Furthermore, we find that even models trained on low-quality annotations can produce comparable levels of performance to their high-quality equivalents, suggesting that datasets with poor annotations can still be used for training, expanding the pool of currently available datasets. Our methods are broadly applicable throughout agricultural deep learning, and present high potential for significant data efficiency improvements.
Towards making the most of NLP-based device mapping optimization for OpenCL kernels
Aug 30, 2022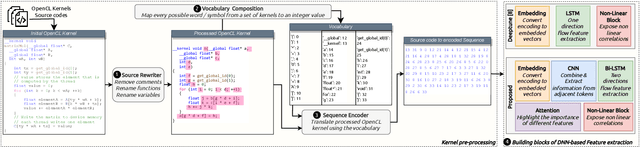
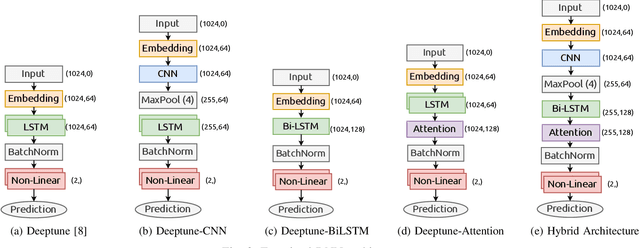
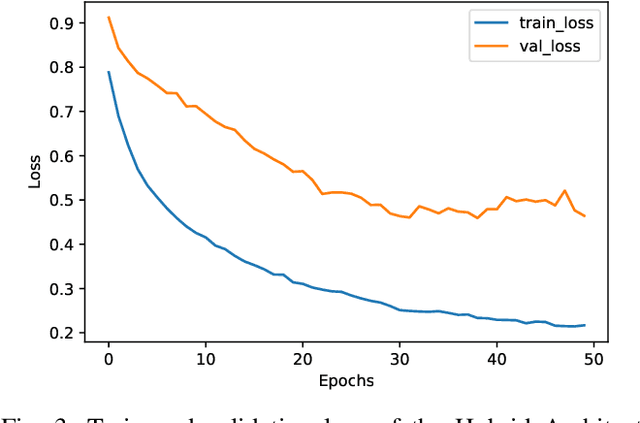
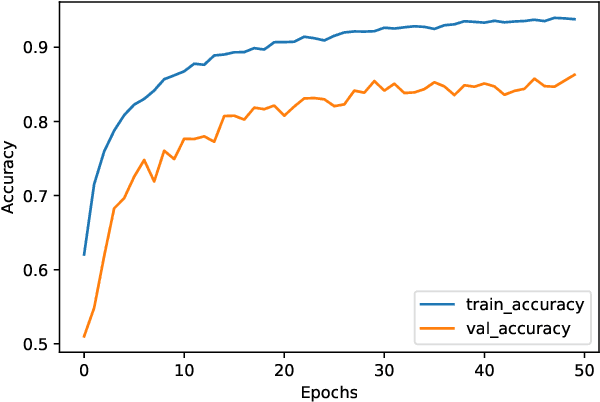
Nowadays, we are living in an era of extreme device heterogeneity. Despite the high variety of conventional CPU architectures, accelerator devices, such as GPUs and FPGAs, also appear in the foreground exploding the pool of available solutions to execute applications. However, choosing the appropriate device per application needs is an extremely challenging task due to the abstract relationship between hardware and software. Automatic optimization algorithms that are accurate are required to cope with the complexity and variety of current hardware and software. Optimal execution has always relied on time-consuming trial and error approaches. Machine learning (ML) and Natural Language Processing (NLP) has flourished over the last decade with research focusing on deep architectures. In this context, the use of natural language processing techniques to source code in order to conduct autotuning tasks is an emerging field of study. In this paper, we extend the work of Cummins et al., namely Deeptune, that tackles the problem of optimal device selection (CPU or GPU) for accelerated OpenCL kernels. We identify three major limitations of Deeptune and, based on these, we propose four different DNN models that provide enhanced contextual information of source codes. Experimental results show that our proposed methodology surpasses that of Cummins et al. work, providing up to 4\% improvement in prediction accuracy.
* Accepted at IEEE COINS 2022
Sliding Window Recurrent Network for Efficient Video Super-Resolution
Aug 24, 2022


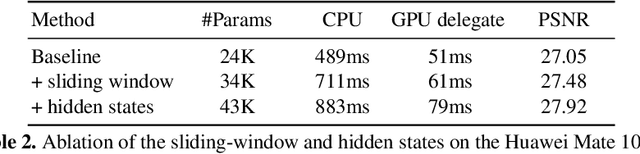
Video super-resolution (VSR) is the task of restoring high-resolution frames from a sequence of low-resolution inputs. Different from single image super-resolution, VSR can utilize frames' temporal information to reconstruct results with more details. Recently, with the rapid development of convolution neural networks (CNN), the VSR task has drawn increasing attention and many CNN-based methods have achieved remarkable results. However, only a few VSR approaches can be applied to real-world mobile devices due to the computational resources and runtime limitations. In this paper, we propose a \textit{Sliding Window based Recurrent Network} (SWRN) which can be real-time inference while still achieving superior performance. Specifically, we notice that video frames should have both spatial and temporal relations that can help to recover details, and the key point is how to extract and aggregate information. Address it, we input three neighboring frames and utilize a hidden state to recurrently store and update the important temporal information. Our experiment on REDS dataset shows that the proposed method can be well adapted to mobile devices and produce visually pleasant results.
LoMEF: A Framework to Produce Local Explanations for Global Model Time Series Forecasts
Nov 13, 2021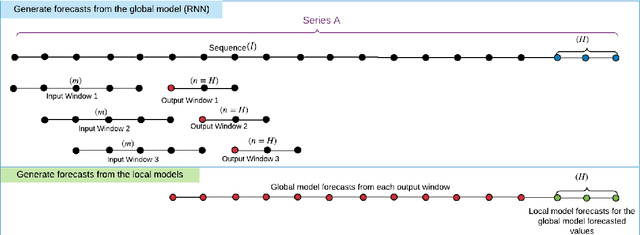
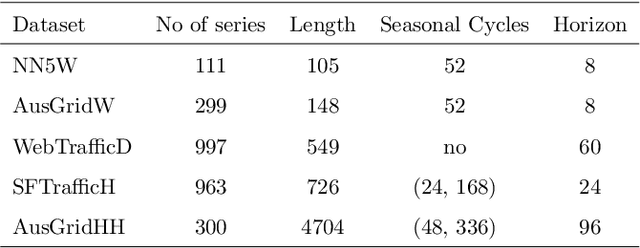
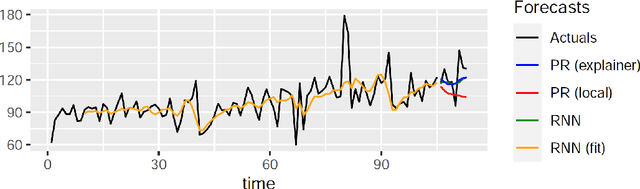
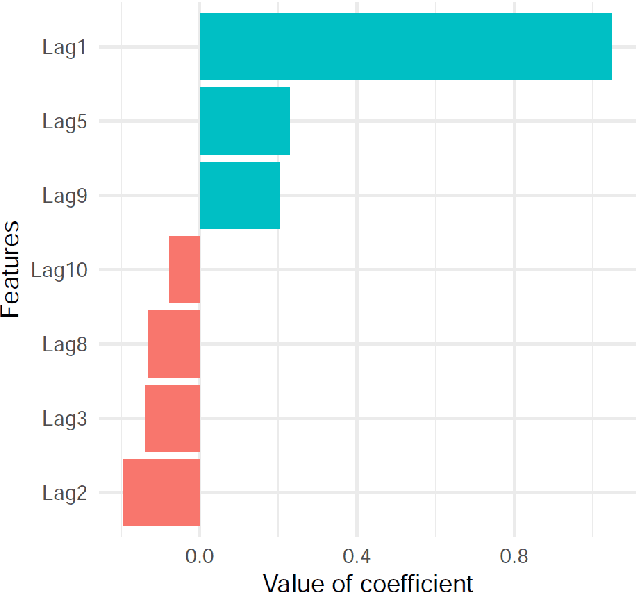
Global Forecasting Models (GFM) that are trained across a set of multiple time series have shown superior results in many forecasting competitions and real-world applications compared with univariate forecasting approaches. One aspect of the popularity of statistical forecasting models such as ETS and ARIMA is their relative simplicity and interpretability (in terms of relevant lags, trend, seasonality, and others), while GFMs typically lack interpretability, especially towards particular time series. This reduces the trust and confidence of the stakeholders when making decisions based on the forecasts without being able to understand the predictions. To mitigate this problem, in this work, we propose a novel local model-agnostic interpretability approach to explain the forecasts from GFMs. We train simpler univariate surrogate models that are considered interpretable (e.g., ETS) on the predictions of the GFM on samples within a neighbourhood that we obtain through bootstrapping or straightforwardly as the one-step-ahead global black-box model forecasts of the time series which needs to be explained. After, we evaluate the explanations for the forecasts of the global models in both qualitative and quantitative aspects such as accuracy, fidelity, stability and comprehensibility, and are able to show the benefits of our approach.