 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic Camera Control and Directing with an Ultra-High-Definition Collaborative Recording System
Aug 10, 2022
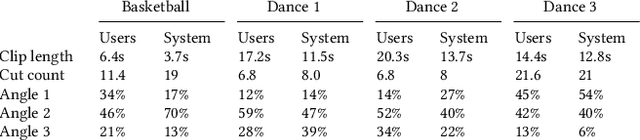

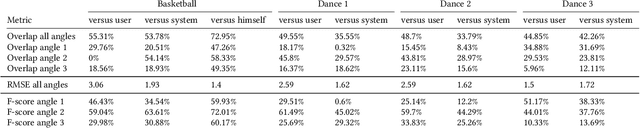

Capturing an event from multiple camera angles can give a viewer the most complete and interesting picture of that event. To be suitable for broadcasting, a human director needs to decide what to show at each point in time. This can become cumbersome with an increasing number of camera angles. The introduction of omnidirectional or wide-angle cameras has allowed for events to be captured more completely, making it even more difficult for the director to pick a good shot. In this paper, a system is presented that, given multiple ultra-high resolution video streams of an event, can generate a visually pleasing sequence of shots that manages to follow the relevant action of an event. Due to the algorithm being general purpose, it can be applied to most scenarios that feature humans. The proposed method allows for online processing when real-time broadcasting is required, as well as offline processing when the quality of the camera operation is the priority. Object detection is used to detect humans and other objects of interest in the input streams. Detected persons of interest, along with a set of rules based on cinematic conventions, are used to determine which video stream to show and what part of that stream is virtually framed. The user can provide a number of settings that determine how these rules are interpreted. The system is able to handle input from different wide-angle video streams by removing lens distortions. Using a user study it is shown, for a number of different scenarios, that the proposed automated director is able to capture an event with aesthetically pleasing video compositions and human-like shot switching behavior.
Domain Decomposition Algorithms for Real-time Homogeneous Diffusion Inpainting in 4K
Oct 11, 2021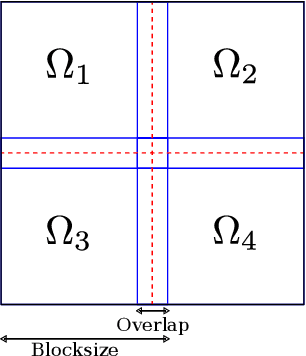
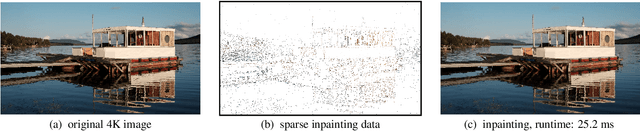
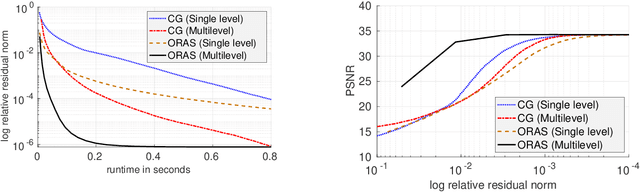
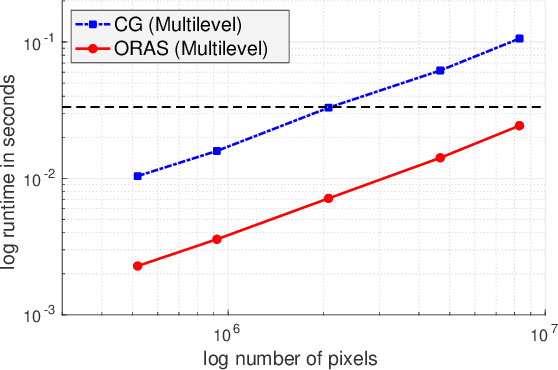
Inpainting-based compression methods are qualitatively promising alternatives to transform-based codecs, but they suffer from the high computational cost of the inpainting step. This prevents them from being applicable to time-critical scenarios such as real-time inpainting of 4K images. As a remedy, we adapt state-of-the-art numerical algorithms of domain decomposition type to this problem. They decompose the image domain into multiple overlapping blocks that can be inpainted in parallel by means of modern GPUs. In contrast to classical block decompositions such as the ones in JPEG, the global inpainting problem is solved without creating block artefacts. We consider the popular homogeneous diffusion inpainting and supplement it with a multilevel version of an optimised restricted additive Schwarz (ORAS) method that solves the local problems with a conjugate gradient algorithm. This enables us to perform real-time inpainting of 4K colour images on contemporary GPUs, which is substantially more efficient than previous algorithms for diffusion-based inpainting.
Digital Twin-Assisted Efficient Reinforcement Learning for Edge Task Scheduling
Aug 02, 2022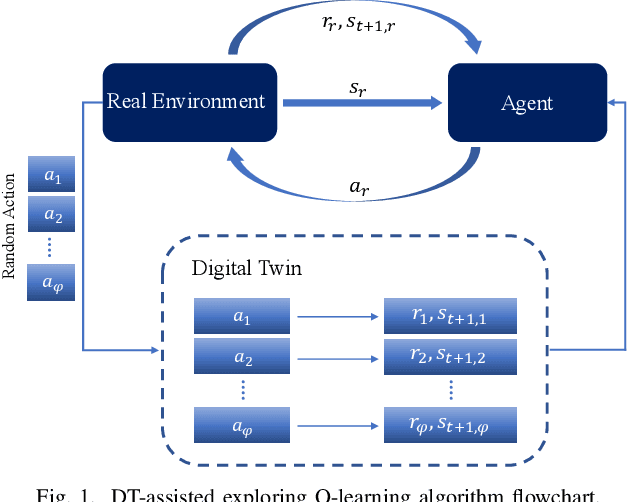
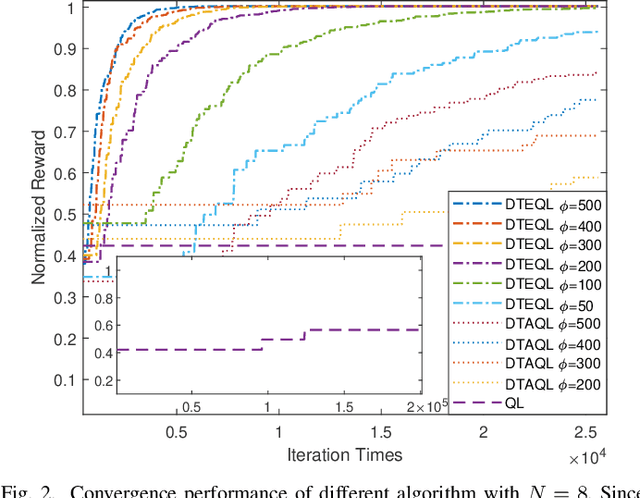


Task scheduling is a critical problem when one user offloads multiple different tasks to the edge server. When a user has multiple tasks to offload and only one task can be transmitted to server at a time, while server processes tasks according to the transmission order, the problem is NP-hard. However, it is difficult for traditional optimization methods to quickly obtain the optimal solution, while approaches based on reinforcement learning face with the challenge of excessively large action space and slow convergence. In this paper, we propose a Digital Twin (DT)-assisted RL-based task scheduling method in order to improve the performance and convergence of the RL. We use DT to simulate the results of different decisions made by the agent, so that one agent can try multiple actions at a time, or, similarly, multiple agents can interact with environment in parallel in DT. In this way, the exploration efficiency of RL can be significantly improved via DT, and thus RL can converges faster and local optimality is less likely to happen. Particularly, two algorithms are designed to made task scheduling decisions, i.e., DT-assisted asynchronous Q-learning (DTAQL) and DT-assisted exploring Q-learning (DTEQL). Simulation results show that both algorithms significantly improve the convergence speed of Q-learning by increasing the exploration efficiency.
SATBench: Benchmarking the speed-accuracy tradeoff in object recognition by humans and dynamic neural networks
Jun 16, 2022
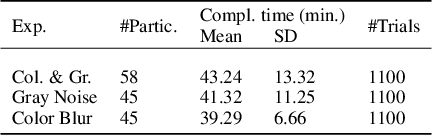
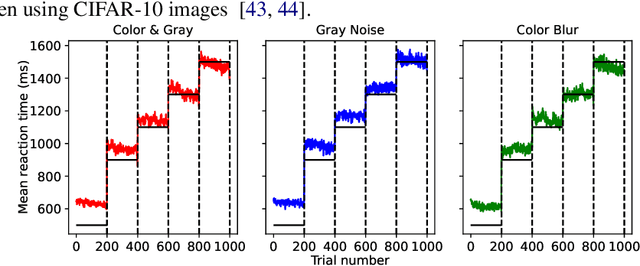
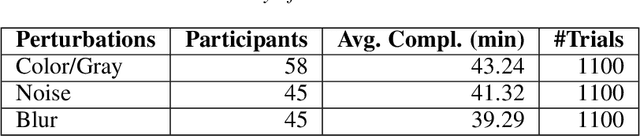
The core of everyday tasks like reading and driving is active object recognition. Attempts to model such tasks are currently stymied by the inability to incorporate time. People show a flexible tradeoff between speed and accuracy and this tradeoff is a crucial human skill. Deep neural networks have emerged as promising candidates for predicting peak human object recognition performance and neural activity. However, modeling the temporal dimension i.e., the speed-accuracy tradeoff (SAT), is essential for them to serve as useful computational models for how humans recognize objects. To this end, we here present the first large-scale (148 observers, 4 neural networks, 8 tasks) dataset of the speed-accuracy tradeoff (SAT) in recognizing ImageNet images. In each human trial, a beep, indicating the desired reaction time, sounds at a fixed delay after the image is presented, and observer's response counts only if it occurs near the time of the beep. In a series of blocks, we test many beep latencies, i.e., reaction times. We observe that human accuracy increases with reaction time and proceed to compare its characteristics with the behavior of several dynamic neural networks that are capable of inference-time adaptive computation. Using FLOPs as an analog for reaction time, we compare networks with humans on curve-fit error, category-wise correlation, and curve steepness, and conclude that cascaded dynamic neural networks are a promising model of human reaction time in object recognition tasks.
Real-Time Hybrid Mapping of Populated Indoor Scenes using a Low-Cost Monocular UAV
Mar 04, 2022
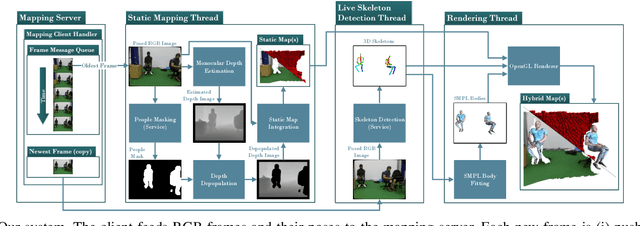
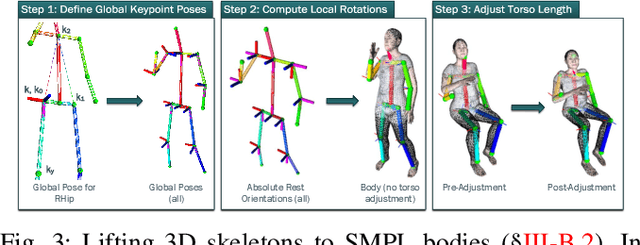
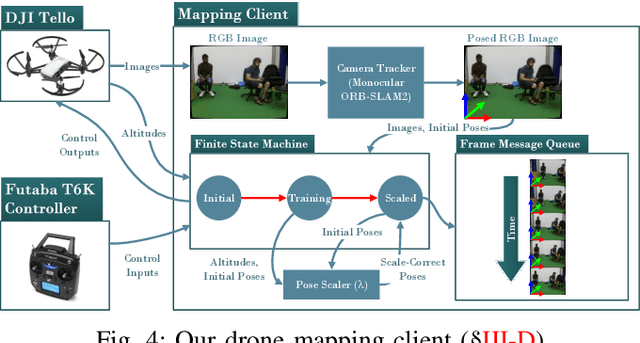
Unmanned aerial vehicles (UAVs) have been used for many applications in recent years, from urban search and rescue, to agricultural surveying, to autonomous underground mine exploration. However, deploying UAVs in tight, indoor spaces, especially close to humans, remains a challenge. One solution, when limited payload is required, is to use micro-UAVs, which pose less risk to humans and typically cost less to replace after a crash. However, micro-UAVs can only carry a limited sensor suite, e.g. a monocular camera instead of a stereo pair or LiDAR, complicating tasks like dense mapping and markerless multi-person 3D human pose estimation, which are needed to operate in tight environments around people. Monocular approaches to such tasks exist, and dense monocular mapping approaches have been successfully deployed for UAV applications. However, despite many recent works on both marker-based and markerless multi-UAV single-person motion capture, markerless single-camera multi-person 3D human pose estimation remains a much earlier-stage technology, and we are not aware of existing attempts to deploy it in an aerial context. In this paper, we present what is thus, to our knowledge, the first system to perform simultaneous mapping and multi-person 3D human pose estimation from a monocular camera mounted on a single UAV. In particular, we show how to loosely couple state-of-the-art monocular depth estimation and monocular 3D human pose estimation approaches to reconstruct a hybrid map of a populated indoor scene in real time. We validate our component-level design choices via extensive experiments on the large-scale ScanNet and GTA-IM datasets. To evaluate our system-level performance, we also construct a new Oxford Hybrid Mapping dataset of populated indoor scenes.
On the properties of path additions for traffic routing
Jul 10, 2022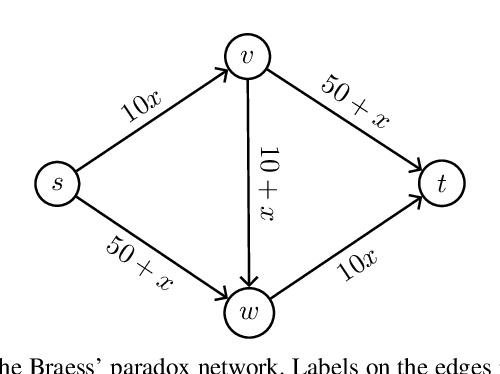
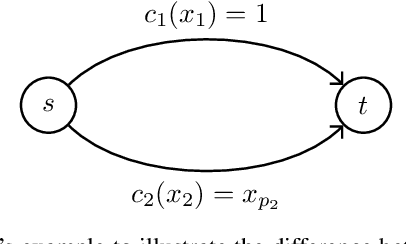
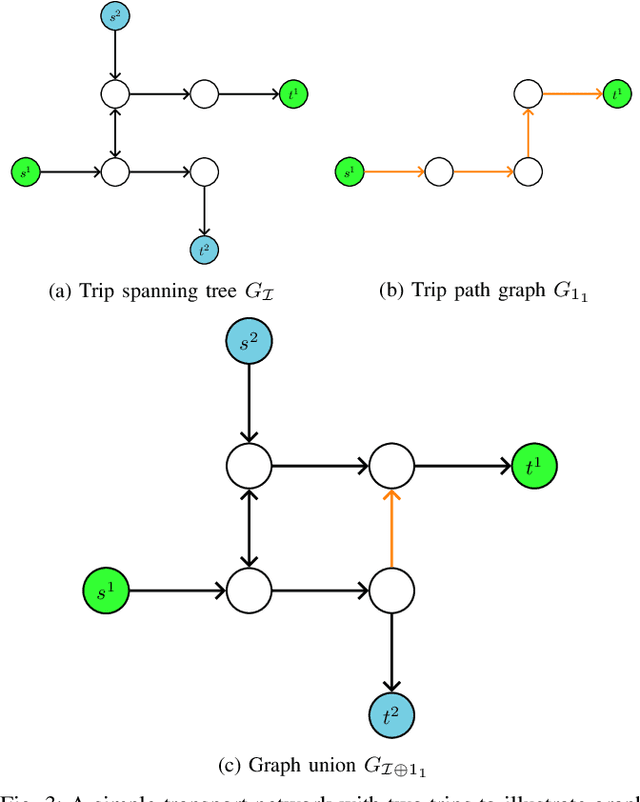
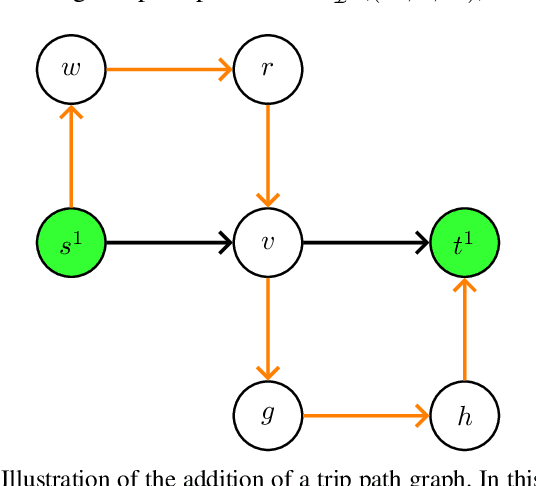
In this paper we investigate the impact of path additions to transport networks with optimised traffic routing. In particular, we study the behaviour of total travel time, and consider both self-interested routing paradigms, such as User Equilibrium (UE) routing, as well as cooperative paradigms, such as classic Multi-Commodity (MC) network flow and System Optimal (SO) routing. We provide a formal framework for designing transport networks through iterative path additions, introducing the concepts of trip spanning tree and trip path graph. Using this formalisation, we prove multiple properties of the objective function for transport network design. Since the underlying routing problem is NP-Hard, we investigate properties that provide guarantees in approximate algorithm design. Firstly, while Braess' paradox has shown that total travel time is not monotonic non-increasing with respect to path additions under self-interested routing (UE), we prove that, instead, monotonicity holds for cooperative routing (MC and SO). This result has the important implication that cooperative agents make the best use of redundant infrastructure. Secondly, we prove via a counterexample that the intuitive statement `adding a path to a transport network always grants greater or equal benefit to users than adding it to a superset of that network' is false. In other words we prove that, for all the routing formulations studied, total travel time is not supermodular with respect to path additions. While this counter-intuitive result yields a hardness property for algorithm design, we provide particular instances where, instead, the property of supermodularity holds. Our study on monotonicity and supermodularity of total travel time with respect to path additions provides formal proofs and scenarios that constitute important insights for transport network designers.
CAESynth: Real-Time Timbre Interpolation and Pitch Control with Conditional Autoencoders
Nov 09, 2021



In this paper, we present a novel audio synthesizer, CAESynth, based on a conditional autoencoder. CAESynth synthesizes timbre in real-time by interpolating the reference sounds in their shared latent feature space, while controlling a pitch independently. We show that training a conditional autoencoder based on accuracy in timbre classification together with adversarial regularization of pitch content allows timbre distribution in latent space to be more effective and stable for timbre interpolation and pitch conditioning. The proposed method is applicable not only to creation of musical cues but also to exploration of audio affordance in mixed reality based on novel timbre mixtures with environmental sounds. We demonstrate by experiments that CAESynth achieves smooth and high-fidelity audio synthesis in real-time through timbre interpolation and independent yet accurate pitch control for musical cues as well as for audio affordance with environmental sound. A Python implementation along with some generated samples are shared online.
Event2Graph: Event-driven Bipartite Graph for Multivariate Time-series Anomaly Detection
Aug 15, 2021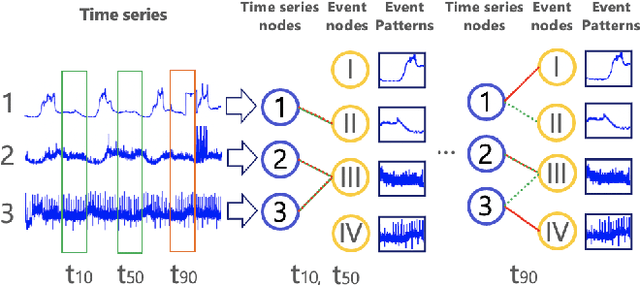
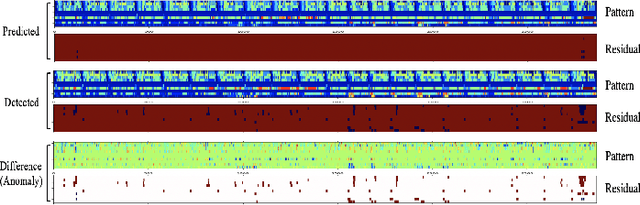
Modeling inter-dependencies between time-series is the key to achieve high performance in anomaly detection for multivariate time-series data. The de-facto solution to model the dependencies is to feed the data into a recurrent neural network (RNN). However, the fully connected network structure underneath the RNN (either GRU or LSTM) assumes a static and complete dependency graph between time-series, which may not hold in many real-world applications. To alleviate this assumption, we propose a dynamic bipartite graph structure to encode the inter-dependencies between time-series. More concretely, we model time series as one type of nodes, and the time series segments (regarded as event) as another type of nodes, where the edge between two types of nodes describe a temporal pattern occurred on a specific time series at a certain time. Based on this design, relations between time series can be explicitly modelled via dynamic connections to event nodes, and the multivariate time-series anomaly detection problem can be formulated as a self-supervised, edge stream prediction problem in dynamic graphs. We conducted extensive experiments to demonstrate the effectiveness of the design.
Causal Inference in Non-linear Time-series using Deep Networks and Knockoff Counterfactuals
Oct 18, 2021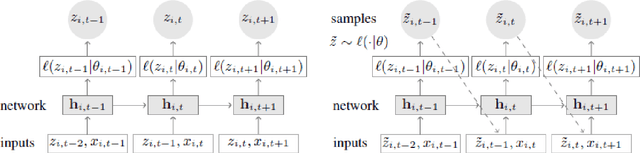
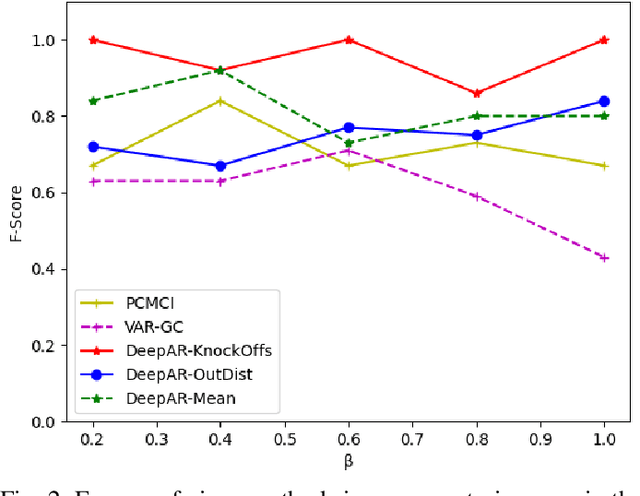
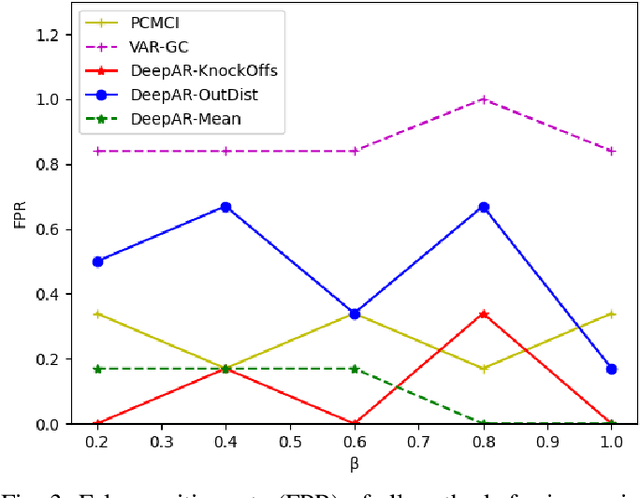
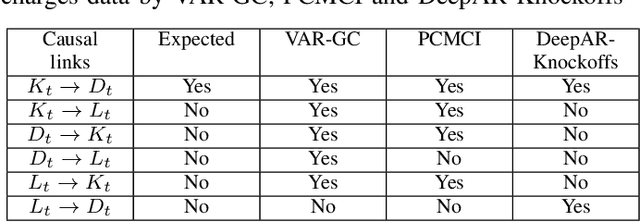
Estimating causal relations is vital in understanding the complex interactions in multivariate time series. Non-linear coupling of variables is one of the major challenges inaccurate estimation of cause-effect relations. In this paper, we propose to use deep autoregressive networks (DeepAR) in tandem with counterfactual analysis to infer nonlinear causal relations in multivariate time series. We extend the concept of Granger causality using probabilistic forecasting with DeepAR. Since deep networks can neither handle missing input nor out-of-distribution intervention, we propose to use the Knockoffs framework (Barberand Cand`es, 2015) for generating intervention variables and consequently counterfactual probabilistic forecasting. Knockoff samples are independent of their output given the observed variables and exchangeable with their counterpart variables without changing the underlying distribution of the data. We test our method on synthetic as well as real-world time series datasets. Overall our method outperforms the widely used vector autoregressive Granger causality and PCMCI in detecting nonlinear causal dependency in multivariate time series.
Time Discretization-Invariant Safe Action Repetition for Policy Gradient Methods
Nov 06, 2021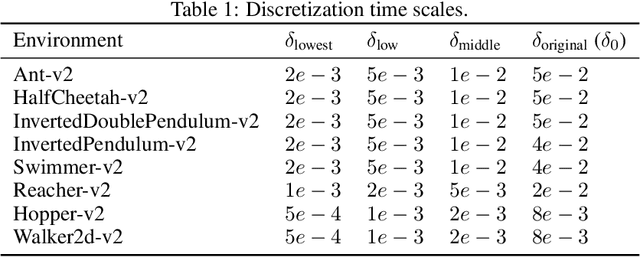
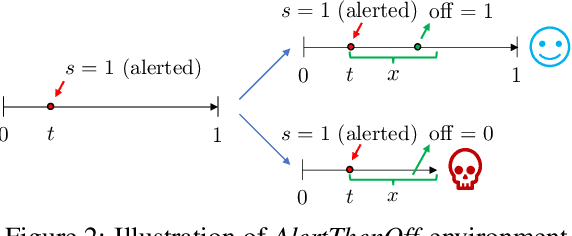
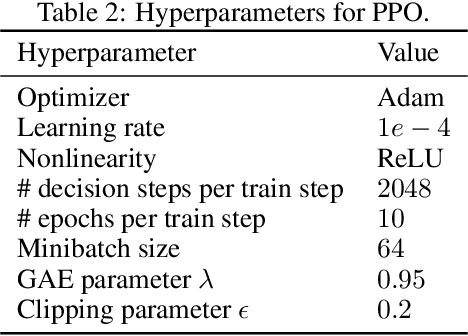
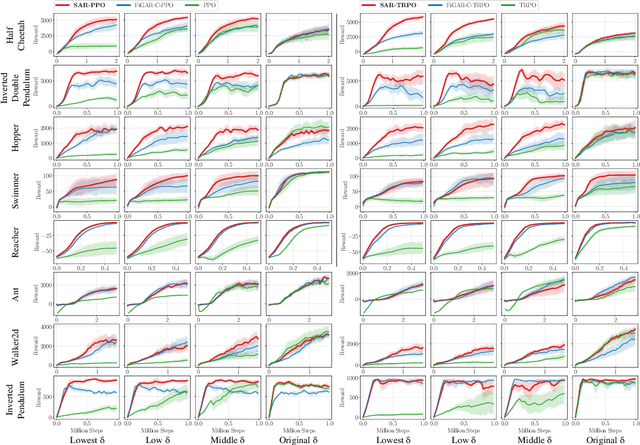
In reinforcement learning, continuous time is often discretized by a time scale $\delta$, to which the resulting performance is known to be highly sensitive. In this work, we seek to find a $\delta$-invariant algorithm for policy gradient (PG) methods, which performs well regardless of the value of $\delta$. We first identify the underlying reasons that cause PG methods to fail as $\delta \to 0$, proving that the variance of the PG estimator can diverge to infinity in stochastic environments under a certain assumption of stochasticity. While durative actions or action repetition can be employed to have $\delta$-invariance, previous action repetition methods cannot immediately react to unexpected situations in stochastic environments. We thus propose a novel $\delta$-invariant method named Safe Action Repetition (SAR) applicable to any existing PG algorithm. SAR can handle the stochasticity of environments by adaptively reacting to changes in states during action repetition. We empirically show that our method is not only $\delta$-invariant but also robust to stochasticity, outperforming previous $\delta$-invariant approaches on eight MuJoCo environments with both deterministic and stochastic settings. Our code is available at https://vision.snu.ac.kr/projects/sar.