 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Monitoring Fidelity of Online Reinforcement Learning Algorithms in Clinical Trials
Feb 26, 2024
Online reinforcement learning (RL) algorithms offer great potential for personalizing treatment for participants in clinical trials. However, deploying an online, autonomous algorithm in the high-stakes healthcare setting makes quality control and data quality especially difficult to achieve. This paper proposes algorithm fidelity as a critical requirement for deploying online RL algorithms in clinical trials. It emphasizes the responsibility of the algorithm to (1) safeguard participants and (2) preserve the scientific utility of the data for post-trial analyses. We also present a framework for pre-deployment planning and real-time monitoring to help algorithm developers and clinical researchers ensure algorithm fidelity. To illustrate our framework's practical application, we present real-world examples from the Oralytics clinical trial. Since Spring 2023, this trial successfully deployed an autonomous, online RL algorithm to personalize behavioral interventions for participants at risk for dental disease.
UrbanGPT: Spatio-Temporal Large Language Models
Feb 25, 2024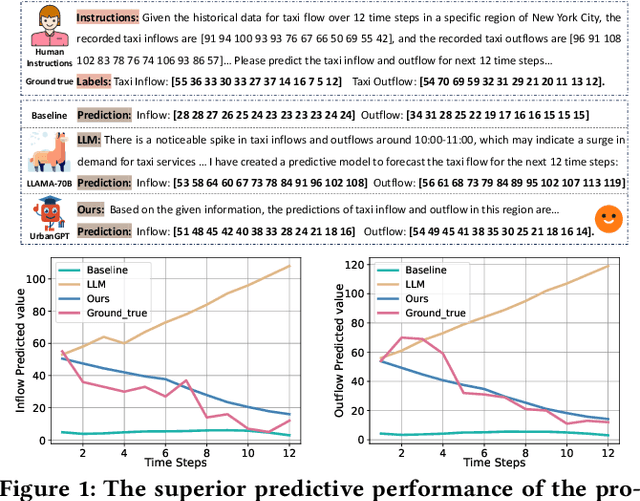
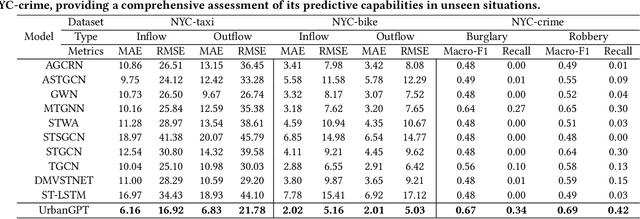
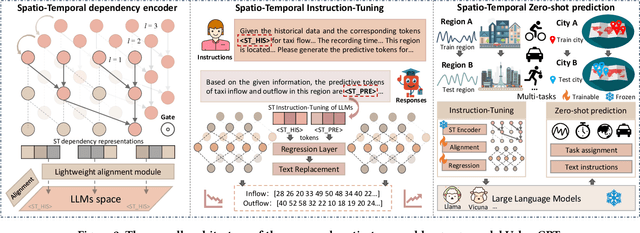
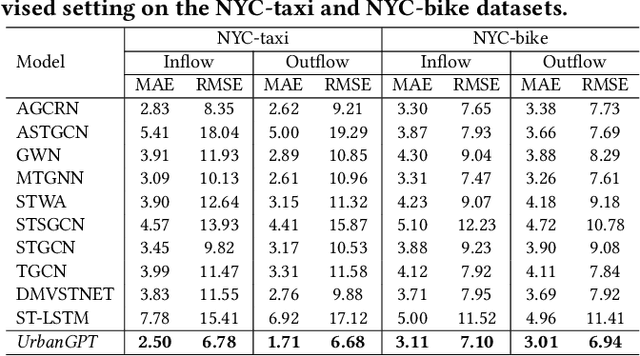
Spatio-temporal prediction aims to forecast and gain insights into the ever-changing dynamics of urban environments across both time and space. Its purpose is to anticipate future patterns, trends, and events in diverse facets of urban life, including transportation, population movement, and crime rates. Although numerous efforts have been dedicated to developing neural network techniques for accurate predictions on spatio-temporal data, it is important to note that many of these methods heavily depend on having sufficient labeled data to generate precise spatio-temporal representations. Unfortunately, the issue of data scarcity is pervasive in practical urban sensing scenarios. Consequently, it becomes necessary to build a spatio-temporal model with strong generalization capabilities across diverse spatio-temporal learning scenarios. Taking inspiration from the remarkable achievements of large language models (LLMs), our objective is to create a spatio-temporal LLM that can exhibit exceptional generalization capabilities across a wide range of downstream urban tasks. To achieve this objective, we present the UrbanGPT, which seamlessly integrates a spatio-temporal dependency encoder with the instruction-tuning paradigm. This integration enables LLMs to comprehend the complex inter-dependencies across time and space, facilitating more comprehensive and accurate predictions under data scarcity. To validate the effectiveness of our approach, we conduct extensive experiments on various public datasets, covering different spatio-temporal prediction tasks. The results consistently demonstrate that our UrbanGPT, with its carefully designed architecture, consistently outperforms state-of-the-art baselines. These findings highlight the potential of building large language models for spatio-temporal learning, particularly in zero-shot scenarios where labeled data is scarce.
MMSR: Symbolic Regression is a Multimodal Task
Feb 28, 2024Mathematical formulas are the crystallization of human wisdom in exploring the laws of nature for thousands of years. Describing the complex laws of nature with a concise mathematical formula is a constant pursuit of scientists and a great challenge for artificial intelligence. This field is called symbolic regression. Symbolic regression was originally formulated as a combinatorial optimization problem, and GP and reinforcement learning algorithms were used to solve it. However, GP is sensitive to hyperparameters, and these two types of algorithms are inefficient. To solve this problem, researchers treat the mapping from data to expressions as a translation problem. And the corresponding large-scale pre-trained model is introduced. However, the data and expression skeletons do not have very clear word correspondences as the two languages do. Instead, they are more like two modalities (e.g., image and text). Therefore, in this paper, we proposed MMSR. The SR problem is solved as a pure multimodal problem, and contrastive learning is also introduced in the training process for modal alignment to facilitate later modal feature fusion. It is worth noting that in order to better promote the modal feature fusion, we adopt the strategy of training contrastive learning loss and other losses at the same time, which only needs one-step training, instead of training contrastive learning loss first and then training other losses. Because our experiments prove training together can make the feature extraction module and feature fusion module running-in better. Experimental results show that compared with multiple large-scale pre-training baselines, MMSR achieves the most advanced results on multiple mainstream datasets including SRBench.
OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web
Feb 28, 2024For decades, human-computer interaction has fundamentally been manual. Even today, almost all productive work done on the computer necessitates human input at every step. Autonomous virtual agents represent an exciting step in automating many of these menial tasks. Virtual agents would empower users with limited technical proficiency to harness the full possibilities of computer systems. They could also enable the efficient streamlining of numerous computer tasks, ranging from calendar management to complex travel bookings, with minimal human intervention. In this paper, we introduce OmniACT, the first-of-a-kind dataset and benchmark for assessing an agent's capability to generate executable programs to accomplish computer tasks. Our scope extends beyond traditional web automation, covering a diverse range of desktop applications. The dataset consists of fundamental tasks such as "Play the next song", as well as longer horizon tasks such as "Send an email to John Doe mentioning the time and place to meet". Specifically, given a pair of screen image and a visually-grounded natural language task, the goal is to generate a script capable of fully executing the task. We run several strong baseline language model agents on our benchmark. The strongest baseline, GPT-4, performs the best on our benchmark However, its performance level still reaches only 15% of the human proficiency in generating executable scripts capable of completing the task, demonstrating the challenge of our task for conventional web agents. Our benchmark provides a platform to measure and evaluate the progress of language model agents in automating computer tasks and motivates future work towards building multimodal models that bridge large language models and the visual grounding of computer screens.
Comparative Analysis of XGBoost and Minirocket Algortihms for Human Activity Recognition
Feb 28, 2024Human Activity Recognition (HAR) has been extensively studied, with recent emphasis on the implementation of advanced Machine Learning (ML) and Deep Learning (DL) algorithms for accurate classification. This study investigates the efficacy of two ML algorithms, eXtreme Gradient Boosting (XGBoost) and MiniRocket, in the realm of HAR using data collected from smartphone sensors. The experiments are conducted on a dataset obtained from the UCI repository, comprising accelerometer and gyroscope signals captured from 30 volunteers performing various activities while wearing a smartphone. The dataset undergoes preprocessing, including noise filtering and feature extraction, before being utilized for training and testing the classifiers. Monte Carlo cross-validation is employed to evaluate the models' robustness. The findings reveal that both XGBoost and MiniRocket attain accuracy, F1 score, and AUC values as high as 0.99 in activity classification. XGBoost exhibits a slightly superior performance compared to MiniRocket. Notably, both algorithms surpass the performance of other ML and DL algorithms reported in the literature for HAR tasks. Additionally, the study compares the computational efficiency of the two algorithms, revealing XGBoost's advantage in terms of training time. Furthermore, the performance of MiniRocket, which achieves accuracy and F1 values of 0.94, and an AUC value of 0.96 using raw data and utilizing only one channel from the sensors, highlights the potential of directly leveraging unprocessed signals. It also suggests potential advantages that could be gained by utilizing sensor fusion or channel fusion techniques. Overall, this research sheds light on the effectiveness and computational characteristics of XGBoost and MiniRocket in HAR tasks, providing insights for future studies in activity recognition using smartphone sensor data.
Verifiable Boosted Tree Ensembles
Feb 22, 2024Verifiable learning advocates for training machine learning models amenable to efficient security verification. Prior research demonstrated that specific classes of decision tree ensembles -- called large-spread ensembles -- allow for robustness verification in polynomial time against any norm-based attacker. This study expands prior work on verifiable learning from basic ensemble methods (i.e., hard majority voting) to advanced boosted tree ensembles, such as those trained using XGBoost or LightGBM. Our formal results indicate that robustness verification is achievable in polynomial time when considering attackers based on the $L_\infty$-norm, but remains NP-hard for other norm-based attackers. Nevertheless, we present a pseudo-polynomial time algorithm to verify robustness against attackers based on the $L_p$-norm for any $p \in \mathbb{N} \cup \{0\}$, which in practice grants excellent performance. Our experimental evaluation shows that large-spread boosted ensembles are accurate enough for practical adoption, while being amenable to efficient security verification.
Debiased Model-based Interactive Recommendation
Feb 24, 2024Existing model-based interactive recommendation systems are trained by querying a world model to capture the user preference, but learning the world model from historical logged data will easily suffer from bias issues such as popularity bias and sampling bias. This is why some debiased methods have been proposed recently. However, two essential drawbacks still remain: 1) ignoring the dynamics of the time-varying popularity results in a false reweighting of items. 2) taking the unknown samples as negative samples in negative sampling results in the sampling bias. To overcome these two drawbacks, we develop a model called \textbf{i}dentifiable \textbf{D}ebiased \textbf{M}odel-based \textbf{I}nteractive \textbf{R}ecommendation (\textbf{iDMIR} in short). In iDMIR, for the first drawback, we devise a debiased causal world model based on the causal mechanism of the time-varying recommendation generation process with identification guarantees; for the second drawback, we devise a debiased contrastive policy, which coincides with the debiased contrastive learning and avoids sampling bias. Moreover, we demonstrate that the proposed method not only outperforms several latest interactive recommendation algorithms but also enjoys diverse recommendation performance.
Replicable Learning of Large-Margin Halfspaces
Feb 21, 2024We provide efficient replicable algorithms for the problem of learning large-margin halfspaces. Our results improve upon the algorithms provided by Impagliazzo, Lei, Pitassi, and Sorrell [STOC, 2022]. We design the first dimension-independent replicable algorithms for this task which runs in polynomial time, is proper, and has strictly improved sample complexity compared to the one achieved by Impagliazzo et al. [2022] with respect to all the relevant parameters. Moreover, our first algorithm has sample complexity that is optimal with respect to the accuracy parameter $\epsilon$. We also design an SGD-based replicable algorithm that, in some parameters' regimes, achieves better sample and time complexity than our first algorithm. Departing from the requirement of polynomial time algorithms, using the DP-to-Replicability reduction of Bun, Gaboardi, Hopkins, Impagliazzo, Lei, Pitassi, Sorrell, and Sivakumar [STOC, 2023], we show how to obtain a replicable algorithm for large-margin halfspaces with improved sample complexity with respect to the margin parameter $\tau$, but running time doubly exponential in $1/\tau^2$ and worse sample complexity dependence on $\epsilon$ than one of our previous algorithms. We then design an improved algorithm with better sample complexity than all three of our previous algorithms and running time exponential in $1/\tau^{2}$.
RobustTSF: Towards Theory and Design of Robust Time Series Forecasting with Anomalies
Feb 03, 2024Time series forecasting is an important and forefront task in many real-world applications. However, most of time series forecasting techniques assume that the training data is clean without anomalies. This assumption is unrealistic since the collected time series data can be contaminated in practice. The forecasting model will be inferior if it is directly trained by time series with anomalies. Thus it is essential to develop methods to automatically learn a robust forecasting model from the contaminated data. In this paper, we first statistically define three types of anomalies, then theoretically and experimentally analyze the loss robustness and sample robustness when these anomalies exist. Based on our analyses, we propose a simple and efficient algorithm to learn a robust forecasting model. Extensive experiments show that our method is highly robust and outperforms all existing approaches. The code is available at https://github.com/haochenglouis/RobustTSF.
CFTM: Continuous time fractional topic model
Jan 29, 2024In this paper, we propose the Continuous Time Fractional Topic Model (cFTM), a new method for dynamic topic modeling. This approach incorporates fractional Brownian motion~(fBm) to effectively identify positive or negative correlations in topic and word distribution over time, revealing long-term dependency or roughness. Our theoretical analysis shows that the cFTM can capture these long-term dependency or roughness in both topic and word distributions, mirroring the main characteristics of fBm. Moreover, we prove that the parameter estimation process for the cFTM is on par with that of LDA, traditional topic models. To demonstrate the cFTM's property, we conduct empirical study using economic news articles. The results from these tests support the model's ability to identify and track long-term dependency or roughness in topics over time.