 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Learning over a Wireless Network with Non-coherent Majority Vote Computation
Sep 10, 2022

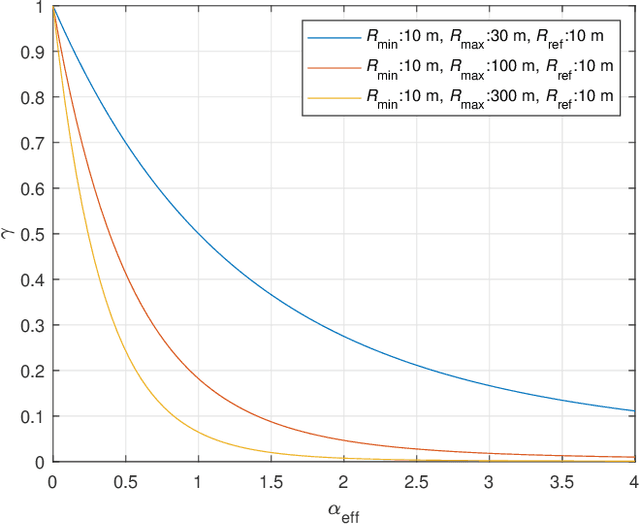
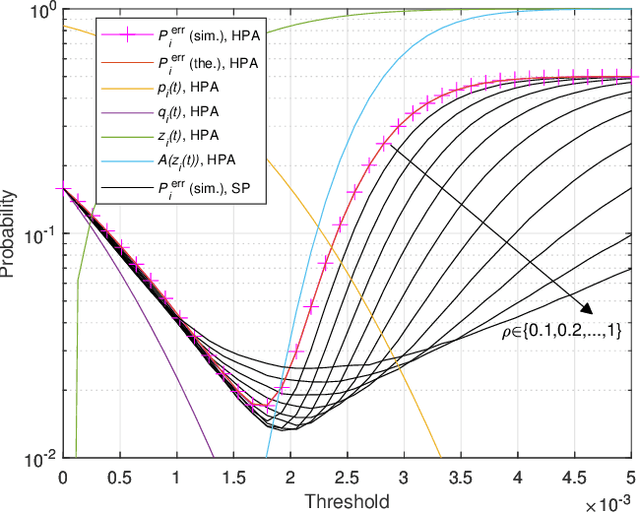

In this study, we propose an over-the-air computation (OAC) scheme to calculate the majority vote (MV) for federated edge learning (FEEL). With the proposed approach, edge devices (EDs) transmit the signs of local stochastic gradients, i.e., votes, by activating one of two orthogonal resources. The MVs at the edge server (ES) are obtained with non-coherent detectors by exploiting the accumulations on the resources. Hence, the proposed scheme eliminates the need for channel state information (CSI) at the EDs and ES. In this study, we analyze various gradient-encoding strategies through the weight functions and waveform configurations over orthogonal frequency division multiplexing (OFDM). We show that specific weight functions that enable absentee EDs (i.e., hard-coded participation with absentees (HPA)) or weighted votes (i.e., soft-coded participation (SP)) can substantially reduce the probability of detecting the incorrect MV. By taking path loss, power control, cell size, and fading channel into account, we prove the convergence of the distributed learning for a non-convex function for HPA. Through simulations, we show that the proposed scheme with HPA and SP can provide high test accuracy even when the time-synchronization and the power control are not ideal under heterogeneous data distribution scenarios.
A new way of video compression via forward-referencing using deep learning
Aug 13, 2022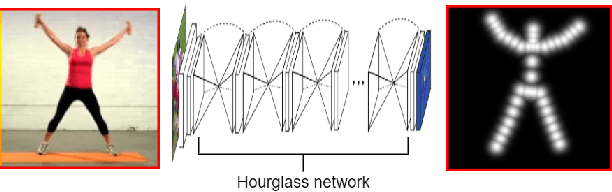
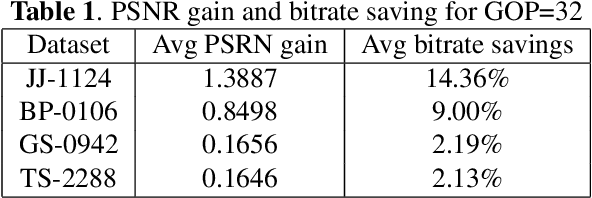
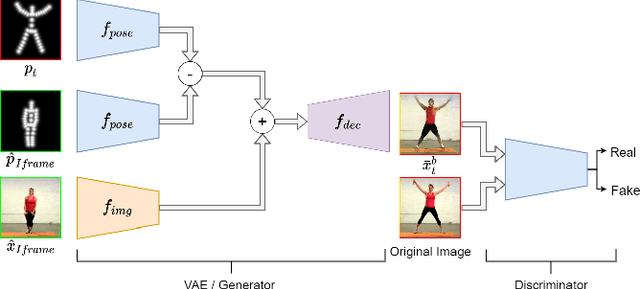
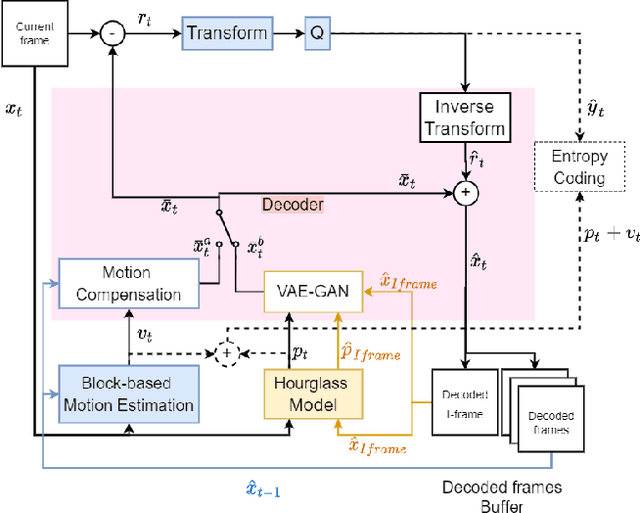
To exploit high temporal correlations in video frames of the same scene, the current frame is predicted from the already-encoded reference frames using block-based motion estimation and compensation techniques. While this approach can efficiently exploit the translation motion of the moving objects, it is susceptible to other types of affine motion and object occlusion/deocclusion. Recently, deep learning has been used to model the high-level structure of human pose in specific actions from short videos and then generate virtual frames in future time by predicting the pose using a generative adversarial network (GAN). Therefore, modelling the high-level structure of human pose is able to exploit semantic correlation by predicting human actions and determining its trajectory. Video surveillance applications will benefit as stored big surveillance data can be compressed by estimating human pose trajectories and generating future frames through semantic correlation. This paper explores a new way of video coding by modelling human pose from the already-encoded frames and using the generated frame at the current time as an additional forward-referencing frame. It is expected that the proposed approach can overcome the limitations of the traditional backward-referencing frames by predicting the blocks containing the moving objects with lower residuals. Experimental results show that the proposed approach can achieve on average up to 2.83 dB PSNR gain and 25.93\% bitrate savings for high motion video sequences
Visual Prompting via Image Inpainting
Sep 01, 2022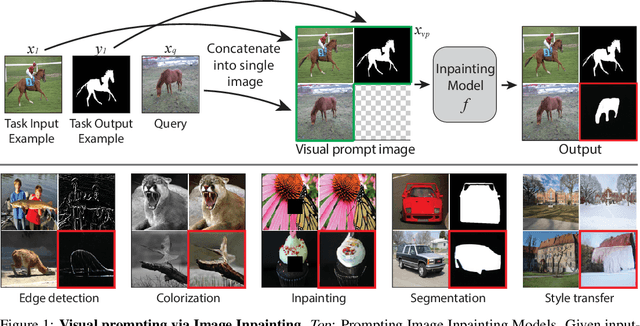
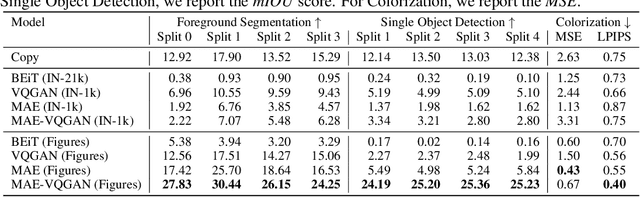
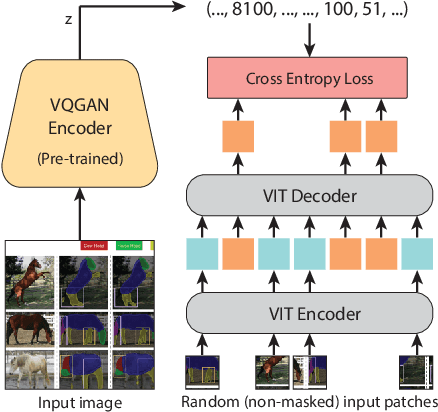
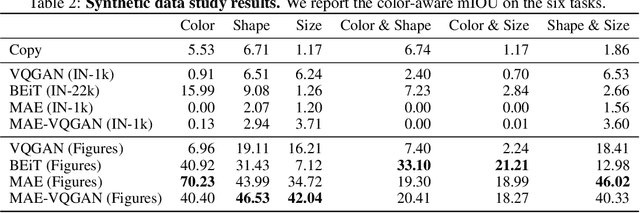
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the output image, consistent with the given examples. We show that posing this problem as simple image inpainting - literally just filling in a hole in a concatenated visual prompt image - turns out to be surprisingly effective, provided that the inpainting algorithm has been trained on the right data. We train masked auto-encoders on a new dataset that we curated - 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream image-to-image tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
Simple and Effective Gradient-Based Tuning of Sequence-to-Sequence Models
Sep 10, 2022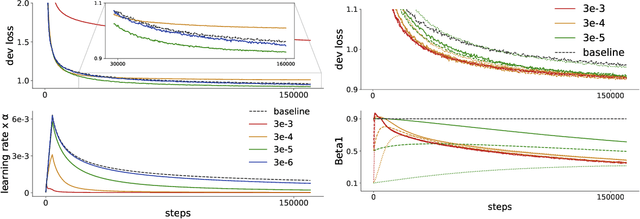
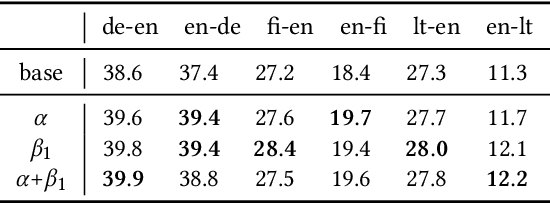
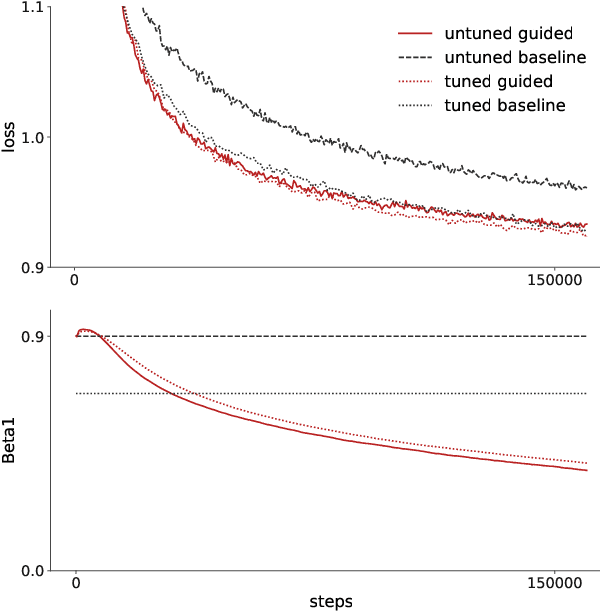
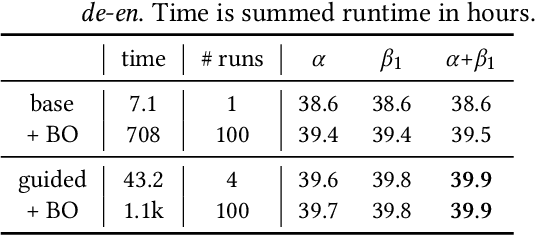
Recent trends towards training ever-larger language models have substantially improved machine learning performance across linguistic tasks. However, the huge cost of training larger models can make tuning them prohibitively expensive, motivating the study of more efficient methods. Gradient-based hyper-parameter optimization offers the capacity to tune hyper-parameters during training, yet has not previously been studied in a sequence-to-sequence setting. We apply a simple and general gradient-based hyperparameter optimization method to sequence-to-sequence tasks for the first time, demonstrating both efficiency and performance gains over strong baselines for both Neural Machine Translation and Natural Language Understanding (NLU) tasks (via T5 pretraining). For translation, we show the method generalizes across language pairs, is more efficient than Bayesian hyper-parameter optimization, and that learned schedules for some hyper-parameters can out-perform even optimal constant-valued tuning. For T5, we show that learning hyper-parameters during pretraining can improve performance across downstream NLU tasks. When learning multiple hyper-parameters concurrently, we show that the global learning rate can follow a schedule over training that improves performance and is not explainable by the `short-horizon bias' of greedy methods \citep{wu2018}. We release the code used to facilitate further research.
Space-Time Adaptive Processing Using Random Matrix Theory Under Limited Training Samples
Feb 10, 2022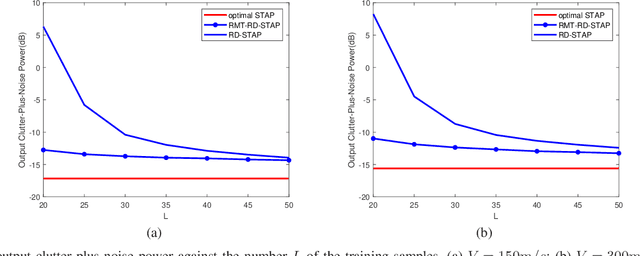
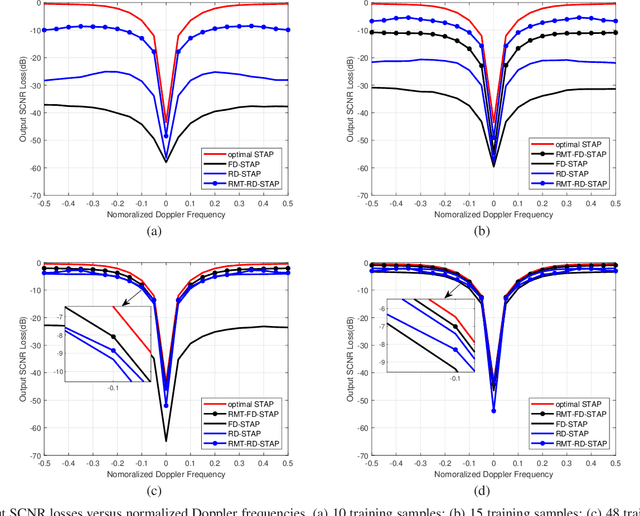
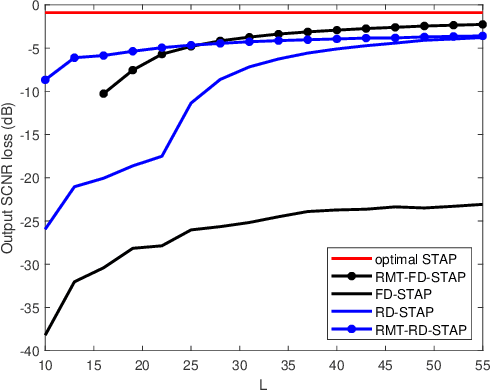
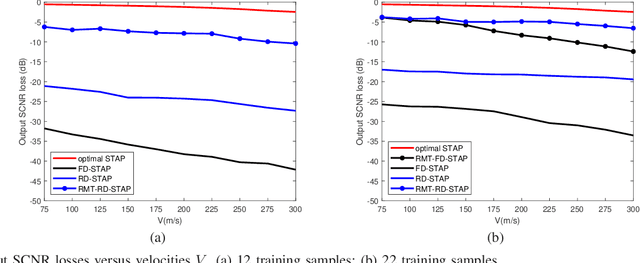
Space-time adaptive processing (STAP) is one of the most effective approaches to suppressing ground clutters in airborne radar systems. It basically takes two forms, i.e., full-dimension STAP (FD-STAP) and reduced-dimension STAP (RD-STAP). When the numbers of clutter training samples are less than two times their respective system degrees-of-freedom (DOF), the performances of both FD-STAP and RD-STAP degrade severely due to inaccurate clutter estimation. To enhance STAP performance under the limited training samples, this paper develops a STAP theory with random matrix theory (RMT). By minimizing the output clutter-plus-noise power, the estimate of the inversion of clutter plus noise covariance matrix (CNCM) can be obtained through optimally manipulating its eigenvalues, and thus producing the optimal STAP weight vector. Two STAP algorithms, FD-STAP using RMT (RMT-FD-STAP) and RD-STAP using RMT (RMT-RD-STAP), are proposed. It is found that both RMT-FD-STAP and RMT-RD-STAP greatly outperform other-related STAP algorithms when the numbers of training samples are larger than their respective clutter DOFs, which are much less than the corresponding system DOFs. Theoretical analyses and simulation demonstrate the effectiveness and the performance advantages of the proposed STAP algorithms.
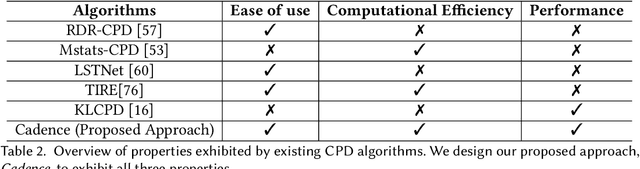
Cadence: A Practical Time-series Partitioning Algorithm for Unlabeled IoT Sensor Streams
Dec 06, 2021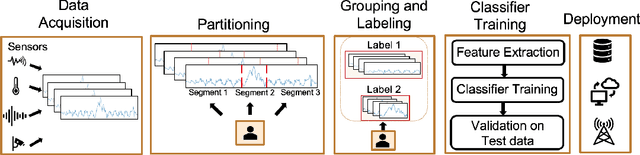
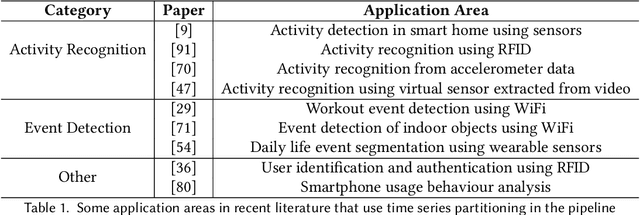
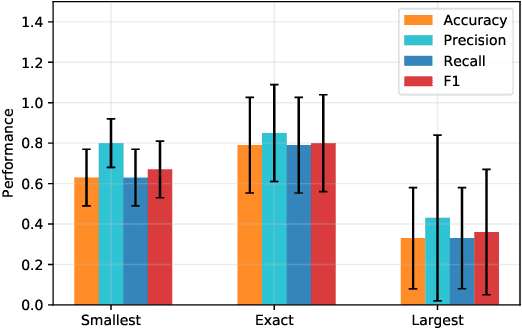
Timeseries partitioning is an essential step in most machine-learning driven, sensor-based IoT applications. This paper introduces a sample-efficient, robust, time-series segmentation model and algorithm. We show that by learning a representation specifically with the segmentation objective based on maximum mean discrepancy (MMD), our algorithm can robustly detect time-series events across different applications. Our loss function allows us to infer whether consecutive sequences of samples are drawn from the same distribution (null hypothesis) and determines the change-point between pairs that reject the null hypothesis (i.e., come from different distributions). We demonstrate its applicability in a real-world IoT deployment for ambient-sensing based activity recognition. Moreover, while many works on change-point detection exist in the literature, our model is significantly simpler and matches or outperforms state-of-the-art methods. We can fully train our model in 9-93 seconds on average with little variation in hyperparameters for data across different applications.
ASAT: Adaptively Scaled Adversarial Training in Time Series
Aug 20, 2021

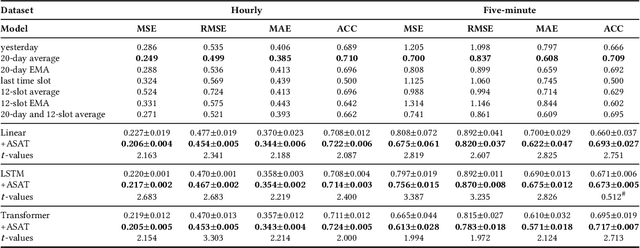

Adversarial training is a method for enhancing neural networks to improve the robustness against adversarial examples. Besides the security concerns of potential adversarial examples, adversarial training can also improve the performance of the neural networks, train robust neural networks, and provide interpretability for neural networks. In this work, we take the first step to introduce adversarial training in time series analysis by taking the finance field as an example. Rethinking existing researches of adversarial training, we propose the adaptively scaled adversarial training (ASAT) in time series analysis, by treating data at different time slots with time-dependent importance weights. Experimental results show that the proposed ASAT can improve both the accuracy and the adversarial robustness of neural networks. Besides enhancing neural networks, we also propose the dimension-wise adversarial sensitivity indicator to probe the sensitivities and importance of input dimensions. With the proposed indicator, we can explain the decision bases of black box neural networks.
Natural Language Inference Prompts for Zero-shot Emotion Classification in Text across Corpora
Sep 15, 2022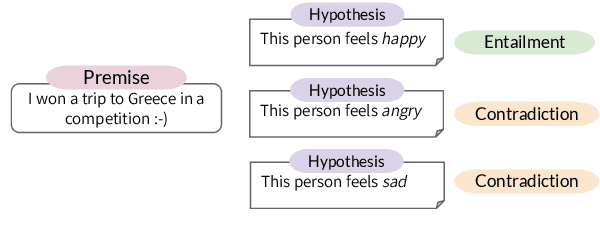


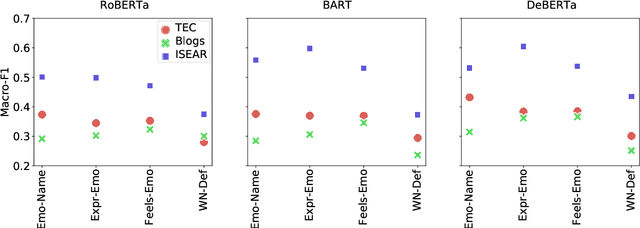
Within textual emotion classification, the set of relevant labels depends on the domain and application scenario and might not be known at the time of model development. This conflicts with the classical paradigm of supervised learning in which the labels need to be predefined. A solution to obtain a model with a flexible set of labels is to use the paradigm of zero-shot learning as a natural language inference task, which in addition adds the advantage of not needing any labeled training data. This raises the question how to prompt a natural language inference model for zero-shot learning emotion classification. Options for prompt formulations include the emotion name anger alone or the statement "This text expresses anger". With this paper, we analyze how sensitive a natural language inference-based zero-shot-learning classifier is to such changes to the prompt under consideration of the corpus: How carefully does the prompt need to be selected? We perform experiments on an established set of emotion datasets presenting different language registers according to different sources (tweets, events, blogs) with three natural language inference models and show that indeed the choice of a particular prompt formulation needs to fit to the corpus. We show that this challenge can be tackled with combinations of multiple prompts. Such ensemble is more robust across corpora than individual prompts and shows nearly the same performance as the individual best prompt for a particular corpus.
Subspace Graph Physics: Real-Time Rigid Body-Driven Granular Flow Simulation
Nov 18, 2021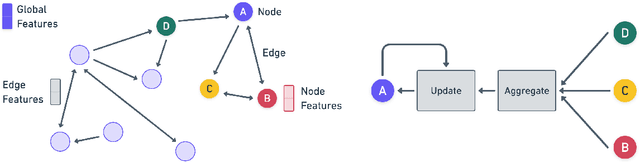
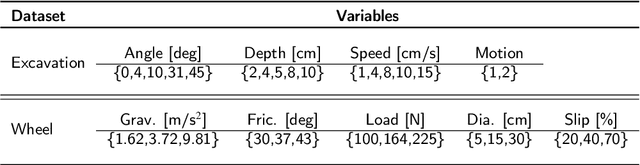
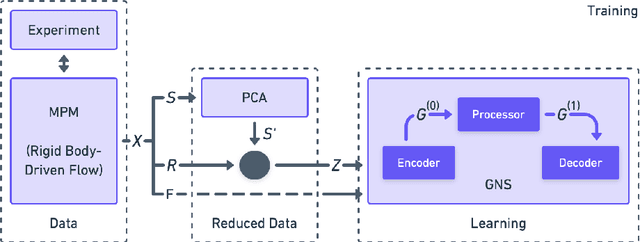
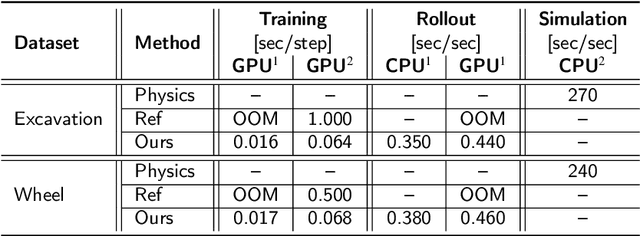
An important challenge in robotics is understanding the interactions between robots and deformable terrains that consist of granular material. Granular flows and their interactions with rigid bodies still pose several open questions. A promising direction for accurate, yet efficient, modeling is using continuum methods. Also, a new direction for real-time physics modeling is the use of deep learning. This research advances machine learning methods for modeling rigid body-driven granular flows, for application to terrestrial industrial machines as well as space robotics (where the effect of gravity is an important factor). In particular, this research considers the development of a subspace machine learning simulation approach. To generate training datasets, we utilize our high-fidelity continuum method, material point method (MPM). Principal component analysis (PCA) is used to reduce the dimensionality of data. We show that the first few principal components of our high-dimensional data keep almost the entire variance in data. A graph network simulator (GNS) is trained to learn the underlying subspace dynamics. The learned GNS is then able to predict particle positions and interaction forces with good accuracy. More importantly, PCA significantly enhances the time and memory efficiency of GNS in both training and rollout. This enables GNS to be trained using a single desktop GPU with moderate VRAM. This also makes the GNS real-time on large-scale 3D physics configurations (700x faster than our continuum method).
On Sparse High-Dimensional Graphical Model Learning For Dependent Time Series
Nov 15, 2021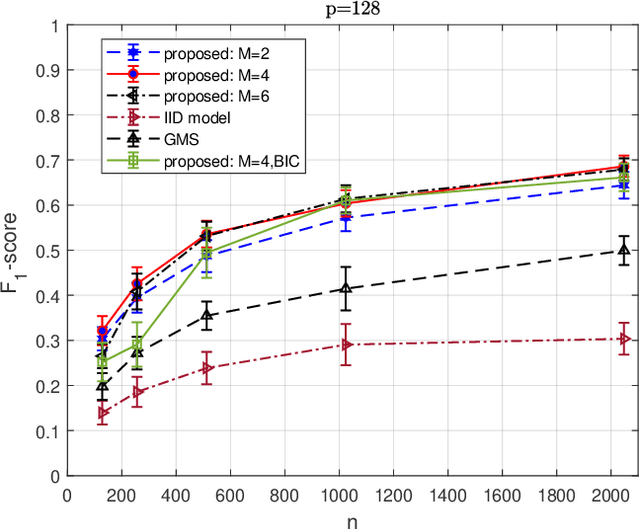
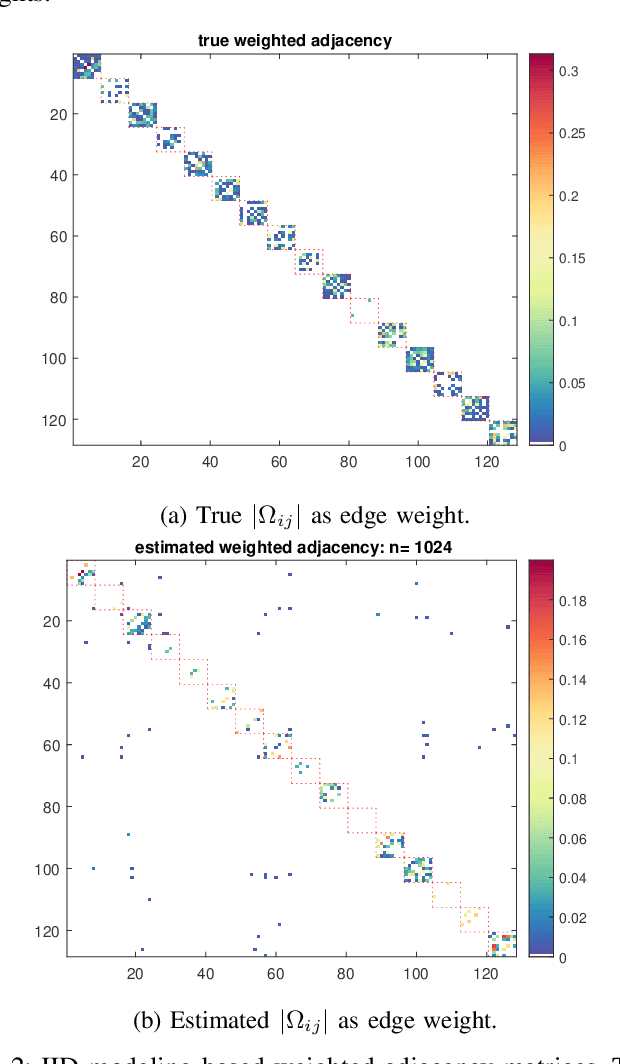
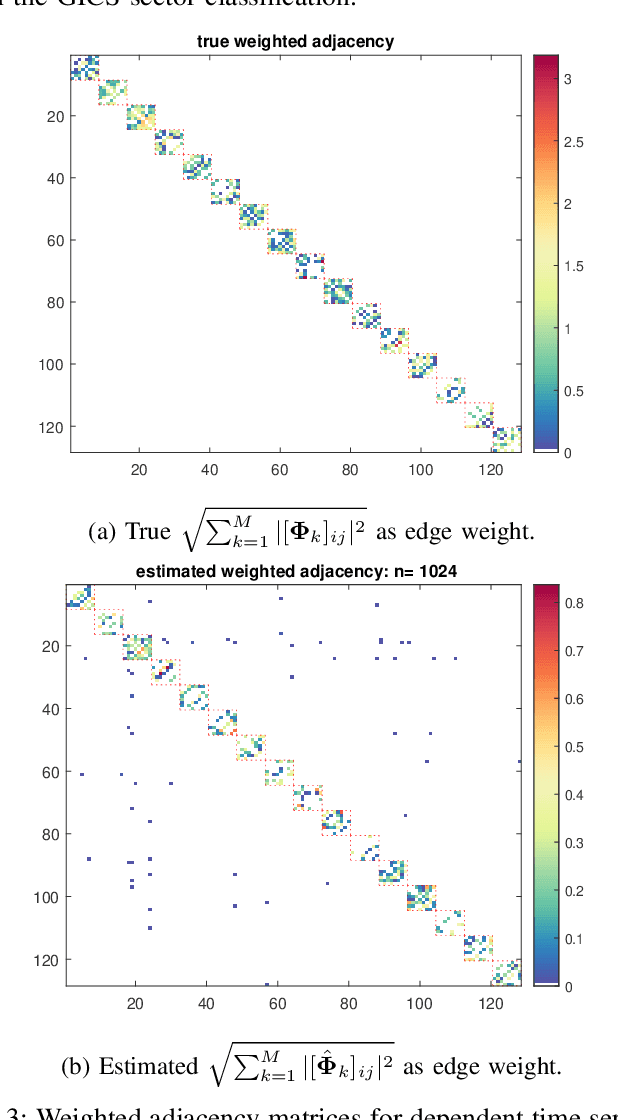
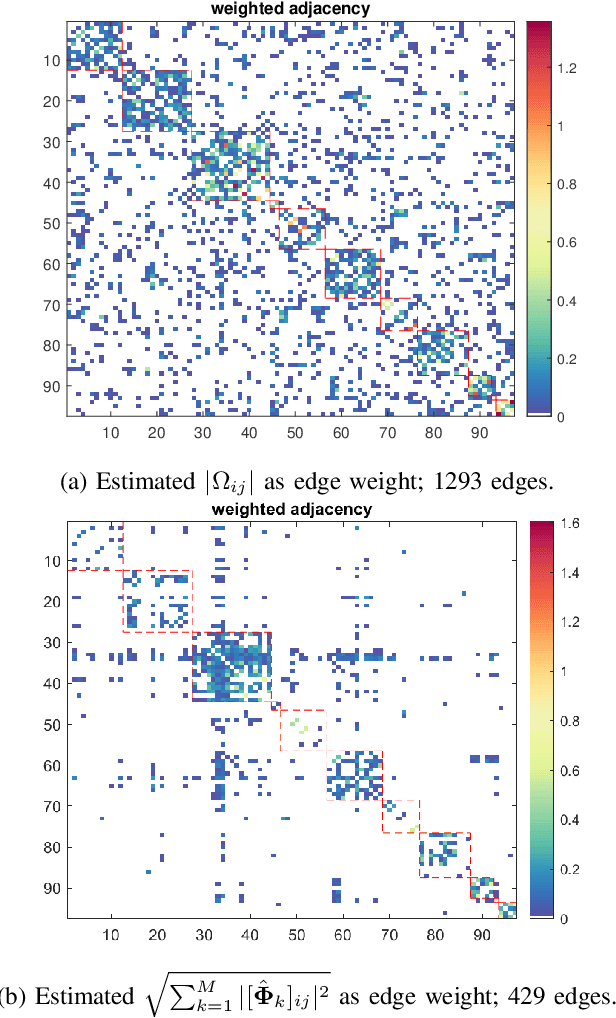
We consider the problem of inferring the conditional independence graph (CIG) of a sparse, high-dimensional stationary multivariate Gaussian time series. A sparse-group lasso-based frequency-domain formulation of the problem based on frequency-domain sufficient statistic for the observed time series is presented. We investigate an alternating direction method of multipliers (ADMM) approach for optimization of the sparse-group lasso penalized log-likelihood. We provide sufficient conditions for convergence in the Frobenius norm of the inverse PSD estimators to the true value, jointly across all frequencies, where the number of frequencies are allowed to increase with sample size. This results also yields a rate of convergence. We also empirically investigate selection of the tuning parameters based on Bayesian information criterion, and illustrate our approach using numerical examples utilizing both synthetic and real data.