 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interpretations Steered Network Pruning via Amortized Inferred Saliency Maps
Sep 07, 2022

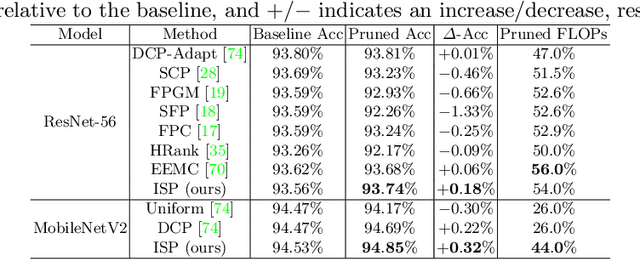
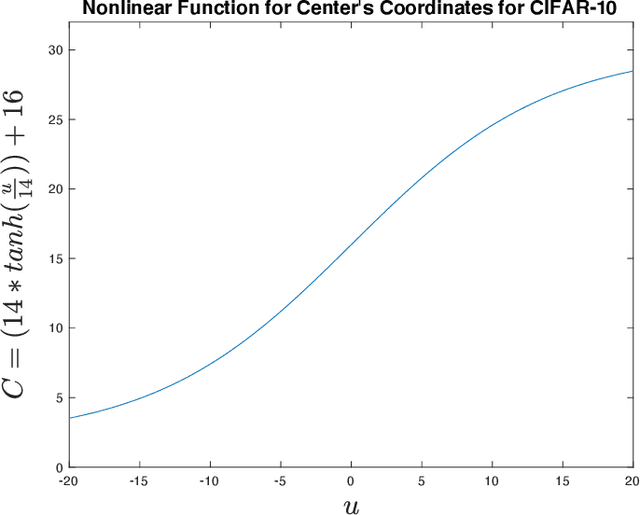
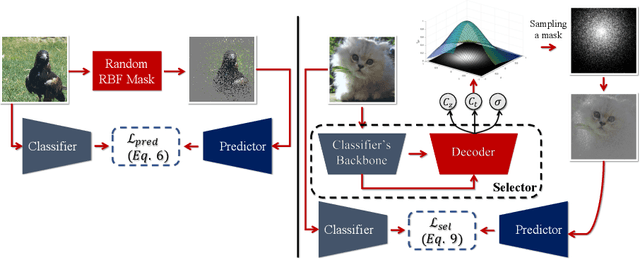
Convolutional Neural Networks (CNNs) compression is crucial to deploying these models in edge devices with limited resources. Existing channel pruning algorithms for CNNs have achieved plenty of success on complex models. They approach the pruning problem from various perspectives and use different metrics to guide the pruning process. However, these metrics mainly focus on the model's `outputs' or `weights' and neglect its `interpretations' information. To fill in this gap, we propose to address the channel pruning problem from a novel perspective by leveraging the interpretations of a model to steer the pruning process, thereby utilizing information from both inputs and outputs of the model. However, existing interpretation methods cannot get deployed to achieve our goal as either they are inefficient for pruning or may predict non-coherent explanations. We tackle this challenge by introducing a selector model that predicts real-time smooth saliency masks for pruned models. We parameterize the distribution of explanatory masks by Radial Basis Function (RBF)-like functions to incorporate geometric prior of natural images in our selector model's inductive bias. Thus, we can obtain compact representations of explanations to reduce the computational costs of our pruning method. We leverage our selector model to steer the network pruning by maximizing the similarity of explanatory representations for the pruned and original models. Extensive experiments on CIFAR-10 and ImageNet benchmark datasets demonstrate the efficacy of our proposed method. Our implementations are available at \url{https://github.com/Alii-Ganjj/InterpretationsSteeredPruning}
Offloading Algorithms for Maximizing Inference Accuracy on Edge Device Under a Time Constraint
Dec 21, 2021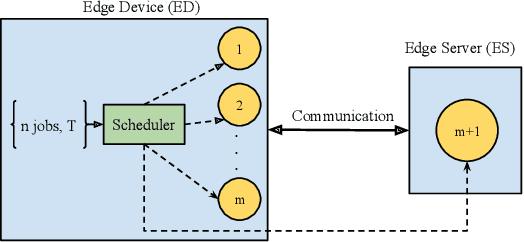
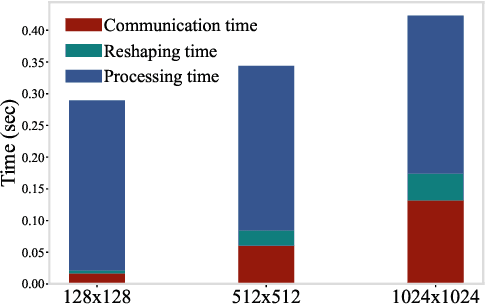
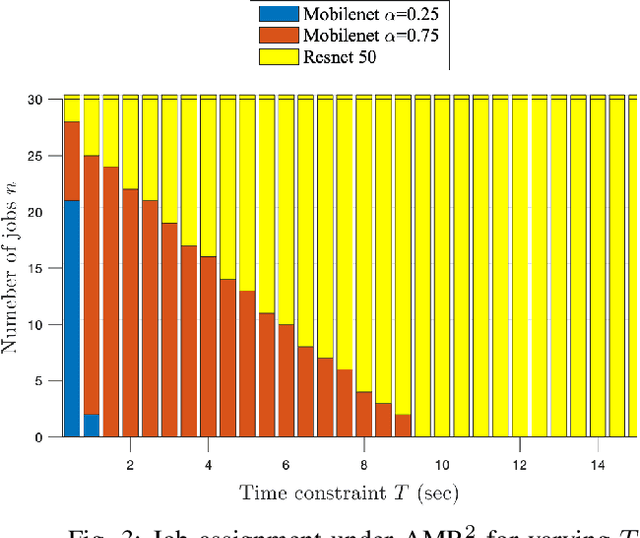
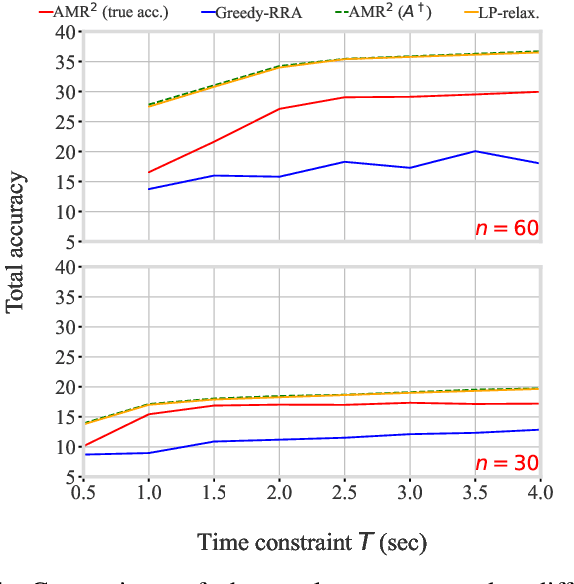
With the emergence of edge computing, the problem of offloading jobs between an Edge Device (ED) and an Edge Server (ES) received significant attention in the past. Motivated by the fact that an increasing number of applications are using Machine Learning (ML) inference, we study the problem of offloading inference jobs by considering the following novel aspects: 1) in contrast to a typical computational job, the processing time of an inference job depends on the size of the ML model, and 2) recently proposed Deep Neural Networks (DNNs) for resource-constrained devices provide the choice of scaling the model size. We formulate an assignment problem with the aim of maximizing the total inference accuracy of n data samples available at the ED, subject to a time constraint T on the makespan. We propose an approximation algorithm AMR2, and prove that it results in a makespan at most 2T, and achieves a total accuracy that is lower by a small constant from optimal total accuracy. As proof of concept, we implemented AMR2 on a Raspberry Pi, equipped with MobileNet, and is connected to a server equipped with ResNet, and studied the total accuracy and makespan performance of AMR2 for image classification application.
On the Convergence of Monte Carlo UCB for Random-Length Episodic MDPs
Sep 07, 2022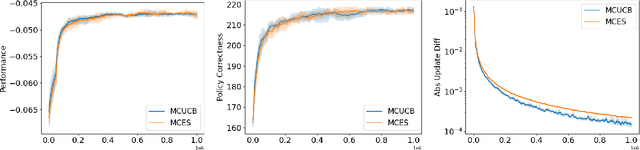
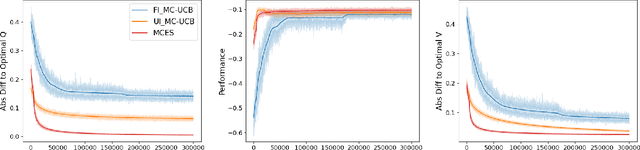
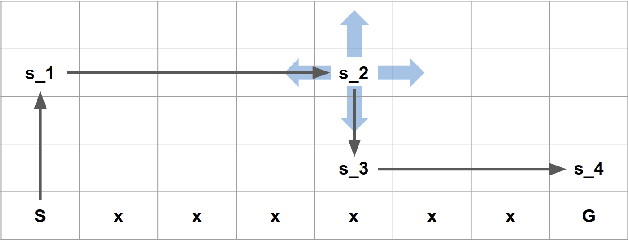
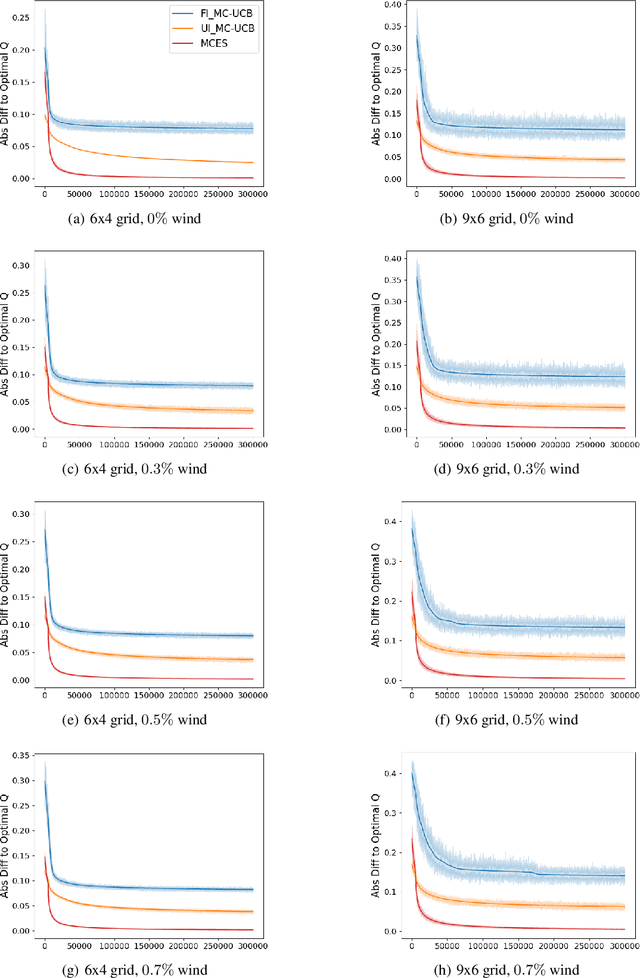
In reinforcement learning, Monte Carlo algorithms update the Q function by averaging the episodic returns. In the Monte Carlo UCB (MC-UCB) algorithm, the action taken in each state is the action that maximizes the Q function plus a UCB exploration term, which biases the choice of actions to those that have been chosen less frequently. Although there has been significant work on establishing regret bounds for MC-UCB, most of that work has been focused on finite-horizon versions of the problem, for which each episode terminates after a constant number of steps. For such finite-horizon problems, the optimal policy depends both on the current state and the time within the episode. However, for many natural episodic problems, such as games like Go and Chess and robotic tasks, the episode is of random length and the optimal policy is stationary. For such environments, it is an open question whether the Q-function in MC-UCB will converge to the optimal Q function; we conjecture that, unlike Q-learning, it does not converge for all MDPs. We nevertheless show that for a large class of MDPs, which includes stochastic MDPs such as blackjack and deterministic MDPs such as Go, the Q-function in MC-UCB converges almost surely to the optimal Q function. An immediate corollary of this result is that it also converges almost surely for all finite-horizon MDPs. We also provide numerical experiments, providing further insights into MC-UCB.
KDD CUP 2022 Wind Power Forecasting Team 88VIP Solution
Aug 18, 2022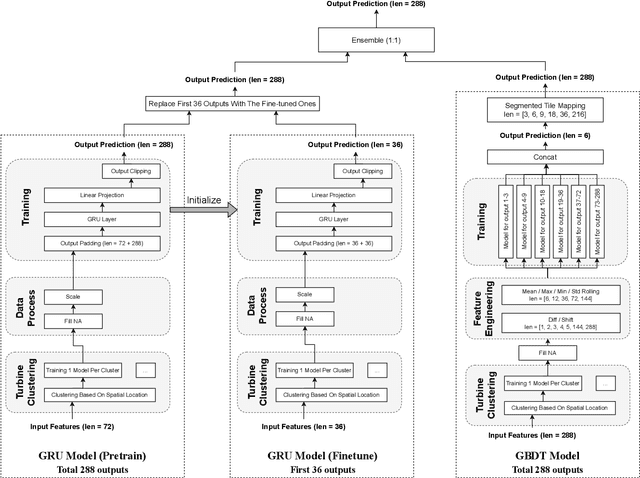

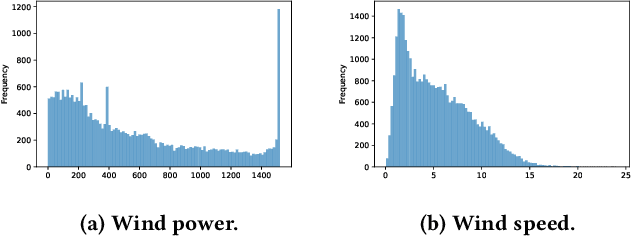

KDD CUP 2022 proposes a time-series forecasting task on spatial dynamic wind power dataset, in which the participants are required to predict the future generation given the historical context factors. The evaluation metrics contain RMSE and MAE. This paper describes the solution of Team 88VIP, which mainly comprises two types of models: a gradient boosting decision tree to memorize the basic data patterns and a recurrent neural network to capture the deep and latent probabilistic transitions. Ensembling these models contributes to tackle the fluctuation of wind power, and training submodels targets on the distinguished properties in heterogeneous timescales of forecasting, from minutes to days. In addition, feature engineering, imputation techniques and the design of offline evaluation are also described in details. The proposed solution achieves an overall online score of -45.213 in Phase 3.
Annealing Optimization for Progressive Learning with Stochastic Approximation
Sep 06, 2022
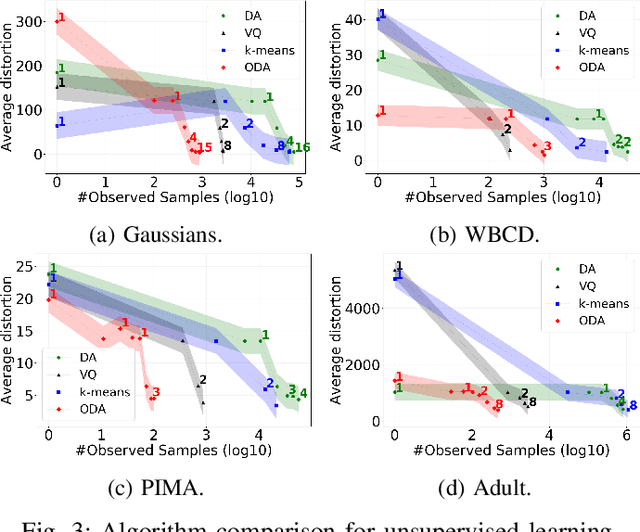
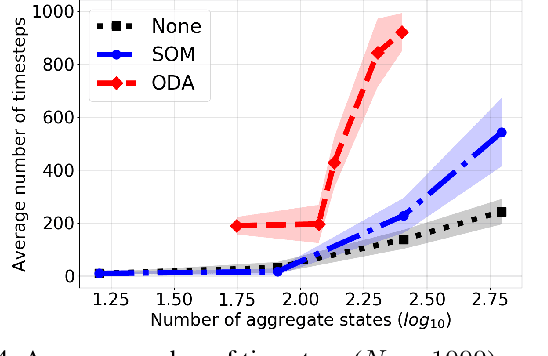
In this work, we introduce a learning model designed to meet the needs of applications in which computational resources are limited, and robustness and interpretability are prioritized. Learning problems can be formulated as constrained stochastic optimization problems, with the constraints originating mainly from model assumptions that define a trade-off between complexity and performance. This trade-off is closely related to over-fitting, generalization capacity, and robustness to noise and adversarial attacks, and depends on both the structure and complexity of the model, as well as the properties of the optimization methods used. We develop an online prototype-based learning algorithm based on annealing optimization that is formulated as an online gradient-free stochastic approximation algorithm. The learning model can be viewed as an interpretable and progressively growing competitive-learning neural network model to be used for supervised, unsupervised, and reinforcement learning. The annealing nature of the algorithm contributes to minimal hyper-parameter tuning requirements, poor local minima prevention, and robustness with respect to the initial conditions. At the same time, it provides online control over the performance-complexity trade-off by progressively increasing the complexity of the learning model as needed, through an intuitive bifurcation phenomenon. Finally, the use of stochastic approximation enables the study of the convergence of the learning algorithm through mathematical tools from dynamical systems and control, and allows for its integration with reinforcement learning algorithms, constructing an adaptive state-action aggregation scheme.
Automated machine learning for borehole resistivity measurements
Jul 20, 2022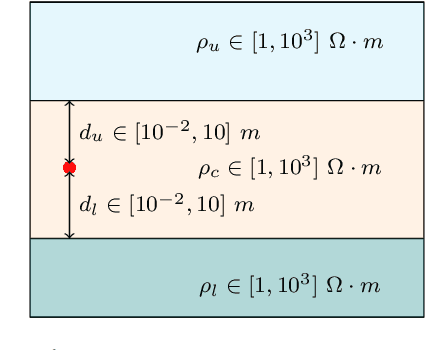
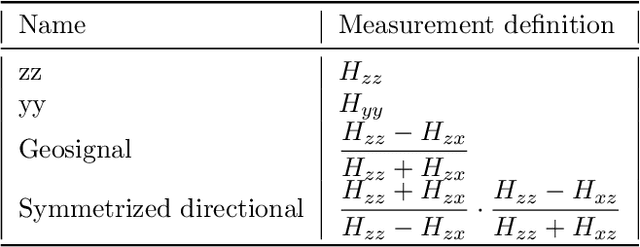
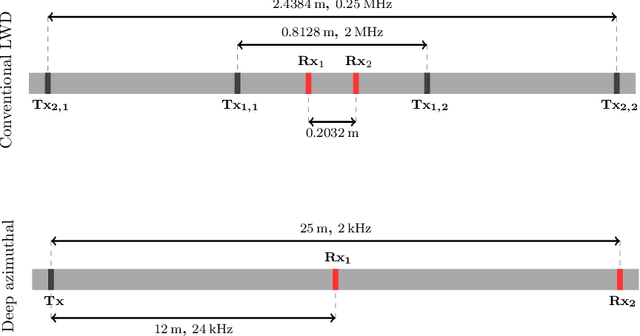

Deep neural networks (DNNs) offer a real-time solution for the inversion of borehole resistivity measurements to approximate forward and inverse operators. It is possible to use extremely large DNNs to approximate the operators, but it demands a considerable training time. Moreover, evaluating the network after training also requires a significant amount of memory and processing power. In addition, we may overfit the model. In this work, we propose a scoring function that accounts for the accuracy and size of the DNNs compared to a reference DNN that provides a good approximation for the operators. Using this scoring function, we use DNN architecture search algorithms to obtain a quasi-optimal DNN smaller than the reference network; hence, it requires less computational effort during training and evaluation. The quasi-optimal DNN delivers comparable accuracy to the original large DNN.
Transformer Quality in Linear Time
Feb 21, 2022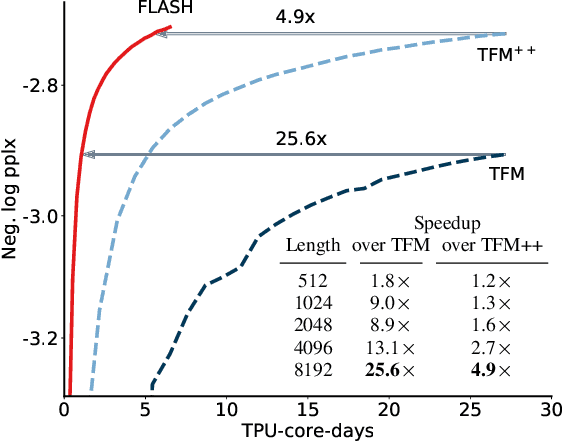
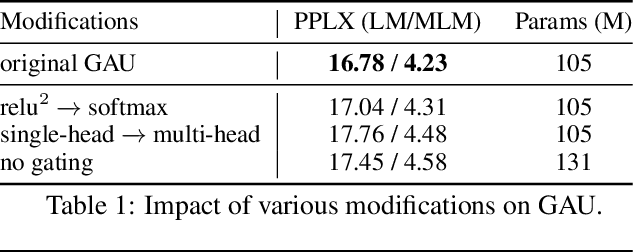
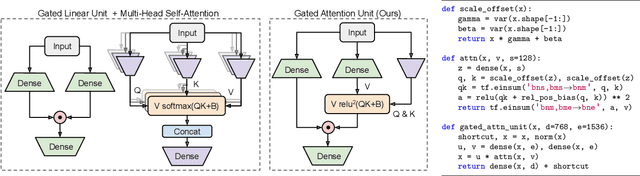

We revisit the design choices in Transformers, and propose methods to address their weaknesses in handling long sequences. First, we propose a simple layer named gated attention unit, which allows the use of a weaker single-head attention with minimal quality loss. We then propose a linear approximation method complementary to this new layer, which is accelerator-friendly and highly competitive in quality. The resulting model, named FLASH, matches the perplexity of improved Transformers over both short (512) and long (8K) context lengths, achieving training speedups of up to 4.9$\times$ on Wiki-40B and 12.1$\times$ on PG-19 for auto-regressive language modeling, and 4.8$\times$ on C4 for masked language modeling.
Little Help Makes a Big Difference: Leveraging Active Learning to Improve Unsupervised Time Series Anomaly Detection
Jan 25, 2022
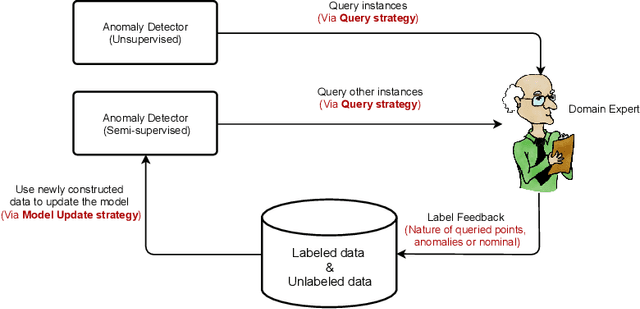
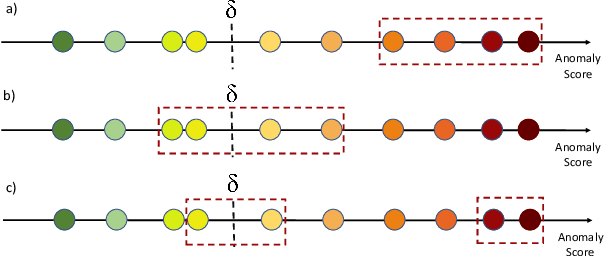

Key Performance Indicators (KPI), which are essentially time series data, have been widely used to indicate the performance of telecom networks. Based on the given KPIs, a large set of anomaly detection algorithms have been deployed for detecting the unexpected network incidents. Generally, unsupervised anomaly detection algorithms gain more popularity than the supervised ones, due to the fact that labeling KPIs is extremely time- and resource-consuming, and error-prone. However, those unsupervised anomaly detection algorithms often suffer from excessive false alarms, especially in the presence of concept drifts resulting from network re-configurations or maintenance. To tackle this challenge and improve the overall performance of unsupervised anomaly detection algorithms, we propose to use active learning to introduce and benefit from the feedback of operators, who can verify the alarms (both false and true ones) and label the corresponding KPIs with reasonable effort. Specifically, we develop three query strategies to select the most informative and representative samples to label. We also develop an efficient method to update the weights of Isolation Forest and optimally adjust the decision threshold, so as to eventually improve the performance of detection model. The experiments with one public dataset and one proprietary dataset demonstrate that our active learning empowered anomaly detection pipeline could achieve performance gain, in terms of F1-score, more than 50% over the baseline algorithm. It also outperforms the existing active learning based methods by approximately 6%-10%, with significantly reduced budget (the ratio of samples to be labeled).
A time-weighted metric for sets of trajectories to assess multi-object tracking algorithms
Oct 26, 2021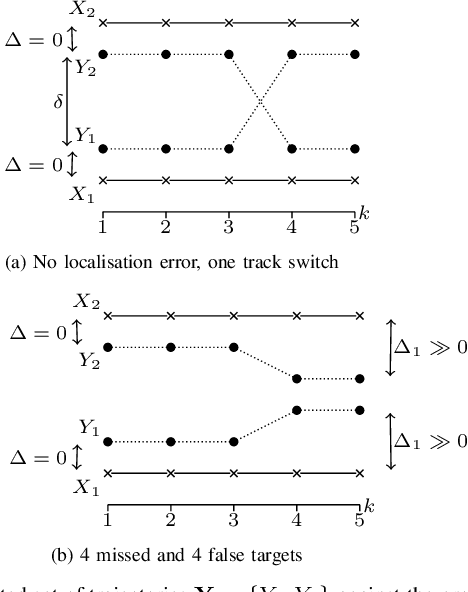
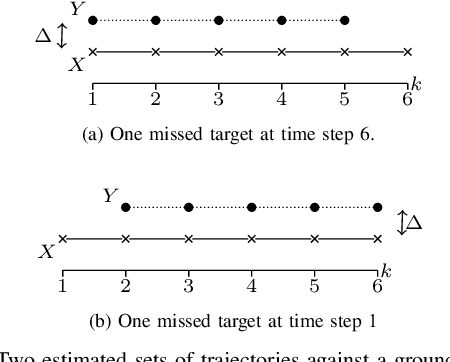
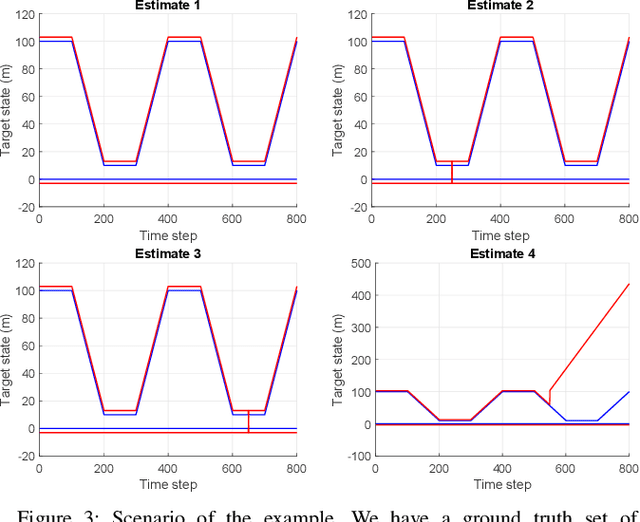
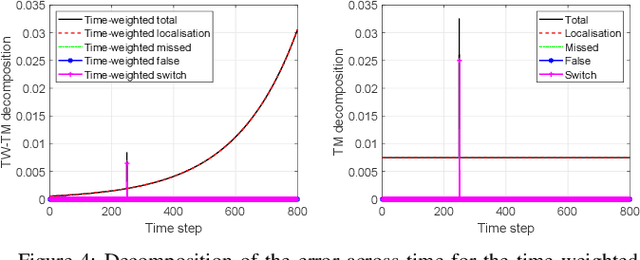
This paper proposes a metric for sets of trajectories to evaluate multi-object tracking algorithms that includes time-weighted costs for localisation errors of properly detected targets, for false targets, missed targets and track switches. The proposed metric extends the metric in [1] by including weights to the costs associated to different time steps. The time-weighted costs increase the flexibility of the metric [1] to fit more applications and user preferences. We first introduce a metric based on multi-dimensional assignments, and then its linear programming relaxation, which is computable in polynomial time and is also a metric. The metrics can also be extended to metrics on random finite sets of trajectories to evaluate and rank algorithms across different scenarios, each with a ground truth set of trajectories.
* Matlab code available at https://github.com/Agarciafernandez/MTT (Trajectory metric folder)
TINYCD: A (Not So) Deep Learning Model For Change Detection
Jul 26, 2022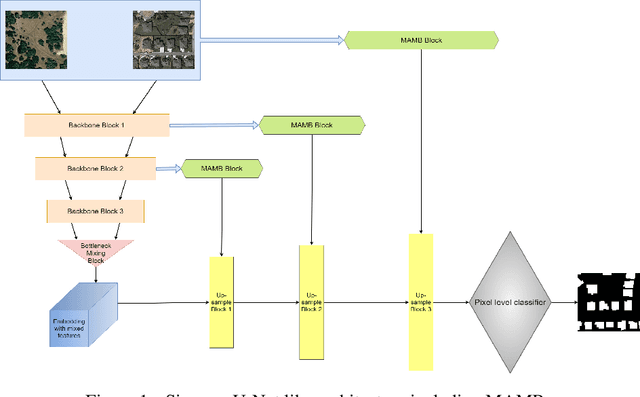
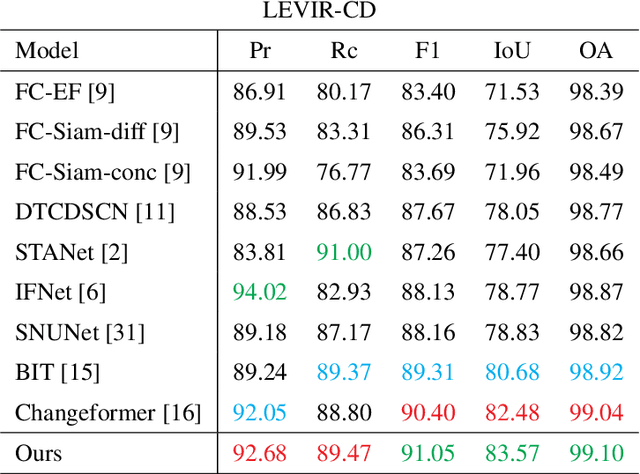
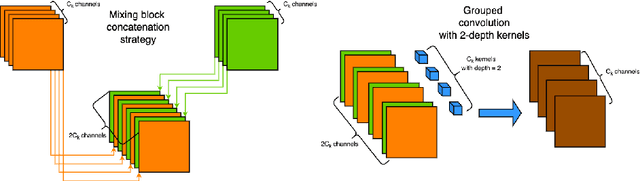
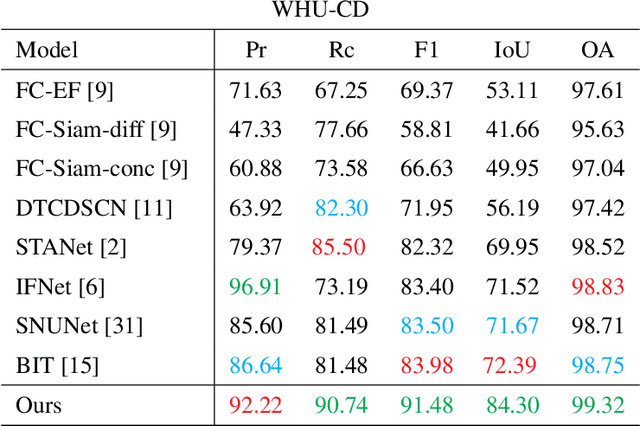
The aim of change detection (CD) is to detect changes occurred in the same area by comparing two images of that place taken at different times. The challenging part of the CD is to keep track of the changes the user wants to highlight, such as new buildings, and to ignore changes due to external factors such as environmental, lighting condition, fog or seasonal changes. Recent developments in the field of deep learning enabled researchers to achieve outstanding performance in this area. In particular, different mechanisms of space-time attention allowed to exploit the spatial features that are extracted from the models and to correlate them also in a temporal way by exploiting both the available images. The downside is that the models have become increasingly complex and large, often unfeasible for edge applications. These are limitations when the models must be applied to the industrial field or in applications requiring real-time performances. In this work we propose a novel model, called TinyCD, demonstrating to be both lightweight and effective, able to achieve performances comparable or even superior to the current state of the art with 13-150X fewer parameters. In our approach we have exploited the importance of low-level features to compare images. To do this, we use only few backbone blocks. This strategy allow us to keep the number of network parameters low. To compose the features extracted from the two images, we introduce a novel, economical in terms of parameters, mixing block capable of cross correlating features in both space and time domains. Finally, to fully exploit the information contained in the computed features, we define the PW-MLP block able to perform a pixel wise classification. Source code, models and results are available here: https://github.com/AndreaCodegoni/Tiny_model_4_CD