 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling cognitive load as a self-supervised brain rate with electroencephalography and deep learning
Sep 21, 2022
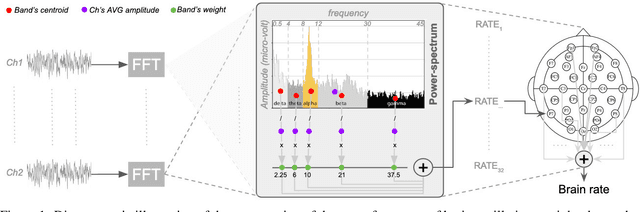
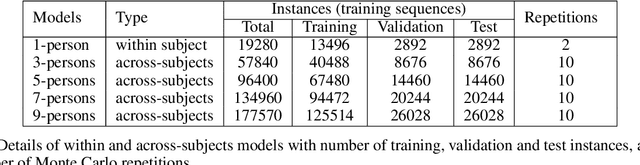
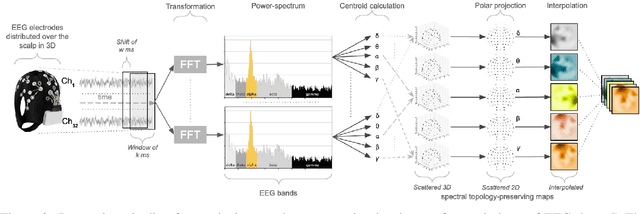
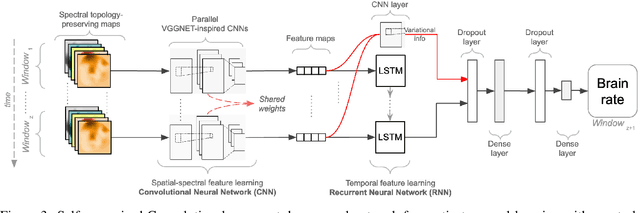
The principal reason for measuring mental workload is to quantify the cognitive cost of performing tasks to predict human performance. Unfortunately, a method for assessing mental workload that has general applicability does not exist yet. This research presents a novel self-supervised method for mental workload modelling from EEG data employing Deep Learning and a continuous brain rate, an index of cognitive activation, without requiring human declarative knowledge. This method is a convolutional recurrent neural network trainable with spatially preserving spectral topographic head-maps from EEG data to fit the brain rate variable. Findings demonstrate the capacity of the convolutional layers to learn meaningful high-level representations from EEG data since within-subject models had a test Mean Absolute Percentage Error average of 11%. The addition of a Long-Short Term Memory layer for handling sequences of high-level representations was not significant, although it did improve their accuracy. Findings point to the existence of quasi-stable blocks of learnt high-level representations of cognitive activation because they can be induced through convolution and seem not to be dependent on each other over time, intuitively matching the non-stationary nature of brain responses. Across-subject models, induced with data from an increasing number of participants, thus containing more variability, obtained a similar accuracy to the within-subject models. This highlights the potential generalisability of the induced high-level representations across people, suggesting the existence of subject-independent cognitive activation patterns. This research contributes to the body of knowledge by providing scholars with a novel computational method for mental workload modelling that aims to be generally applicable, does not rely on ad-hoc human-crafted models supporting replicability and falsifiability.
Towards Frame Rate Agnostic Multi-Object Tracking
Sep 23, 2022

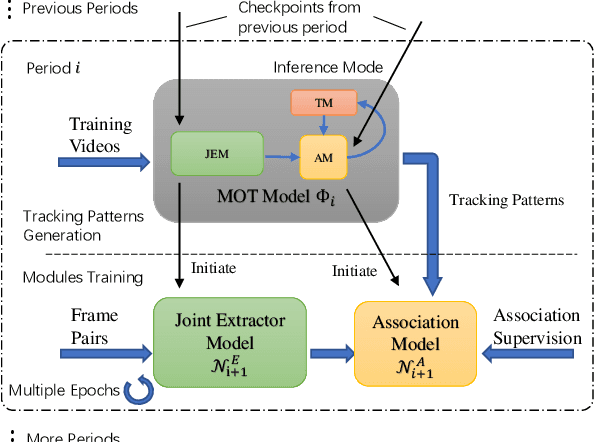
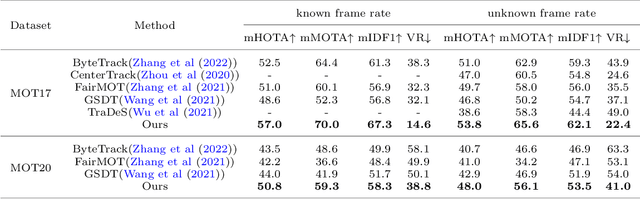
Multi-Object Tracking (MOT) is one of the most fundamental computer vision tasks which contributes to a variety of video analysis applications. Despite the recent promising progress, current MOT research is still limited to a fixed sampling frame rate of the input stream. In fact, we empirically find that the accuracy of all recent state-of-the-art trackers drops dramatically when the input frame rate changes. For a more intelligent tracking solution, we shift the attention of our research work to the problem of Frame Rate Agnostic MOT (FraMOT). In this paper, we propose a Frame Rate Agnostic MOT framework with Periodic training Scheme (FAPS) to tackle the FraMOT problem for the first time. Specifically, we propose a Frame Rate Agnostic Association Module (FAAM) that infers and encodes the frame rate information to aid identity matching across multi-frame-rate inputs, improving the capability of the learned model in handling complex motion-appearance relations in FraMOT. Besides, the association gap between training and inference is enlarged in FraMOT because those post-processing steps not included in training make a larger difference in lower frame rate scenarios. To address it, we propose Periodic Training Scheme (PTS) to reflect all post-processing steps in training via tracking pattern matching and fusion. Along with the proposed approaches, we make the first attempt to establish an evaluation method for this new task of FraMOT in two different modes, i.e., known frame rate and unknown frame rate, aiming to handle a more complex situation. The quantitative experiments on the challenging MOT datasets (FraMOT version) have clearly demonstrated that the proposed approaches can handle different frame rates better and thus improve the robustness against complicated scenarios.
PIETS: Parallelised Irregularity Encoders for Forecasting with Heterogeneous Time-Series
Oct 06, 2021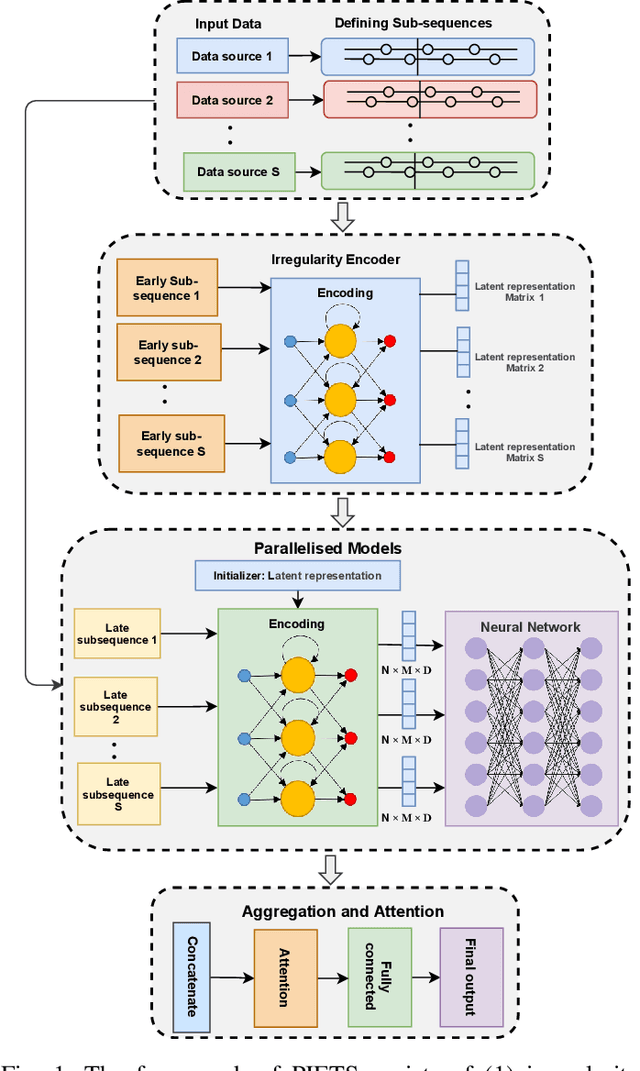
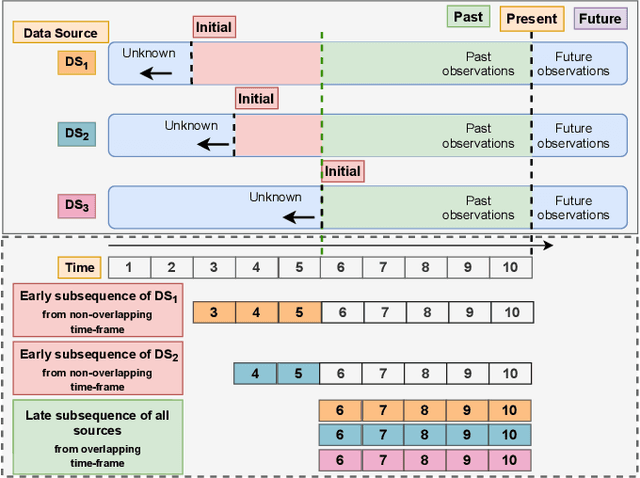
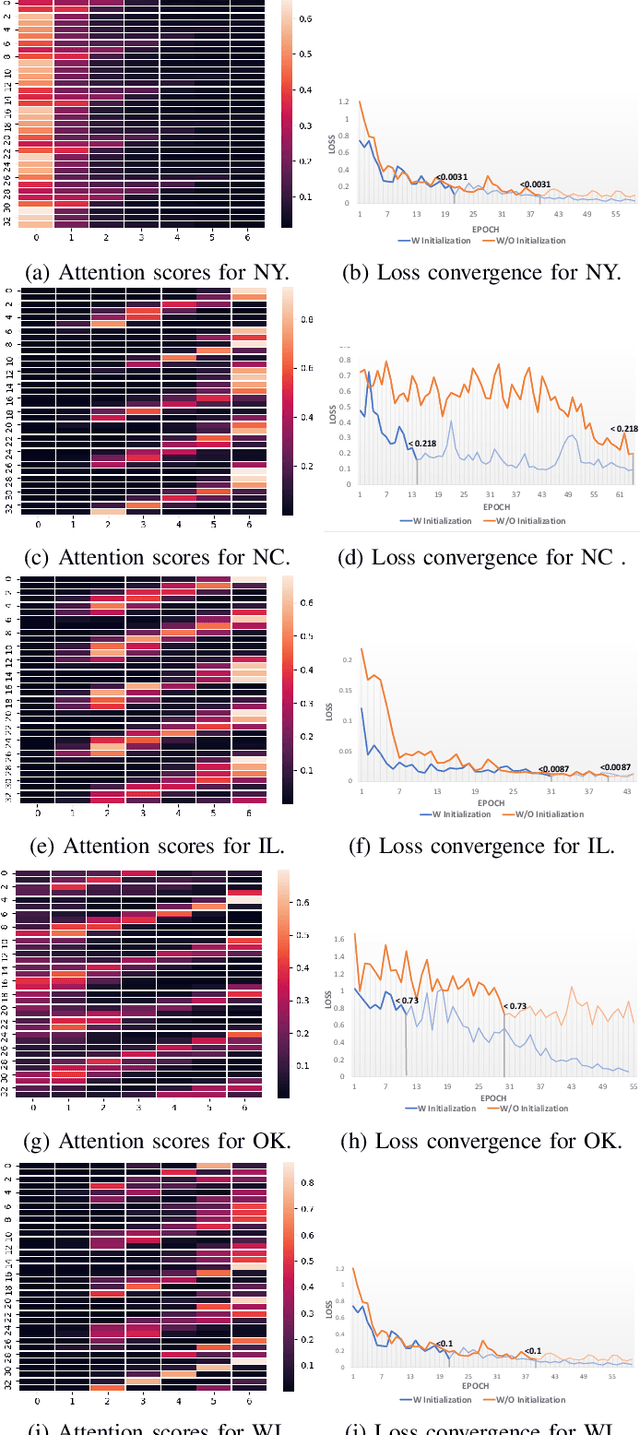
Heterogeneity and irregularity of multi-source data sets present a significant challenge to time-series analysis. In the literature, the fusion of multi-source time-series has been achieved either by using ensemble learning models which ignore temporal patterns and correlation within features or by defining a fixed-size window to select specific parts of the data sets. On the other hand, many studies have shown major improvement to handle the irregularity of time-series, yet none of these studies has been applied to multi-source data. In this work, we design a novel architecture, PIETS, to model heterogeneous time-series. PIETS has the following characteristics: (1) irregularity encoders for multi-source samples that can leverage all available information and accelerate the convergence of the model; (2) parallelised neural networks to enable flexibility and avoid information overwhelming; and (3) attention mechanism that highlights different information and gives high importance to the most related data. Through extensive experiments on real-world data sets related to COVID-19, we show that the proposed architecture is able to effectively model heterogeneous temporal data and outperforms other state-of-the-art approaches in the prediction task.
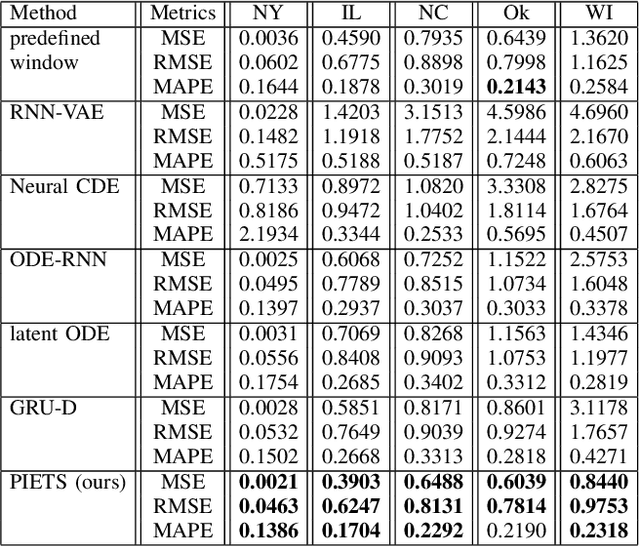
Will there be a construction? Predicting road constructions based on heterogeneous spatiotemporal data
Sep 14, 2022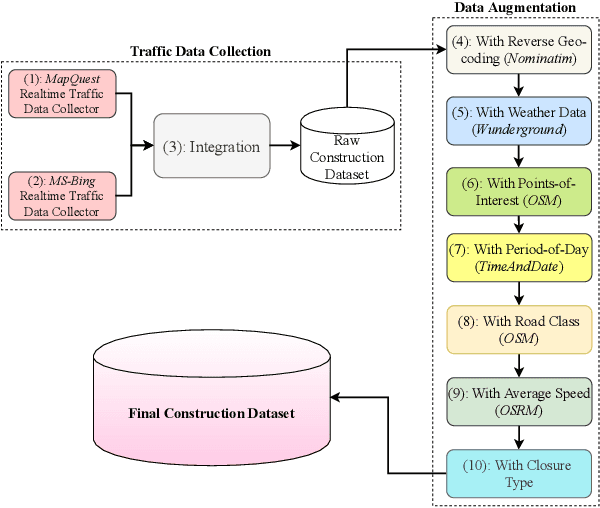
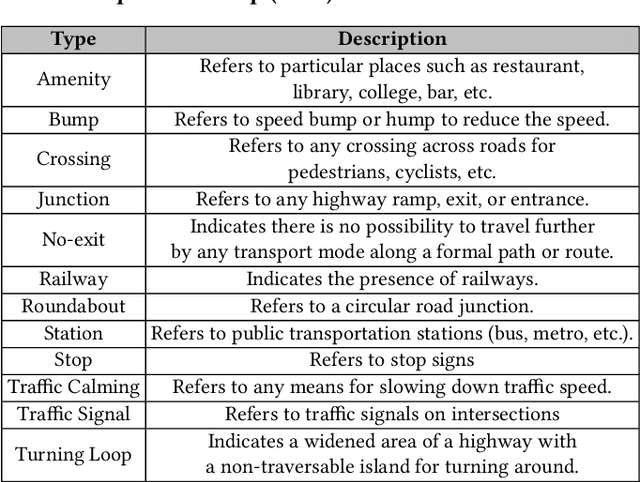
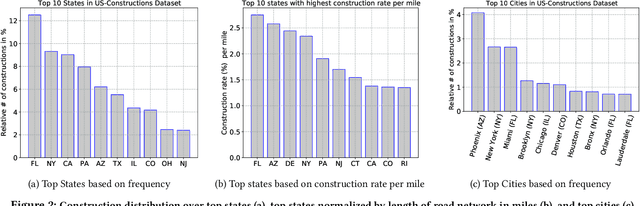
Road construction projects maintain transportation infrastructures. These projects range from the short-term (e.g., resurfacing or fixing potholes) to the long-term (e.g., adding a shoulder or building a bridge). Deciding what the next construction project is and when it is to be scheduled is traditionally done through inspection by humans using special equipment. This approach is costly and difficult to scale. An alternative is the use of computational approaches that integrate and analyze multiple types of past and present spatiotemporal data to predict location and time of future road constructions. This paper reports on such an approach, one that uses a deep-neural-network-based model to predict future constructions. Our model applies both convolutional and recurrent components on a heterogeneous dataset consisting of construction, weather, map and road-network data. We also report on how we addressed the lack of adequate publicly available data - by building a large scale dataset named "US-Constructions", that includes 6.2 million cases of road constructions augmented by a variety of spatiotemporal attributes and road-network features, collected in the contiguous United States (US) between 2016 and 2021. Using extensive experiments on several major cities in the US, we show the applicability of our work in accurately predicting future constructions - an average f1-score of 0.85 and accuracy 82.2% - that outperform baselines. Additionally, we show how our training pipeline addresses spatial sparsity of data.
Multi-task Swin Transformer for Motion Artifacts Classification and Cardiac Magnetic Resonance Image Segmentation
Sep 06, 2022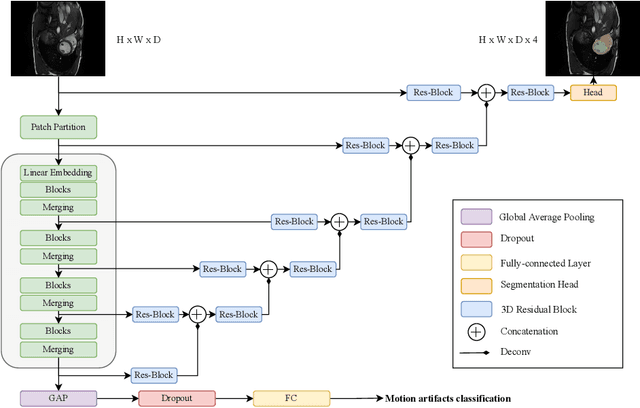
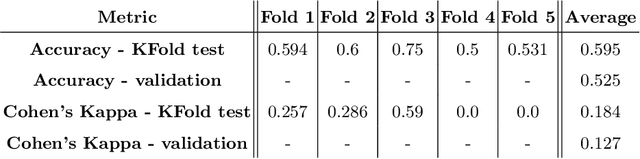
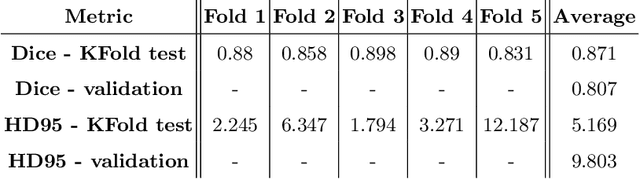
Cardiac Magnetic Resonance Imaging is commonly used for the assessment of the cardiac anatomy and function. The delineations of left and right ventricle blood pools and left ventricular myocardium are important for the diagnosis of cardiac diseases. Unfortunately, the movement of a patient during the CMR acquisition procedure may result in motion artifacts appearing in the final image. Such artifacts decrease the diagnostic quality of CMR images and force redoing of the procedure. In this paper, we present a Multi-task Swin UNEt TRansformer network for simultaneous solving of two tasks in the CMRxMotion challenge: CMR segmentation and motion artifacts classification. We utilize both segmentation and classification as a multi-task learning approach which allows us to determine the diagnostic quality of CMR and generate masks at the same time. CMR images are classified into three diagnostic quality classes, whereas, all samples with non-severe motion artifacts are being segmented. Ensemble of five networks trained using 5-Fold Cross-validation achieves segmentation performance of DICE coefficient of 0.871 and classification accuracy of 0.595.
OmniVoxel: A Fast and Precise Reconstruction Method of Omnidirectional Neural Radiance Field
Aug 12, 2022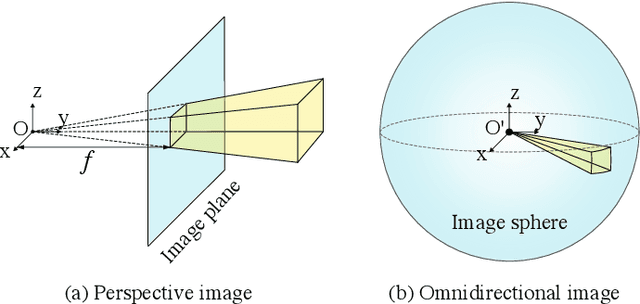

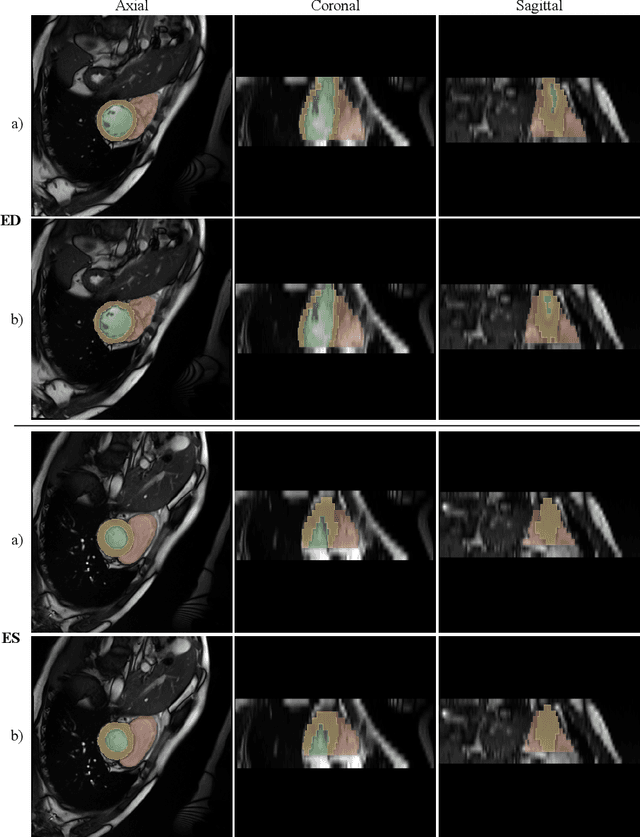
This paper proposes a method to reconstruct the neural radiance field with equirectangular omnidirectional images. Implicit neural scene representation with a radiance field can reconstruct the 3D shape of a scene continuously within a limited spatial area. However, training a fully implicit representation on commercial PC hardware requires a lot of time and computing resources (15 $\sim$ 20 hours per scene). Therefore, we propose a method to accelerate this process significantly (20 $\sim$ 40 minutes per scene). Instead of using a fully implicit representation of rays for radiance field reconstruction, we adopt feature voxels that contain density and color features in tensors. Considering omnidirectional equirectangular input and the camera layout, we use spherical voxelization for representation instead of cubic representation. Our voxelization method could balance the reconstruction quality of the inner scene and outer scene. In addition, we adopt the axis-aligned positional encoding method on the color features to increase the total image quality. Our method achieves satisfying empirical performance on synthetic datasets with random camera poses. Moreover, we test our method with real scenes which contain complex geometries and also achieve state-of-the-art performance. Our code and complete dataset will be released at the same time as the paper publication.
An Indian Roads Dataset for Supported and Suspended Traffic Lights Detection
Sep 09, 2022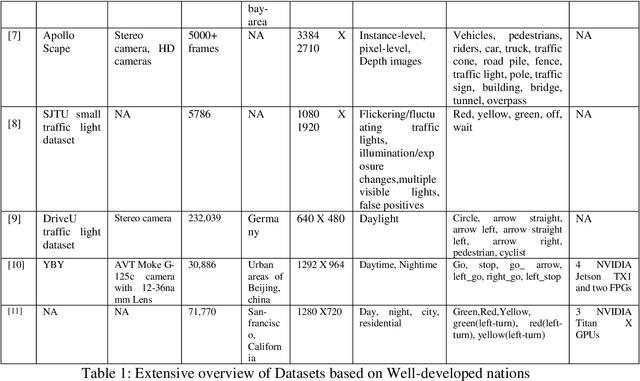
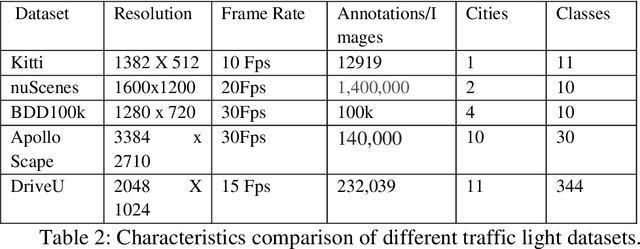

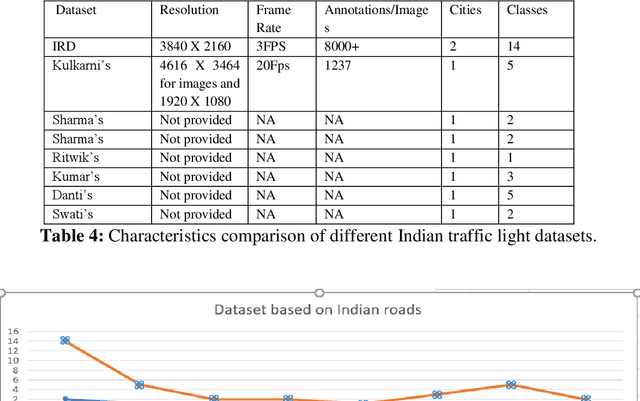
Autonomous vehicles are growing rapidly, in well-developed nations like America, Europe, and China. Tech giants like Google, Tesla, Audi, BMW, and Mercedes are building highly efficient self-driving vehicles. However, the technology is still not mainstream for developing nations like India, Thailand, Africa, etc., In this paper, we present a thorough comparison of the existing datasets based on well-developed nations as well as Indian roads. We then developed a new dataset "Indian Roads Dataset" (IRD) having more than 8000 annotations extracted from 3000+ images shot using a 64 (megapixel) camera. All the annotations are manually labelled adhering to the strict rules of annotations. Real-time video sequences have been captured from two different cities in India namely New Delhi and Chandigarh during the day and night-light conditions. Our dataset exceeds previous Indian traffic light datasets in size, annotations, and variance. We prove the amelioration of our dataset by providing an extensive comparison with existing Indian datasets. Various dataset criteria like size, capturing device, a number of cities, and variations of traffic light orientations are considered. The dataset can be downloaded from here https://sites.google.com/view/ird-dataset/home
Predicting Driver Takeover Time in Conditionally Automated Driving
Jul 20, 2021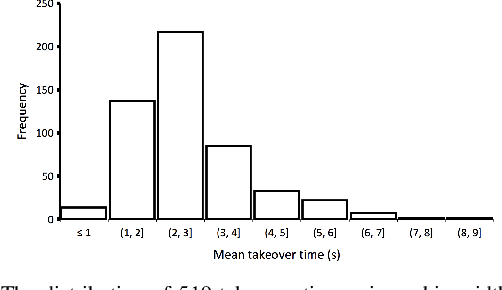
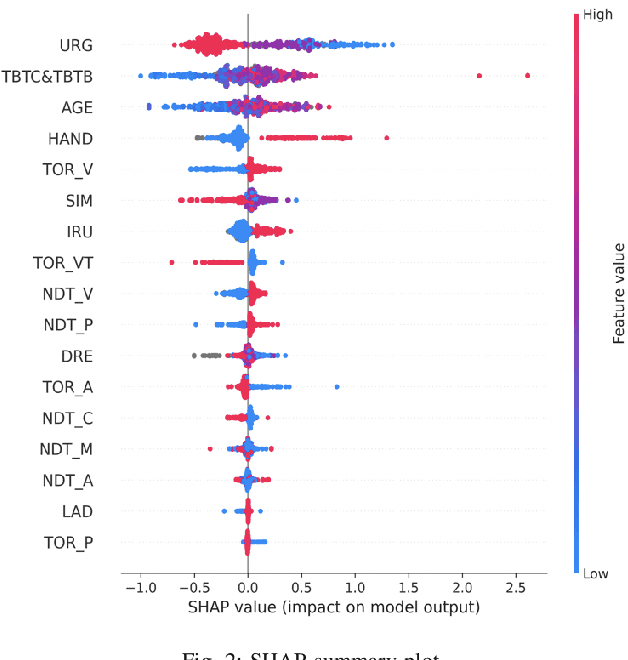
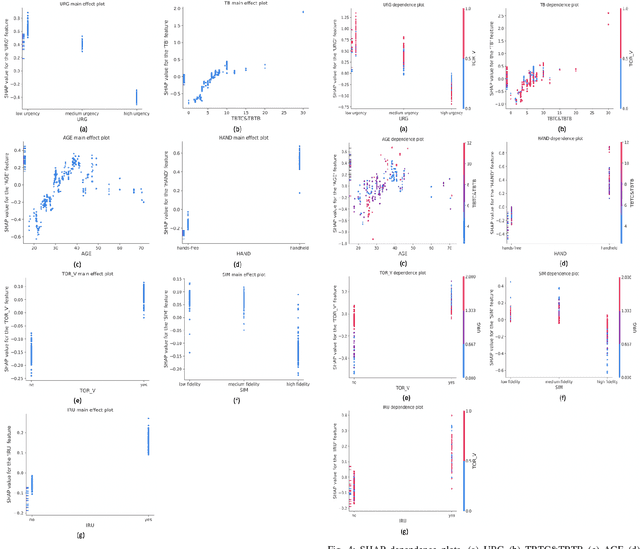
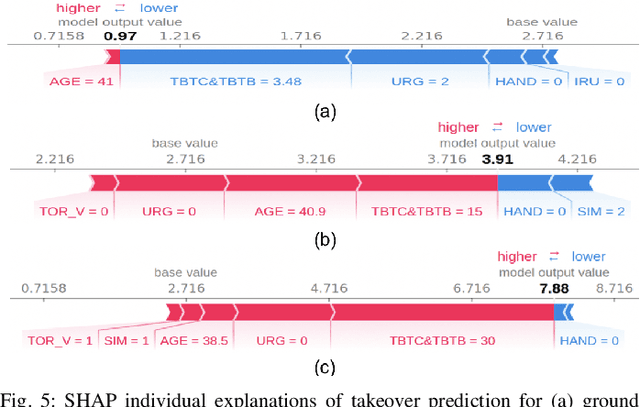
It is extremely important to ensure a safe takeover transition in conditionally automated driving. One of the critical factors that quantifies the safe takeover transition is takeover time. Previous studies identified the effects of many factors on takeover time, such as takeover lead time, non-driving tasks, modalities of the takeover requests (TORs), and scenario urgency. However, there is a lack of research to predict takeover time by considering these factors all at the same time. Toward this end, we used eXtreme Gradient Boosting (XGBoost) to predict the takeover time using a dataset from a meta-analysis study [1]. In addition, we used SHAP (SHapley Additive exPlanation) to analyze and explain the effects of the predictors on takeover time. We identified seven most critical predictors that resulted in the best prediction performance. Their main effects and interaction effects on takeover time were examined. The results showed that the proposed approach provided both good performance and explainability. Our findings have implications on the design of in-vehicle monitoring and alert systems to facilitate the interaction between the drivers and the automated vehicle.
Good Time to Ask: A Learning Framework for Asking for Help in Embodied Visual Navigation
Jun 20, 2022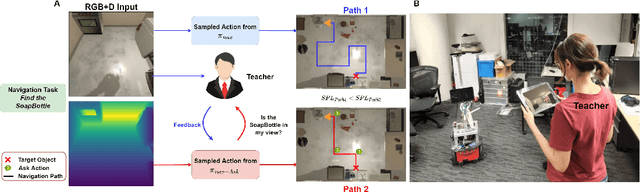
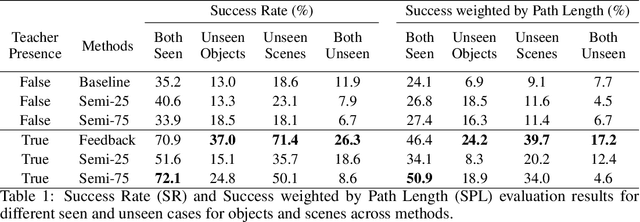
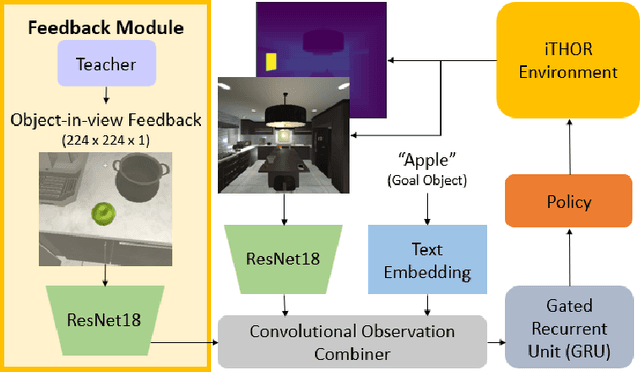
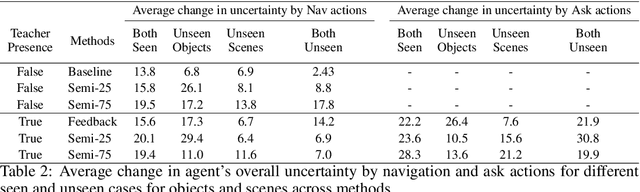
In reality, it is often more efficient to ask for help than to search the entire space to find an object with an unknown location. We present a learning framework that enables an agent to actively ask for help in such embodied visual navigation tasks, where the feedback informs the agent of where the goal is in its view. To emulate the real-world scenario that a teacher may not always be present, we propose a training curriculum where feedback is not always available. We formulate an uncertainty measure of where the goal is and use empirical results to show that through this approach, the agent learns to ask for help effectively while remaining robust when feedback is not available.
Motion Robust High-Speed Light-weighted Object Detection with Event Camera
Aug 24, 2022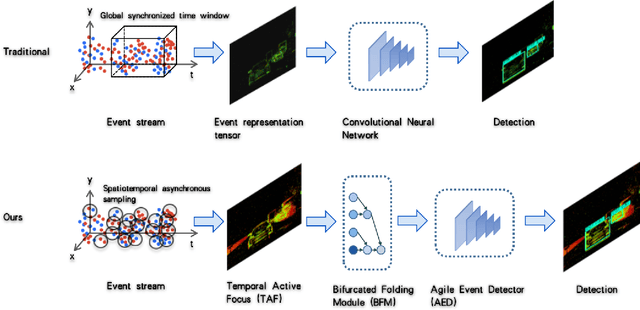
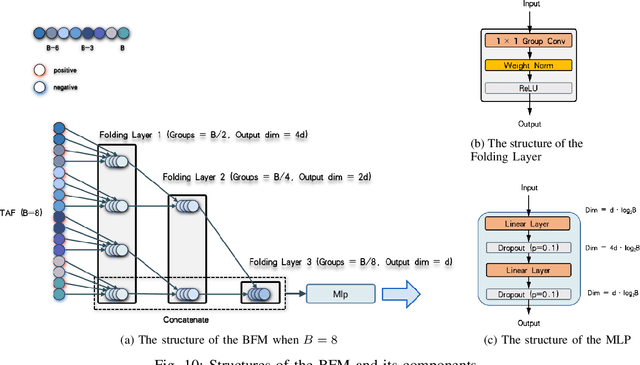
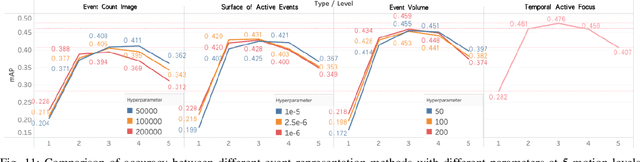
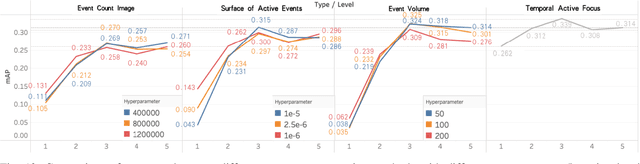
The event camera produces a large dynamic range event stream with a very high temporal resolution discarding redundant visual information, thus bringing new possibilities for object detection tasks. However, the existing methods of applying the event camera to object detection tasks using deep learning methods still have many problems. First, existing methods cannot take into account objects with different velocities relative to the motion of the event camera due to the global synchronized time window and temporal resolution. Second, most of the existing methods rely on large parameter neural networks, which implies a large computational burden and low inference speed, thus contrary to the high temporal resolution of the event stream. In our work, we design a high-speed lightweight detector called Agile Event Detector (AED) with a simple but effective data augmentation method. Also, we propose an event stream representation tensor called Temporal Active Focus (TAF), which takes full advantage of the asynchronous generation of event stream data and is robust to the motion of moving objects. It can also be constructed without much time-consuming. We further propose a module called the Bifurcated Folding Module (BFM) to extract the rich temporal information in the TAF tensor at the input layer of the AED detector. We conduct our experiments on two typical real-scene event camera object detection datasets: the complete Prophesee GEN1 Automotive Detection Dataset and the Prophesee 1 MEGAPIXEL Automotive Detection Dataset with partial annotation. Experiments show that our method is competitive in terms of accuracy, speed, and the number of parameters simultaneously. Also by classifying the objects into multiple motion levels based on the optical flow density metric, we illustrated the robustness of our method for objects with different velocities relative to the camera.