 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A deep learning approach to predict the number of k-barriers for intrusion detection over a circular region using wireless sensor networks
Aug 25, 2022
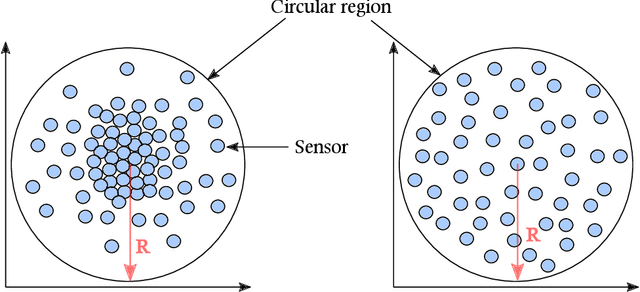
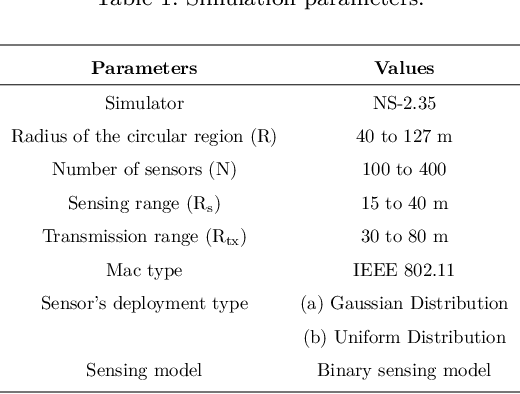
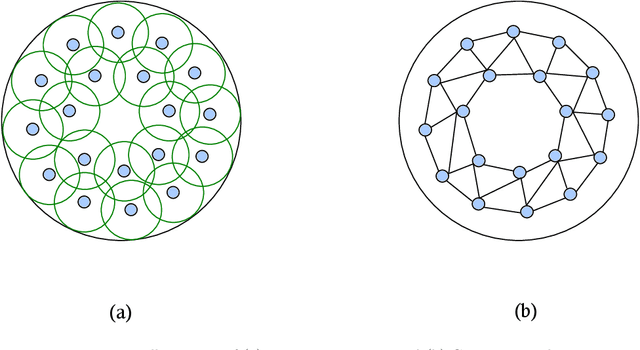
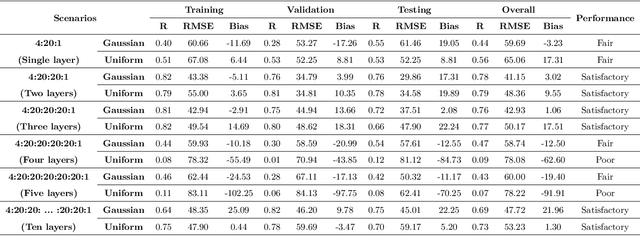
Wireless Sensor Networks (WSNs) is a promising technology with enormous applications in almost every walk of life. One of the crucial applications of WSNs is intrusion detection and surveillance at the border areas and in the defense establishments. The border areas are stretched in hundreds to thousands of miles, hence, it is not possible to patrol the entire border region. As a result, an enemy may enter from any point absence of surveillance and cause the loss of lives or destroy the military establishments. WSNs can be a feasible solution for the problem of intrusion detection and surveillance at the border areas. Detection of an enemy at the border areas and nearby critical areas such as military cantonments is a time-sensitive task as a delay of few seconds may have disastrous consequences. Therefore, it becomes imperative to design systems that are able to identify and detect the enemy as soon as it comes in the range of the deployed system. In this paper, we have proposed a deep learning architecture based on a fully connected feed-forward Artificial Neural Network (ANN) for the accurate prediction of the number of k-barriers for fast intrusion detection and prevention. We have trained and evaluated the feed-forward ANN model using four potential features, namely area of the circular region, sensing range of sensors, the transmission range of sensors, and the number of sensor for Gaussian and uniform sensor distribution. These features are extracted through Monte Carlo simulation. In doing so, we found that the model accurately predicts the number of k-barriers for both Gaussian and uniform sensor distribution with correlation coefficient (R = 0.78) and Root Mean Square Error (RMSE = 41.15) for the former and R = 0.79 and RMSE = 48.36 for the latter. Further, the proposed approach outperforms the other benchmark algorithms in terms of accuracy and computational time complexity.
* Singh, A., Amutha, J., Nagar, J., & Sharma, S. (2022). A deep learning approach to predict the number of k-barriers for intrusion detection over a circular region using wireless sensor networks. Expert Systems with Applications, 118588
Meteorological Satellite Images Prediction Based on Deep Multi-scales Extrapolation Fusion
Sep 19, 2022

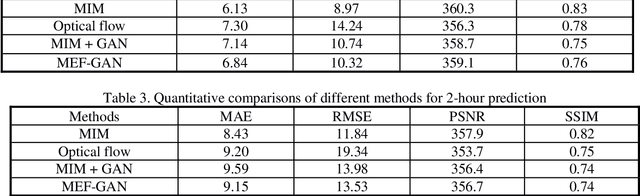
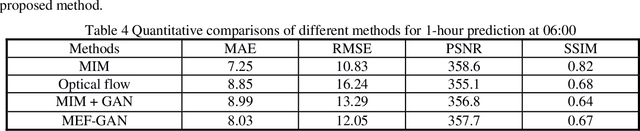
Meteorological satellite imagery is critical for meteorologists. The data have played an important role in monitoring and analyzing weather and climate changes. However, satellite imagery is a kind of observation data and exists a significant time delay when transmitting the data back to Earth. It is important to make accurate predictions for meteorological satellite images, especially the nowcasting prediction up to 2 hours ahead. In recent years, there has been growing interest in the research of nowcasting prediction applications of weather radar images based on deep learning. Compared to the weather radar images prediction problem, the main challenge for meteorological satellite images prediction is the large-scale observation areas and therefore the large sizes of the observation products. Here we present a deep multi-scales extrapolation fusion method, to address the challenge of the meteorological satellite images nowcasting prediction. First, we downsample the original satellite images dataset with large size to several images datasets with smaller resolutions, then we use a deep spatiotemporal sequences prediction method to generate the multi-scales prediction images with different resolutions separately. Second, we fuse the multi-scales prediction results to the targeting prediction images with the original size by a conditional generative adversarial network. The experiments based on the FY-4A meteorological satellite data show that the proposed method can generate realistic prediction images that effectively capture the evolutions of the weather systems in detail. We believe that the general idea of this work can be potentially applied to other spatiotemporal sequence prediction tasks with a large size.
On Efficient Reinforcement Learning for Full-length Game of StarCraft II
Sep 23, 2022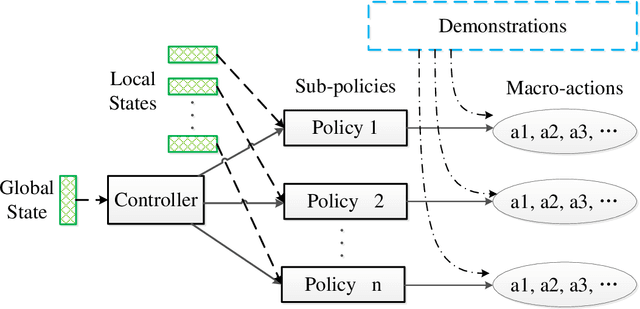

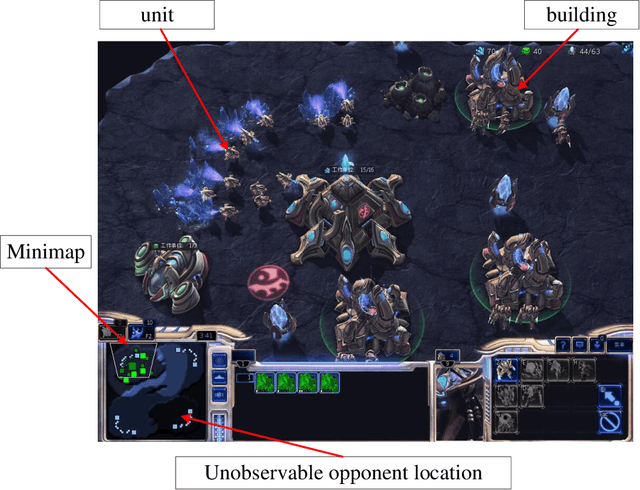

StarCraft II (SC2) poses a grand challenge for reinforcement learning (RL), of which the main difficulties include huge state space, varying action space, and a long time horizon. In this work, we investigate a set of RL techniques for the full-length game of StarCraft II. We investigate a hierarchical RL approach involving extracted macro-actions and a hierarchical architecture of neural networks. We investigate a curriculum transfer training procedure and train the agent on a single machine with 4 GPUs and 48 CPU threads. On a 64x64 map and using restrictive units, we achieve a win rate of 99% against the level-1 built-in AI. Through the curriculum transfer learning algorithm and a mixture of combat models, we achieve a 93% win rate against the most difficult non-cheating level built-in AI (level-7). In this extended version of the paper, we improve our architecture to train the agent against the cheating level AIs and achieve the win rate against the level-8, level-9, and level-10 AIs as 96%, 97%, and 94%, respectively. Our codes are at https://github.com/liuruoze/HierNet-SC2. To provide a baseline referring the AlphaStar for our work as well as the research and open-source community, we reproduce a scaled-down version of it, mini-AlphaStar (mAS). The latest version of mAS is 1.07, which can be trained on the raw action space which has 564 actions. It is designed to run training on a single common machine, by making the hyper-parameters adjustable. We then compare our work with mAS using the same resources and show that our method is more effective. The codes of mini-AlphaStar are at https://github.com/liuruoze/mini-AlphaStar. We hope our study could shed some light on the future research of efficient reinforcement learning on SC2 and other large-scale games.
DAVE Aquatic Virtual Environment: Toward a General Underwater Robotics Simulator
Sep 06, 2022



We present DAVE Aquatic Virtual Environment (DAVE), an open source simulation stack for underwater robots, sensors, and environments. Conventional robotics simulators are not designed to address unique challenges that come with the marine environment, including but not limited to environment conditions that vary spatially and temporally, impaired or challenging perception, and the unavailability of data in a generally unexplored environment. Given the variety of sensors and platforms, wheels are often reinvented for specific use cases that inevitably resist wider adoption. Building on existing simulators, we provide a framework to help speed up the development and evaluation of algorithms that would otherwise require expensive and time-consuming operations at sea. The framework includes basic building blocks (e.g., new vehicles, water-tracking Doppler Velocity Logger, physics-based multibeam sonar) as well as development tools (e.g., dynamic bathymetry spawning, ocean currents), which allows the user to focus on methodology rather than software infrastructure. We demonstrate usage through example scenarios, bathymetric data import, user interfaces for data inspection and motion planning for manipulation, and visualizations.
Sequence Feature Extraction for Malware Family Analysis via Graph Neural Network
Aug 10, 2022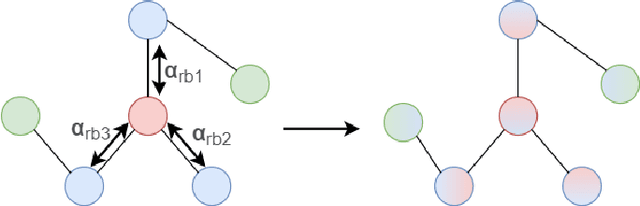
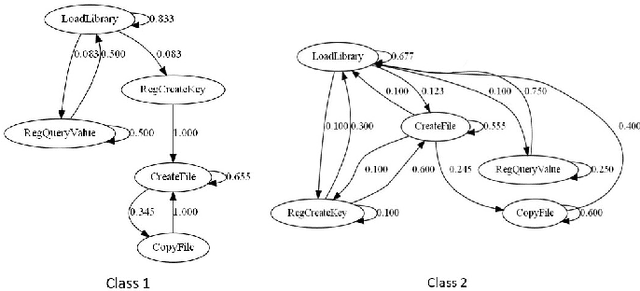
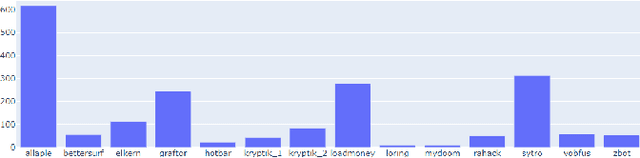
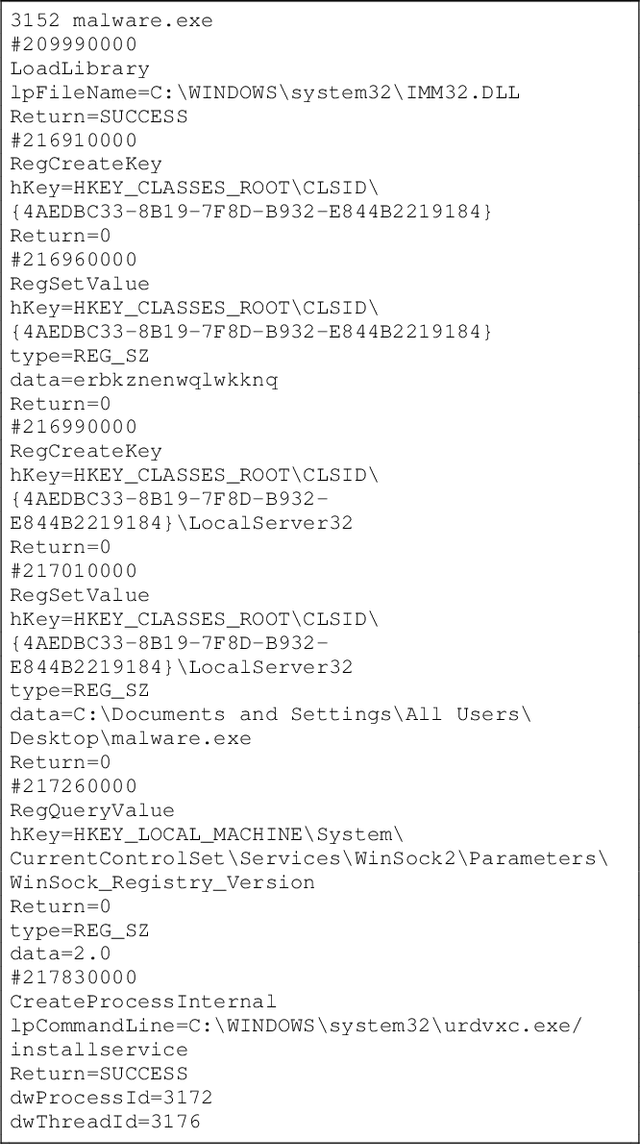
Malicious software (malware) causes much harm to our devices and life. We are eager to understand the malware behavior and the threat it made. Most of the record files of malware are variable length and text-based files with time stamps, such as event log data and dynamic analysis profiles. Using the time stamps, we can sort such data into sequence-based data for the following analysis. However, dealing with the text-based sequences with variable lengths is difficult. In addition, unlike natural language text data, most sequential data in information security have specific properties and structure, such as loop, repeated call, noise, etc. To deeply analyze the API call sequences with their structure, we use graphs to represent the sequences, which can further investigate the information and structure, such as the Markov model. Therefore, we design and implement an Attention Aware Graph Neural Network (AWGCN) to analyze the API call sequences. Through AWGCN, we can obtain the sequence embeddings to analyze the behavior of the malware. Moreover, the classification experiment result shows that AWGCN outperforms other classifiers in the call-like datasets, and the embedding can further improve the classic model's performance.
TrackletMapper: Ground Surface Segmentation and Mapping from Traffic Participant Trajectories
Sep 12, 2022
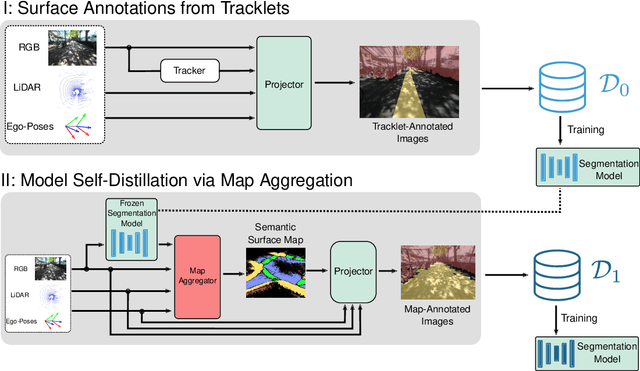
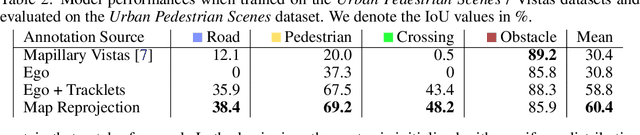

Robustly classifying ground infrastructure such as roads and street crossings is an essential task for mobile robots operating alongside pedestrians. While many semantic segmentation datasets are available for autonomous vehicles, models trained on such datasets exhibit a large domain gap when deployed on robots operating in pedestrian spaces. Manually annotating images recorded from pedestrian viewpoints is both expensive and time-consuming. To overcome this challenge, we propose TrackletMapper, a framework for annotating ground surface types such as sidewalks, roads, and street crossings from object tracklets without requiring human-annotated data. To this end, we project the robot ego-trajectory and the paths of other traffic participants into the ego-view camera images, creating sparse semantic annotations for multiple types of ground surfaces from which a ground segmentation model can be trained. We further show that the model can be self-distilled for additional performance benefits by aggregating a ground surface map and projecting it into the camera images, creating a denser set of training annotations compared to the sparse tracklet annotations. We qualitatively and quantitatively attest our findings on a novel large-scale dataset for mobile robots operating in pedestrian areas. Code and dataset will be made available at http://trackletmapper.cs.uni-freiburg.de.
Generating Negative Samples for Sequential Recommendation
Aug 07, 2022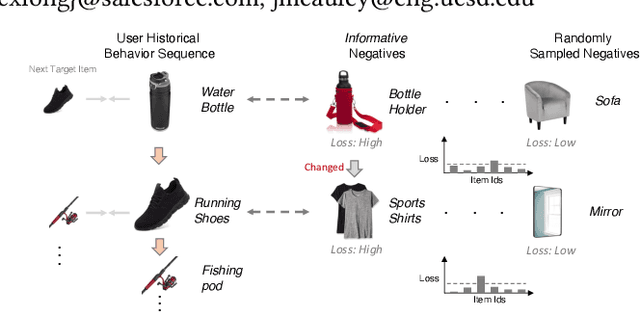
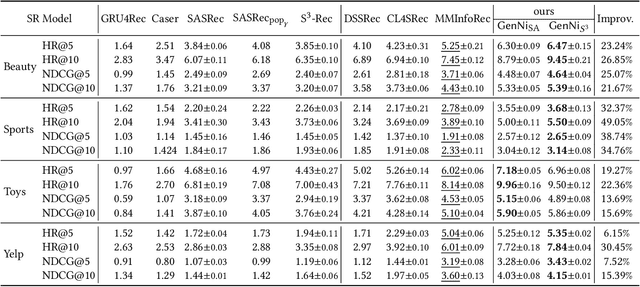
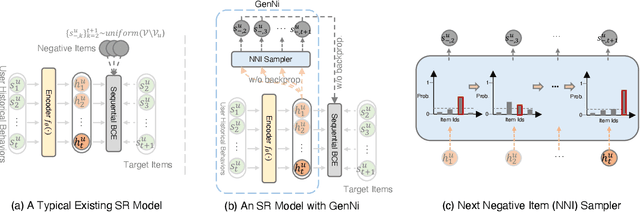
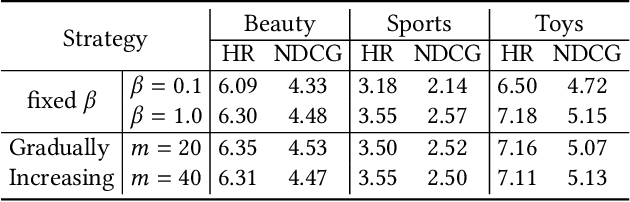
To make Sequential Recommendation (SR) successful, recent works focus on designing effective sequential encoders, fusing side information, and mining extra positive self-supervision signals. The strategy of sampling negative items at each time step is less explored. Due to the dynamics of users' interests and model updates during training, considering randomly sampled items from a user's non-interacted item set as negatives can be uninformative. As a result, the model will inaccurately learn user preferences toward items. Identifying informative negatives is challenging because informative negative items are tied with both dynamically changed interests and model parameters (and sampling process should also be efficient). To this end, we propose to Generate Negative Samples (items) for SR (GenNi). A negative item is sampled at each time step based on the current SR model's learned user preferences toward items. An efficient implementation is proposed to further accelerate the generation process, making it scalable to large-scale recommendation tasks. Extensive experiments on four public datasets verify the importance of providing high-quality negative samples for SR and demonstrate the effectiveness and efficiency of GenNi.
Amortised Inference in Structured Generative Models with Explaining Away
Sep 12, 2022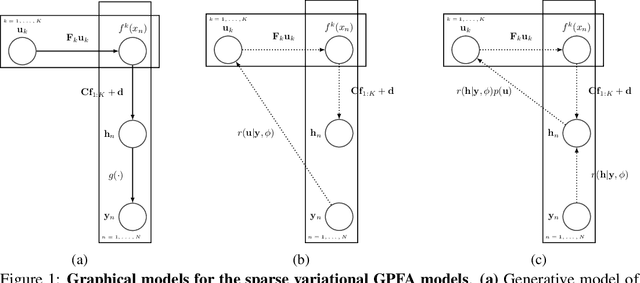
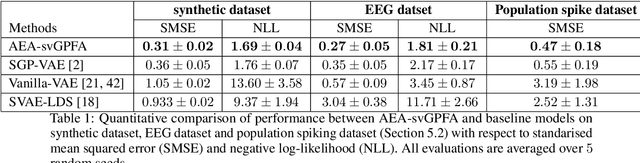
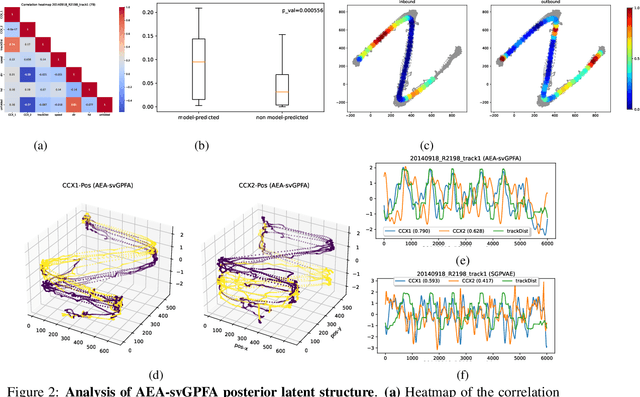
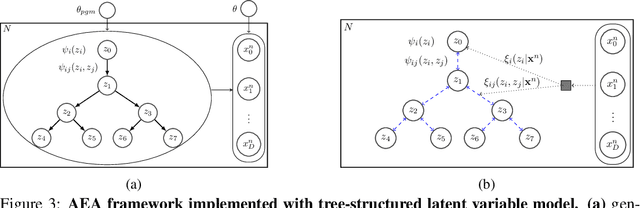
A key goal of unsupervised learning is to go beyond density estimation and sample generation to reveal the structure inherent within observed data. Such structure can be expressed in the pattern of interactions between explanatory latent variables captured through a probabilistic graphical model. Although the learning of structured graphical models has a long history, much recent work in unsupervised modelling has instead emphasised flexible deep-network-based generation, either transforming independent latent generators to model complex data or assuming that distinct observed variables are derived from different latent nodes. Here, we extend the output of amortised variational inference to incorporate structured factors over multiple variables, able to capture the observation-induced posterior dependence between latents that results from "explaining away" and thus allow complex observations to depend on multiple nodes of a structured graph. We show that appropriately parameterised factors can be combined efficiently with variational message passing in elaborate graphical structures. We instantiate the framework based on Gaussian Process Factor Analysis models, and empirically evaluate its improvement over existing methods on synthetic data with known generative processes. We then fit the structured model to high-dimensional neural spiking time-series from the hippocampus of freely moving rodents, demonstrating that the model identifies latent signals that correlate with behavioural covariates.
Dynamic optical path provisioning for alien access links: architecture, demonstration, and challenges
Sep 12, 2022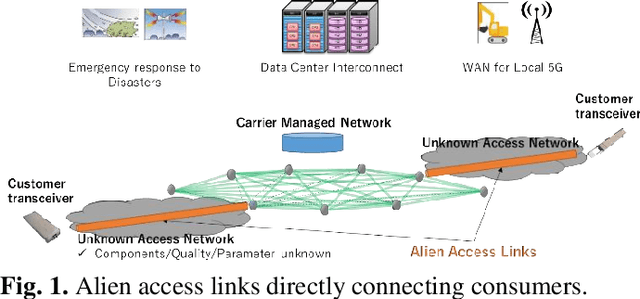
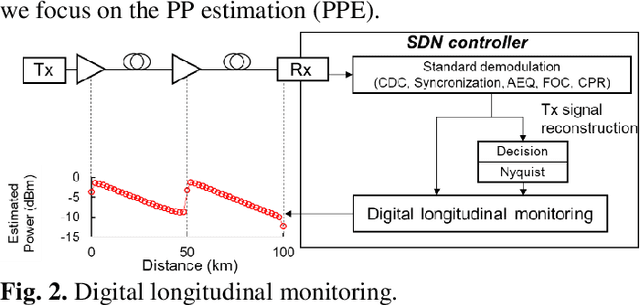
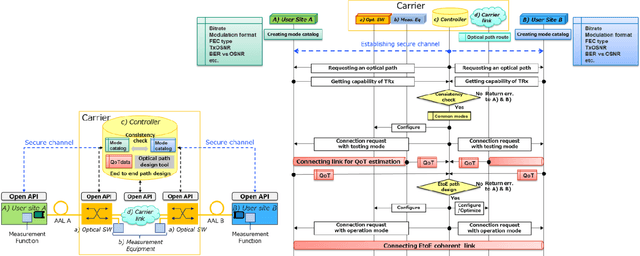
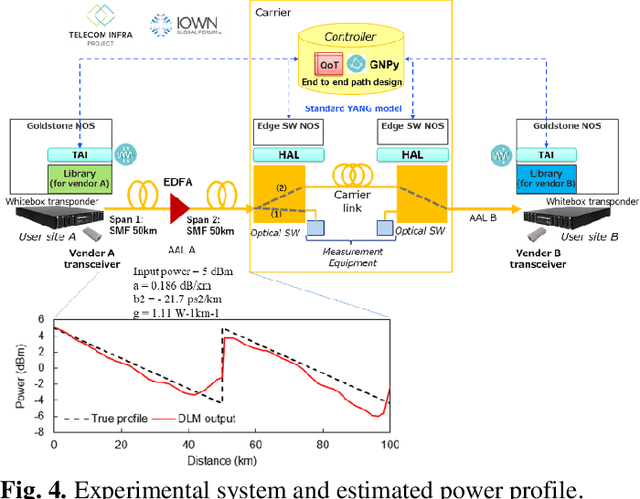
With the spread of Data Center Interconnect (DCI) and local 5G, there is a growing need for dynamically established connections between customer locations through high-capacity optical links. However, link parameters such as signal power profile and amplifier gains are often unknown and have to be measured by experts, preventing dynamic path provisioning due to the time-consuming manual measurements. Although several techniques for estimating the unknown parameters of such alien access links have been proposed, no work has presented architecture and protocol that drive the estimation techniques to establish an optical path between the customer locations. Our study aims to automatically connect customer-owned transceivers via alien access links with optimal quality of transmission (QoT). We first propose an architecture and protocol for cooperative optical path design between a customer and carrier, utilizing a state-of-the-art technique for estimating link parameters. We then implement the proposed protocol in a software-defined network (SDN) controller and white-box transponders using an open API. The experiments demonstrate that the optical path is dynamically established via alien access links in 137 seconds from the transceiver's cold start. Lastly, we discuss the QoT accuracy obtained with this method and the remaining issues.
Learning-Augmented Maximum Flow
Jul 26, 2022We propose a framework for speeding up maximum flow computation by using predictions. A prediction is a flow, i.e., an assignment of non-negative flow values to edges, which satisfies the flow conservation property, but does not necessarily respect the edge capacities of the actual instance (since these were unknown at the time of learning). We present an algorithm that, given an $m$-edge flow network and a predicted flow, computes a maximum flow in $O(m\eta)$ time, where $\eta$ is the $\ell_1$ error of the prediction, i.e., the sum over the edges of the absolute difference between the predicted and optimal flow values. Moreover, we prove that, given an oracle access to a distribution over flow networks, it is possible to efficiently PAC-learn a prediction minimizing the expected $\ell_1$ error over that distribution. Our results fit into the recent line of research on learning-augmented algorithms, which aims to improve over worst-case bounds of classical algorithms by using predictions, e.g., machine-learned from previous similar instances. So far, the main focus in this area was on improving competitive ratios for online problems. Following Dinitz et al. (NeurIPS 2021), our results are one of the firsts to improve the running time of an offline problem.