 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can LLMs Generate Architectural Design Decisions? -An Exploratory Empirical study
Mar 04, 2024
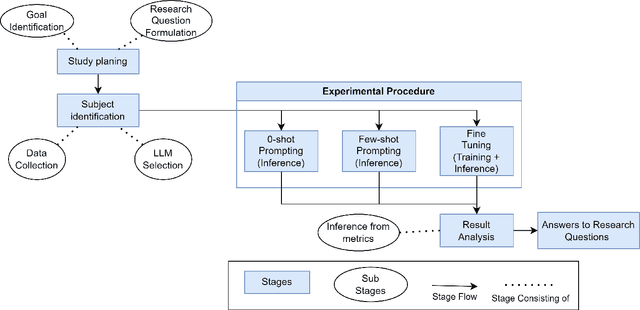



Architectural Knowledge Management (AKM) involves the organized handling of information related to architectural decisions and design within a project or organization. An essential artifact of AKM is the Architecture Decision Records (ADR), which documents key design decisions. ADRs are documents that capture decision context, decision made and various aspects related to a design decision, thereby promoting transparency, collaboration, and understanding. Despite their benefits, ADR adoption in software development has been slow due to challenges like time constraints and inconsistent uptake. Recent advancements in Large Language Models (LLMs) may help bridge this adoption gap by facilitating ADR generation. However, the effectiveness of LLM for ADR generation or understanding is something that has not been explored. To this end, in this work, we perform an exploratory study that aims to investigate the feasibility of using LLM for the generation of ADRs given the decision context. In our exploratory study, we utilize GPT and T5-based models with 0-shot, few-shot, and fine-tuning approaches to generate the Decision of an ADR given its Context. Our results indicate that in a 0-shot setting, state-of-the-art models such as GPT-4 generate relevant and accurate Design Decisions, although they fall short of human-level performance. Additionally, we observe that more cost-effective models like GPT-3.5 can achieve similar outcomes in a few-shot setting, and smaller models such as Flan-T5 can yield comparable results after fine-tuning. To conclude, this exploratory study suggests that LLM can generate Design Decisions, but further research is required to attain human-level generation and establish standardized widespread adoption.
From Zero to Hero: How local curvature at artless initial conditions leads away from bad minima
Mar 04, 2024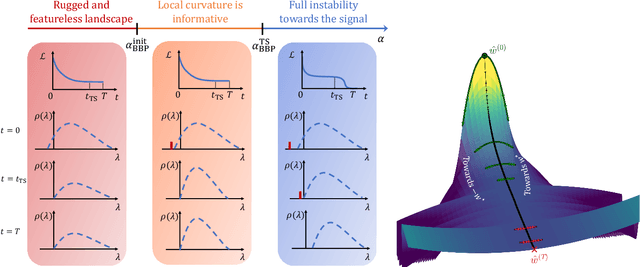
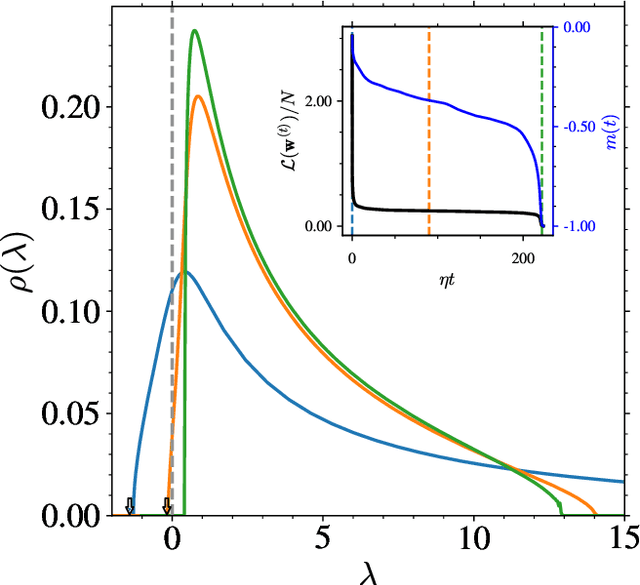
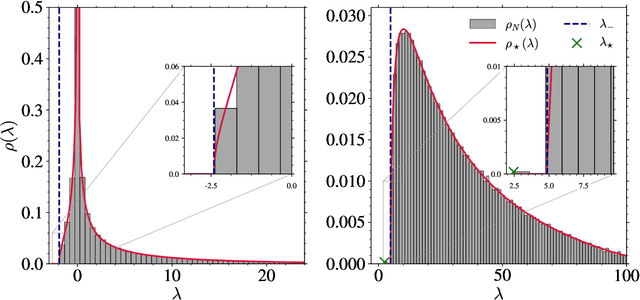
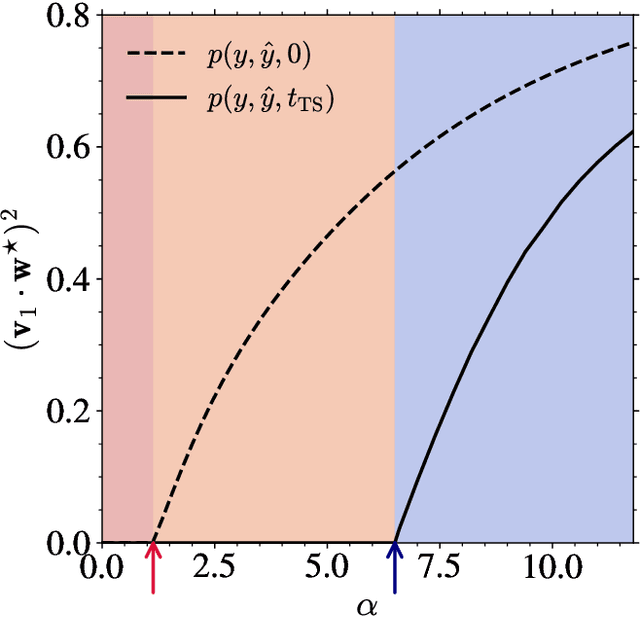
We investigate the optimization dynamics of gradient descent in a non-convex and high-dimensional setting, with a focus on the phase retrieval problem as a case study for complex loss landscapes. We first study the high-dimensional limit where both the number $M$ and the dimension $N$ of the data are going to infinity at fixed signal-to-noise ratio $\alpha = M/N$. By analyzing how the local curvature changes during optimization, we uncover that for intermediate $\alpha$, the Hessian displays a downward direction pointing towards good minima in the first regime of the descent, before being trapped in bad minima at the end. Hence, the local landscape is benign and informative at first, before gradient descent brings the system into a uninformative maze. The transition between the two regimes is associated to a BBP-type threshold in the time-dependent Hessian. Through both theoretical analysis and numerical experiments, we show that in practical cases, i.e. for finite but even very large $N$, successful optimization via gradient descent in phase retrieval is achieved by falling towards the good minima before reaching the bad ones. This mechanism explains why successful recovery is obtained well before the algorithmic transition corresponding to the high-dimensional limit. Technically, this is associated to strong logarithmic corrections of the algorithmic transition at large $N$ with respect to the one expected in the $N\to\infty$ limit. Our analysis sheds light on such a new mechanism that facilitate gradient descent dynamics in finite large dimensions, also highlighting the importance of good initialization of spectral properties for optimization in complex high-dimensional landscapes.
Improving and Unifying Discrete&Continuous-time Discrete Denoising Diffusion
Feb 06, 2024Discrete diffusion models have seen a surge of attention with applications on naturally discrete data such as language and graphs. Although discrete-time discrete diffusion has been established for a while, only recently Campbell et al. (2022) introduced the first framework for continuous-time discrete diffusion. However, their training and sampling processes differ significantly from the discrete-time version, necessitating nontrivial approximations for tractability. In this paper, we first present a series of mathematical simplifications of the variational lower bound that enable more accurate and easy-to-optimize training for discrete diffusion. In addition, we derive a simple formulation for backward denoising that enables exact and accelerated sampling, and importantly, an elegant unification of discrete-time and continuous-time discrete diffusion. Thanks to simpler analytical formulations, both forward and now also backward probabilities can flexibly accommodate any noise distribution, including different noise distributions for multi-element objects. Experiments show that our proposed USD3 (for Unified Simplified Discrete Denoising Diffusion) outperform all SOTA baselines on established datasets. We open-source our unified code at https://github.com/LingxiaoShawn/USD3.
Exploring the dynamic interplay of cognitive load and emotional arousal by using multimodal measurements: Correlation of pupil diameter and emotional arousal in emotionally engaging tasks
Mar 01, 2024
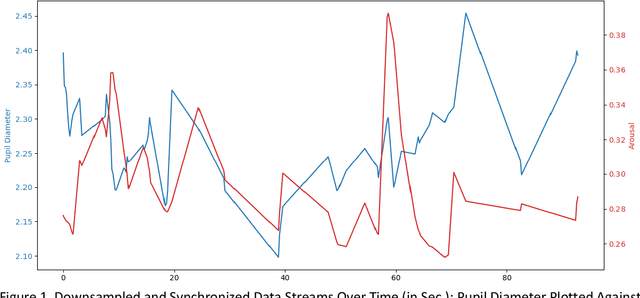
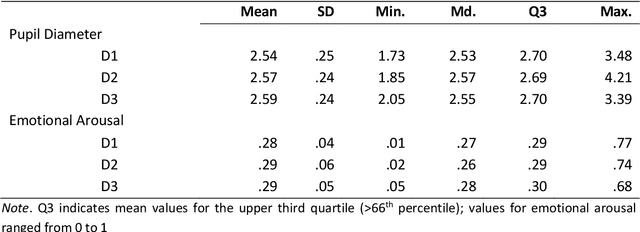
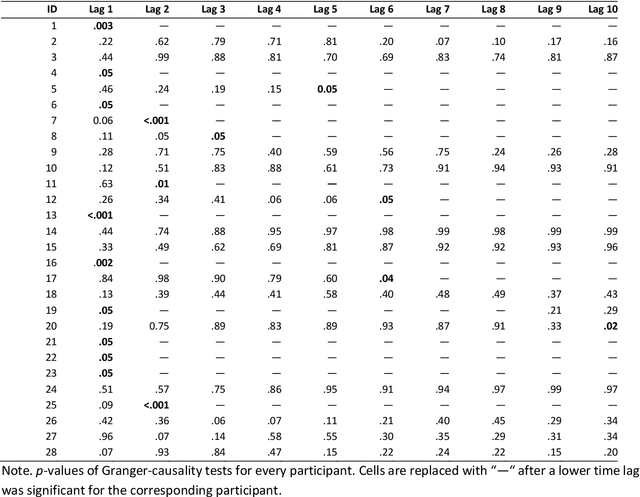
Multimodal data analysis and validation based on streams from state-of-the-art sensor technology such as eye-tracking or emotion recognition using the Facial Action Coding System (FACTs) with deep learning allows educational researchers to study multifaceted learning and problem-solving processes and to improve educational experiences. This study aims to investigate the correlation between two continuous sensor streams, pupil diameter as an indicator of cognitive workload and FACTs with deep learning as an indicator of emotional arousal (RQ 1a), specifically for epochs of high, medium, and low arousal (RQ 1b). Furthermore, the time lag between emotional arousal and pupil diameter data will be analyzed (RQ 2). 28 participants worked on three cognitively demanding and emotionally engaging everyday moral dilemmas while eye-tracking and emotion recognition data were collected. The data were pre-processed in Phyton (synchronization, blink control, downsampling) and analyzed using correlation analysis and Granger causality tests. The results show negative and statistically significant correlations between the data streams for emotional arousal and pupil diameter. However, the correlation is negative and significant only for epochs of high arousal, while positive but non-significant relationships were found for epochs of medium or low arousal. The average time lag for the relationship between arousal and pupil diameter was 2.8 ms. In contrast to previous findings without a multimodal approach suggesting a positive correlation between the constructs, the results contribute to the state of research by highlighting the importance of multimodal data validation and research on convergent vagility. Future research should consider emotional regulation strategies and emotional valence.
Deep Reinforcement Learning: A Convex Optimization Approach
Feb 29, 2024In this paper, we consider reinforcement learning of nonlinear systems with continuous state and action spaces. We present an episodic learning algorithm, where we for each episode use convex optimization to find a two-layer neural network approximation of the optimal $Q$-function. The convex optimization approach guarantees that the weights calculated at each episode are optimal, with respect to the given sampled states and actions of the current episode. For stable nonlinear systems, we show that the algorithm converges and that the converging parameters of the trained neural network can be made arbitrarily close to the optimal neural network parameters. In particular, if the regularization parameter is $\rho$ and the time horizon is $T$, then the parameters of the trained neural network converge to $w$, where the distance between $w$ from the optimal parameters $w^\star$ is bounded by $\mathcal{O}(\rho T^{-1})$. That is, when the number of episodes goes to infinity, there exists a constant $C$ such that \[\|w-w^\star\| \le C\cdot\frac{\rho}{T}.\] In particular, our algorithm converges arbitrarily close to the optimal neural network parameters as the time horizon increases or as the regularization parameter decreases.
Critical windows: non-asymptotic theory for feature emergence in diffusion models
Mar 03, 2024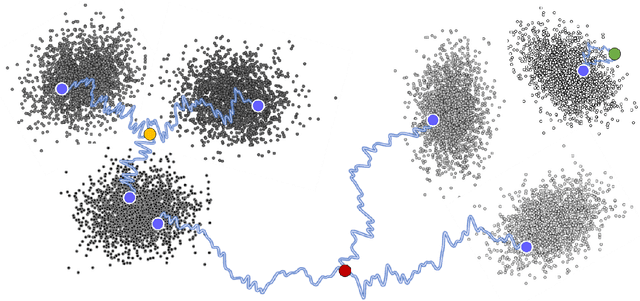
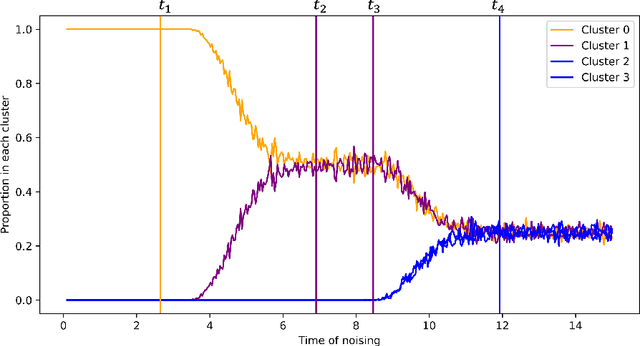

We develop theory to understand an intriguing property of diffusion models for image generation that we term critical windows. Empirically, it has been observed that there are narrow time intervals in sampling during which particular features of the final image emerge, e.g. the image class or background color (Ho et al., 2020b; Georgiev et al., 2023; Raya & Ambrogioni, 2023; Sclocchi et al., 2024; Biroli et al., 2024). While this is advantageous for interpretability as it implies one can localize properties of the generation to a small segment of the trajectory, it seems at odds with the continuous nature of the diffusion. We propose a formal framework for studying these windows and show that for data coming from a mixture of strongly log-concave densities, these windows can be provably bounded in terms of certain measures of inter- and intra-group separation. We also instantiate these bounds for concrete examples like well-conditioned Gaussian mixtures. Finally, we use our bounds to give a rigorous interpretation of diffusion models as hierarchical samplers that progressively "decide" output features over a discrete sequence of times. We validate our bounds with synthetic experiments. Additionally, preliminary experiments on Stable Diffusion suggest critical windows may serve as a useful tool for diagnosing fairness and privacy violations in real-world diffusion models.
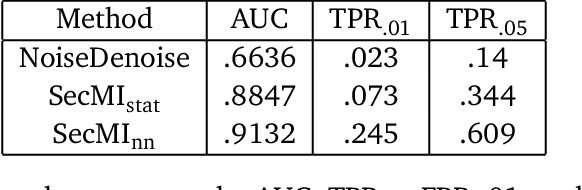
DUFOMap: Efficient Dynamic Awareness Mapping
Mar 03, 2024
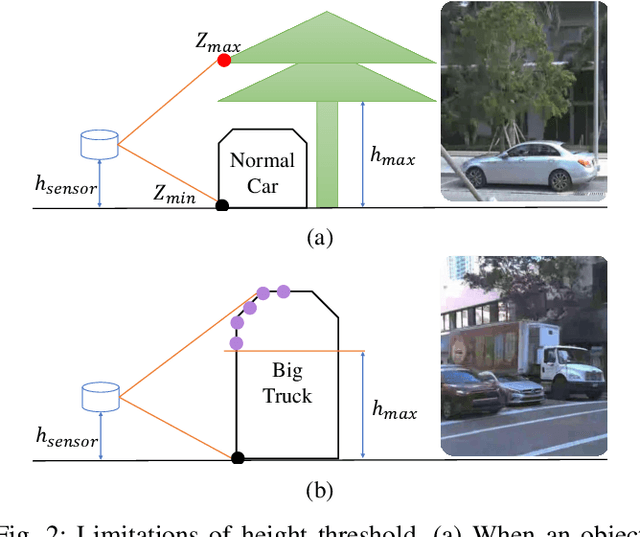
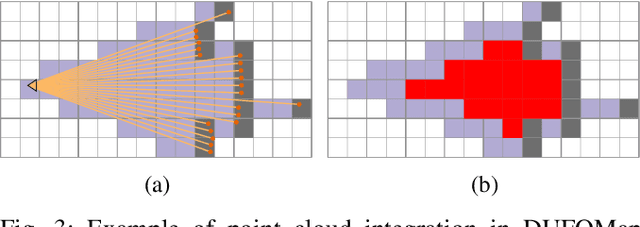
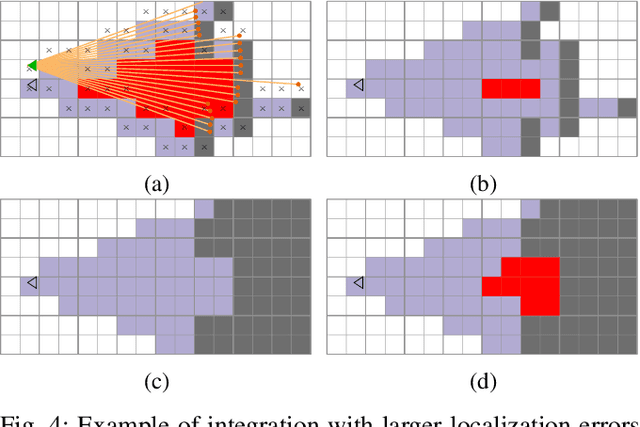
The dynamic nature of the real world is one of the main challenges in robotics. The first step in dealing with it is to detect which parts of the world are dynamic. A typical benchmark task is to create a map that contains only the static part of the world to support, for example, localization and planning. Current solutions are often applied in post-processing, where parameter tuning allows the user to adjust the setting for a specific dataset. In this paper, we propose DUFOMap, a novel dynamic awareness mapping framework designed for efficient online processing. Despite having the same parameter settings for all scenarios, it performs better or is on par with state-of-the-art methods. Ray casting is utilized to identify and classify fully observed empty regions. Since these regions have been observed empty, it follows that anything inside them at another time must be dynamic. Evaluation is carried out in various scenarios, including outdoor environments in KITTI and Argoverse 2, open areas on the KTH campus, and with different sensor types. DUFOMap outperforms the state of the art in terms of accuracy and computational efficiency. The source code, benchmarks, and links to the datasets utilized are provided. See https://kin-zhang.github.io/dufomap for more details.
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Feb 27, 2024Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.
On Latency Predictors for Neural Architecture Search
Mar 04, 2024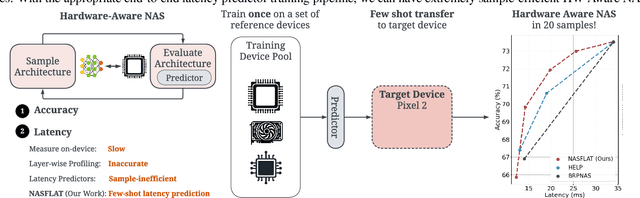
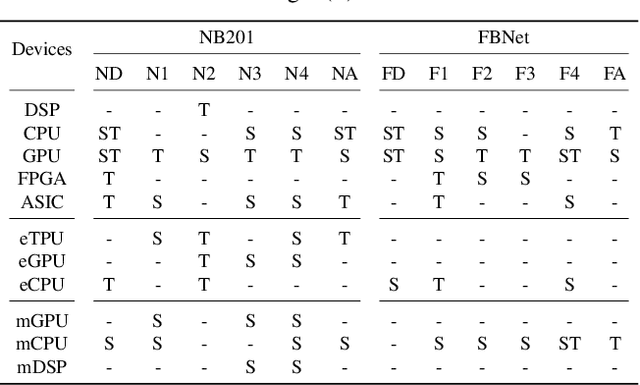
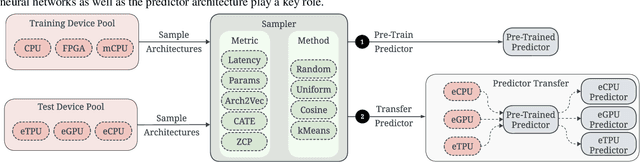

Efficient deployment of neural networks (NN) requires the co-optimization of accuracy and latency. For example, hardware-aware neural architecture search has been used to automatically find NN architectures that satisfy a latency constraint on a specific hardware device. Central to these search algorithms is a prediction model that is designed to provide a hardware latency estimate for a candidate NN architecture. Recent research has shown that the sample efficiency of these predictive models can be greatly improved through pre-training on some \textit{training} devices with many samples, and then transferring the predictor on the \textit{test} (target) device. Transfer learning and meta-learning methods have been used for this, but often exhibit significant performance variability. Additionally, the evaluation of existing latency predictors has been largely done on hand-crafted training/test device sets, making it difficult to ascertain design features that compose a robust and general latency predictor. To address these issues, we introduce a comprehensive suite of latency prediction tasks obtained in a principled way through automated partitioning of hardware device sets. We then design a general latency predictor to comprehensively study (1) the predictor architecture, (2) NN sample selection methods, (3) hardware device representations, and (4) NN operation encoding schemes. Building on conclusions from our study, we present an end-to-end latency predictor training strategy that outperforms existing methods on 11 out of 12 difficult latency prediction tasks, improving latency prediction by 22.5\% on average, and up to to 87.6\% on the hardest tasks. Focusing on latency prediction, our HW-Aware NAS reports a $5.8\times$ speedup in wall-clock time. Our code is available on \href{https://github.com/abdelfattah-lab/nasflat_latency}{https://github.com/abdelfattah-lab/nasflat\_latency}.
Brilla AI: AI Contestant for the National Science and Maths Quiz
Mar 04, 2024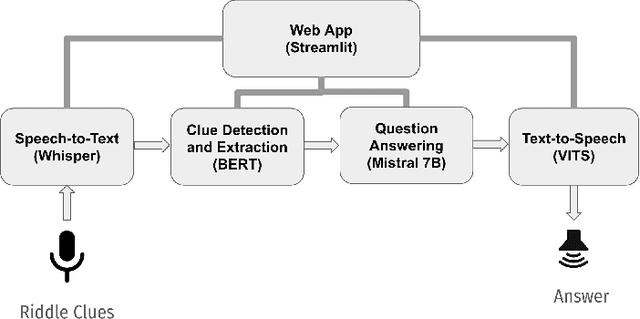
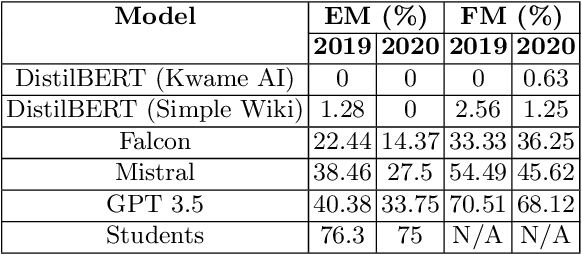

The African continent lacks enough qualified teachers which hampers the provision of adequate learning support. An AI could potentially augment the efforts of the limited number of teachers, leading to better learning outcomes. Towards that end, this work describes and evaluates the first key output for the NSMQ AI Grand Challenge, which proposes a robust, real-world benchmark for such an AI: "Build an AI to compete live in Ghana's National Science and Maths Quiz (NSMQ) competition and win - performing better than the best contestants in all rounds and stages of the competition". The NSMQ is an annual live science and mathematics competition for senior secondary school students in Ghana in which 3 teams of 2 students compete by answering questions across biology, chemistry, physics, and math in 5 rounds over 5 progressive stages until a winning team is crowned for that year. In this work, we built Brilla AI, an AI contestant that we deployed to unofficially compete remotely and live in the Riddles round of the 2023 NSMQ Grand Finale, the first of its kind in the 30-year history of the competition. Brilla AI is currently available as a web app that livestreams the Riddles round of the contest, and runs 4 machine learning systems: (1) speech to text (2) question extraction (3) question answering and (4) text to speech that work together in real-time to quickly and accurately provide an answer, and then say it with a Ghanaian accent. In its debut, our AI answered one of the 4 riddles ahead of the 3 human contesting teams, unofficially placing second (tied). Improvements and extensions of this AI could potentially be deployed to offer science tutoring to students and eventually enable millions across Africa to have one-on-one learning interactions, democratizing science education.