 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ZeroFL: Efficient On-Device Training for Federated Learning with Local Sparsity
Aug 04, 2022
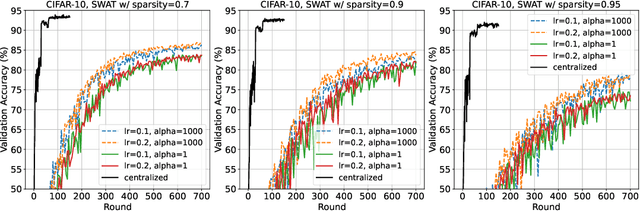
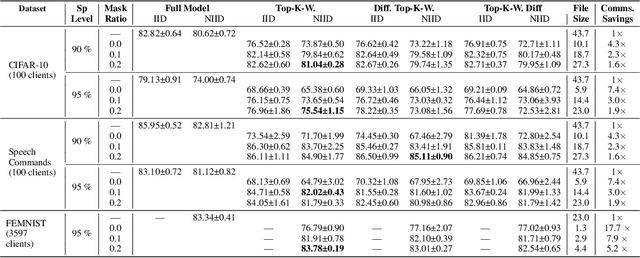
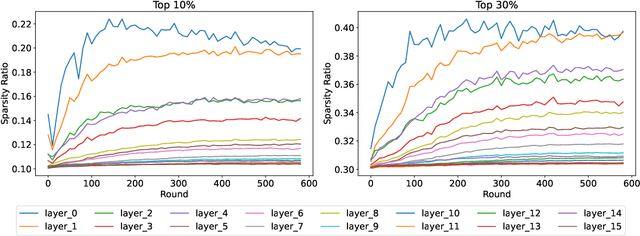
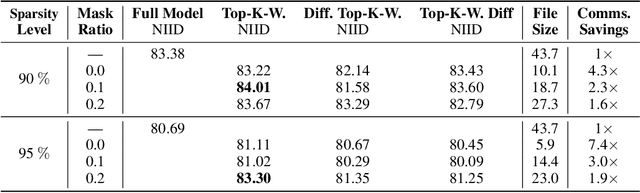
When the available hardware cannot meet the memory and compute requirements to efficiently train high performing machine learning models, a compromise in either the training quality or the model complexity is needed. In Federated Learning (FL), nodes are orders of magnitude more constrained than traditional server-grade hardware and are often battery powered, severely limiting the sophistication of models that can be trained under this paradigm. While most research has focused on designing better aggregation strategies to improve convergence rates and in alleviating the communication costs of FL, fewer efforts have been devoted to accelerating on-device training. Such stage, which repeats hundreds of times (i.e. every round) and can involve thousands of devices, accounts for the majority of the time required to train federated models and, the totality of the energy consumption at the client side. In this work, we present the first study on the unique aspects that arise when introducing sparsity at training time in FL workloads. We then propose ZeroFL, a framework that relies on highly sparse operations to accelerate on-device training. Models trained with ZeroFL and 95% sparsity achieve up to 2.3% higher accuracy compared to competitive baselines obtained from adapting a state-of-the-art sparse training framework to the FL setting.
* Published as a conference paper at ICLR 2022
Landmark Tracking in Liver US images Using Cascade Convolutional Neural Networks with Long Short-Term Memory
Sep 14, 2022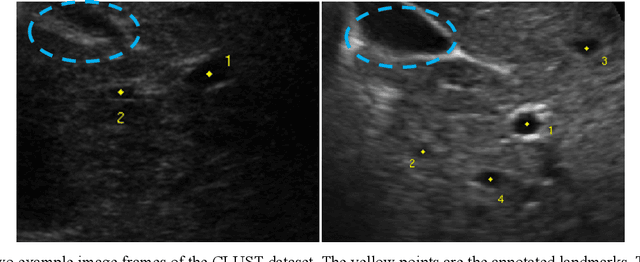
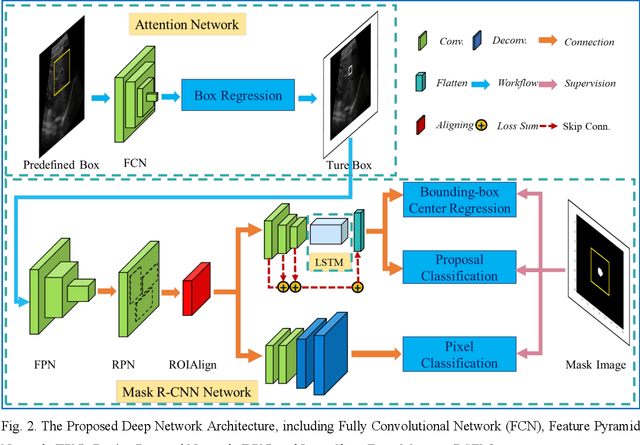
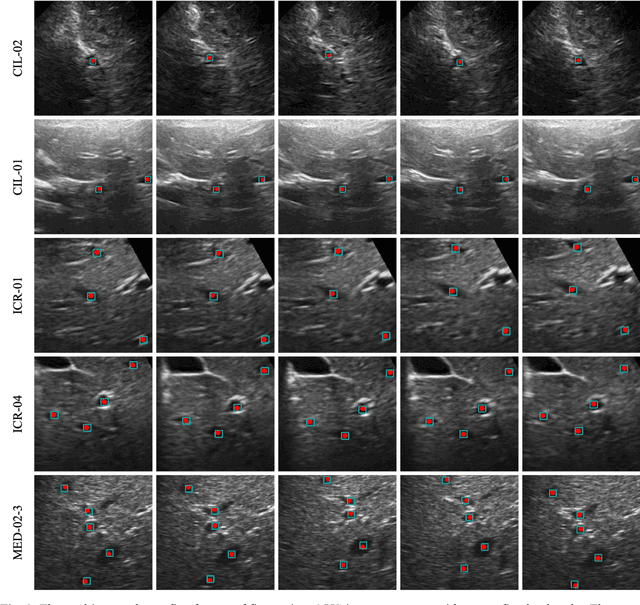
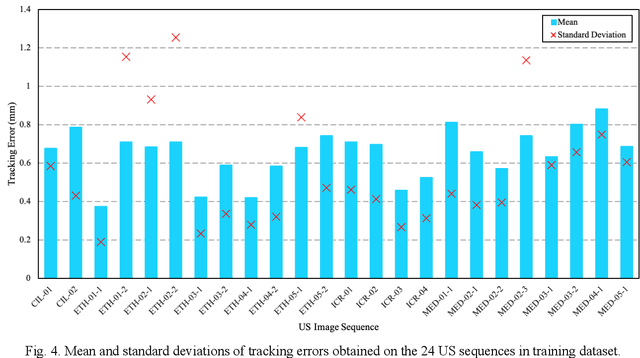
This study proposed a deep learning-based tracking method for ultrasound (US) image-guided radiation therapy. The proposed cascade deep learning model is composed of an attention network, a mask region-based convolutional neural network (mask R-CNN), and a long short-term memory (LSTM) network. The attention network learns a mapping from a US image to a suspected area of landmark motion in order to reduce the search region. The mask R-CNN then produces multiple region-of-interest (ROI) proposals in the reduced region and identifies the proposed landmark via three network heads: bounding box regression, proposal classification, and landmark segmentation. The LSTM network models the temporal relationship among the successive image frames for bounding box regression and proposal classification. To consolidate the final proposal, a selection method is designed according to the similarities between sequential frames. The proposed method was tested on the liver US tracking datasets used in the Medical Image Computing and Computer Assisted Interventions (MICCAI) 2015 challenges, where the landmarks were annotated by three experienced observers to obtain their mean positions. Five-fold cross-validation on the 24 given US sequences with ground truths shows that the mean tracking error for all landmarks is 0.65+/-0.56 mm, and the errors of all landmarks are within 2 mm. We further tested the proposed model on 69 landmarks from the testing dataset that has a similar image pattern to the training pattern, resulting in a mean tracking error of 0.94+/-0.83 mm. Our experimental results have demonstrated the feasibility and accuracy of our proposed method in tracking liver anatomic landmarks using US images, providing a potential solution for real-time liver tracking for active motion management during radiation therapy.
Confidence Estimation for Object Detection in Document Images
Aug 29, 2022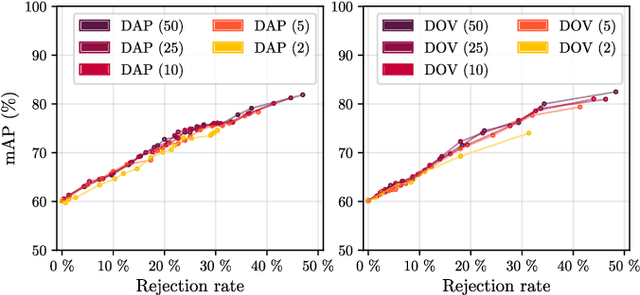
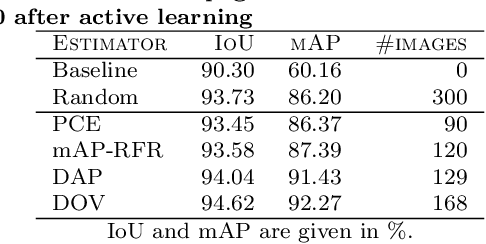
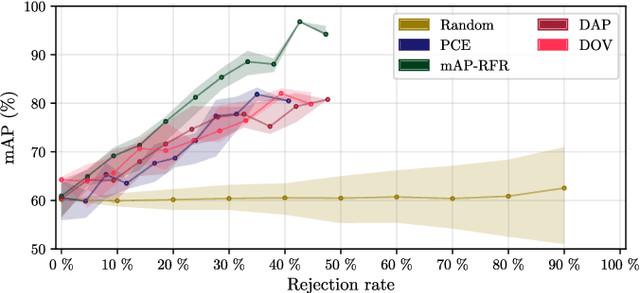
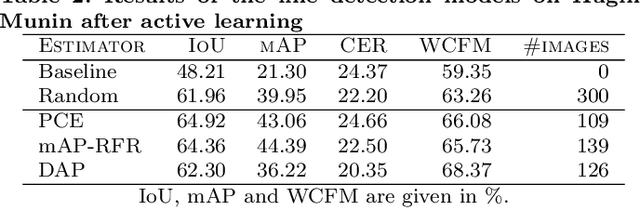
Deep neural networks are becoming increasingly powerful and large and always require more labelled data to be trained. However, since annotating data is time-consuming, it is now necessary to develop systems that show good performance while learning on a limited amount of data. These data must be correctly chosen to obtain models that are still efficient. For this, the systems must be able to determine which data should be annotated to achieve the best results. In this paper, we propose four estimators to estimate the confidence of object detection predictions. The first two are based on Monte Carlo dropout, the third one on descriptive statistics and the last one on the detector posterior probabilities. In the active learning framework, the three first estimators show a significant improvement in performance for the detection of document physical pages and text lines compared to a random selection of images. We also show that the proposed estimator based on descriptive statistics can replace MC dropout, reducing the computational cost without compromising the performances.
On the Design of Privacy-Aware Cameras: a Study on Deep Neural Networks
Aug 24, 2022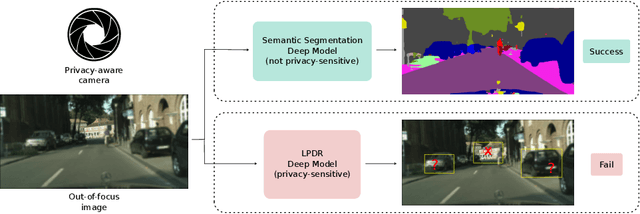
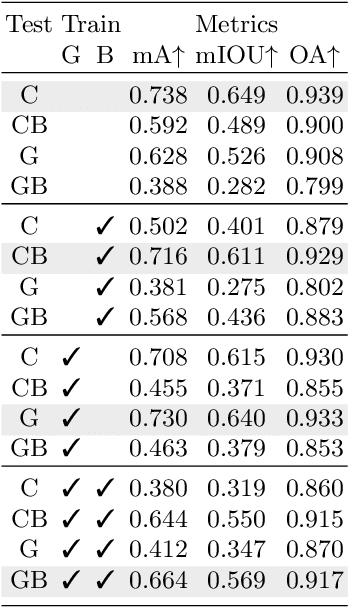
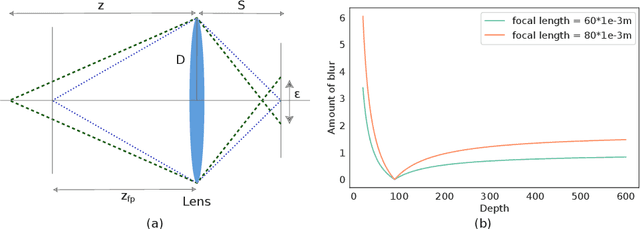

In spite of the legal advances in personal data protection, the issue of private data being misused by unauthorized entities is still of utmost importance. To prevent this, Privacy by Design is often proposed as a solution for data protection. In this paper, the effect of camera distortions is studied using Deep Learning techniques commonly used to extract sensitive data. To do so, we simulate out-of-focus images corresponding to a realistic conventional camera with fixed focal length, aperture, and focus, as well as grayscale images coming from a monochrome camera. We then prove, through an experimental study, that we can build a privacy-aware camera that cannot extract personal information such as license plate numbers. At the same time, we ensure that useful non-sensitive data can still be extracted from distorted images. Code is available at https://github.com/upciti/privacy-by-design-semseg .
Fault Detection and Classification of Aerospace Sensors using a VGG16-based Deep Neural Network
Jul 27, 2022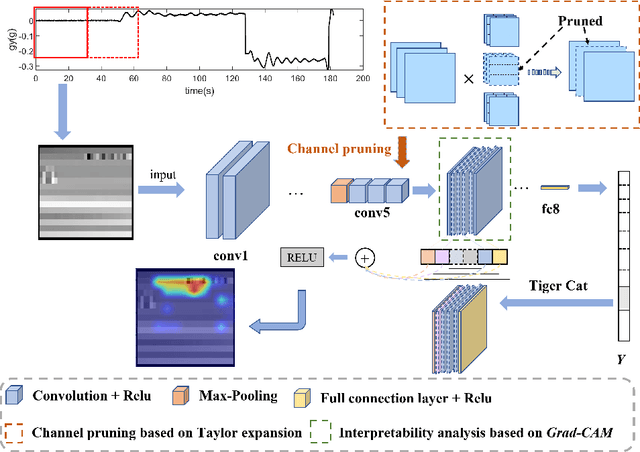
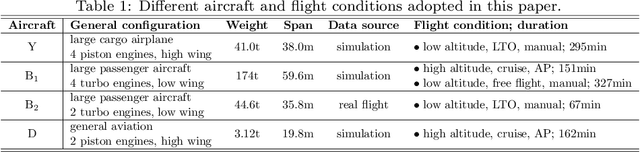

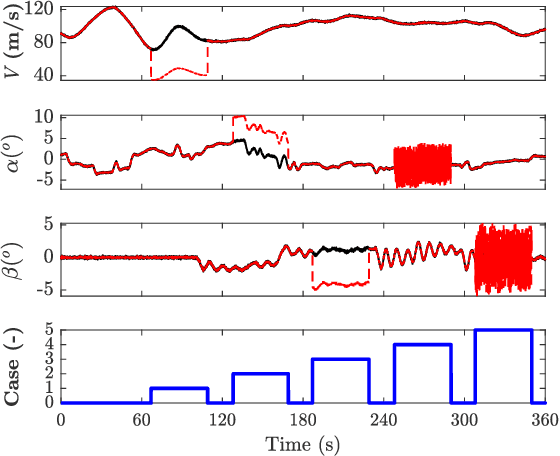
Compared with traditional model-based fault detection and classification (FDC) methods, deep neural networks (DNN) prove to be effective for the aerospace sensors FDC problems. However, time being consumed in training the DNN is excessive, and explainability analysis for the FDC neural network is still underwhelming. A concept known as imagefication-based intelligent FDC has been studied in recent years. This concept advocates to stack the sensors measurement data into an image format, the sensors FDC issue is then transformed to abnormal regions detection problem on the stacked image, which may well borrow the recent advances in the machine vision vision realm. Although promising results have been claimed in the imagefication-based intelligent FDC researches, due to the low size of the stacked image, small convolutional kernels and shallow DNN layers were used, which hinders the FDC performance. In this paper, we first propose a data augmentation method which inflates the stacked image to a larger size (correspondent to the VGG16 net developed in the machine vision realm). The FDC neural network is then trained via fine-tuning the VGG16 directly. To truncate and compress the FDC net size (hence its running time), we perform model pruning on the fine-tuned net. Class activation mapping (CAM) method is also adopted for explainability analysis of the FDC net to verify its internal operations. Via data augmentation, fine-tuning from VGG16, and model pruning, the FDC net developed in this paper claims an FDC accuracy 98.90% across 4 aircraft at 5 flight conditions (running time 26 ms). The CAM results also verify the FDC net w.r.t. its internal operations.
Active Learning of Classifiers with Label and Seed Queries
Sep 08, 2022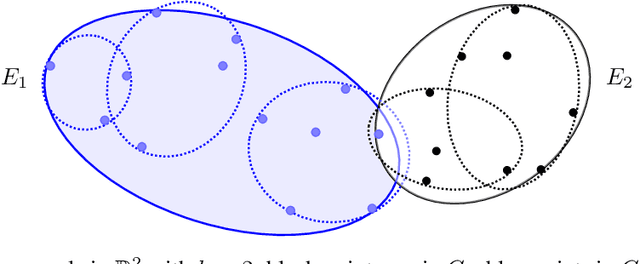
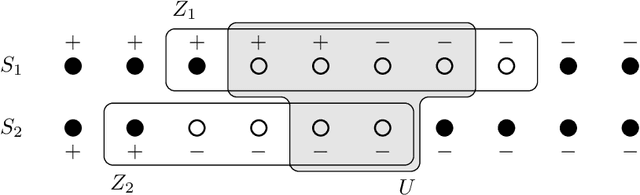
We study exact active learning of binary and multiclass classifiers with margin. Given an $n$-point set $X \subset \mathbb{R}^m$, we want to learn any unknown classifier on $X$ whose classes have finite strong convex hull margin, a new notion extending the SVM margin. In the standard active learning setting, where only label queries are allowed, learning a classifier with strong convex hull margin $\gamma$ requires in the worst case $\Omega\big(1+\frac{1}{\gamma}\big)^{(m-1)/2}$ queries. On the other hand, using the more powerful seed queries (a variant of equivalence queries), the target classifier could be learned in $O(m \log n)$ queries via Littlestone's Halving algorithm; however, Halving is computationally inefficient. In this work we show that, by carefully combining the two types of queries, a binary classifier can be learned in time $\operatorname{poly}(n+m)$ using only $O(m^2 \log n)$ label queries and $O\big(m \log \frac{m}{\gamma}\big)$ seed queries; the result extends to $k$-class classifiers at the price of a $k!k^2$ multiplicative overhead. Similar results hold when the input points have bounded bit complexity, or when only one class has strong convex hull margin against the rest. We complement the upper bounds by showing that in the worst case any algorithm needs $\Omega\big(k m \log \frac{1}{\gamma}\big)$ seed and label queries to learn a $k$-class classifier with strong convex hull margin $\gamma$.
Online Video Super-Resolution with Convolutional Kernel Bypass Graft
Aug 04, 2022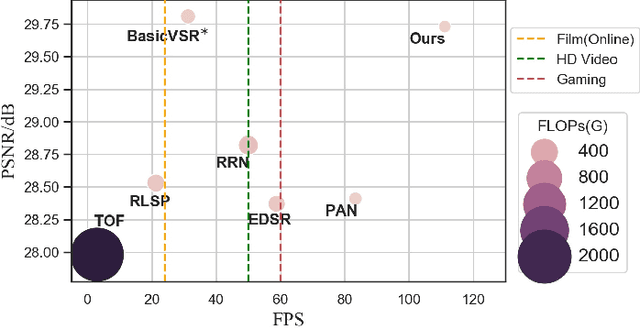

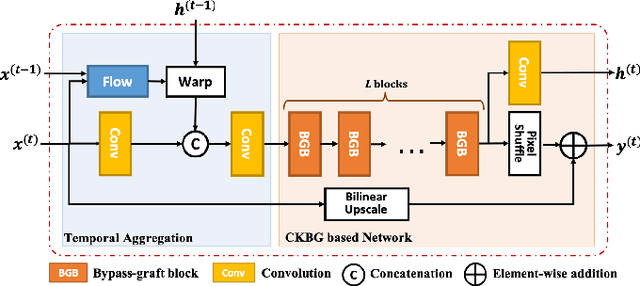
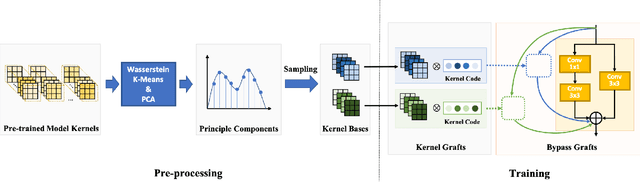
Deep learning-based models have achieved remarkable performance in video super-resolution (VSR) in recent years, but most of these models are less applicable to online video applications. These methods solely consider the distortion quality and ignore crucial requirements for online applications, e.g., low latency and low model complexity. In this paper, we focus on online video transmission, in which VSR algorithms are required to generate high-resolution video sequences frame by frame in real time. To address such challenges, we propose an extremely low-latency VSR algorithm based on a novel kernel knowledge transfer method, named convolutional kernel bypass graft (CKBG). First, we design a lightweight network structure that does not require future frames as inputs and saves extra time costs for caching these frames. Then, our proposed CKBG method enhances this lightweight base model by bypassing the original network with ``kernel grafts'', which are extra convolutional kernels containing the prior knowledge of external pretrained image SR models. In the testing phase, we further accelerate the grafted multi-branch network by converting it into a simple single-path structure. Experiment results show that our proposed method can process online video sequences up to 110 FPS, with very low model complexity and competitive SR performance.
Denoised Labels for Financial Time-Series Data via Self-Supervised Learning
Dec 19, 2021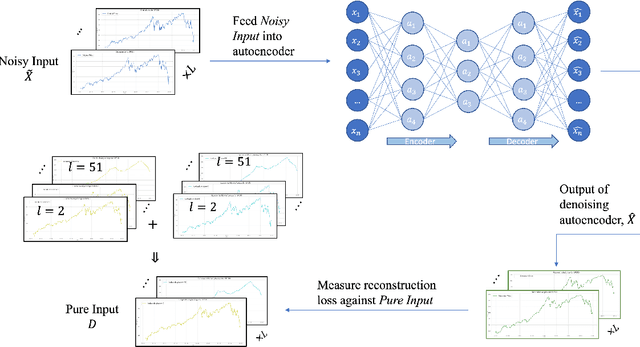
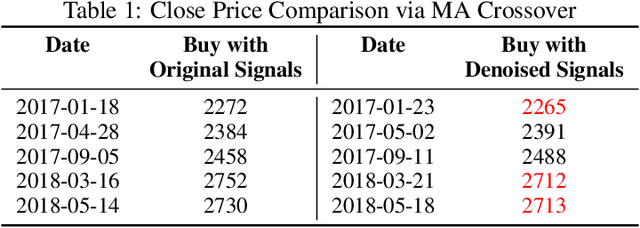
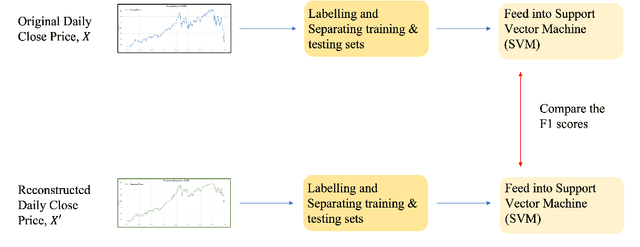
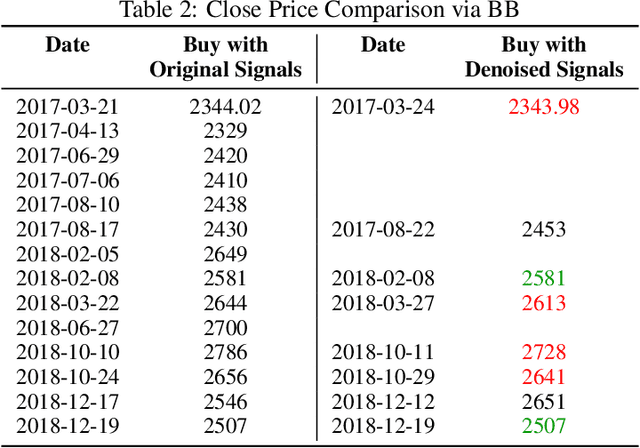
The introduction of electronic trading platforms effectively changed the organisation of traditional systemic trading from quote-driven markets into order-driven markets. Its convenience led to an exponentially increasing amount of financial data, which is however hard to use for the prediction of future prices, due to the low signal-to-noise ratio and the non-stationarity of financial time series. Simpler classification tasks -- where the goal is to predict the directions of future price movement -- via supervised learning algorithms, need sufficiently reliable labels to generalise well. Labelling financial data is however less well defined than other domains: did the price go up because of noise or because of signal? The existing labelling methods have limited countermeasures against noise and limited effects in improving learning algorithms. This work takes inspiration from image classification in trading and success in self-supervised learning. We investigate the idea of applying computer vision techniques to financial time-series to reduce the noise exposure and hence generate correct labels. We look at the label generation as the pretext task of a self-supervised learning approach and compare the naive (and noisy) labels, commonly used in the literature, with the labels generated by a denoising autoencoder for the same downstream classification task. Our results show that our denoised labels improve the performances of the downstream learning algorithm, for both small and large datasets. We further show that the signals we obtain can be used to effectively trade with binary strategies. We suggest that with proposed techniques, self-supervised learning constitutes a powerful framework for generating "better" financial labels that are useful for studying the underlying patterns of the market.
Evolutionary Preference Learning via Graph Nested GRU ODE for Session-based Recommendation
Jun 26, 2022
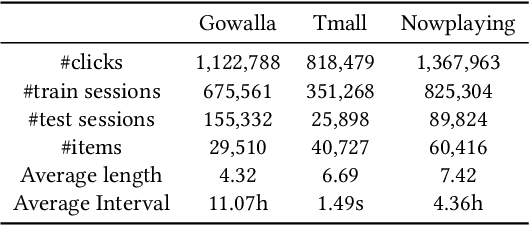
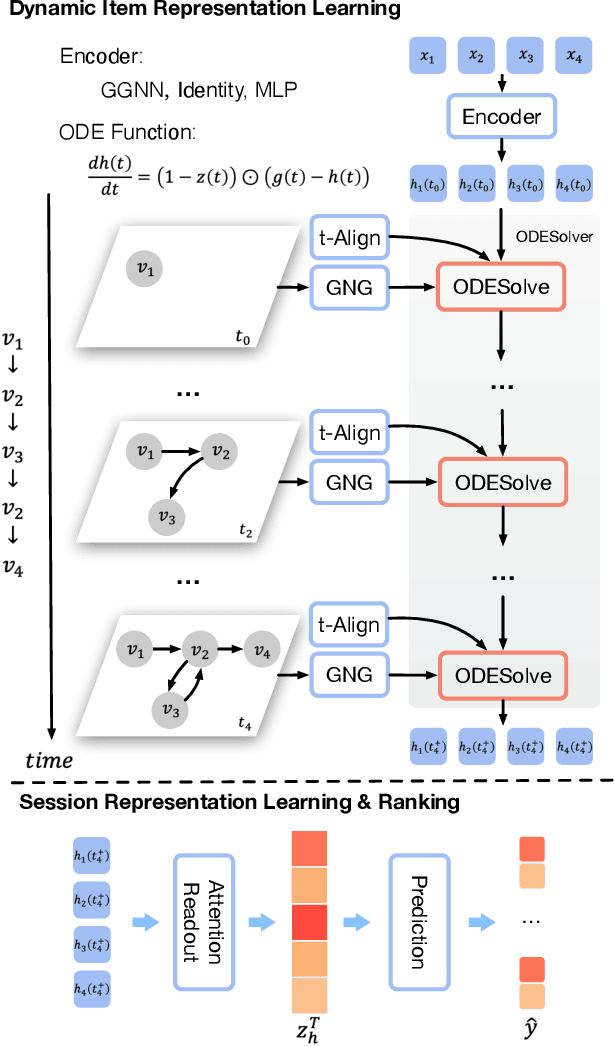
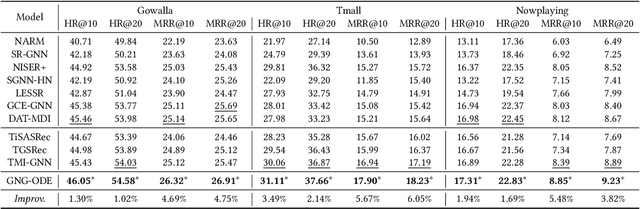
Session-based recommendation (SBR) aims to predict the user next action based on the ongoing sessions. Recently, there has been an increasing interest in modeling the user preference evolution to capture the fine-grained user interests. While latent user preferences behind the sessions drift continuously over time, most existing approaches still model the temporal session data in discrete state spaces, which are incapable of capturing the fine-grained preference evolution and result in sub-optimal solutions. To this end, we propose Graph Nested GRU ordinary differential equation (ODE), namely GNG-ODE, a novel continuum model that extends the idea of neural ODEs to continuous-time temporal session graphs. The proposed model preserves the continuous nature of dynamic user preferences, encoding both temporal and structural patterns of item transitions into continuous-time dynamic embeddings. As the existing ODE solvers do not consider graph structure change and thus cannot be directly applied to the dynamic graph, we propose a time alignment technique, called t-Alignment, to align the updating time steps of the temporal session graphs within a batch. Empirical results on three benchmark datasets show that GNG-ODE significantly outperforms other baselines.
Learning to Solve Soft-Constrained Vehicle Routing Problems with Lagrangian Relaxation
Jul 29, 2022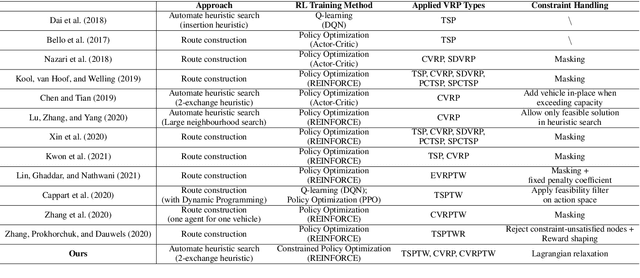

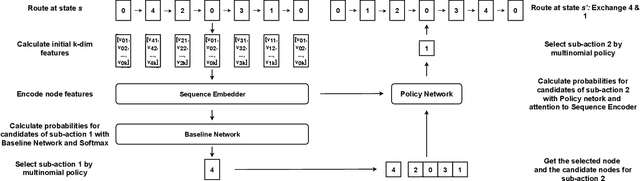
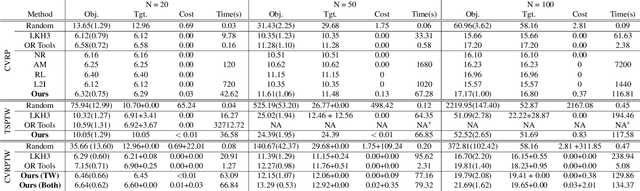
Vehicle Routing Problems (VRPs) in real-world applications often come with various constraints, therefore bring additional computational challenges to exact solution methods or heuristic search approaches. The recent idea to learn heuristic move patterns from sample data has become increasingly promising to reduce solution developing costs. However, using learning-based approaches to address more types of constrained VRP remains a challenge. The difficulty lies in controlling for constraint violations while searching for optimal solutions. To overcome this challenge, we propose a Reinforcement Learning based method to solve soft-constrained VRPs by incorporating the Lagrangian relaxation technique and using constrained policy optimization. We apply the method on three common types of VRPs, the Travelling Salesman Problem with Time Windows (TSPTW), the Capacitated VRP (CVRP) and the Capacitated VRP with Time Windows (CVRPTW), to show the generalizability of the proposed method. After comparing to existing RL-based methods and open-source heuristic solvers, we demonstrate its competitive performance in finding solutions with a good balance in travel distance, constraint violations and inference speed.