 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Marker-free Extrinsic Camera Calibration using Person Keypoint Detections
Sep 15, 2022
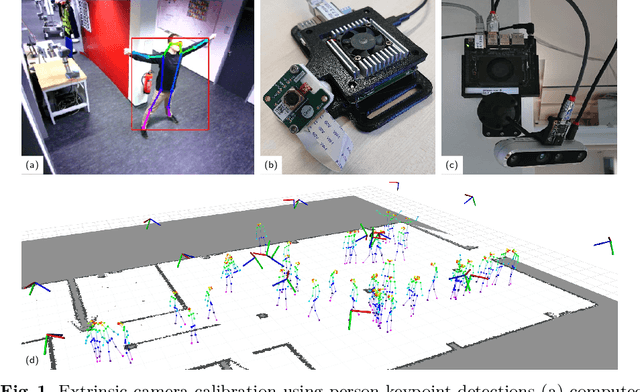
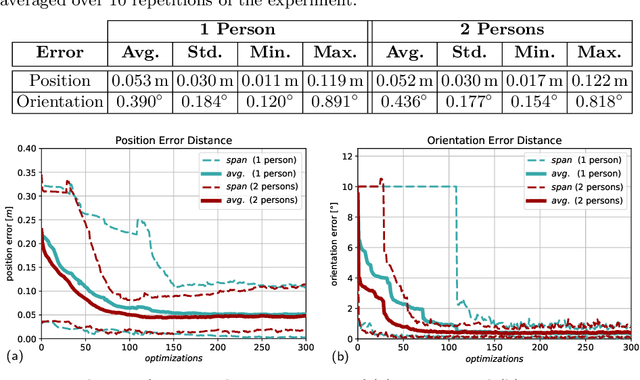
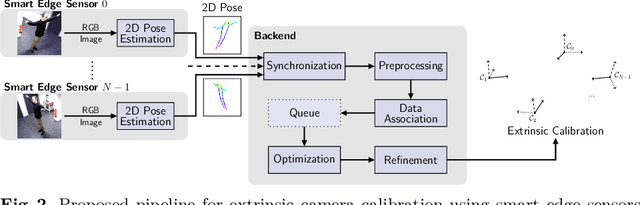
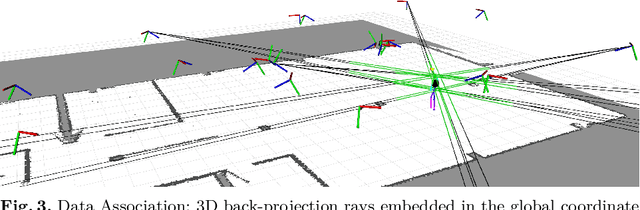
Calibration of multi-camera systems, i.e. determining the relative poses between the cameras, is a prerequisite for many tasks in computer vision and robotics. Camera calibration is typically achieved using offline methods that use checkerboard calibration targets. These methods, however, often are cumbersome and lengthy, considering that a new calibration is required each time any camera pose changes. In this work, we propose a novel, marker-free online method for the extrinsic calibration of multiple smart edge sensors, relying solely on 2D human keypoint detections that are computed locally on the sensor boards from RGB camera images. Our method assumes the intrinsic camera parameters to be known and requires priming with a rough initial estimate of the camera poses. The person keypoint detections from multiple views are received at a central backend where they are synchronized, filtered, and assigned to person hypotheses. We use these person hypotheses to repeatedly solve optimization problems in the form of factor graphs. Given suitable observations of one or multiple persons traversing the scene, the estimated camera poses converge towards a coherent extrinsic calibration within a few minutes. We evaluate our approach in real-world settings and show that the calibration with our method achieves lower reprojection errors compared to a reference calibration generated by an offline method using a traditional calibration target.
MDM: Molecular Diffusion Model for 3D Molecule Generation
Sep 13, 2022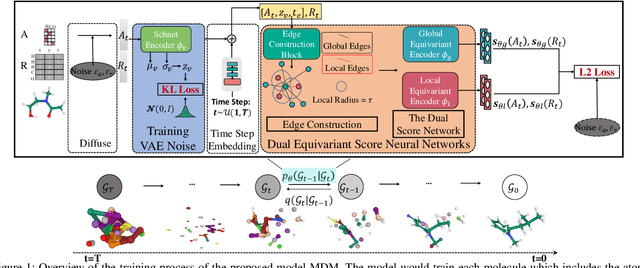
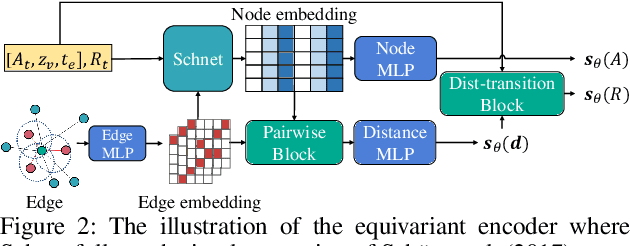
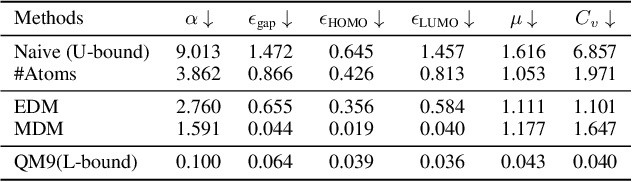
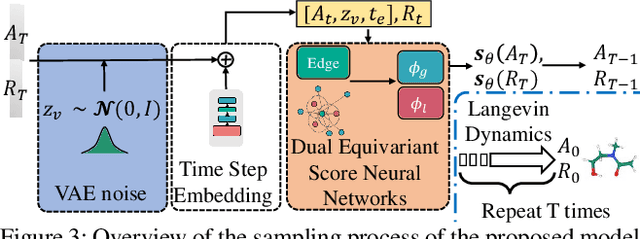
Molecule generation, especially generating 3D molecular geometries from scratch (i.e., 3D \textit{de novo} generation), has become a fundamental task in drug designs. Existing diffusion-based 3D molecule generation methods could suffer from unsatisfactory performances, especially when generating large molecules. At the same time, the generated molecules lack enough diversity. This paper proposes a novel diffusion model to address those two challenges. First, interatomic relations are not in molecules' 3D point cloud representations. Thus, it is difficult for existing generative models to capture the potential interatomic forces and abundant local constraints. To tackle this challenge, we propose to augment the potential interatomic forces and further involve dual equivariant encoders to encode interatomic forces of different strengths. Second, existing diffusion-based models essentially shift elements in geometry along the gradient of data density. Such a process lacks enough exploration in the intermediate steps of the Langevin dynamics. To address this issue, we introduce a distributional controlling variable in each diffusion/reverse step to enforce thorough explorations and further improve generation diversity. Extensive experiments on multiple benchmarks demonstrate that the proposed model significantly outperforms existing methods for both unconditional and conditional generation tasks. We also conduct case studies to help understand the physicochemical properties of the generated molecules.
Meta-Learning Online Control for Linear Dynamical Systems
Aug 18, 2022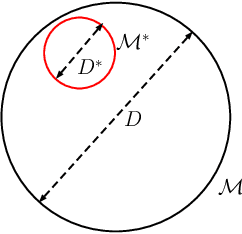
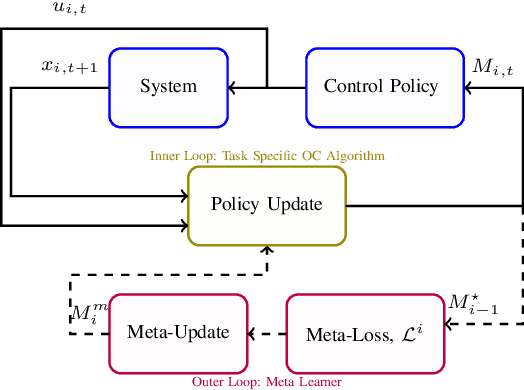
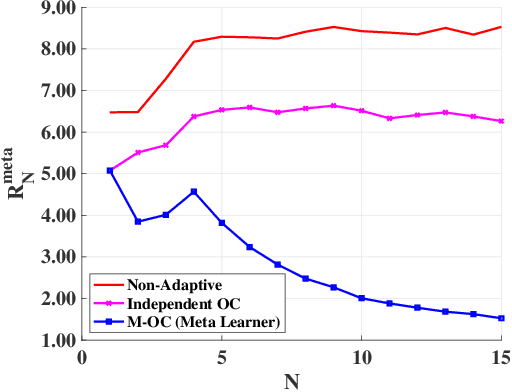
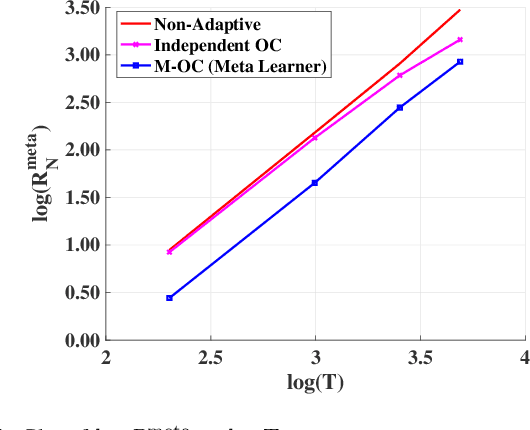
In this paper, we consider the problem of finding a meta-learning online control algorithm that can learn across the tasks when faced with a sequence of $N$ (similar) control tasks. Each task involves controlling a linear dynamical system for a finite horizon of $T$ time steps. The cost function and system noise at each time step are adversarial and unknown to the controller before taking the control action. Meta-learning is a broad approach where the goal is to prescribe an online policy for any new unseen task exploiting the information from other tasks and the similarity between the tasks. We propose a meta-learning online control algorithm for the control setting and characterize its performance by \textit{meta-regret}, the average cumulative regret across the tasks. We show that when the number of tasks are sufficiently large, our proposed approach achieves a meta-regret that is smaller by a factor $D/D^{*}$ compared to an independent-learning online control algorithm which does not perform learning across the tasks, where $D$ is a problem constant and $D^{*}$ is a scalar that decreases with increase in the similarity between tasks. Thus, when the sequence of tasks are similar the regret of the proposed meta-learning online control is significantly lower than that of the naive approaches without meta-learning. We also present experiment results to demonstrate the superior performance achieved by our meta-learning algorithm.
HarDNet-DFUS: An Enhanced Harmonically-Connected Network for Diabetic Foot Ulcer Image Segmentation and Colonoscopy Polyp Segmentation
Sep 15, 2022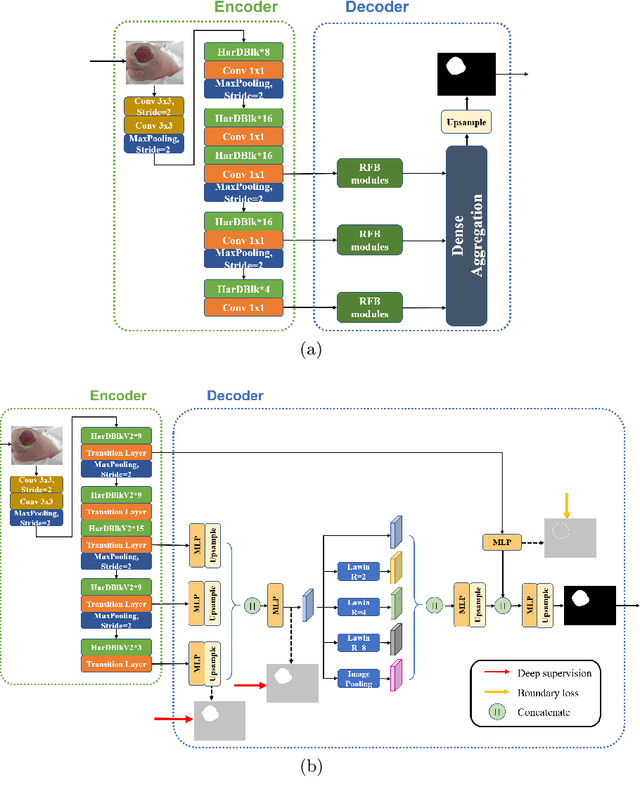

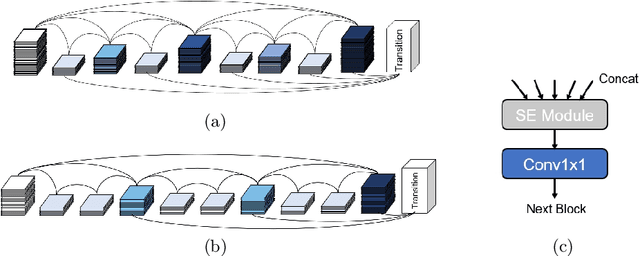

We present a neural network architecture for medical image segmentation of diabetic foot ulcers and colonoscopy polyps. Diabetic foot ulcers are caused by neuropathic and vascular complications of diabetes mellitus. In order to provide a proper diagnosis and treatment, wound care professionals need to extract accurate morphological features from the foot wounds. Using computer-aided systems is a promising approach to extract related morphological features and segment the lesions. We propose a convolution neural network called HarDNet-DFUS by enhancing the backbone and replacing the decoder of HarDNet-MSEG, which was SOTA for colonoscopy polyp segmentation in 2021. For the MICCAI 2022 Diabetic Foot Ulcer Segmentation Challenge (DFUC2022), we train HarDNet-DFUS using the DFUC2022 dataset and increase its robustness by means of five-fold cross validation, Test Time Augmentation, etc. In the validation phase of DFUC2022, HarDNet-DFUS achieved 0.7063 mean dice and was ranked third among all participants. In the final testing phase of DFUC2022, it achieved 0.7287 mean dice and was the first place winner. HarDNet-DFUS also deliver excellent performance for the colonoscopy polyp segmentation task. It achieves 0.924 mean Dice on the famous Kvasir dataset, an improvement of 1.2\% over the original HarDNet-MSEG. The codes are available on https://github.com/kytimmylai/DFUC2022 (for Diabetic Foot Ulcers Segmentation) and https://github.com/YuWenLo/HarDNet-DFUS (for Colonoscopy Polyp Segmentation).
Time-Frequency Attention for Monaural Speech Enhancement
Nov 17, 2021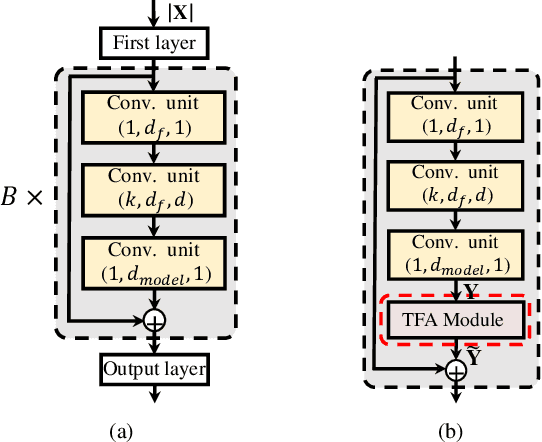
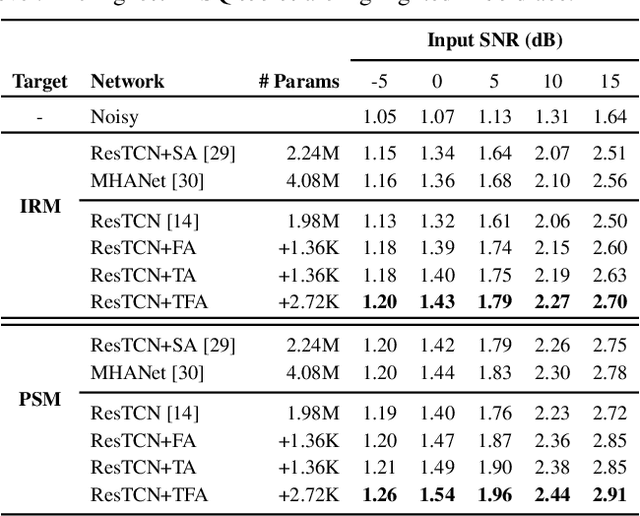
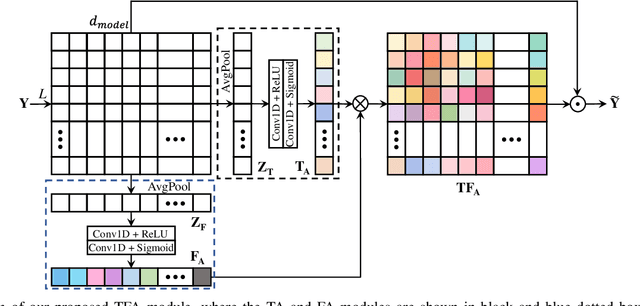
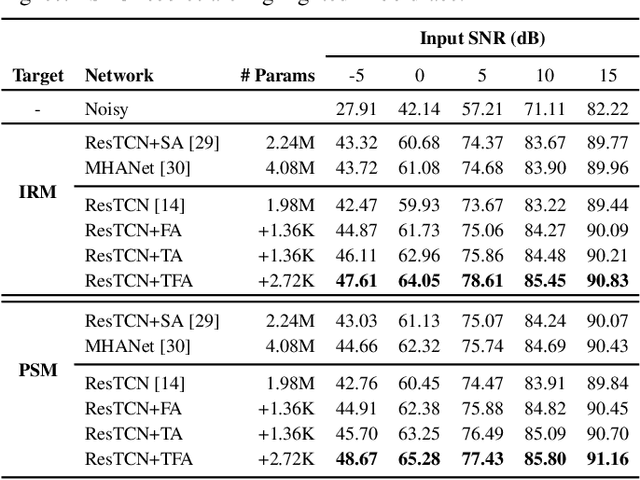
Most studies on speech enhancement generally don't consider the energy distribution of speech in time-frequency (T-F) representation, which is important for accurate prediction of mask or spectra. In this paper, we present a simple yet effective T-F attention (TFA) module, where a 2-D attention map is produced to provide differentiated weights to the spectral components of T-F representation. To validate the effectiveness of our proposed TFA module, we use the residual temporal convolution network (ResTCN) as the backbone network and conduct extensive experiments on two commonly used training targets. Our experiments demonstrate that applying our TFA module significantly improves the performance in terms of five objective evaluation metrics with negligible parameter overhead. The evaluation results show that the proposed ResTCN with the TFA module (ResTCN+TFA) consistently outperforms other baselines by a large margin.
High-dimensional Multivariate Time Series Forecasting in IoT Applications using Embedding Non-stationary Fuzzy Time Series
Jul 20, 2021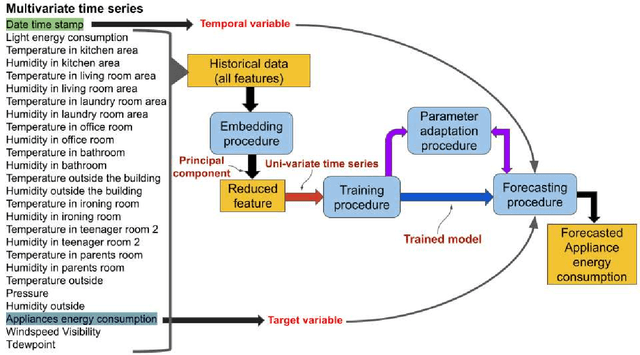

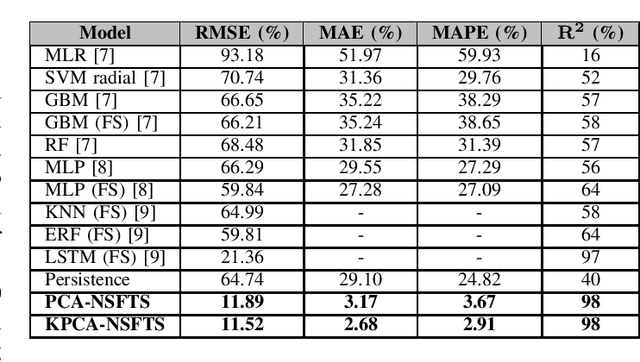
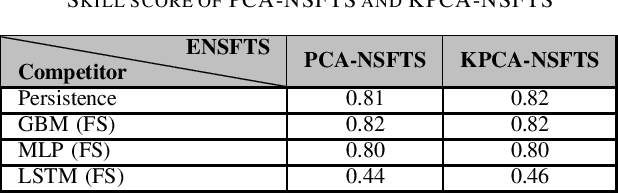
In Internet of things (IoT), data is continuously recorded from different data sources and devices can suffer faults in their embedded electronics, thus leading to a high-dimensional data sets and concept drift events. Therefore, methods that are capable of high-dimensional non-stationary time series are of great value in IoT applications. Fuzzy Time Series (FTS) models stand out as data-driven non-parametric models of easy implementation and high accuracy. Unfortunately, FTS encounters difficulties when dealing with data sets of many variables and scenarios with concept drift. We present a new approach to handle high-dimensional non-stationary time series, by projecting the original high-dimensional data into a low dimensional embedding space and using FTS approach. Combining these techniques enables a better representation of the complex content of non-stationary multivariate time series and accurate forecasts. Our model is able to explain 98% of the variance and reach 11.52% of RMSE, 2.68% of MAE and 2.91% of MAPE.
Automated Assessment of Transthoracic Echocardiogram Image Quality Using Deep Neural Networks
Sep 02, 2022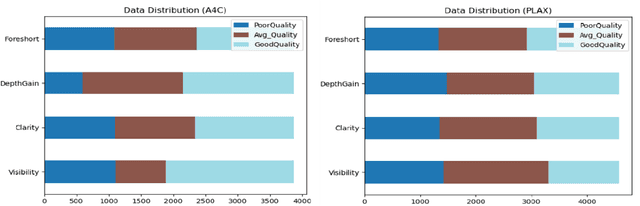
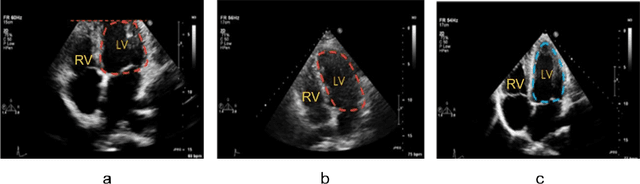
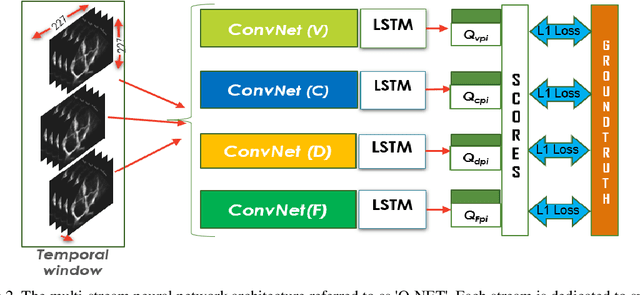
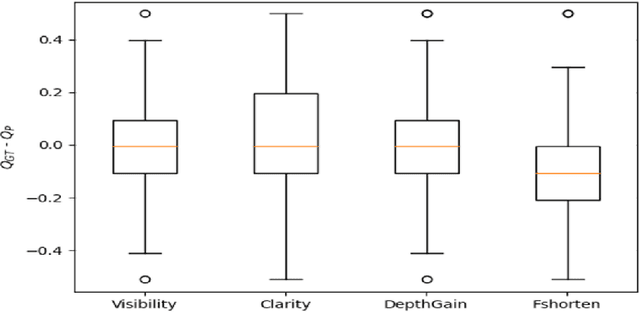
Standard views in two-dimensional echocardiography are well established but the quality of acquired images are highly dependent on operator skills and are assessed subjectively. This study is aimed at providing an objective assessment pipeline for echocardiogram image quality by defining a new set of domain-specific quality indicators. Consequently, image quality assessment can thus be automated to enhance clinical measurements, interpretation, and real-time optimization. We have developed deep neural networks for the automated assessment of echocardiographic frame which were randomly sampled from 11,262 adult patients. The private echocardiography dataset consists of 33,784 frames, previously acquired between 2010 and 2020. Deep learning approaches were used to extract the spatiotemporal features and the image quality indicators were evaluated against the mean absolute error. Our quality indicators encapsulate both anatomical and pathological elements to provide multivariate assessment scores for anatomical visibility, clarity, depth-gain and foreshortedness, respectively.
Harnessing Abstractive Summarization for Fact-Checked Claim Detection
Sep 10, 2022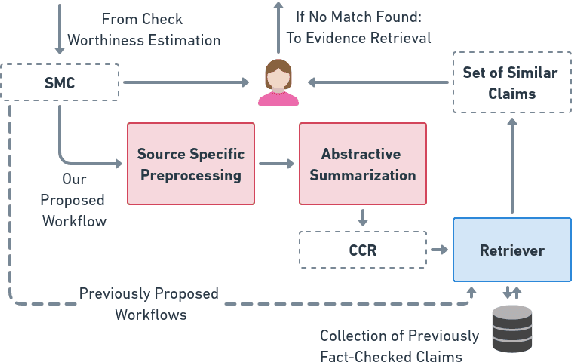
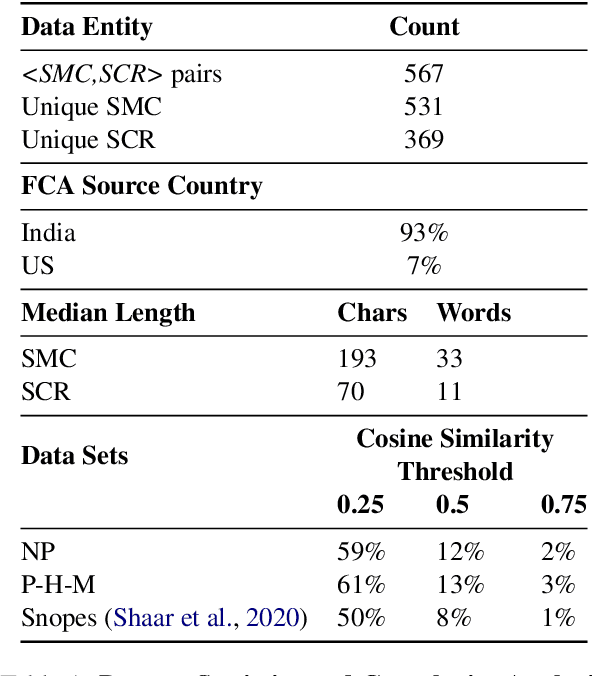
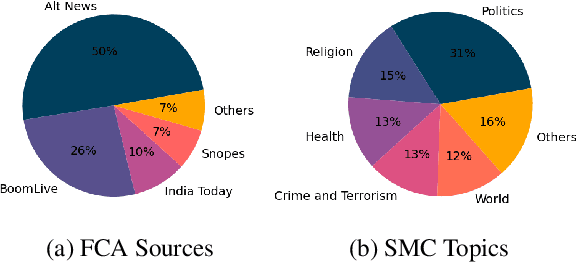
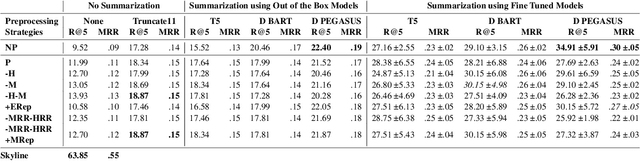
Social media platforms have become new battlegrounds for anti-social elements, with misinformation being the weapon of choice. Fact-checking organizations try to debunk as many claims as possible while staying true to their journalistic processes but cannot cope with its rapid dissemination. We believe that the solution lies in partial automation of the fact-checking life cycle, saving human time for tasks which require high cognition. We propose a new workflow for efficiently detecting previously fact-checked claims that uses abstractive summarization to generate crisp queries. These queries can then be executed on a general-purpose retrieval system associated with a collection of previously fact-checked claims. We curate an abstractive text summarization dataset comprising noisy claims from Twitter and their gold summaries. It is shown that retrieval performance improves 2x by using popular out-of-the-box summarization models and 3x by fine-tuning them on the accompanying dataset compared to verbatim querying. Our approach achieves Recall@5 and MRR of 35% and 0.3, compared to baseline values of 10% and 0.1, respectively. Our dataset, code, and models are available publicly: https://github.com/varadhbhatnagar/FC-Claim-Det/
Accurate online training of dynamical spiking neural networks through Forward Propagation Through Time
Dec 20, 2021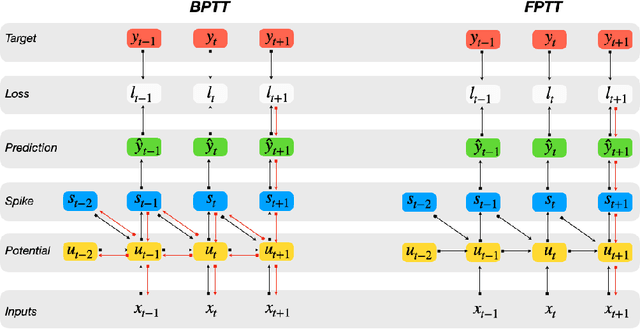
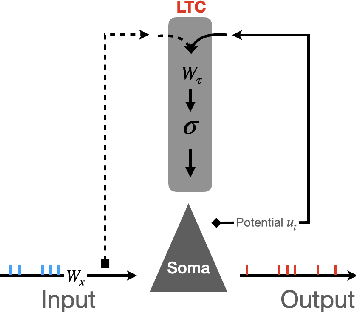
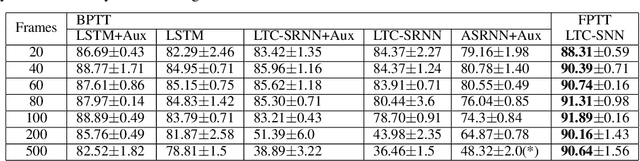
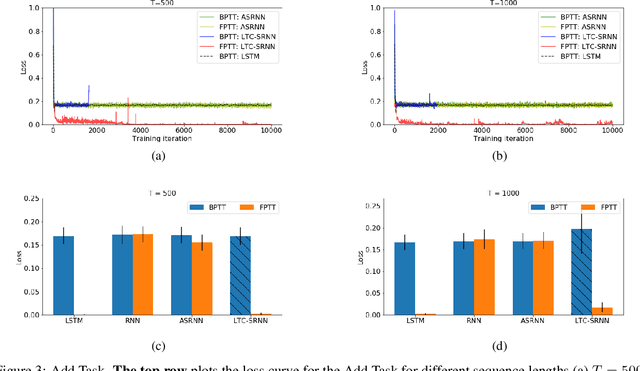
The event-driven and sparse nature of communication between spiking neurons in the brain holds great promise for flexible and energy-efficient AI. Recent advances in learning algorithms have demonstrated that recurrent networks of spiking neurons can be effectively trained to achieve competitive performance compared to standard recurrent neural networks. Still, as these learning algorithms use error-backpropagation through time (BPTT), they suffer from high memory requirements, are slow to train, and are incompatible with online learning. This limits the application of these learning algorithms to relatively small networks and to limited temporal sequence lengths. Online approximations to BPTT with lower computational and memory complexity have been proposed (e-prop, OSTL), but in practice also suffer from memory limitations and, as approximations, do not outperform standard BPTT training. Here, we show how a recently developed alternative to BPTT, Forward Propagation Through Time (FPTT) can be applied in spiking neural networks. Different from BPTT, FPTT attempts to minimize an ongoing dynamically regularized risk on the loss. As a result, FPTT can be computed in an online fashion and has fixed complexity with respect to the sequence length. When combined with a novel dynamic spiking neuron model, the Liquid-Time-Constant neuron, we show that SNNs trained with FPTT outperform online BPTT approximations, and approach or exceed offline BPTT accuracy on temporal classification tasks. This approach thus makes it feasible to train SNNs in a memory-friendly online fashion on long sequences and scale up SNNs to novel and complex neural architectures.
D-Flow: A Real Time Spatial Temporal Model for Target Area Segmentation
Nov 08, 2021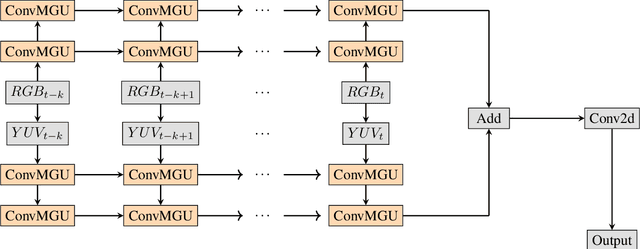
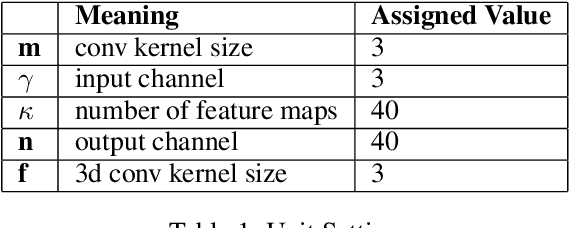
Semantic segmentation has attracted a large amount of attention in recent years. In robotics, segmentation can be used to identify a region of interest, or \emph{target area}. For example, in the RoboCup Standard Platform League (SPL), segmentation separates the soccer field from the background and from players on the field. For satellite or vehicle applications, it is often necessary to find certain regions such as roads, bodies of water or kinds of terrain. In this paper, we propose a novel approach to real-time target area segmentation based on a newly designed spatial temporal network. The method operates under domain constraints defined by both the robot's hardware and its operating environment . The proposed network is able to run in real-time, working within the constraints of limited run time and computing power. This work is compared against other real time segmentation methods on a dataset generated by a Nao V6 humanoid robot simulating the RoboCup SPL competition. In this case, the target area is defined as the artificial grass field. The method is also tested on a maritime dataset collected by a moving vessel, where the aim is to separate the ocean region from the rest of the image. This dataset demonstrates that the proposed model can generalise to a variety of vision problems.