 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time FPGA Design for OMP Targeting 8K Image Reconstruction
Oct 10, 2021
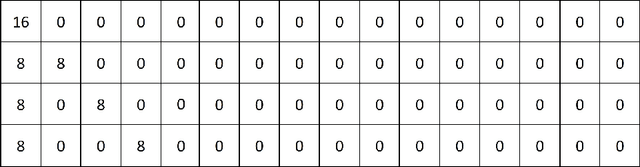
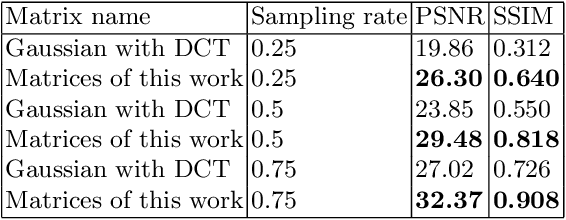

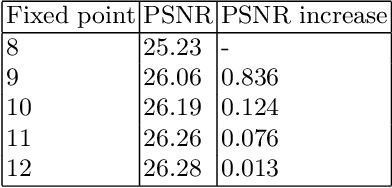
During the past decade, implementing reconstruction algorithms on hardware has been at the center of much attention in the field of real-time reconstruction in Compressed Sensing (CS). Orthogonal Matching Pursuit (OMP) is the most widely used reconstruction algorithm on hardware implementation because OMP obtains good quality reconstruction results under a proper time cost. OMP includes Dot Product (DP) and Least Square Problem (LSP). These two parts have numerous division calculations and considerable vector-based multiplications, which limit the implementation of real-time reconstruction on hardware. In the theory of CS, besides the reconstruction algorithm, the choice of sensing matrix affects the quality of reconstruction. It also influences the reconstruction efficiency by affecting the hardware architecture. Thus, designing a real-time hardware architecture of OMP needs to take three factors into consideration. The choice of sensing matrix, the implementation of DP and LSP. In this paper, a sensing matrix, which is sparsity and contains zero vectors mainly, is adopted to optimize the OMP reconstruction to break the bottleneck of reconstruction efficiency. Based on the features of the chosen matrix, the DP and LSP are implemented by simple shift, add and comparing procedures. This work is implemented on the Xilinx Virtex UltraScale+ FPGA device. To reconstruct a digital signal with 1024 length under 0.25 sampling rate, the proposal method costs 0.818us while the state-of-the-art costs 238$us. Thus, this work speedups the state-of-the-art method 290 times. This work costs 0.026s to reconstruct an 8K gray image, which achieves 30FPS real-time reconstruction.
Cost-Efficient Deployment of a Reliable Multi-UAV Unmanned Aerial System
Aug 30, 2022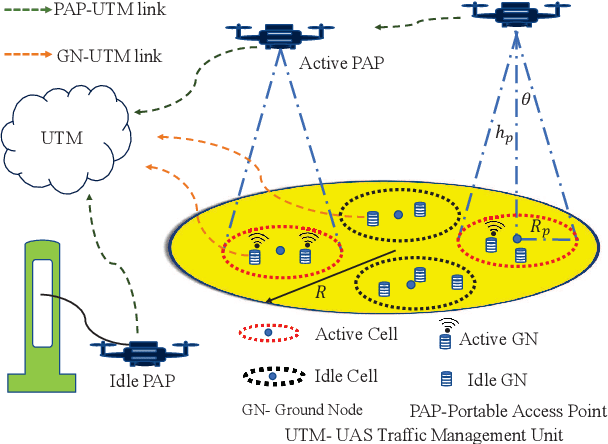
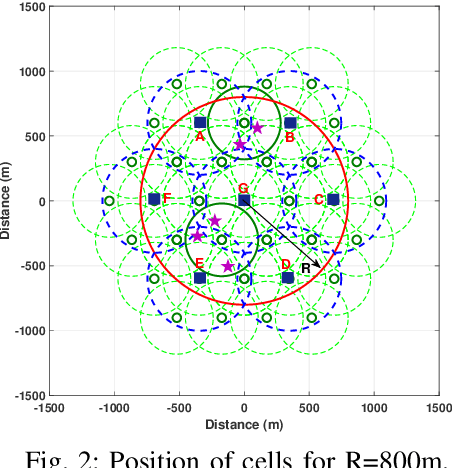
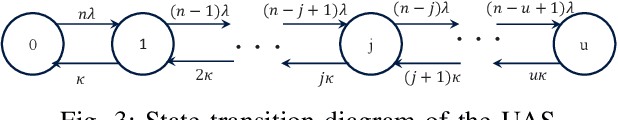
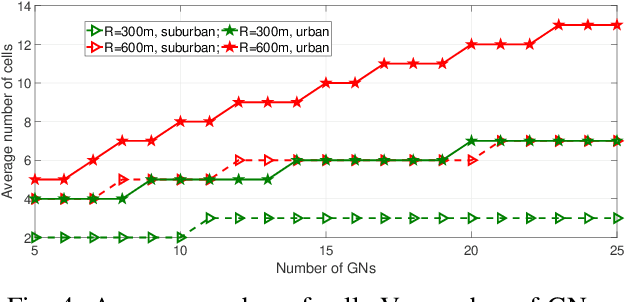
In this work, we study the trade-off between the reliability and the investment cost of an unmanned aerial system (UAS) consisting of a set of unmanned aerial vehicles (UAVs) carrying radio access nodes, called portable access points (PAPs)), deployed to serve a set of ground nodes (GNs). Using the proposed algorithm, a given geographical region is equivalently represented as a set of circular regions, where each circle represents the coverage region of a PAP. Then, the steady-state availability of the UAS is analytically derived by modelling it as a continuous time birth-death Markov decision process (MDP). Numerical evaluations show that the investment cost to guarantee a given steady-state availability to a set of GNs can be reduced by considering the traffic demand and distribution of GNs.
Entity-based Claim Representation Improves Fact-Checking of Medical Content in Tweets
Sep 16, 2022
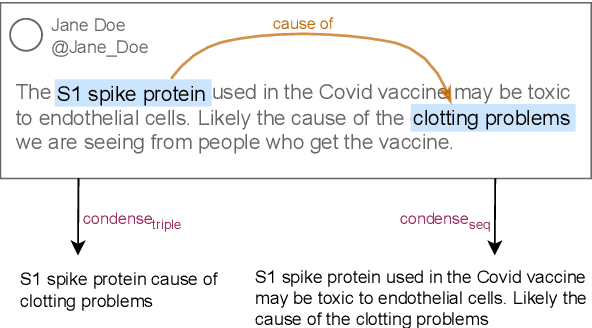
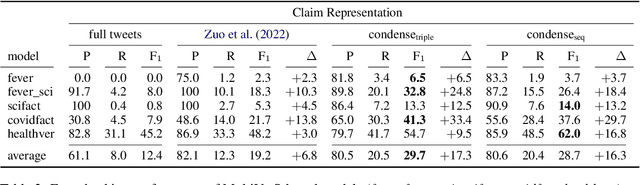
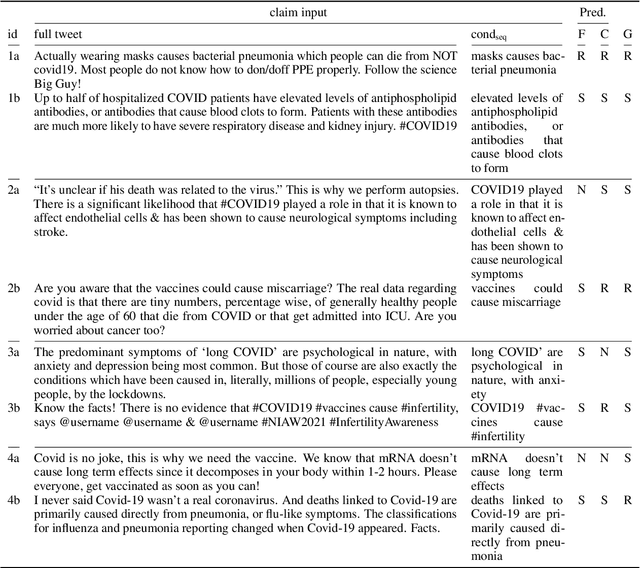
False medical information on social media poses harm to people's health. While the need for biomedical fact-checking has been recognized in recent years, user-generated medical content has received comparably little attention. At the same time, models for other text genres might not be reusable, because the claims they have been trained with are substantially different. For instance, claims in the SciFact dataset are short and focused: "Side effects associated with antidepressants increases risk of stroke". In contrast, social media holds naturally-occurring claims, often embedded in additional context: "`If you take antidepressants like SSRIs, you could be at risk of a condition called serotonin syndrome' Serotonin syndrome nearly killed me in 2010. Had symptoms of stroke and seizure." This showcases the mismatch between real-world medical claims and the input that existing fact-checking systems expect. To make user-generated content checkable by existing models, we propose to reformulate the social-media input in such a way that the resulting claim mimics the claim characteristics in established datasets. To accomplish this, our method condenses the claim with the help of relational entity information and either compiles the claim out of an entity-relation-entity triple or extracts the shortest phrase that contains these elements. We show that the reformulated input improves the performance of various fact-checking models as opposed to checking the tweet text in its entirety.
Semantic Segmentation in Learned Compressed Domain
Sep 03, 2022
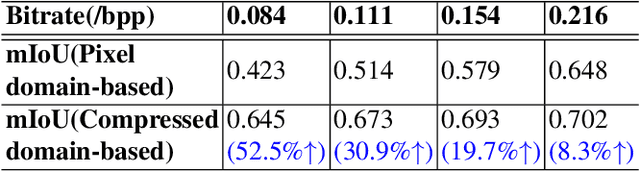
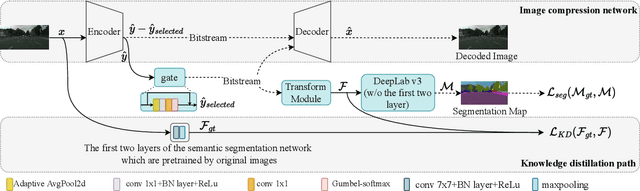

Most machine vision tasks (e.g., semantic segmentation) are based on images encoded and decoded by image compression algorithms (e.g., JPEG). However, these decoded images in the pixel domain introduce distortion, and they are optimized for human perception, making the performance of machine vision tasks suboptimal. In this paper, we propose a method based on the compressed domain to improve segmentation tasks. i) A dynamic and a static channel selection method are proposed to reduce the redundancy of compressed representations that are obtained by encoding. ii) Two different transform modules are explored and analyzed to help the compressed representation be transformed as the features in the segmentation network. The experimental results show that we can save up to 15.8\% bitrates compared with a state-of-the-art compressed domain-based work while saving up to about 83.6\% bitrates and 44.8\% inference time compared with the pixel domain-based method.
TransPolymer: a Transformer-based Language Model for Polymer Property Predictions
Sep 11, 2022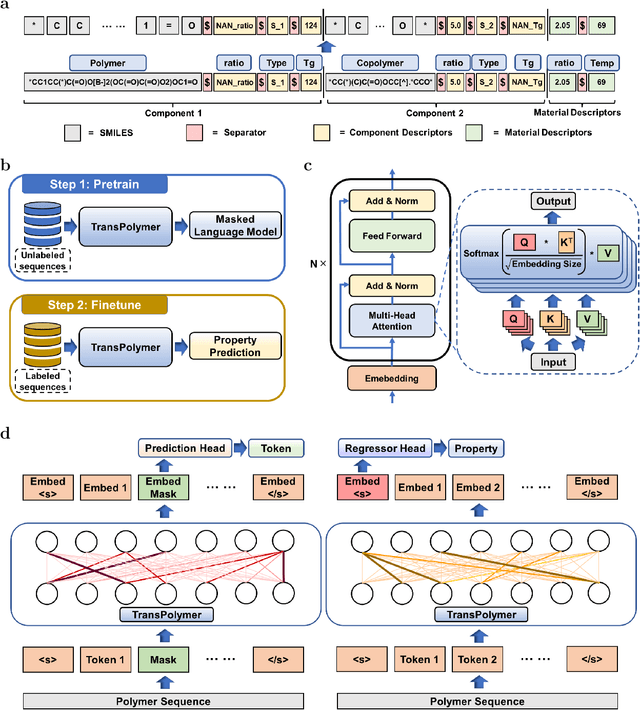
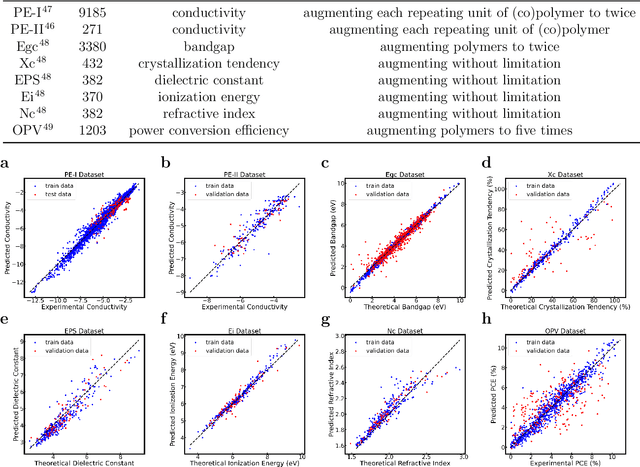
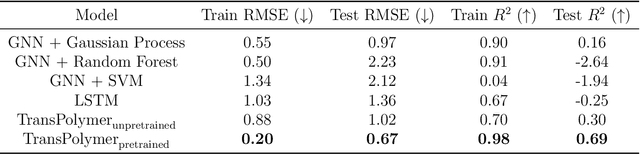
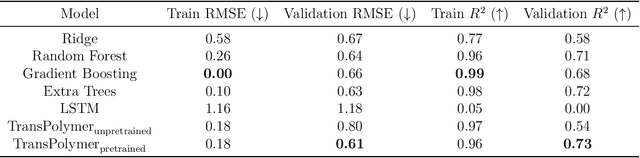
Accurate and efficient prediction of polymer properties is of great significance in polymer development and design. Conventionally, expensive and time-consuming experiments or simulations are required to evaluate the function of polymers. Recently, Transformer models, equipped with attention mechanisms, have exhibited superior performance in various natural language processing tasks. However, such methods have not been investigated in polymer sciences. Herein, we report TransPolymer, a Transformer-based language model for polymer property prediction. Owing to our proposed polymer tokenizer with chemical awareness, TransPolymer can learn representations directly from polymer sequences. The model learns expressive representations by pretraining on a large unlabeled dataset, followed by finetuning the model on downstream datasets concerning various polymer properties. TransPolymer achieves superior performance in all eight datasets and surpasses other baselines significantly on most downstream tasks. Moreover, the improvement by the pretrained TransPolymer over supervised TransPolymer and other language models strengthens the significant benefits of pretraining on large unlabeled data in representation learning. Experiment results further demonstrate the important role of the attention mechanism in understanding polymer sequences. We highlight this model as a promising computational tool for promoting rational polymer design and understanding structure-property relationships in a data science view.
Time-Energy-Constrained Closed-Loop FBL Communication for Dependable MEC
Dec 07, 2021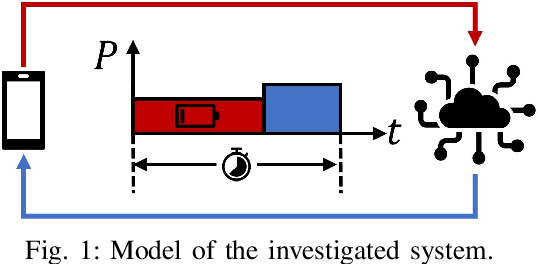
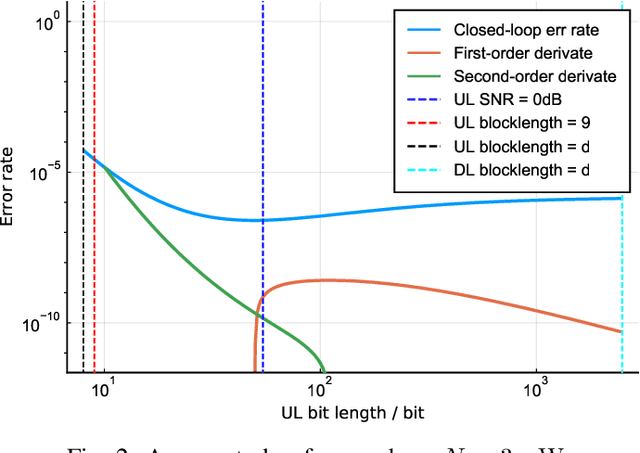
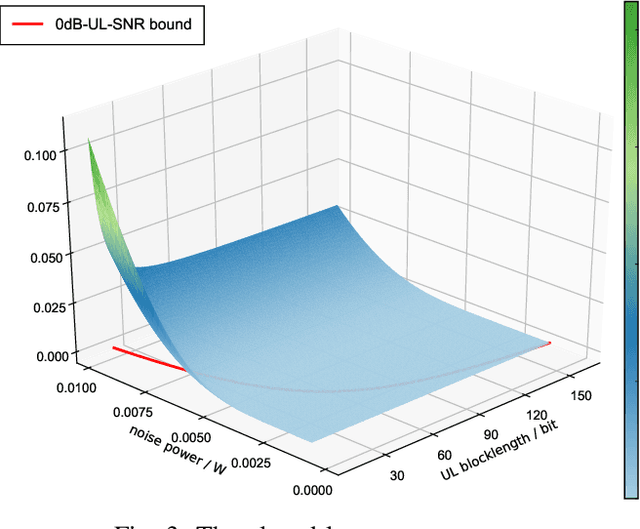
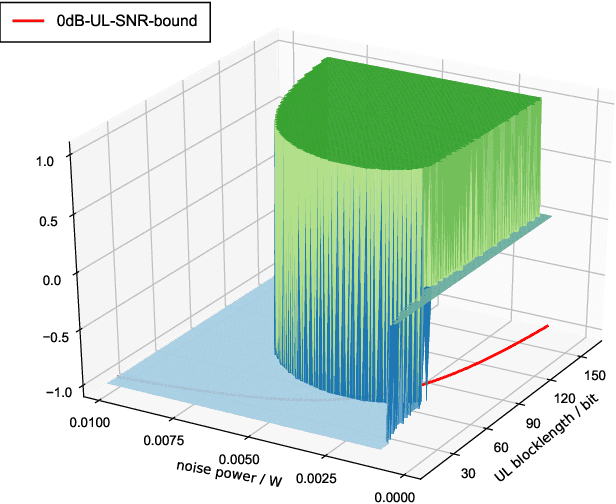
The deployment of multi-access edge computing (MEC) is paving the way towards pervasive intelligence in future 6G networks. This new paradigm also proposes emerging requirements of dependable communications, which goes beyond the ultra-reliable low latency communication (URLLC), focusing on the performance of a closed loop instead of that of an unidirectional link. This work studies the simple but efficient one-shot transmission scheme, investigating the closed-loop-reliability-optimal policy of blocklength allocation under stringent time and energy constraints.
Entity Tagging: Extracting Entities in Text Without Mention Supervision
Sep 13, 2022
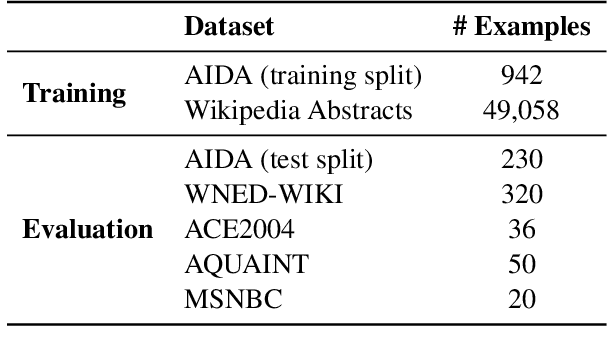

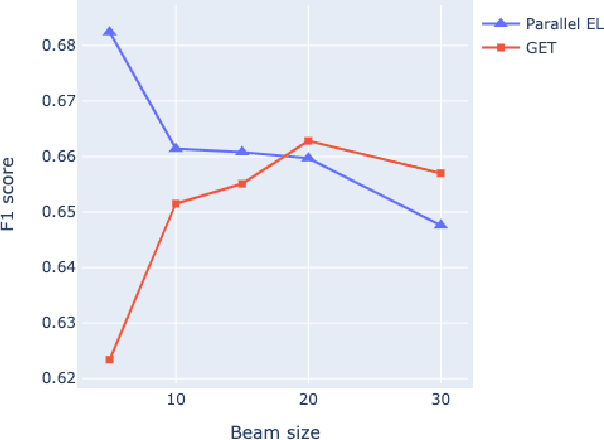
Detection and disambiguation of all entities in text is a crucial task for a wide range of applications. The typical formulation of the problem involves two stages: detect mention boundaries and link all mentions to a knowledge base. For a long time, mention detection has been considered as a necessary step for extracting all entities in a piece of text, even if the information about mention spans is ignored by some downstream applications that merely focus on the set of extracted entities. In this paper we show that, in such cases, detection of mention boundaries does not bring any considerable performance gain in extracting entities, and therefore can be skipped. To conduct our analysis, we propose an "Entity Tagging" formulation of the problem, where models are evaluated purely on the set of extracted entities without considering mentions. We compare a state-of-the-art mention-aware entity linking solution against GET, a mention-agnostic sequence-to-sequence model that simply outputs a list of disambiguated entities given an input context. We find that these models achieve comparable performance when trained both on a fully and partially annotated dataset across multiple benchmarks, demonstrating that GET can extract disambiguated entities with strong performance without explicit mention boundaries supervision.
Multiscale Adaptive Scheduling and Path-Planning for Power-Constrained UAV-Relays via SMDPs
Sep 16, 2022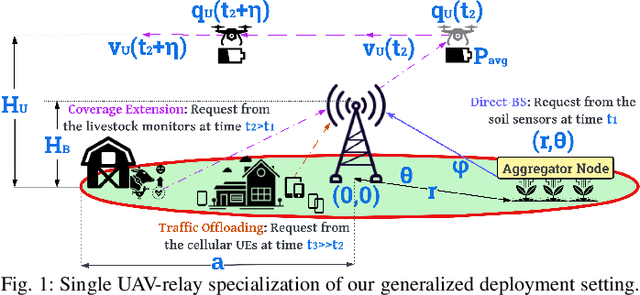
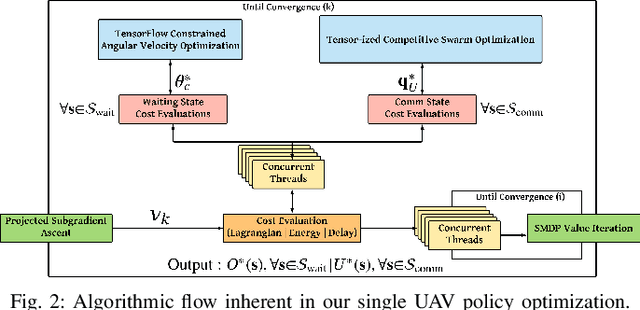
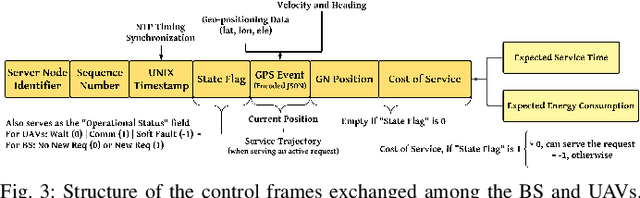
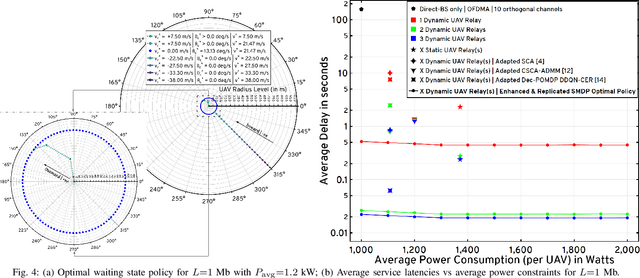
We describe the orchestration of a decentralized swarm of rotary-wing UAV-relays, augmenting the coverage and service capabilities of a terrestrial base station. Our goal is to minimize the time-average service latencies involved in handling transmission requests from ground users under Poisson arrivals, subject to an average UAV power constraint. Equipped with rate adaptation to efficiently leverage air-to-ground channel stochastics, we first derive the optimal control policy for a single relay via a semi-Markov decision process formulation, with competitive swarm optimization for UAV trajectory design. Accordingly, we detail a multiscale decomposition of this construction: outer decisions on radial wait velocities and end positions optimize the expected long-term delay-power trade-off; consequently, inner decisions on angular wait velocities, service schedules, and UAV trajectories greedily minimize the instantaneous delay-power costs. Next, generalizing to UAV swarms via replication and consensus-driven command-and-control, this policy is embedded with spread maximization and conflict resolution heuristics. We demonstrate that our framework offers superior performance vis-\`a-vis average service latencies and average per-UAV power consumption: 11x faster data payload delivery relative to static UAV-relay deployments and 2x faster than a deep-Q network solution; remarkably, one relay with our scheme outclasses three relays under a joint successive convex approximation policy by 62%.
Intelligent Perception System for Vehicle-Road Cooperation
Aug 30, 2022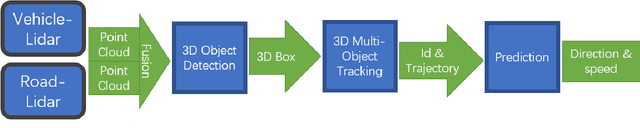

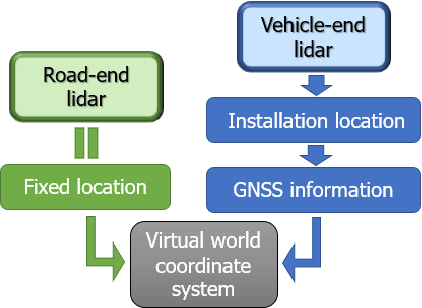

With the development of autonomous driving, the improvement of autonomous driving technology for individual vehicles has reached the bottleneck. The advancement of vehicle-road cooperation autonomous driving technology can expand the vehicle's perception range, supplement the perception blind area and improve the perception accuracy, to promote the development of autonomous driving technology and achieve vehicle-road integration. This project mainly uses lidar to develop data fusion schemes to realize the sharing and combination of vehicle and road equipment data and achieve the detection and tracking of dynamic targets. At the same time, some test scenarios for the vehicle-road cooperative system were designed and used to test our vehicle-road cooperative awareness system, which proved the advantages of vehicle-road cooperative autonomous driving over single-vehicle autonomous driving.
Supervised GAN Watermarking for Intellectual Property Protection
Sep 07, 2022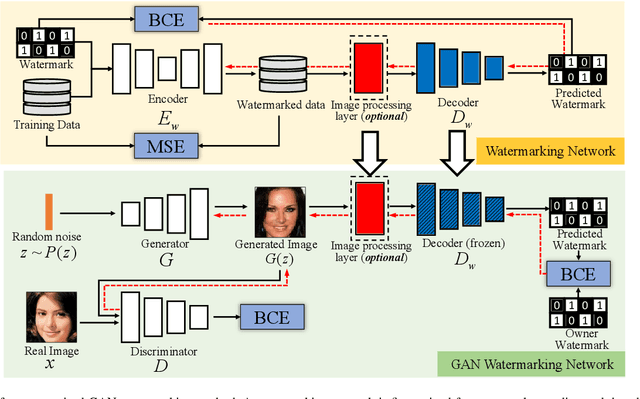

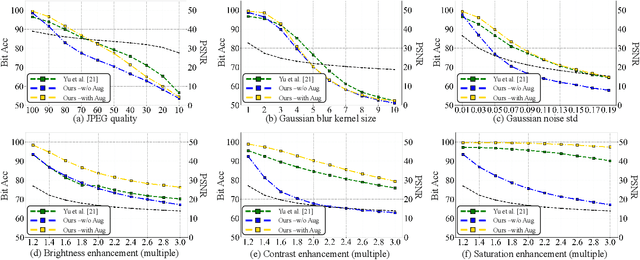

We propose a watermarking method for protecting the Intellectual Property (IP) of Generative Adversarial Networks (GANs). The aim is to watermark the GAN model so that any image generated by the GAN contains an invisible watermark (signature), whose presence inside the image can be checked at a later stage for ownership verification. To achieve this goal, a pre-trained CNN watermarking decoding block is inserted at the output of the generator. The generator loss is then modified by including a watermark loss term, to ensure that the prescribed watermark can be extracted from the generated images. The watermark is embedded via fine-tuning, with reduced time complexity. Results show that our method can effectively embed an invisible watermark inside the generated images. Moreover, our method is a general one and can work with different GAN architectures, different tasks, and different resolutions of the output image. We also demonstrate the good robustness performance of the embedded watermark against several post-processing, among them, JPEG compression, noise addition, blurring, and color transformations.