 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep model with built-in self-attention alignment for acoustic echo cancellation
Aug 24, 2022
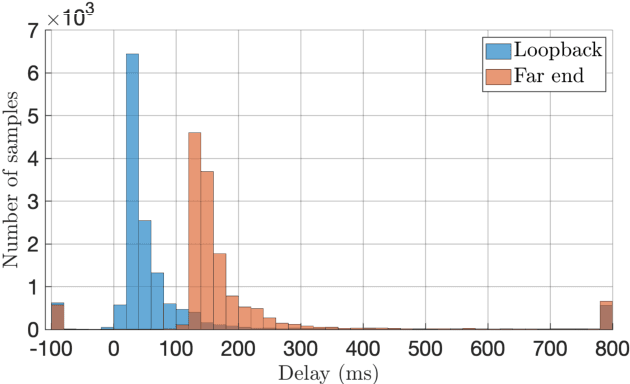

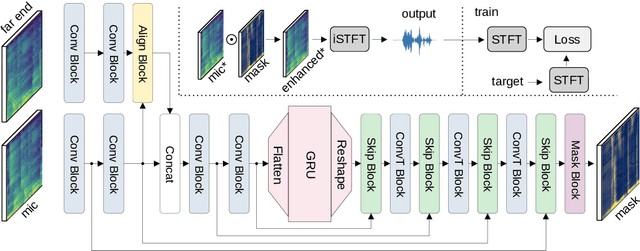
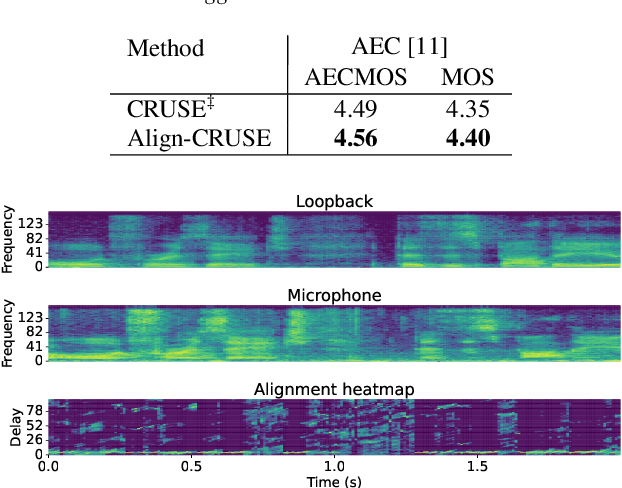
With recent research advances, deep learning models have become an attractive choice for acoustic echo cancellation (AEC) in real-time teleconferencing applications. Since acoustic echo is one of the major sources of poor audio quality, a wide variety of deep models have been proposed. However, an important but often omitted requirement for good echo cancellation quality is the synchronization of the microphone and far end signals. Typically implemented using classical algorithms based on cross-correlation, the alignment module is a separate functional block with known design limitations. In our work we propose a deep learning architecture with built-in self-attention based alignment, which is able to handle unaligned inputs, improving echo cancellation performance while simplifying the communication pipeline. Moreover, we show that our approach achieves significant improvements for difficult delay estimation cases on real recordings from AEC Challenge data set.
Real-time Human Response Prediction Using a Non-intrusive Data-driven Model Reduction Scheme
Oct 26, 2021
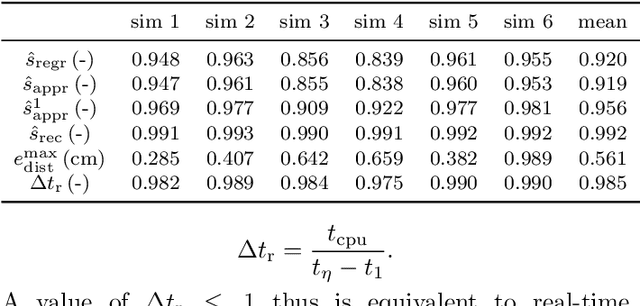
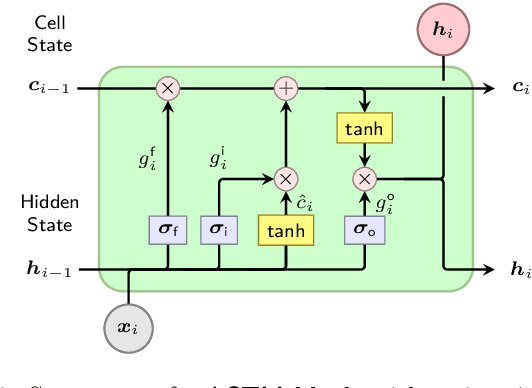
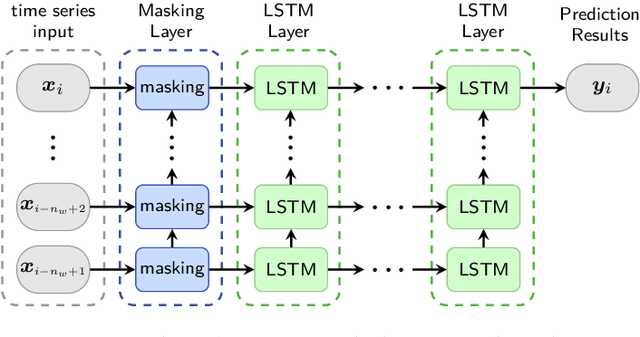
Recent research in non-intrusive data-driven model order reduction (MOR) enabled accurate and efficient approximation of parameterized ordinary differential equations (ODEs). However, previous studies have focused on constant parameters, whereas time-dependent parameters have been neglected. The purpose of this paper is to introduce a novel two-step MOR scheme to tackle this issue. In a first step, classic MOR approaches are applied to calculate a low-dimensional representation of high-dimensional ODE solutions, i.e. to extract the most important features of simulation data. Based on this representation, a long short-term memory (LSTM) is trained to predict the reduced dynamics iteratively in a second step. This enables the parameters to be taken into account during the respective time step. The potential of this approach is demonstrated on an occupant model within a car driving scenario. The reduced model's response to time-varying accelerations matches the reference data with high accuracy for a limited amount of time. Furthermore, real-time capability is achieved. Accordingly, it is concluded that the presented method is well suited to approximate parameterized ODEs and can handle time-dependent parameters in contrast to common methods.
On the Dilution of Precision for Time Difference of Arrival with Station Deployment
Dec 10, 2021
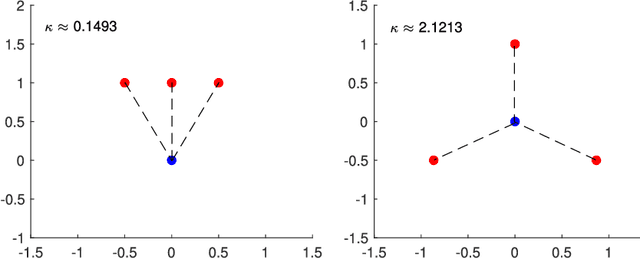
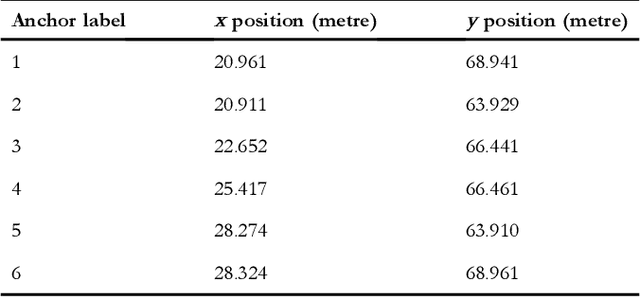

The paper aims to reveal the relationship between the performance of moving object tracking algorithms and the tracking anchors (station) deployment. The Dilution of Precision (DoP) for Time difference of arrival (TDoA) technique with respect to anchor deployment is studied. Linear estimator and non-linear estimator are used for TDoA algorithms. The research findings are: for the linear estimator, the DoP attain a lower value when other anchors are scattered around a central anchor; for the nonlinear estimator, the DoP is optimal when the anchors are scattered around the target tag. Experiments on both of the algorithms are conducted, targeting the location precision related to the anchors' deployment, with practical situations for tracking moving objects integrated with a Kalman Filter (KF) in an Ultra-Wide Band (UWB) based real-time localization system. The work provides a guideline for deploying anchors in UWB-based tracking systems.
Optimized Precoding for MU-MIMO With Fronthaul Quantization
Sep 05, 2022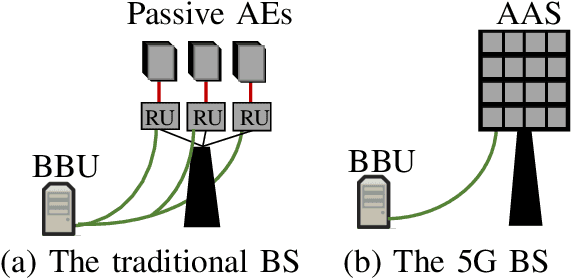
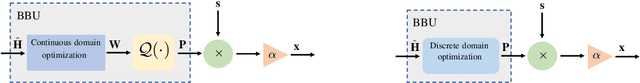
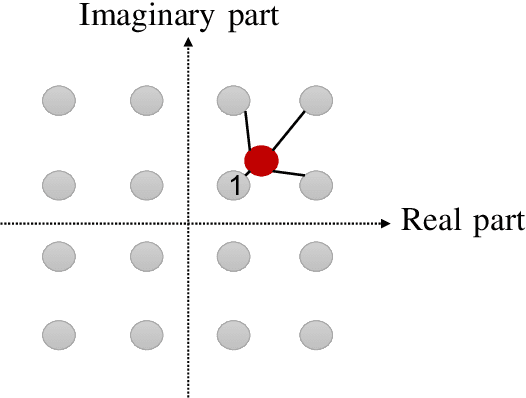
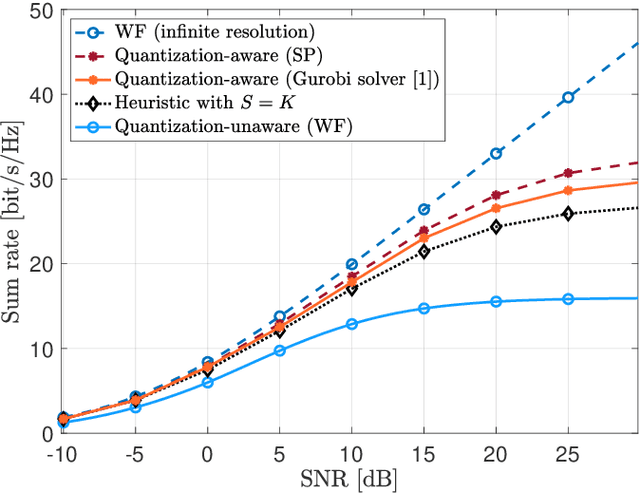
One of the first widespread uses of multi-user multiple-input multiple-output (MU-MIMO) is in 5G networks, where each base station has an advanced antenna system (AAS) that is connected to the baseband unit (BBU) with a capacity-constrained fronthaul. In the AAS configuration, multiple passive antenna elements and radio units are integrated into a single box. This paper considers precoded downlink transmission over a single-cell MU-MIMO system. We study optimized linear precoding for AAS with a limited-capacity fronthaul, which requires the precoding matrix to be quantized. We propose a new precoding design that is aware of the fronthaul quantization and minimizes the mean-squared error at the receiver side. We compute the precoding matrix using a sphere decoding (SD) approach. We also propose a heuristic low-complexity approach to quantized precoding. This heuristic is computationally efficient enough for massive MIMO systems. The numerical results show that our proposed precoding significantly outperforms quantization-unaware precoding and other previous approaches in terms of the sum rate. The performance loss for our heuristic method compared to quantization-aware precoding is insignificant considering the complexity reduction, which makes the heuristic method feasible for real-time applications. We consider both perfect and imperfect channel state information.
Planning under periodic observations: bounds and bounding-based solutions
Aug 05, 2022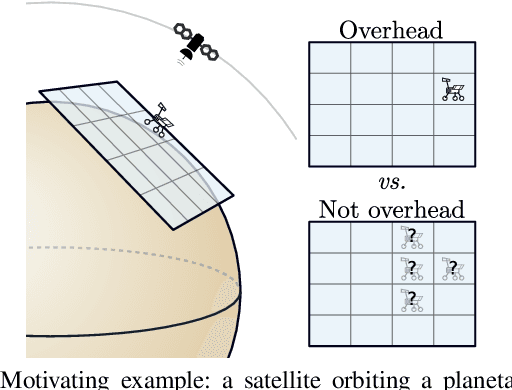
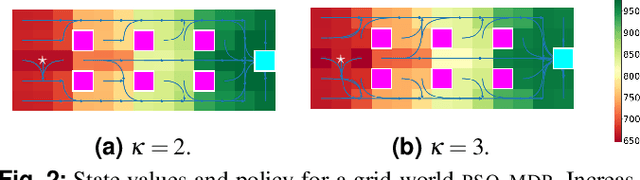
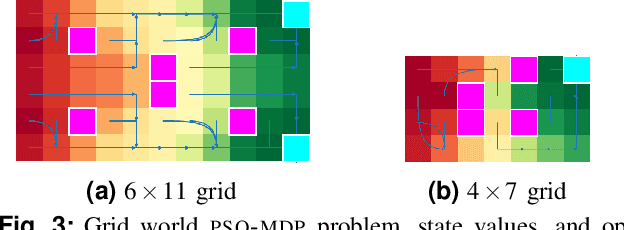
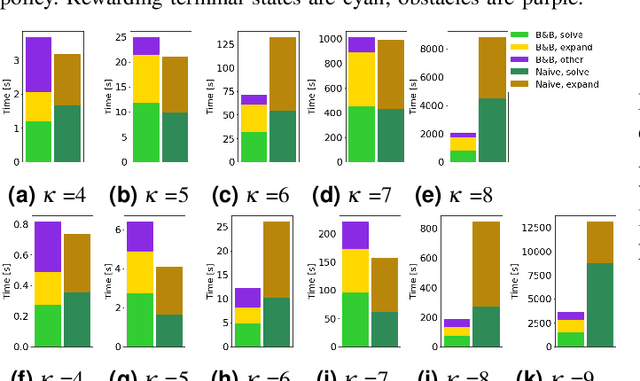
We study planning problems faced by robots operating in uncertain environments with incomplete knowledge of state, and actions that are noisy and/or imprecise. This paper identifies a new problem sub-class that models settings in which information is revealed only intermittently through some exogenous process that provides state information periodically. Several practical domains fit this model, including the specific scenario that motivates our research: autonomous navigation of a planetary exploration rover augmented by remote imaging. With an eye to efficient specialized solution methods, we examine the structure of instances of this sub-class. They lead to Markov Decision Processes with exponentially large action-spaces but for which, as those actions comprise sequences of more atomic elements, one may establish performance bounds by comparing policies under different information assumptions. This provides a way in which to construct performance bounds systematically. Such bounds are useful because, in conjunction with the insights they confer, they can be employed in bounding-based methods to obtain high-quality solutions efficiently; the empirical results we present demonstrate their effectiveness for the considered problems. The foregoing has also alluded to the distinctive role that time plays for these problems -- more specifically: time until information is revealed -- and we uncover and discuss several interesting subtleties in this regard.
AutoPET Challenge: Combining nn-Unet with Swin UNETR Augmented by Maximum Intensity Projection Classifier
Sep 02, 2022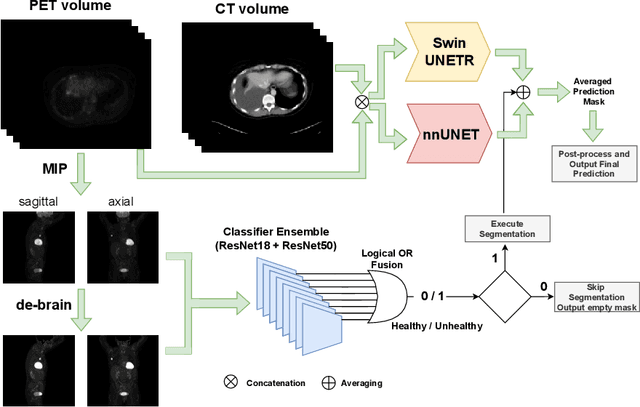
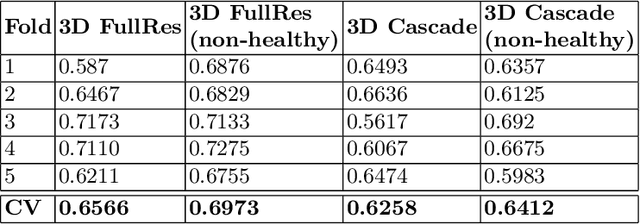
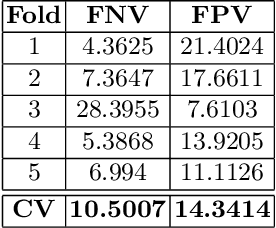
Tumor volume and changes in tumor characteristics over time are important biomarkers for cancer therapy. In this context, FDG-PET/CT scans are routinely used for staging and re-staging of cancer, as the radiolabeled fluorodeoxyglucose is taken up in regions of high metabolism. Unfortunately, these regions with high metabolism are not specific to tumors and can also represent physiological uptake by normal functioning organs, inflammation, or infection, making detailed and reliable tumor segmentation in these scans a demanding task. This gap in research is addressed by the AutoPET challenge, which provides a public data set with FDG-PET/CT scans from 900 patients to encourage further improvement in this field. Our contribution to this challenge is an ensemble of two state-of-the-art segmentation models, the nn-Unet and the Swin UNETR, augmented by a maximum intensity projection classifier that acts like a gating mechanism. If it predicts the existence of lesions, both segmentations are combined by a late fusion approach. Our solution achieves a Dice score of 72.12\% on patients diagnosed with lung cancer, melanoma, and lymphoma in our cross-validation. Code: https://github.com/heiligerl/autopet_submission
Utilizing Excess Resources in Training Neural Networks
Jul 12, 2022


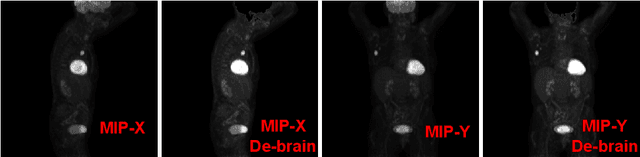
In this work, we suggest Kernel Filtering Linear Overparameterization (KFLO), where a linear cascade of filtering layers is used during training to improve network performance in test time. We implement this cascade in a kernel filtering fashion, which prevents the trained architecture from becoming unnecessarily deeper. This also allows using our approach with almost any network architecture and let combining the filtering layers into a single layer in test time. Thus, our approach does not add computational complexity during inference. We demonstrate the advantage of KFLO on various network models and datasets in supervised learning.
Validation Methods for Energy Time Series Scenarios from Deep Generative Models
Oct 27, 2021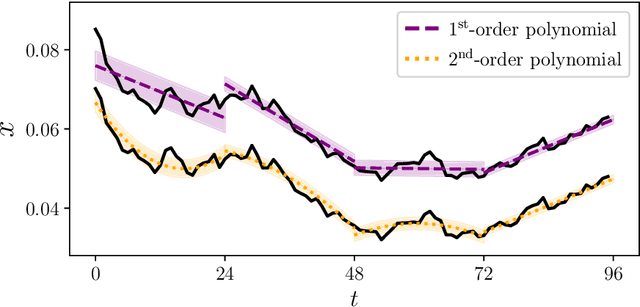
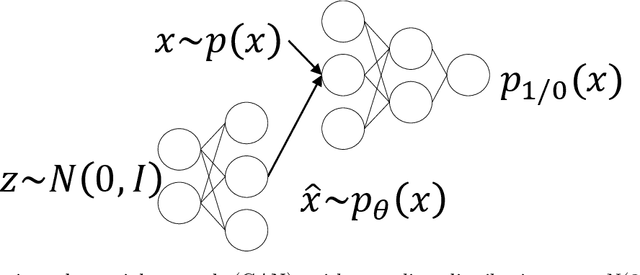
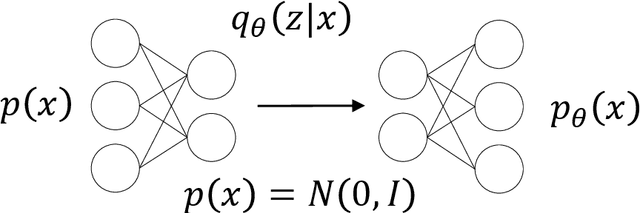
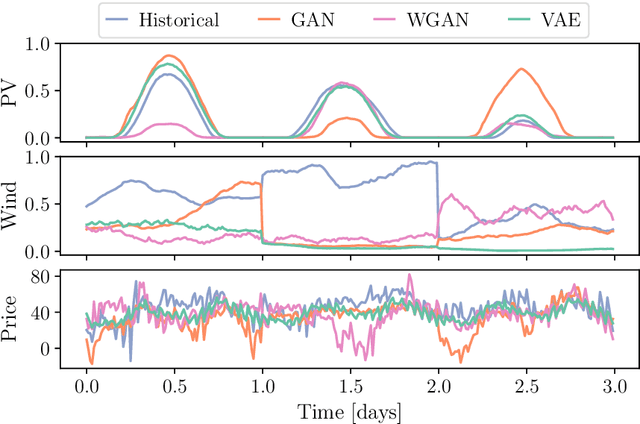
The design and operation of modern energy systems are heavily influenced by time-dependent and uncertain parameters, e.g., renewable electricity generation, load-demand, and electricity prices. These are typically represented by a set of discrete realizations known as scenarios. A popular scenario generation approach uses deep generative models (DGM) that allow scenario generation without prior assumptions about the data distribution. However, the validation of generated scenarios is difficult, and a comprehensive discussion about appropriate validation methods is currently lacking. To start this discussion, we provide a critical assessment of the currently used validation methods in the energy scenario generation literature. In particular, we assess validation methods based on probability density, auto-correlation, and power spectral density. Furthermore, we propose using the multifractal detrended fluctuation analysis (MFDFA) as an additional validation method for non-trivial features like peaks, bursts, and plateaus. As representative examples, we train generative adversarial networks (GANs), Wasserstein GANs (WGANs), and variational autoencoders (VAEs) on two renewable power generation time series (photovoltaic and wind from Germany in 2013 to 2015) and an intra-day electricity price time series form the European Energy Exchange in 2017 to 2019. We apply the four validation methods to both the historical and the generated data and discuss the interpretation of validation results as well as common mistakes, pitfalls, and limitations of the validation methods. Our assessment shows that no single method sufficiently characterizes a scenario but ideally validation should include multiple methods and be interpreted carefully in the context of scenarios over short time periods.
Prediction-based One-shot Dynamic Parking Pricing
Aug 30, 2022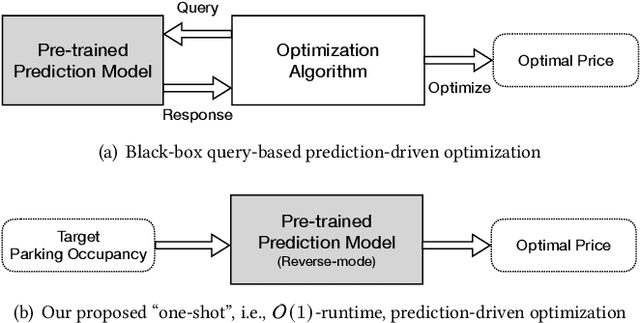
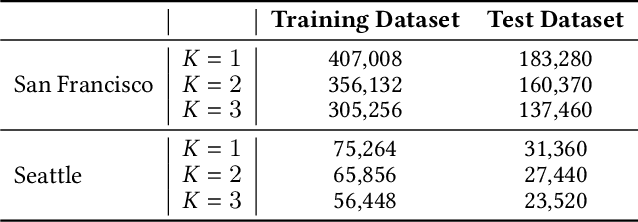
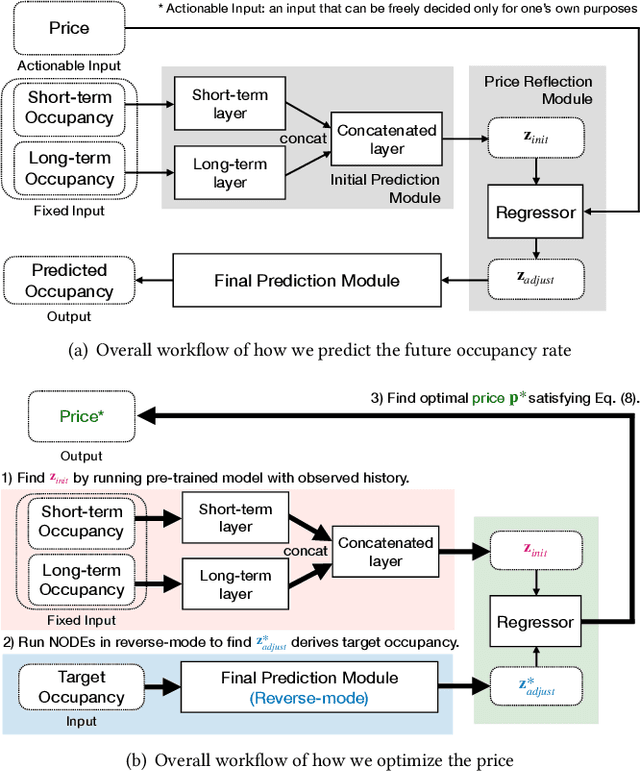
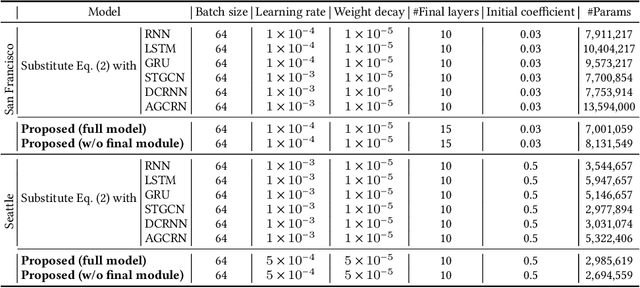
Many U.S. metropolitan cities are notorious for their severe shortage of parking spots. To this end, we present a proactive prediction-driven optimization framework to dynamically adjust parking prices. We use state-of-the-art deep learning technologies such as neural ordinary differential equations (NODEs) to design our future parking occupancy rate prediction model given historical occupancy rates and price information. Owing to the continuous and bijective characteristics of NODEs, in addition, we design a one-shot price optimization method given a pre-trained prediction model, which requires only one iteration to find the optimal solution. In other words, we optimize the price input to the pre-trained prediction model to achieve targeted occupancy rates in the parking blocks. We conduct experiments with the data collected in San Francisco and Seattle for years. Our prediction model shows the best accuracy in comparison with various temporal or spatio-temporal forecasting models. Our one-shot optimization method greatly outperforms other black-box and white-box search methods in terms of the search time and always returns the optimal price solution.
SCULPTOR: Skeleton-Consistent Face Creation Using a Learned Parametric Generator
Sep 14, 2022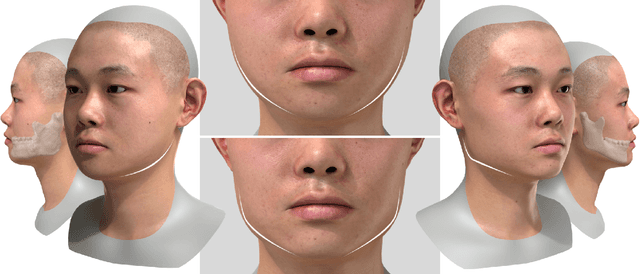
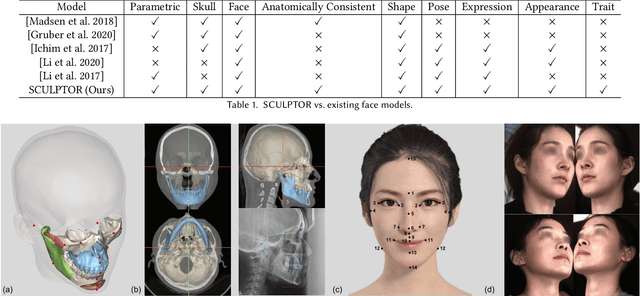
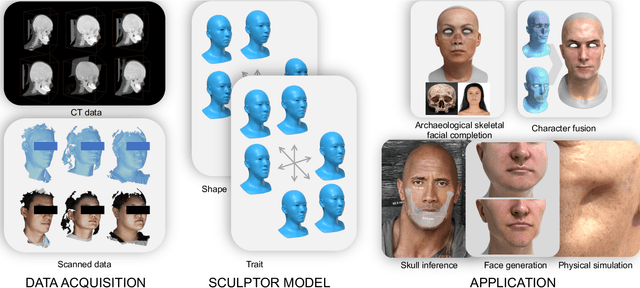
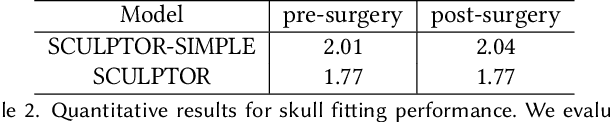
Recent years have seen growing interest in 3D human faces modelling due to its wide applications in digital human, character generation and animation. Existing approaches overwhelmingly emphasized on modeling the exterior shapes, textures and skin properties of faces, ignoring the inherent correlation between inner skeletal structures and appearance. In this paper, we present SCULPTOR, 3D face creations with Skeleton Consistency Using a Learned Parametric facial generaTOR, aiming to facilitate easy creation of both anatomically correct and visually convincing face models via a hybrid parametric-physical representation. At the core of SCULPTOR is LUCY, the first large-scale shape-skeleton face dataset in collaboration with plastic surgeons. Named after the fossils of one of the oldest known human ancestors, our LUCY dataset contains high-quality Computed Tomography (CT) scans of the complete human head before and after orthognathic surgeries, critical for evaluating surgery results. LUCY consists of 144 scans of 72 subjects (31 male and 41 female) where each subject has two CT scans taken pre- and post-orthognathic operations. Based on our LUCY dataset, we learn a novel skeleton consistent parametric facial generator, SCULPTOR, which can create the unique and nuanced facial features that help define a character and at the same time maintain physiological soundness. Our SCULPTOR jointly models the skull, face geometry and face appearance under a unified data-driven framework, by separating the depiction of a 3D face into shape blend shape, pose blend shape and facial expression blend shape. SCULPTOR preserves both anatomic correctness and visual realism in facial generation tasks compared with existing methods. Finally, we showcase the robustness and effectiveness of SCULPTOR in various fancy applications unseen before.