 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting spatial distribution of Palmer Drought Severity Index
Sep 01, 2022
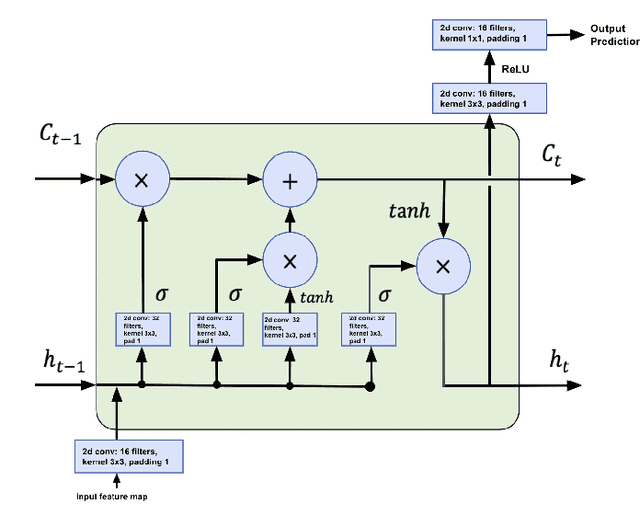
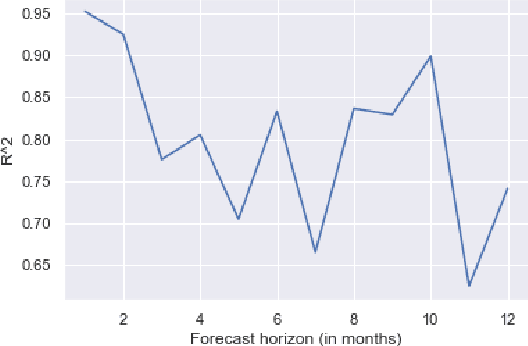
The probability of a drought for a particular region is crucial when making decisions related to agriculture. Forecasting this probability is critical for management and challenging at the same time. The prediction model should consider multiple factors with complex relationships across the region of interest and neighbouring regions. We approach this problem by presenting an end-to-end solution based on a spatio-temporal neural network. The model predicts the Palmer Drought Severity Index (PDSI) for subregions of interest. Predictions by climate models provide an additional source of knowledge of the model leading to more accurate drought predictions. Our model has better accuracy than baseline Gradient boosting solutions, as the $R^2$ score for it is $0.90$ compared to $0.85$ for Gradient boosting. Specific attention is on the range of applicability of the model. We examine various regions across the globe to validate them under different conditions. We complement the results with an analysis of how future climate changes for different scenarios affect the PDSI and how our model can help to make better decisions and more sustainable economics.
Minute ventilation measurement using Plethysmographic Imaging and lighting parameters
Aug 29, 2022
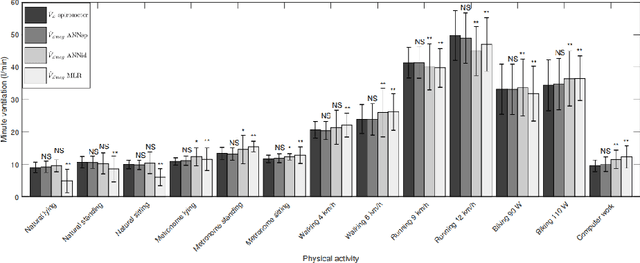
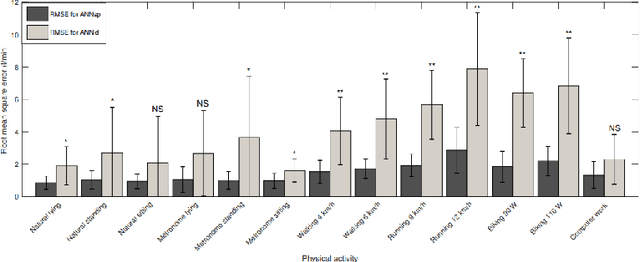
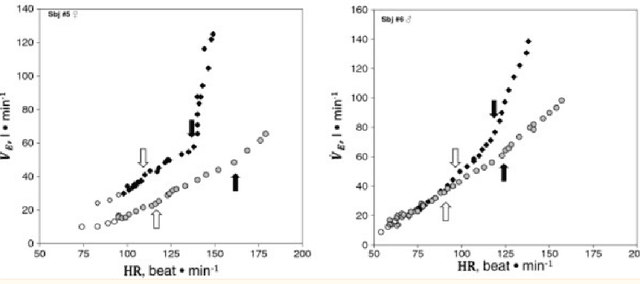
Breathing disorders such as sleep apnea is a critical disorder that affects a large number of individuals due to the insufficient capacity of the lungs to contain/exchange oxygen and carbon dioxide to ensure that the body is in the stable state of homeostasis. Respiratory Measurements such as minute ventilation can be used in correlation with other physiological measurements such as heart rate and heart rate variability for remote monitoring of health and detecting symptoms of such breathing related disorders. In this work, we formulate a deep learning based approach to measure remote ventilation on a private dataset. The dataset will be made public upon acceptance of this work. We use two versions of a deep neural network to estimate the minute ventilation from data streams obtained through wearable heart rate and respiratory devices. We demonstrate that the simple design of our pipeline - which includes lightweight deep neural networks - can be easily incorporate into real time health monitoring systems.
A machine-learning-based tool for last closed magnetic flux surface reconstruction on tokamak
Jul 12, 2022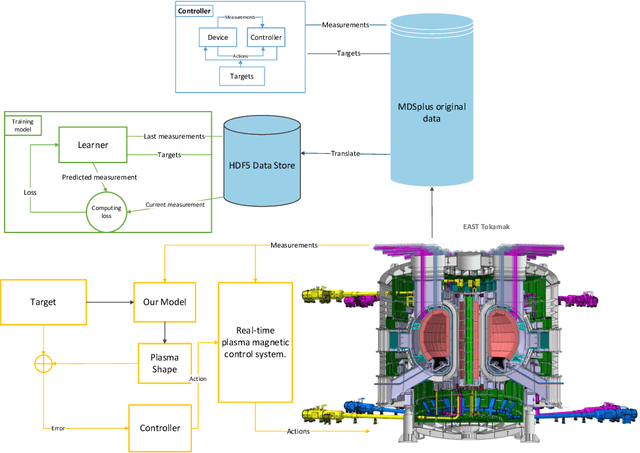

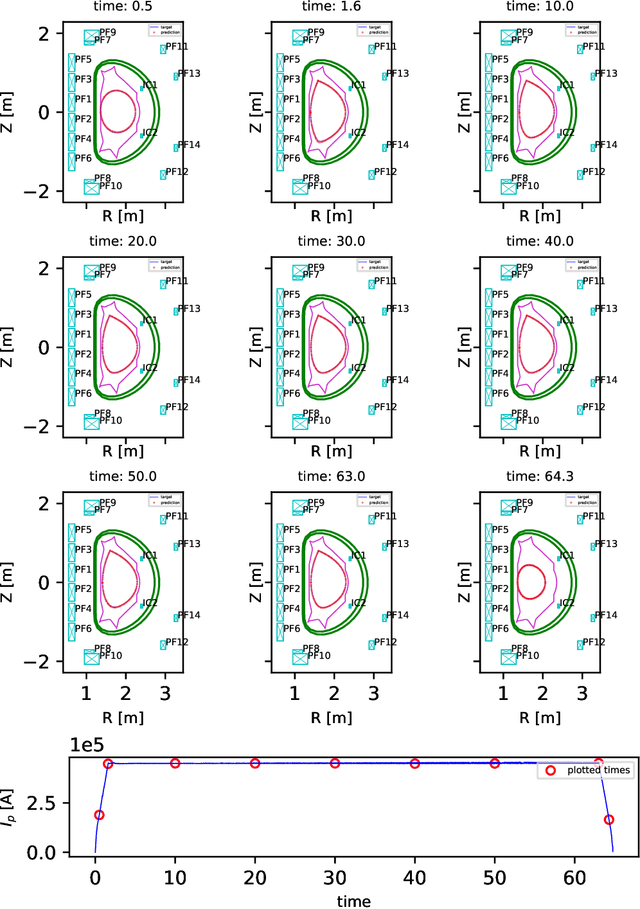
Nuclear fusion power created by tokamak devices holds one of the most promising ways as a sustainable source of clean energy. One main challenge research field of tokamak is to predict the last closed magnetic flux surface (LCFS) determined by the interaction of the actuator coils and the internal tokamak plasma. This work requires high-dimensional, high-frequency, high-fidelity, real-time tools, further complicated by the wide range of actuator coils input interact with internal tokamak plasma states. In this work, we present a new machine learning model for reconstructing the LCFS from the Experimental Advanced Superconducting Tokamak (EAST) that learns automatically from the experimental data of EAST. This architecture can check the control strategy design and integrate it with the tokamak control system for real-time magnetic prediction. In the real-time modeling test, our approach achieves over 99% average similarity in LCFS reconstruction of the entire discharge process. In the offline magnetic reconstruction, our approach reaches over 93% average similarity.
Cooperative Backscatter NOMA with Imperfect SIC: Towards Energy Efficient Sum Rate Maximization in Sustainable 6G Networks
Jul 07, 2022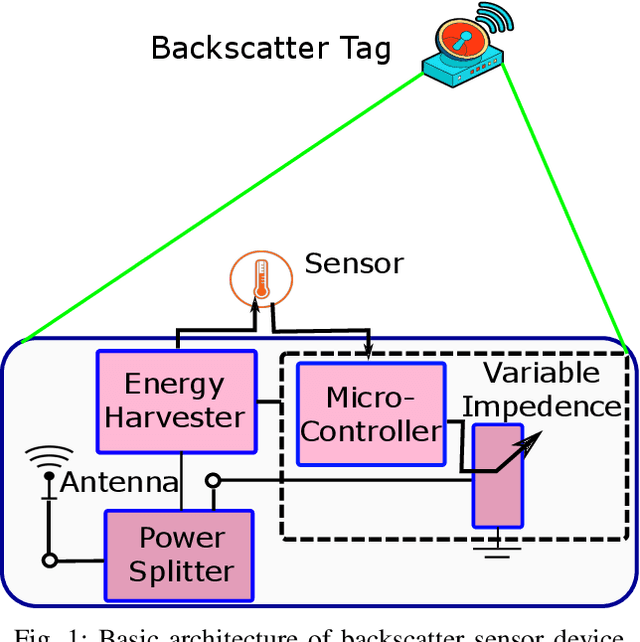
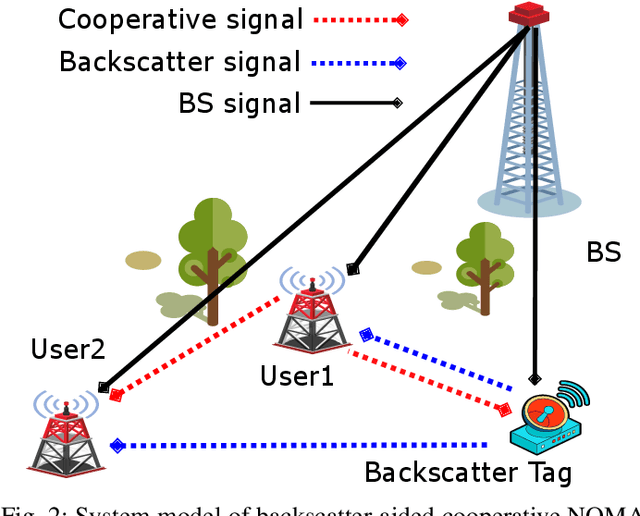
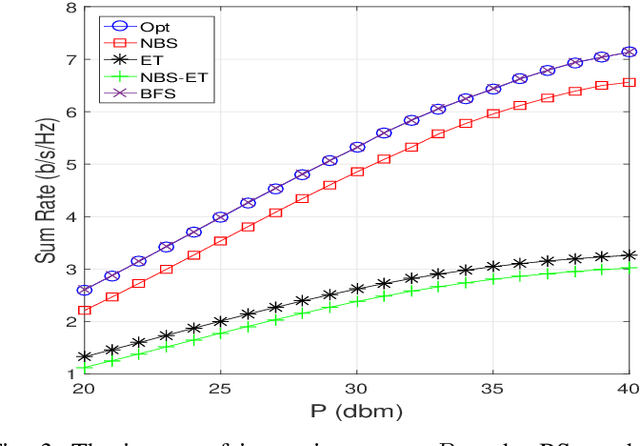
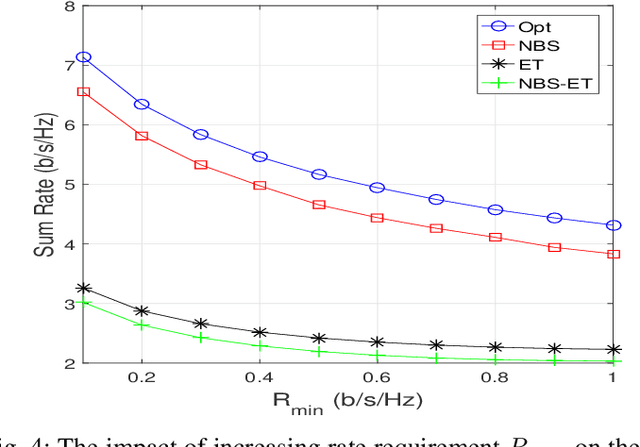
The combination of backscatter communication with non-orthogonal multiple access (NOMA) has the potential to support low-powered massive connections in upcoming sixth-generation (6G) wireless networks. More specifically, backscatter communication can harvest and use the existing RF signals in the atmosphere for communication, while NOMA provides communication to multiple wireless devices over the same frequency and time resources. This paper has proposed a new resource management framework for backscatter-aided cooperative NOMA communication in upcoming 6G networks. In particular, the proposed work has simultaneously optimized the base station's transmit power, relaying node, the reflection coefficient of the backscatter tag, and time allocation under imperfect successive interference cancellation to maximize the sum rate of the system. To obtain an efficient solution for the resource management framework, we have proposed a combination of the bisection method and dual theory, where the sub-gradient method is adopted to optimize the Lagrangian multipliers. Numerical results have shown that the proposed solution provides excellent performance. When the performance of the proposed technique is compared to a brute-forcing search technique that guarantees optimal solution however, is very time-consuming, it was seen that the gap in performance is actually 0\%. Hence, the proposed framework has provided performance equal to a cumbersome brute-force search technique while offering much less complexity. The works in the literature on cooperative NOMA considered equal time distribution for cooperation and direct communication. Our results showed that optimizing the time-division can increase the performance by more than 110\% for high transmission powers.
HistoPerm: A Permutation-Based View Generation Approach for Learning Histopathologic Feature Representations
Sep 13, 2022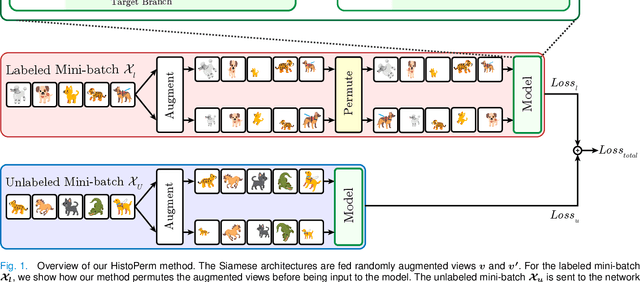
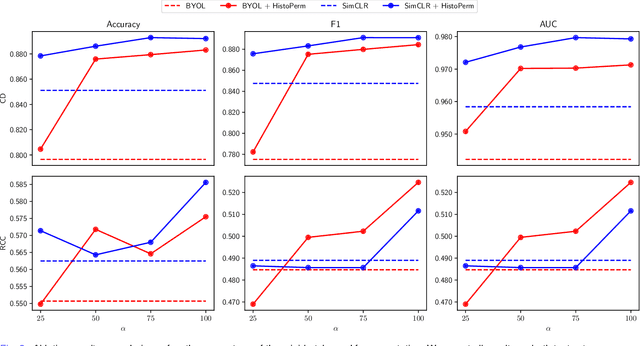
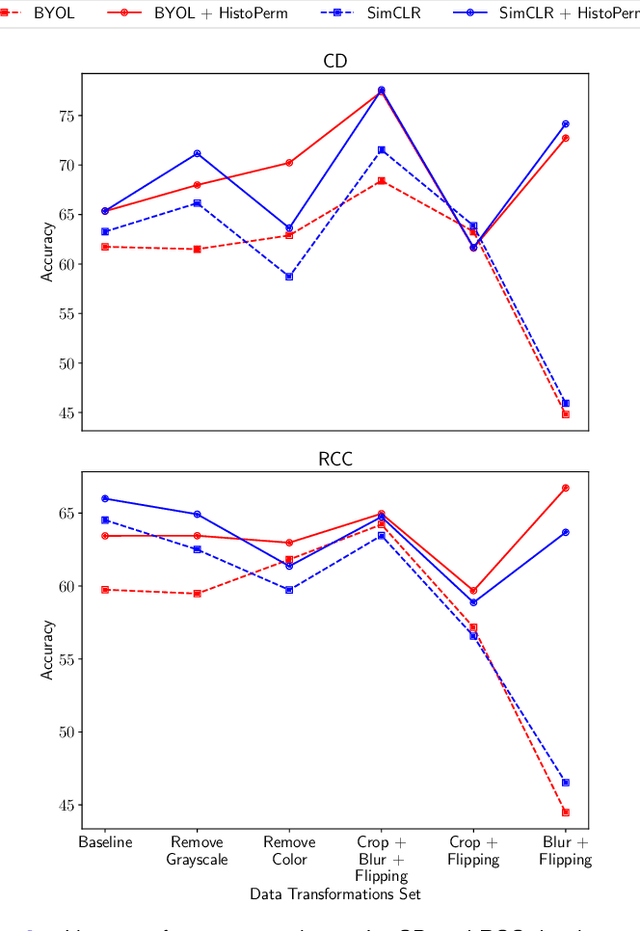
Recently, deep learning methods have been successfully applied to solve numerous challenges in the field of digital pathology. However, many of these approaches are fully supervised and require annotated images. Annotating a histology image is a time-consuming and tedious process for even a highly skilled pathologist, and, as such, most histology datasets lack region-of-interest annotations and are weakly labeled. In this paper, we introduce HistoPerm, a view generation approach designed for improving the performance of representation learning techniques on histology images in weakly supervised settings. In HistoPerm, we permute augmented views of patches generated from whole-slide histology images to improve classification accuracy. These permuted views belong to the same original slide-level class but are produced from distinct patch instances. We tested adding HistoPerm to BYOL and SimCLR, two prominent representation learning methods, on two public histology datasets for Celiac disease and Renal Cell Carcinoma. For both datasets, we found improved performance in terms of accuracy, F1-score, and AUC compared to the standard BYOL and SimCLR approaches. Particularly, in a linear evaluation configuration, HistoPerm increases classification accuracy on the Celiac disease dataset by 8% for BYOL and 3% for SimCLR. Similarly, with HistoPerm, classification accuracy increases by 2% for BYOL and 0.25% for SimCLR on the Renal Cell Carcinoma dataset. The proposed permutation-based view generation approach can be adopted in common representation learning frameworks to capture histopathology features in weakly supervised settings and can lead to whole-slide classification outcomes that are close to, or even better than, fully supervised methods.
A Linear and Exact Algorithm for Whole-Body Collision Evaluation via Scale Optimization
Aug 12, 2022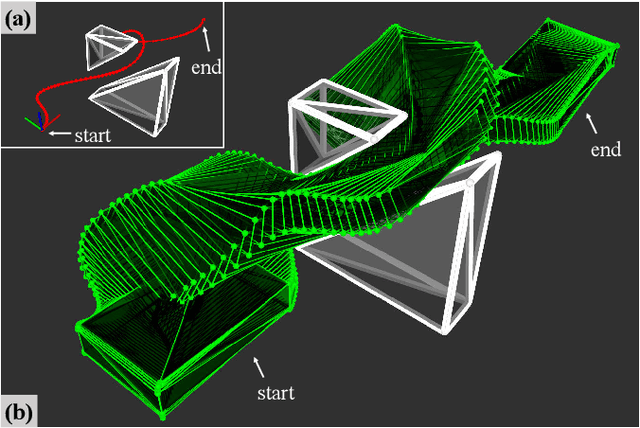
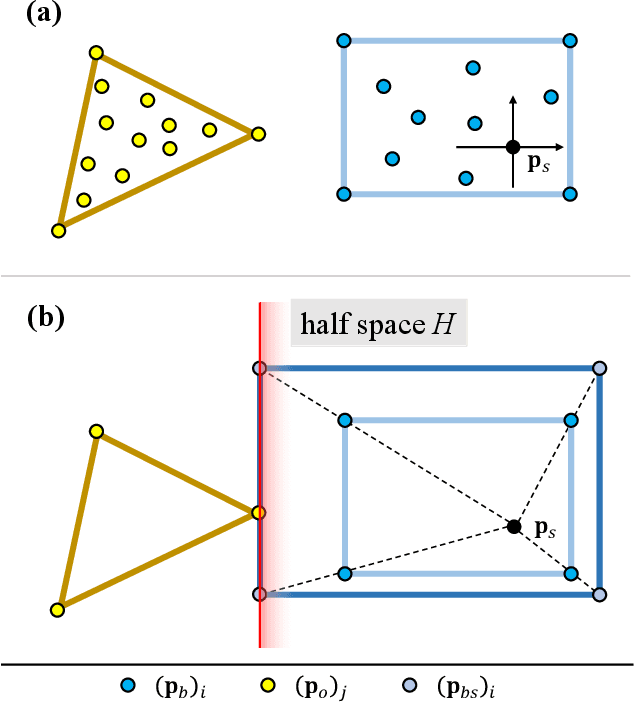
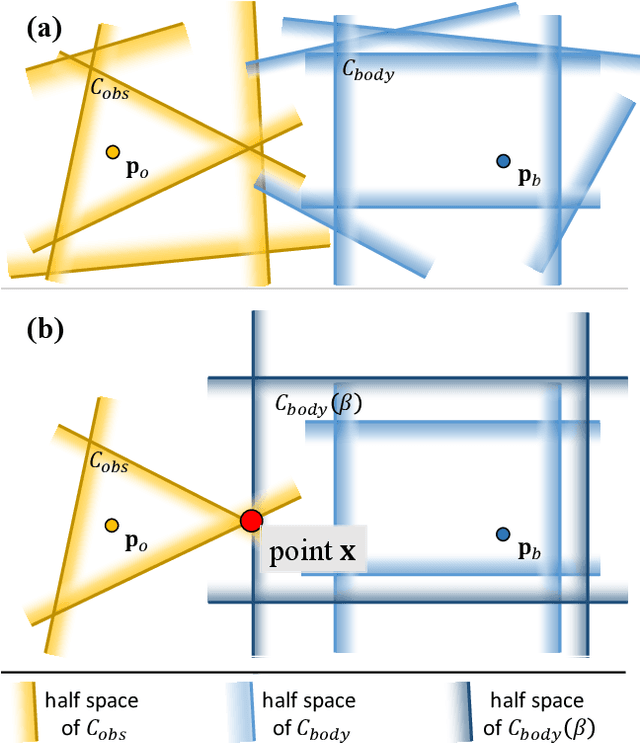
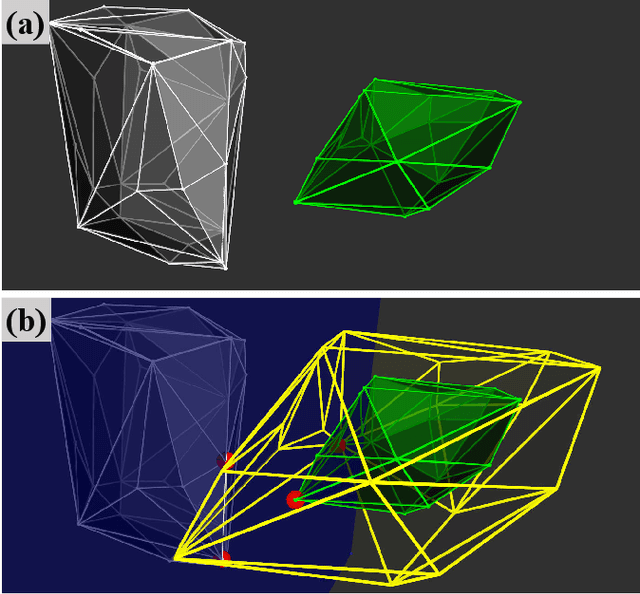
Collision evaluation is of vital importance in various applications. However, existing methods are either cumbersome to calculate or have a gap with the actual value. In this paper, we propose a zero-gap whole-body collision evaluation which can be formulated as a low dimensional linear program. This evaluation can be solved analytically in O(m) computational time, where m is the total number of the linear inequalities in this linear program. Moreover, the proposed method is efficient in obtaining its gradient, making it easy to apply to optimization-based applications.
Graph-PHPA: Graph-based Proactive Horizontal Pod Autoscaling for Microservices using LSTM-GNN
Sep 06, 2022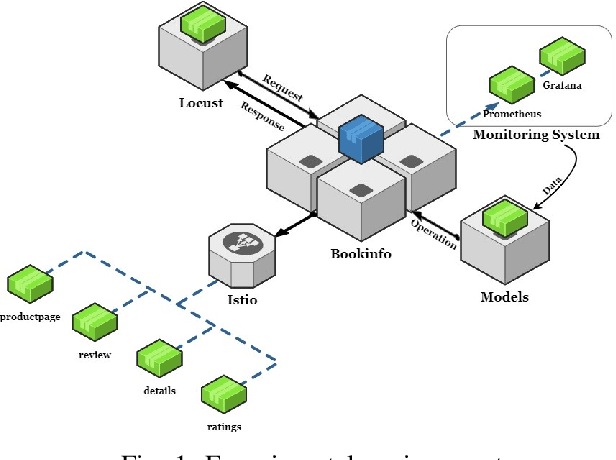
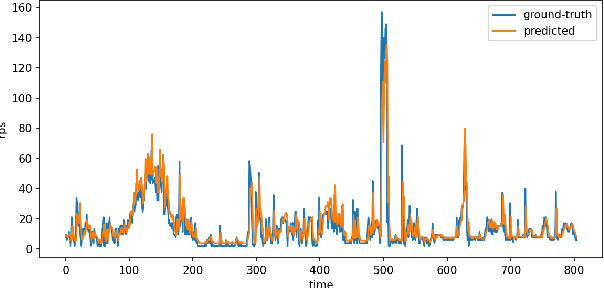
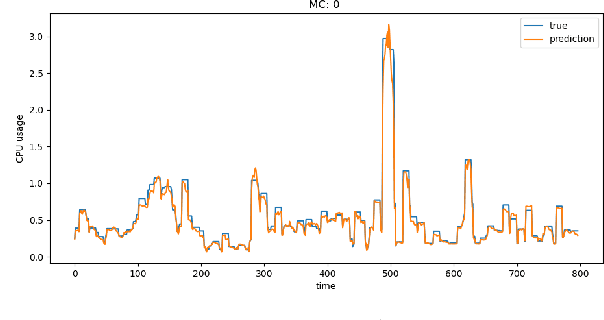
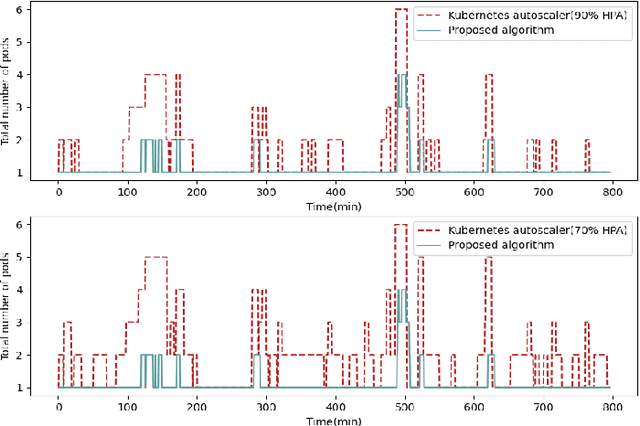
Microservice-based architecture has become prevalent for cloud-native applications. With an increasing number of applications being deployed on cloud platforms every day leveraging this architecture, more research efforts are required to understand how different strategies can be applied to effectively manage various cloud resources at scale. A large body of research has deployed automatic resource allocation algorithms using reactive and proactive autoscaling policies. However, there is still a gap in the efficiency of current algorithms in capturing the important features of microservices from their architecture and deployment environment, for example, lack of consideration of graphical dependency. To address this challenge, we propose Graph-PHPA, a graph-based proactive horizontal pod autoscaling strategy for allocating cloud resources to microservices leveraging long short-term memory (LSTM) and graph neural network (GNN) based prediction methods. We evaluate the performance of Graph-PHPA using the Bookinfo microservices deployed in a dedicated testing environment with real-time workloads generated based on realistic datasets. We demonstrate the efficacy of Graph-PHPA by comparing it with the rule-based resource allocation scheme in Kubernetes as our baseline. Extensive experiments have been implemented and our results illustrate the superiority of our proposed approach in resource savings over the reactive rule-based baseline algorithm in different testing scenarios.
Bayesian Inference with Latent Hamiltonian Neural Networks
Aug 12, 2022
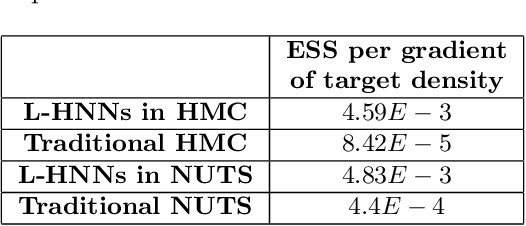

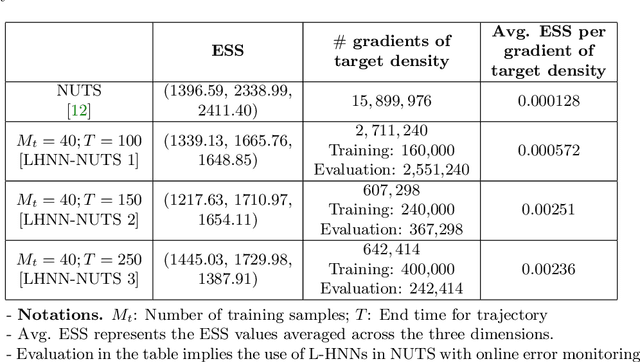
When sampling for Bayesian inference, one popular approach is to use Hamiltonian Monte Carlo (HMC) and specifically the No-U-Turn Sampler (NUTS) which automatically decides the end time of the Hamiltonian trajectory. However, HMC and NUTS can require numerous numerical gradients of the target density, and can prove slow in practice. We propose Hamiltonian neural networks (HNNs) with HMC and NUTS for solving Bayesian inference problems. Once trained, HNNs do not require numerical gradients of the target density during sampling. Moreover, they satisfy important properties such as perfect time reversibility and Hamiltonian conservation, making them well-suited for use within HMC and NUTS because stationarity can be shown. We also propose an HNN extension called latent HNNs (L-HNNs), which are capable of predicting latent variable outputs. Compared to HNNs, L-HNNs offer improved expressivity and reduced integration errors. Finally, we employ L-HNNs in NUTS with an online error monitoring scheme to prevent sample degeneracy in regions of low probability density. We demonstrate L-HNNs in NUTS with online error monitoring on several examples involving complex, heavy-tailed, and high-local-curvature probability densities. Overall, L-HNNs in NUTS with online error monitoring satisfactorily inferred these probability densities. Compared to traditional NUTS, L-HNNs in NUTS with online error monitoring required 1--2 orders of magnitude fewer numerical gradients of the target density and improved the effective sample size (ESS) per gradient by an order of magnitude.
EMVLight: a Multi-agent Reinforcement Learning Framework for an Emergency Vehicle Decentralized Routing and Traffic Signal Control System
Jun 29, 2022

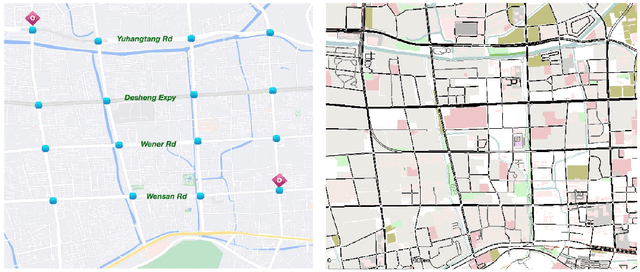
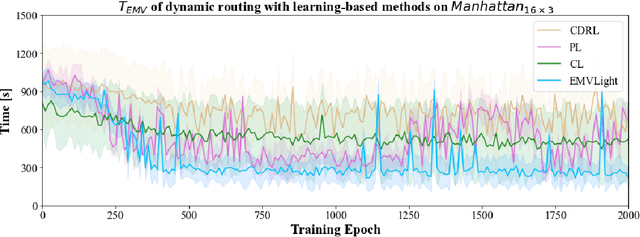
Emergency vehicles (EMVs) play a crucial role in responding to time-critical calls such as medical emergencies and fire outbreaks in urban areas. Existing methods for EMV dispatch typically optimize routes based on historical traffic-flow data and design traffic signal pre-emption accordingly; however, we still lack a systematic methodology to address the coupling between EMV routing and traffic signal control. In this paper, we propose EMVLight, a decentralized reinforcement learning (RL) framework for joint dynamic EMV routing and traffic signal pre-emption. We adopt the multi-agent advantage actor-critic method with policy sharing and spatial discounted factor. This framework addresses the coupling between EMV navigation and traffic signal control via an innovative design of multi-class RL agents and a novel pressure-based reward function. The proposed methodology enables EMVLight to learn network-level cooperative traffic signal phasing strategies that not only reduce EMV travel time but also shortens the travel time of non-EMVs. Simulation-based experiments indicate that EMVLight enables up to a $42.6\%$ reduction in EMV travel time as well as an $23.5\%$ shorter average travel time compared with existing approaches.
A Deep Generative Approach to Oversampling in Ptychography
Jul 28, 2022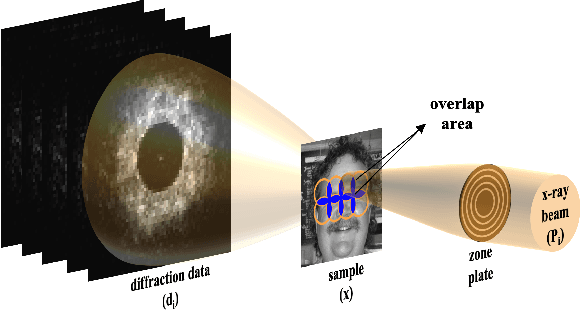


Ptychography is a well-studied phase imaging method that makes non-invasive imaging possible at a nanometer scale. It has developed into a mainstream technique with various applications across a range of areas such as material science or the defense industry. One major drawback of ptychography is the long data acquisition time due to the high overlap requirement between adjacent illumination areas to achieve a reasonable reconstruction. Traditional approaches with reduced overlap between scanning areas result in reconstructions with artifacts. In this paper, we propose complementing sparsely acquired or undersampled data with data sampled from a deep generative network to satisfy the oversampling requirement in ptychography. Because the deep generative network is pre-trained and its output can be computed as we collect data, the experimental data and the time to acquire the data can be reduced. We validate the method by presenting the reconstruction quality compared to the previously proposed and traditional approaches and comment on the strengths and drawbacks of the proposed approach.