 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CrackSeg9k: A Collection and Benchmark for Crack Segmentation Datasets and Frameworks
Aug 27, 2022

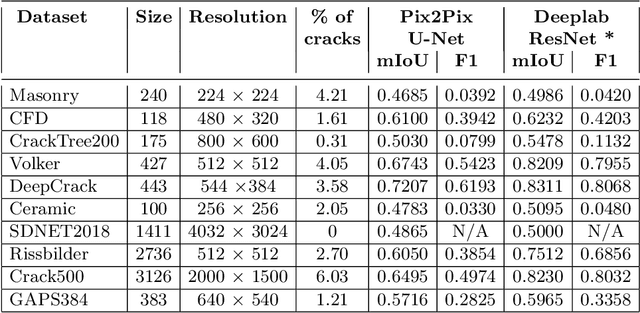

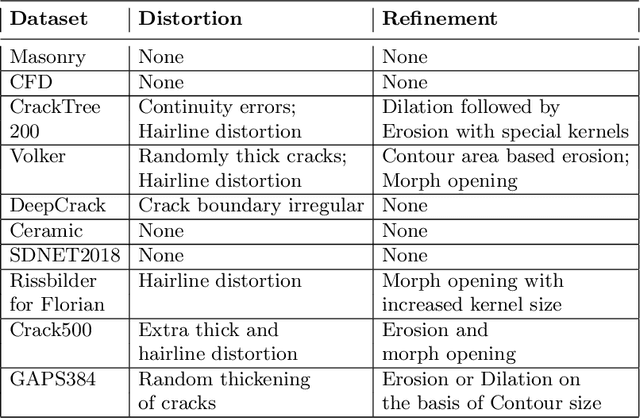
The detection of cracks is a crucial task in monitoring structural health and ensuring structural safety. The manual process of crack detection is time-consuming and subjective to the inspectors. Several researchers have tried tackling this problem using traditional Image Processing or learning-based techniques. However, their scope of work is limited to detecting cracks on a single type of surface (walls, pavements, glass, etc.). The metrics used to evaluate these methods are also varied across the literature, making it challenging to compare techniques. This paper addresses these problems by combining previously available datasets and unifying the annotations by tackling the inherent problems within each dataset, such as noise and distortions. We also present a pipeline that combines Image Processing and Deep Learning models. Finally, we benchmark the results of proposed models on these metrics on our new dataset and compare them with state-of-the-art models in the literature.
Highly precise AMCW time-of-flight scanning sensor based on digital-parallel demodulation
Dec 16, 2021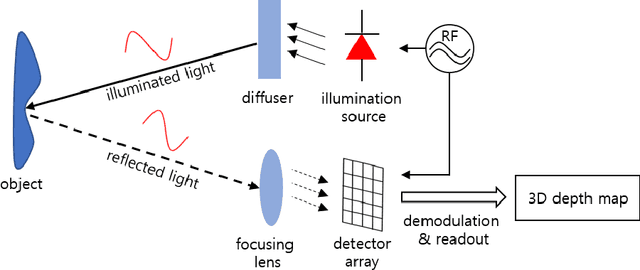
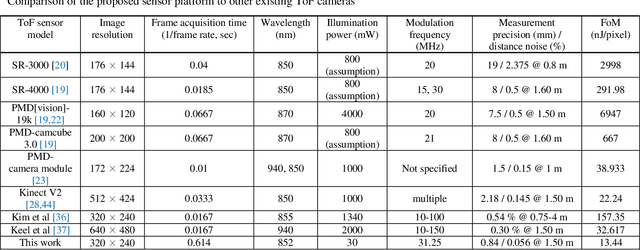
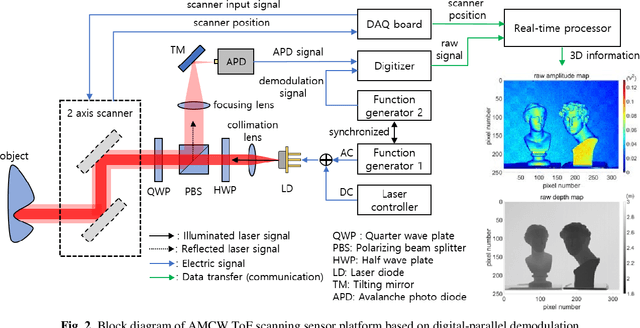
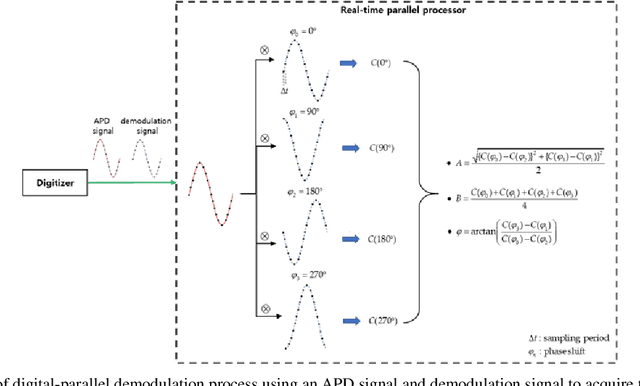
In this paper, a novel amplitude-modulated continuous wave (AMCW) time-of-flight (ToF) scanning sensor based on digital-parallel demodulation is proposed and demonstrated in the aspect of distance measurement precision. Since digital-parallel demodulation utilizes a high-amplitude demodulation signal with zero-offset, the proposed sensor platform can maintain extremely high demodulation contrast. Meanwhile, as all cross correlated samples are calculated in parallel and in extremely short integration time, the proposed sensor platform can utilize a 2D laser scanning structure with a single photo detector, maintaining a moderate frame rate. This optical structure can increase the received optical SNR and remove the crosstalk of image pixel array. Based on these measurement properties, the proposed AMCW ToF scanning sensor shows highly precise 3D depth measurement performance. In this study, this precise measurement performance is explained in detail. Additionally, the actual measurement performance of the proposed sensor platform is experimentally validated under various conditions.
Responsible AI Pattern Catalogue: a Multivocal Literature Review
Sep 12, 2022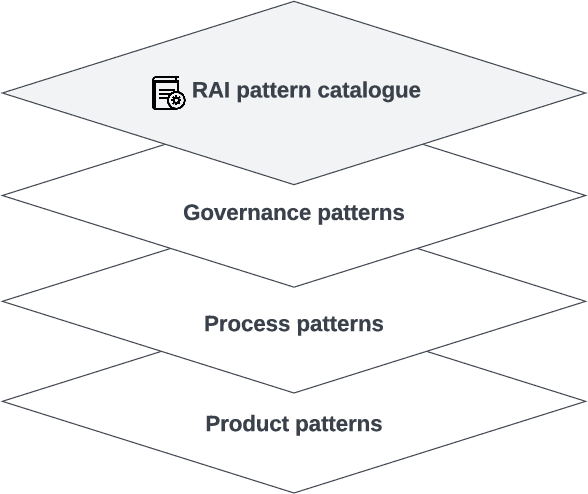

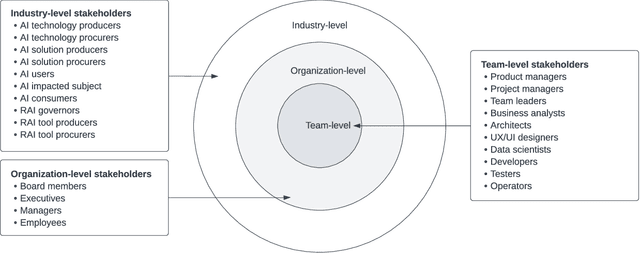
Responsible AI has been widely considered as one of the greatest scientific challenges of our time and the key to unlock the AI market and increase the adoption. To address the responsible AI challenge, a number of AI ethics principles frameworks have been published recently, which AI systems are supposed to conform to. However, without further best practice guidance, practitioners are left with nothing much beyond truisms. Also, significant efforts have been placed at algorithm-level rather than system-level, mainly focusing on a subset of mathematics-amenable ethical principles (such as privacy and fairness). Nevertheless, ethical issues can occur at any step of the development lifecycle crosscutting many AI, non-AI and data components of systems beyond AI algorithms and models. To operationalize responsible AI from a system perspective, in this paper, we adopt a pattern-oriented approach and present a Responsible AI Pattern Catalogue based on the results of a systematic Multivocal Literature Review (MLR). Rather than staying at the ethical principle level or algorithm level, we focus on patterns that AI system stakeholders can undertake in practice to ensure that the developed AI systems are responsible throughout the entire governance and engineering lifecycle. The Responsible AI Pattern Catalogue classifies patterns into three groups: multi-level governance patterns, trustworthy process patterns, and responsible-AI-by-design product patterns. These patterns provide a systematic and actionable guidance for stakeholders to implement responsible AI.
Back to the Manifold: Recovering from Out-of-Distribution States
Jul 18, 2022
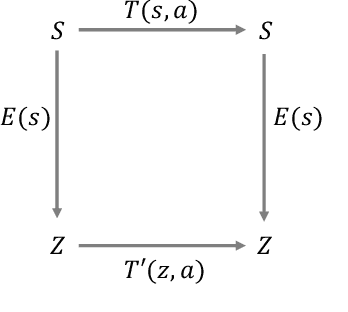
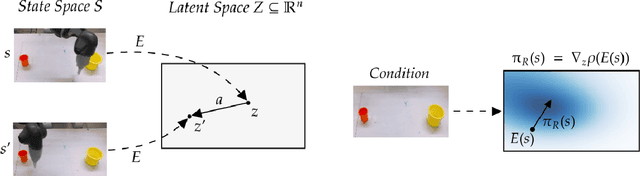

Learning from previously collected datasets of expert data offers the promise of acquiring robotic policies without unsafe and costly online explorations. However, a major challenge is a distributional shift between the states in the training dataset and the ones visited by the learned policy at the test time. While prior works mainly studied the distribution shift caused by the policy during the offline training, the problem of recovering from out-of-distribution states at the deployment time is not very well studied yet. We alleviate the distributional shift at the deployment time by introducing a recovery policy that brings the agent back to the training manifold whenever it steps out of the in-distribution states, e.g., due to an external perturbation. The recovery policy relies on an approximation of the training data density and a learned equivariant mapping that maps visual observations into a latent space in which translations correspond to the robot actions. We demonstrate the effectiveness of the proposed method through several manipulation experiments on a real robotic platform. Our results show that the recovery policy enables the agent to complete tasks while the behavioral cloning alone fails because of the distributional shift problem.
Free-Space Optical Communications for 6G-enabled Long-Range Wireless Networks: Challenges, Opportunities, and Prototype Validation
Sep 16, 2022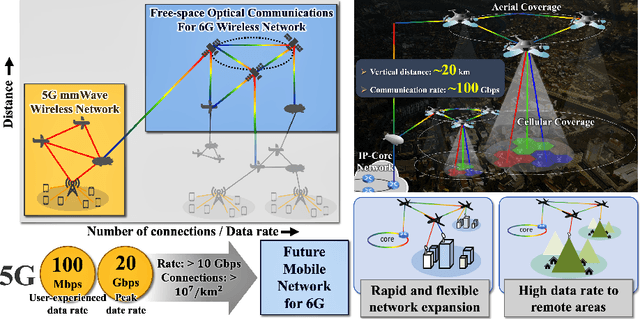
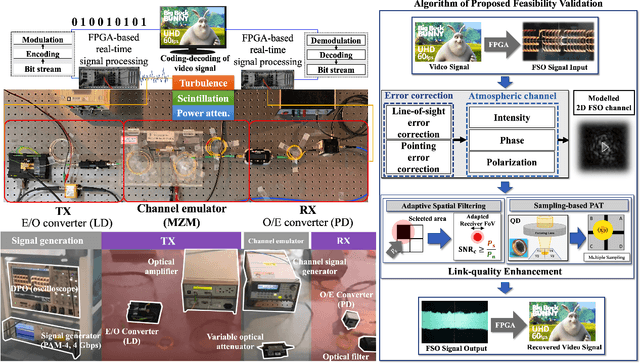
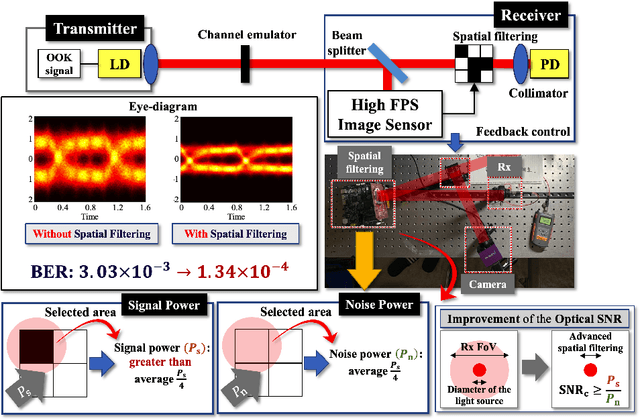
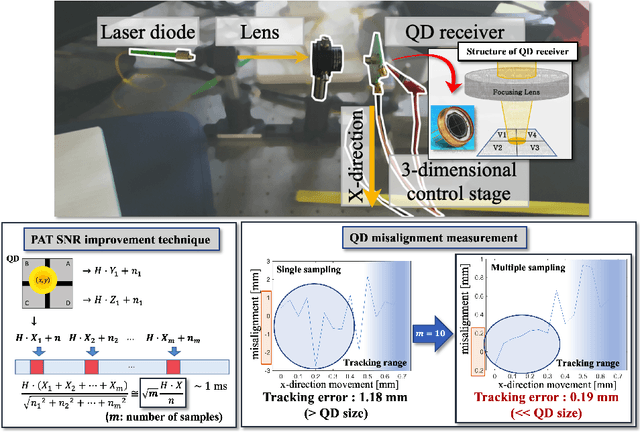
Numerous researchers have studied innovations in future sixth-generation (6G) wireless communications. Indeed, a critical issue that has emerged is to contend with society's insatiable demand for high data rates and massive 6G connectivity. Some scholars consider one innovation to be a breakthrough--the application of free-space optical (FSO) communication. Owing to its exceedingly high carrier frequency/bandwidth and the potential of the unlicensed spectrum domain, FSO communication provides an excellent opportunity to develop ultrafast data links that can be applied in a variety of 6G applications, including heterogeneous networks with enormous connectivity and wireless backhauls for cellular systems. In this study, we perform video signal transmissions via an FPGA-based FSO communication prototype to investigate the feasibility of an FSO link with a distance of up to 20~km. We use a channel emulator to reliably model turbulence, scintillation, and power attenuation of the long-range FSO channel. We use the FPGA-based real-time SDR prototype to process the transmitted and received video signals. Our study also presents the channel-generation process of a given long-distance FSO link. To enhance the link quality, we apply spatial selective filtering to suppress the background noise generated by sunlight. To measure the misalignment of the transceiver, we use sampling-based pointing, acquisition, and tracking to compensate for it by improving the signal-to-noise ratio. For the main video signal transmission testbed, we consider various environments by changing the amount of turbulence and wind speed. We demonstrate that the testbed even permits the successful transmission of ultra-high-definition (UHD: 3840 x 2160 resolution) 60 fps videos under severe turbulence and high wind speeds.
Toward Data-Driven Radar STAP
Sep 07, 2022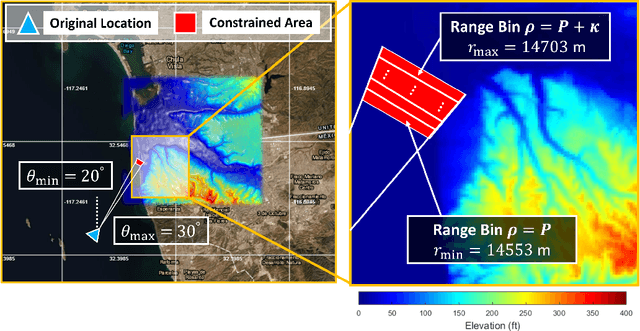
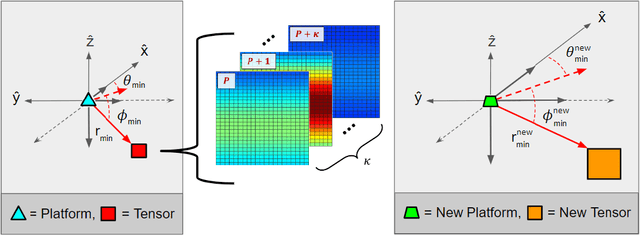
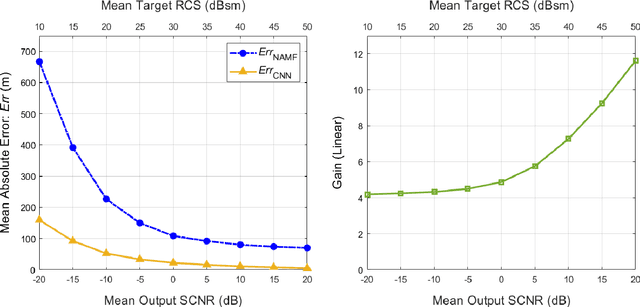
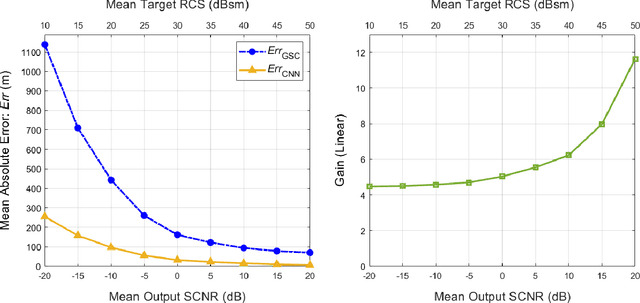
Catalyzed by the recent emergence of site-specific, high-fidelity radio frequency (RF) modeling and simulation tools purposed for radar, data-driven formulations of classical methods in radar have rapidly grown in popularity over the past decade. Despite this surge, limited focus has been directed toward the theoretical foundations of these classical methods. In this regard, as part of our ongoing data-driven approach to radar space-time adaptive processing (STAP), we analyze the asymptotic performance guarantees of select subspace separation methods in the context of radar target localization, and augment this analysis through a proposed deep learning framework for target location estimation. In our approach, we generate comprehensive datasets by randomly placing targets of variable strengths in predetermined constrained areas using RFView, a site-specific RF modeling and simulation tool developed by ISL Inc. For each radar return signal from these constrained areas, we generate heatmap tensors in range, azimuth, and elevation of the normalized adaptive matched filter (NAMF) test statistic, and of the output power of a generalized sidelobe canceller (GSC). Using our deep learning framework, we estimate target locations from these heatmap tensors to demonstrate the feasibility of and significant improvements provided by our data-driven approach in matched and mismatched settings.
Towards Confidence-guided Shape Completion for Robotic Applications
Sep 09, 2022
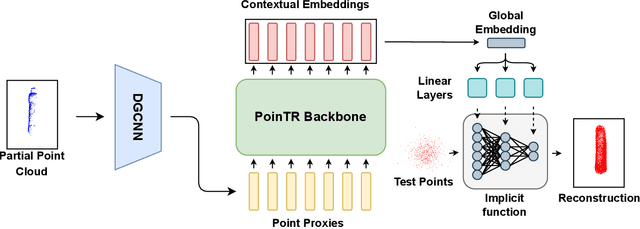


Many robotic tasks involving some form of 3D visual perception greatly benefit from a complete knowledge of the working environment. However, robots often have to tackle unstructured environments and their onboard visual sensors can only provide incomplete information due to limited workspaces, clutter or object self-occlusion. In recent years, deep learning architectures for shape completion have begun taking traction as effective means of inferring a complete 3D object representation from partial visual data. Nevertheless, most of the existing state-of-the-art approaches provide a fixed output resolution in the form of voxel grids, strictly related to the size of the neural network output stage. While this is enough for some tasks, e.g. obstacle avoidance in navigation, grasping and manipulation require finer resolutions and simply scaling up the neural network outputs is computationally expensive. In this paper, we address this limitation by proposing an object shape completion method based on an implicit 3D representation providing a confidence value for each reconstructed point. As a second contribution, we propose a gradient-based method for efficiently sampling such implicit function at an arbitrary resolution, tunable at inference time. We experimentally validate our approach by comparing reconstructed shapes with ground truths, and by deploying our shape completion algorithm in a robotic grasping pipeline. In both cases, we compare results with a state-of-the-art shape completion approach.
Object Goal Navigation using Data Regularized Q-Learning
Aug 27, 2022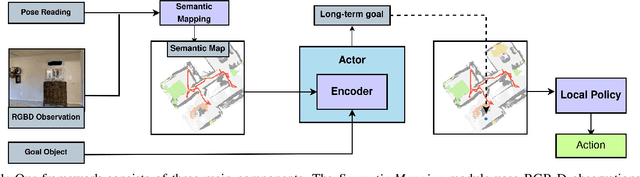
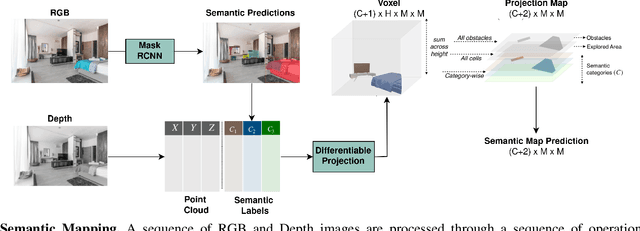
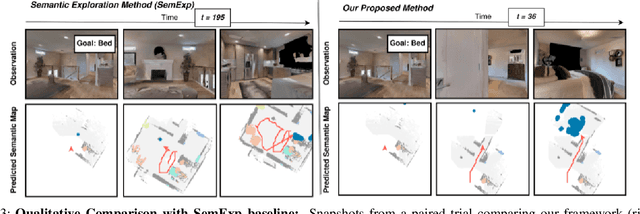

Object Goal Navigation requires a robot to find and navigate to an instance of a target object class in a previously unseen environment. Our framework incrementally builds a semantic map of the environment over time, and then repeatedly selects a long-term goal ('where to go') based on the semantic map to locate the target object instance. Long-term goal selection is formulated as a vision-based deep reinforcement learning problem. Specifically, an Encoder Network is trained to extract high-level features from a semantic map and select a long-term goal. In addition, we incorporate data augmentation and Q-function regularization to make the long-term goal selection more effective. We report experimental results using the photo-realistic Gibson benchmark dataset in the AI Habitat 3D simulation environment to demonstrate substantial performance improvement on standard measures in comparison with a state of the art data-driven baseline.
WATCH: Wasserstein Change Point Detection for High-Dimensional Time Series Data
Jan 18, 2022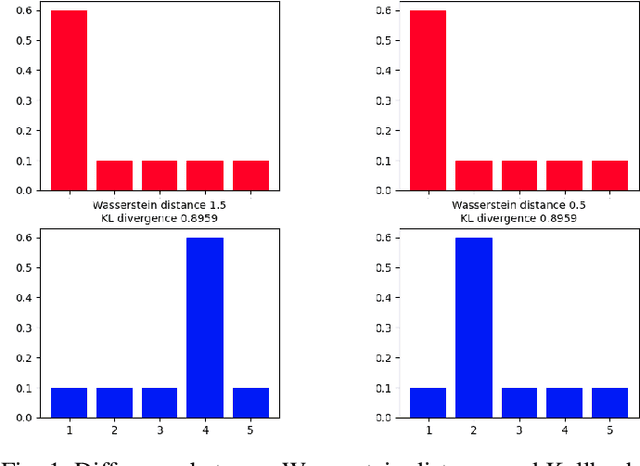
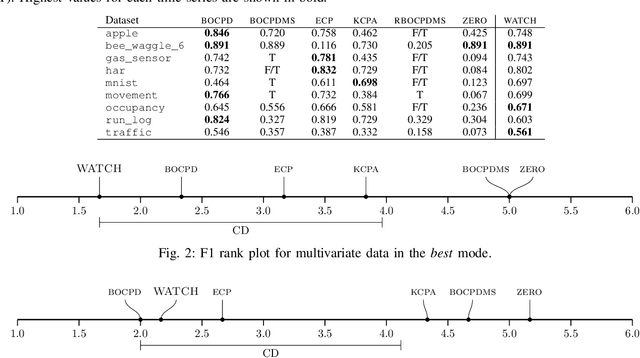


Detecting relevant changes in dynamic time series data in a timely manner is crucially important for many data analysis tasks in real-world settings. Change point detection methods have the ability to discover changes in an unsupervised fashion, which represents a desirable property in the analysis of unbounded and unlabeled data streams. However, one limitation of most of the existing approaches is represented by their limited ability to handle multivariate and high-dimensional data, which is frequently observed in modern applications such as traffic flow prediction, human activity recognition, and smart grids monitoring. In this paper, we attempt to fill this gap by proposing WATCH, a novel Wasserstein distance-based change point detection approach that models an initial distribution and monitors its behavior while processing new data points, providing accurate and robust detection of change points in dynamic high-dimensional data. An extensive experimental evaluation involving a large number of benchmark datasets shows that WATCH is capable of accurately identifying change points and outperforming state-of-the-art methods.
DC-MRTA: Decentralized Multi-Robot Task Allocation and Navigation in Complex Environments
Sep 07, 2022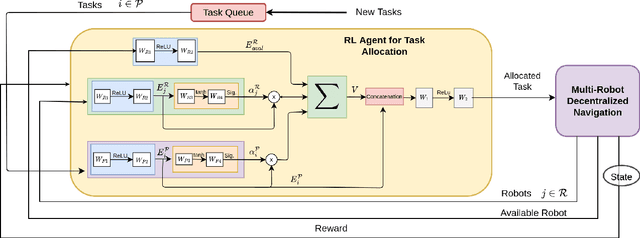
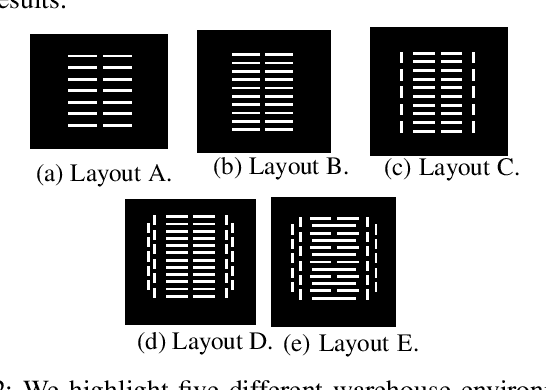
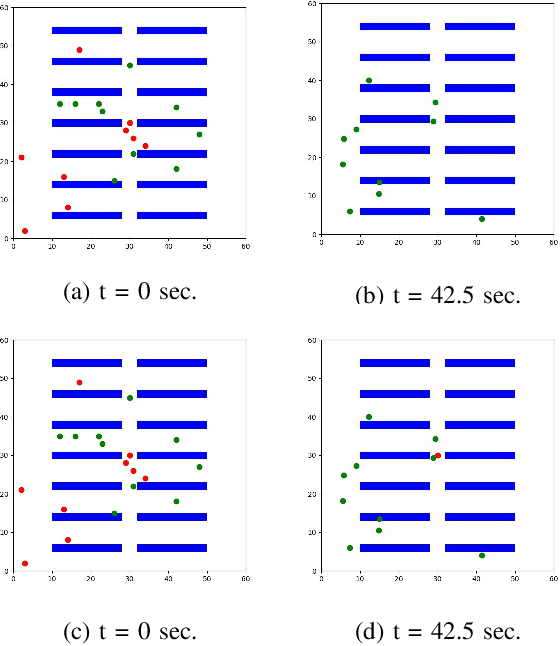
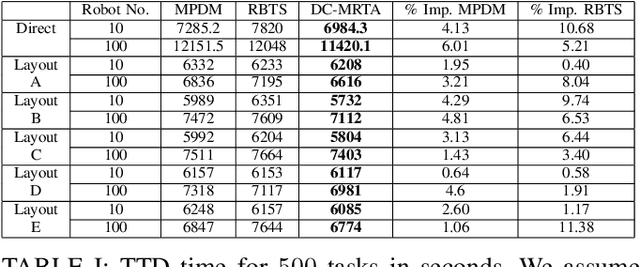
We present a novel reinforcement learning (RL) based task allocation and decentralized navigation algorithm for mobile robots in warehouse environments. Our approach is designed for scenarios in which multiple robots are used to perform various pick up and delivery tasks. We consider the problem of joint decentralized task allocation and navigation and present a two level approach to solve it. At the higher level, we solve the task allocation by formulating it in terms of Markov Decision Processes and choosing the appropriate rewards to minimize the Total Travel Delay (TTD). At the lower level, we use a decentralized navigation scheme based on ORCA that enables each robot to perform these tasks in an independent manner, and avoid collisions with other robots and dynamic obstacles. We combine these lower and upper levels by defining rewards for the higher level as the feedback from the lower level navigation algorithm. We perform extensive evaluation in complex warehouse layouts with large number of agents and highlight the benefits over state-of-the-art algorithms based on myopic pickup distance minimization and regret-based task selection. We observe improvement up to 14% in terms of task completion time and up-to 40% improvement in terms of computing collision-free trajectories for the robots.