 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-area Target Individual Detection with Free Drawing on Video
Jul 06, 2022
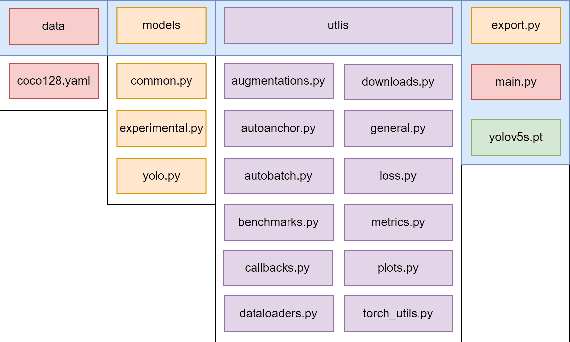
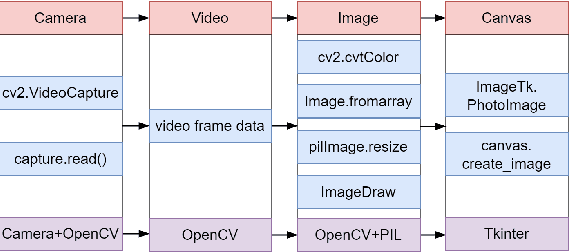
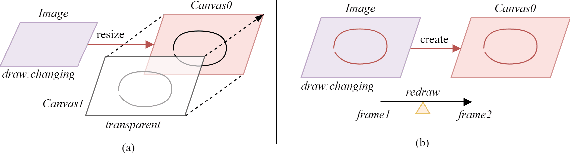
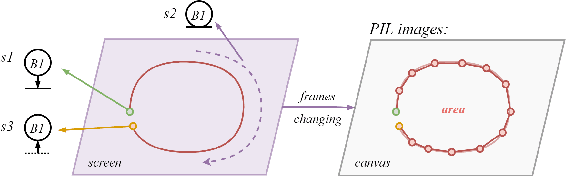
This paper has provided a novel design idea and some implementation methods to make a real time detection of multi-areas with multiple detecting areas that are generated by the real time drawing on the screen display of the video. The drawing on the video will remain the output as polylines, and the colors of the outlines will change when the stage of drawing or detecting is changed. The shape of the drawn area is free to be customized and real-time effective. The configuration of the drawn areas can be renewed and the detecting areas are working individually. The detection result should be shown with a GUI designed by Tkinter. The object recognition model was developed on YOLOv5 but can be changed to others, which means the core design and implementation idea of this paper is model-independent. With PIL and OpenCV and Tkinter, the drawing effect is real time and efficient. The design and code of this research is basic and can be extended to be implemented in numerous monitoring and detecting situations.
Classify Respiratory Abnormality in Lung Sounds Using STFT and a Fine-Tuned ResNet18 Network
Aug 30, 2022
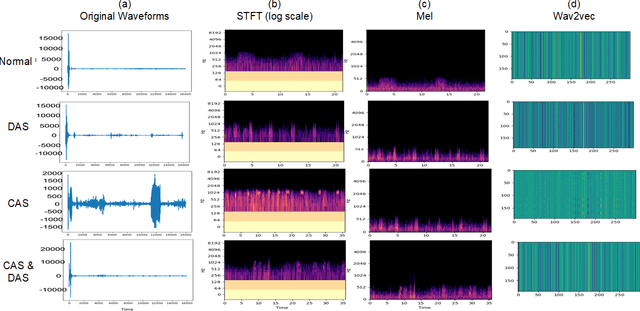
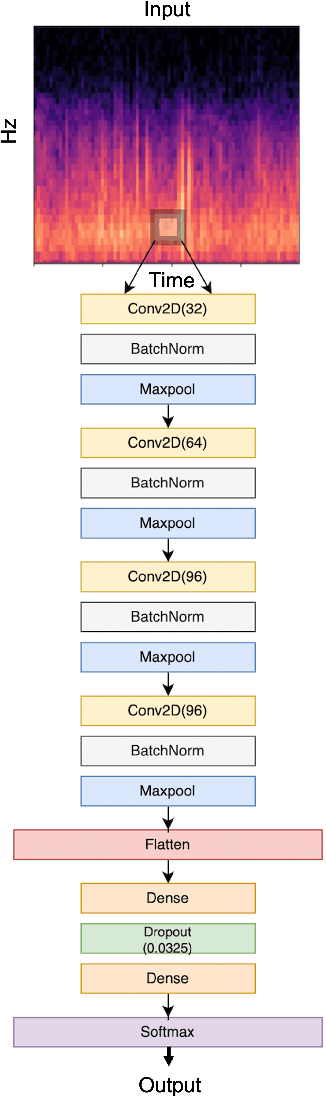
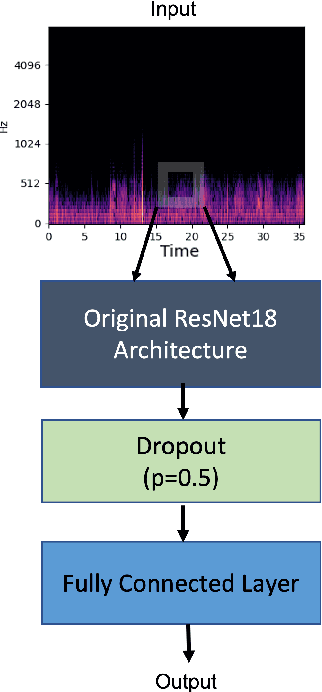
Recognizing patterns in lung sounds is crucial to detecting and monitoring respiratory diseases. Current techniques for analyzing respiratory sounds demand domain experts and are subject to interpretation. Hence an accurate and automatic respiratory sound classification system is desired. In this work, we took a data-driven approach to classify abnormal lung sounds. We compared the performance using three different feature extraction techniques, which are short-time Fourier transformation (STFT), Mel spectrograms, and Wav2vec, as well as three different classifiers, including pre-trained ResNet18, LightCNN, and Audio Spectrogram Transformer. Our key contributions include the bench-marking of different audio feature extractors and neural network based classifiers, and the implementation of a complete pipeline using STFT and a fine-tuned ResNet18 network. The proposed method achieved Harmonic Scores of 0.89, 0.80, 0.71, 0.36 for tasks 1-1, 1-2, 2-1 and 2-2, respectively on the testing sets in the IEEE BioCAS 2022 Grand Challenge on Respiratory Sound Classification.
Interactions in Information Spread
Sep 16, 2022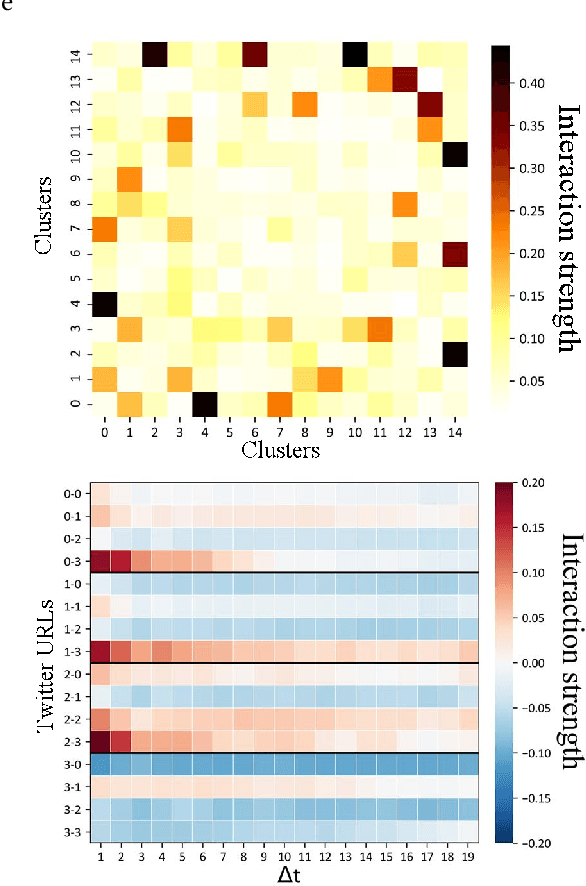
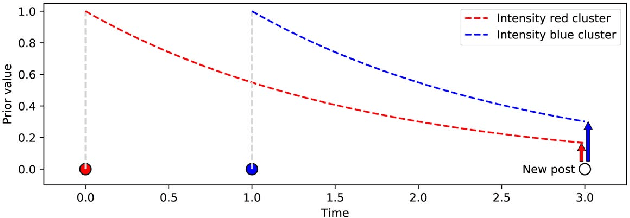
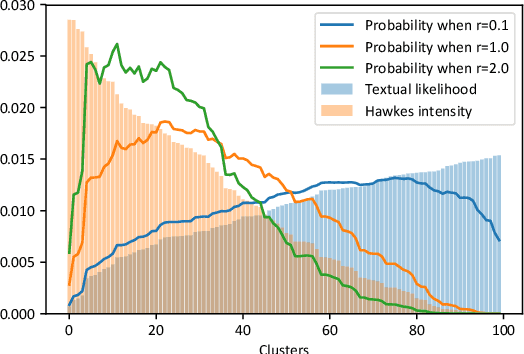
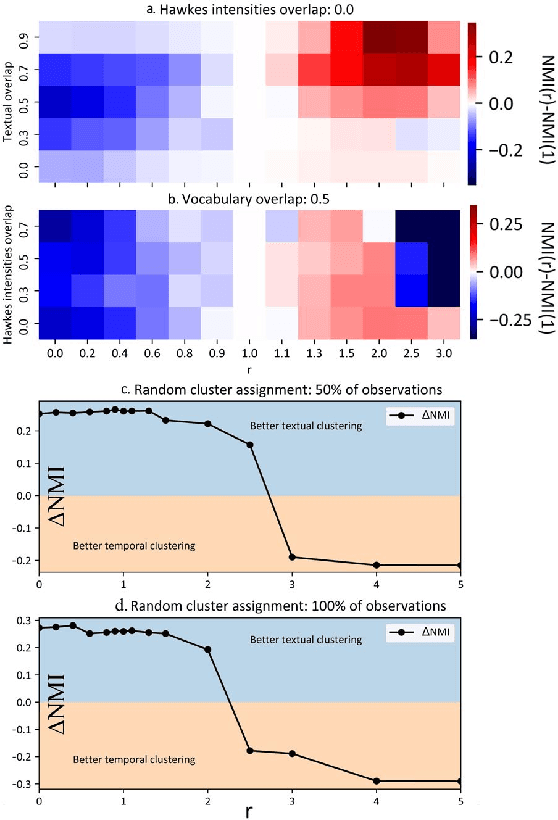
Since the development of writing 5000 years ago, human-generated data gets produced at an ever-increasing pace. Classical archival methods aimed at easing information retrieval. Nowadays, archiving is not enough anymore. The amount of data that gets generated daily is beyond human comprehension, and appeals for new information retrieval strategies. Instead of referencing every single data piece as in traditional archival techniques, a more relevant approach consists in understanding the overall ideas conveyed in data flows. To spot such general tendencies, a precise comprehension of the underlying data generation mechanisms is required. In the rich literature tackling this problem, the question of information interaction remains nearly unexplored. First, we investigate the frequency of such interactions. Building on recent advances made in Stochastic Block Modelling, we explore the role of interactions in several social networks. We find that interactions are rare in these datasets. Then, we wonder how interactions evolve over time. Earlier data pieces should not have an everlasting influence on ulterior data generation mechanisms. We model this using dynamic network inference advances. We conclude that interactions are brief. Finally, we design a framework that jointly models rare and brief interactions based on Dirichlet-Hawkes Processes. We argue that this new class of models fits brief and sparse interaction modelling. We conduct a large-scale application on Reddit and find that interactions play a minor role in this dataset. From a broader perspective, our work results in a collection of highly flexible models and in a rethinking of core concepts of machine learning. Consequently, we open a range of novel perspectives both in terms of real-world applications and in terms of technical contributions to machine learning.
On the Horizon: Interactive and Compositional Deepfakes
Sep 05, 2022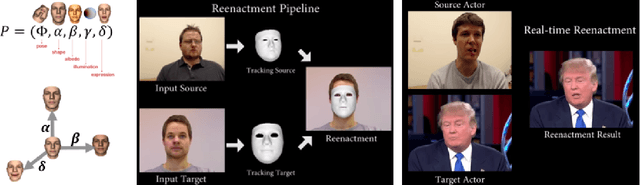
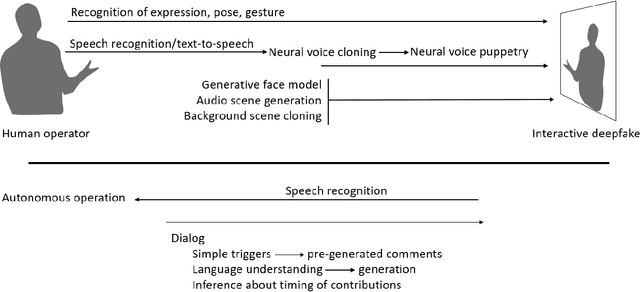
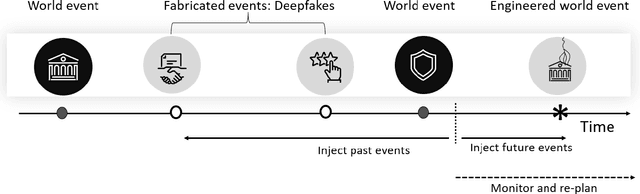
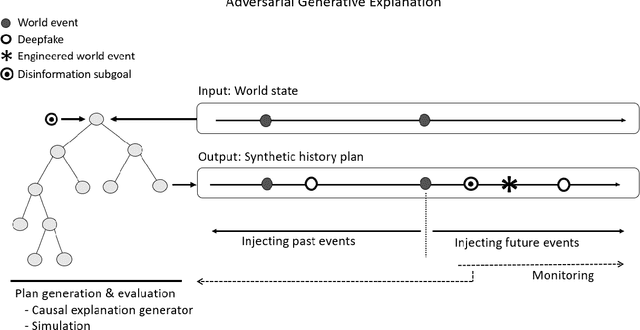
Over a five-year period, computing methods for generating high-fidelity, fictional depictions of people and events moved from exotic demonstrations by computer science research teams into ongoing use as a tool of disinformation. The methods, referred to with the portmanteau of "deepfakes," have been used to create compelling audiovisual content. Here, I share challenges ahead with malevolent uses of two classes of deepfakes that we can expect to come into practice with costly implications for society: interactive and compositional deepfakes. Interactive deepfakes have the capability to impersonate people with realistic interactive behaviors, taking advantage of advances in multimodal interaction. Compositional deepfakes leverage synthetic content in larger disinformation plans that integrate sets of deepfakes over time with observed, expected, and engineered world events to create persuasive synthetic histories. Synthetic histories can be constructed manually but may one day be guided by adversarial generative explanation (AGE) techniques. In the absence of mitigations, interactive and compositional deepfakes threaten to move us closer to a post-epistemic world, where fact cannot be distinguished from fiction. I shall describe interactive and compositional deepfakes and reflect about cautions and potential mitigations to defend against them.
Design and Development of Miniature long distance multi-moving robots for 3D Smart Sensing for underground Pipe Inspection
Aug 22, 2022


Designing an in-pipe climbing robot that manipulates sharp gears to study complex line relationships. Traditional rolling/happening pipe climbing robots tend to slide when exploring pipe curves. The proposed gearbox connects to the farthest ground plane of a standard dual output gearbox. Instrumentation helps achieve a very well-defined deceleration sequence in which the robot slides and pulls as it moves forward. This instrument takes into account the forces exerted on each track within the line relationship and intentionally modifies the robot's track speed, unlocking the key to fine-tuning. This makes the 3 output transmissions take a lot of time. Deflection of the robot on a pipe network with various bearings and non-slip pipe bends demonstrates the integrity of the proposed structure.
Bayesian Algorithm Execution for Tuning Particle Accelerator Emittance with Partial Measurements
Sep 10, 2022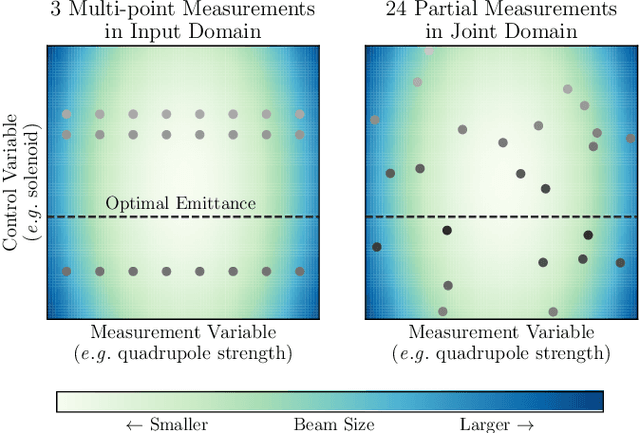
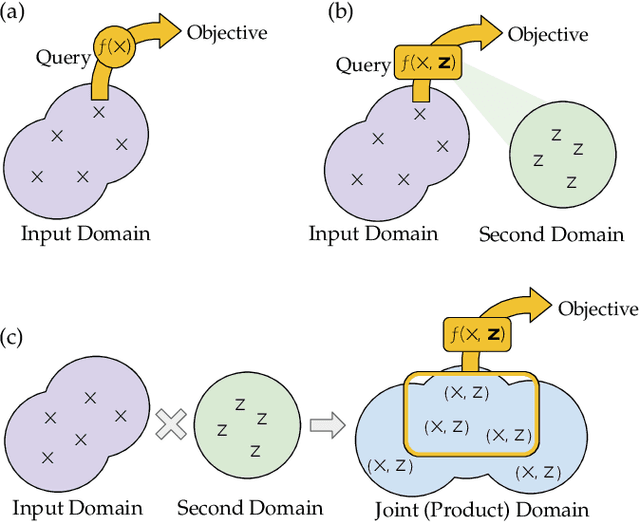
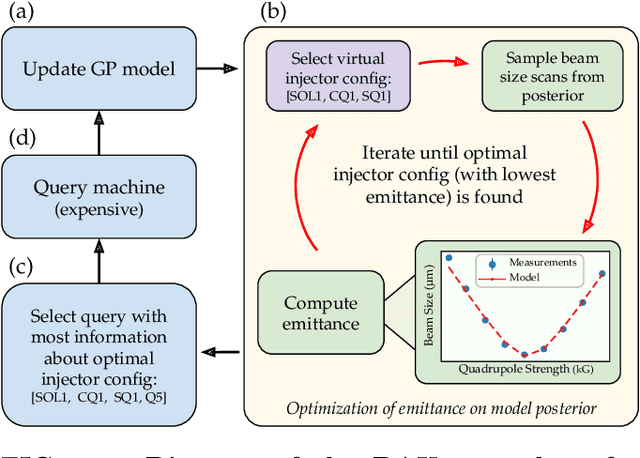
Traditional black-box optimization methods are inefficient when dealing with multi-point measurement, i.e. when each query in the control domain requires a set of measurements in a secondary domain to calculate the objective. In particle accelerators, emittance tuning from quadrupole scans is an example of optimization with multi-point measurements. Although the emittance is a critical parameter for the performance of high-brightness machines, including X-ray lasers and linear colliders, comprehensive optimization is often limited by the time required for tuning. Here, we extend the recently-proposed Bayesian Algorithm Execution (BAX) to the task of optimization with multi-point measurements. BAX achieves sample-efficiency by selecting and modeling individual points in the joint control-measurement domain. We apply BAX to emittance minimization at the Linac Coherent Light Source (LCLS) and the Facility for Advanced Accelerator Experimental Tests II (FACET-II) particle accelerators. In an LCLS simulation environment, we show that BAX delivers a 20x increase in efficiency while also being more robust to noise compared to traditional optimization methods. Additionally, we ran BAX live at both LCLS and FACET-II, matching the hand-tuned emittance at FACET-II and achieving an optimal emittance that was 24% lower than that obtained by hand-tuning at LCLS. We anticipate that our approach can readily be adapted to other types of optimization problems involving multi-point measurements commonly found in scientific instruments.
Modeling Long-term Dependencies and Short-term Correlations in Patient Journey Data with Temporal Attention Networks for Health Prediction
Jul 15, 2022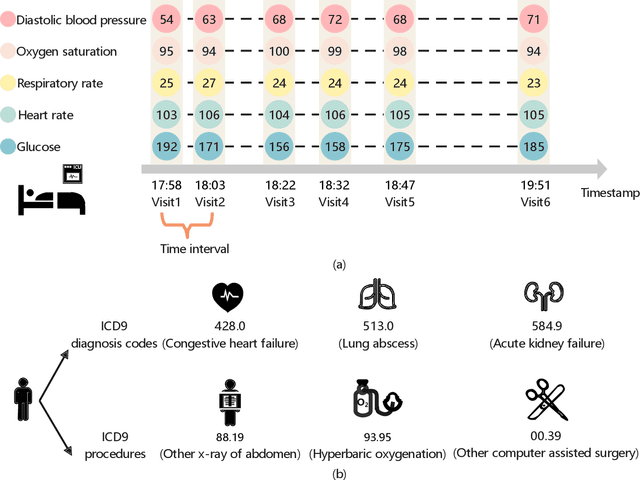
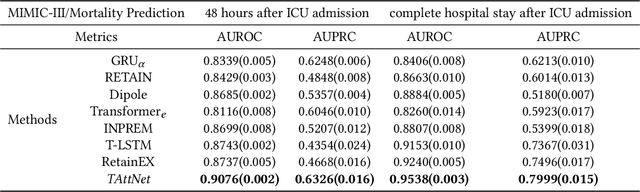
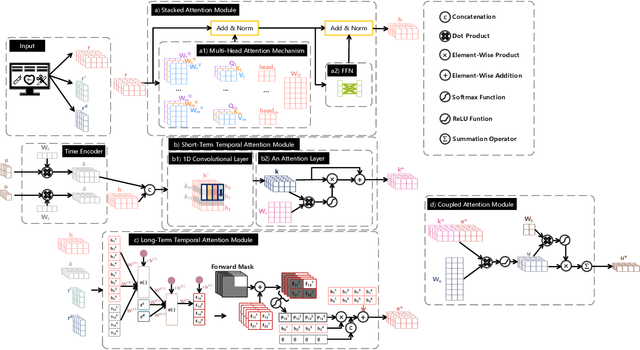
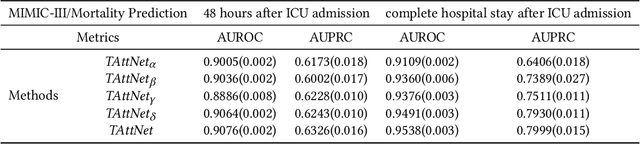
Building models for health prediction based on Electronic Health Records (EHR) has become an active research area. EHR patient journey data consists of patient time-ordered clinical events/visits from patients. Most existing studies focus on modeling long-term dependencies between visits, without explicitly taking short-term correlations between consecutive visits into account, where irregular time intervals, incorporated as auxiliary information, are fed into health prediction models to capture latent progressive patterns of patient journeys. We present a novel deep neural network with four modules to take into account the contributions of various variables for health prediction: i) the Stacked Attention module strengthens the deep semantics in clinical events within each patient journey and generates visit embeddings, ii) the Short-Term Temporal Attention module models short-term correlations between consecutive visit embeddings while capturing the impact of time intervals within those visit embeddings, iii) the Long-Term Temporal Attention module models long-term dependencies between visit embeddings while capturing the impact of time intervals within those visit embeddings, iv) and finally, the Coupled Attention module adaptively aggregates the outputs of Short-Term Temporal Attention and Long-Term Temporal Attention modules to make health predictions. Experimental results on MIMIC-III demonstrate superior predictive accuracy of our model compared to existing state-of-the-art methods, as well as the interpretability and robustness of this approach. Furthermore, we found that modeling short-term correlations contributes to local priors generation, leading to improved predictive modeling of patient journeys.
NPB-REC: Non-parametric Assessment of Uncertainty in Deep-learning-based MRI Reconstruction from Undersampled Data
Aug 08, 2022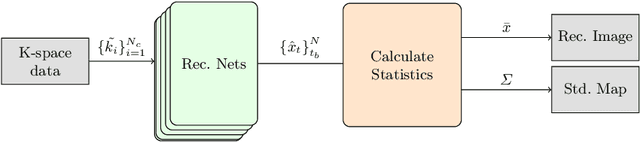
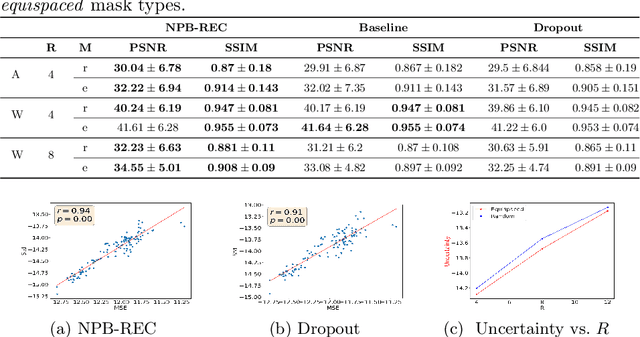
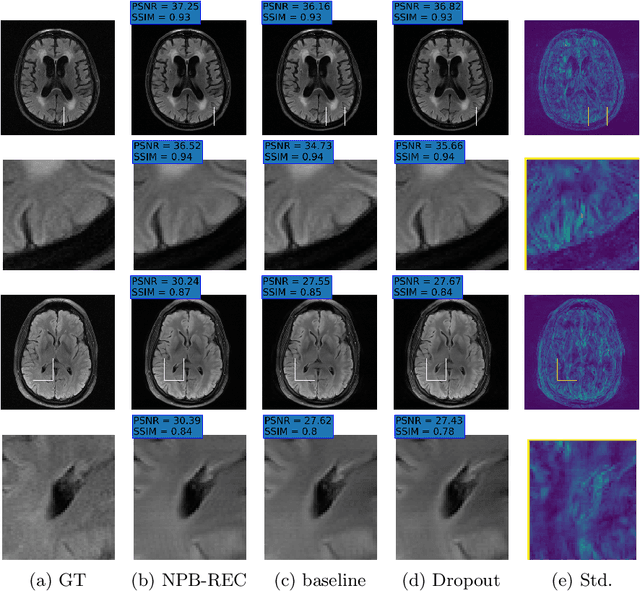
Uncertainty quantification in deep-learning (DL) based image reconstruction models is critical for reliable clinical decision making based on the reconstructed images. We introduce "NPB-REC", a non-parametric fully Bayesian framework for uncertainty assessment in MRI reconstruction from undersampled "k-space" data. We use Stochastic gradient Langevin dynamics (SGLD) during the training phase to characterize the posterior distribution of the network weights. We demonstrated the added-value of our approach on the multi-coil brain MRI dataset, from the fastmri challenge, in comparison to the baseline E2E-VarNet with and without inference-time dropout. Our experiments show that NPB-REC outperforms the baseline by means of reconstruction accuracy (PSNR and SSIM of $34.55$, $0.908$ vs. $33.08$, $0.897$, $p<0.01$) in high acceleration rates ($R=8$). This is also measured in regions of clinical annotations. More significantly, it provides a more accurate estimate of the uncertainty that correlates with the reconstruction error, compared to the Monte-Carlo inference time Dropout method (Pearson correlation coefficient of $R=0.94$ vs. $R=0.91$). The proposed approach has the potential to facilitate safe utilization of DL based methods for MRI reconstruction from undersampled data. Code and trained models are available in \url{https://github.com/samahkh/NPB-REC}.
MRF-PINN: A Multi-Receptive-Field convolutional physics-informed neural network for solving partial differential equations
Sep 16, 2022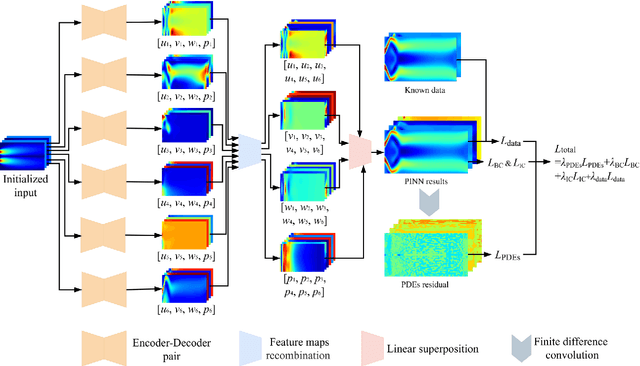
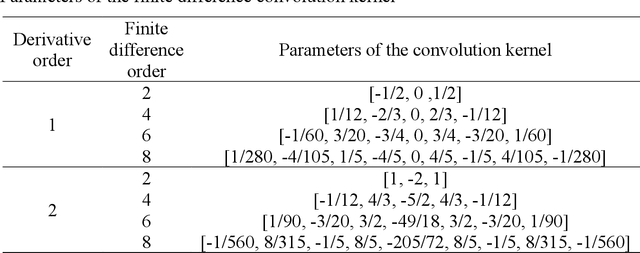
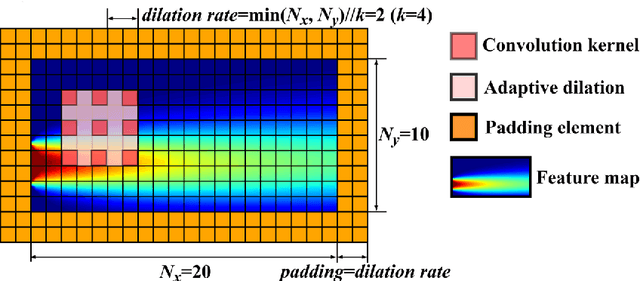

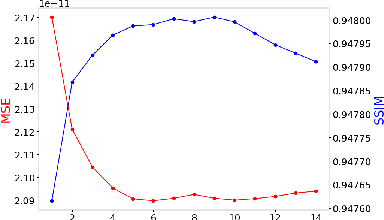
Compared with conventional numerical approaches to solving partial differential equations (PDEs), physics-informed neural networks (PINN) have manifested the capability to save development effort and computational cost, especially in scenarios of reconstructing the physics field and solving the inverse problem. Considering the advantages of parameter sharing, spatial feature extraction and low inference cost, convolutional neural networks (CNN) are increasingly used in PINN. However, some challenges still remain as follows. To adapt convolutional PINN to solve different PDEs, considerable effort is usually needed for tuning critical hyperparameters. Furthermore, the effects of the finite difference accuracy, and the mesh resolution on the predictivity of convolutional PINN are not settled. To fill the gaps above, we propose three initiatives in this paper: (1) A Multi-Receptive-Field PINN (MRF-PINN) model is established to solve different types of PDEs on various mesh resolutions without manual tuning; (2) The dimensional balance method is used to estimate the loss weights when solving Navier-Stokes equations; (3) The Taylor polynomial is used to pad the virtual nodes near the boundaries for implementing high-order finite difference. The proposed MRF-PINN is tested for solving three typical linear PDEs (elliptic, parabolic, hyperbolic) and a series of nonlinear PDEs (Navier-Stokes PDEs) to demonstrate its generality and superiority. This paper shows that MRF-PINN can adapt to completely different equation types and mesh resolutions without any hyperparameter tuning. The dimensional balance method saves computational time and improves the convergence for solving Navier-Stokes PDEs. Further, the solving error is significantly decreased under high-order finite difference, large channel number, and high mesh resolution, which is expected to be a general convolutional PINN scheme.
Learning Clinical Concepts for Predicting Risk of Progression to Severe COVID-19
Aug 28, 2022
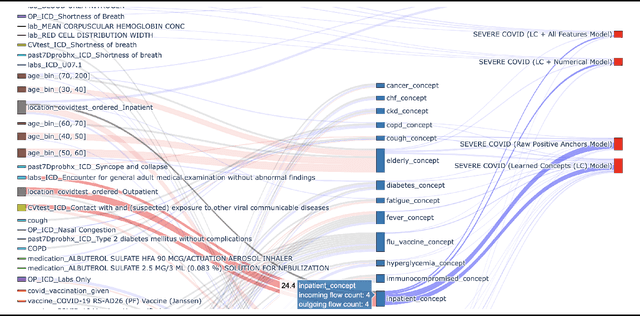
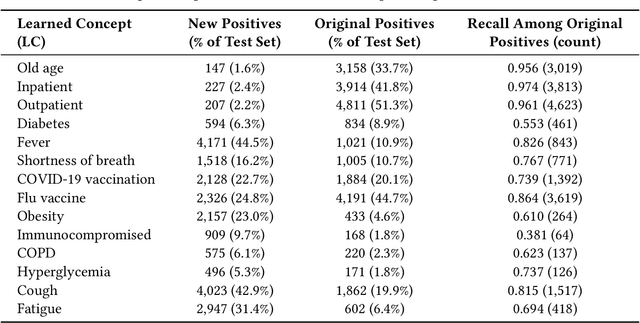
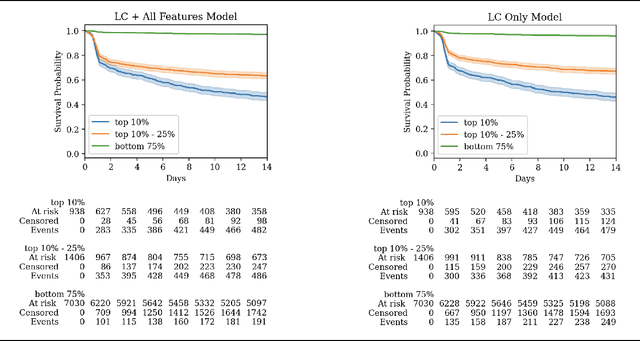
With COVID-19 now pervasive, identification of high-risk individuals is crucial. Using data from a major healthcare provider in Southwestern Pennsylvania, we develop survival models predicting severe COVID-19 progression. In this endeavor, we face a tradeoff between more accurate models relying on many features and less accurate models relying on a few features aligned with clinician intuition. Complicating matters, many EHR features tend to be under-coded, degrading the accuracy of smaller models. In this study, we develop two sets of high-performance risk scores: (i) an unconstrained model built from all available features; and (ii) a pipeline that learns a small set of clinical concepts before training a risk predictor. Learned concepts boost performance over the corresponding features (C-index 0.858 vs. 0.844) and demonstrate improvements over (i) when evaluated out-of-sample (subsequent time periods). Our models outperform previous works (C-index 0.844-0.872 vs. 0.598-0.810).