 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
If Influence Functions are the Answer, Then What is the Question?
Sep 12, 2022
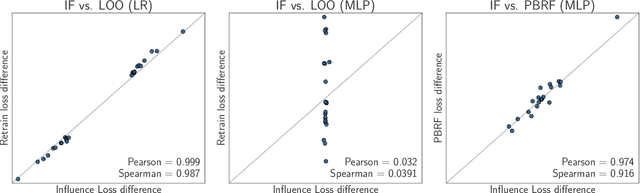


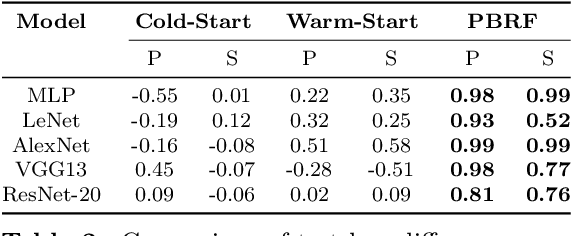
Influence functions efficiently estimate the effect of removing a single training data point on a model's learned parameters. While influence estimates align well with leave-one-out retraining for linear models, recent works have shown this alignment is often poor in neural networks. In this work, we investigate the specific factors that cause this discrepancy by decomposing it into five separate terms. We study the contributions of each term on a variety of architectures and datasets and how they vary with factors such as network width and training time. While practical influence function estimates may be a poor match to leave-one-out retraining for nonlinear networks, we show they are often a good approximation to a different object we term the proximal Bregman response function (PBRF). Since the PBRF can still be used to answer many of the questions motivating influence functions, such as identifying influential or mislabeled examples, our results suggest that current algorithms for influence function estimation give more informative results than previous error analyses would suggest.
Vaccine Discourse on Twitter During the COVID-19 Pandemic
Jul 23, 2022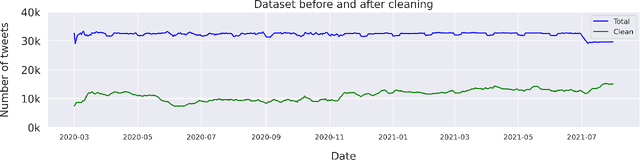

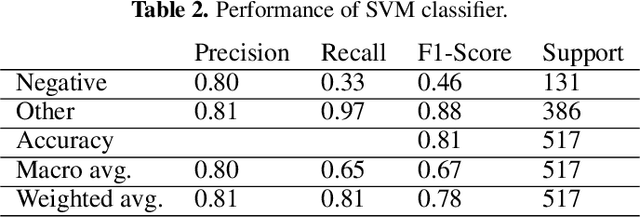
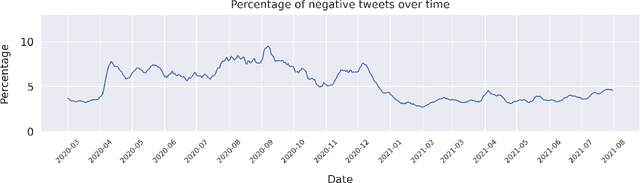
Since the onset of the COVID-19 pandemic, vaccines have been an important topic in public discourse. The discussions around vaccines are polarized as some see them as an important measure to end the pandemic, and others are hesitant or find them harmful. This study investigates posts related to COVID-19 vaccines on Twitter and focuses on those which have a negative stance toward vaccines. A dataset of 16,713,238 English tweets related to COVID-19 vaccines was collected covering the period from March 1, 2020, to July 31, 2021. We used the Scikit-learn Python library to apply a support vector machine (SVM) classifier to identify the tweets with a negative stance toward the COVID-19 vaccines. A total of 5,163 tweets were used to train the classifier, out of which a subset of 2,484 tweets were manually annotated by us and made publicly available. We used the BERTtopic model to extract and investigate the topics discussed within the negative tweets and how they changed over time. We show that the negativity with respect to COVID-19 vaccines has decreased over time along with the vaccine roll-outs. We identify 37 topics of discussion and present their respective importance over time. We show that popular topics consist of conspiratorial discussions such as 5G towers and microchips, but also contain legitimate concerns around vaccination safety and side effects as well as concerns about policies. Our study shows that even unpopular opinions or conspiracy theories can become widespread when paired with a widely popular discussion topic such as COVID-19 vaccines. Understanding the concerns and the discussed topics and how they change over time is essential for policymakers and public health authorities to provide better and in-time information and policies, to facilitate vaccination of the population in future similar crises.
Learning Noise with Generative Adversarial Networks: Explorations with Classical Random Process Models
Jul 03, 2022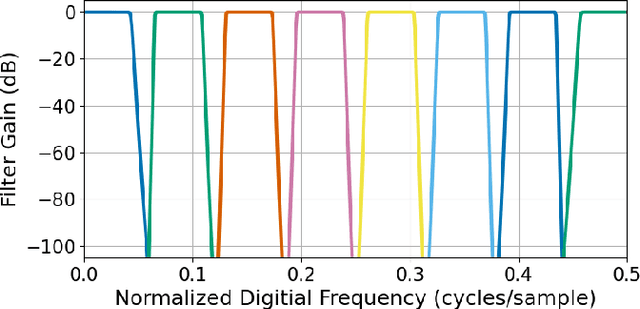
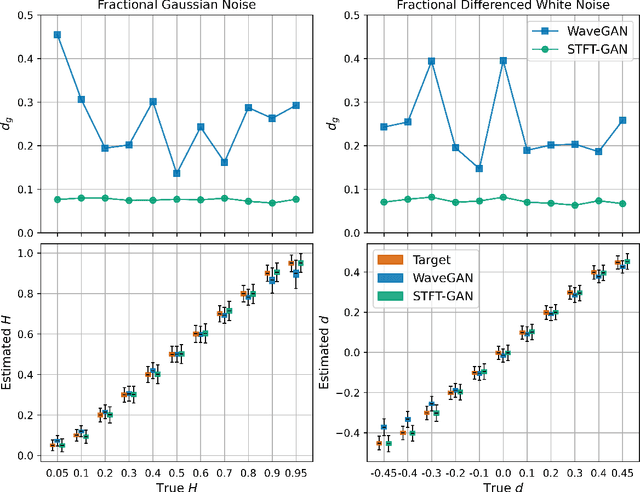
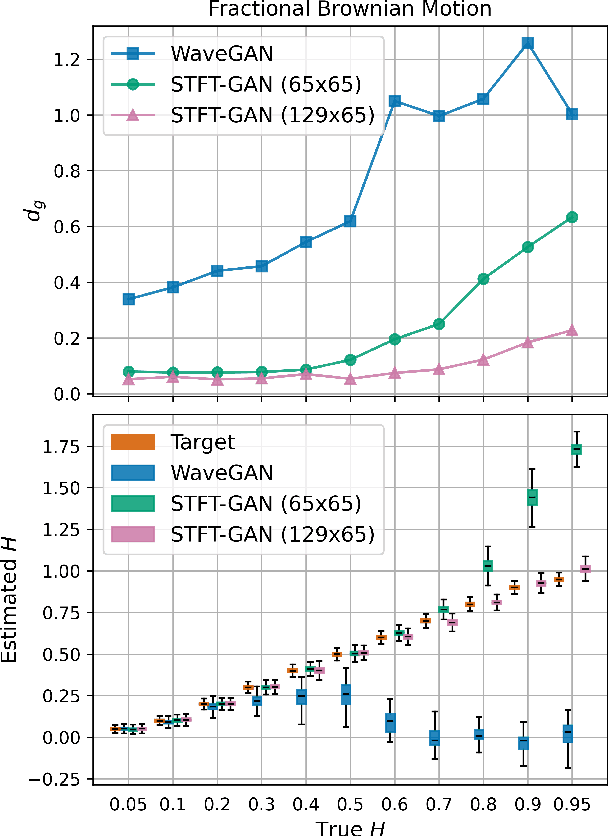
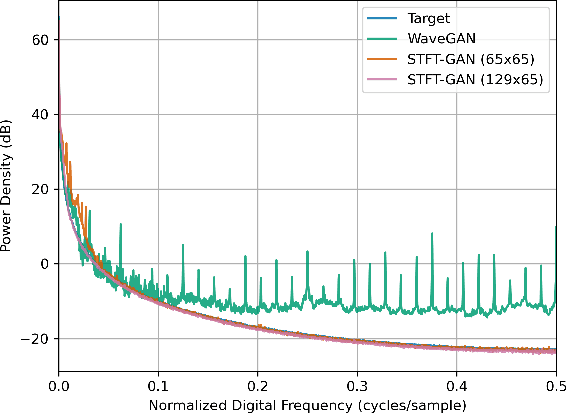
Random noise arising from physical processes is an inherent characteristic of measurements and a limiting factor for most signal processing tasks. Given the recent interest in generative adversarial networks (GANs) for data-driven signal modeling, it is important to determine to what extent GANs can faithfully reproduce noise in target data sets. In this paper, we present an empirical investigation that aims to shed light on this issue for time series. Namely, we examine the ability of two general-purpose time-series GANs, a direct time-series model and an image-based model using a short-time Fourier transform (STFT) representation, to learn a broad range of noise types commonly encountered in electronics and communication systems: band-limited thermal noise, power law noise, shot noise, and impulsive noise. We find that GANs are capable of learning many noise types, although they predictably struggle when the GAN architecture is not well suited to some aspects of the noise, e.g., impulsive time-series with extreme outliers. Our findings provide insights into the capabilities and potential limitations of current approaches to time-series GANs and highlight areas for further research. In addition, our battery of tests provides a useful benchmark to aid the development of deep generative models for time series.
A review on longitudinal data analysis with random forest in precision medicine
Aug 08, 2022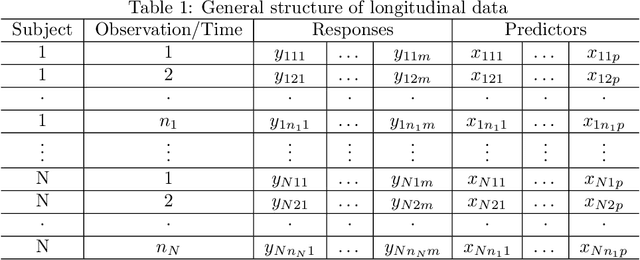
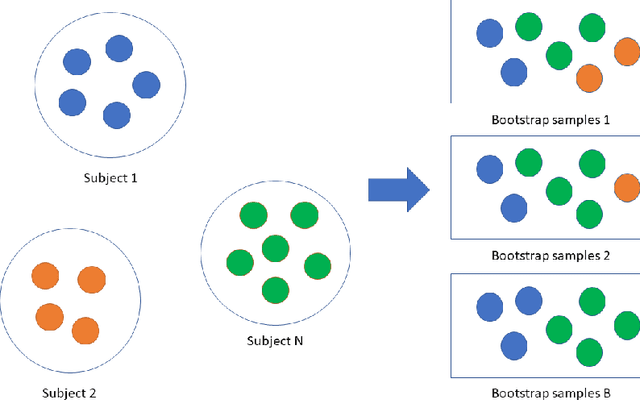
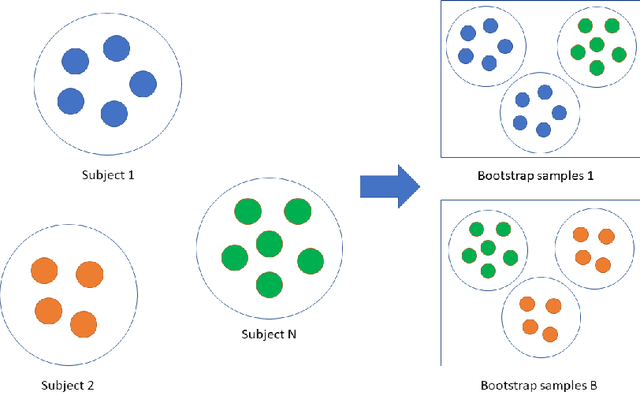

Precision medicine provides customized treatments to patients based on their characteristics and is a promising approach to improving treatment efficiency. Large scale omics data are useful for patient characterization, but often their measurements change over time, leading to longitudinal data. Random forest is one of the state-of-the-art machine learning methods for building prediction models, and can play a crucial role in precision medicine. In this paper, we review extensions of the standard random forest method for the purpose of longitudinal data analysis. Extension methods are categorized according to the data structures for which they are designed. We consider both univariate and multivariate responses and further categorize the repeated measurements according to whether the time effect is relevant. Information of available software implementations of the reviewed extensions is also given. We conclude with discussions on the limitations of our review and some future research directions.
Sensing Aided OTFS Channel Estimation for Massive MIMO Systems
Sep 22, 2022
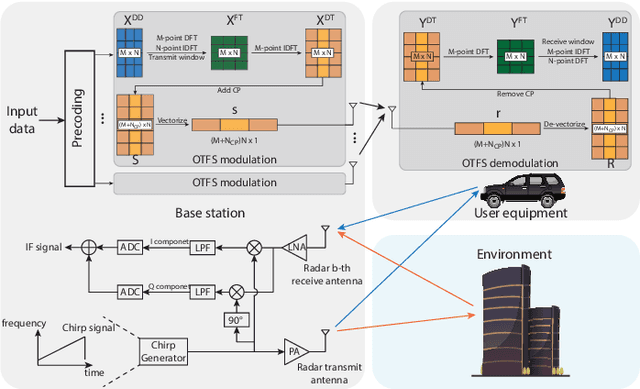


Orthogonal time frequency space (OTFS) modulation has the potential to enable robust communications in highly-mobile scenarios. Estimating the channels for OTFS systems, however, is associated with high pilot signaling overhead that scales with the maximum delay and Doppler spreads. This becomes particularly challenging for massive MIMO systems where the overhead also scales with the number of antennas. An important observation however is that the delay, Doppler, and angle of departure/arrival information are directly related to the distance, velocity, and direction information of the mobile user and the various scatterers in the environment. With this motivation, we propose to leverage radar sensing to obtain this information about the mobile users and scatterers in the environment and leverage it to aid the OTFS channel estimation in massive MIMO systems. As one approach to realize our vision, this paper formulates the OTFS channel estimation problem in massive MIMO systems as a sparse recovery problem and utilizes the radar sensing information to determine the support (locations of the non-zero delay-Doppler taps). The proposed radar sensing aided sparse recovery algorithm is evaluated based on an accurate 3D ray-tracing framework with co-existing radar and communication data. The results show that the developed sensing-aided solution consistently outperforms the standard sparse recovery algorithms (that do not leverage radar sensing data) and leads to a significant reduction in the pilot overhead, which highlights a promising direction for OTFS based massive MIMO systems.
Vehicle Trajectory Tracking Through Magnetic Sensors
Sep 09, 2022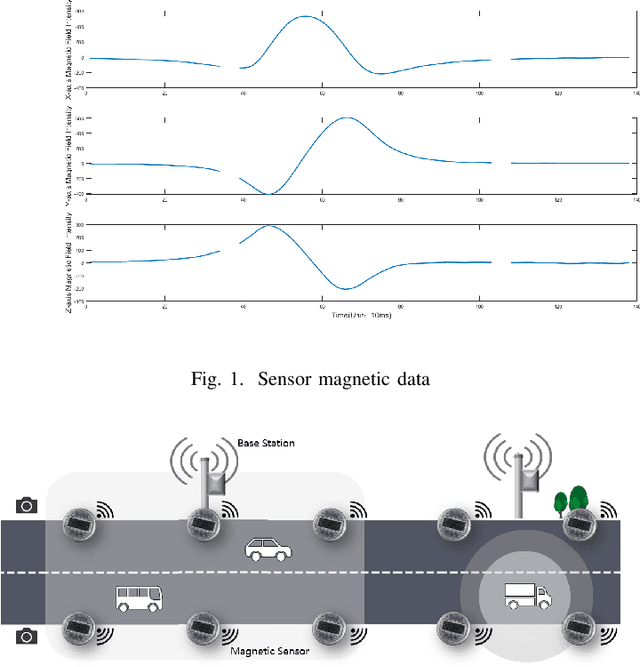
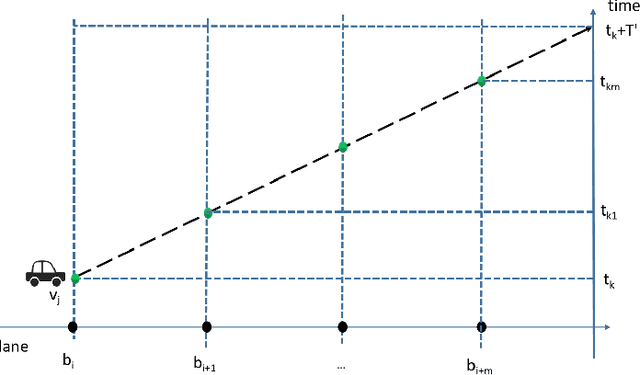
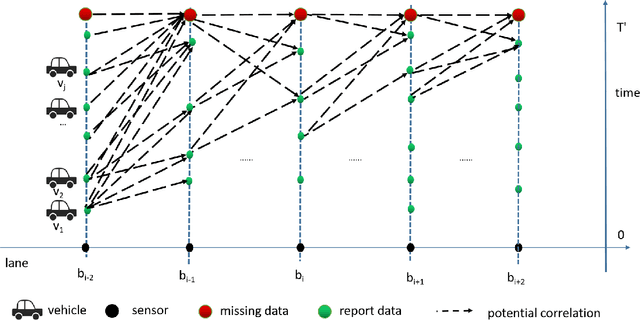
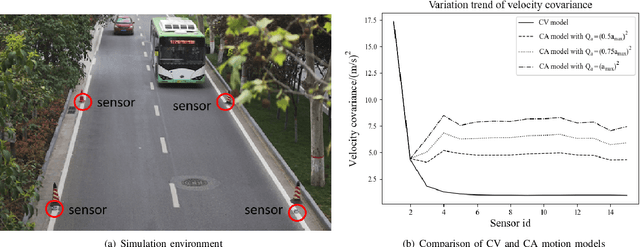
Traffic surveillance is an important issue in Intelligent Transportation Systems(ITS). In this paper, we propose a novel surveillance system to detect and track vehicles using ubiquitously deployed magnetic sensors. That is, multiple magnetic sensors, mounted roadside and along lane boundary lines, are used to track various vehicles. Real-time vehicle detection data are reported from magnetic sensors, collected into data center via base stations, and processed to depict vehicle trajectories including vehicle position, timestamp, speed and type. We first define a vehicle trajectory tracking problem. We then propose a graph-based data association algorithm to track each detected vehicle, and design a related online algorithm framework respectively. We finally validate the performance via both experimental simulation and real-world road test. The experimental results demonstrate that the proposed solution provides a cost-effective solution to capture the driving status of vehicles and on that basis form various traffic safety and efficiency applications.
A Multi-Task Learning Model for Super Resolution of Wireless Channel Characteristics
Sep 09, 2022Channel modeling has always been the core part in communication system design and development, especially in 5G and 6G era. Traditional approaches like stochastic channel modeling and ray-tracing (RT) based channel modeling depend heavily on measurement data or simulation, which are usually expensive and time consuming. In this paper, we propose a novel super resolution (SR) model for generating channel characteristics data. The model is based on multi-task learning (MTL) convolutional neural networks (CNN) with residual connection. Experiments demonstrate that the proposed SR model could achieve excellent performances in mean absolute error and standard deviation of error. Advantages of the proposed model are demonstrated in comparisons with other state-of-the-art deep learning models. Ablation study also proved the necessity of multi-task learning and techniques in model design. The contribution in this paper could be helpful in channel modeling, network optimization, positioning and other wireless channel characteristics related work by largely reducing workload of simulation or measurement.
CLIO: a Novel Robotic Solution for Exploration and Rescue Missions in Hostile Mountain Environments
Sep 20, 2022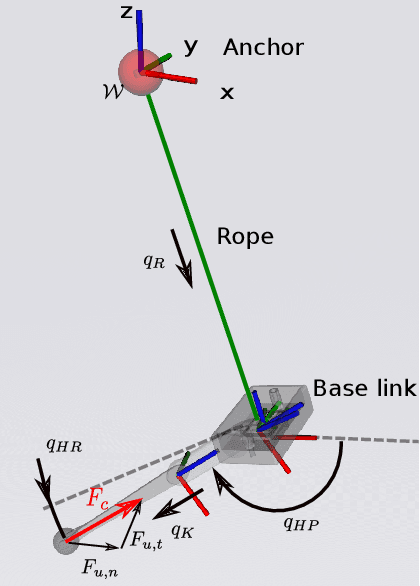
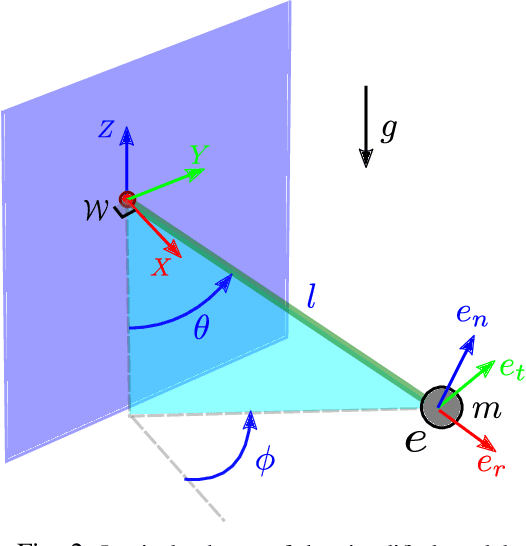
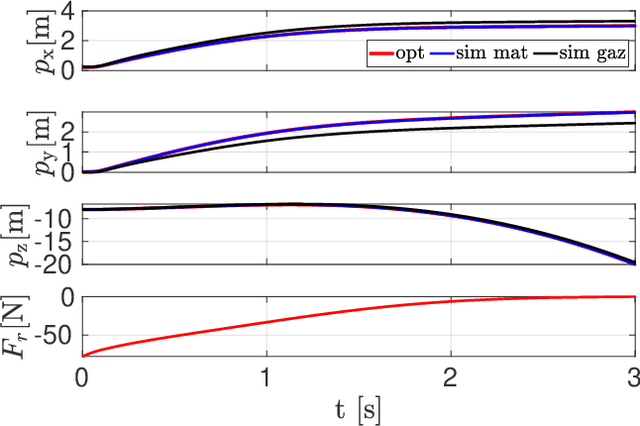
Rescue missions in mountain environments are hardly achievable by standard legged robots - because of the high slopes - or by flying robots - because of limited payload capacity. We present a novel concept for a rope-aided climbing robot, which can negotiate up-to-vertical slopes and carry heavy payloads. The robot is attached to the mountain through a rope, and is equipped with a leg to push against the mountain and initiate jumping maneuvers. Between jumps, a hoist is used to wind/unwind the rope to move vertically and affect the lateral motion. This simple (yet effective) two-fold actuation allows the system to achieve high safety and energy efficiency. Indeed, the rope prevents the robot from falling, while compensating for most of its weight, drastically reducing the effort required by the leg actuator. We also present an optimal control strategy to generate point-to-point trajectories overcoming an obstacle. We achieve fast computation time ($<$1 s) thanks to the use of a custom simplified robot model. We validated the generated optimal movements in Gazebo simulations with a complete robot model, showing the effectiveness of the proposed approach, and confirming the interest of our concept. Finally, we performed a reachability analysis showing that the region of achievable targets is strongly affected by the friction properties of the foot-wall contact.
Efficient Concurrent Design of the Morphology of Unmanned Aerial Systems and their Collective-Search Behavior
Sep 26, 2022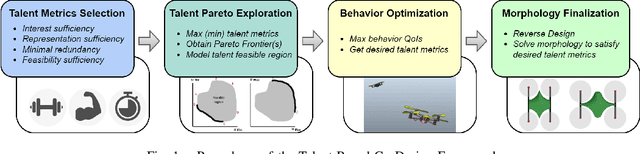
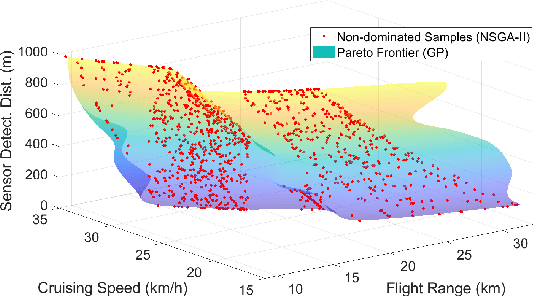
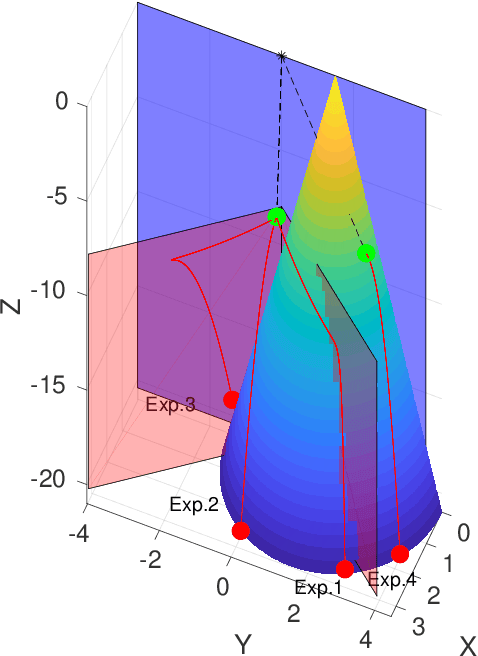
The collective operation of robots, such as unmanned aerial vehicles (UAVs) operating as a team or swarm, is affected by their individual capabilities, which in turn is dependent on their physical design, aka morphology. However, with the exception of a few (albeit ad hoc) evolutionary robotics methods, there has been very little work on understanding the interplay of morphology and collective behavior. There is especially a lack of computational frameworks to concurrently search for the robot morphology and the hyper-parameters of their behavior model that jointly optimize the collective (team) performance. To address this gap, this paper proposes a new co-design framework. Here the exploding computational cost of an otherwise nested morphology/behavior co-design is effectively alleviated through the novel concept of ``talent" metrics; while also allowing significantly better solutions compared to the typically sub-optimal sequential morphology$\to$behavior design approach. This framework comprises four major steps: talent metrics selection, talent Pareto exploration (a multi-objective morphology optimization process), behavior optimization, and morphology finalization. This co-design concept is demonstrated by applying it to design UAVs that operate as a team to localize signal sources, e.g., in victim search and hazard localization. Here, the collective behavior is driven by a recently reported batch Bayesian search algorithm called Bayes-Swarm. Our case studies show that the outcome of co-design provides significantly higher success rates in signal source localization compared to a baseline design, across a variety of signal environments and teams with 6 to 15 UAVs. Moreover, this co-design process provides two orders of magnitude reduction in computing time compared to a projected nested design approach.
Learning sparse auto-encoders for green AI image coding
Sep 09, 2022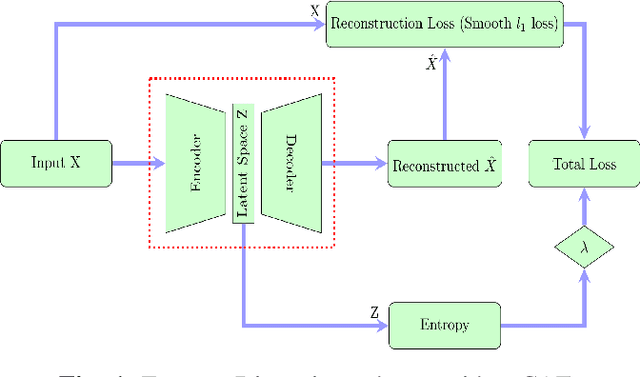
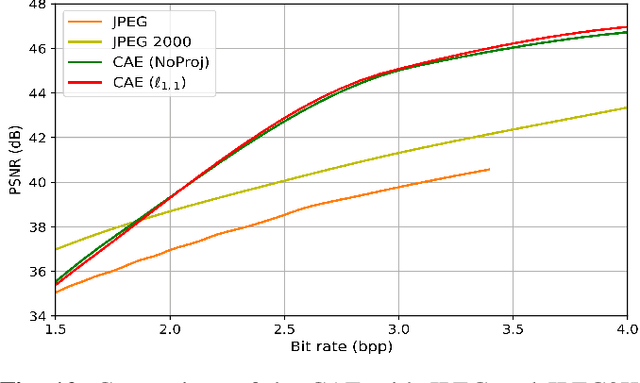
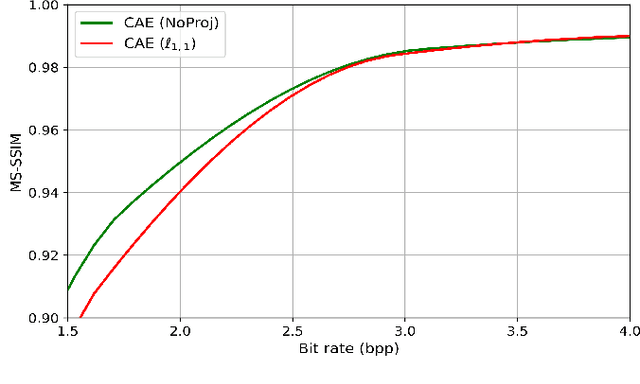

Recently, convolutional auto-encoders (CAE) were introduced for image coding. They achieved performance improvements over the state-of-the-art JPEG2000 method. However, these performances were obtained using massive CAEs featuring a large number of parameters and whose training required heavy computational power.\\ In this paper, we address the problem of lossy image compression using a CAE with a small memory footprint and low computational power usage. In order to overcome the computational cost issue, the majority of the literature uses Lagrangian proximal regularization methods, which are time consuming themselves.\\ In this work, we propose a constrained approach and a new structured sparse learning method. We design an algorithm and test it on three constraints: the classical $\ell_1$ constraint, the $\ell_{1,\infty}$ and the new $\ell_{1,1}$ constraint. Experimental results show that the $\ell_{1,1}$ constraint provides the best structured sparsity, resulting in a high reduction of memory and computational cost, with similar rate-distortion performance as with dense networks.