 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comprehensive Survey on Trustworthy Recommender Systems
Sep 21, 2022
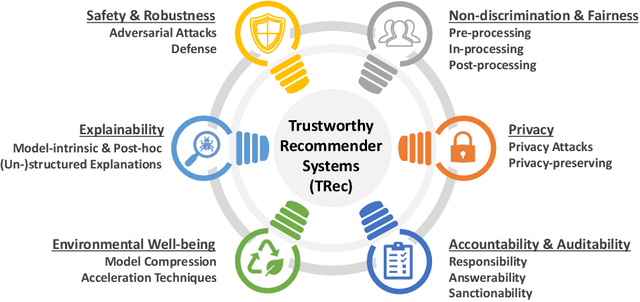
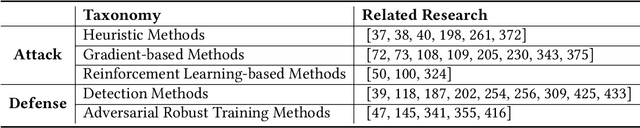

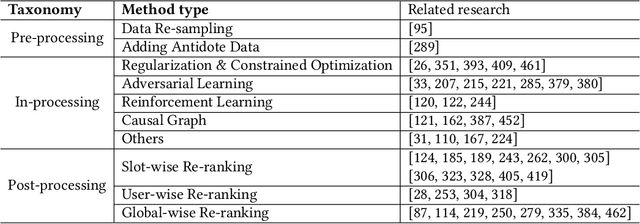
As one of the most successful AI-powered applications, recommender systems aim to help people make appropriate decisions in an effective and efficient way, by providing personalized suggestions in many aspects of our lives, especially for various human-oriented online services such as e-commerce platforms and social media sites. In the past few decades, the rapid developments of recommender systems have significantly benefited human by creating economic value, saving time and effort, and promoting social good. However, recent studies have found that data-driven recommender systems can pose serious threats to users and society, such as spreading fake news to manipulate public opinion in social media sites, amplifying unfairness toward under-represented groups or individuals in job matching services, or inferring privacy information from recommendation results. Therefore, systems' trustworthiness has been attracting increasing attention from various aspects for mitigating negative impacts caused by recommender systems, so as to enhance the public's trust towards recommender systems techniques. In this survey, we provide a comprehensive overview of Trustworthy Recommender systems (TRec) with a specific focus on six of the most important aspects; namely, Safety & Robustness, Nondiscrimination & Fairness, Explainability, Privacy, Environmental Well-being, and Accountability & Auditability. For each aspect, we summarize the recent related technologies and discuss potential research directions to help achieve trustworthy recommender systems in the future.
The Dual Form of Neural Networks Revisited: Connecting Test Time Predictions to Training Patterns via Spotlights of Attention
Feb 11, 2022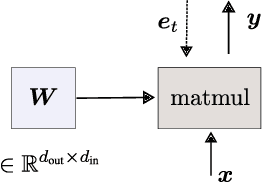
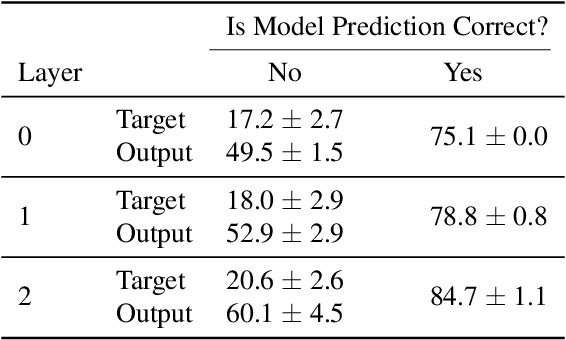
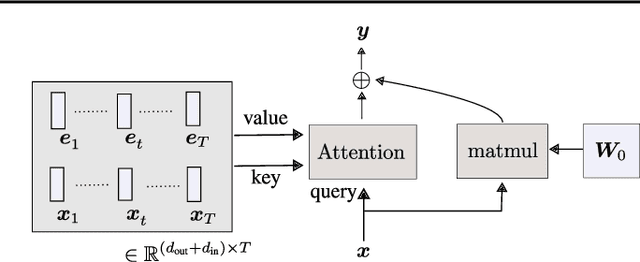

Linear layers in neural networks (NNs) trained by gradient descent can be expressed as a key-value memory system which stores all training datapoints and the initial weights, and produces outputs using unnormalised dot attention over the entire training experience. While this has been technically known since the '60s, no prior work has effectively studied the operations of NNs in such a form, presumably due to prohibitive time and space complexities and impractical model sizes, all of them growing linearly with the number of training patterns which may get very large. However, this dual formulation offers a possibility of directly visualizing how an NN makes use of training patterns at test time, by examining the corresponding attention weights. We conduct experiments on small scale supervised image classification tasks in single-task, multi-task, and continual learning settings, as well as language modelling, and discuss potentials and limits of this view for better understanding and interpreting how NNs exploit training patterns. Our code is public.
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers
Oct 26, 2021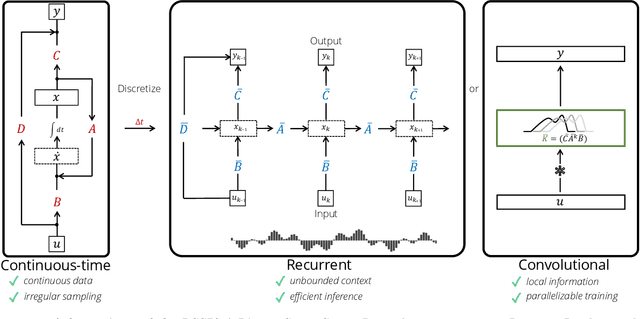
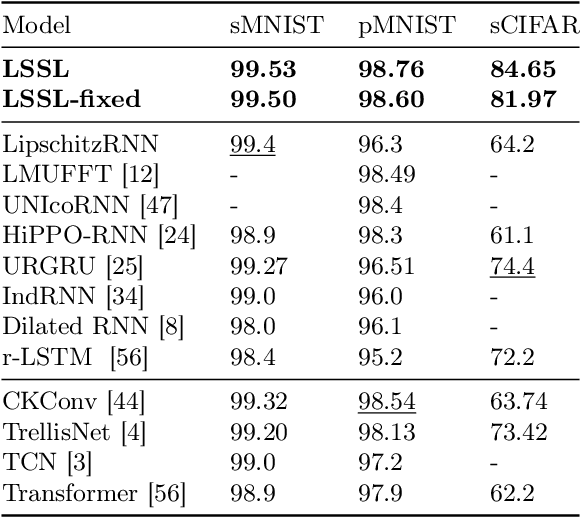
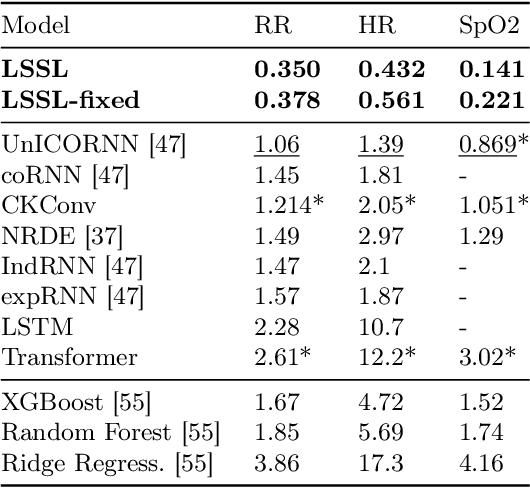
Recurrent neural networks (RNNs), temporal convolutions, and neural differential equations (NDEs) are popular families of deep learning models for time-series data, each with unique strengths and tradeoffs in modeling power and computational efficiency. We introduce a simple sequence model inspired by control systems that generalizes these approaches while addressing their shortcomings. The Linear State-Space Layer (LSSL) maps a sequence $u \mapsto y$ by simply simulating a linear continuous-time state-space representation $\dot{x} = Ax + Bu, y = Cx + Du$. Theoretically, we show that LSSL models are closely related to the three aforementioned families of models and inherit their strengths. For example, they generalize convolutions to continuous-time, explain common RNN heuristics, and share features of NDEs such as time-scale adaptation. We then incorporate and generalize recent theory on continuous-time memorization to introduce a trainable subset of structured matrices $A$ that endow LSSLs with long-range memory. Empirically, stacking LSSL layers into a simple deep neural network obtains state-of-the-art results across time series benchmarks for long dependencies in sequential image classification, real-world healthcare regression tasks, and speech. On a difficult speech classification task with length-16000 sequences, LSSL outperforms prior approaches by 24 accuracy points, and even outperforms baselines that use hand-crafted features on 100x shorter sequences.
Robin: A Novel Online Suicidal Text Corpus of Substantial Breadth and Scale
Sep 13, 2022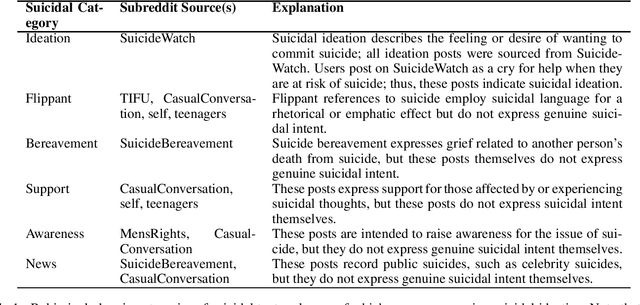
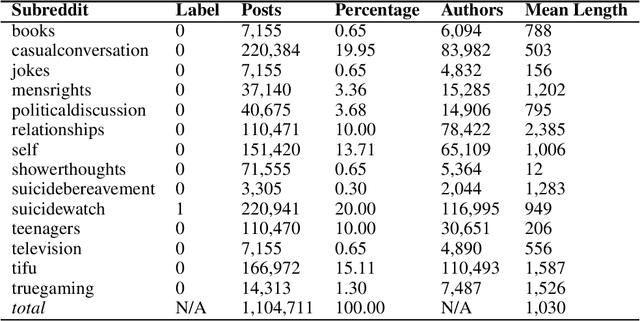
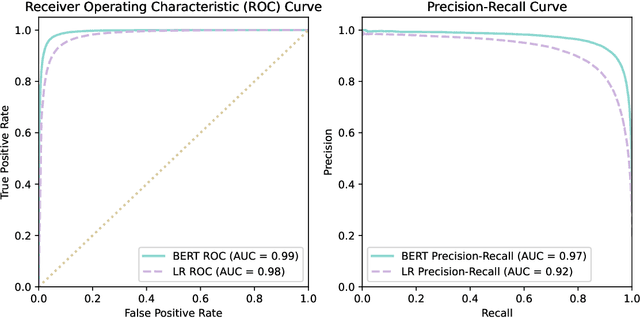
Suicide is a major public health crisis. With more than 20,000,000 suicide attempts each year, the early detection of suicidal intent has the potential to save hundreds of thousands of lives. Traditional mental health screening methods are time-consuming, costly, and often inaccessible to disadvantaged populations; online detection of suicidal intent using machine learning offers a viable alternative. Here we present Robin, the largest non-keyword generated suicidal corpus to date, consisting of over 1.1 million online forum postings. In addition to its unprecedented size, Robin is specially constructed to include various categories of suicidal text, such as suicide bereavement and flippant references, better enabling models trained on Robin to learn the subtle nuances of text expressing suicidal ideation. Experimental results achieve state-of-the-art performance for the classification of suicidal text, both with traditional methods like logistic regression (F1=0.85), as well as with large-scale pre-trained language models like BERT (F1=0.92). Finally, we release the Robin dataset publicly as a machine learning resource with the potential to drive the next generation of suicidal sentiment research.
Deep Forest with Hashing Screening and Window Screening
Jul 25, 2022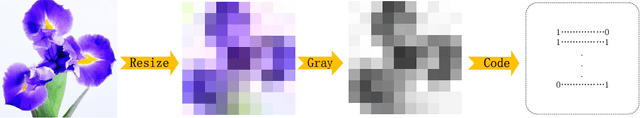
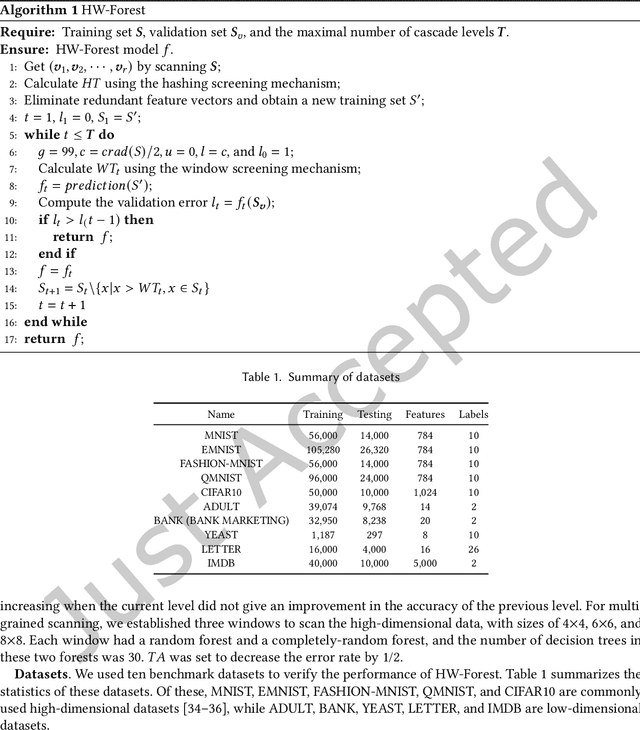
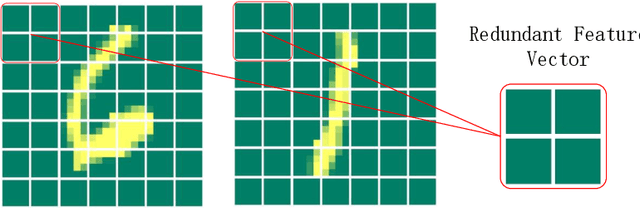
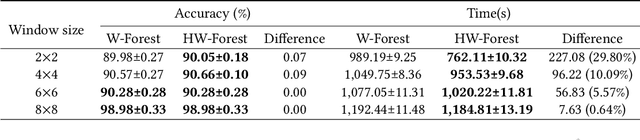
As a novel deep learning model, gcForest has been widely used in various applications. However, the current multi-grained scanning of gcForest produces many redundant feature vectors, and this increases the time cost of the model. To screen out redundant feature vectors, we introduce a hashing screening mechanism for multi-grained scanning and propose a model called HW-Forest which adopts two strategies, hashing screening and window screening. HW-Forest employs perceptual hashing algorithm to calculate the similarity between feature vectors in hashing screening strategy, which is used to remove the redundant feature vectors produced by multi-grained scanning and can significantly decrease the time cost and memory consumption. Furthermore, we adopt a self-adaptive instance screening strategy to improve the performance of our approach, called window screening, which can achieve higher accuracy without hyperparameter tuning on different datasets. Our experimental results show that HW-Forest has higher accuracy than other models, and the time cost is also reduced.
Low-cost machine learning approach to the prediction of transition metal phosphor excited state properties
Sep 18, 2022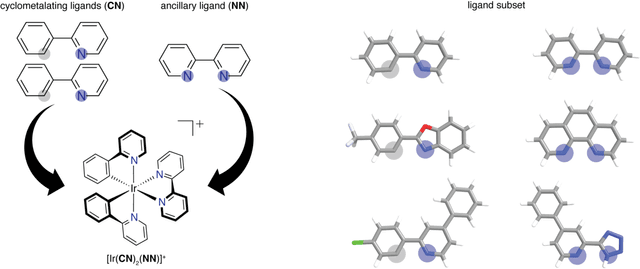
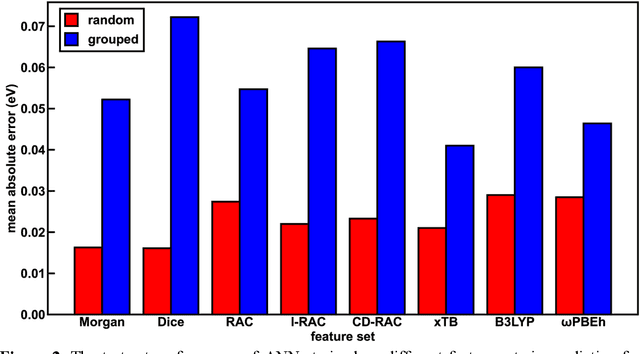
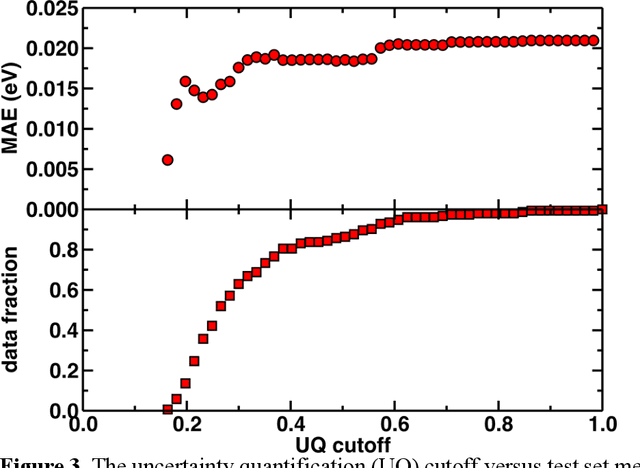
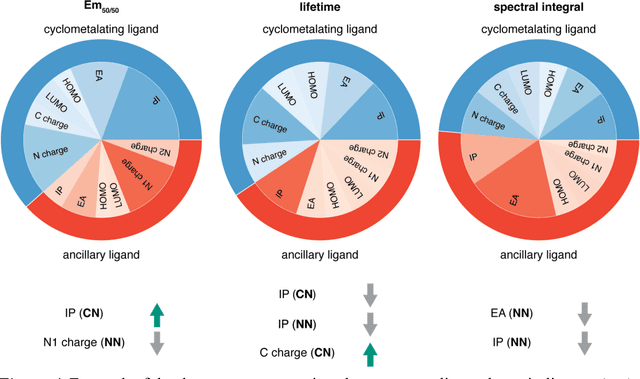
Photoactive iridium complexes are of broad interest due to their applications ranging from lighting to photocatalysis. However, the excited state property prediction of these complexes challenges ab initio methods such as time-dependent density functional theory (TDDFT) both from an accuracy and a computational cost perspective, complicating high throughput virtual screening (HTVS). We instead leverage low-cost machine learning (ML) models to predict the excited state properties of photoactive iridium complexes. We use experimental data of 1,380 iridium complexes to train and evaluate the ML models and identify the best-performing and most transferable models to be those trained on electronic structure features from low-cost density functional theory tight binding calculations. Using these models, we predict the three excited state properties considered, mean emission energy of phosphorescence, excited state lifetime, and emission spectral integral, with accuracy competitive with or superseding TDDFT. We conduct feature importance analysis to identify which iridium complex attributes govern excited state properties and we validate these trends with explicit examples. As a demonstration of how our ML models can be used for HTVS and the acceleration of chemical discovery, we curate a set of novel hypothetical iridium complexes and identify promising ligands for the design of new phosphors.
Decentralized Learning with Separable Data: Generalization and Fast Algorithms
Sep 16, 2022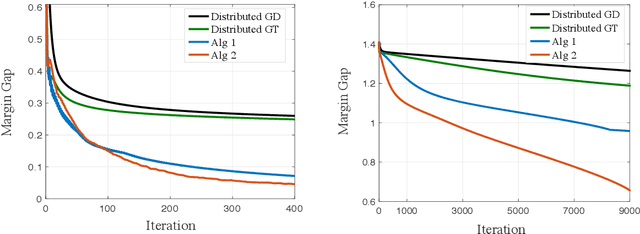
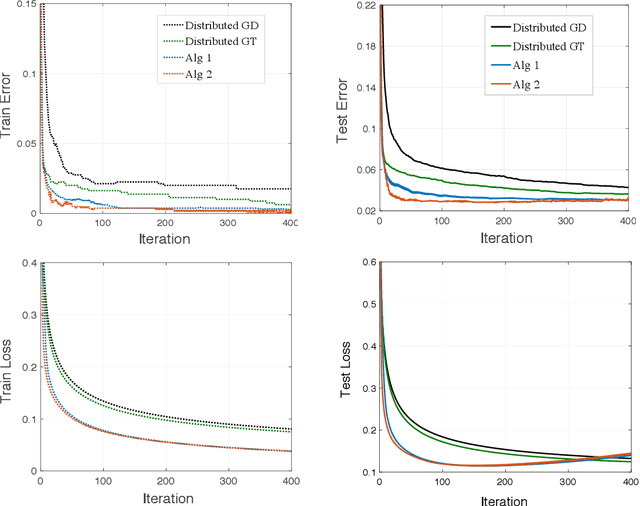
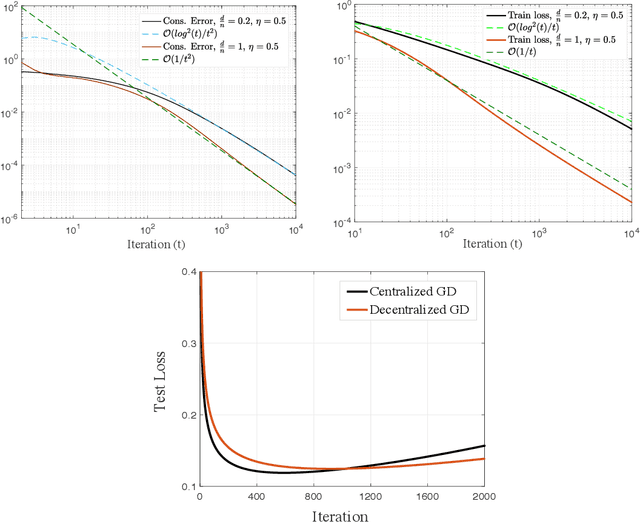
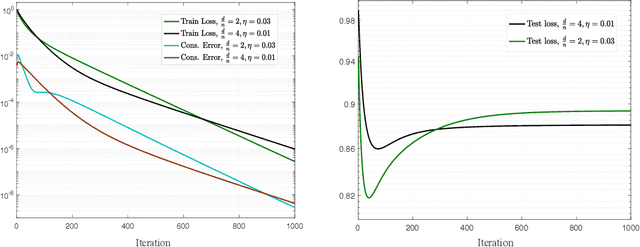
Decentralized learning offers privacy and communication efficiency when data are naturally distributed among agents communicating over an underlying graph. Motivated by overparameterized learning settings, in which models are trained to zero training loss, we study algorithmic and generalization properties of decentralized learning with gradient descent on separable data. Specifically, for decentralized gradient descent (DGD) and a variety of loss functions that asymptote to zero at infinity (including exponential and logistic losses), we derive novel finite-time generalization bounds. This complements a long line of recent work that studies the generalization performance and the implicit bias of gradient descent over separable data, but has thus far been limited to centralized learning scenarios. Notably, our generalization bounds match in order their centralized counterparts. Critical behind this, and of independent interest, is establishing novel bounds on the training loss and the rate-of-consensus of DGD for a class of self-bounded losses. Finally, on the algorithmic front, we design improved gradient-based routines for decentralized learning with separable data and empirically demonstrate orders-of-magnitude of speed-up in terms of both training and generalization performance.
Branching Time Active Inference with Bayesian Filtering
Dec 14, 2021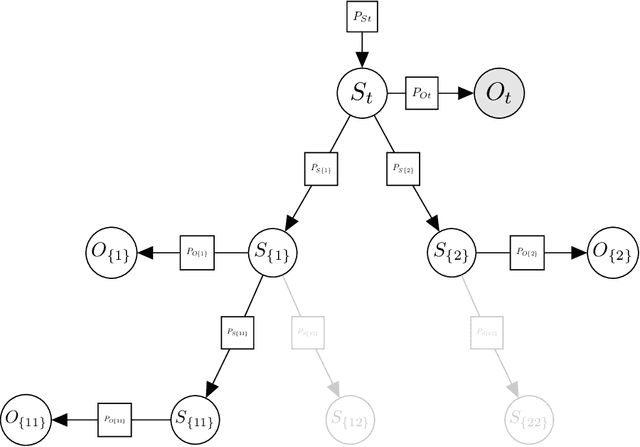
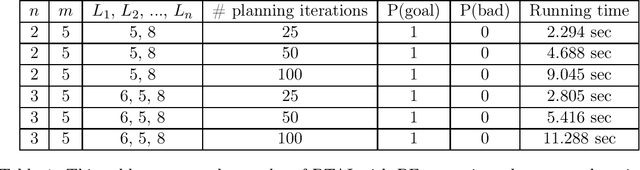
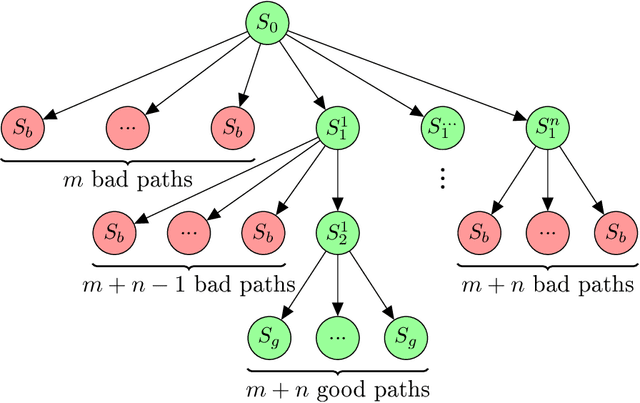
Branching Time Active Inference (Champion et al., 2021b,a) is a framework proposing to look at planning as a form of Bayesian model expansion. Its root can be found in Active Inference (Friston et al., 2016; Da Costa et al., 2020; Champion et al., 2021c), a neuroscientific framework widely used for brain modelling, as well as in Monte Carlo Tree Search (Browne et al., 2012), a method broadly applied in the Reinforcement Learning literature. Up to now, the inference of the latent variables was carried out by taking advantage of the flexibility offered by Variational Message Passing (Winn and Bishop, 2005), an iterative process that can be understood as sending messages along the edges of a factor graph (Forney, 2001). In this paper, we harness the efficiency of an alternative method for inference called Bayesian Filtering (Fox et al., 2003), which does not require the iteration of the update equations until convergence of the Variational Free Energy. Instead, this scheme alternates between two phases: integration of evidence and prediction of future states. Both of those phases can be performed efficiently and this provides a seventy times speed up over the state-of-the-art.
A Novel Deep Parallel Time-series Relation Network for Fault Diagnosis
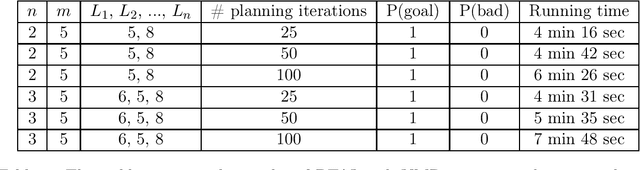
Dec 03, 2021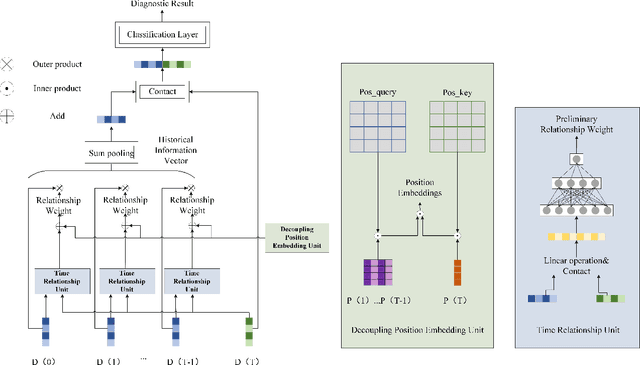

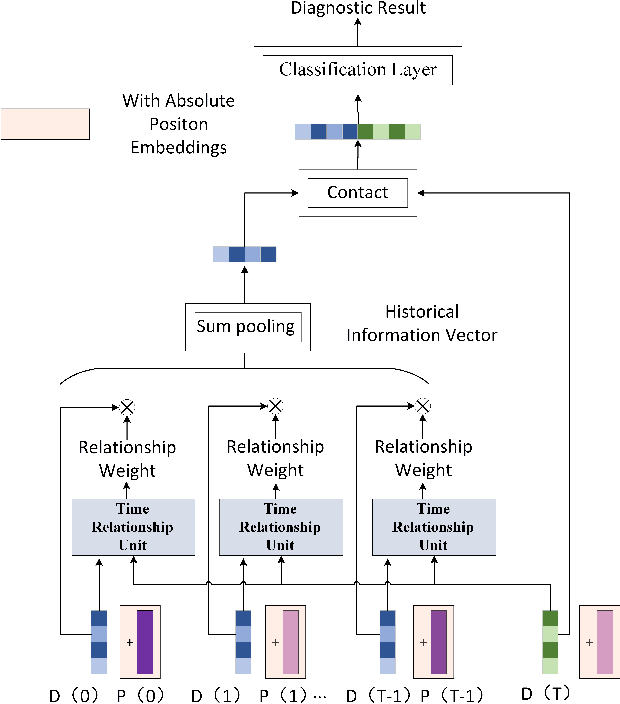

Considering the models that apply the contextual information of time-series data could improve the fault diagnosis performance, some neural network structures such as RNN, LSTM, and GRU were proposed to model the industrial process effectively. However, these models are restricted by their serial computation and hence cannot achieve high diagnostic efficiency. Also the parallel CNN is difficult to implement fault diagnosis in an efficient way because it requires larger convolution kernels or deep structure to achieve long-term feature extraction capabilities. Besides, BERT model applies absolute position embedding to introduce contextual information to the model, which would bring noise to the raw data and therefore cannot be applied to fault diagnosis directly. In order to address the above problems, a fault diagnosis model named deep parallel time-series relation network(\textit{DPTRN}) has been proposed in this paper. There are mainly three advantages for DPTRN: (1) Our proposed time relationship unit is based on full multilayer perceptron(\textit{MLP}) structure, therefore, DPTRN performs fault diagnosis in a parallel way and improves computing efficiency significantly. (2) By improving the absolute position embedding, our novel decoupling position embedding unit could be applied on the fault diagnosis directly and learn contextual information. (3) Our proposed DPTRN has obvious advantage in feature interpretability. Our model outperforms other methods on both TE and KDD-CUP99 datasets which confirms the effectiveness, efficiency and interpretability of the proposed DPTRN model.
Haptic Feedback Relocation from the Fingertips to the Wrist for Two-Finger Manipulation in Virtual Reality
Sep 15, 2022
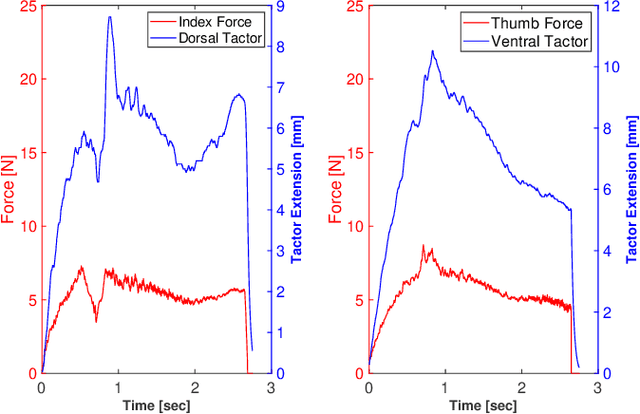
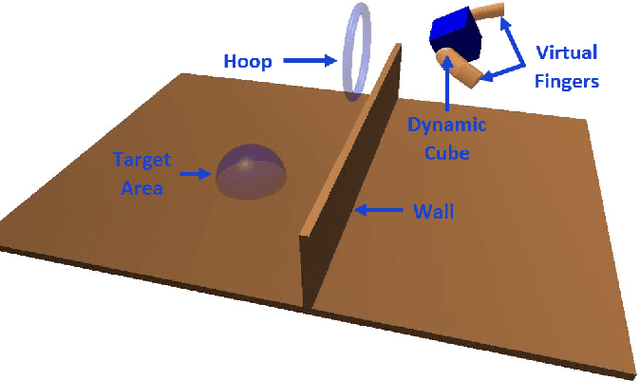
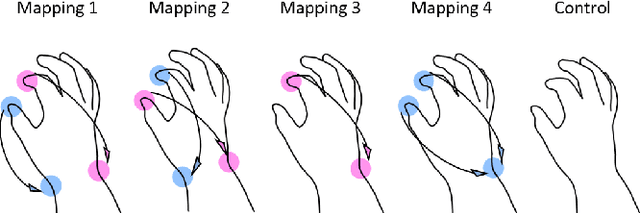
Relocation of haptic feedback from the fingertips to the wrist has been considered as a way to enable haptic interaction with mixed reality virtual environments while leaving the fingers free for other tasks. We present a pair of wrist-worn tactile haptic devices and a virtual environment to study how various mappings between fingers and tactors affect task performance. The haptic feedback rendered to the wrist reflects the interaction forces occurring between a virtual object and virtual avatars controlled by the index finger and thumb. We performed a user study comparing four different finger-to-tactor haptic feedback mappings and one no-feedback condition as a control. We evaluated users' ability to perform a simple pick-and-place task via the metrics of task completion time, path length of the fingers and virtual cube, and magnitudes of normal and shear forces at the fingertips. We found that multiple mappings were effective, and there was a greater impact when visual cues were limited. We discuss the limitations of our approach and describe next steps toward multi-degree-of-freedom haptic rendering for wrist-worn devices to improve task performance in virtual environments.