 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Traffic incident duration prediction via a deep learning framework for text description encoding
Sep 19, 2022
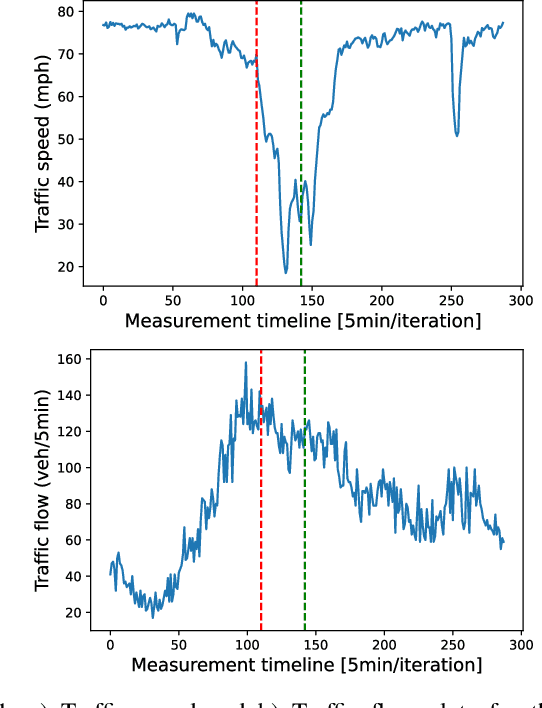
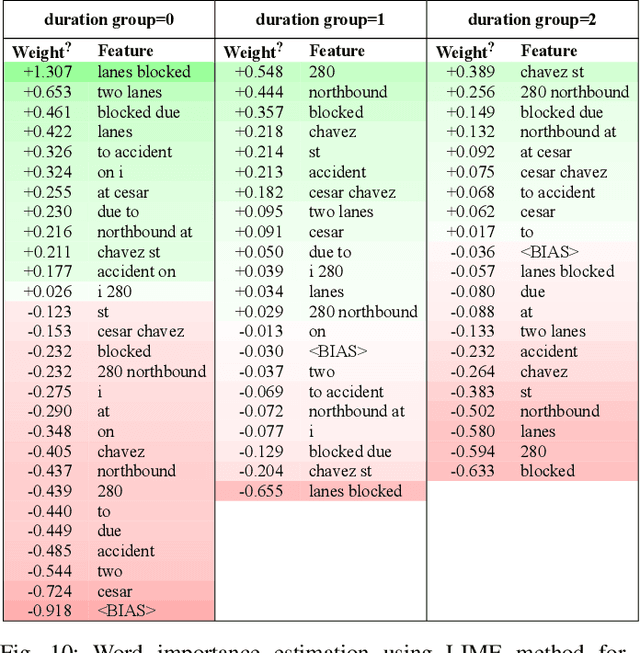
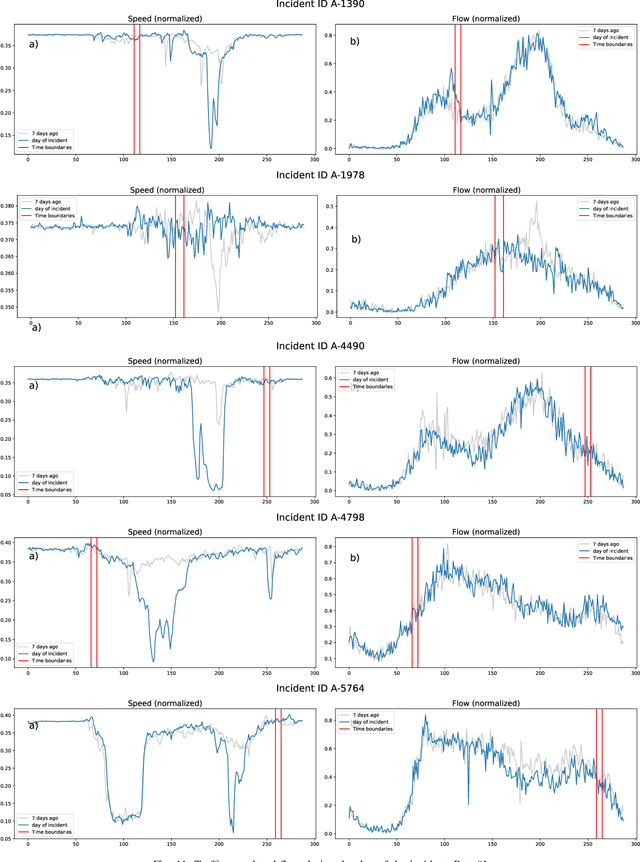
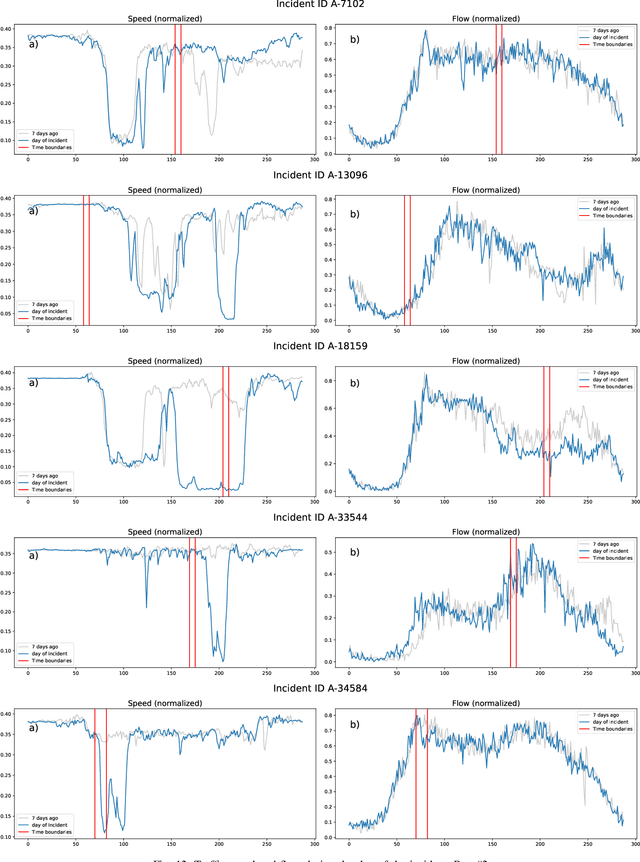
Predicting the traffic incident duration is a hard problem to solve due to the stochastic nature of incident occurrence in space and time, a lack of information at the beginning of a reported traffic disruption, and lack of advanced methods in transport engineering to derive insights from past accidents. This paper proposes a new fusion framework for predicting the incident duration from limited information by using an integration of machine learning with traffic flow/speed and incident description as features, encoded via several Deep Learning methods (ANN autoencoder and character-level LSTM-ANN sentiment classifier). The paper constructs a cross-disciplinary modelling approach in transport and data science. The approach improves the incident duration prediction accuracy over the top-performing ML models applied to baseline incident reports. Results show that our proposed method can improve the accuracy by $60\%$ when compared to standard linear or support vector regression models, and a further $7\%$ improvement with respect to the hybrid deep learning auto-encoded GBDT model which seems to outperform all other models. The application area is the city of San Francisco, rich in both traffic incident logs (Countrywide Traffic Accident Data set) and past historical traffic congestion information (5-minute precision measurements from Caltrans Performance Measurement System).
DDSP-based Singing Vocoders: A New Subtractive-based Synthesizer and A Comprehensive Evaluation
Aug 09, 2022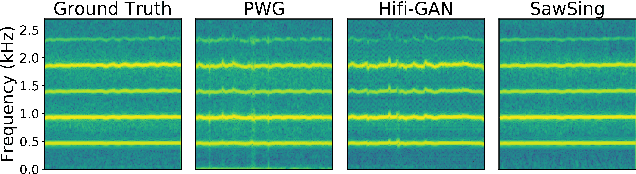
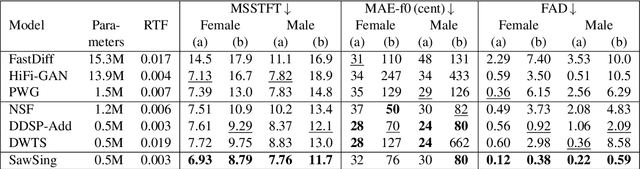
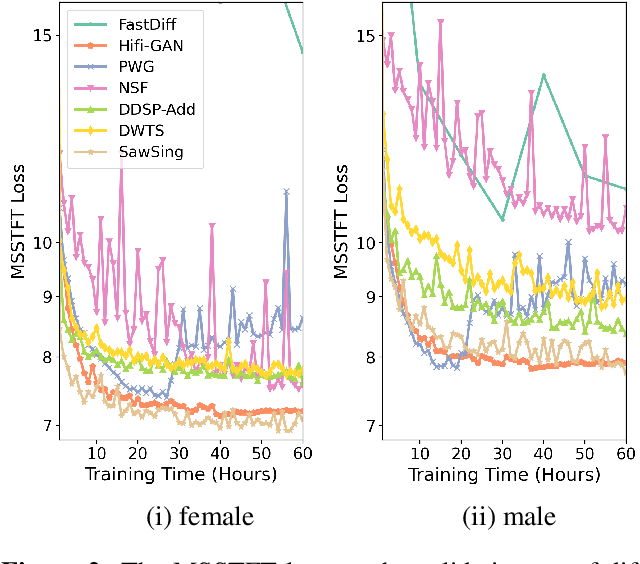
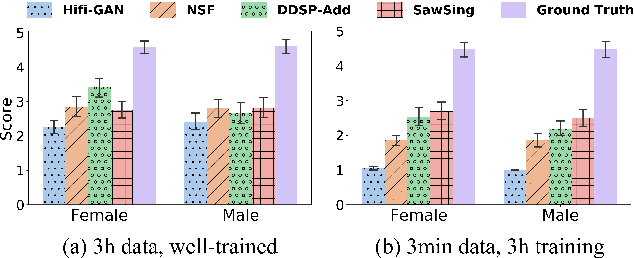
A vocoder is a conditional audio generation model that converts acoustic features such as mel-spectrograms into waveforms. Taking inspiration from Differentiable Digital Signal Processing (DDSP), we propose a new vocoder named SawSing for singing voices. SawSing synthesizes the harmonic part of singing voices by filtering a sawtooth source signal with a linear time-variant finite impulse response filter whose coefficients are estimated from the input mel-spectrogram by a neural network. As this approach enforces phase continuity, SawSing can generate singing voices without the phase-discontinuity glitch of many existing vocoders. Moreover, the source-filter assumption provides an inductive bias that allows SawSing to be trained on a small amount of data. Our experiments show that SawSing converges much faster and outperforms state-of-the-art generative adversarial network and diffusion-based vocoders in a resource-limited scenario with only 3 training recordings and a 3-hour training time.
Ensembles of Compact, Region-specific & Regularized Spiking Neural Networks for Scalable Place Recognition
Sep 19, 2022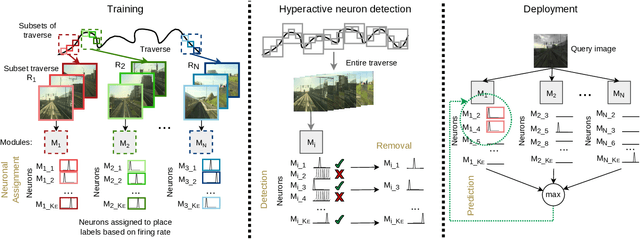
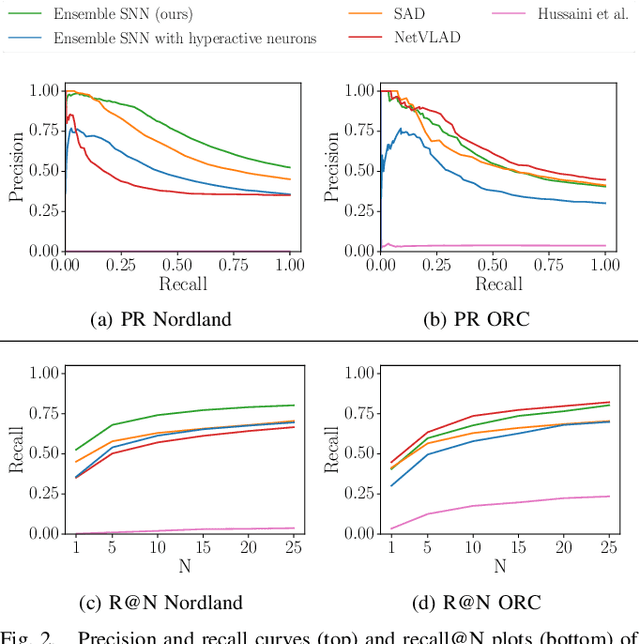
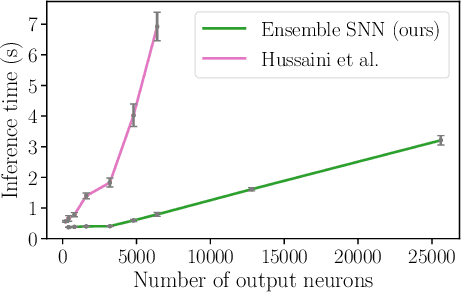
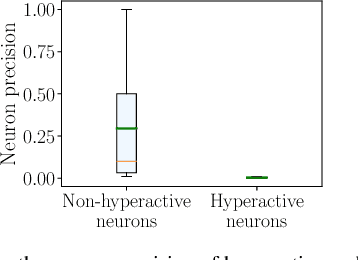
Spiking neural networks have significant potential utility in robotics due to their high energy efficiency on specialized hardware, but proof-of-concept implementations have not yet typically achieved competitive performance or capability with conventional approaches. In this paper, we tackle one of the key practical challenges of scalability by introducing a novel modular ensemble network approach, where compact, localized spiking networks each learn and are solely responsible for recognizing places in a local region of the environment only. This modular approach creates a highly scalable system. However, it comes with a high-performance cost where a lack of global regularization at deployment time leads to hyperactive neurons that erroneously respond to places outside their learned region. Our second contribution introduces a regularization approach that detects and removes these problematic hyperactive neurons during the initial environmental learning phase. We evaluate this new scalable modular system on benchmark localization datasets Nordland and Oxford RobotCar, with comparisons to both standard techniques NetVLAD and SAD, and a previous spiking neural network system. Our system substantially outperforms the previous SNN system on its small dataset, but also maintains performance on 27 times larger benchmark datasets where the operation of the previous system is computationally infeasible, and performs competitively with the conventional localization systems.
GLARE: A Dataset for Traffic Sign Detection in Sun Glare
Sep 19, 2022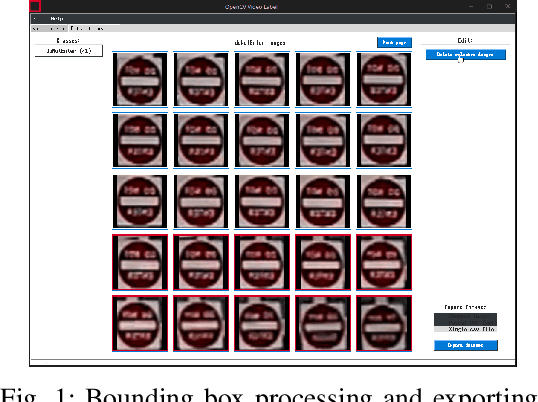
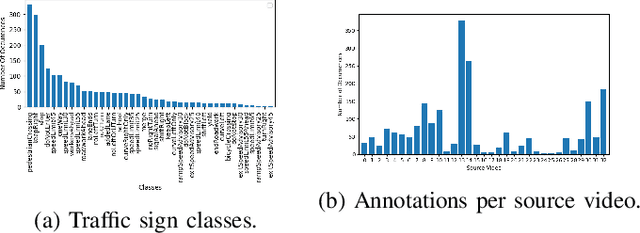

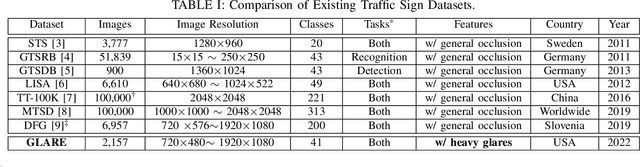
Real-time machine learning detection algorithms are often found within autonomous vehicle technology and depend on quality datasets. It is essential that these algorithms work correctly in everyday conditions as well as under strong sun glare. Reports indicate glare is one of the two most prominent environment-related reasons for crashes. However, existing datasets, such as LISA and the German Traffic Sign Recognition Benchmark, do not reflect the existence of sun glare at all. This paper presents the GLARE traffic sign dataset: a collection of images with U.S based traffic signs under heavy visual interference by sunlight. GLARE contains 2,157 images of traffic signs with sun glare, pulled from 33 videos of dashcam footage of roads in the United States. It provides an essential enrichment to the widely used LISA Traffic Sign dataset. Our experimental study shows that although several state-of-the-art baseline methods demonstrate superior performance when trained and tested against traffic sign datasets without sun glare, they greatly suffer when tested against GLARE (e.g., ranging from 9% to 21% mean mAP, which is significantly lower than the performances on LISA dataset). We also notice that current architectures have better detection accuracy (e.g., on average 42% mean mAP gain for mainstream algorithms) when trained on images of traffic signs in sun glare.
Topological Structure Learning for Weakly-Supervised Out-of-Distribution Detection
Sep 16, 2022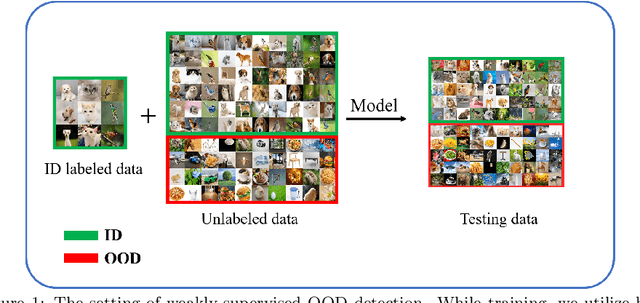
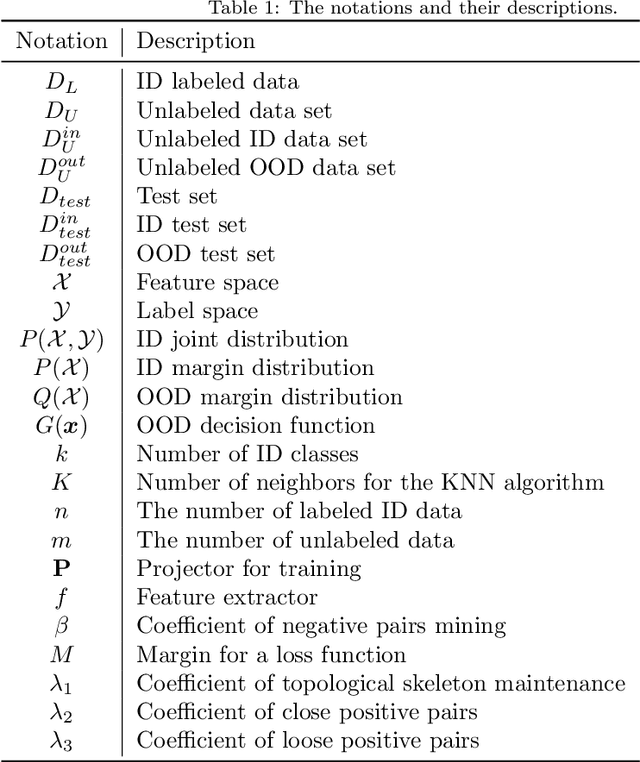
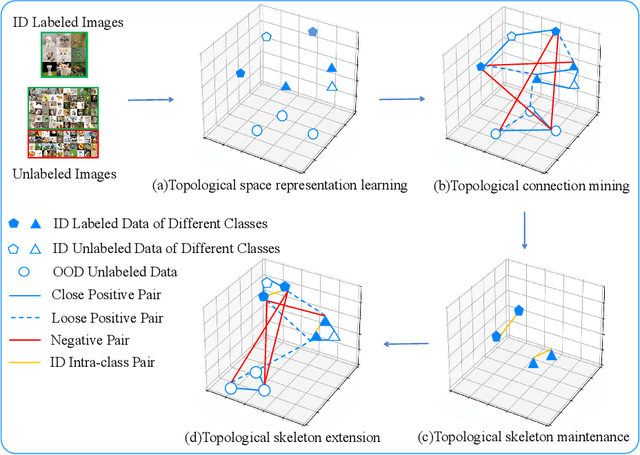
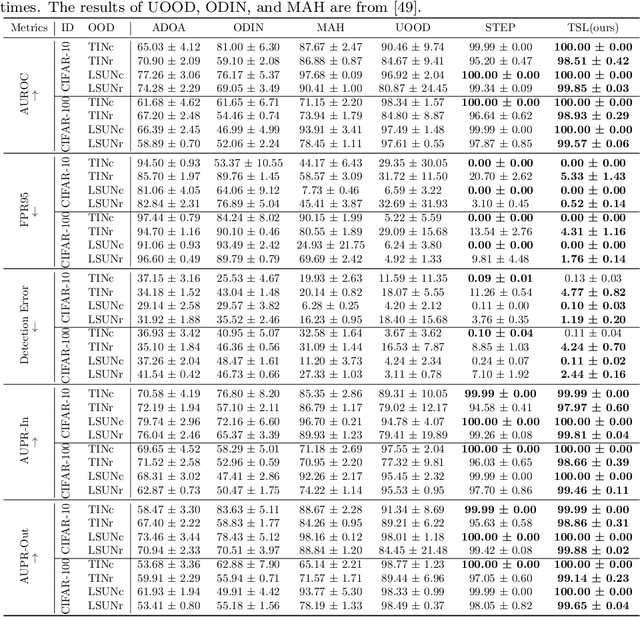
Out-of-distribution (OOD) detection is the key to deploying models safely in the open world. For OOD detection, collecting sufficient in-distribution (ID) labeled data is usually more time-consuming and costly than unlabeled data. When ID labeled data is limited, the previous OOD detection methods are no longer superior due to their high dependence on the amount of ID labeled data. Based on limited ID labeled data and sufficient unlabeled data, we define a new setting called Weakly-Supervised Out-of-Distribution Detection (WSOOD). To solve the new problem, we propose an effective method called Topological Structure Learning (TSL). Firstly, TSL uses a contrastive learning method to build the initial topological structure space for ID and OOD data. Secondly, TSL mines effective topological connections in the initial topological space. Finally, based on limited ID labeled data and mined topological connections, TSL reconstructs the topological structure in a new topological space to increase the separability of ID and OOD instances. Extensive studies on several representative datasets show that TSL remarkably outperforms the state-of-the-art, verifying the validity and robustness of our method in the new setting of WSOOD.
DisenHCN: Disentangled Hypergraph Convolutional Networks for Spatiotemporal Activity Prediction
Aug 14, 2022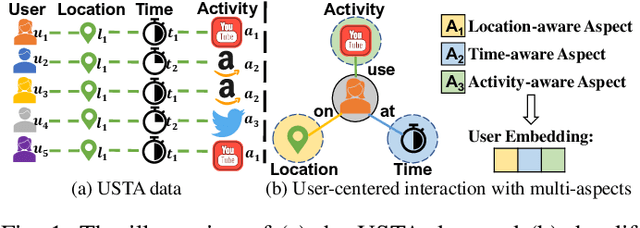
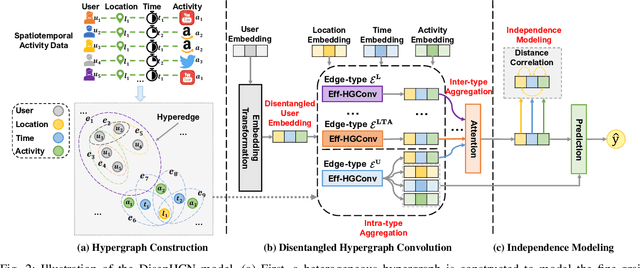
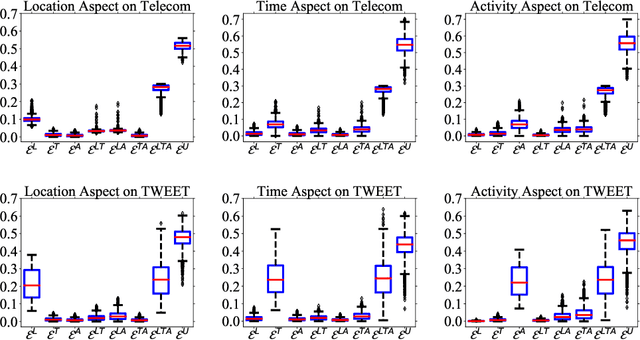
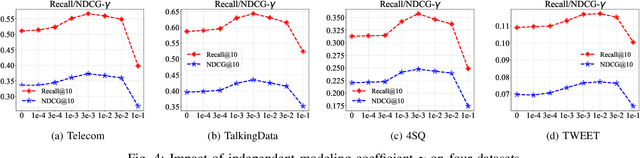
Spatiotemporal activity prediction, aiming to predict user activities at a specific location and time, is crucial for applications like urban planning and mobile advertising. Existing solutions based on tensor decomposition or graph embedding suffer from the following two major limitations: 1) ignoring the fine-grained similarities of user preferences; 2) user's modeling is entangled. In this work, we propose a hypergraph neural network model called DisenHCN to bridge the above gaps. In particular, we first unify the fine-grained user similarity and the complex matching between user preferences and spatiotemporal activity into a heterogeneous hypergraph. We then disentangle the user representations into different aspects (location-aware, time-aware, and activity-aware) and aggregate corresponding aspect's features on the constructed hypergraph, capturing high-order relations from different aspects and disentangles the impact of each aspect for final prediction. Extensive experiments show that our DisenHCN outperforms the state-of-the-art methods by 14.23% to 18.10% on four real-world datasets. Further studies also convincingly verify the rationality of each component in our DisenHCN.
A Hybrid SFANC-FxNLMS Algorithm for Active Noise Control based on Deep Learning
Aug 17, 2022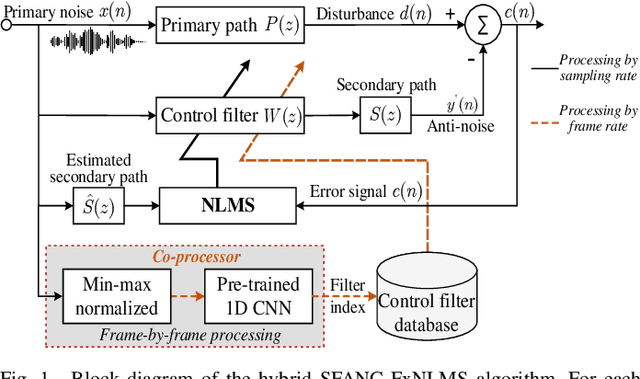
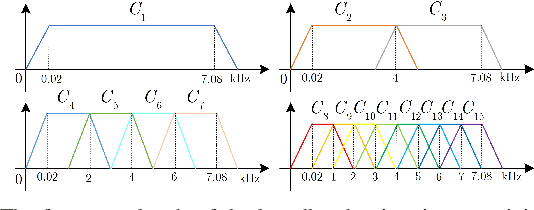
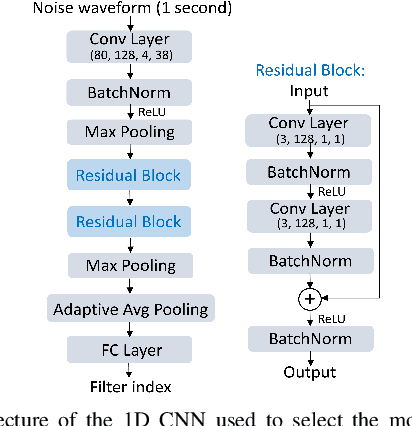
The selective fixed-filter active noise control (SFANC) method selecting the best pre-trained control filters for various types of noise can achieve a fast response time. However, it may lead to large steady-state errors due to inaccurate filter selection and the lack of adaptability. In comparison, the filtered-X normalized least-mean-square (FxNLMS) algorithm can obtain lower steady-state errors through adaptive optimization. Nonetheless, its slow convergence has a detrimental effect on dynamic noise attenuation. Therefore, this paper proposes a hybrid SFANC-FxNLMS approach to overcome the adaptive algorithm's slow convergence and provide a better noise reduction level than the SFANC method. A lightweight one-dimensional convolutional neural network (1D CNN) is designed to automatically select the most suitable pre-trained control filter for each frame of the primary noise. Meanwhile, the FxNLMS algorithm continues to update the coefficients of the chosen pre-trained control filter at the sampling rate. Owing to the effective combination of the two algorithms, experimental results show that the hybrid SFANC-FxNLMS algorithm can achieve a rapid response time, a low noise reduction error, and a high degree of robustness.
Document Image Binarization in JPEG Compressed Domain using Dual Discriminator Generative Adversarial Networks
Sep 13, 2022

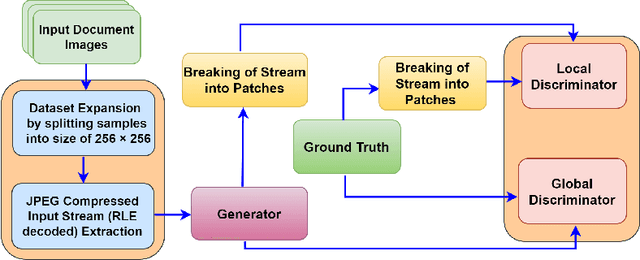

Image binarization techniques are being popularly used in enhancement of noisy and/or degraded images catering different Document Image Anlaysis (DIA) applications like word spotting, document retrieval, and OCR. Most of the existing techniques focus on feeding pixel images into the Convolution Neural Networks to accomplish document binarization, which may not produce effective results when working with compressed images that need to be processed without full decompression. Therefore in this research paper, the idea of document image binarization directly using JPEG compressed stream of document images is proposed by employing Dual Discriminator Generative Adversarial Networks (DD-GANs). Here the two discriminator networks - Global and Local work on different image ratios and use focal loss as generator loss. The proposed model has been thoroughly tested with different versions of DIBCO dataset having challenges like holes, erased or smudged ink, dust, and misplaced fibres. The model proved to be highly robust, efficient both in terms of time and space complexities, and also resulted in state-of-the-art performance in JPEG compressed domain.
Real-time Rendering for Integral Imaging Light Field Displays Based on a Voxel-Pixel Lookup Table
Jan 26, 2022A real-time elemental image array (EIA) generation method which does not sacrifice accuracy nor rely on high-performance hardware is developed, through raytracing and pre-stored voxel-pixel lookup table (LUT). Benefiting from both offline and online working flow, experiments verified the effectiveness.
CPnP: Consistent Pose Estimator for Perspective-n-Point Problem with Bias Elimination
Sep 13, 2022
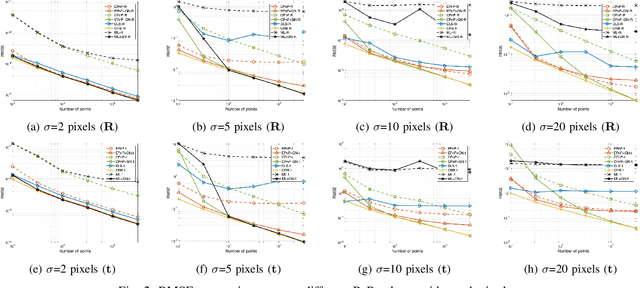

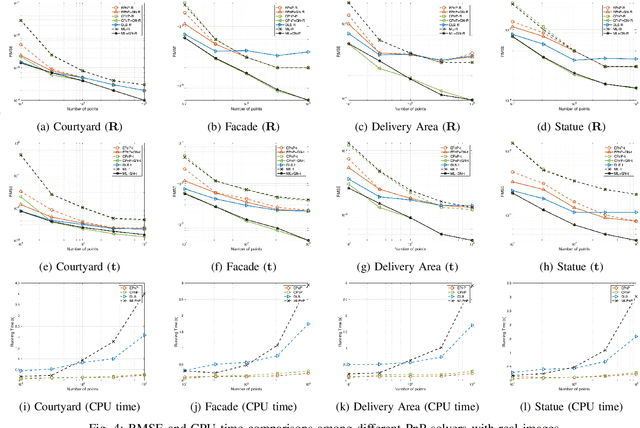
The Perspective-n-Point (PnP) problem has been widely studied in both computer vision and photogrammetry societies. With the development of feature extraction techniques, a large number of feature points might be available in a single shot. It is promising to devise a consistent estimator, i.e., the estimate can converge to the true camera pose as the number of points increases. To this end, we propose a consistent PnP solver, named \emph{CPnP}, with bias elimination. Specifically, linear equations are constructed from the original projection model via measurement model modification and variable elimination, based on which a closed-form least-squares solution is obtained. We then analyze and subtract the asymptotic bias of this solution, resulting in a consistent estimate. Additionally, Gauss-Newton (GN) iterations are executed to refine the consistent solution. Our proposed estimator is efficient in terms of computations -- it has $O(n)$ computational complexity. Experimental tests on both synthetic data and real images show that our proposed estimator is superior to some well-known ones for images with dense visual features, in terms of estimation precision and computing time.