 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UNav: An Infrastructure-Independent Vision-Based Navigation System for People with Blindness and Low vision
Sep 22, 2022
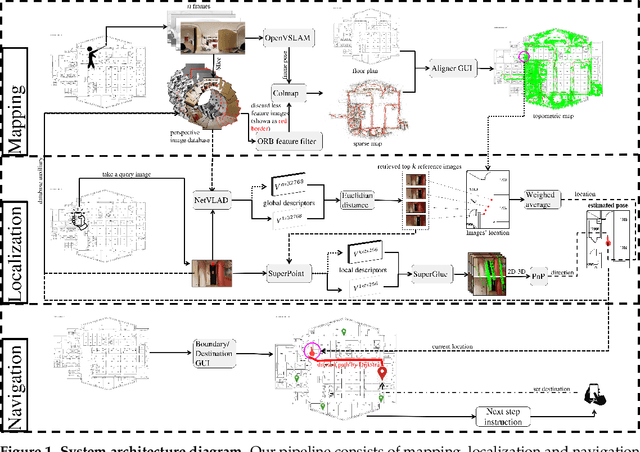

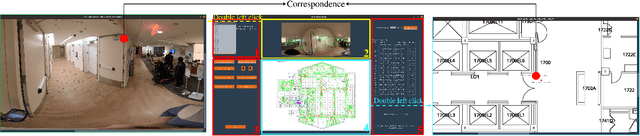
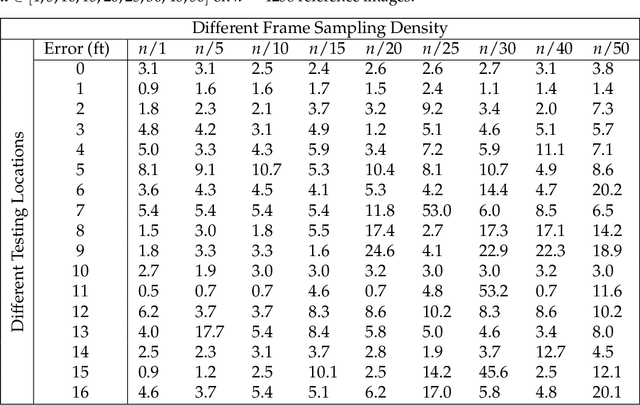
Vision-based localization approaches now underpin newly emerging navigation pipelines for myriad use cases from robotics to assistive technologies. Compared to sensor-based solutions, vision-based localization does not require pre-installed sensor infrastructure, which is costly, time-consuming, and/or often infeasible at scale. Herein, we propose a novel vision-based localization pipeline for a specific use case: navigation support for end-users with blindness and low vision. Given a query image taken by an end-user on a mobile application, the pipeline leverages a visual place recognition (VPR) algorithm to find similar images in a reference image database of the target space. The geolocations of these similar images are utilized in downstream tasks that employ a weighted-average method to estimate the end-user's location and a perspective-n-point (PnP) algorithm to estimate the end-user's direction. Additionally, this system implements Dijkstra's algorithm to calculate a shortest path based on a navigable map that includes trip origin and destination. The topometric map used for localization and navigation is built using a customized graphical user interface that projects a 3D reconstructed sparse map, built from a sequence of images, to the corresponding a priori 2D floor plan. Sequential images used for map construction can be collected in a pre-mapping step or scavenged through public databases/citizen science. The end-to-end system can be installed on any internet-accessible device with a camera that hosts a custom mobile application. For evaluation purposes, mapping and localization were tested in a complex hospital environment. The evaluation results demonstrate that our system can achieve localization with an average error of less than 1 meter without knowledge of the camera's intrinsic parameters, such as focal length.
Overlapped speech and gender detection with WavLM pre-trained features
Sep 09, 2022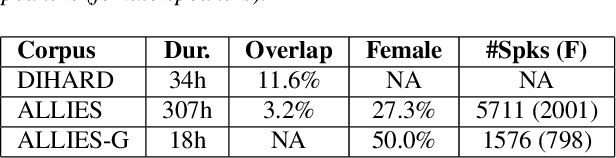
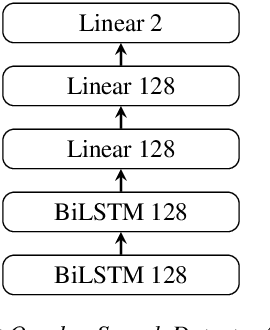
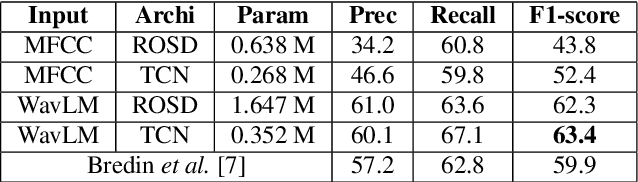
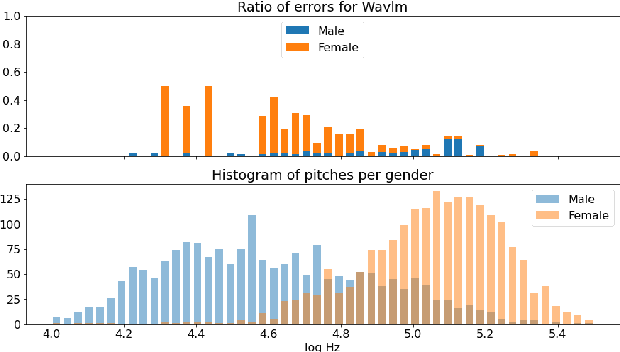
This article focuses on overlapped speech and gender detection in order to study interactions between women and men in French audiovisual media (Gender Equality Monitoring project). In this application context, we need to automatically segment the speech signal according to speakers gender, and to identify when at least two speakers speak at the same time. We propose to use WavLM model which has the advantage of being pre-trained on a huge amount of speech data, to build an overlapped speech detection (OSD) and a gender detection (GD) systems. In this study, we use two different corpora. The DIHARD III corpus which is well adapted for the OSD task but lack gender information. The ALLIES corpus fits with the project application context. Our best OSD system is a Temporal Convolutional Network (TCN) with WavLM pre-trained features as input, which reaches a new state-of-the-art F1-score performance on DIHARD. A neural GD is trained with WavLM inputs on a gender balanced subset of the French broadcast news ALLIES data, and obtains an accuracy of 97.9%. This work opens new perspectives for human science researchers regarding the differences of representation between women and men in French media.
Motion Robust High-Speed Light-weighted Object Detection with Event Camera
Aug 24, 2022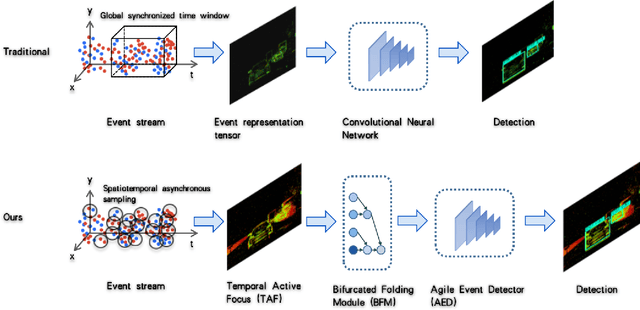
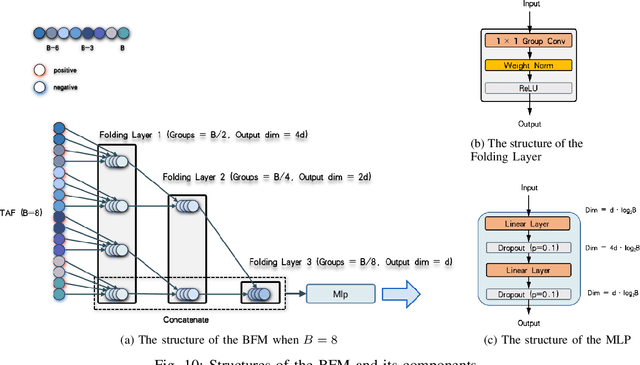
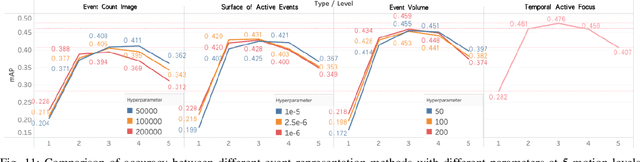
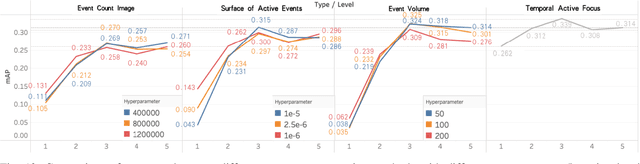
The event camera produces a large dynamic range event stream with a very high temporal resolution discarding redundant visual information, thus bringing new possibilities for object detection tasks. However, the existing methods of applying the event camera to object detection tasks using deep learning methods still have many problems. First, existing methods cannot take into account objects with different velocities relative to the motion of the event camera due to the global synchronized time window and temporal resolution. Second, most of the existing methods rely on large parameter neural networks, which implies a large computational burden and low inference speed, thus contrary to the high temporal resolution of the event stream. In our work, we design a high-speed lightweight detector called Agile Event Detector (AED) with a simple but effective data augmentation method. Also, we propose an event stream representation tensor called Temporal Active Focus (TAF), which takes full advantage of the asynchronous generation of event stream data and is robust to the motion of moving objects. It can also be constructed without much time-consuming. We further propose a module called the Bifurcated Folding Module (BFM) to extract the rich temporal information in the TAF tensor at the input layer of the AED detector. We conduct our experiments on two typical real-scene event camera object detection datasets: the complete Prophesee GEN1 Automotive Detection Dataset and the Prophesee 1 MEGAPIXEL Automotive Detection Dataset with partial annotation. Experiments show that our method is competitive in terms of accuracy, speed, and the number of parameters simultaneously. Also by classifying the objects into multiple motion levels based on the optical flow density metric, we illustrated the robustness of our method for objects with different velocities relative to the camera.
Tree-based Subgroup Discovery In Electronic Health Records: Heterogeneity of Treatment Effects for DTG-containing Therapies
Aug 30, 2022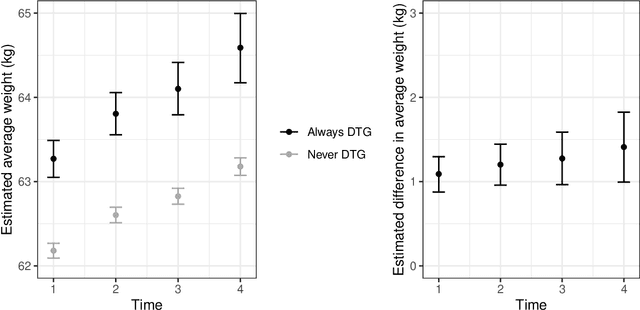

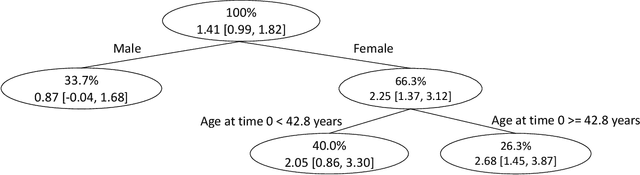

The rich longitudinal individual level data available from electronic health records (EHRs) can be used to examine treatment effect heterogeneity. However, estimating treatment effects using EHR data poses several challenges, including time-varying confounding, repeated and temporally non-aligned measurements of covariates, treatment assignments and outcomes, and loss-to-follow-up due to dropout. Here, we develop the Subgroup Discovery for Longitudinal Data (SDLD) algorithm, a tree-based algorithm for discovering subgroups with heterogeneous treatment effects using longitudinal data by combining the generalized interaction tree algorithm, a general data-driven method for subgroup discovery, with longitudinal targeted maximum likelihood estimation. We apply the algorithm to EHR data to discover subgroups of people living with human immunodeficiency virus (HIV) who are at higher risk of weight gain when receiving dolutegravir-containing antiretroviral therapies (ARTs) versus when receiving non dolutegravir-containing ARTs.
Learning Bilinear Models of Actuated Koopman Generators from Partially-Observed Trajectories
Sep 20, 2022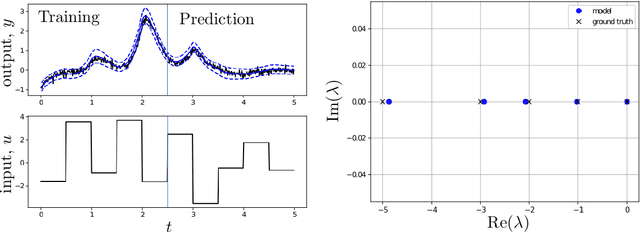
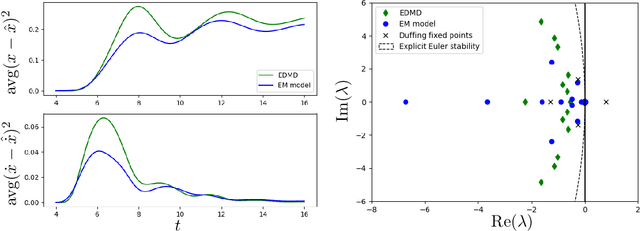
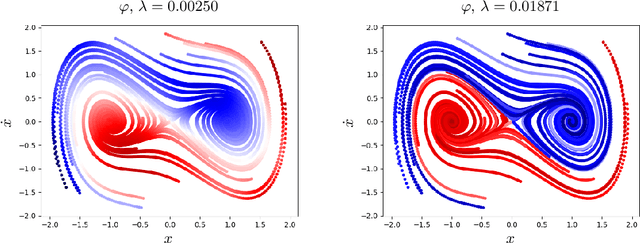
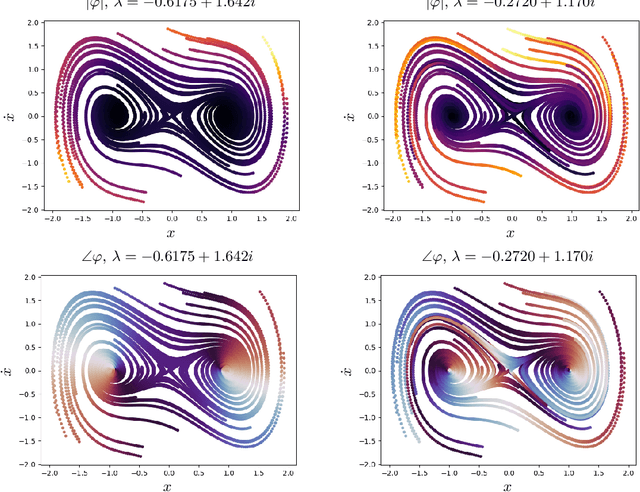
Data-driven models for nonlinear dynamical systems based on approximating the underlying Koopman operator or generator have proven to be successful tools for forecasting, feature learning, state estimation, and control. It has become well known that the Koopman generators for control-affine systems also have affine dependence on the input, leading to convenient finite-dimensional bilinear approximations of the dynamics. Yet there are still two main obstacles that limit the scope of current approaches for approximating the Koopman generators of systems with actuation. First, the performance of existing methods depends heavily on the choice of basis functions over which the Koopman generator is to be approximated; and there is currently no universal way to choose them for systems that are not measure preserving. Secondly, if we do not observe the full state, we may not gain access to a sufficiently rich collection of such functions to describe the dynamics. This is because the commonly used method of forming time-delayed observables fails when there is actuation. To remedy these issues, we write the dynamics of observables governed by the Koopman generator as a bilinear hidden Markov model, and determine the model parameters using the expectation-maximization (EM) algorithm. The E-step involves a standard Kalman filter and smoother, while the M-step resembles control-affine dynamic mode decomposition for the generator. We demonstrate the performance of this method on three examples, including recovery of a finite-dimensional Koopman-invariant subspace for an actuated system with a slow manifold; estimation of Koopman eigenfunctions for the unforced Duffing equation; and model-predictive control of a fluidic pinball system based only on noisy observations of lift and drag.
Good Time to Ask: A Learning Framework for Asking for Help in Embodied Visual Navigation
Jun 20, 2022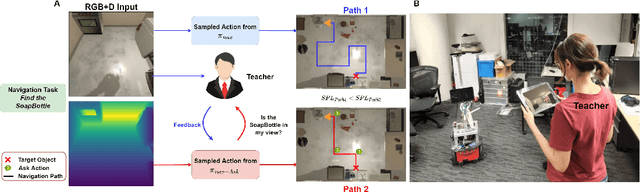
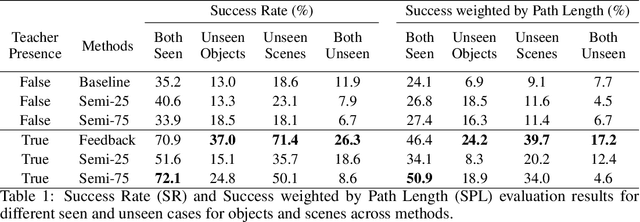
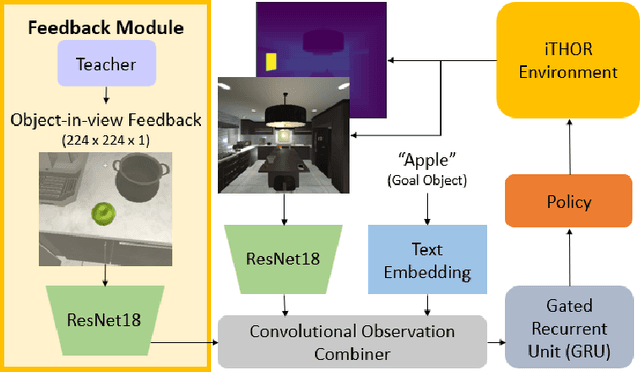
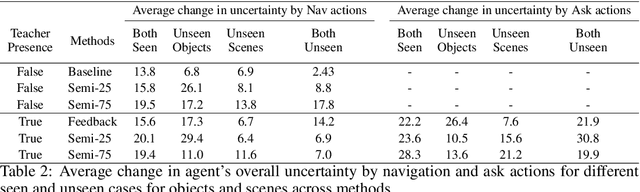
In reality, it is often more efficient to ask for help than to search the entire space to find an object with an unknown location. We present a learning framework that enables an agent to actively ask for help in such embodied visual navigation tasks, where the feedback informs the agent of where the goal is in its view. To emulate the real-world scenario that a teacher may not always be present, we propose a training curriculum where feedback is not always available. We formulate an uncertainty measure of where the goal is and use empirical results to show that through this approach, the agent learns to ask for help effectively while remaining robust when feedback is not available.
A Hybrid Deep Learning Model-based Remaining Useful Life Estimation for Reed Relay with Degradation Pattern Clustering
Sep 14, 2022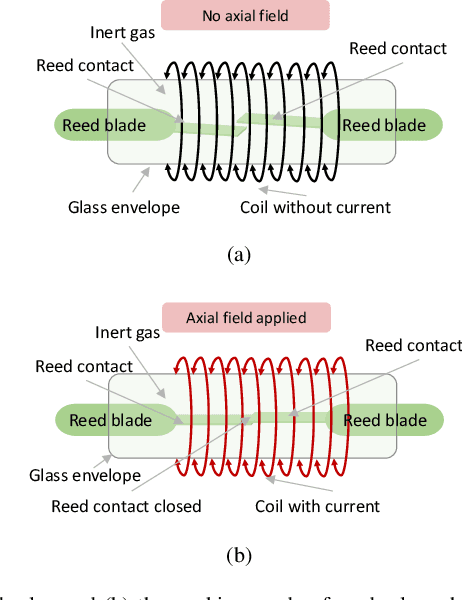
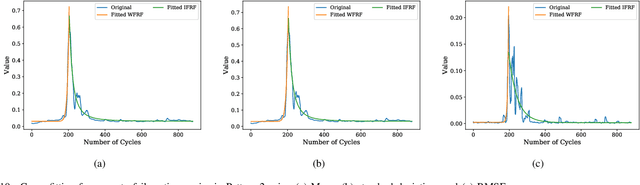
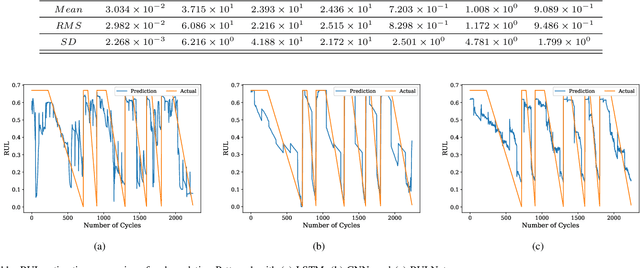
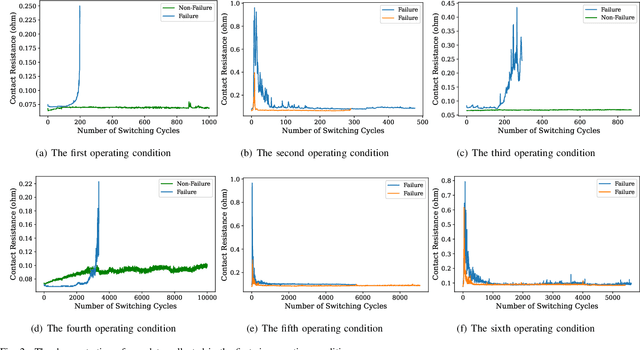
Reed relay serves as the fundamental component of functional testing, which closely relates to the successful quality inspection of electronics. To provide accurate remaining useful life (RUL) estimation for reed relay, a hybrid deep learning network with degradation pattern clustering is proposed based on the following three considerations. First, multiple degradation behaviors are observed for reed relay, and hence a dynamic time wrapping-based $K$-means clustering is offered to distinguish degradation patterns from each other. Second, although proper selections of features are of great significance, few studies are available to guide the selection. The proposed method recommends operational rules for easy implementation purposes. Third, a neural network for remaining useful life estimation (RULNet) is proposed to address the weakness of the convolutional neural network (CNN) in capturing temporal information of sequential data, which incorporates temporal correlation ability after high-level feature representation of convolutional operation. In this way, three variants of RULNet are constructed with health indicators, features with self-organizing map, or features with curve fitting. Ultimately, the proposed hybrid model is compared with the typical baseline models, including CNN and long short-term memory network (LSTM), through a practical reed relay dataset with two distinct degradation manners. The results from both degradation cases demonstrate that the proposed method outperforms CNN and LSTM regarding the index root mean squared error.
Multi Robot Collision Avoidance by Learning Whom to Communicate
Sep 14, 2022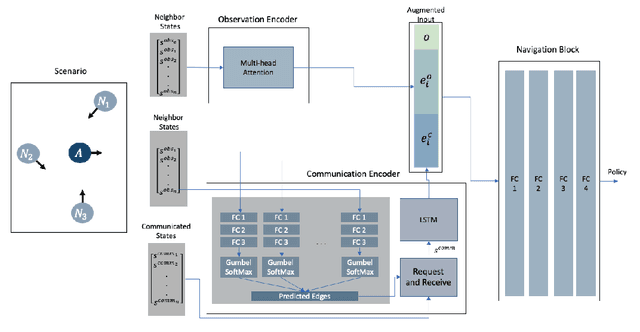
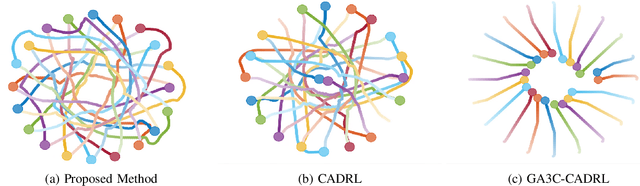


Agents in decentralized multi-agent navigation lack the world knowledge to make safe and (near-)optimal plans reliably. They base their decisions on their neighbors' observable states, which hide the neighbors' navigation intent. We propose augmenting decentralized navigation with inter-agent communication to improve their performance and aid agent in making sound navigation decisions. In this regard, we present a novel reinforcement learning method for multi-agent collision avoidance using selective inter-agent communication. Our network learns to decide 'when' and with 'whom' to communicate to request additional information in an end-to-end fashion. We pose communication selection as a link prediction problem, where the network predicts if communication is necessary given the observable information. The communicated information augments the observed neighbor information to select a suitable navigation plan. As the number of neighbors for a robot varies, we use a multi-head self-attention mechanism to encode neighbor information and create a fixed-length observation vector. We validate that our proposed approach achieves safe and efficient navigation among multiple robots in challenging simulation benchmarks. Aided by learned communication, our network performs significantly better than existing decentralized methods across various metrics such as time-to-goal and collision frequency. Besides, we showcase that the network effectively learns to communicate when necessary in a situation of high complexity.
Monash Time Series Forecasting Archive
May 14, 2021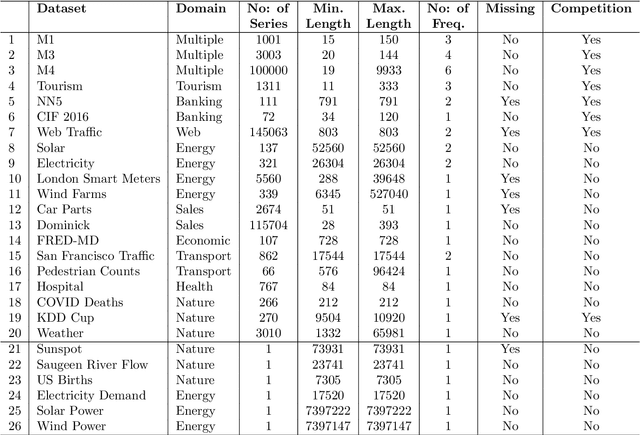
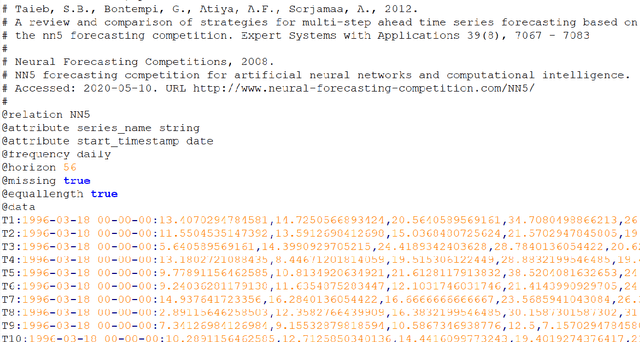


Many businesses and industries nowadays rely on large quantities of time series data making time series forecasting an important research area. Global forecasting models that are trained across sets of time series have shown a huge potential in providing accurate forecasts compared with the traditional univariate forecasting models that work on isolated series. However, there are currently no comprehensive time series archives for forecasting that contain datasets of time series from similar sources available for the research community to evaluate the performance of new global forecasting algorithms over a wide variety of datasets. In this paper, we present such a comprehensive time series forecasting archive containing 20 publicly available time series datasets from varied domains, with different characteristics in terms of frequency, series lengths, and inclusion of missing values. We also characterise the datasets, and identify similarities and differences among them, by conducting a feature analysis. Furthermore, we present the performance of a set of standard baseline forecasting methods over all datasets across eight error metrics, for the benefit of researchers using the archive to benchmark their forecasting algorithms.
PIETS: Parallelised Irregularity Encoders for Forecasting with Heterogeneous Time-Series
Oct 06, 2021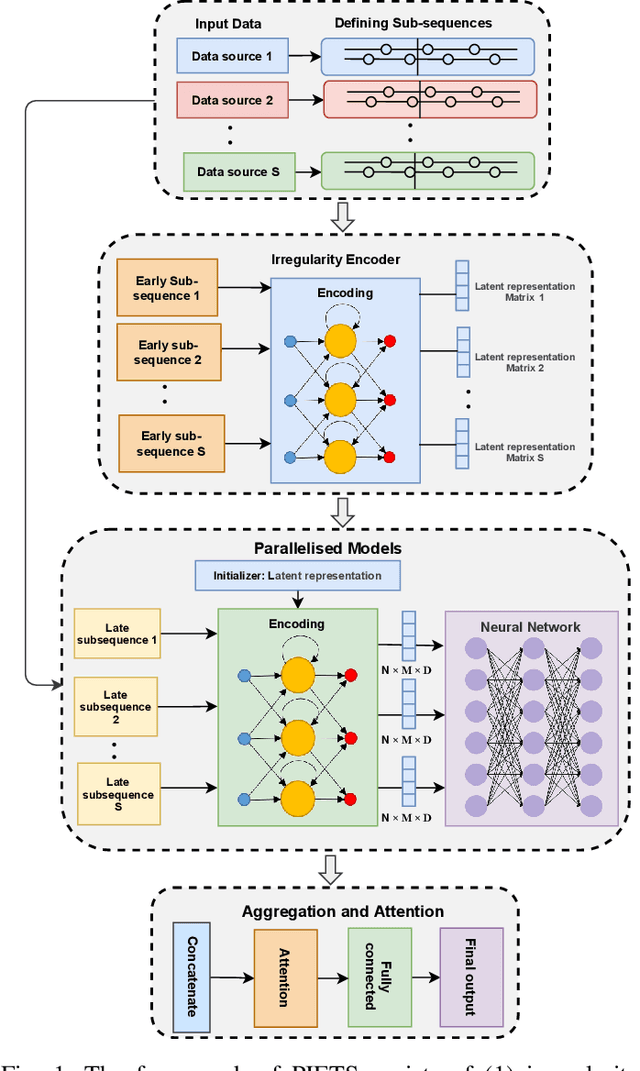
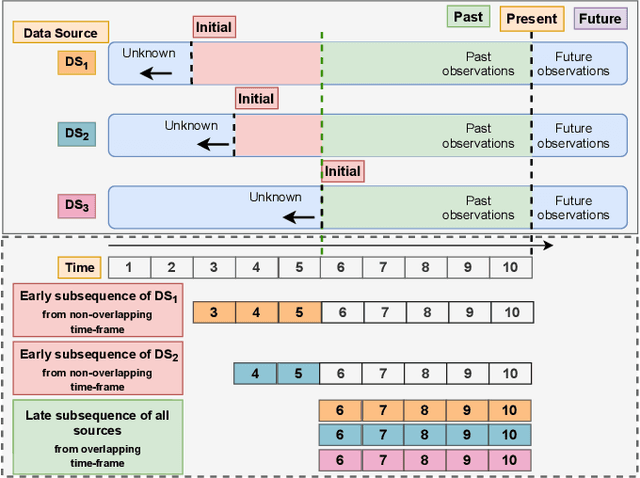
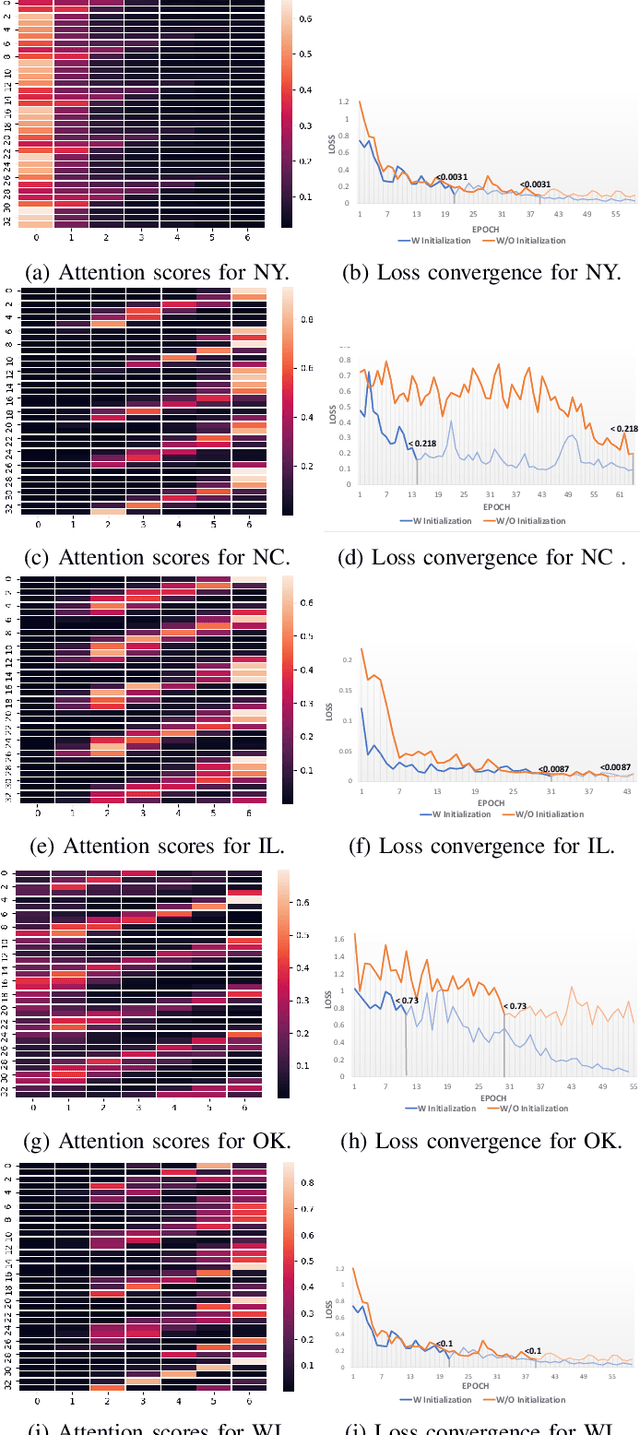
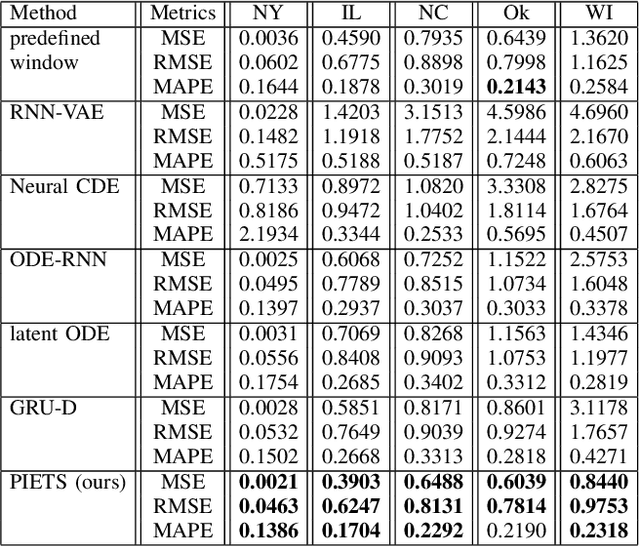
Heterogeneity and irregularity of multi-source data sets present a significant challenge to time-series analysis. In the literature, the fusion of multi-source time-series has been achieved either by using ensemble learning models which ignore temporal patterns and correlation within features or by defining a fixed-size window to select specific parts of the data sets. On the other hand, many studies have shown major improvement to handle the irregularity of time-series, yet none of these studies has been applied to multi-source data. In this work, we design a novel architecture, PIETS, to model heterogeneous time-series. PIETS has the following characteristics: (1) irregularity encoders for multi-source samples that can leverage all available information and accelerate the convergence of the model; (2) parallelised neural networks to enable flexibility and avoid information overwhelming; and (3) attention mechanism that highlights different information and gives high importance to the most related data. Through extensive experiments on real-world data sets related to COVID-19, we show that the proposed architecture is able to effectively model heterogeneous temporal data and outperforms other state-of-the-art approaches in the prediction task.