 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic optical path provisioning for alien access links: architecture, demonstration, and challenges
Sep 12, 2022
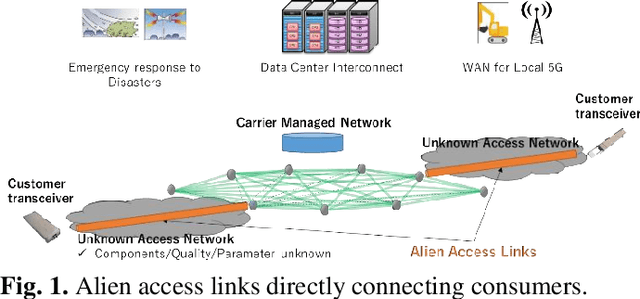
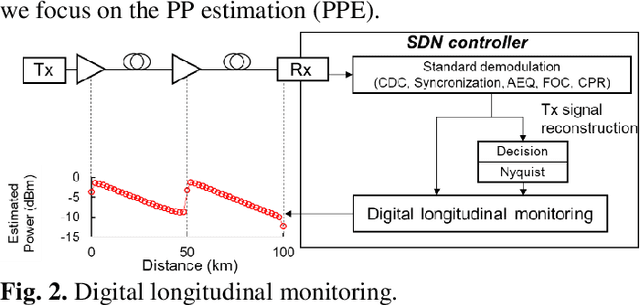
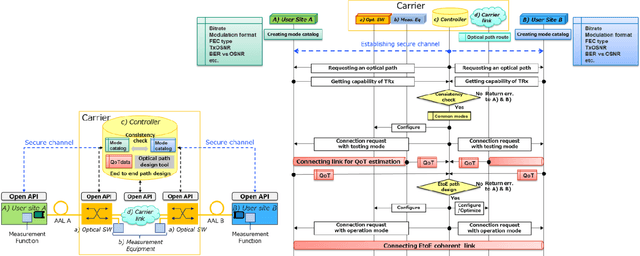
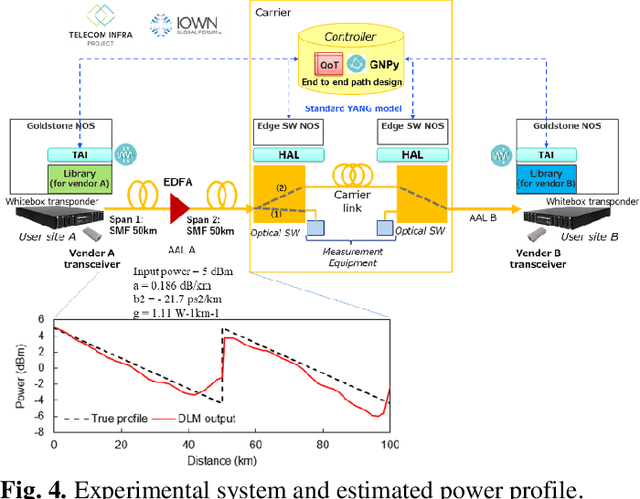
With the spread of Data Center Interconnect (DCI) and local 5G, there is a growing need for dynamically established connections between customer locations through high-capacity optical links. However, link parameters such as signal power profile and amplifier gains are often unknown and have to be measured by experts, preventing dynamic path provisioning due to the time-consuming manual measurements. Although several techniques for estimating the unknown parameters of such alien access links have been proposed, no work has presented architecture and protocol that drive the estimation techniques to establish an optical path between the customer locations. Our study aims to automatically connect customer-owned transceivers via alien access links with optimal quality of transmission (QoT). We first propose an architecture and protocol for cooperative optical path design between a customer and carrier, utilizing a state-of-the-art technique for estimating link parameters. We then implement the proposed protocol in a software-defined network (SDN) controller and white-box transponders using an open API. The experiments demonstrate that the optical path is dynamically established via alien access links in 137 seconds from the transceiver's cold start. Lastly, we discuss the QoT accuracy obtained with this method and the remaining issues.
Generating Negative Samples for Sequential Recommendation
Aug 07, 2022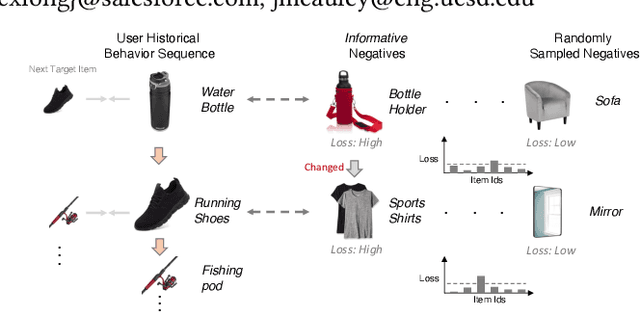
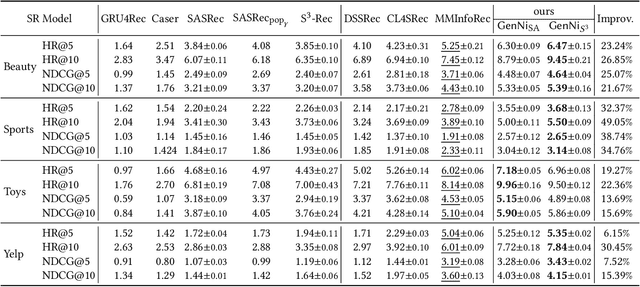
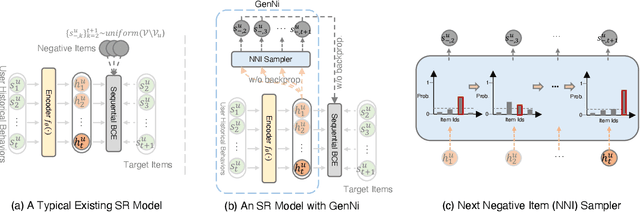
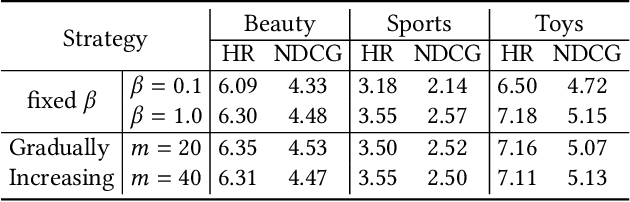
To make Sequential Recommendation (SR) successful, recent works focus on designing effective sequential encoders, fusing side information, and mining extra positive self-supervision signals. The strategy of sampling negative items at each time step is less explored. Due to the dynamics of users' interests and model updates during training, considering randomly sampled items from a user's non-interacted item set as negatives can be uninformative. As a result, the model will inaccurately learn user preferences toward items. Identifying informative negatives is challenging because informative negative items are tied with both dynamically changed interests and model parameters (and sampling process should also be efficient). To this end, we propose to Generate Negative Samples (items) for SR (GenNi). A negative item is sampled at each time step based on the current SR model's learned user preferences toward items. An efficient implementation is proposed to further accelerate the generation process, making it scalable to large-scale recommendation tasks. Extensive experiments on four public datasets verify the importance of providing high-quality negative samples for SR and demonstrate the effectiveness and efficiency of GenNi.
Reconstructing the Dynamic Directivity of Unconstrained Speech
Sep 09, 2022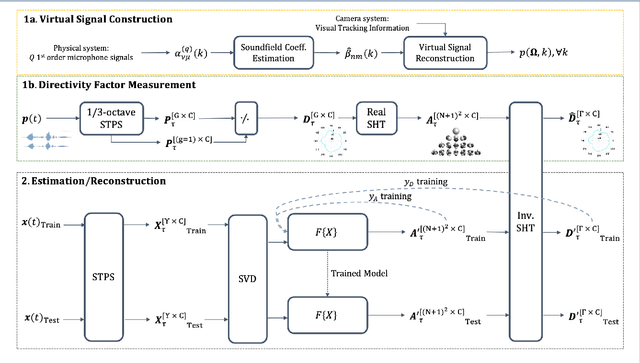
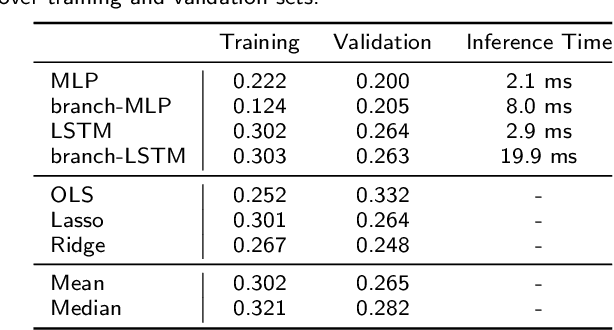

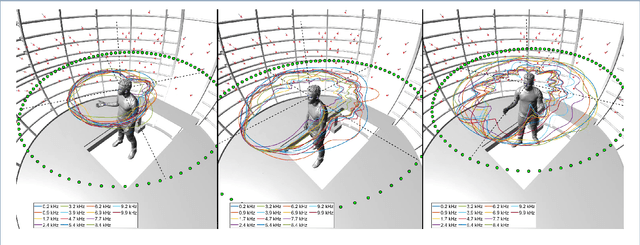
An accurate model of natural speech directivity is an important step toward achieving realistic vocal presence within a virtual communication setting. In this article, we propose a method to estimate and reconstruct the spatial energy distribution pattern of natural, unconstrained speech. We detail our method in two stages. Using recordings of speech captured by a real, static microphone array, we create a virtual array that tracks with the movement of the speaker over time. We use this egocentric virtual array to measure and encode the high-resolution directivity pattern of the speech signal as it dynamically evolves with natural speech and movement. Utilizing this encoded directivity representation, we train a machine learning model that leverages to estimate the full, dynamic directivity pattern when given a limited set of speech signals, as would be the case when speech is recorded using the microphones on a head-mounted display (HMD). We examine a variety of model architectures and training paradigms, and discuss the utility and practicality of each implementation. Our results demonstrate that neural networks can be used to regress from limited speech information to an accurate, dynamic estimation of the full directivity pattern.
Learning-Augmented Maximum Flow
Jul 26, 2022We propose a framework for speeding up maximum flow computation by using predictions. A prediction is a flow, i.e., an assignment of non-negative flow values to edges, which satisfies the flow conservation property, but does not necessarily respect the edge capacities of the actual instance (since these were unknown at the time of learning). We present an algorithm that, given an $m$-edge flow network and a predicted flow, computes a maximum flow in $O(m\eta)$ time, where $\eta$ is the $\ell_1$ error of the prediction, i.e., the sum over the edges of the absolute difference between the predicted and optimal flow values. Moreover, we prove that, given an oracle access to a distribution over flow networks, it is possible to efficiently PAC-learn a prediction minimizing the expected $\ell_1$ error over that distribution. Our results fit into the recent line of research on learning-augmented algorithms, which aims to improve over worst-case bounds of classical algorithms by using predictions, e.g., machine-learned from previous similar instances. So far, the main focus in this area was on improving competitive ratios for online problems. Following Dinitz et al. (NeurIPS 2021), our results are one of the firsts to improve the running time of an offline problem.
On topological data analysis for structural dynamics: an introduction to persistent homology
Sep 12, 2022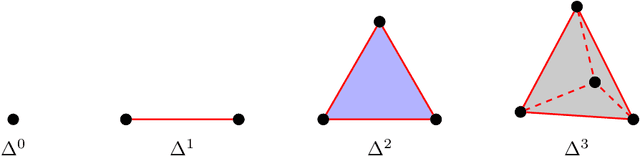
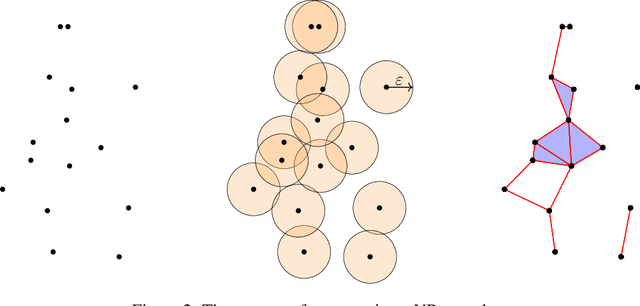
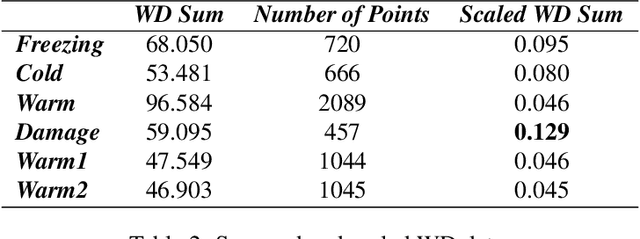
Topological methods can provide a way of proposing new metrics and methods of scrutinising data, that otherwise may be overlooked. In this work, a method of quantifying the shape of data, via a topic called topological data analysis will be introduced. The main tool within topological data analysis (TDA) is persistent homology. Persistent homology is a method of quantifying the shape of data over a range of length scales. The required background and a method of computing persistent homology is briefly discussed in this work. Ideas from topological data analysis are then used for nonlinear dynamics to analyse some common attractors, by calculating their embedding dimension, and then to assess their general topologies. A method will also be proposed, that uses topological data analysis to determine the optimal delay for a time-delay embedding. TDA will also be applied to a Z24 Bridge case study in structural health monitoring, where it will be used to scrutinise different data partitions, classified by the conditions at which the data were collected. A metric, from topological data analysis, is used to compare data between the partitions. The results presented demonstrate that the presence of damage alters the manifold shape more significantly than the effects present from temperature.
Regime-based Implied Stochastic Volatility Model for Crypto Option Pricing
Aug 15, 2022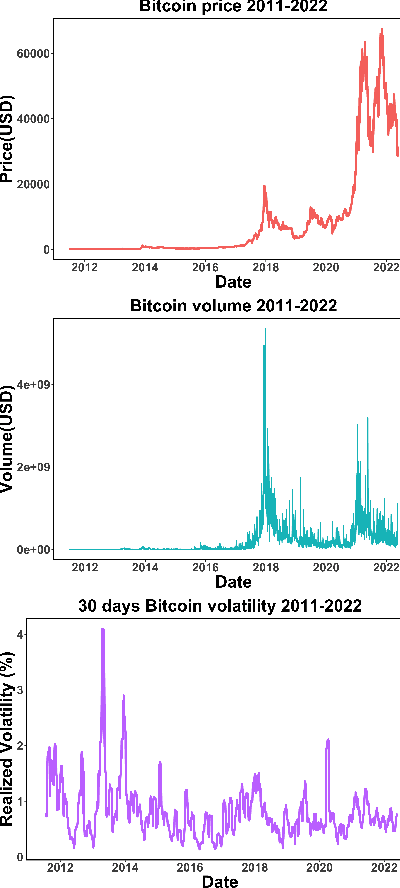
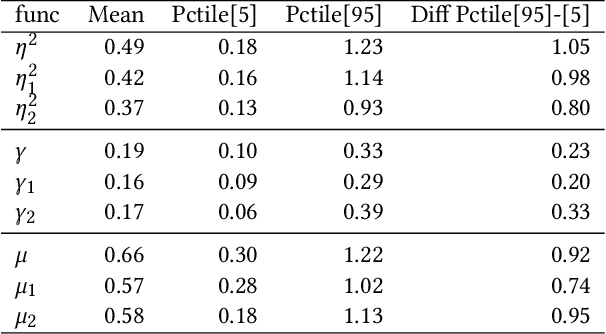
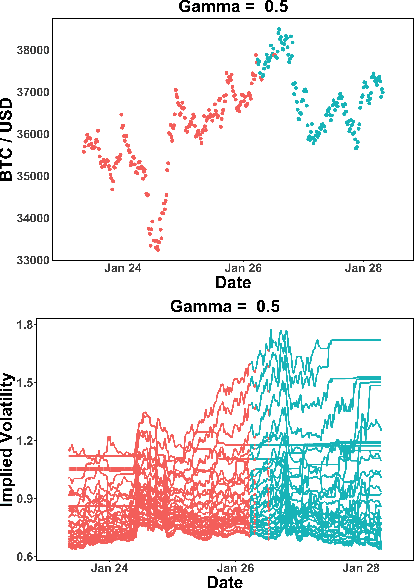
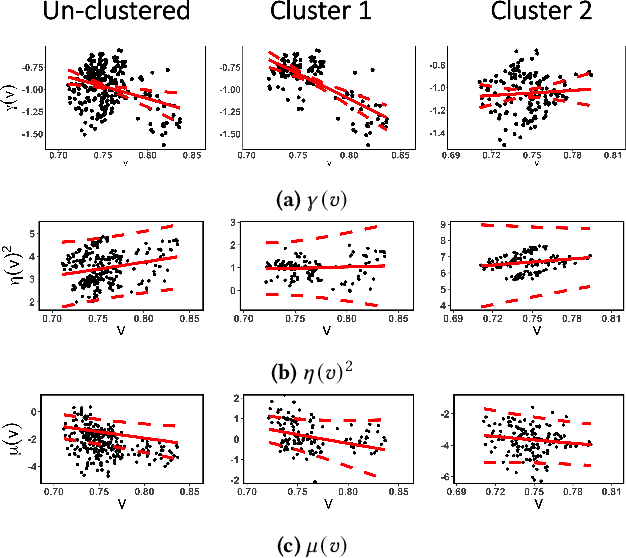
The increasing adoption of Digital Assets (DAs), such as Bitcoin (BTC), rises the need for accurate option pricing models. Yet, existing methodologies fail to cope with the volatile nature of the emerging DAs. Many models have been proposed to address the unorthodox market dynamics and frequent disruptions in the microstructure caused by the non-stationarity, and peculiar statistics, in DA markets. However, they are either prone to the curse of dimensionality, as additional complexity is required to employ traditional theories, or they overfit historical patterns that may never repeat. Instead, we leverage recent advances in market regime (MR) clustering with the Implied Stochastic Volatility Model (ISVM). Time-regime clustering is a temporal clustering method, that clusters the historic evolution of a market into different volatility periods accounting for non-stationarity. ISVM can incorporate investor expectations in each of the sentiment-driven periods by using implied volatility (IV) data. In this paper, we applied this integrated time-regime clustering and ISVM method (termed MR-ISVM) to high-frequency data on BTC options at the popular trading platform Deribit. We demonstrate that MR-ISVM contributes to overcome the burden of complex adaption to jumps in higher order characteristics of option pricing models. This allows us to price the market based on the expectations of its participants in an adaptive fashion.
Efficient and Consistent Bundle Adjustment on Lidar Point Clouds
Sep 19, 2022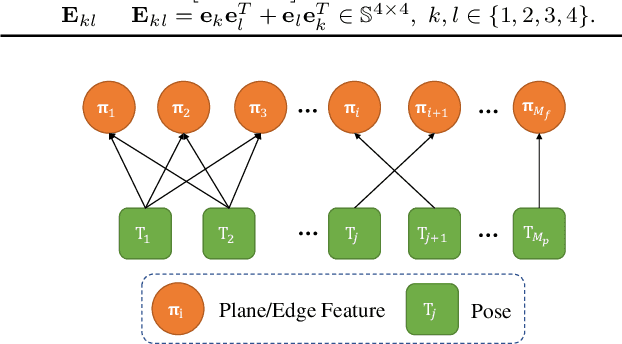
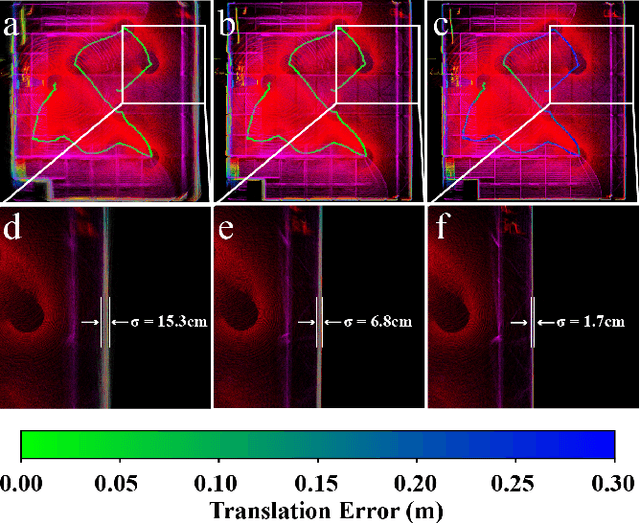
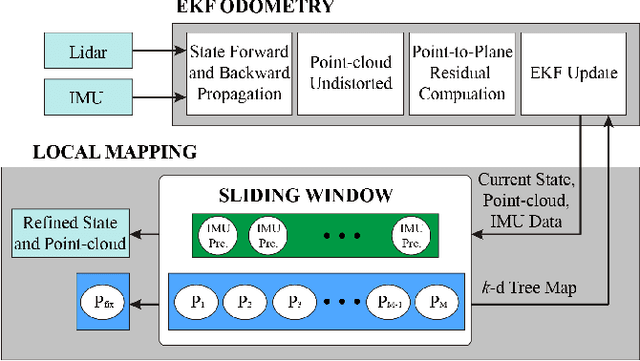
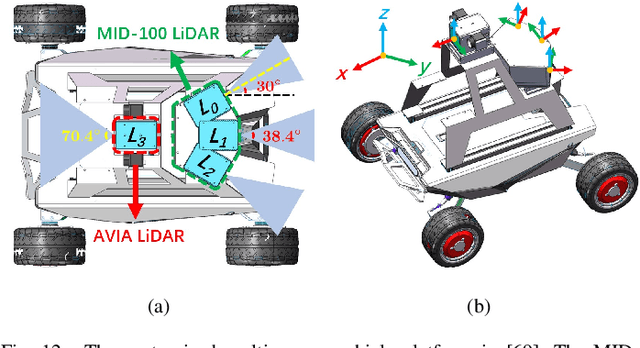
Bundle Adjustment (BA) refers to the problem of simultaneous determination of sensor poses and scene geometry, which is a fundamental problem in robot vision. This paper presents an efficient and consistent bundle adjustment method for lidar sensors. The method employs edge and plane features to represent the scene geometry, and directly minimizes the natural Euclidean distance from each raw point to the respective geometry feature. A nice property of this formulation is that the geometry features can be analytically solved, drastically reducing the dimension of the numerical optimization. To represent and solve the resultant optimization problem more efficiently, this paper then proposes a novel concept {\it point clusters}, which encodes all raw points associated to the same feature by a compact set of parameters, the {\it point cluster coordinates}. We derive the closed-form derivatives, up to the second order, of the BA optimization based on the point cluster coordinates and show their theoretical properties such as the null spaces and sparsity. Based on these theoretical results, this paper develops an efficient second-order BA solver. Besides estimating the lidar poses, the solver also exploits the second order information to estimate the pose uncertainty caused by measurement noises, leading to consistent estimates of lidar poses. Moreover, thanks to the use of point cluster, the developed solver fundamentally avoids the enumeration of each raw point (which is very time-consuming due to the large number) in all steps of the optimization: cost evaluation, derivatives evaluation and uncertainty evaluation. The implementation of our method is open sourced to benefit the robotics community and beyond.
CLINS: Continuous-Time Trajectory Estimation for LiDAR-Inertial System
Sep 10, 2021
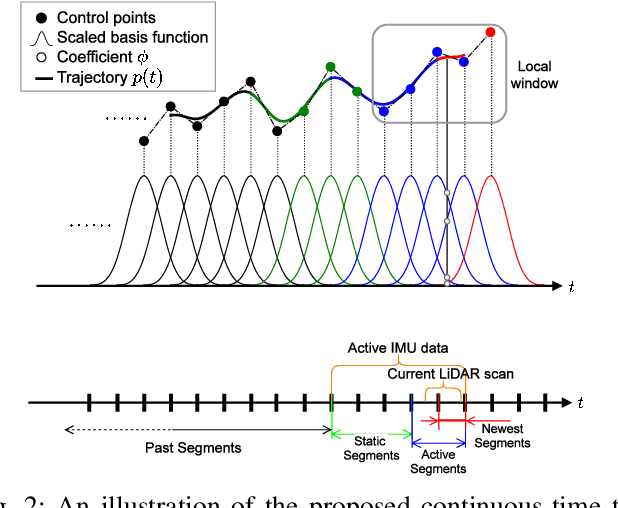
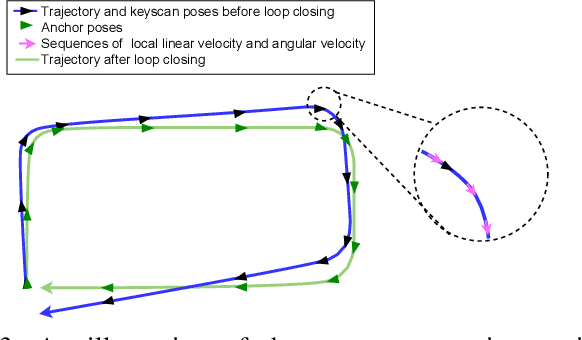
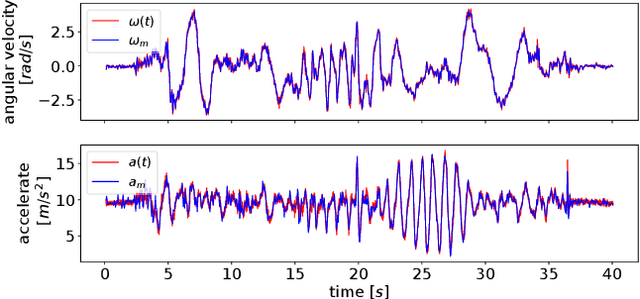
In this paper, we propose a highly accurate continuous-time trajectory estimation framework dedicated to SLAM (Simultaneous Localization and Mapping) applications, which enables fuse high-frequency and asynchronous sensor data effectively. We apply the proposed framework in a 3D LiDAR-inertial system for evaluations. The proposed method adopts a non-rigid registration method for continuous-time trajectory estimation and simultaneously removing the motion distortion in LiDAR scans. Additionally, we propose a two-state continuous-time trajectory correction method to efficiently and efficiently tackle the computationally-intractable global optimization problem when loop closure happens. We examine the accuracy of the proposed approach on several publicly available datasets and the data we collected. The experimental results indicate that the proposed method outperforms the discrete-time methods regarding accuracy especially when aggressive motion occurs. Furthermore, we open source our code at \url{https://github.com/APRIL-ZJU/clins} to benefit research community.
Performance Optimization for Variable Bitwidth Federated Learning in Wireless Networks
Sep 21, 2022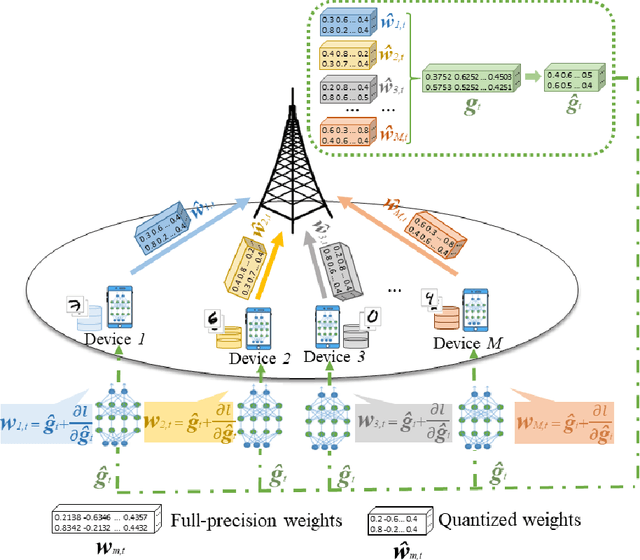
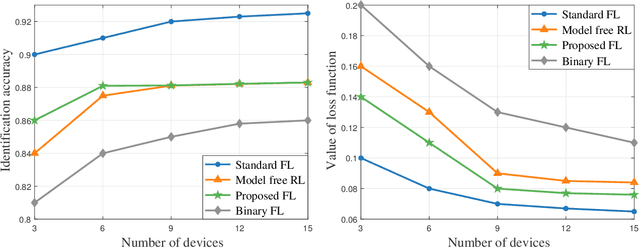
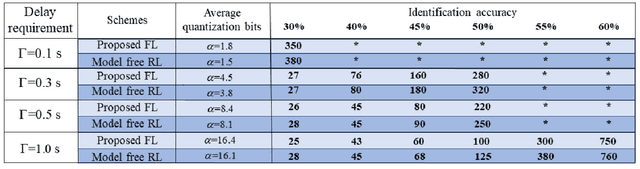
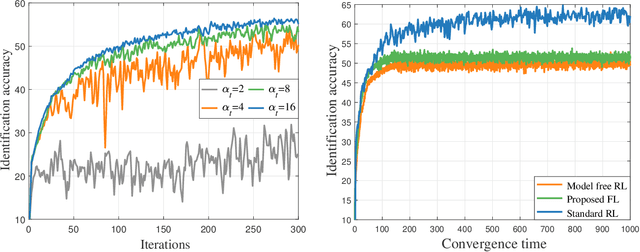
This paper considers improving wireless communication and computation efficiency in federated learning (FL) via model quantization. In the proposed bitwidth FL scheme, edge devices train and transmit quantized versions of their local FL model parameters to a coordinating server, which, in turn, aggregates them into a quantized global model and synchronizes the devices. The goal is to jointly determine the bitwidths employed for local FL model quantization and the set of devices participating in FL training at each iteration. This problem is posed as an optimization problem whose goal is to minimize the training loss of quantized FL under a per-iteration device sampling budget and delay requirement. To derive the solution, an analytical characterization is performed in order to show how the limited wireless resources and induced quantization errors affect the performance of the proposed FL method. The analytical results show that the improvement of FL training loss between two consecutive iterations depends on the device selection and quantization scheme as well as on several parameters inherent to the model being learned. Given linear regression-based estimates of these model properties, it is shown that the FL training process can be described as a Markov decision process (MDP), and, then, a model-based reinforcement learning (RL) method is proposed to optimize action selection over iterations. Compared to model-free RL, this model-based RL approach leverages the derived mathematical characterization of the FL training process to discover an effective device selection and quantization scheme without imposing additional device communication overhead. Simulation results show that the proposed FL algorithm can reduce 29% and 63% convergence time compared to a model free RL method and the standard FL method, respectively.
Ultra-low Latency Adaptive Local Binary Spiking Neural Network with Accuracy Loss Estimator
Jul 31, 2022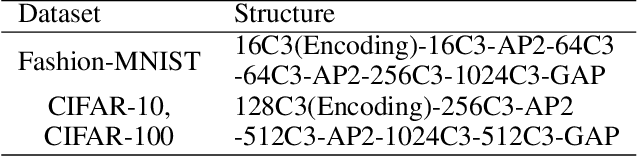
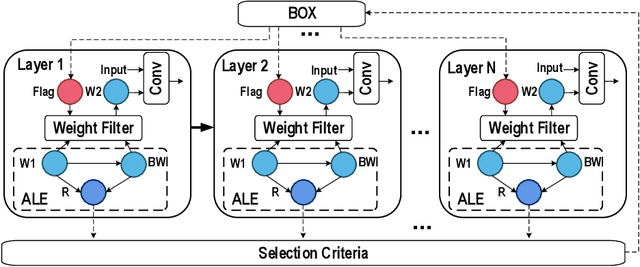
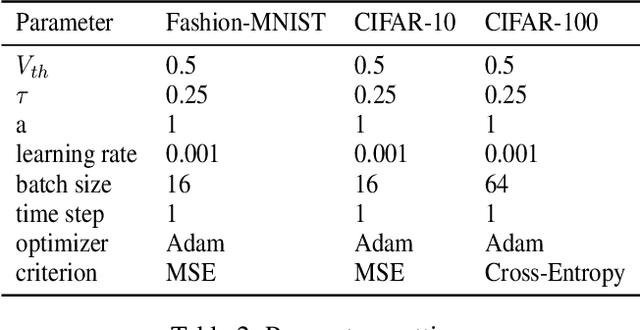
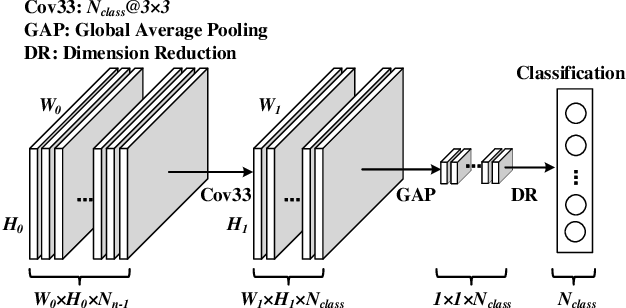
Spiking neural network (SNN) is a brain-inspired model which has more spatio-temporal information processing capacity and computational energy efficiency. However, with the increasing depth of SNNs, the memory problem caused by the weights of SNNs has gradually attracted attention. Inspired by Artificial Neural Networks (ANNs) quantization technology, binarized SNN (BSNN) is introduced to solve the memory problem. Due to the lack of suitable learning algorithms, BSNN is usually obtained by ANN-to-SNN conversion, whose accuracy will be limited by the trained ANNs. In this paper, we propose an ultra-low latency adaptive local binary spiking neural network (ALBSNN) with accuracy loss estimators, which dynamically selects the network layers to be binarized to ensure the accuracy of the network by evaluating the error caused by the binarized weights during the network learning process. Experimental results show that this method can reduce storage space by more than 20 % without losing network accuracy. At the same time, in order to accelerate the training speed of the network, the global average pooling(GAP) layer is introduced to replace the fully connected layers by the combination of convolution and pooling, so that SNNs can use a small number of time steps to obtain better recognition accuracy. In the extreme case of using only one time step, we still can achieve 92.92 %, 91.63 % ,and 63.54 % testing accuracy on three different datasets, FashionMNIST, CIFAR-10, and CIFAR-100, respectively.