 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Post-hoc Interpretability based Parameter Selection for Data Oriented Nuclear Reactor Accident Diagnosis System
Aug 03, 2022
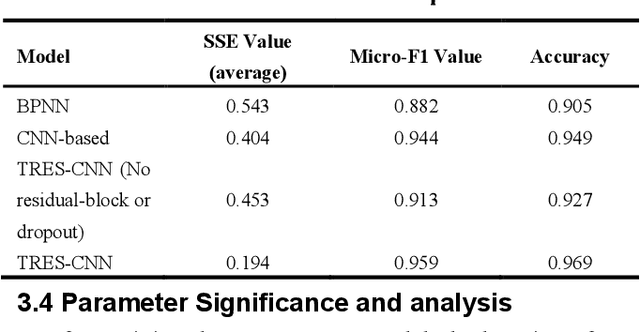
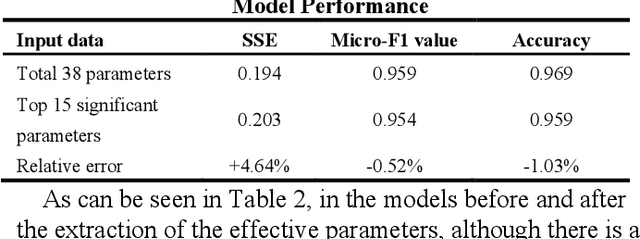
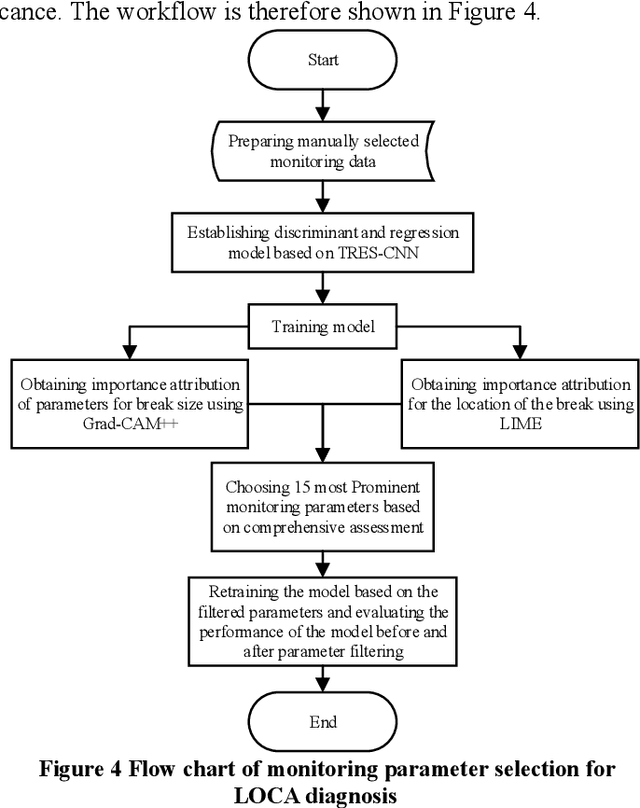
During applying data-oriented diagnosis systems to distinguishing the type of and evaluating the severity of nuclear power plant initial events, it is of vital importance to decide which parameters to be used as the system input. However, although several diagnosis systems have already achieved acceptable performance in diagnosis precision and speed, hardly have the researchers discussed the method of monitoring point choosing and its layout. For this reason, redundant measuring data are used to train the diagnostic model, leading to high uncertainty of the classification, extra training time consumption, and higher probability of overfitting while training. In this study, a method of choosing thermal hydraulics parameters of a nuclear power plant is proposed, using the theory of post-hoc interpretability theory in deep learning. At the start, a novel Time-sequential Residual Convolutional Neural Network (TRES-CNN) diagnosis model is introduced to identify the position and hydrodynamic diameter of breaks in LOCA, using 38 parameters manually chosen on HPR1000 empirically. Afterwards, post-hoc interpretability methods are applied to evaluate the attributions of diagnosis model's outputs, deciding which 15 parameters to be more decisive in diagnosing LOCA details. The results show that the TRES-CNN based diagnostic model successfully predicts the position and size of breaks in LOCA via selected 15 parameters of HPR1000, with 25% of time consumption while training the model compared the process using total 38 parameters. In addition, the relative diagnostic accuracy error is within 1.5 percent compared with the model using parameters chosen empirically, which can be regarded as the same amount of diagnostic reliability.
Quantifying How Hateful Communities Radicalize Online Users
Sep 19, 2022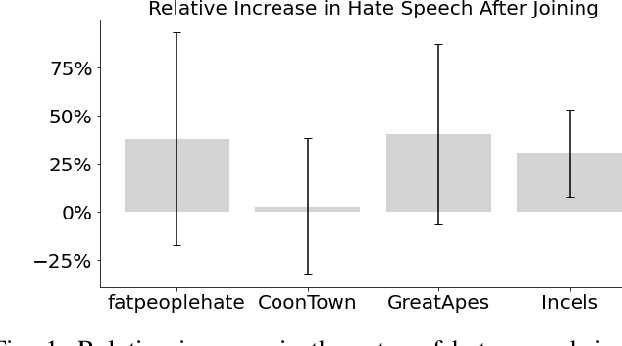
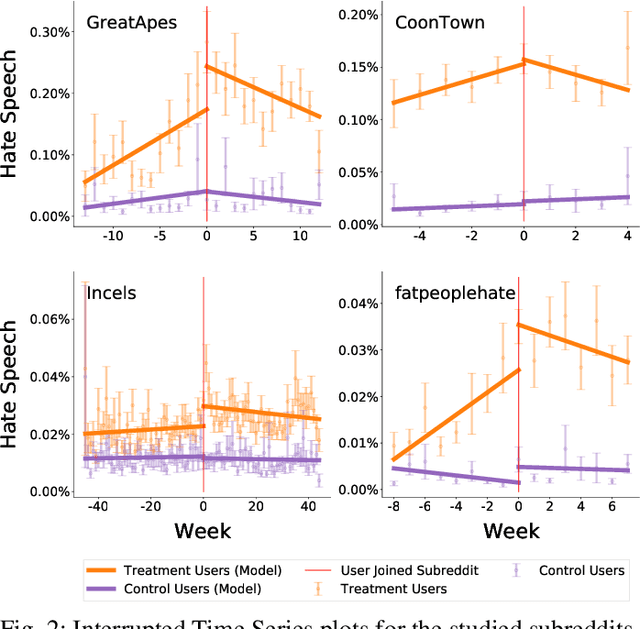
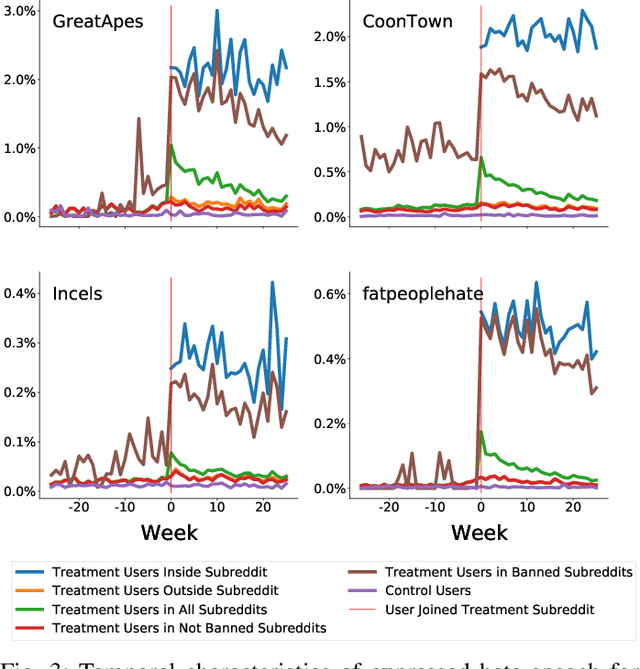
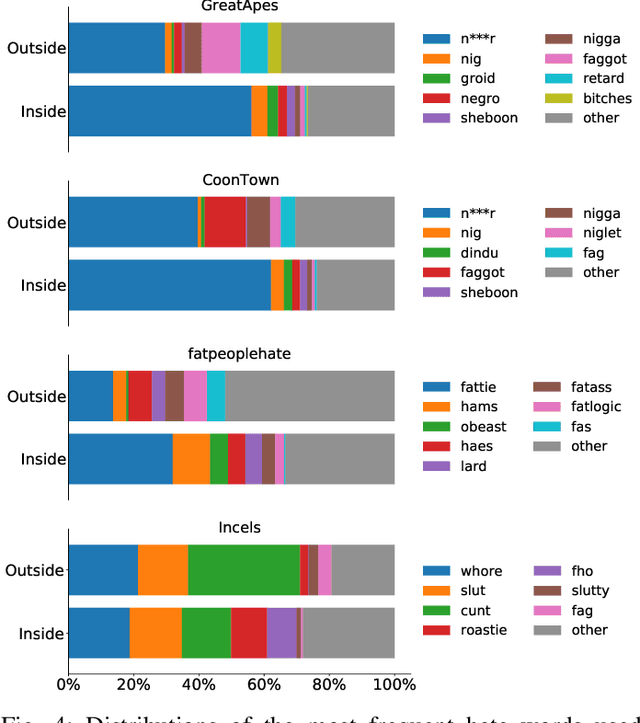
While online social media offers a way for ignored or stifled voices to be heard, it also allows users a platform to spread hateful speech. Such speech usually originates in fringe communities, yet it can spill over into mainstream channels. In this paper, we measure the impact of joining fringe hateful communities in terms of hate speech propagated to the rest of the social network. We leverage data from Reddit to assess the effect of joining one type of echo chamber: a digital community of like-minded users exhibiting hateful behavior. We measure members' usage of hate speech outside the studied community before and after they become active participants. Using Interrupted Time Series (ITS) analysis as a causal inference method, we gauge the spillover effect, in which hateful language from within a certain community can spread outside that community by using the level of out-of-community hate word usage as a proxy for learned hate. We investigate four different Reddit sub-communities (subreddits) covering three areas of hate speech: racism, misogyny and fat-shaming. In all three cases we find an increase in hate speech outside the originating community, implying that joining such community leads to a spread of hate speech throughout the platform. Moreover, users are found to pick up this new hateful speech for months after initially joining the community. We show that the harmful speech does not remain contained within the community. Our results provide new evidence of the harmful effects of echo chambers and the potential benefit of moderating them to reduce adoption of hateful speech.
Reconfigurable and Real-Time Nyquist OTDM Demultiplexing in Silicon Photonics
Oct 19, 2021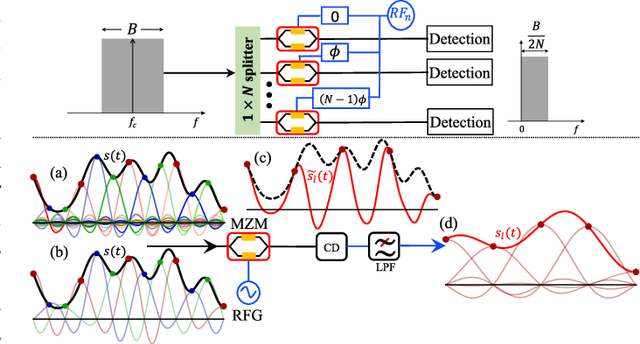
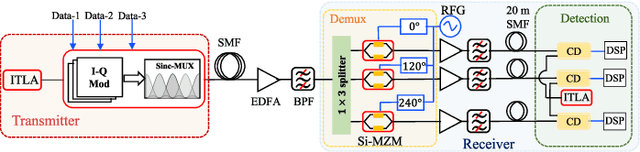
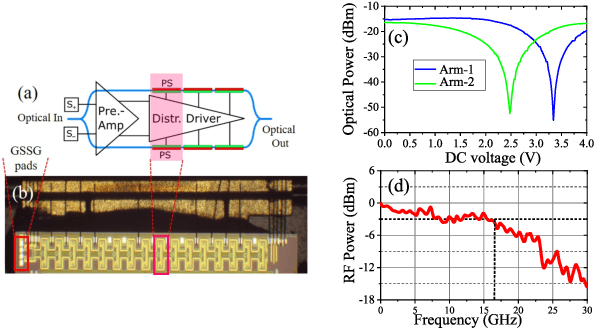
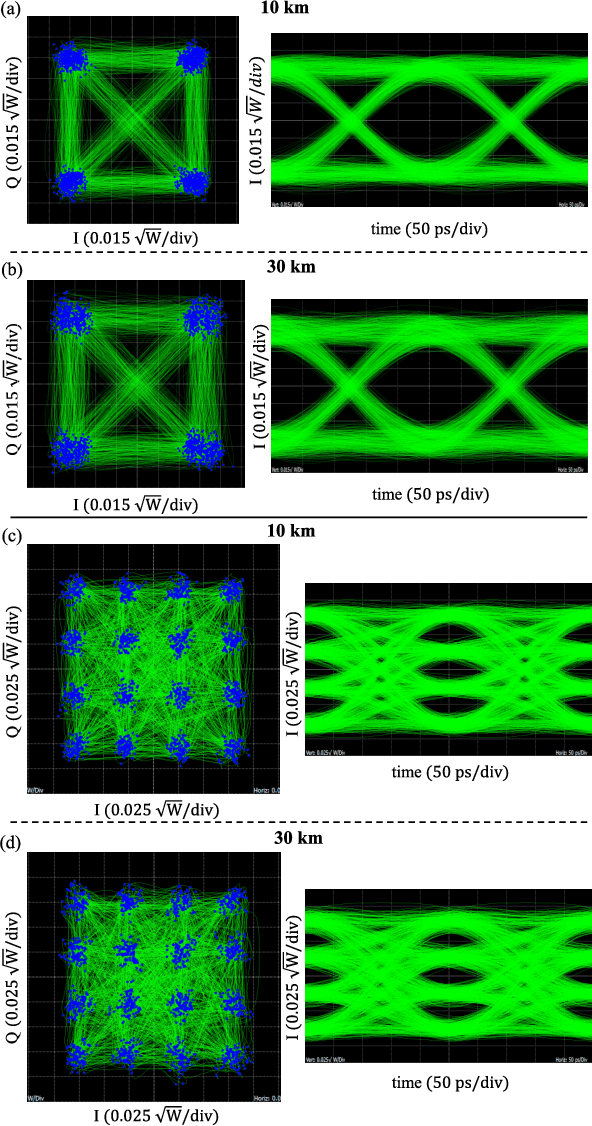
We demonstrate for the first time, to the best of our knowledge, reconfigurable and real-time orthogonal time-domain demultiplexing of coherent multilevel Nyquist signals in silicon photonics. No external pulse source is needed and frequencytime coherence is used to sample the incoming Nyquist OTDM signal with orthogonal sinc-shaped Nyquist pulse sequences using Mach-Zehnder modulators. All the parameters such as bandwidth and channel selection are completely tunable in the electrical domain. The feasibility of this scheme is demonstrated through a demultiplexing experiment over the entire C-band (1530 nm - 1550 nm), employing 24 Gbaud Nyquist QAM signals due to experimental constraints on the transmitter side. However, the silicon Mach-Zehnder modulator with a 3-dB bandwidth of only 16 GHz can demultiplex Nyquist pulses of 90 GHz optical bandwidth suggesting a possibility to reach symbol rates up to 90 GBd in an integrated Nyquist transceiver.
Sequence Feature Extraction for Malware Family Analysis via Graph Neural Network
Aug 10, 2022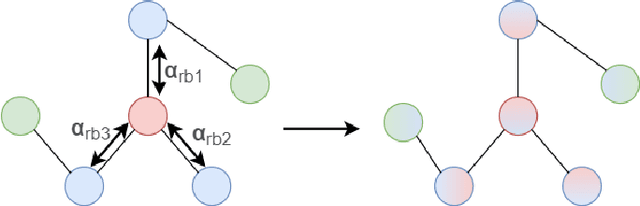
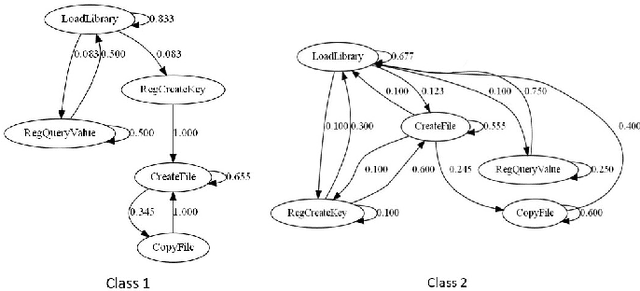
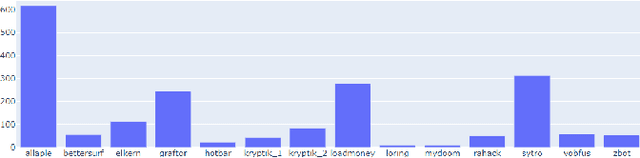
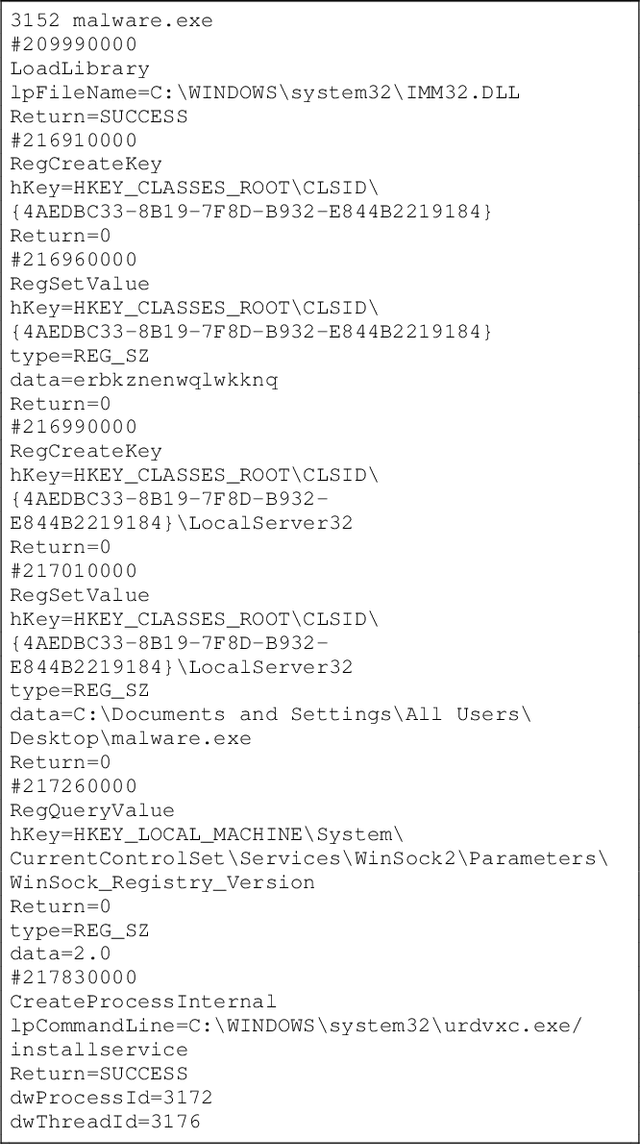
Malicious software (malware) causes much harm to our devices and life. We are eager to understand the malware behavior and the threat it made. Most of the record files of malware are variable length and text-based files with time stamps, such as event log data and dynamic analysis profiles. Using the time stamps, we can sort such data into sequence-based data for the following analysis. However, dealing with the text-based sequences with variable lengths is difficult. In addition, unlike natural language text data, most sequential data in information security have specific properties and structure, such as loop, repeated call, noise, etc. To deeply analyze the API call sequences with their structure, we use graphs to represent the sequences, which can further investigate the information and structure, such as the Markov model. Therefore, we design and implement an Attention Aware Graph Neural Network (AWGCN) to analyze the API call sequences. Through AWGCN, we can obtain the sequence embeddings to analyze the behavior of the malware. Moreover, the classification experiment result shows that AWGCN outperforms other classifiers in the call-like datasets, and the embedding can further improve the classic model's performance.
Multi-task Swin Transformer for Motion Artifacts Classification and Cardiac Magnetic Resonance Image Segmentation
Sep 06, 2022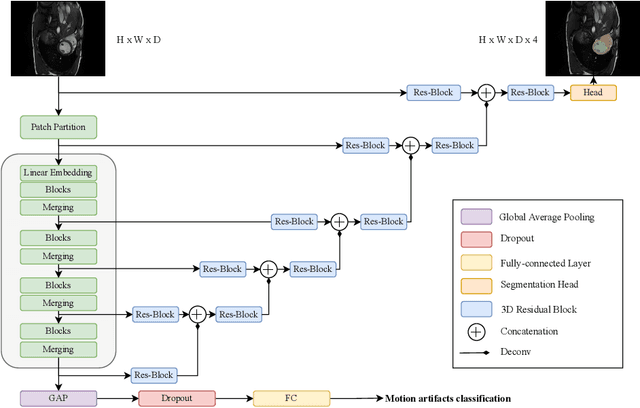
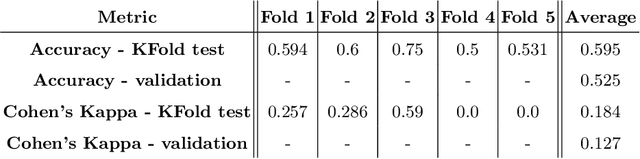
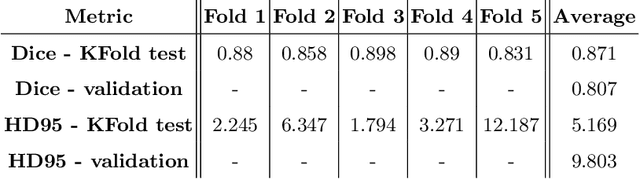
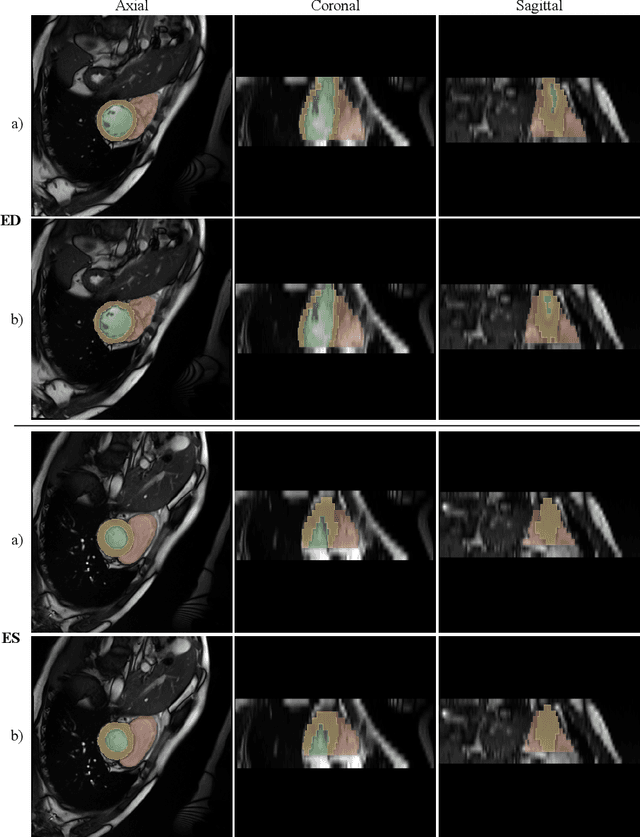
Cardiac Magnetic Resonance Imaging is commonly used for the assessment of the cardiac anatomy and function. The delineations of left and right ventricle blood pools and left ventricular myocardium are important for the diagnosis of cardiac diseases. Unfortunately, the movement of a patient during the CMR acquisition procedure may result in motion artifacts appearing in the final image. Such artifacts decrease the diagnostic quality of CMR images and force redoing of the procedure. In this paper, we present a Multi-task Swin UNEt TRansformer network for simultaneous solving of two tasks in the CMRxMotion challenge: CMR segmentation and motion artifacts classification. We utilize both segmentation and classification as a multi-task learning approach which allows us to determine the diagnostic quality of CMR and generate masks at the same time. CMR images are classified into three diagnostic quality classes, whereas, all samples with non-severe motion artifacts are being segmented. Ensemble of five networks trained using 5-Fold Cross-validation achieves segmentation performance of DICE coefficient of 0.871 and classification accuracy of 0.595.
Network-wide link travel time and station waiting time estimation using automatic fare collection data: A computational graph approach
Aug 19, 2021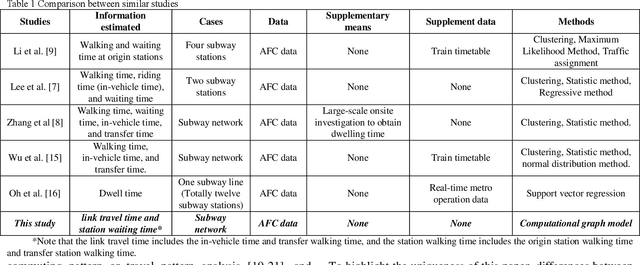
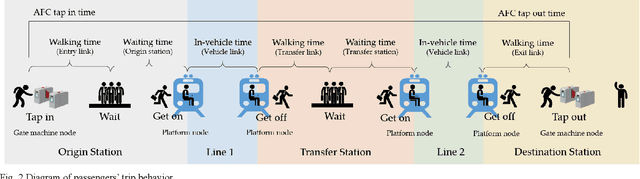
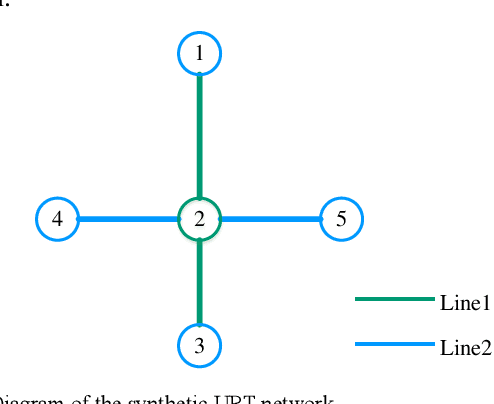
Urban rail transit (URT) system plays a dominating role in many megacities like Beijing and Hong Kong. Due to its important role and complex nature, it is always in great need for public agencies to better understand the performance of the URT system. This paper focuses on an essential and hard problem to estimate the network-wide link travel time and station waiting time using the automatic fare collection (AFC) data in the URT system, which is beneficial to better understand the system-wide real-time operation state. The emerging data-driven techniques, such as computational graph (CG) models in the machine learning field, provide a new solution for solving this problem. In this study, we first formulate a data-driven estimation optimization framework to estimate the link travel time and station waiting time. Then, we cast the estimation optimization model into a CG framework to solve the optimization problem and obtain the estimation results. The methodology is verified on a synthetic URT network and applied to a real-world URT network using the synthetic and real-world AFC data, respectively. Results show the robustness and effectiveness of the CG-based framework. To the best of our knowledge, this is the first time that the CG is applied to the URT. This study can provide critical insights to better understand the operational state in URT.
Connection Reduction Is All You Need
Aug 02, 2022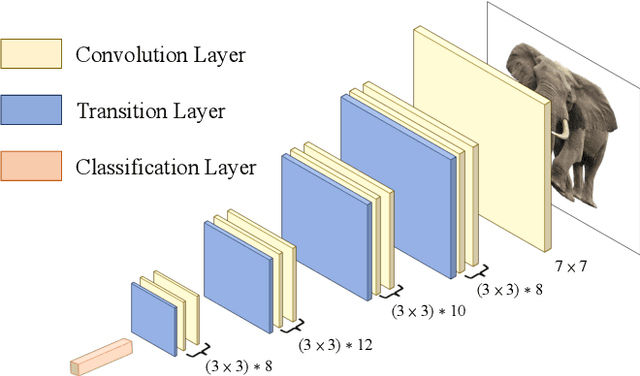
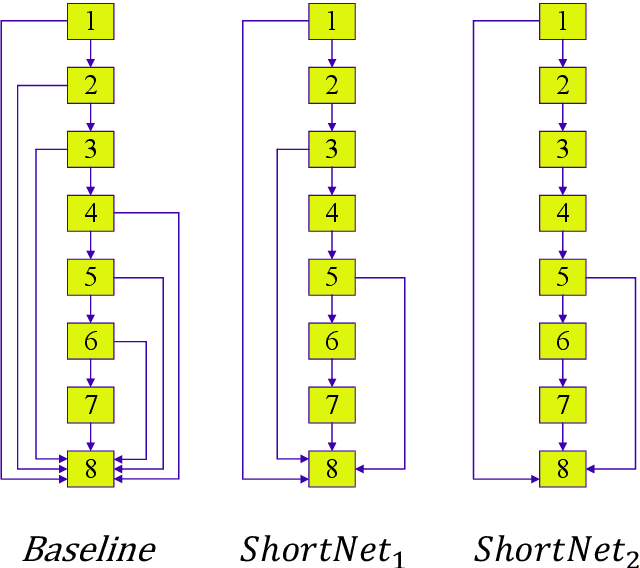
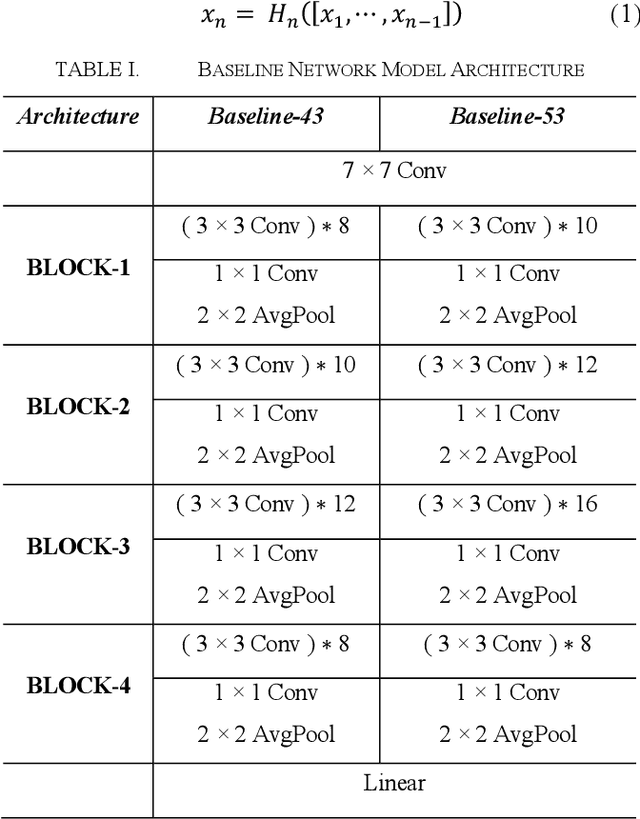
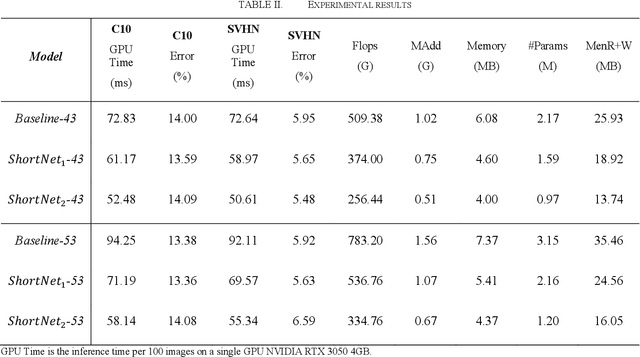
Convolutional Neural Networks (CNN) increase depth by stacking convolutional layers, and deeper network models perform better in image recognition. Empirical research shows that simply stacking convolutional layers does not make the network train better, and skip connection (residual learning) can improve network model performance. For the image classification task, models with global densely connected architectures perform well in large datasets like ImageNet, but are not suitable for small datasets such as CIFAR-10 and SVHN. Different from dense connections, we propose two new algorithms to connect layers. Baseline is a densely connected network, and the networks connected by the two new algorithms are named ShortNet1 and ShortNet2 respectively. The experimental results of image classification on CIFAR-10 and SVHN show that ShortNet1 has a 5% lower test error rate and 25% faster inference time than Baseline. ShortNet2 speeds up inference time by 40% with less loss in test accuracy.
An Indian Roads Dataset for Supported and Suspended Traffic Lights Detection
Sep 09, 2022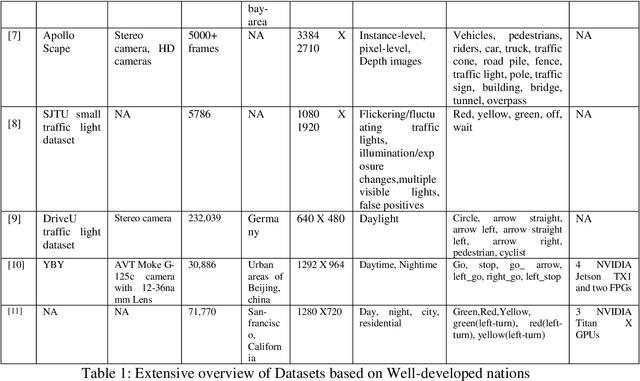
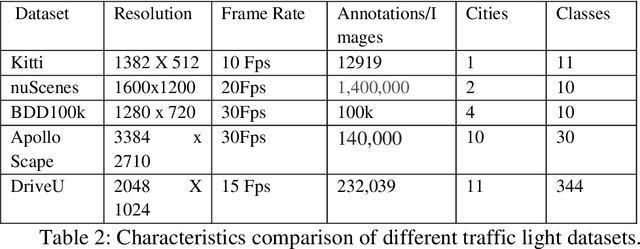

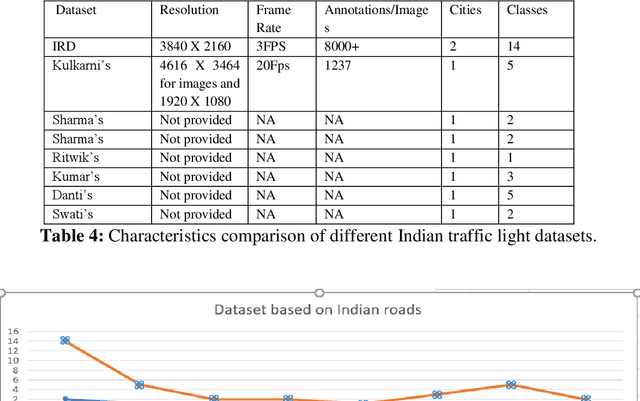
Autonomous vehicles are growing rapidly, in well-developed nations like America, Europe, and China. Tech giants like Google, Tesla, Audi, BMW, and Mercedes are building highly efficient self-driving vehicles. However, the technology is still not mainstream for developing nations like India, Thailand, Africa, etc., In this paper, we present a thorough comparison of the existing datasets based on well-developed nations as well as Indian roads. We then developed a new dataset "Indian Roads Dataset" (IRD) having more than 8000 annotations extracted from 3000+ images shot using a 64 (megapixel) camera. All the annotations are manually labelled adhering to the strict rules of annotations. Real-time video sequences have been captured from two different cities in India namely New Delhi and Chandigarh during the day and night-light conditions. Our dataset exceeds previous Indian traffic light datasets in size, annotations, and variance. We prove the amelioration of our dataset by providing an extensive comparison with existing Indian datasets. Various dataset criteria like size, capturing device, a number of cities, and variations of traffic light orientations are considered. The dataset can be downloaded from here https://sites.google.com/view/ird-dataset/home
Regime-based Implied Stochastic Volatility Model for Crypto Option Pricing
Aug 15, 2022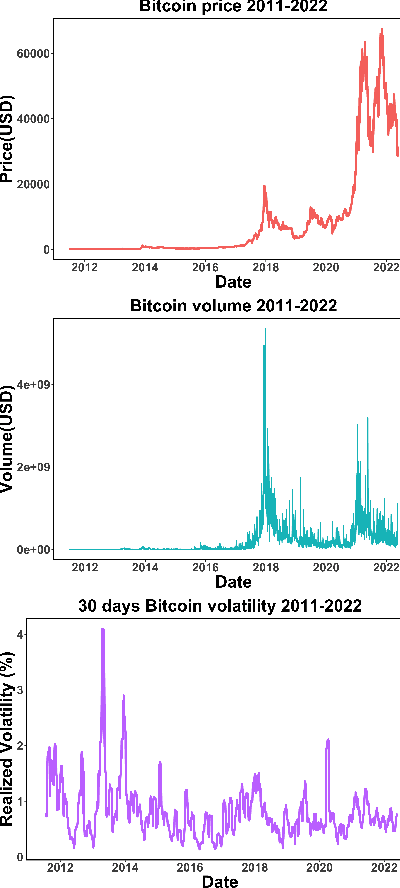
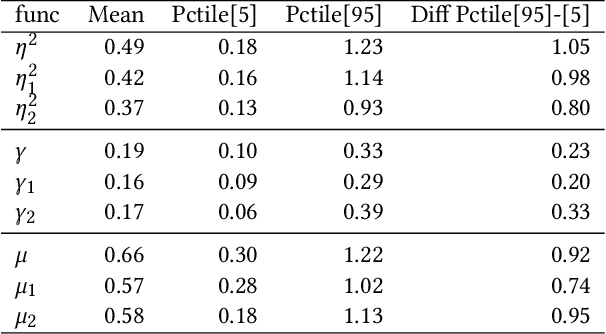
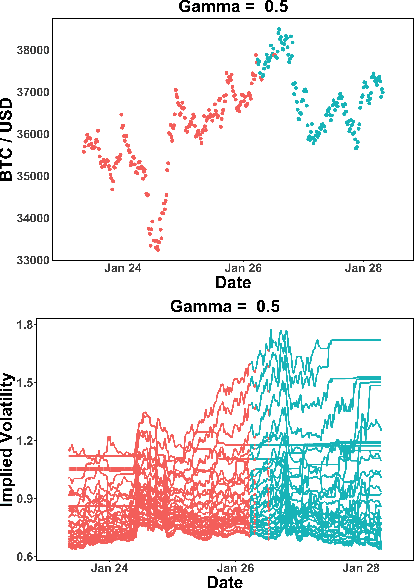
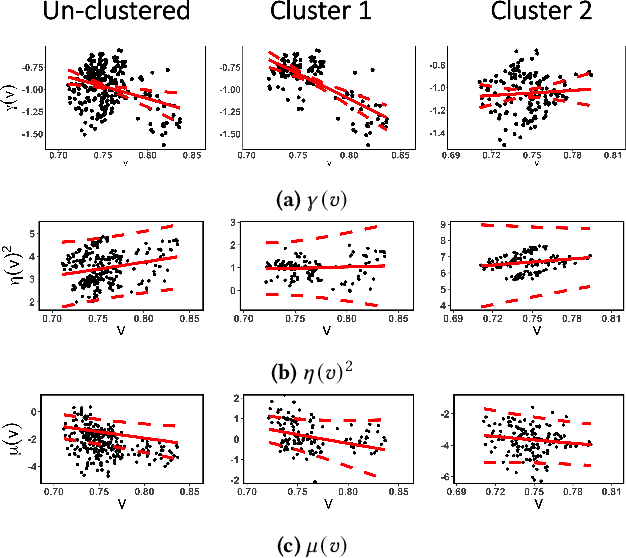
The increasing adoption of Digital Assets (DAs), such as Bitcoin (BTC), rises the need for accurate option pricing models. Yet, existing methodologies fail to cope with the volatile nature of the emerging DAs. Many models have been proposed to address the unorthodox market dynamics and frequent disruptions in the microstructure caused by the non-stationarity, and peculiar statistics, in DA markets. However, they are either prone to the curse of dimensionality, as additional complexity is required to employ traditional theories, or they overfit historical patterns that may never repeat. Instead, we leverage recent advances in market regime (MR) clustering with the Implied Stochastic Volatility Model (ISVM). Time-regime clustering is a temporal clustering method, that clusters the historic evolution of a market into different volatility periods accounting for non-stationarity. ISVM can incorporate investor expectations in each of the sentiment-driven periods by using implied volatility (IV) data. In this paper, we applied this integrated time-regime clustering and ISVM method (termed MR-ISVM) to high-frequency data on BTC options at the popular trading platform Deribit. We demonstrate that MR-ISVM contributes to overcome the burden of complex adaption to jumps in higher order characteristics of option pricing models. This allows us to price the market based on the expectations of its participants in an adaptive fashion.
Generating Negative Samples for Sequential Recommendation
Aug 07, 2022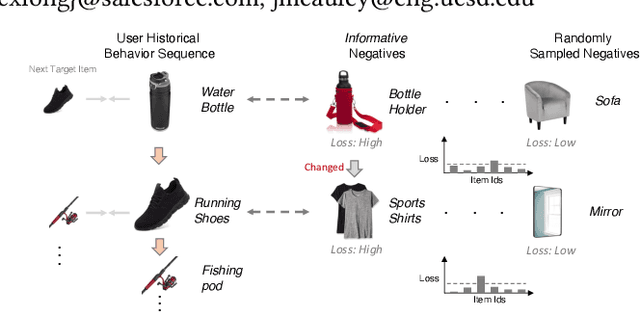
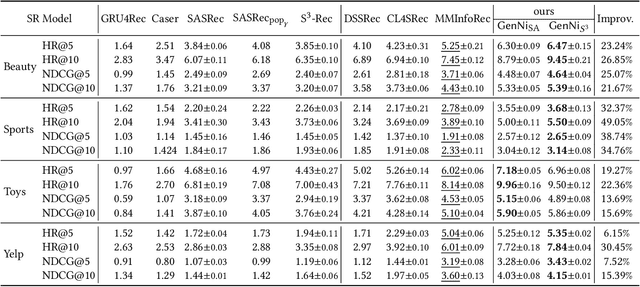
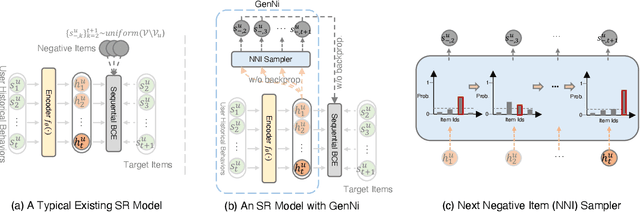
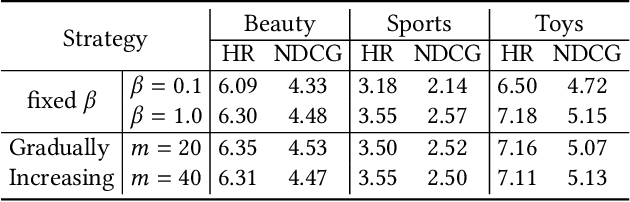
To make Sequential Recommendation (SR) successful, recent works focus on designing effective sequential encoders, fusing side information, and mining extra positive self-supervision signals. The strategy of sampling negative items at each time step is less explored. Due to the dynamics of users' interests and model updates during training, considering randomly sampled items from a user's non-interacted item set as negatives can be uninformative. As a result, the model will inaccurately learn user preferences toward items. Identifying informative negatives is challenging because informative negative items are tied with both dynamically changed interests and model parameters (and sampling process should also be efficient). To this end, we propose to Generate Negative Samples (items) for SR (GenNi). A negative item is sampled at each time step based on the current SR model's learned user preferences toward items. An efficient implementation is proposed to further accelerate the generation process, making it scalable to large-scale recommendation tasks. Extensive experiments on four public datasets verify the importance of providing high-quality negative samples for SR and demonstrate the effectiveness and efficiency of GenNi.