 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Facial Expression Recognition using Facial Landmarks and Neural Networks
Jan 31, 2022



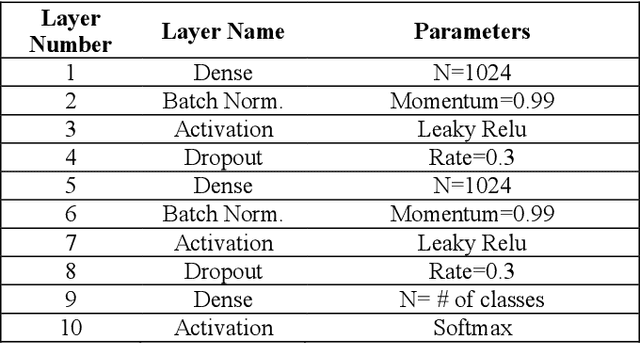
This paper presents a lightweight algorithm for feature extraction, classification of seven different emotions, and facial expression recognition in a real-time manner based on static images of the human face. In this regard, a Multi-Layer Perceptron (MLP) neural network is trained based on the foregoing algorithm. In order to classify human faces, first, some pre-processing is applied to the input image, which can localize and cut out faces from it. In the next step, a facial landmark detection library is used, which can detect the landmarks of each face. Then, the human face is split into upper and lower faces, which enables the extraction of the desired features from each part. In the proposed model, both geometric and texture-based feature types are taken into account. After the feature extraction phase, a normalized vector of features is created. A 3-layer MLP is trained using these feature vectors, leading to 96% accuracy on the test set.
Rethinking Efficiency and Redundancy in Training Large-scale Graphs
Sep 02, 2022
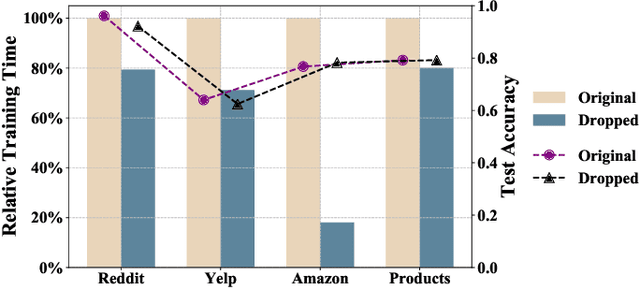
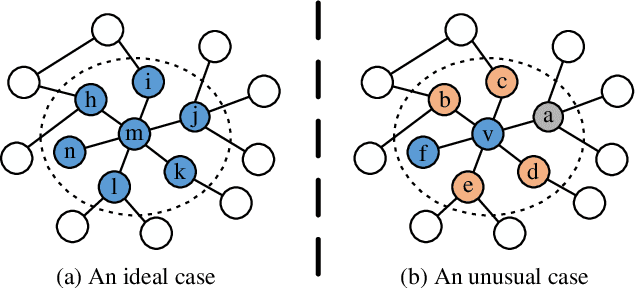
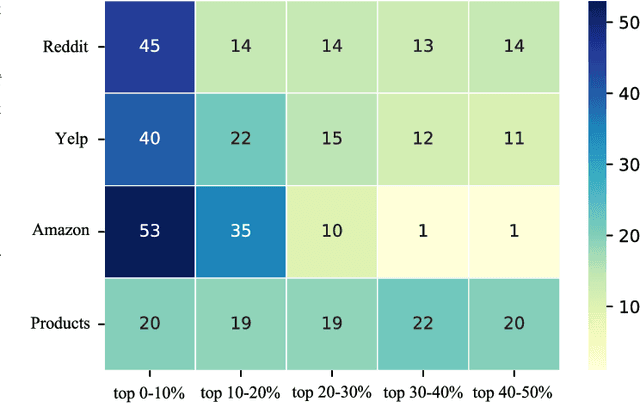
Large-scale graphs are ubiquitous in real-world scenarios and can be trained by Graph Neural Networks (GNNs) to generate representation for downstream tasks. Given the abundant information and complex topology of a large-scale graph, we argue that redundancy exists in such graphs and will degrade the training efficiency. Unfortunately, the model scalability severely restricts the efficiency of training large-scale graphs via vanilla GNNs. Despite recent advances in sampling-based training methods, sampling-based GNNs generally overlook the redundancy issue. It still takes intolerable time to train these models on large-scale graphs. Thereby, we propose to drop redundancy and improve efficiency of training large-scale graphs with GNNs, by rethinking the inherent characteristics in a graph. In this paper, we pioneer to propose a once-for-all method, termed DropReef, to drop the redundancy in large-scale graphs. Specifically, we first conduct preliminary experiments to explore potential redundancy in large-scale graphs. Next, we present a metric to quantify the neighbor heterophily of all nodes in a graph. Based on both experimental and theoretical analysis, we reveal the redundancy in a large-scale graph, i.e., nodes with high neighbor heterophily and a great number of neighbors. Then, we propose DropReef to detect and drop the redundancy in large-scale graphs once and for all, helping reduce the training time while ensuring no sacrifice in the model accuracy. To demonstrate the effectiveness of DropReef, we apply it to recent state-of-the-art sampling-based GNNs for training large-scale graphs, owing to the high precision of such models. With DropReef leveraged, the training efficiency of models can be greatly promoted. DropReef is highly compatible and is offline performed, benefiting the state-of-the-art sampling-based GNNs in the present and future to a significant extent.
Parameter-Efficient Finetuning for Robust Continual Multilingual Learning
Sep 14, 2022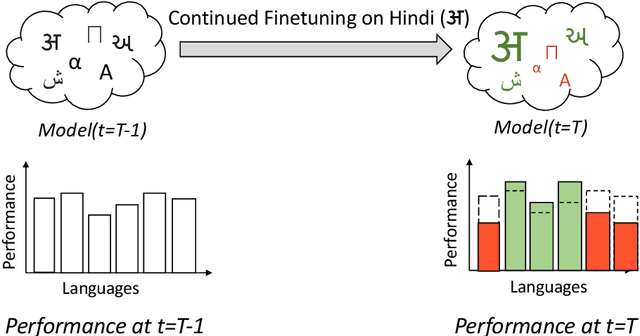

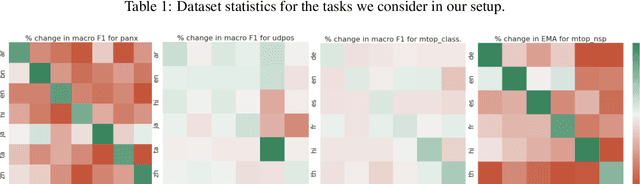
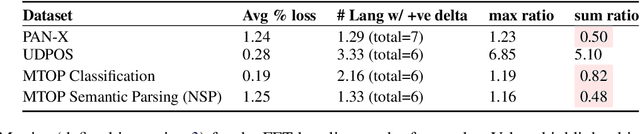
NLU systems deployed in the real world are expected to be regularly updated by retraining or finetuning the underlying neural network on new training examples accumulated over time. In our work, we focus on the multilingual setting where we would want to further finetune a multilingual model on new training data for the same NLU task on which the aforementioned model has already been trained for. We show that under certain conditions, naively updating the multilingual model can lead to losses in performance over a subset of languages although the aggregated performance metric shows an improvement. We establish this phenomenon over four tasks belonging to three task families (token-level, sentence-level and seq2seq) and find that the baseline is far from ideal for the setting at hand. We then build upon recent advances in parameter-efficient finetuning to develop novel finetuning pipelines that allow us to jointly minimize catastrophic forgetting while encouraging positive cross-lingual transfer, hence improving the spread of gains over different languages while reducing the losses incurred in this setup.
Online Whole-body Motion Planning for Quadrotor using Multi-resolution Search
Sep 14, 2022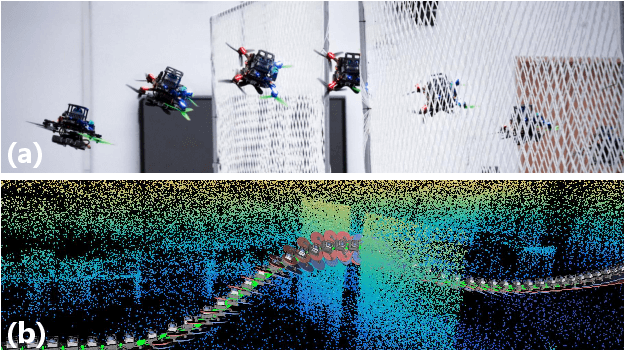
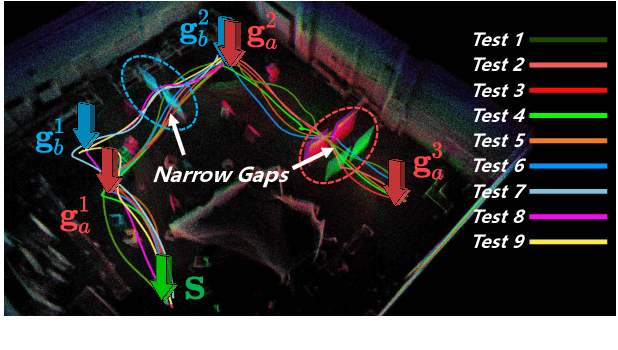
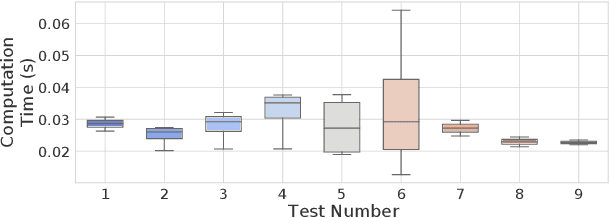
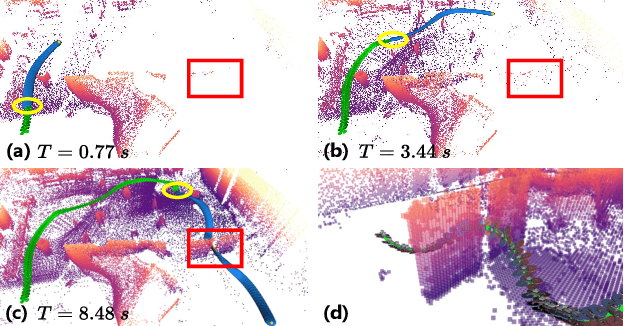
In this paper, we address the problem of online quadrotor whole-body motion planning (SE(3) planning) in unknown and unstructured environments. We propose a novel multi-resolution search method, which discovers narrow areas requiring full pose planning and normal areas requiring only position planning. As a consequence, a quadrotor planning problem is decomposed into several SE(3) (if necessary) and R^3 sub-problems. To fly through the discovered narrow areas, a carefully designed corridor generation strategy for narrow areas is proposed, which significantly increases the planning success rate. The overall problem decomposition and hierarchical planning framework substantially accelerate the planning process, making it possible to work online with fully onboard sensing and computation in unknown environments. Extensive simulation benchmark comparisons show that the proposed method has an order of magnitude faster than the state-of-the-art methods in computation time while maintaining high planning success rate. The proposed method is finally integrated into a LiDAR-based autonomous quadrotor, and various real-world experiments in unknown and unstructured environments are conducted to demonstrate the outstanding performance of the proposed method.
Uncertainty-aware Perception Models for Off-road Autonomous Unmanned Ground Vehicles
Sep 22, 2022
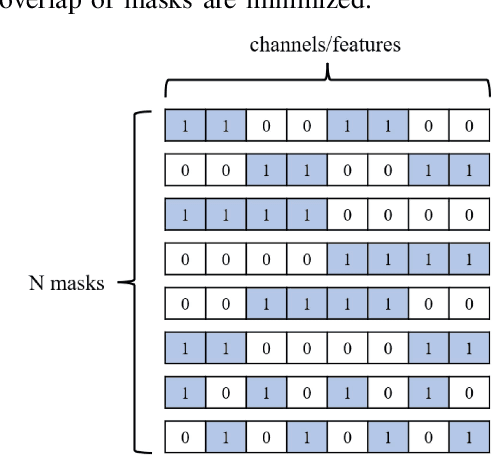
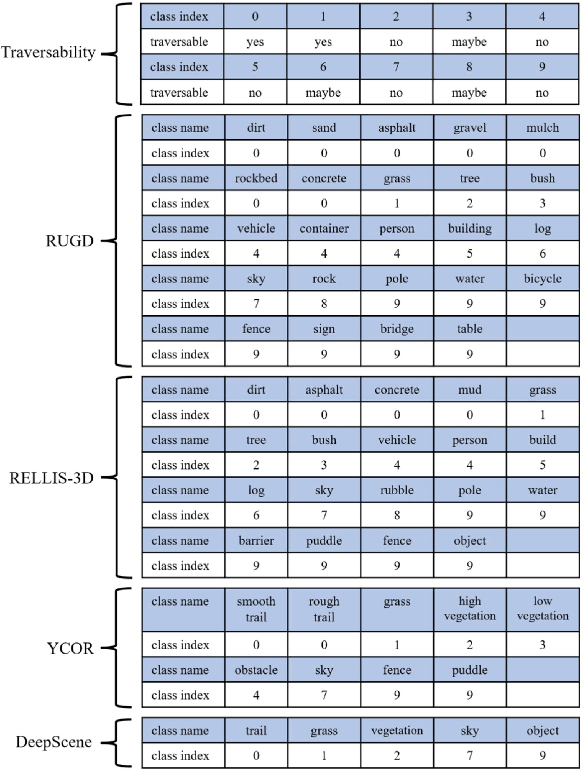
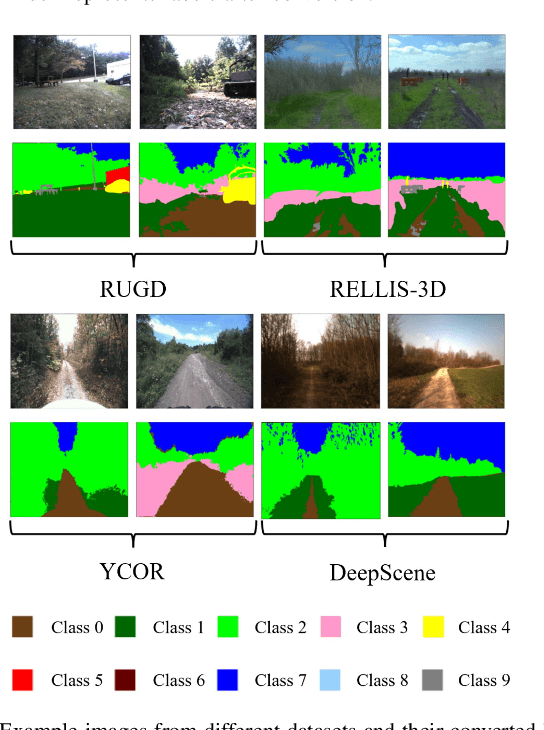
Off-road autonomous unmanned ground vehicles (UGVs) are being developed for military and commercial use to deliver crucial supplies in remote locations, help with mapping and surveillance, and to assist war-fighters in contested environments. Due to complexity of the off-road environments and variability in terrain, lighting conditions, diurnal and seasonal changes, the models used to perceive the environment must handle a lot of input variability. Current datasets used to train perception models for off-road autonomous navigation lack of diversity in seasons, locations, semantic classes, as well as time of day. We test the hypothesis that model trained on a single dataset may not generalize to other off-road navigation datasets and new locations due to the input distribution drift. Additionally, we investigate how to combine multiple datasets to train a semantic segmentation-based environment perception model and we show that training the model to capture uncertainty could improve the model performance by a significant margin. We extend the Masksembles approach for uncertainty quantification to the semantic segmentation task and compare it with Monte Carlo Dropout and standard baselines. Finally, we test the approach against data collected from a UGV platform in a new testing environment. We show that the developed perception model with uncertainty quantification can be feasibly deployed on an UGV to support online perception and navigation tasks.
Copula Entropy based Variable Selection for Survival Analysis
Sep 04, 2022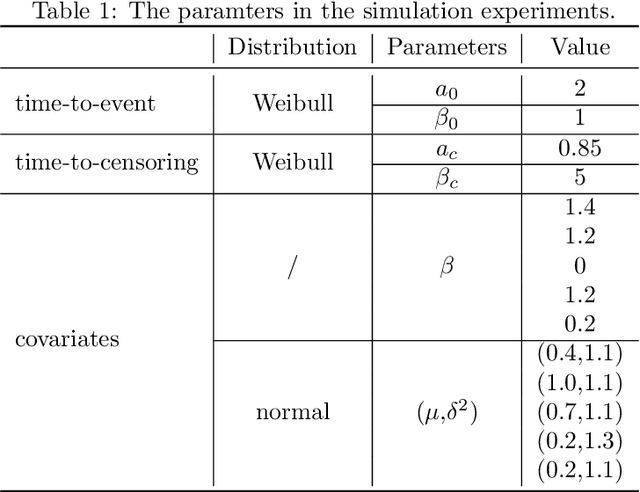
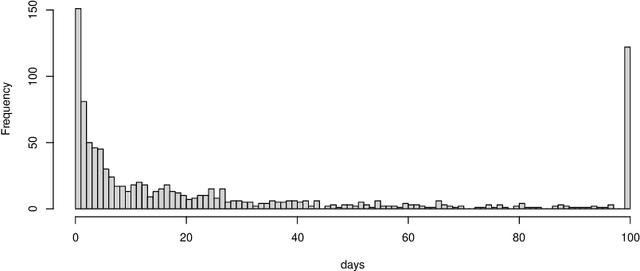
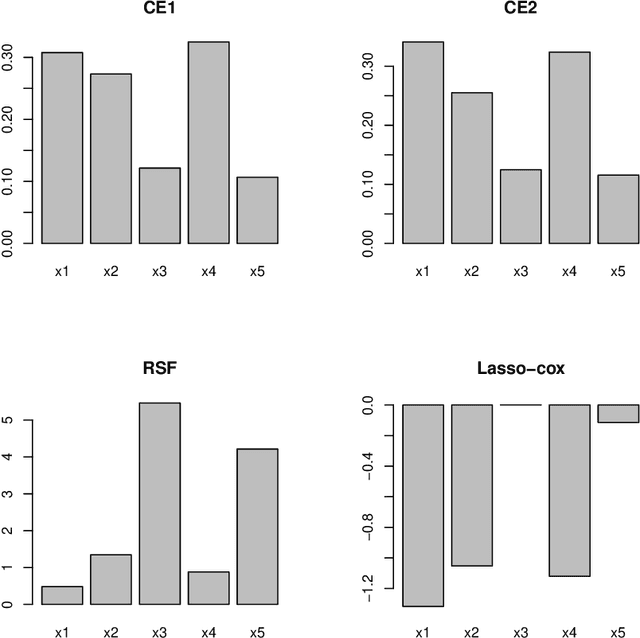

Variable selection is an important problem in statistics and machine learning. Copula Entropy (CE) is a mathematical concept for measuring statistical independence and has been applied to variable selection recently. In this paper we propose to apply the CE-based method for variable selection to survival analysis. The idea is to measure the correlation between variables and time-to-event with CE and then select variables according to their CE value. Experiments on simulated data and two real cancer data were conducted to compare the proposed method with two related methods: random survival forest and Lasso-Cox. Experimental results showed that the proposed method can select the 'right' variables out that are more interpretable and lead to better prediction performance.
Modelling Technical and Biological Effects in scRNA-seq data with Scalable GPLVMs
Sep 14, 2022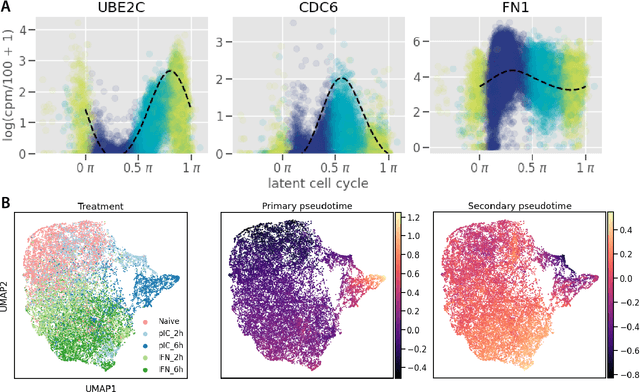
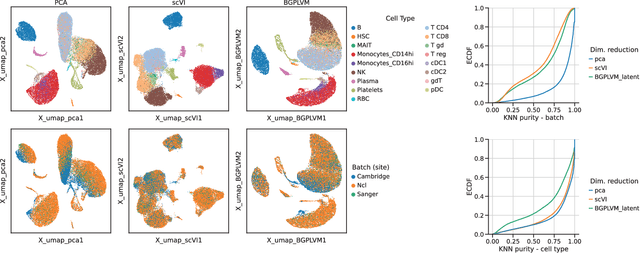
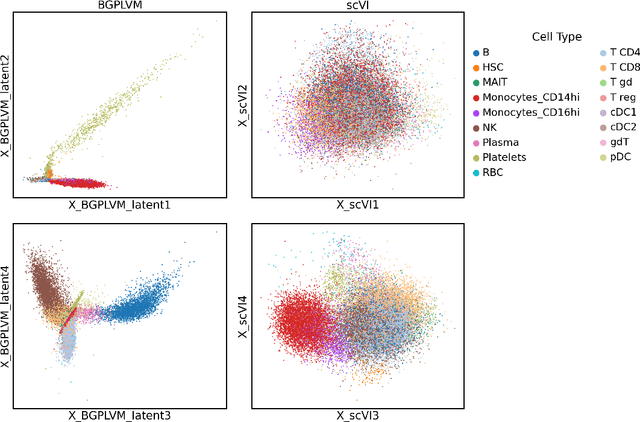
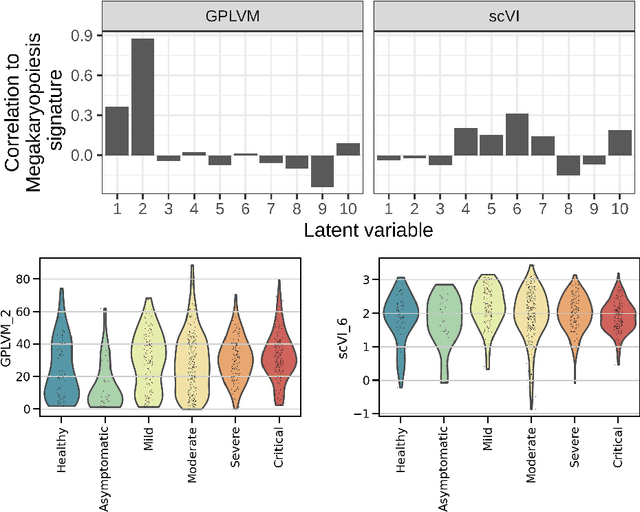
Single-cell RNA-seq datasets are growing in size and complexity, enabling the study of cellular composition changes in various biological/clinical contexts. Scalable dimensionality reduction techniques are in need to disentangle biological variation in them, while accounting for technical and biological confounders. In this work, we extend a popular approach for probabilistic non-linear dimensionality reduction, the Gaussian process latent variable model, to scale to massive single-cell datasets while explicitly accounting for technical and biological confounders. The key idea is to use an augmented kernel which preserves the factorisability of the lower bound allowing for fast stochastic variational inference. We demonstrate its ability to reconstruct latent signatures of innate immunity recovered in Kumasaka et al. (2021) with 9x lower training time. We further analyze a COVID dataset and demonstrate across a cohort of 130 individuals, that this framework enables data integration while capturing interpretable signatures of infection. Specifically, we explore COVID severity as a latent dimension to refine patient stratification and capture disease-specific gene expression.
Online Subset Selection using $α$-Core with no Augmented Regret
Sep 29, 2022
We consider the problem of sequential sparse subset selections in an online learning setup. Assume that the set $[N]$ consists of $N$ distinct elements. On the $t^{\text{th}}$ round, a monotone reward function $f_t: 2^{[N]} \to \mathbb{R}_+,$ which assigns a non-negative reward to each subset of $[N],$ is revealed to a learner. The learner selects (perhaps randomly) a subset $S_t \subseteq [N]$ of $k$ elements before the reward function $f_t$ for that round is revealed $(k \leq N)$. As a consequence of its choice, the learner receives a reward of $f_t(S_t)$ on the $t^{\text{th}}$ round. The learner's goal is to design an online subset selection policy to maximize its expected cumulative reward accrued over a given time horizon. In this connection, we propose an online learning policy called SCore (Subset Selection with Core) that solves the problem for a large class of reward functions. The proposed SCore policy is based on a new concept of $\alpha$-Core, which is a generalization of the notion of Core from the cooperative game theory literature. We establish a learning guarantee for the SCore policy in terms of a new performance metric called $\alpha$-augmented regret. In this new metric, the power of the offline benchmark is suitably augmented compared to the online policy. We give several illustrative examples to show that a broad class of reward functions, including submodular, can be efficiently learned with the SCore policy. We also outline how the SCore policy can be used under a semi-bandit feedback model and conclude the paper with a number of open problems.
Locally Constrained Representations in Reinforcement Learning
Sep 20, 2022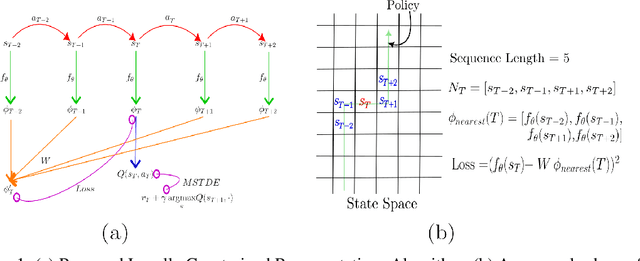
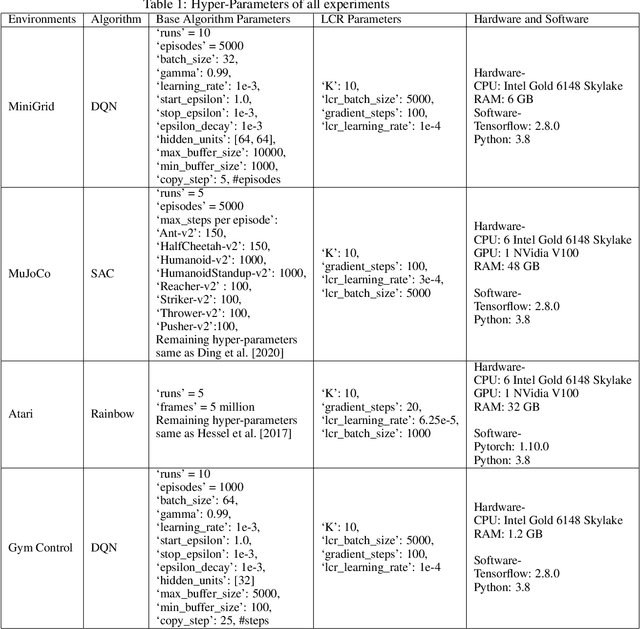
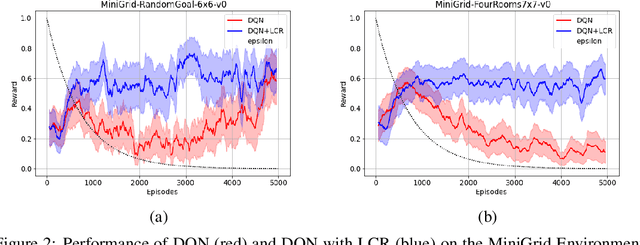
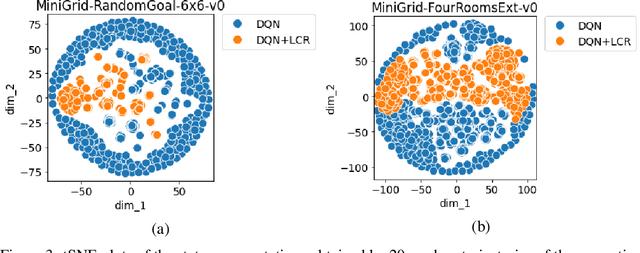
The success of Reinforcement Learning (RL) heavily relies on the ability to learn robust representations from the observations of the environment. In most cases, the representations learned purely by the reinforcement learning loss can differ vastly across states depending on how the value functions change. However, the representations learned need not be very specific to the task at hand. Relying only on the RL objective may yield representations that vary greatly across successive time steps. In addition, since the RL loss has a changing target, the representations learned would depend on how good the current values/policies are. Thus, disentangling the representations from the main task would allow them to focus more on capturing transition dynamics which can improve generalization. To this end, we propose locally constrained representations, where an auxiliary loss forces the state representations to be predictable by the representations of the neighbouring states. This encourages the representations to be driven not only by the value/policy learning but also self-supervised learning, which constrains the representations from changing too rapidly. We evaluate the proposed method on several known benchmarks and observe strong performance. Especially in continuous control tasks, our experiments show a significant advantage over a strong baseline.
Safe Autonomous Docking Maneuvers for a Floating Platform based on Input Sharing Control Barrier Functions
Sep 14, 2022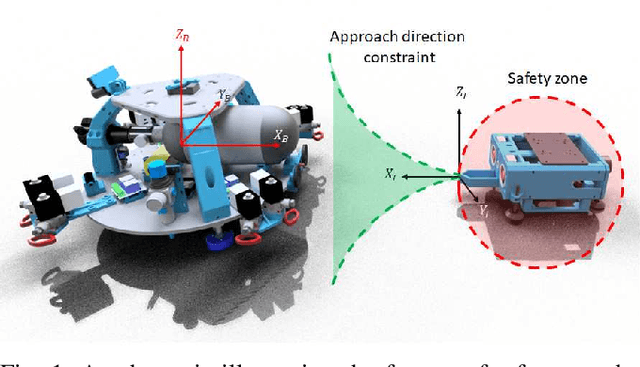
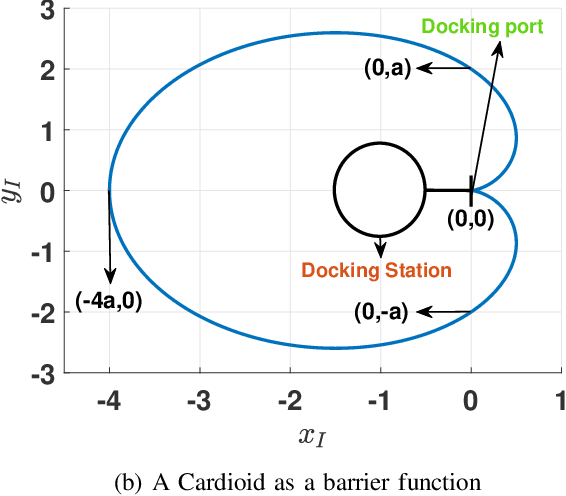
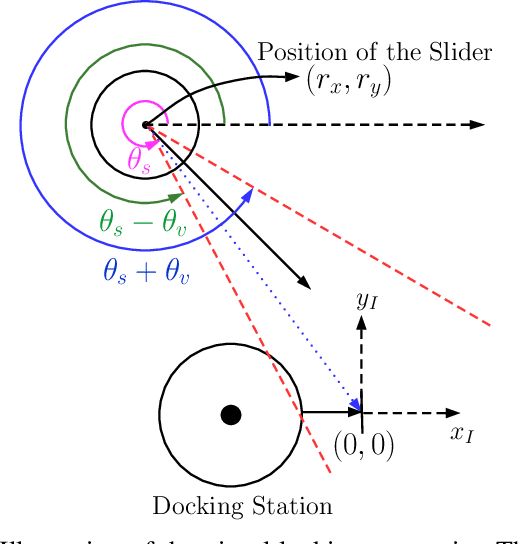
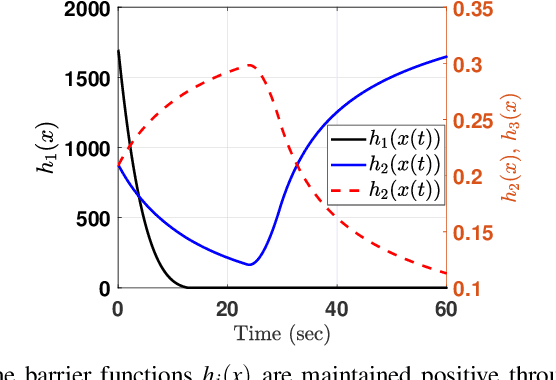
In this article, we present a control strategy for the problem of safe autonomous docking for a planar floating platform (Slider) that emulates the movement of a satellite. Employing the proposed strategy, Slider approaches a docking port with the right orientation, maintaining a safe distance, while always keeping a visual lock on the docking port throughout the docking maneuver. Control barrier functions are designed to impose the safety, direction of approach and visual locking constraints. Three control inputs of the Slider are shared among three barrier functions in enforcing the constraints. It is proved that the control inputs are shared in a conflict-free manner in rendering the sets defining safety and visual locking constraints forward invariant and in establishing finite-time convergence to the visual locking mode. The conflict-free input-sharing ensures the feasibility of a quadratic program that generates minimally-invasive corrections for a nominal controller, that is designed to track the docking port, so that the barrier constraints are respected throughout the docking maneuver. The efficacy of the proposed control design approach is validated through various simulations.