 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Supervised GAN Watermarking for Intellectual Property Protection
Sep 07, 2022
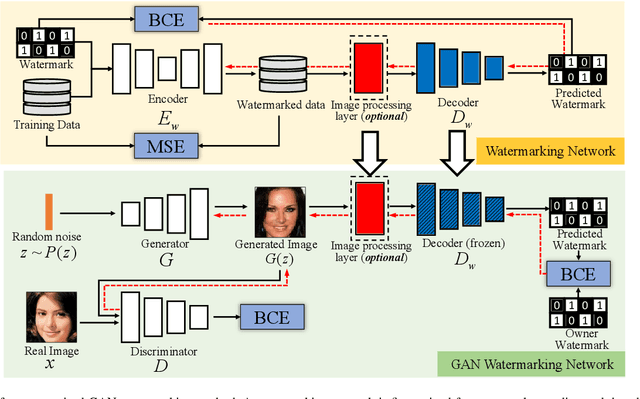

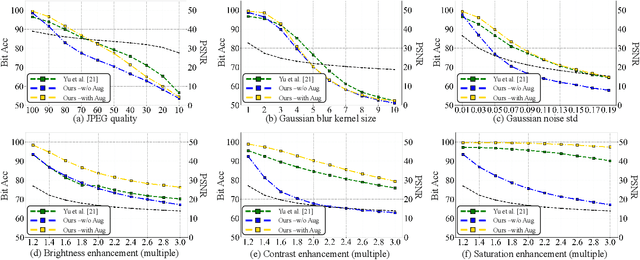

We propose a watermarking method for protecting the Intellectual Property (IP) of Generative Adversarial Networks (GANs). The aim is to watermark the GAN model so that any image generated by the GAN contains an invisible watermark (signature), whose presence inside the image can be checked at a later stage for ownership verification. To achieve this goal, a pre-trained CNN watermarking decoding block is inserted at the output of the generator. The generator loss is then modified by including a watermark loss term, to ensure that the prescribed watermark can be extracted from the generated images. The watermark is embedded via fine-tuning, with reduced time complexity. Results show that our method can effectively embed an invisible watermark inside the generated images. Moreover, our method is a general one and can work with different GAN architectures, different tasks, and different resolutions of the output image. We also demonstrate the good robustness performance of the embedded watermark against several post-processing, among them, JPEG compression, noise addition, blurring, and color transformations.
Intelligent Perception System for Vehicle-Road Cooperation
Aug 30, 2022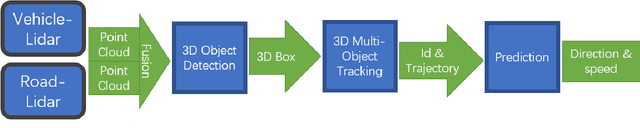

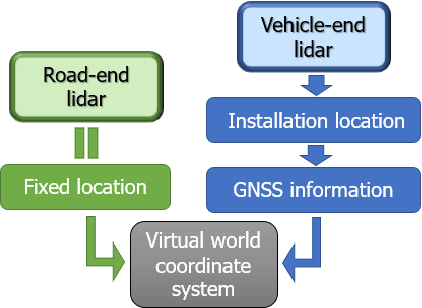

With the development of autonomous driving, the improvement of autonomous driving technology for individual vehicles has reached the bottleneck. The advancement of vehicle-road cooperation autonomous driving technology can expand the vehicle's perception range, supplement the perception blind area and improve the perception accuracy, to promote the development of autonomous driving technology and achieve vehicle-road integration. This project mainly uses lidar to develop data fusion schemes to realize the sharing and combination of vehicle and road equipment data and achieve the detection and tracking of dynamic targets. At the same time, some test scenarios for the vehicle-road cooperative system were designed and used to test our vehicle-road cooperative awareness system, which proved the advantages of vehicle-road cooperative autonomous driving over single-vehicle autonomous driving.
Benchmark Results for Bookshelf Organization Problem as Mixed Integer Nonlinear Program with Mode Switch and Collision Avoidance
Aug 28, 2022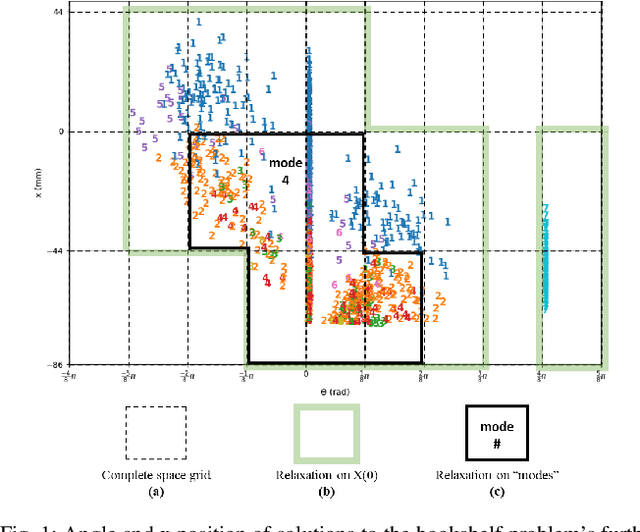


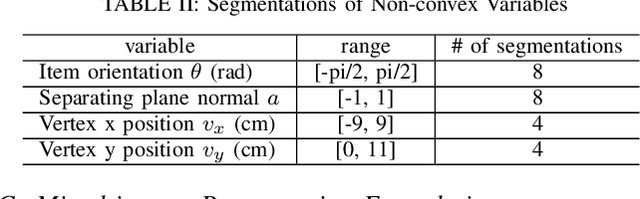
Mixed integer convex and nonlinear programs, MICP and MINLP, are expressive but require long solving times. Recent work that combines data-driven methods on solver heuristics has shown potential to overcome this issue allowing for applications on larger scale practical problems. To solve mixed-integer bilinear programs online with data-driven methods, several formulations exist including mathematical programming with complementary constraints (MPCC), mixed-integer programming (MIP). In this work, we benchmark the performances of those data-driven schemes on a bookshelf organization problem that has discrete mode switch and collision avoidance constraints. The success rate, optimal cost and solving time are compared along with non-data-driven methods. Our proposed methods are demonstrated as a high level planner for a robotic arm for the bookshelf problem.
Dynamic Maintenance of Kernel Density Estimation Data Structure: From Practice to Theory
Aug 08, 2022Kernel density estimation (KDE) stands out as a challenging task in machine learning. The problem is defined in the following way: given a kernel function $f(x,y)$ and a set of points $\{x_1, x_2, \cdots, x_n \} \subset \mathbb{R}^d$, we would like to compute $\frac{1}{n}\sum_{i=1}^{n} f(x_i,y)$ for any query point $y \in \mathbb{R}^d$. Recently, there has been a growing trend of using data structures for efficient KDE. However, the proposed KDE data structures focus on static settings. The robustness of KDE data structures over dynamic changing data distributions is not addressed. In this work, we focus on the dynamic maintenance of KDE data structures with robustness to adversarial queries. Especially, we provide a theoretical framework of KDE data structures. In our framework, the KDE data structures only require subquadratic spaces. Moreover, our data structure supports the dynamic update of the dataset in sublinear time. Furthermore, we can perform adaptive queries with the potential adversary in sublinear time.
A Failure Identification and Recovery Framework for a Planar Reconfigurable Cable Driven Parallel Robot
Sep 02, 2022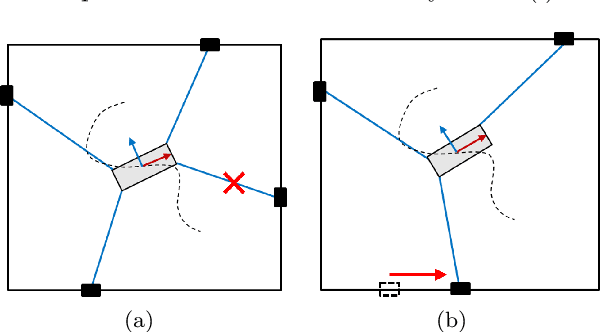
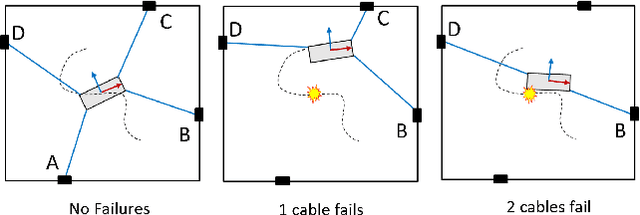
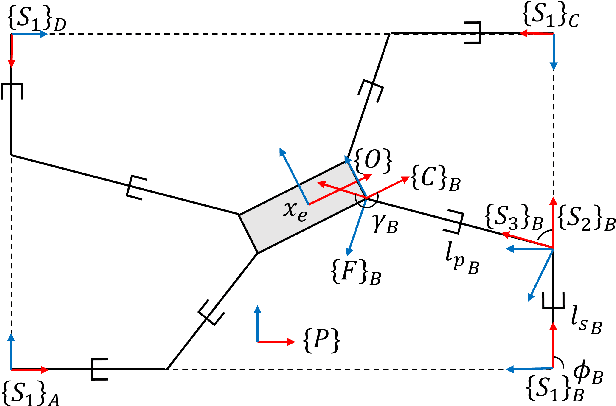
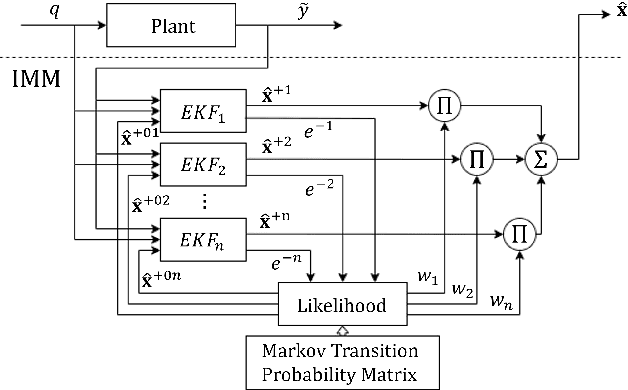
In cable driven parallel robots (CDPRs), a single cable malfunction usually induces complete failure of the entire robot. However, the lost static workspace (due to failure) can often be recovered through reconfiguration of the cable attachment points on the frame. This capability is introduced by adding kinematic redundancies to the robot in the form of moving linear sliders that are manipulated in a real-time redundancy resolution controller. The presented work combines this controller with an online failure detection framework to develop a complete fault tolerant control scheme for automatic task recovery. This solution provides robustness by combining pose estimation of the end-effector with the failure detection through the application of an Interactive Multiple Model (IMM) algorithm relying only on end-effector information. The failure and pose estimation scheme is then tied into the redundancy resolution approach to produce a seamless automatic task (trajectory) recovery approach for cable failures.
Cooperative trajectory planning algorithm of USV-UAV with hull dynamic constraints
Sep 07, 2022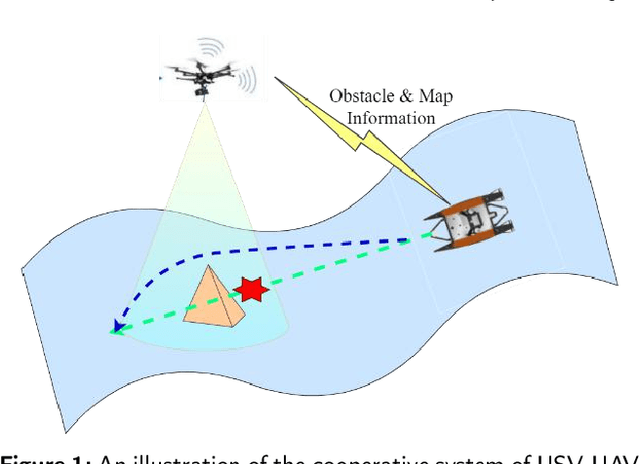

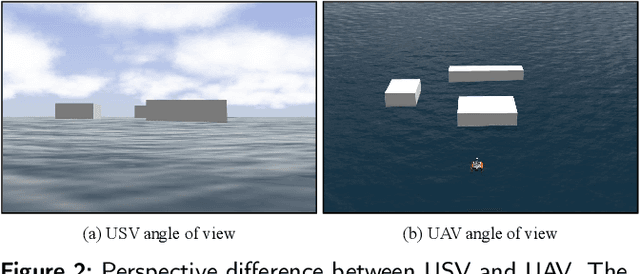
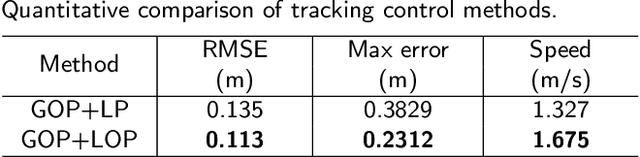
Efficient trajectory generation in complex dynamic environment stills remains an open problem in the unmanned surface vehicle (USV) domain. In this paper, a cooperative trajectory planning algorithm for the coupled USV-UAV system is proposed, to ensure that USV can execute safe and smooth path in the process of autonomous advance in multi obstacle maps. Specifically, the unmanned aerial vehicle (UAV) plays the role as a flight sensor, and it provides real-time global map and obstacle information with lightweight semantic segmentation network and 3D projection transformation. And then an initial obstacle avoidance trajectory is generated by a graph-based search method. Concerning the unique under-actuated kinematic characteristics of the USV, a numerical optimization method based on hull dynamic constraints is introduced to make the trajectory easier to be tracked for motion control. Finally, a motion control method based on NMPC with the lowest energy consumption constraint during execution is proposed. Experimental results verify the effectiveness of whole system, and the generated trajectory is locally optimal for USV with considerable tracking accuracy.
Real-time FPGA Design for OMP Targeting 8K Image Reconstruction
Oct 10, 2021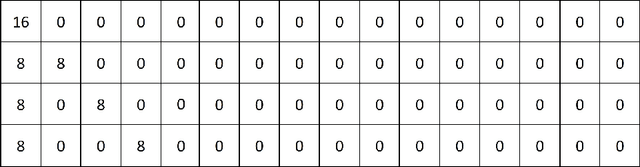
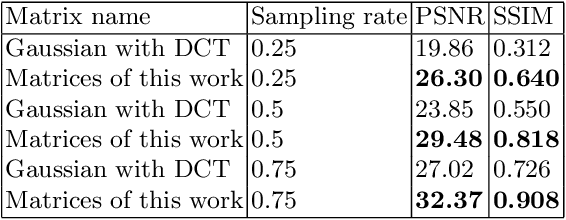

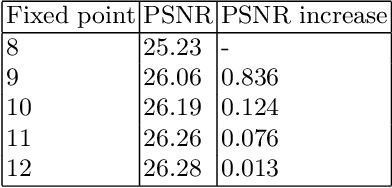
During the past decade, implementing reconstruction algorithms on hardware has been at the center of much attention in the field of real-time reconstruction in Compressed Sensing (CS). Orthogonal Matching Pursuit (OMP) is the most widely used reconstruction algorithm on hardware implementation because OMP obtains good quality reconstruction results under a proper time cost. OMP includes Dot Product (DP) and Least Square Problem (LSP). These two parts have numerous division calculations and considerable vector-based multiplications, which limit the implementation of real-time reconstruction on hardware. In the theory of CS, besides the reconstruction algorithm, the choice of sensing matrix affects the quality of reconstruction. It also influences the reconstruction efficiency by affecting the hardware architecture. Thus, designing a real-time hardware architecture of OMP needs to take three factors into consideration. The choice of sensing matrix, the implementation of DP and LSP. In this paper, a sensing matrix, which is sparsity and contains zero vectors mainly, is adopted to optimize the OMP reconstruction to break the bottleneck of reconstruction efficiency. Based on the features of the chosen matrix, the DP and LSP are implemented by simple shift, add and comparing procedures. This work is implemented on the Xilinx Virtex UltraScale+ FPGA device. To reconstruct a digital signal with 1024 length under 0.25 sampling rate, the proposal method costs 0.818us while the state-of-the-art costs 238$us. Thus, this work speedups the state-of-the-art method 290 times. This work costs 0.026s to reconstruct an 8K gray image, which achieves 30FPS real-time reconstruction.
OmniVL:One Foundation Model for Image-Language and Video-Language Tasks
Sep 15, 2022
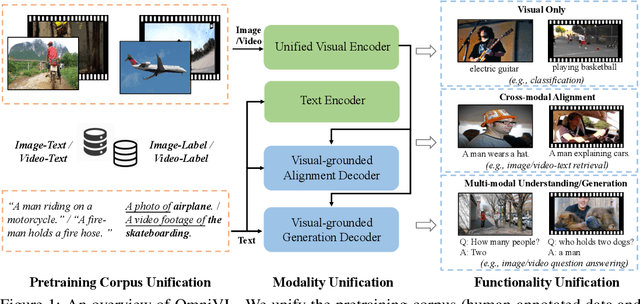
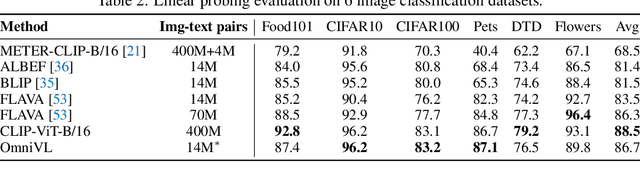
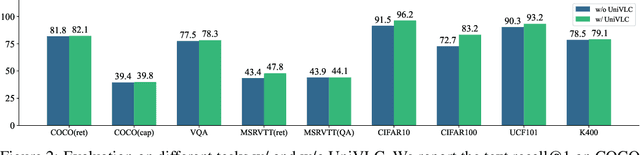
This paper presents OmniVL, a new foundation model to support both image-language and video-language tasks using one universal architecture. It adopts a unified transformer-based visual encoder for both image and video inputs, and thus can perform joint image-language and video-language pretraining. We demonstrate, for the first time, such a paradigm benefits both image and video tasks, as opposed to the conventional one-directional transfer (e.g., use image-language to help video-language). To this end, we propose a decoupled joint pretraining of image-language and video-language to effectively decompose the vision-language modeling into spatial and temporal dimensions and obtain performance boost on both image and video tasks. Moreover, we introduce a novel unified vision-language contrastive (UniVLC) loss to leverage image-text, video-text, image-label (e.g., image classification), video-label (e.g., video action recognition) data together, so that both supervised and noisily supervised pretraining data are utilized as much as possible. Without incurring extra task-specific adaptors, OmniVL can simultaneously support visual only tasks (e.g., image classification, video action recognition), cross-modal alignment tasks (e.g., image/video-text retrieval), and multi-modal understanding and generation tasks (e.g., image/video question answering, captioning). We evaluate OmniVL on a wide range of downstream tasks and achieve state-of-the-art or competitive results with similar model size and data scale.
Improving Fuzzy-Logic based Map-Matching Method with Trajectory Stay-Point Detection
Aug 04, 2022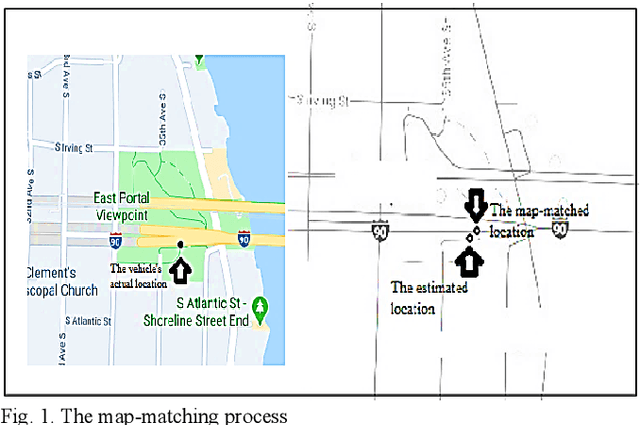
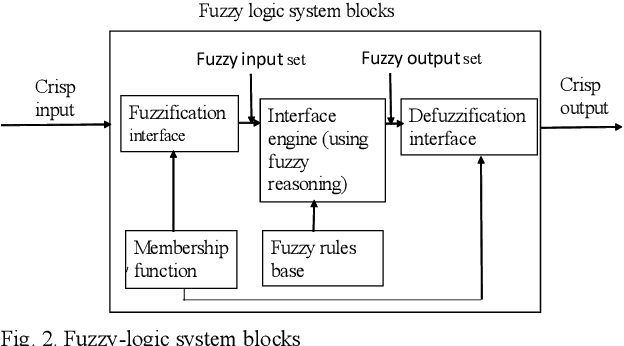
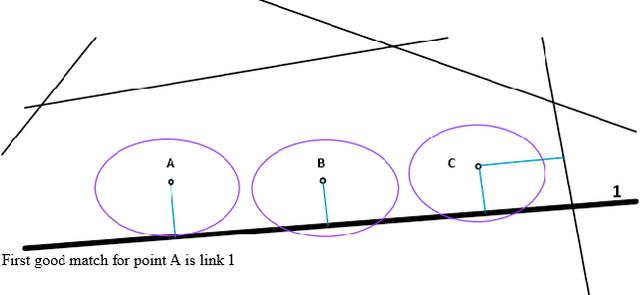
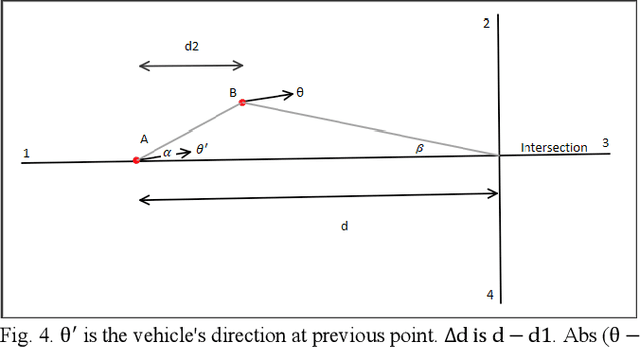
The requirement to trace and process moving objects in the contemporary era gradually increases since numerous applications quickly demand precise moving object locations. The Map-matching method is employed as a preprocessing technique, which matches a moving object point on a corresponding road. However, most of the GPS trajectory datasets include stay-points irregularity, which makes map-matching algorithms mismatch trajectories to irrelevant streets. Therefore, determining the stay-point region in GPS trajectory datasets results in better accurate matching and more rapid approaches. In this work, we cluster stay-points in a trajectory dataset with DBSCAN and eliminate redundant data to improve the efficiency of the map-matching algorithm by lowering processing time. We reckoned our proposed method's performance and exactness with a ground truth dataset compared to a fuzzy-logic based map-matching algorithm. Fortunately, our approach yields 27.39% data size reduction and 8.9% processing time reduction with the same accurate results as the previous fuzzy-logic based map-matching approach.
Downlink Interference Analysis of UAV-based mmWave Fronthaul for Small Cell Networks
Aug 11, 2022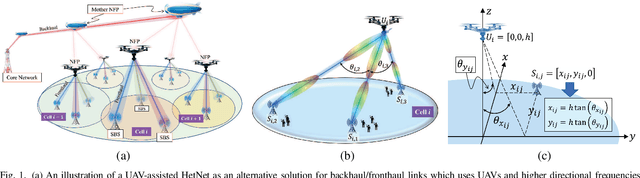
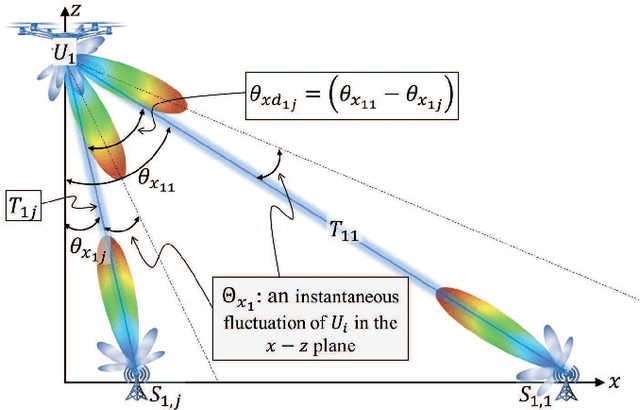
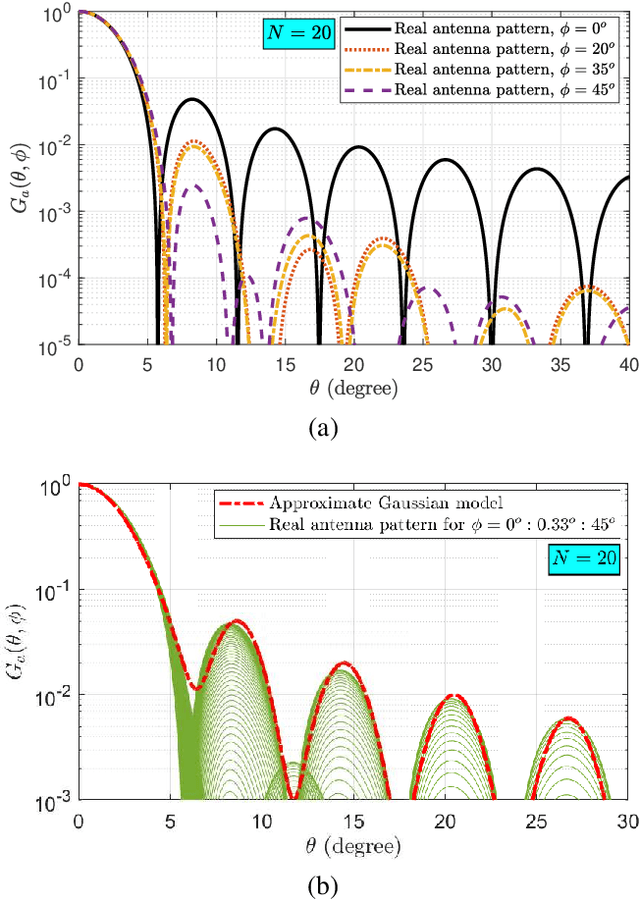
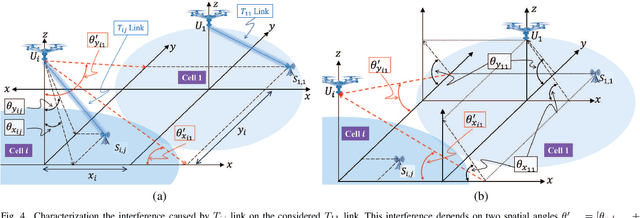
In this paper, an unmanned aerial vehicles (UAV)-based heterogeneous network is studied to solve the problem of transferring massive traffic of distributed small cells to the core network. First, a detailed three-dimensional (3D) model of the downlink channel is characterized by taking into account the real antenna pattern, UAVs' vibrations, random distribution of small cell base stations (SBSs), and the position of UAVs in 3D space. Then, a rigorous analysis of interference is performed for two types pf interference: intra-cell interference and inter-cell interference. The interference analysis results are then used to derive an upper bound of outage probability on the considered system. Using numerical results show that the analytical and simulation results match one another. The results show that, in the presence of UAV's fluctuations, optimizing radiation pattern shape requires balancing an inherent tradeoff between increasing pattern gain to reduce the interference as well as to compensate large path loss at mmWave frequencies and decreasing it to alleviate the adverse effect of a UAV's vibrations. The analytical derivations enable the derivation of the optimal antenna pattern for any condition in a short time instead of using time-consuming extensive simulations.