 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
pFedDef: Defending Grey-Box Attacks for Personalized Federated Learning
Sep 17, 2022
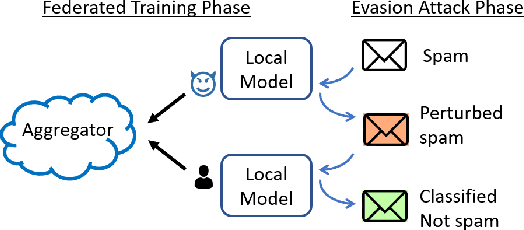
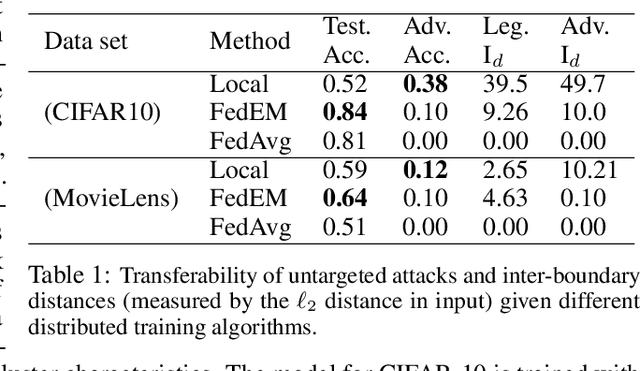
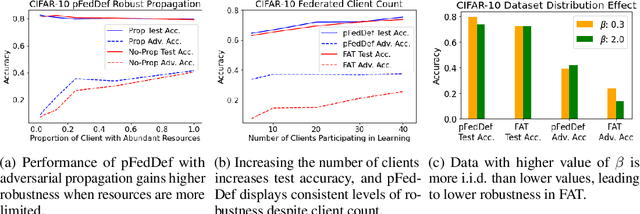

Personalized federated learning allows for clients in a distributed system to train a neural network tailored to their unique local data while leveraging information at other clients. However, clients' models are vulnerable to attacks during both the training and testing phases. In this paper we address the issue of adversarial clients crafting evasion attacks at test time to deceive other clients. For example, adversaries may aim to deceive spam filters and recommendation systems trained with personalized federated learning for monetary gain. The adversarial clients have varying degrees of personalization based on the method of distributed learning, leading to a "grey-box" situation. We are the first to characterize the transferability of such internal evasion attacks for different learning methods and analyze the trade-off between model accuracy and robustness depending on the degree of personalization and similarities in client data. We introduce a defense mechanism, pFedDef, that performs personalized federated adversarial training while respecting resource limitations at clients that inhibit adversarial training. Overall, pFedDef increases relative grey-box adversarial robustness by 62% compared to federated adversarial training and performs well even under limited system resources.
DevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022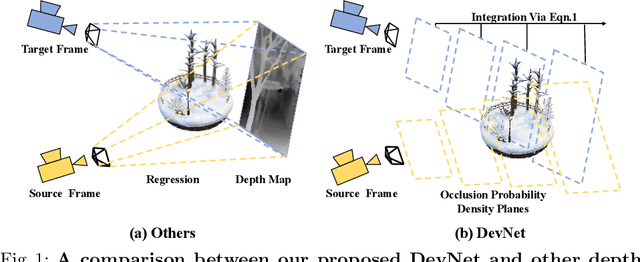
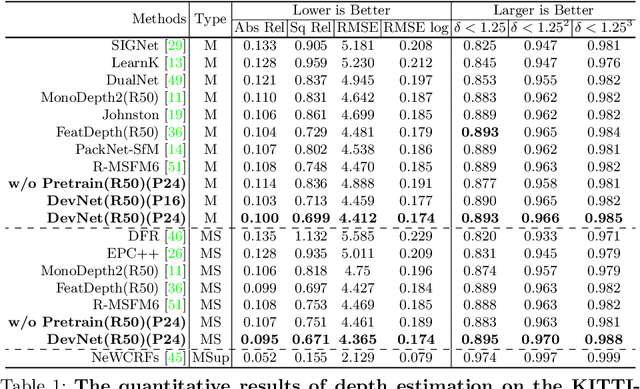
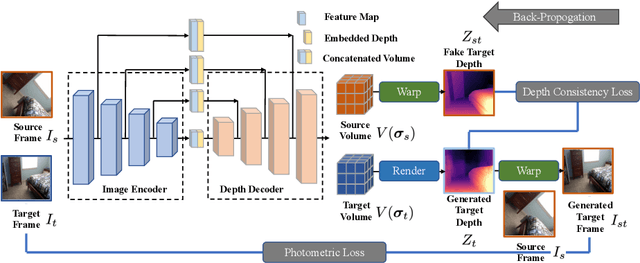

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.
DeepVol: Volatility Forecasting from High-Frequency Data with Dilated Causal Convolutions
Sep 23, 2022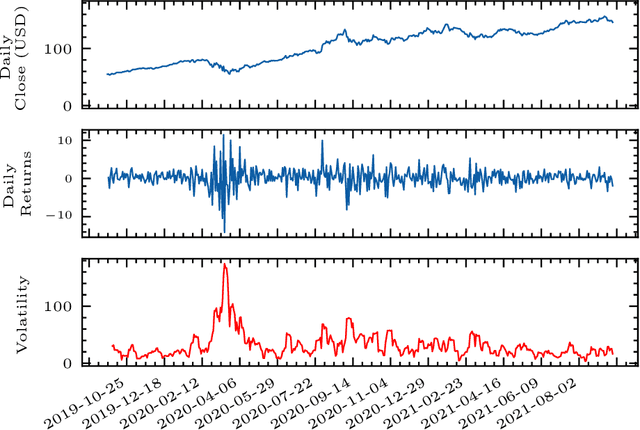
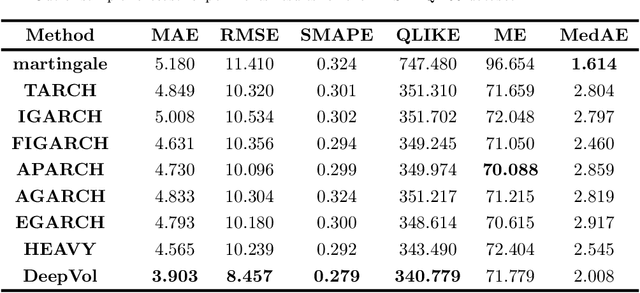
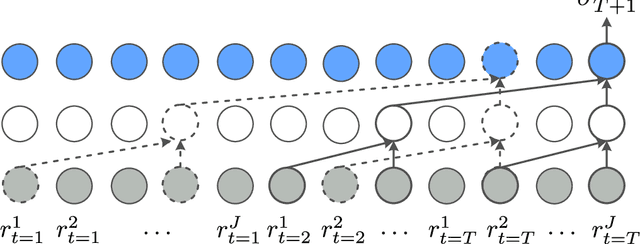
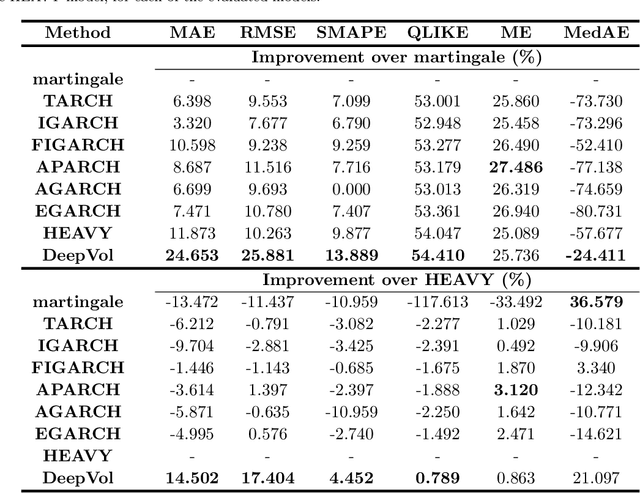
Volatility forecasts play a central role among equity risk measures. Besides traditional statistical models, modern forecasting techniques, based on machine learning, can readily be employed when treating volatility as a univariate, daily time-series. However, econometric studies have shown that increasing the number of daily observations with high-frequency intraday data helps to improve predictions. In this work, we propose DeepVol, a model based on Dilated Causal Convolutions to forecast day-ahead volatility by using high-frequency data. We show that the dilated convolutional filters are ideally suited to extract relevant information from intraday financial data, thereby naturally mimicking (via a data-driven approach) the econometric models which incorporate realised measures of volatility into the forecast. This allows us to take advantage of the abundance of intraday observations, helping us to avoid the limitations of models that use daily data, such as model misspecification or manually designed handcrafted features, whose devise involves optimising the trade-off between accuracy and computational efficiency and makes models prone to lack of adaptation into changing circumstances. In our analysis, we use two years of intraday data from NASDAQ-100 to evaluate DeepVol's performance. The reported empirical results suggest that the proposed deep learning-based approach learns global features from high-frequency data, achieving more accurate predictions than traditional methodologies, yielding to more appropriate risk measures.
PADLoC: LiDAR-Based Deep Loop Closure Detection and Registration using Panoptic Attention
Sep 20, 2022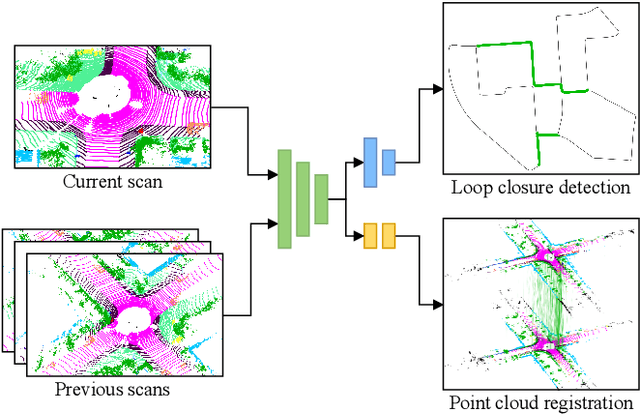
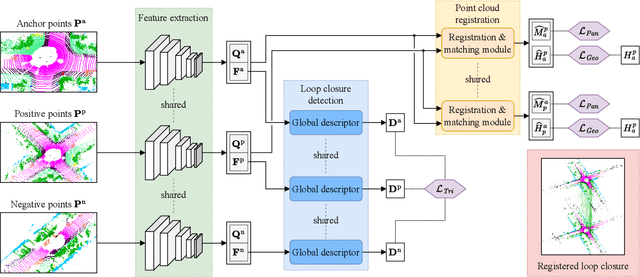
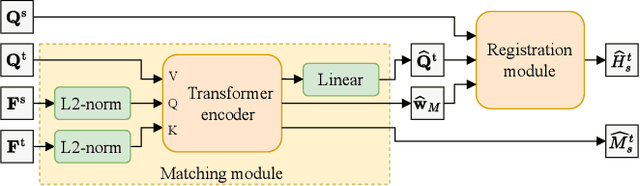
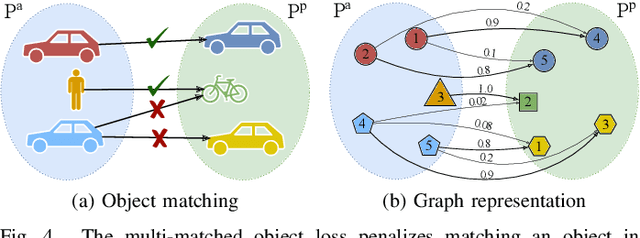
A key component of graph-based SLAM systems is the ability to detect loop closures in a trajectory to reduce the drift accumulated over time from the odometry. Most LiDAR-based methods achieve this goal by using only the geometric information, disregarding the semantics of the scene. In this work, we introduce PADLoC, a LiDAR-based loop closure detection and registration architecture comprising a shared 3D convolutional feature extraction backbone, a global descriptor head for loop closure detection, and a novel transformer-based head for point cloud matching and registration. We present multiple methods for estimating the point-wise matching confidence based on diversity indices. Additionally, to improve forward-backward consistency, we propose the use of two shared matching and registration heads with their source and target inputs swapped by exploiting that the estimated relative transformations must be inverse of each other. Furthermore, we leverage panoptic information during training in the form of a novel loss function that reframes the matching problem as a classification task in the case of the semantic labels and as a graph connectivity assignment for the instance labels. We perform extensive evaluations of PADLoC on multiple real-world datasets demonstrating that it achieves state-of-the-art performance. The code of our work is publicly available at http://padloc.cs.uni-freiburg.de.
Joint Delay and Phase Precoding Under True-Time Delay Constraint for THz Massive MIMO
Nov 19, 2021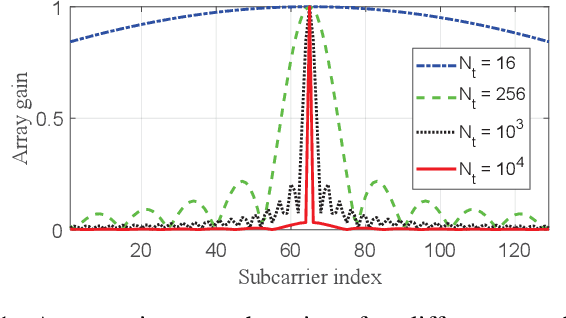
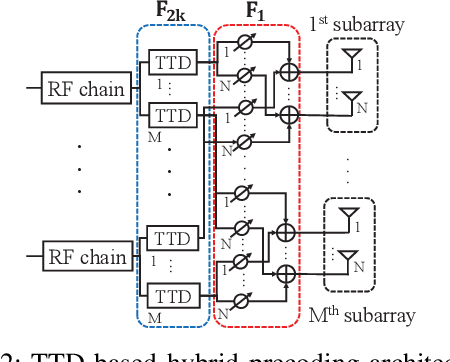
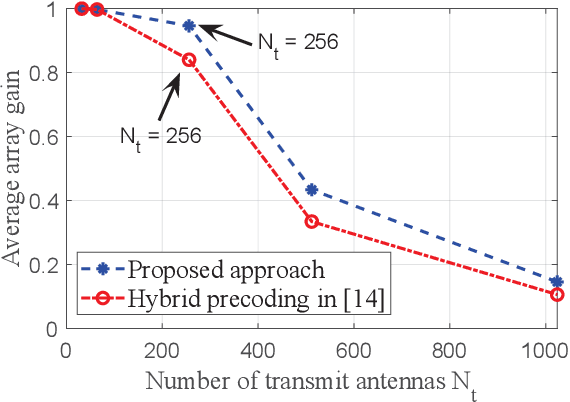
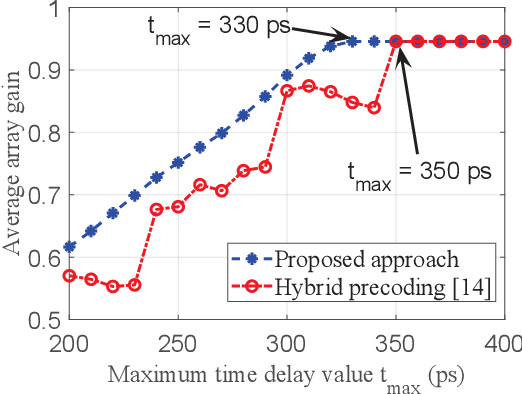
A new approach is presented to the problem of compensating the beam squint effect arising in wideband terahertz (THz) hybrid massive multiple-input multiple-output (MIMO) systems, based on the joint optimization of the phase shifter (PS) and true-time delay (TTD) values under per-TTD device time delay constraints. Unlike the prior approaches, the new approach does not require the unbounded time delay assumption; the range of time delay values that a TTD device can produce is strictly limited in our approach. Instead of focusing on the design of TTD values, we jointly optimize both the TTD and PS values to effectively cope with the practical time delay constraint. Simulation results that illustrate the performance benefits of the new method for the beam squint compensation are presented. Through simulations and analysis, we show that our approach is a generalization of the prior TTD-based precoding approaches.
Mel Spectrogram Inversion with Stable Pitch
Aug 26, 2022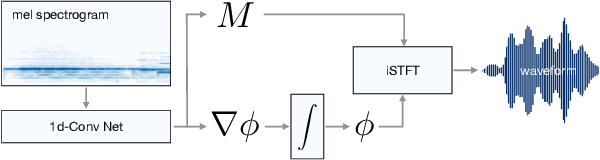
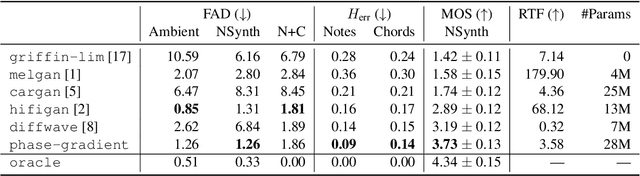
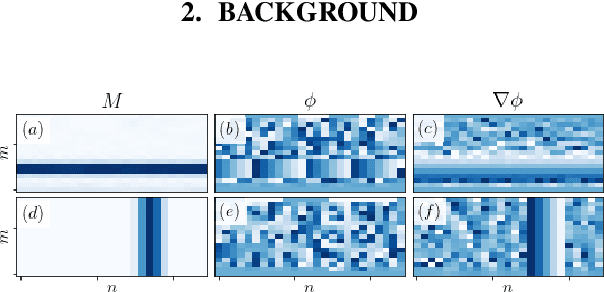
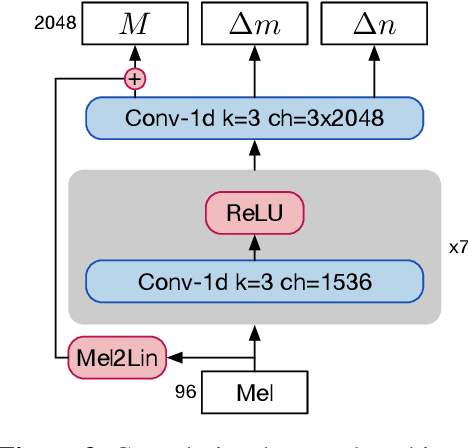
Vocoders are models capable of transforming a low-dimensional spectral representation of an audio signal, typically the mel spectrogram, to a waveform. Modern speech generation pipelines use a vocoder as their final component. Recent vocoder models developed for speech achieve a high degree of realism, such that it is natural to wonder how they would perform on music signals. Compared to speech, the heterogeneity and structure of the musical sound texture offers new challenges. In this work we focus on one specific artifact that some vocoder models designed for speech tend to exhibit when applied to music: the perceived instability of pitch when synthesizing sustained notes. We argue that the characteristic sound of this artifact is due to the lack of horizontal phase coherence, which is often the result of using a time-domain target space with a model that is invariant to time-shifts, such as a convolutional neural network. We propose a new vocoder model that is specifically designed for music. Key to improving the pitch stability is the choice of a shift-invariant target space that consists of the magnitude spectrum and the phase gradient. We discuss the reasons that inspired us to re-formulate the vocoder task, outline a working example, and evaluate it on musical signals. Our method results in 60% and 10% improved reconstruction of sustained notes and chords with respect to existing models, using a novel harmonic error metric.
Denoising MCMC for Accelerating Diffusion-Based Generative Models
Sep 29, 2022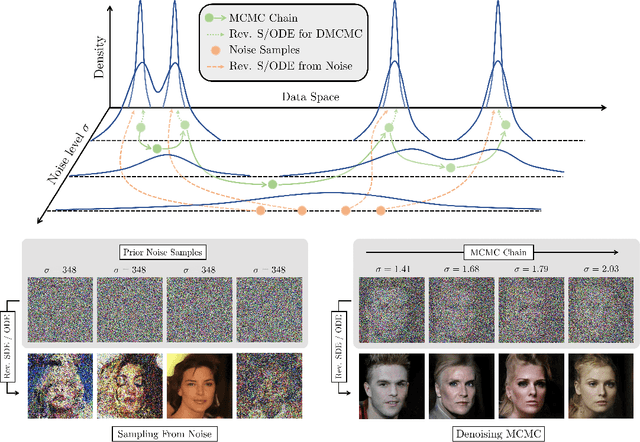
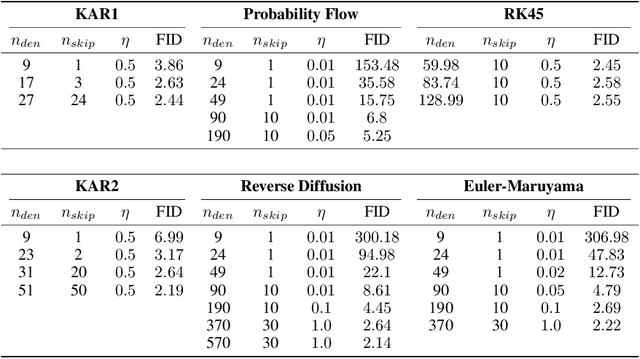
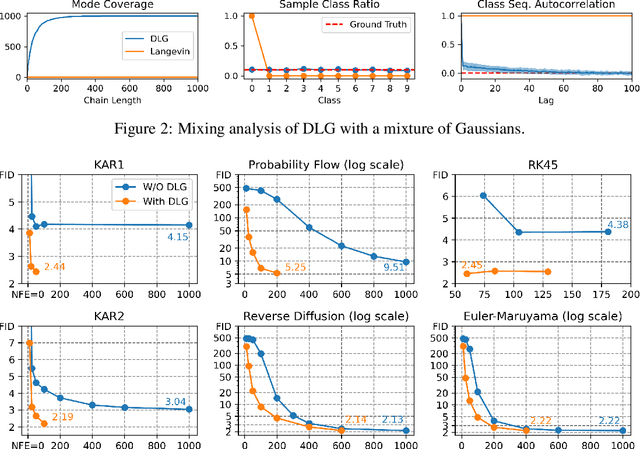
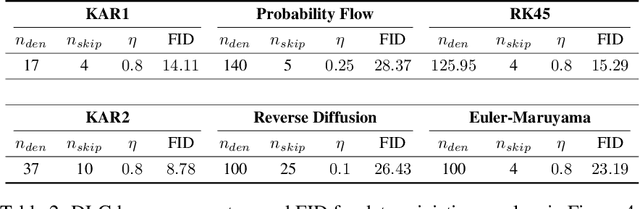
Diffusion models are powerful generative models that simulate the reverse of diffusion processes using score functions to synthesize data from noise. The sampling process of diffusion models can be interpreted as solving the reverse stochastic differential equation (SDE) or the ordinary differential equation (ODE) of the diffusion process, which often requires up to thousands of discretization steps to generate a single image. This has sparked a great interest in developing efficient integration techniques for reverse-S/ODEs. Here, we propose an orthogonal approach to accelerating score-based sampling: Denoising MCMC (DMCMC). DMCMC first uses MCMC to produce samples in the product space of data and variance (or diffusion time). Then, a reverse-S/ODE integrator is used to denoise the MCMC samples. Since MCMC traverses close to the data manifold, the computation cost of producing a clean sample for DMCMC is much less than that of producing a clean sample from noise. To verify the proposed concept, we show that Denoising Langevin Gibbs (DLG), an instance of DMCMC, successfully accelerates all six reverse-S/ODE integrators considered in this work on the tasks of CIFAR10 and CelebA-HQ-256 image generation. Notably, combined with integrators of Karras et al. (2022) and pre-trained score models of Song et al. (2021b), DLG achieves SOTA results. In the limited number of score function evaluation (NFE) settings on CIFAR10, we have $3.86$ FID with $\approx 10$ NFE and $2.63$ FID with $\approx 20$ NFE. On CelebA-HQ-256, we have $6.99$ FID with $\approx 160$ NFE, which beats the current best record of Kim et al. (2022) among score-based models, $7.16$ FID with $4000$ NFE. Code: https://github.com/1202kbs/DMCMC
Algebraic Reduction of Hidden Markov Models
Aug 11, 2022The problem of reducing a Hidden Markov Model (HMM) to a one of smaller dimension that exactly reproduces the same marginals is tackled by using a system-theoretic approach, adapted to HMMs by leveraging on a suitable algebraic representation of probability spaces. We propose two algorithms that return coarse-grained equivalent HMMs obtained by stochastic projection operators: the first returns models that reproduce the single-time distribution of a given output process, while in the second the full (multi-time) distribution is preserved. The reduction method exploits not only the structure of the observed output, but also its initial condition, whenever the latter is known or belongs to a given subclass. Optimal algorithms are derived for a class of HMM, namely observable ones. In the general case, we propose algorithms that have produced minimal models for all the examples we analyzed, and conjecture their optimality.
Analysis Of The Anytime MAPF Solvers Based On The Combination Of Conflict-Based Search (CBS) and Focal Search (FS)
Sep 20, 2022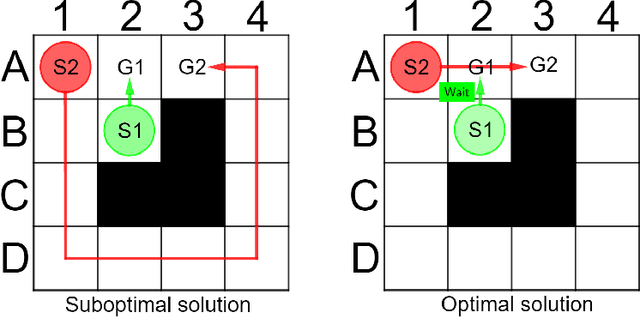
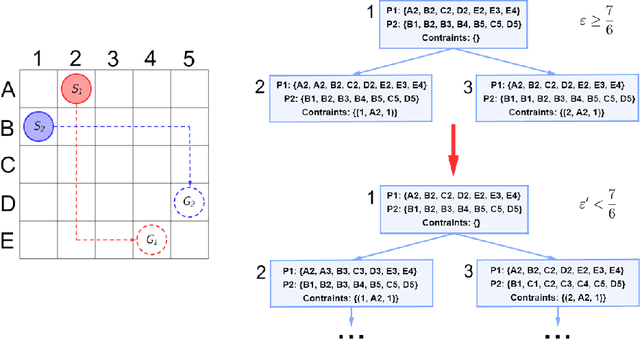
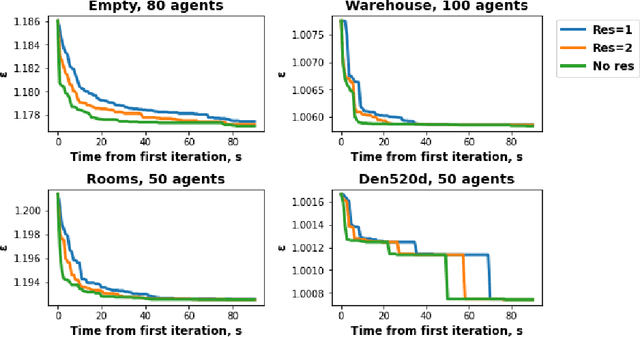
Conflict-Based Search (CBS) is a widely used algorithm for solving multi-agent pathfinding (MAPF) problems optimally. The core idea of CBS is to run hierarchical search, when, on the high level the tree of solutions candidates is explored, and on the low-level an individual planning for a specific agent (subject to certain constraints) is carried out. To trade-off optimality for running time different variants of bounded sub-optimal CBS were designed, which alter both high- and low-level search routines of CBS. Moreover, anytime variant of CBS does exist that applies Focal Search (FS) to the high-level of CBS - Anytime BCBS. However, no comprehensive analysis of how well this algorithm performs compared to the naive one, when we simply re-invoke CBS with the decreased sub-optimality bound, was present. This work aims at filling this gap. Moreover, we present and evaluate another anytime version of CBS that uses FS on both levels of CBS. Empirically, we show that its behavior is principally different from the one demonstrated by Anytime BCBS. Finally, we compare both algorithms head-to-head and show that using Focal Search on both levels of CBS can be beneficial in a wide range of setups.
Proceedings Fourth International Workshop on Formal Methods for Autonomous Systems (FMAS) and Fourth International Workshop on Automated and verifiable Software sYstem DEvelopment (ASYDE)
Sep 27, 2022This EPTCS volume contains the joint proceedings for the fourth international workshop on Formal Methods for Autonomous Systems (FMAS 2022) and the fourth international workshop on Automated and verifiable Software sYstem DEvelopment (ASYDE 2022), which were held on the 26th and 27th of September 2022. FMAS 2022 and ASYDE 2022 were held in conjunction with 20th International Conference on Software Engineering and Formal Methods (SEFM'22), at Humboldt University in Berlin. For FMAS, this year's workshop was our return to having in-person attendance after two editions of FMAS that were entirely online because of the restrictions necessitated by COVID-19. We were also keen to ensure that FMAS 2022 remained easily accessible to people who were unable to travel, so the workshop facilitated remote presentation and attendance. The goal of FMAS is to bring together leading researchers who are using formal methods to tackle the unique challenges presented by autonomous systems, to share their recent and ongoing work. Autonomous systems are highly complex and present unique challenges for the application of formal methods. Autonomous systems act without human intervention, and are often embedded in a robotic system, so that they can interact with the real world. As such, they exhibit the properties of safety-critical, cyber-physical, hybrid, and real-time systems. We are interested in work that uses formal methods to specify, model, or verify autonomous and/or robotic systems; in whole or in part. We are also interested in successful industrial applications and potential directions for this emerging application of formal methods.