 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reconstruction-guided attention improves the robustness and shape processing of neural networks
Sep 27, 2022
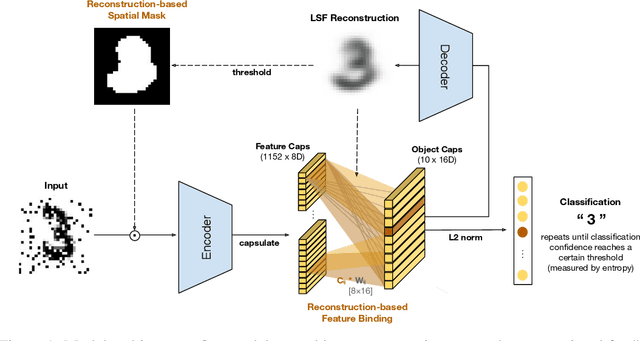
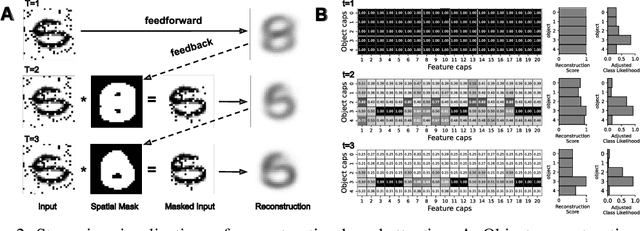
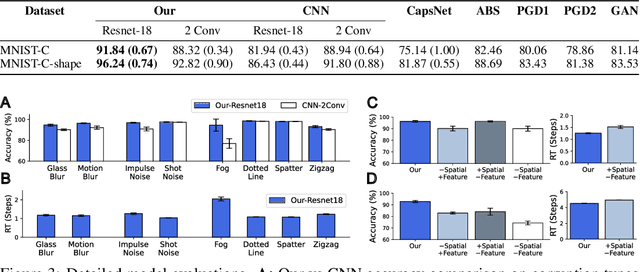
Many visual phenomena suggest that humans use top-down generative or reconstructive processes to create visual percepts (e.g., imagery, object completion, pareidolia), but little is known about the role reconstruction plays in robust object recognition. We built an iterative encoder-decoder network that generates an object reconstruction and used it as top-down attentional feedback to route the most relevant spatial and feature information to feed-forward object recognition processes. We tested this model using the challenging out-of-distribution digit recognition dataset, MNIST-C, where 15 different types of transformation and corruption are applied to handwritten digit images. Our model showed strong generalization performance against various image perturbations, on average outperforming all other models including feedforward CNNs and adversarially trained networks. Our model is particularly robust to blur, noise, and occlusion corruptions, where shape perception plays an important role. Ablation studies further reveal two complementary roles of spatial and feature-based attention in robust object recognition, with the former largely consistent with spatial masking benefits in the attention literature (the reconstruction serves as a mask) and the latter mainly contributing to the model's inference speed (i.e., number of time steps to reach a certain confidence threshold) by reducing the space of possible object hypotheses. We also observed that the model sometimes hallucinates a non-existing pattern out of noise, leading to highly interpretable human-like errors. Our study shows that modeling reconstruction-based feedback endows AI systems with a powerful attention mechanism, which can help us understand the role of generating perception in human visual processing.
Generalized Wasserstein Dice Loss, Test-time Augmentation, and Transformers for the BraTS 2021 challenge
Dec 24, 2021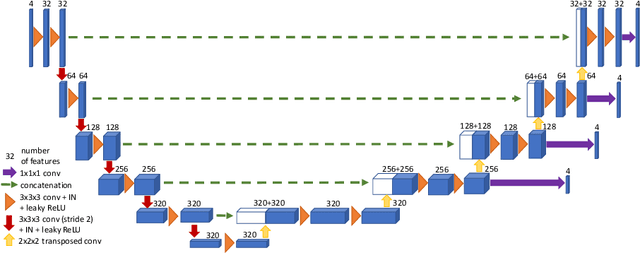
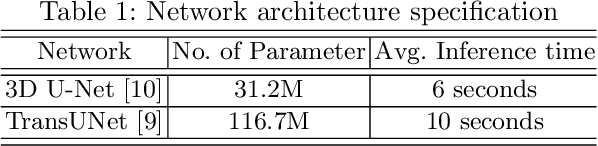
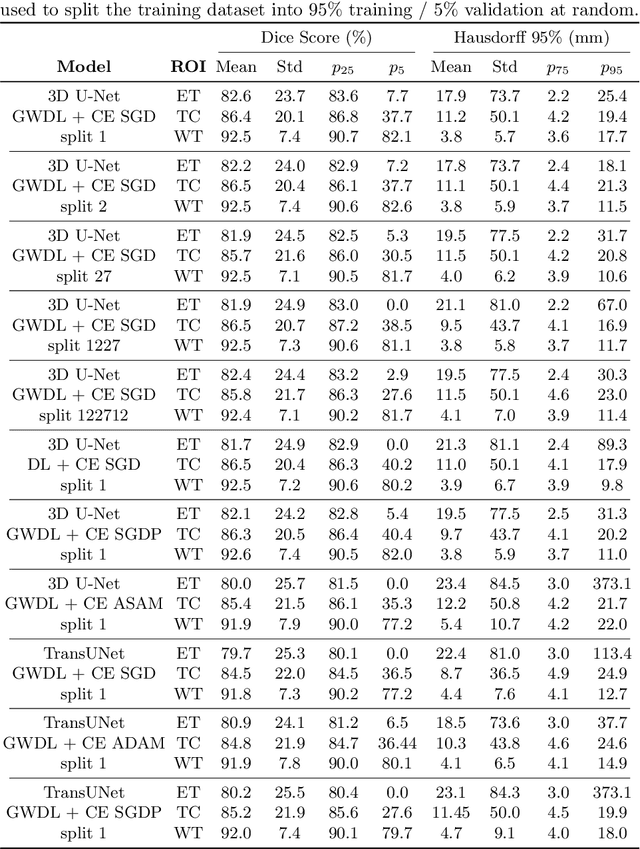
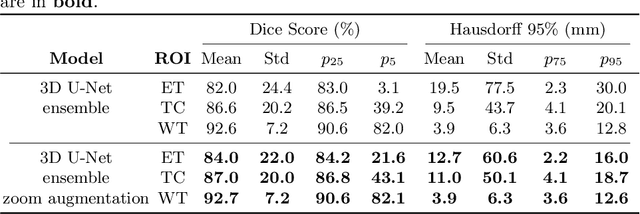
Brain tumor segmentation from multiple Magnetic Resonance Imaging (MRI) modalities is a challenging task in medical image computation. The main challenges lie in the generalizability to a variety of scanners and imaging protocols. In this paper, we explore strategies to increase model robustness without increasing inference time. Towards this aim, we explore finding a robust ensemble from models trained using different losses, optimizers, and train-validation data split. Importantly, we explore the inclusion of a transformer in the bottleneck of the U-Net architecture. While we find transformer in the bottleneck performs slightly worse than the baseline U-Net in average, the generalized Wasserstein Dice loss consistently produces superior results. Further, we adopt an efficient test time augmentation strategy for faster and robust inference. Our final ensemble of seven 3D U-Nets with test-time augmentation produces an average dice score of 89.4% and an average Hausdorff 95% distance of 10.0 mm when evaluated on the BraTS 2021 testing dataset. Our code and trained models are publicly available at https://github.com/LucasFidon/TRABIT_BraTS2021.
Neural Networks for Extreme Quantile Regression with an Application to Forecasting of Flood Risk
Aug 16, 2022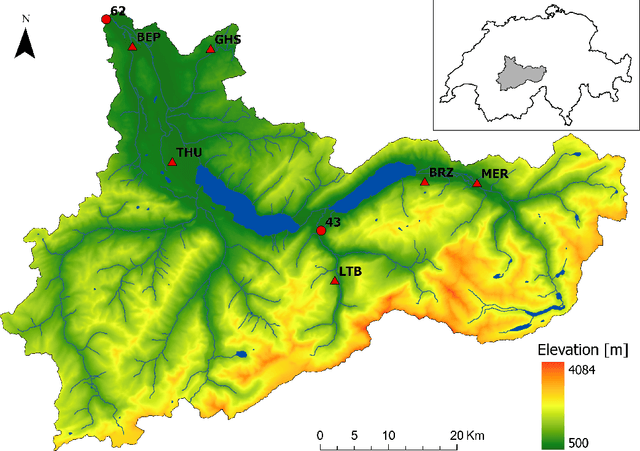
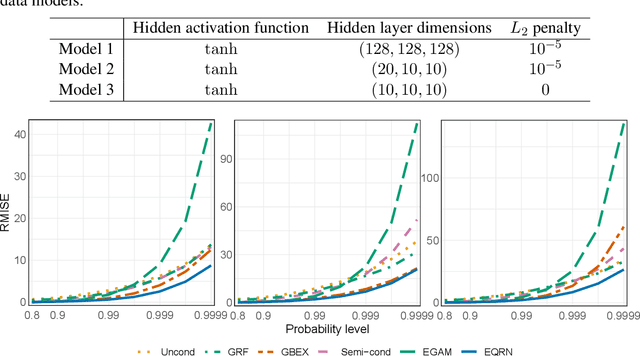
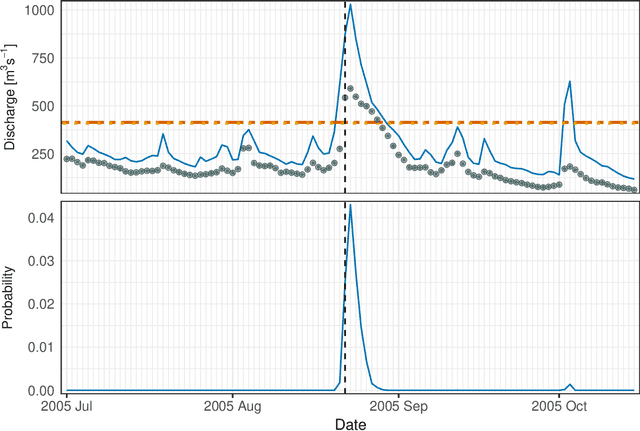
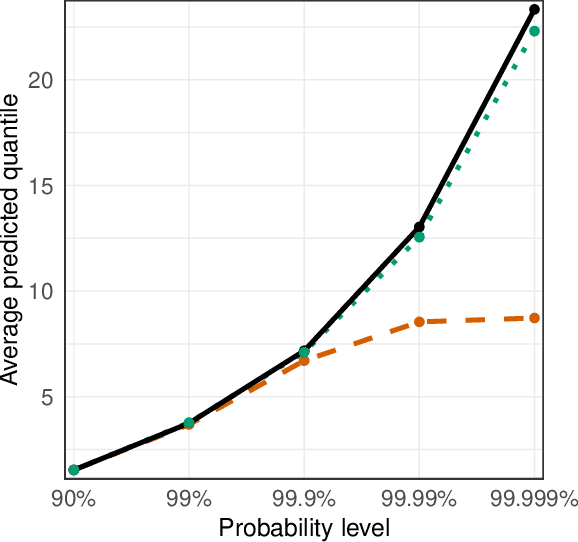
Risk assessment for extreme events requires accurate estimation of high quantiles that go beyond the range of historical observations. When the risk depends on the values of observed predictors, regression techniques are used to interpolate in the predictor space. We propose the EQRN model that combines tools from neural networks and extreme value theory into a method capable of extrapolation in the presence of complex predictor dependence. Neural networks can naturally incorporate additional structure in the data. We develop a recurrent version of EQRN that is able to capture complex sequential dependence in time series. We apply this method to forecasting of flood risk in the Swiss Aare catchment. It exploits information from multiple covariates in space and time to provide one-day-ahead predictions of return levels and exceedances probabilities. This output complements the static return level from a traditional extreme value analysis and the predictions are able to adapt to distributional shifts as experienced in a changing climate. Our model can help authorities to manage flooding more effectively and to minimize their disastrous impacts through early warning systems.
Towards Quantum Advantage on Noisy Quantum Computers
Sep 27, 2022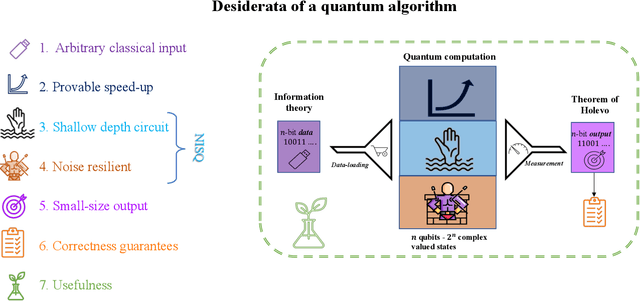

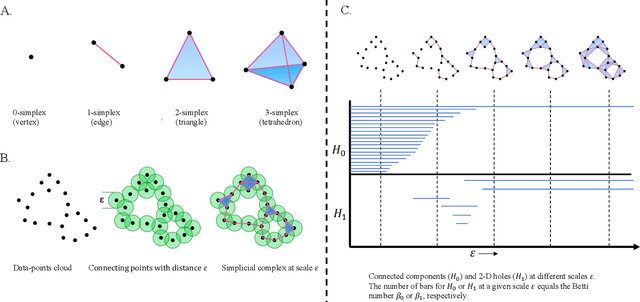
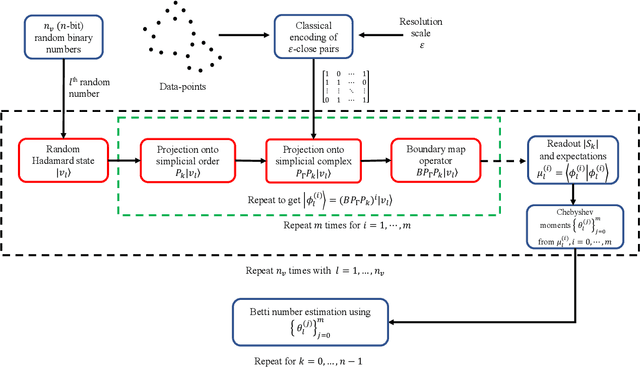
Topological data analysis (TDA) is a powerful technique for extracting complex and valuable shape-related summaries of high-dimensional data. However, the computational demands of classical TDA algorithms are exorbitant, and quickly become impractical for high-order characteristics. Quantum computing promises exponential speedup for certain problems. Yet, many existing quantum algorithms with notable asymptotic speedups require a degree of fault tolerance that is currently unavailable. In this paper, we present NISQ-TDA, the first fully implemented end-to-end quantum machine learning algorithm needing only a linear circuit-depth, that is applicable to non-handcrafted high-dimensional classical data, with potential speedup under stringent conditions. The algorithm neither suffers from the data-loading problem nor does it need to store the input data on the quantum computer explicitly. Our approach includes three key innovations: (a) an efficient realization of the full boundary operator as a sum of Pauli operators; (b) a quantum rejection sampling and projection approach to restrict a uniform superposition to the simplices of the desired order in the complex; and (c) a stochastic rank estimation method to estimate the topological features in the form of approximate Betti numbers. We present theoretical results that establish additive error guarantees for NISQ-TDA, and the circuit and computational time and depth complexities for exponentially scaled output estimates, up to the error tolerance. The algorithm was successfully executed on quantum computing devices, as well as on noisy quantum simulators, applied to small datasets. Preliminary empirical results suggest that the algorithm is robust to noise.
An Intelligent Deterministic Scheduling Method for Ultra-Low Latency Communication in Edge Enabled Industrial Internet of Things
Jul 17, 2022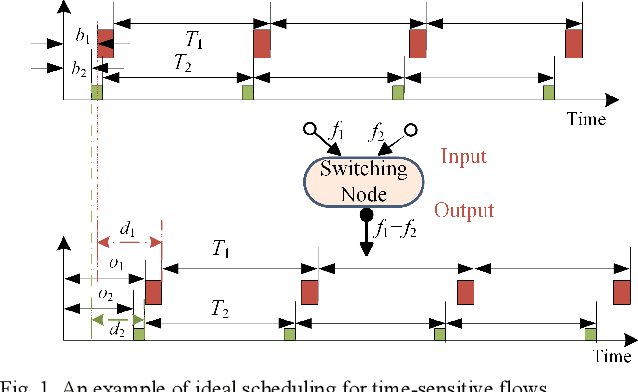

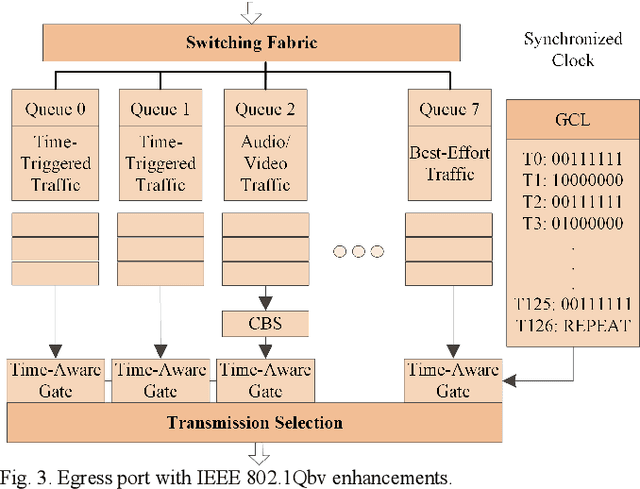
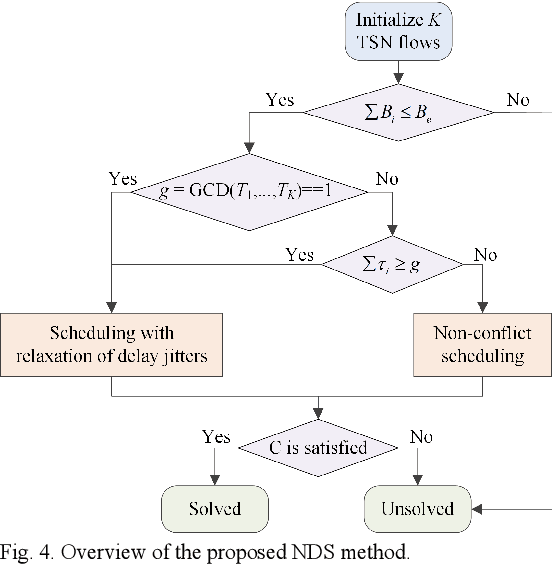
Edge enabled Industrial Internet of Things (IIoT) platform is of great significance to accelerate the development of smart industry. However, with the dramatic increase in real-time IIoT applications, it is a great challenge to support fast response time, low latency, and efficient bandwidth utilization. To address this issue, Time Sensitive Network (TSN) is recently researched to realize low latency communication via deterministic scheduling. To the best of our knowledge, the combinability of multiple flows, which can significantly affect the scheduling performance, has never been systematically analyzed before. In this article, we first analyze the combinability problem. Then a non-collision theory based deterministic scheduling (NDS) method is proposed to achieve ultra-low latency communication for the time-sensitive flows. Moreover, to improve bandwidth utilization, a dynamic queue scheduling (DQS) method is presented for the best-effort flows. Experiment results demonstrate that NDS/DQS can well support deterministic ultra-low latency services and guarantee efficient bandwidth utilization.
An Adaptive Observer for Uncertain Linear Time-Varying Systems with Unknown Additive Perturbations
Dec 10, 2021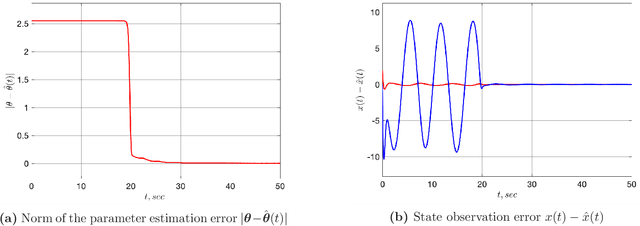
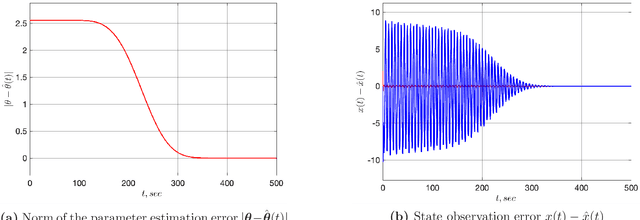
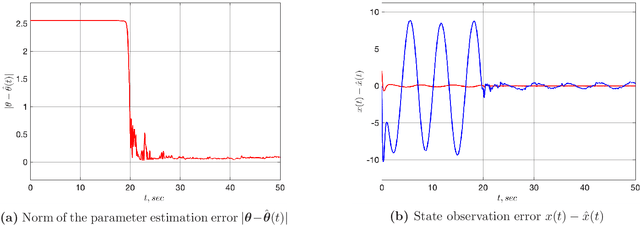
In this paper we are interested in the problem of adaptive state observation of linear time-varying (LTV) systems where the system and the input matrices depend on unknown time-varying parameters. It is assumed that these parameters satisfy some known LTV dynamics, but with unknown initial conditions. Moreover, the state equation is perturbed by an additive signal generated from an exosystem with uncertain constant parameters. Our main contribution is to propose a globally convergent state observer that requires only a weak excitation assumption on the system.
Accelerating Laboratory Automation Through Robot Skill Learning For Sample Scraping
Sep 29, 2022
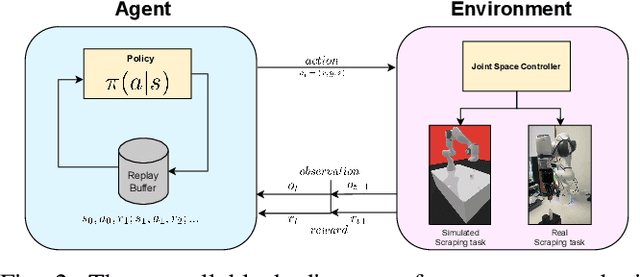
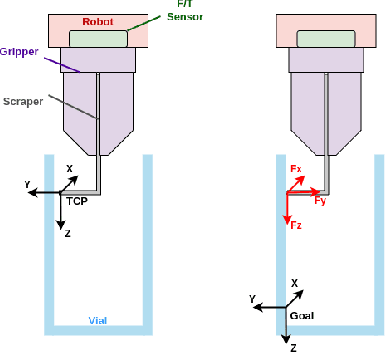
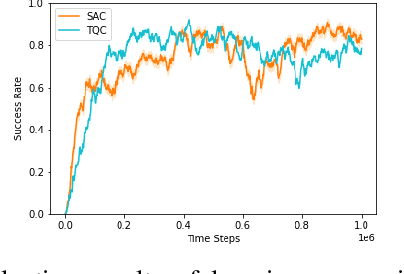
The potential use of robotics for laboratory experiments offers an attractive route to alleviate scientists from tedious tasks while accelerating the process of obtaining new materials, where topical issues such as climate change and disease risks worldwide would greatly benefit. While some experimental workflows can already benefit from automation, it is common that sample preparation is still carried out manually due to the high level of motor function required when dealing with heterogeneous systems, e.g., different tools, chemicals, and glassware. A fundamental workflow in chemical fields is crystallisation, where one application is polymorph screening, i.e., obtaining a three dimensional molecular structure from a crystal. For this process, it is of utmost importance to recover as much of the sample as possible since synthesising molecules is both costly in time and money. To this aim, chemists have to scrape vials to retrieve sample contents prior to imaging plate transfer. Automating this process is challenging as it goes beyond robotic insertion tasks due to a fundamental requirement of having to execute fine-granular movements within a constrained environment that is the sample vial. Motivated by how human chemists carry out this process of scraping powder from vials, our work proposes a model-free reinforcement learning method for learning a scraping policy, leading to a fully autonomous sample scraping procedure. To realise that, we first create a simulation environment with a Panda Franka Emika robot using a laboratory scraper which is inserted into a simulated vial, to demonstrate how a scraping policy can be learned successfully. We then evaluate our method on a real robotic manipulator in laboratory settings, and show that our method can autonomously scrape powder across various setups.
FoVolNet: Fast Volume Rendering using Foveated Deep Neural Networks
Sep 20, 2022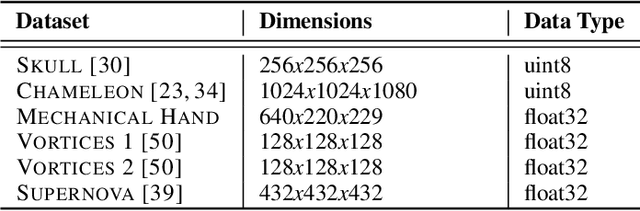



Volume data is found in many important scientific and engineering applications. Rendering this data for visualization at high quality and interactive rates for demanding applications such as virtual reality is still not easily achievable even using professional-grade hardware. We introduce FoVolNet -- a method to significantly increase the performance of volume data visualization. We develop a cost-effective foveated rendering pipeline that sparsely samples a volume around a focal point and reconstructs the full-frame using a deep neural network. Foveated rendering is a technique that prioritizes rendering computations around the user's focal point. This approach leverages properties of the human visual system, thereby saving computational resources when rendering data in the periphery of the user's field of vision. Our reconstruction network combines direct and kernel prediction methods to produce fast, stable, and perceptually convincing output. With a slim design and the use of quantization, our method outperforms state-of-the-art neural reconstruction techniques in both end-to-end frame times and visual quality. We conduct extensive evaluations of the system's rendering performance, inference speed, and perceptual properties, and we provide comparisons to competing neural image reconstruction techniques. Our test results show that FoVolNet consistently achieves significant time saving over conventional rendering while preserving perceptual quality.
Bayesian Complementary Kernelized Learning for Multidimensional Spatiotemporal Data
Aug 21, 2022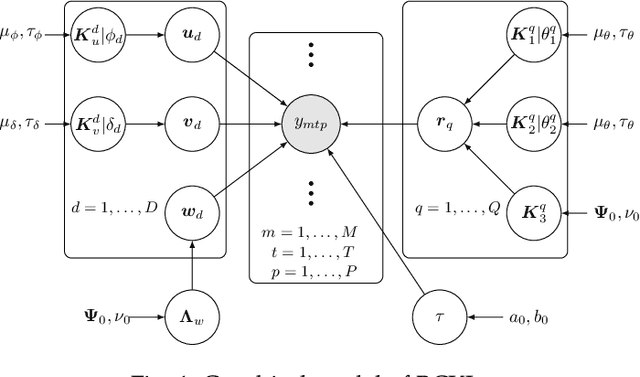
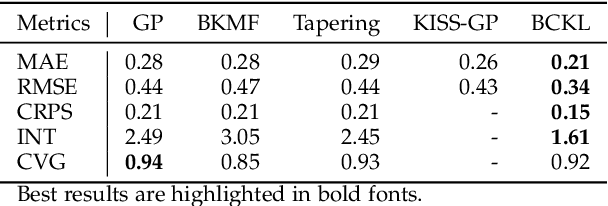
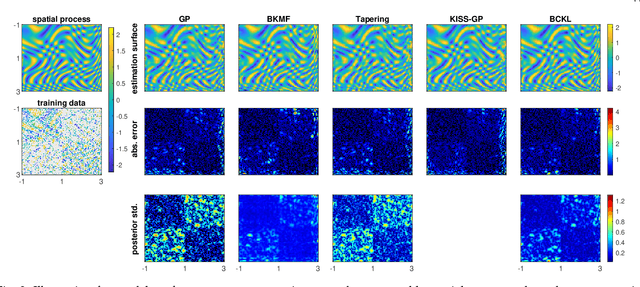
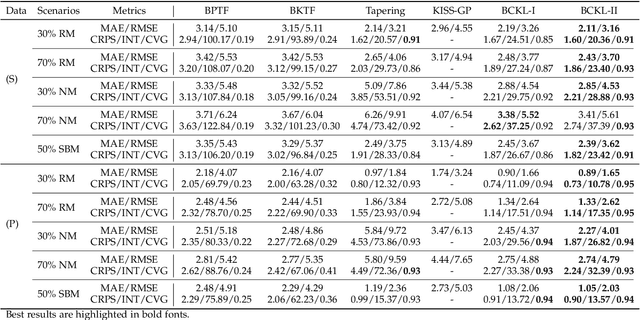
Probabilistic modeling of multidimensional spatiotemporal data is critical to many real-world applications. However, real-world spatiotemporal data often exhibits complex dependencies that are nonstationary, i.e., correlation structure varies with location/time, and nonseparable, i.e., dependencies exist between space and time. Developing effective and computationally efficient statistical models to accommodate nonstationary/nonseparable processes containing both long-range and short-scale variations becomes a challenging task, especially for large-scale datasets with various corruption/missing structures. In this paper, we propose a new statistical framework -- Bayesian Complementary Kernelized Learning (BCKL) -- to achieve scalable probabilistic modeling for multidimensional spatiotemporal data. To effectively describe complex dependencies, BCKL integrates kernelized low-rank factorization with short-range spatiotemporal Gaussian processes (GP), in which the two components complement each other. Specifically, we use a multi-linear low-rank factorization component to capture the global/long-range correlations in the data and introduce an additive short-scale GP based on compactly supported kernel functions to characterize the remaining local variabilities. We develop an efficient Markov chain Monte Carlo (MCMC) algorithm for model inference and evaluate the proposed BCKL framework on both synthetic and real-world spatiotemporal datasets. Our results confirm the superior performance of BCKL in providing accurate posterior mean and high-quality uncertainty estimates.
Flow 2.0 -a flexible, scalable, cross-platform post-processing software for realtime phase contrast sequences
Jul 26, 2022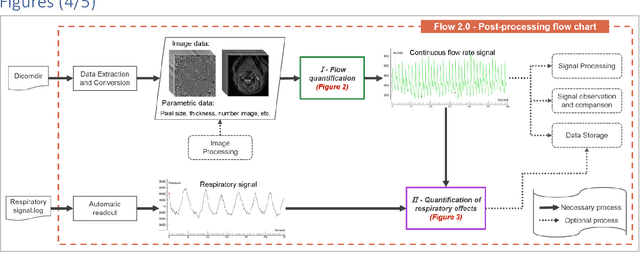
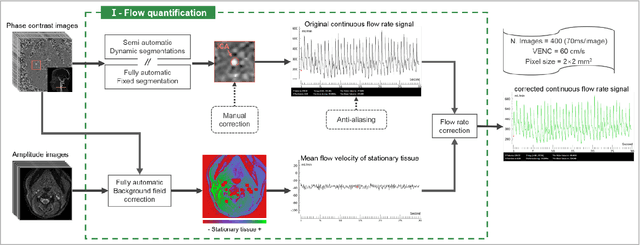
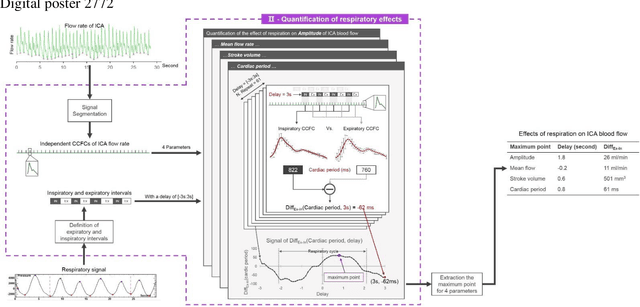
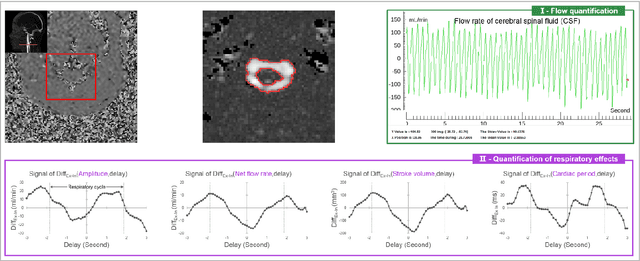
Flow 2.0 is an end-to-end easy-of-use software that allows us to quickly, robustly and accurately perform a batch process real-time phase contrast data and multivariate analysis of the effect of respiration on cerebral fluids circulation. Synopsis (99/100) Real-time phase contrast sequences (RT-PC) have potential value as a scientific and clinical tool in quantifying the effects of respiration on cerebral circulation. To simplify its complicated post-processing process, we developed Flow 2.0 software, which provides a complete post-processing workflow including converting DICOM data, image segmentation, image processing, data extraction, background field correction, antialiasing filter, signal processing and analysis and a novel time-domain method for quantifying the effect of respiration on the cerebral circulation. This end-to-end software allows us to quickly, robustly and accurately perform batch process RT-PC and multivariate analysis of the effects of respiration on cerebral circulation.