 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Solar Flare Index Prediction Using SDO/HMI Vector Magnetic Data Products with Statistical and Machine Learning Methods
Sep 28, 2022

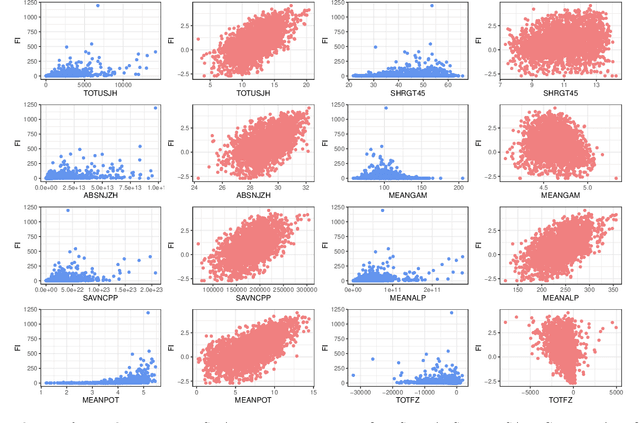

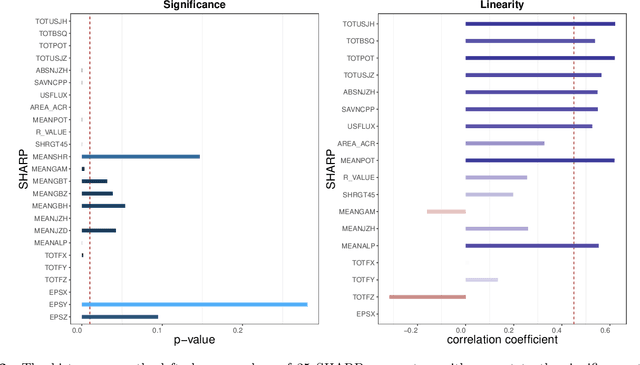
Solar flares, especially the M- and X-class flares, are often associated with coronal mass ejections (CMEs). They are the most important sources of space weather effects, that can severely impact the near-Earth environment. Thus it is essential to forecast flares (especially the M-and X-class ones) to mitigate their destructive and hazardous consequences. Here, we introduce several statistical and Machine Learning approaches to the prediction of the AR's Flare Index (FI) that quantifies the flare productivity of an AR by taking into account the numbers of different class flares within a certain time interval. Specifically, our sample includes 563 ARs appeared on solar disk from May 2010 to Dec 2017. The 25 magnetic parameters, provided by the Space-weather HMI Active Region Patches (SHARP) from Helioseismic and Magnetic Imager (HMI) on board the Solar Dynamics Observatory (SDO), characterize coronal magnetic energy stored in ARs by proxy and are used as the predictors. We investigate the relationship between these SHARP parameters and the FI of ARs with a machine-learning algorithm (spline regression) and the resampling method (Synthetic Minority Over-Sampling Technique for Regression with Gaussian Noise, short by SMOGN). Based on the established relationship, we are able to predict the value of FIs for a given AR within the next 1-day period. Compared with other 4 popular machine learning algorithms, our methods improve the accuracy of FI prediction, especially for large FI. In addition, we sort the importance of SHARP parameters by Borda Count method calculated from the ranks that are rendered by 9 different machine learning methods.
Efficient Customer Service Combining Human Operators and Virtual Agents
Sep 12, 2022
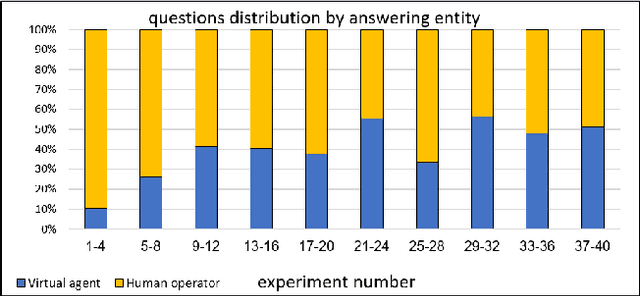
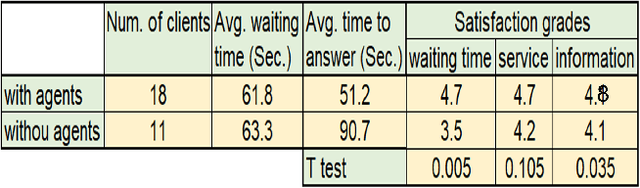
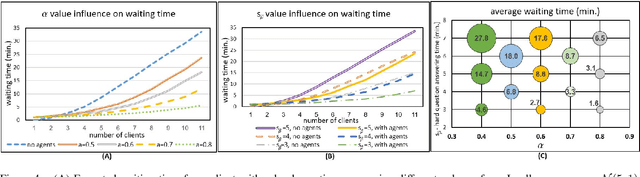
The prospect of combining human operators and virtual agents (bots) into an effective hybrid system that provides proper customer service to clients is promising yet challenging. The hybrid system decreases the customers' frustration when bots are unable to provide appropriate service and increases their satisfaction when they prefer to interact with human operators. Furthermore, we show that it is possible to decrease the cost and efforts of building and maintaining such virtual agents by enabling the virtual agent to incrementally learn from the human operators. We employ queuing theory to identify the key parameters that govern the behavior and efficiency of such hybrid systems and determine the main parameters that should be optimized in order to improve the service. We formally prove, and demonstrate in extensive simulations and in a user study, that with the proper choice of parameters, such hybrid systems are able to increase the number of served clients while simultaneously decreasing their expected waiting time and increasing satisfaction.
Solving Seismic Wave Equations on Variable Velocity Models with Fourier Neural Operator
Sep 25, 2022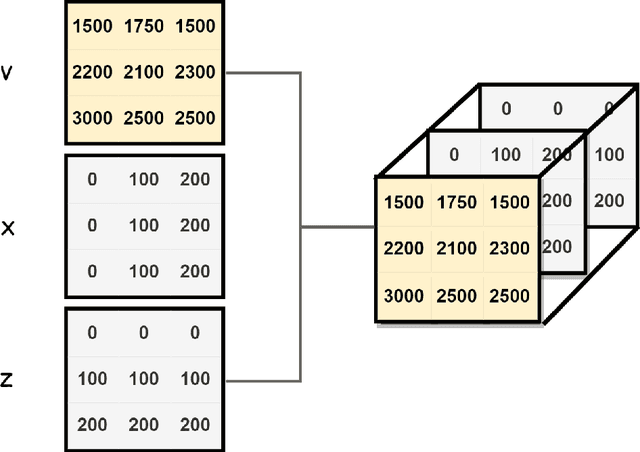
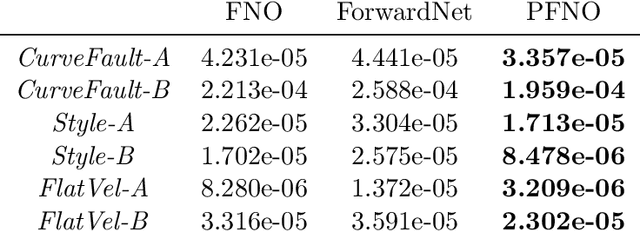
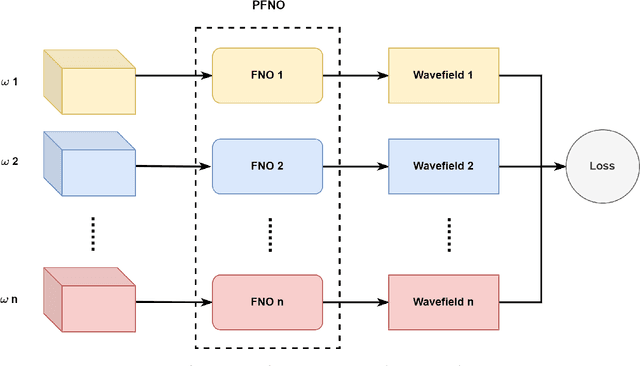

In the study of subsurface seismic imaging, solving the acoustic wave equation is a pivotal component in existing models. With the advancement of deep learning, neural networks are applied to numerically solve partial differential equations by learning the mapping between the inputs and the solution of the equation, the wave equation in particular, since traditional methods can be time consuming if numerous instances are to be solved. Previous works that concentrate on solving the wave equation by neural networks consider either a single velocity model or multiple simple velocity models, which is restricted in practice. Therefore, inspired by the idea of operator learning, this work leverages the Fourier neural operator (FNO) to effectively learn the frequency domain seismic wavefields under the context of variable velocity models. Moreover, we propose a new framework paralleled Fourier neural operator (PFNO) for efficiently training the FNO-based solver given multiple source locations and frequencies. Numerical experiments demonstrate the high accuracy of both FNO and PFNO with complicated velocity models in the OpenFWI datasets. Furthermore, the cross-dataset generalization test verifies that PFNO adapts to out-of-distribution velocity models. Also, PFNO has robust performance in the presence of random noise in the labels. Finally, PFNO admits higher computational efficiency on large-scale testing datasets, compared with the traditional finite-difference method. The aforementioned advantages endow the FNO-based solver with the potential to build powerful models for research on seismic waves.
FFPA-Net: Efficient Feature Fusion with Projection Awareness for 3D Object Detection
Sep 15, 2022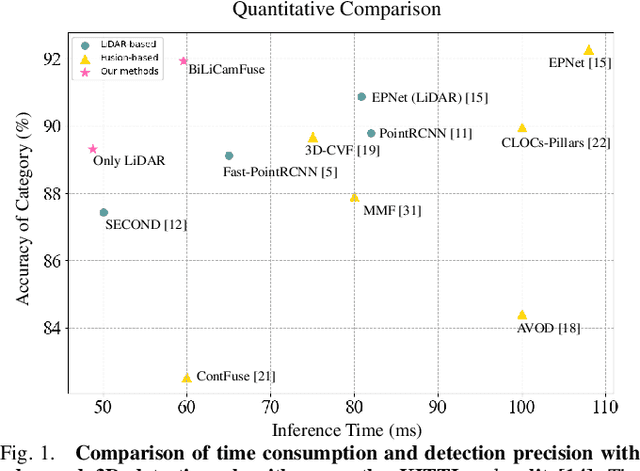
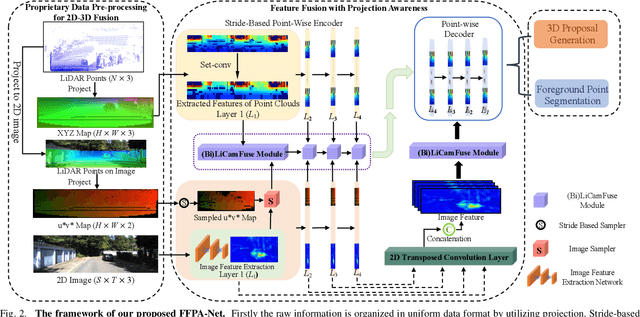
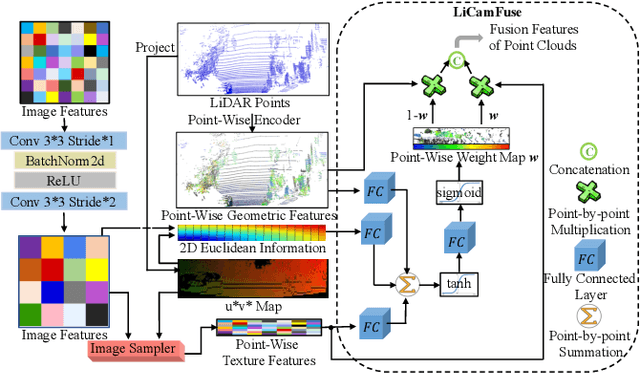
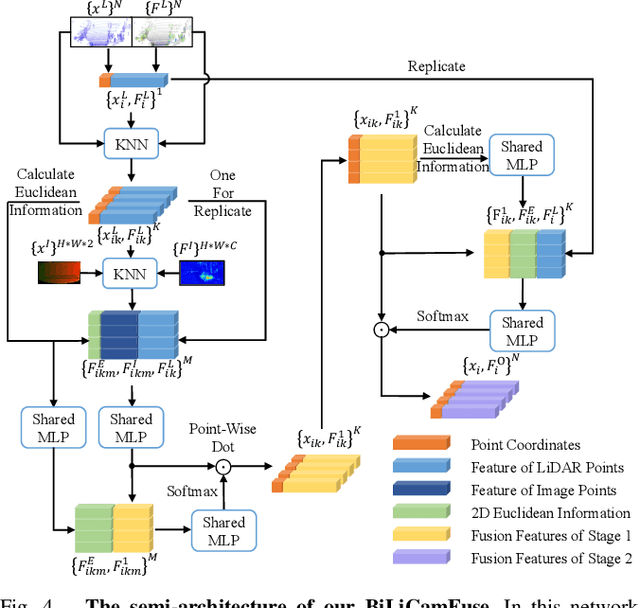
Promising complementarity exists between the texture features of color images and the geometric information of LiDAR point clouds. However, there still present many challenges for efficient and robust feature fusion in the field of 3D object detection. In this paper, first, unstructured 3D point clouds are filled in the 2D plane and 3D point cloud features are extracted faster using projection-aware convolution layers. Further, the corresponding indexes between different sensor signals are established in advance in the data preprocessing, which enables faster cross-modal feature fusion. To address LiDAR points and image pixels misalignment problems, two new plug-and-play fusion modules, LiCamFuse and BiLiCamFuse, are proposed. In LiCamFuse, soft query weights with perceiving the Euclidean distance of bimodal features are proposed. In BiLiCamFuse, the fusion module with dual attention is proposed to deeply correlate the geometric and textural features of the scene. The quantitative results on the KITTI dataset demonstrate that the proposed method achieves better feature-level fusion. In addition, the proposed network shows a shorter running time compared to existing methods.
On the programming effort required to generate Behavior Trees and Finite State Machines for robotic applications
Sep 15, 2022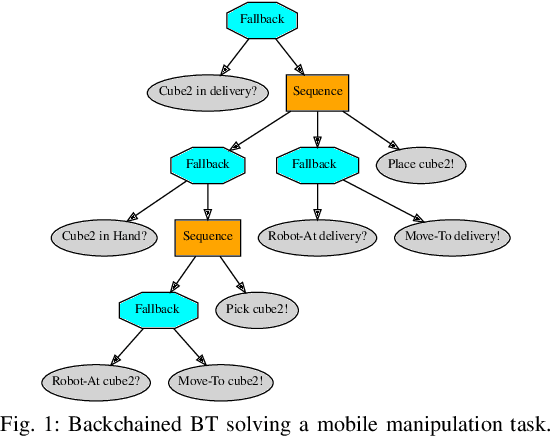
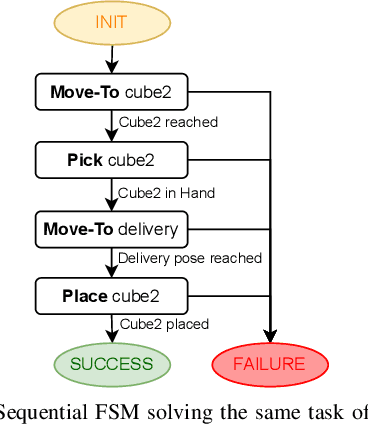


In this paper we provide a practical demonstration of how the modularity in a Behavior Tree (BT) decreases the effort in programming a robot task when compared to a Finite State Machine (FSM). In recent years the way to represent a task plan to control an autonomous agent has been shifting from the standard FSM towards BTs. Many works in the literature have highlighted and proven the benefits of such design compared to standard approaches, especially in terms of modularity, reactivity and human readability. However, these works have often failed in providing a tangible comparison in the implementation of those policies and the programming effort required to modify them. This is a relevant aspect in many robotic applications, where the design choice is dictated both by the robustness of the policy and by the time required to program it. In this work, we compare backward chained BTs with a fault-tolerant design of FSMs by evaluating the cost to modify them. We validate the analysis with a set of experiments in a simulation environment where a mobile manipulator solves an item fetching task.
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Sep 30, 2022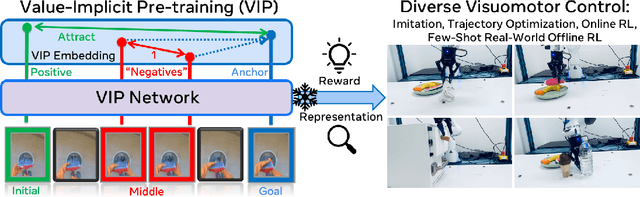

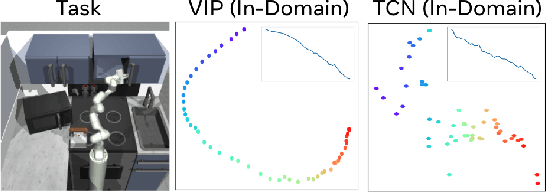
Reward and representation learning are two long-standing challenges for learning an expanding set of robot manipulation skills from sensory observations. Given the inherent cost and scarcity of in-domain, task-specific robot data, learning from large, diverse, offline human videos has emerged as a promising path towards acquiring a generally useful visual representation for control; however, how these human videos can be used for general-purpose reward learning remains an open question. We introduce $\textbf{V}$alue-$\textbf{I}$mplicit $\textbf{P}$re-training (VIP), a self-supervised pre-trained visual representation capable of generating dense and smooth reward functions for unseen robotic tasks. VIP casts representation learning from human videos as an offline goal-conditioned reinforcement learning problem and derives a self-supervised dual goal-conditioned value-function objective that does not depend on actions, enabling pre-training on unlabeled human videos. Theoretically, VIP can be understood as a novel implicit time contrastive objective that generates a temporally smooth embedding, enabling the value function to be implicitly defined via the embedding distance, which can then be used to construct the reward for any goal-image specified downstream task. Trained on large-scale Ego4D human videos and without any fine-tuning on in-domain, task-specific data, VIP's frozen representation can provide dense visual reward for an extensive set of simulated and $\textbf{real-robot}$ tasks, enabling diverse reward-based visual control methods and significantly outperforming all prior pre-trained representations. Notably, VIP can enable simple, $\textbf{few-shot}$ offline RL on a suite of real-world robot tasks with as few as 20 trajectories.
From Weakly Supervised Learning to Active Learning
Sep 23, 2022
Applied mathematics and machine computations have raised a lot of hope since the recent success of supervised learning. Many practitioners in industries have been trying to switch from their old paradigms to machine learning. Interestingly, those data scientists spend more time scrapping, annotating and cleaning data than fine-tuning models. This thesis is motivated by the following question: can we derive a more generic framework than the one of supervised learning in order to learn from clutter data? This question is approached through the lens of weakly supervised learning, assuming that the bottleneck of data collection lies in annotation. We model weak supervision as giving, rather than a unique target, a set of target candidates. We argue that one should look for an ``optimistic'' function that matches most of the observations. This allows us to derive a principle to disambiguate partial labels. We also discuss the advantage to incorporate unsupervised learning techniques into our framework, in particular manifold regularization approached through diffusion techniques, for which we derived a new algorithm that scales better with input dimension then the baseline method. Finally, we switch from passive to active weakly supervised learning, introducing the ``active labeling'' framework, in which a practitioner can query weak information about chosen data. Among others, we leverage the fact that one does not need full information to access stochastic gradients and perform stochastic gradient descent.
Locally temporal-spatial pattern learning with graph attention mechanism for EEG-based emotion recognition
Aug 19, 2022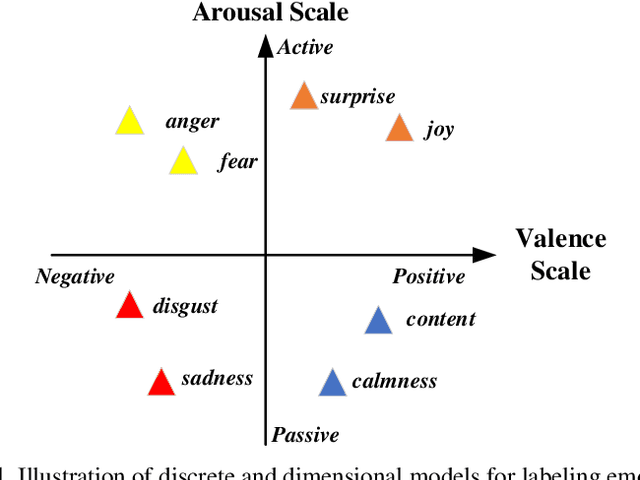

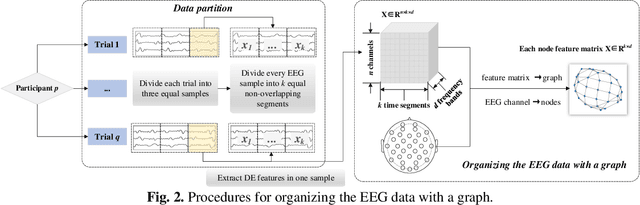
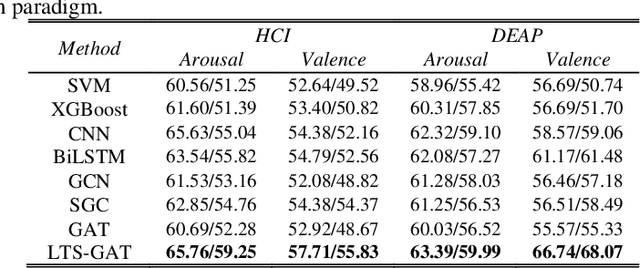
Technique of emotion recognition enables computers to classify human affective states into discrete categories. However, the emotion may fluctuate instead of maintaining a stable state even within a short time interval. There is also a difficulty to take the full use of the EEG spatial distribution due to its 3-D topology structure. To tackle the above issues, we proposed a locally temporal-spatial pattern learning graph attention network (LTS-GAT) in the present study. In the LTS-GAT, a divide-and-conquer scheme was used to examine local information on temporal and spatial dimensions of EEG patterns based on the graph attention mechanism. A dynamical domain discriminator was added to improve the robustness against inter-individual variations of the EEG statistics to learn robust EEG feature representations across different participants. We evaluated the LTS-GAT on two public datasets for affective computing studies under individual-dependent and independent paradigms. The effectiveness of LTS-GAT model was demonstrated when compared to other existing mainstream methods. Moreover, visualization methods were used to illustrate the relations of different brain regions and emotion recognition. Meanwhile, the weights of different time segments were also visualized to investigate emotion sparsity problems.
Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation
Aug 16, 2022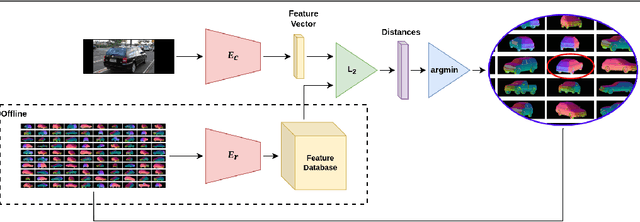
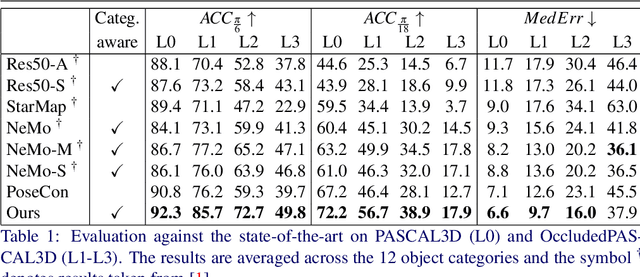

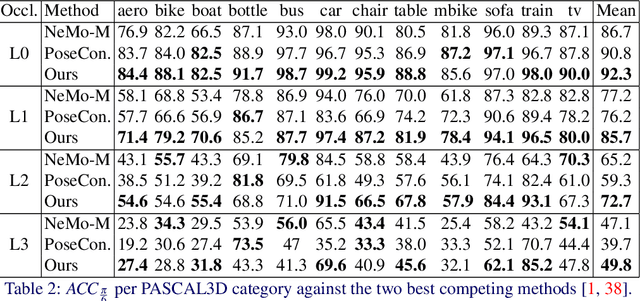
Pose estimation is usually tackled as either a bin classification problem or as a regression problem. In both cases, the idea is to directly predict the pose of an object. This is a non-trivial task because of appearance variations of similar poses and similarities between different poses. Instead, we follow the key idea that it is easier to compare two poses than to estimate them. Render-and-compare approaches have been employed to that end, however, they tend to be unstable, computationally expensive, and slow for real-time applications. We propose doing category-level pose estimation by learning an alignment metric using a contrastive loss with a dynamic margin and a continuous pose-label space. For efficient inference, we use a simple real-time image retrieval scheme with a reference set of renderings projected to an embedding space. To achieve robustness to real-world conditions, we employ synthetic occlusions, bounding box perturbations, and appearance augmentations. Our approach achieves state-of-the-art performance on PASCAL3D and OccludedPASCAL3D, as well as high-quality results on KITTI3D.
Benchmarking real-time algorithms for in-phase auditory stimulation of low amplitude slow waves with wearable EEG devices during sleep
Mar 04, 2022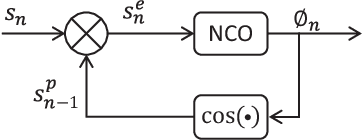
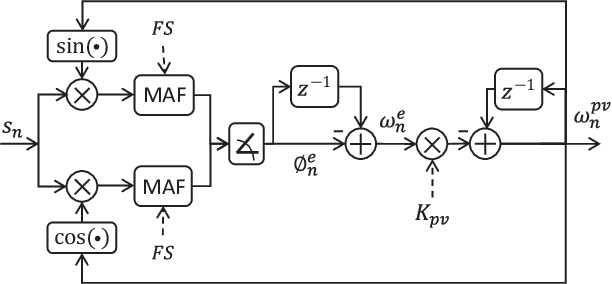
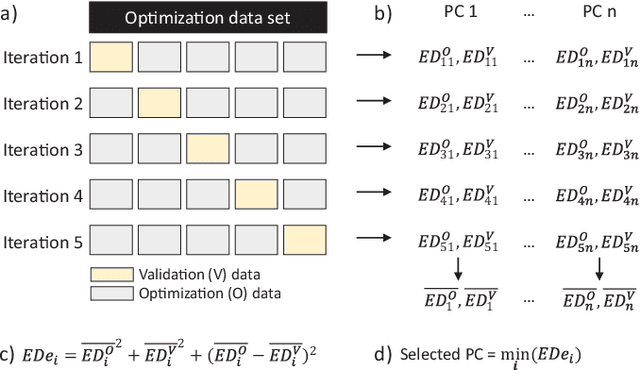
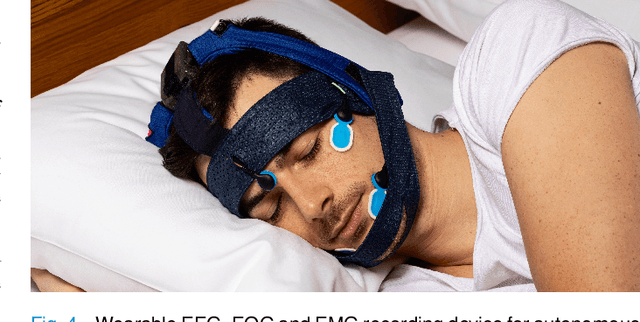
Auditory stimulation of EEG slow waves (SW) during non-rapid eye movement (NREM) sleep has shown to improve cognitive function when it is delivered at the up-phase of SW. SW enhancement is particularly desirable in subjects with low-amplitude SW such as older adults or patients suffering from neurodegeneration such as Parkinson disease (PD). However, existing algorithms to estimate the up-phase suffer from a poor phase accuracy at low EEG amplitudes and when SW frequencies are not constant. We introduce two novel algorithms for real-time EEG phase estimation on autonomous wearable devices. The algorithms were based on a phase-locked loop (PLL) and, for the first time, a phase vocoder (PV). We compared these phase tracking algorithms with a simple amplitude threshold approach. The optimized algorithms were benchmarked for phase accuracy, the capacity to estimate phase at SW amplitudes between 20 and 60 microV, and SW frequencies above 1 Hz on 324 recordings from healthy older adults and PD patients. Furthermore, the algorithms were implemented on a wearable device and the computational efficiency and the performance was evaluated on simulated sleep EEG, as well as prospectively during a recording with a PD patient. All three algorithms delivered more than 70% of the stimulation triggers during the SW up-phase. The PV showed the highest capacity on targeting low-amplitude SW and SW with frequencies above 1 Hz. The testing on real-time hardware revealed that both PV and PLL have marginal impact on microcontroller load, while the efficiency of the PV was 4% lower than the PLL. Active auditory stimulation did not influence the phase tracking. This work demonstrated that phase-accurate auditory stimulation can be delivered during home-based sleep interventions with a wearable device also in populations with low-amplitude SW.