 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Barrier Functions Inspired Reward Shaping for Reinforcement Learning
Mar 03, 2024

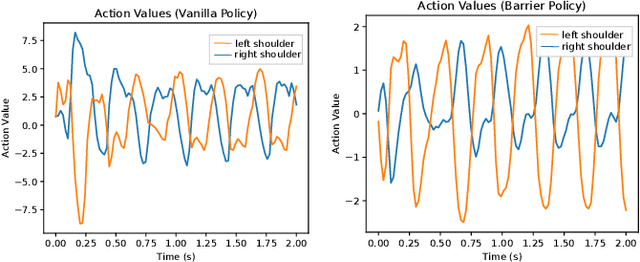
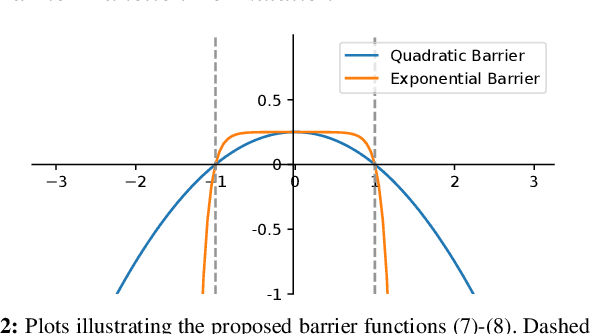
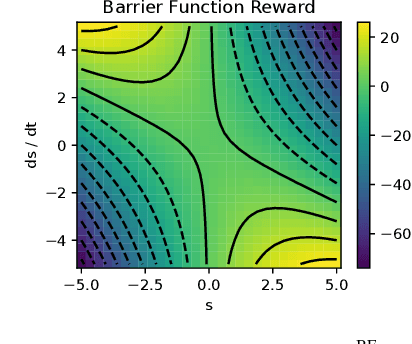
Reinforcement Learning (RL) has progressed from simple control tasks to complex real-world challenges with large state spaces. While RL excels in these tasks, training time remains a limitation. Reward shaping is a popular solution, but existing methods often rely on value functions, which face scalability issues. This paper presents a novel safety-oriented reward-shaping framework inspired by barrier functions, offering simplicity and ease of implementation across various environments and tasks. To evaluate the effectiveness of the proposed reward formulations, we conduct simulation experiments on CartPole, Ant, and Humanoid environments, along with real-world deployment on the Unitree Go1 quadruped robot. Our results demonstrate that our method leads to 1.4-2.8 times faster convergence and as low as 50-60% actuation effort compared to the vanilla reward. In a sim-to-real experiment with the Go1 robot, we demonstrated better control and dynamics of the bot with our reward framework.
Estimation and Deconvolution of Second Order Cyclostationary Signals
Feb 29, 2024This method solves the dual problem of blind deconvolution and estimation of the time waveform of noisy second-order cyclo-stationary (CS2) signals that traverse a Transfer Function (TF) en route to a sensor. We have proven that the deconvolution filter exists and eliminates the TF effect from signals whose statistics vary over time. This method is blind, meaning it does not require prior knowledge about the signals or TF. Simulations demonstrate the algorithm high precision across various signal types, TFs, and Signal-to-Noise Ratios (SNRs). In this study, the CS2 signals family is restricted to the product of a deterministic periodic function and white noise. Furthermore, this method has the potential to improve the training of Machine Learning models where the aggregation of signals from identical systems but with different TFs is required.
Denoising Time Cycle Modeling for Recommendation
Feb 05, 2024Recently, modeling temporal patterns of user-item interactions have attracted much attention in recommender systems. We argue that existing methods ignore the variety of temporal patterns of user behaviors. We define the subset of user behaviors that are irrelevant to the target item as noises, which limits the performance of target-related time cycle modeling and affect the recommendation performance. In this paper, we propose Denoising Time Cycle Modeling (DiCycle), a novel approach to denoise user behaviors and select the subset of user behaviors that are highly related to the target item. DiCycle is able to explicitly model diverse time cycle patterns for recommendation. Extensive experiments are conducted on both public benchmarks and a real-world dataset, demonstrating the superior performance of DiCycle over the state-of-the-art recommendation methods.
Learning time-dependent PDE via graph neural networks and deep operator network for robust accuracy on irregular grids
Feb 13, 2024Scientific computing using deep learning has seen significant advancements in recent years. There has been growing interest in models that learn the operator from the parameters of a partial differential equation (PDE) to the corresponding solutions. Deep Operator Network (DeepONet) and Fourier Neural operator, among other models, have been designed with structures suitable for handling functions as inputs and outputs, enabling real-time predictions as surrogate models for solution operators. There has also been significant progress in the research on surrogate models based on graph neural networks (GNNs), specifically targeting the dynamics in time-dependent PDEs. In this paper, we propose GraphDeepONet, an autoregressive model based on GNNs, to effectively adapt DeepONet, which is well-known for successful operator learning. GraphDeepONet exhibits robust accuracy in predicting solutions compared to existing GNN-based PDE solver models. It maintains consistent performance even on irregular grids, leveraging the advantages inherited from DeepONet and enabling predictions on arbitrary grids. Additionally, unlike traditional DeepONet and its variants, GraphDeepONet enables time extrapolation for time-dependent PDE solutions. We also provide theoretical analysis of the universal approximation capability of GraphDeepONet in approximating continuous operators across arbitrary time intervals.
Learning to Program Variational Quantum Circuits with Fast Weights
Feb 27, 2024Quantum Machine Learning (QML) has surfaced as a pioneering framework addressing sequential control tasks and time-series modeling. It has demonstrated empirical quantum advantages notably within domains such as Reinforcement Learning (RL) and time-series prediction. A significant advancement lies in Quantum Recurrent Neural Networks (QRNNs), specifically tailored for memory-intensive tasks encompassing partially observable environments and non-linear time-series prediction. Nevertheless, QRNN-based models encounter challenges, notably prolonged training duration stemming from the necessity to compute quantum gradients using backpropagation-through-time (BPTT). This predicament exacerbates when executing the complete model on quantum devices, primarily due to the substantial demand for circuit evaluation arising from the parameter-shift rule. This paper introduces the Quantum Fast Weight Programmers (QFWP) as a solution to the temporal or sequential learning challenge. The QFWP leverages a classical neural network (referred to as the 'slow programmer') functioning as a quantum programmer to swiftly modify the parameters of a variational quantum circuit (termed the 'fast programmer'). Instead of completely overwriting the fast programmer at each time-step, the slow programmer generates parameter changes or updates for the quantum circuit parameters. This approach enables the fast programmer to incorporate past observations or information. Notably, the proposed QFWP model achieves learning of temporal dependencies without necessitating the use of quantum recurrent neural networks. Numerical simulations conducted in this study showcase the efficacy of the proposed QFWP model in both time-series prediction and RL tasks. The model exhibits performance levels either comparable to or surpassing those achieved by QLSTM-based models.
Generalizability Under Sensor Failure: Tokenization + Transformers Enable More Robust Latent Spaces
Feb 29, 2024A major goal in neuroscience is to discover neural data representations that generalize. This goal is challenged by variability along recording sessions (e.g. environment), subjects (e.g. varying neural structures), and sensors (e.g. sensor noise), among others. Recent work has begun to address generalization across sessions and subjects, but few study robustness to sensor failure which is highly prevalent in neuroscience experiments. In order to address these generalizability dimensions we first collect our own electroencephalography dataset with numerous sessions, subjects, and sensors, then study two time series models: EEGNet (Lawhern et al., 2018) and TOTEM (Talukder et al., 2024). EEGNet is a widely used convolutional neural network, while TOTEM is a discrete time series tokenizer and transformer model. We find that TOTEM outperforms or matches EEGNet across all generalizability cases. Finally through analysis of TOTEM's latent codebook we observe that tokenization enables generalization
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
Mar 03, 2024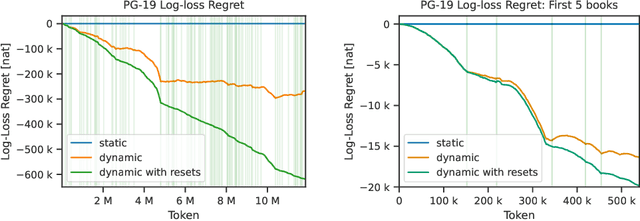
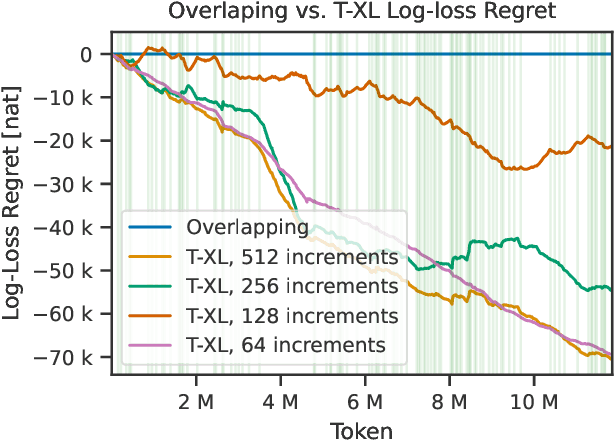
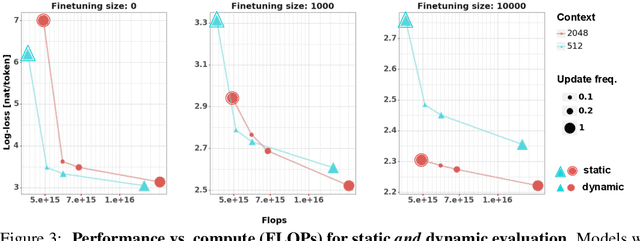
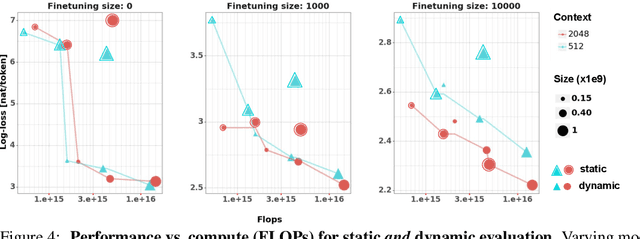
We consider the problem of online fine tuning the parameters of a language model at test time, also known as dynamic evaluation. While it is generally known that this approach improves the overall predictive performance, especially when considering distributional shift between training and evaluation data, we here emphasize the perspective that online adaptation turns parameters into temporally changing states and provides a form of context-length extension with memory in weights, more in line with the concept of memory in neuroscience. We pay particular attention to the speed of adaptation (in terms of sample efficiency),sensitivity to the overall distributional drift, and the computational overhead for performing gradient computations and parameter updates. Our empirical study provides insights on when online adaptation is particularly interesting. We highlight that with online adaptation the conceptual distinction between in-context learning and fine tuning blurs: both are methods to condition the model on previously observed tokens.
On the Compressibility of Quantized Large Language Models
Mar 03, 2024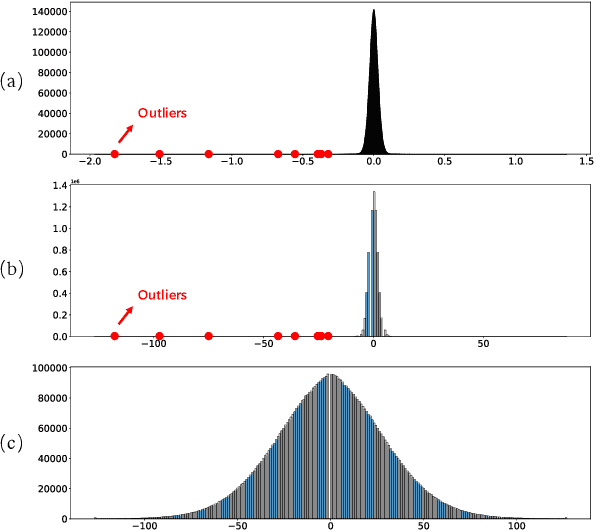

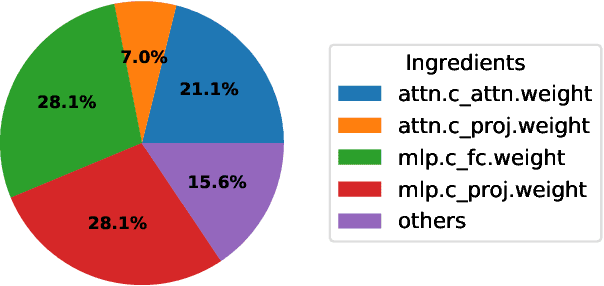
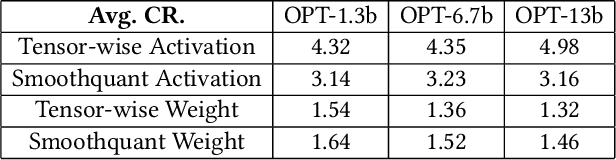
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
A Closer Look at Wav2Vec2 Embeddings for On-Device Single-Channel Speech Enhancement
Mar 03, 2024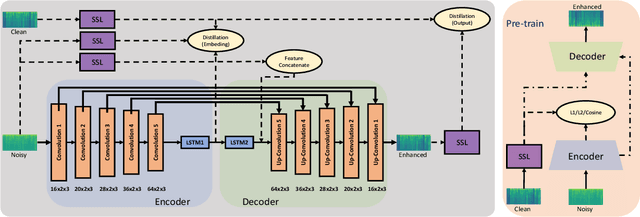
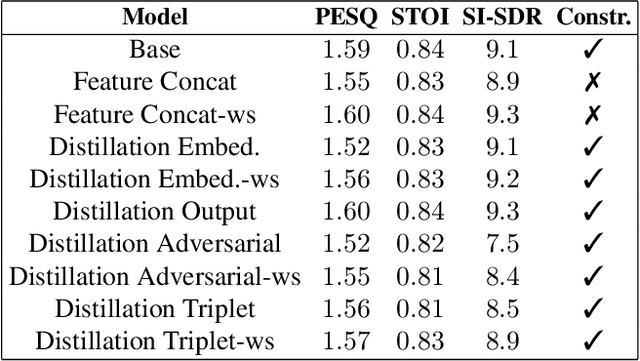
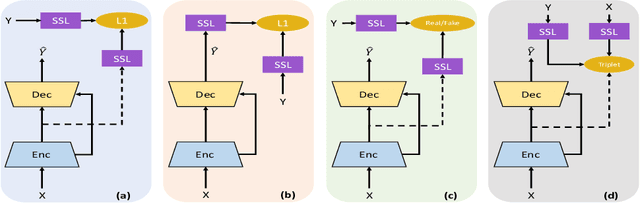
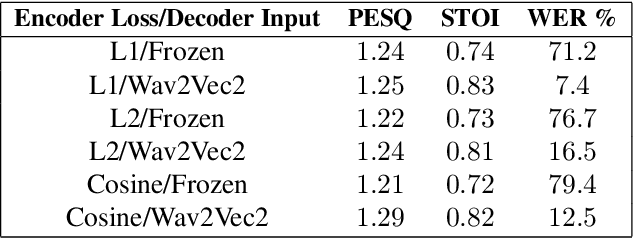
Self-supervised learned models have been found to be very effective for certain speech tasks such as automatic speech recognition, speaker identification, keyword spotting and others. While the features are undeniably useful in speech recognition and associated tasks, their utility in speech enhancement systems is yet to be firmly established, and perhaps not properly understood. In this paper, we investigate the uses of SSL representations for single-channel speech enhancement in challenging conditions and find that they add very little value for the enhancement task. Our constraints are designed around on-device real-time speech enhancement -- model is causal, the compute footprint is small. Additionally, we focus on low SNR conditions where such models struggle to provide good enhancement. In order to systematically examine how SSL representations impact performance of such enhancement models, we propose a variety of techniques to utilize these embeddings which include different forms of knowledge-distillation and pre-training.
Large-scale variational Gaussian state-space models
Mar 03, 2024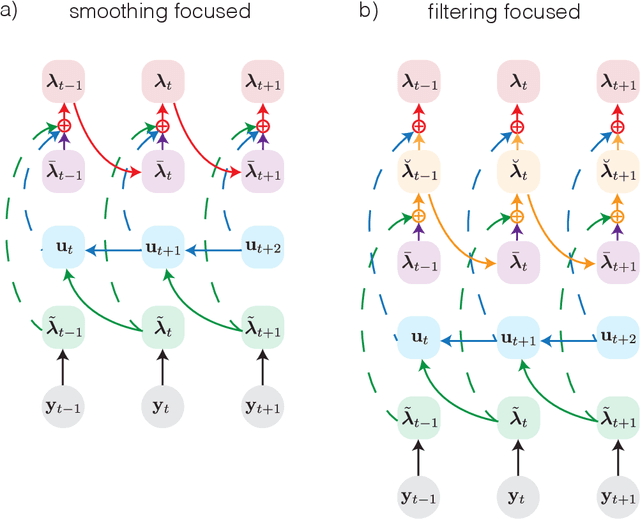

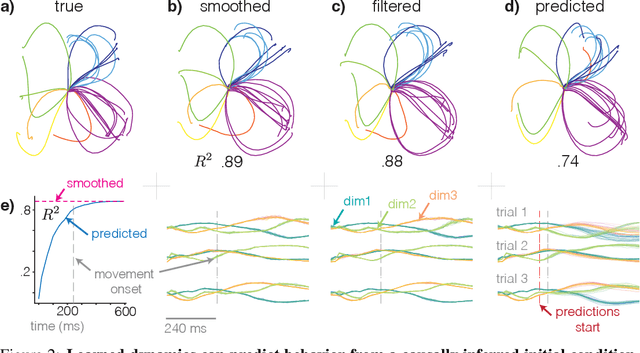
We introduce an amortized variational inference algorithm and structured variational approximation for state-space models with nonlinear dynamics driven by Gaussian noise. Importantly, the proposed framework allows for efficient evaluation of the ELBO and low-variance stochastic gradient estimates without resorting to diagonal Gaussian approximations by exploiting (i) the low-rank structure of Monte-Carlo approximations to marginalize the latent state through the dynamics (ii) an inference network that approximates the update step with low-rank precision matrix updates (iii) encoding current and future observations into pseudo observations -- transforming the approximate smoothing problem into an (easier) approximate filtering problem. Overall, the necessary statistics and ELBO can be computed in $O(TL(Sr + S^2 + r^2))$ time where $T$ is the series length, $L$ is the state-space dimensionality, $S$ are the number of samples used to approximate the predict step statistics, and $r$ is the rank of the approximate precision matrix update in the update step (which can be made of much lower dimension than $L$).