 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multigraph Topology Design for Cross-Silo Federated Learning
Jul 21, 2022
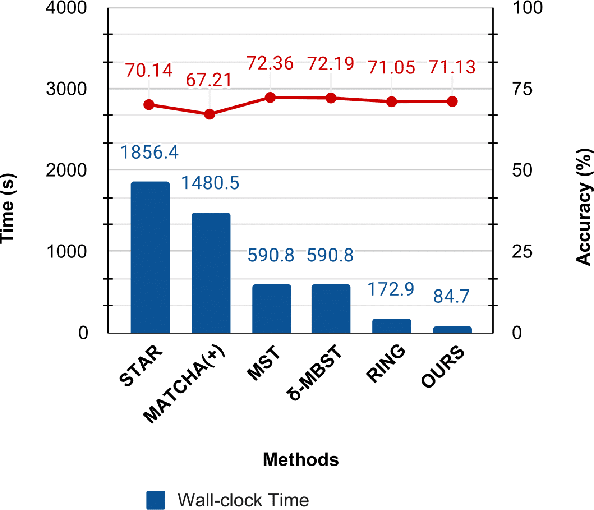
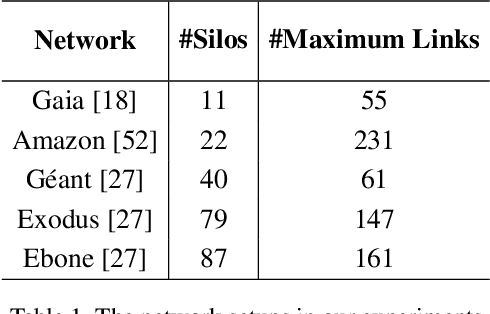
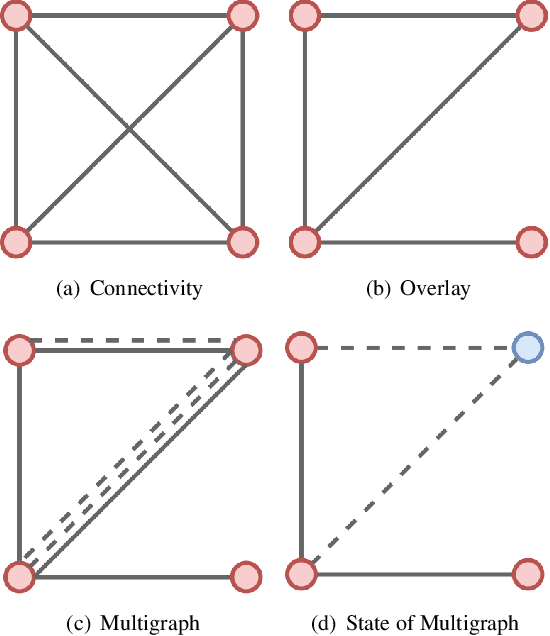
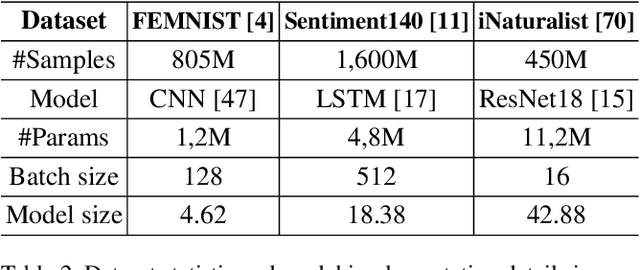
Cross-silo federated learning utilizes a few hundred reliable data silos with high-speed access links to jointly train a model. While this approach becomes a popular setting in federated learning, designing a robust topology to reduce the training time is still an open problem. In this paper, we present a new multigraph topology for cross-silo federated learning. We first construct the multigraph using the overlay graph. We then parse this multigraph into different simple graphs with isolated nodes. The existence of isolated nodes allows us to perform model aggregation without waiting for other nodes, hence reducing the training time. We further propose a new distributed learning algorithm to use with our multigraph topology. The intensive experiments on public datasets show that our proposed method significantly reduces the training time compared with recent state-of-the-art topologies while ensuring convergence and maintaining the model's accuracy.
Model Predictive Control for Dynamic Cloth Manipulation: Parameter Learning and Experimental Validation
Sep 20, 2022
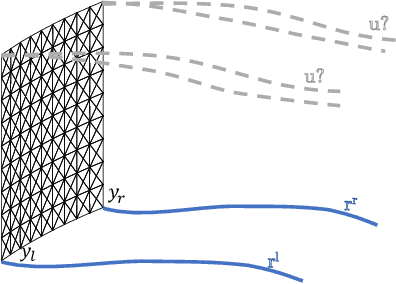
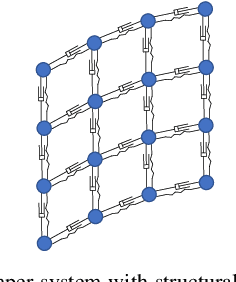
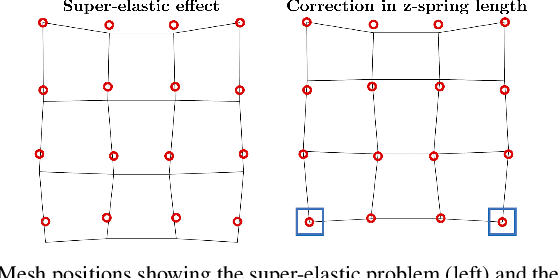
Robotic cloth manipulation is a relevant challenging problem for autonomous robotic systems. Highly deformable objects as textile items can adopt multiple configurations and shapes during their manipulation. Hence, robots should not only understand the current cloth configuration but also be able to predict the future possible behaviors of the cloth. This paper addresses the problem of indirectly controlling the configuration of certain points of a textile object, by applying actions on other parts of the object through the use of a Model Predictive Control (MPC) strategy, which also allows to foresee the behavior of indirectly controlled points. The designed controller finds the optimal control signals to attain the desired future target configuration. The explored scenario in this paper considers tracking a reference trajectory with the lower corners of a square piece of cloth by grasping its upper corners. To do so, we propose and validate a linear cloth model that allows solving the MPC-related optimization problem in real time. Reinforcement Learning (RL) techniques are used to learn the optimal parameters of the proposed cloth model and also to tune the resulting MPC. After obtaining accurate tracking results in simulation, the full control scheme was implemented and executed in a real robot, obtaining accurate tracking even in adverse conditions. While total observed errors reach the 5 cm mark, for a 30x30 cm cloth, an analysis shows the MPC contributes less than 30% to that value.
A Novel Data Augmentation Technique for Out-of-Distribution Sample Detection using Compounded Corruptions
Jul 28, 2022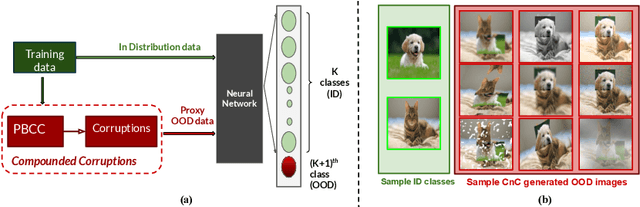
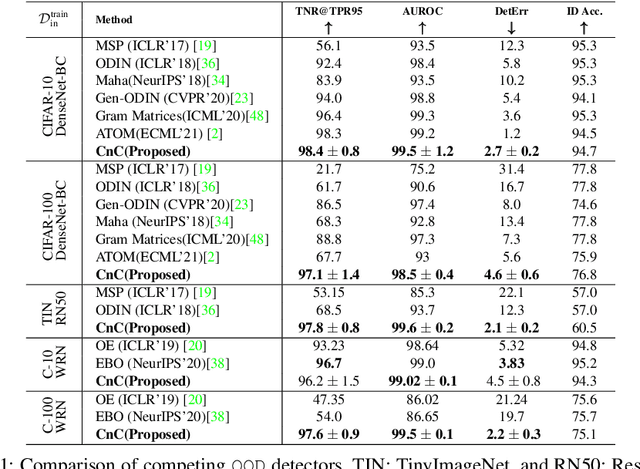
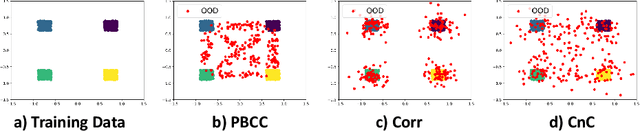
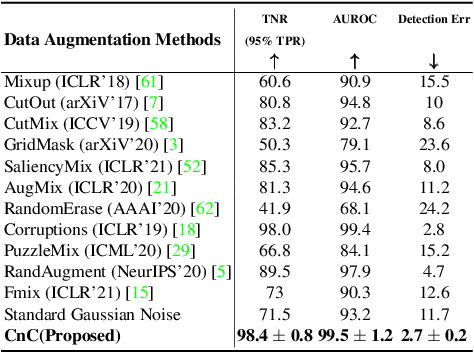
Modern deep neural network models are known to erroneously classify out-of-distribution (OOD) test data into one of the in-distribution (ID) training classes with high confidence. This can have disastrous consequences for safety-critical applications. A popular mitigation strategy is to train a separate classifier that can detect such OOD samples at the test time. In most practical settings OOD examples are not known at the train time, and hence a key question is: how to augment the ID data with synthetic OOD samples for training such an OOD detector? In this paper, we propose a novel Compounded Corruption technique for the OOD data augmentation termed CnC. One of the major advantages of CnC is that it does not require any hold-out data apart from the training set. Further, unlike current state-of-the-art (SOTA) techniques, CnC does not require backpropagation or ensembling at the test time, making our method much faster at inference. Our extensive comparison with 20 methods from the major conferences in last 4 years show that a model trained using CnC based data augmentation, significantly outperforms SOTA, both in terms of OOD detection accuracy as well as inference time. We include a detailed post-hoc analysis to investigate the reasons for the success of our method and identify higher relative entropy and diversity of CnC samples as probable causes. We also provide theoretical insights via a piece-wise decomposition analysis on a two-dimensional dataset to reveal (visually and quantitatively) that our approach leads to a tighter boundary around ID classes, leading to better detection of OOD samples. Source code link: https://github.com/cnc-ood
A Visual Analytics System for Improving Attention-based Traffic Forecasting Models
Aug 11, 2022
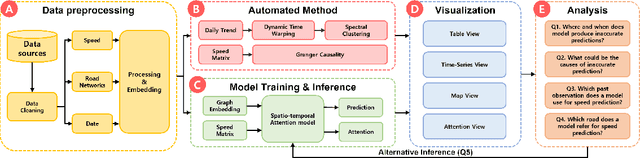
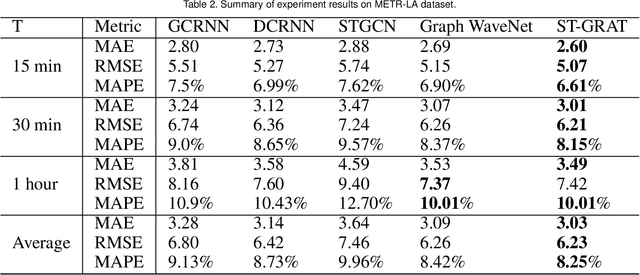
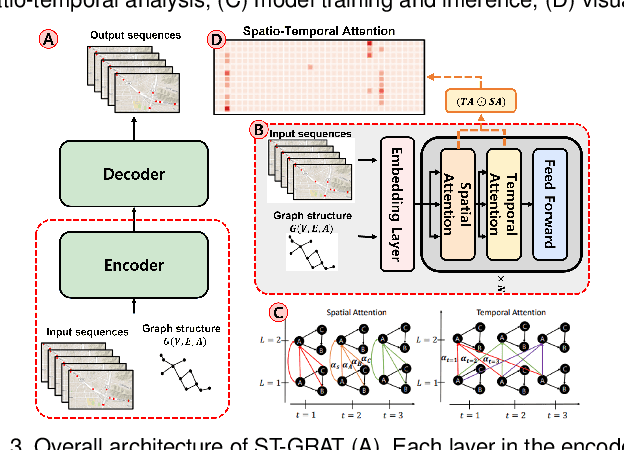
With deep learning (DL) outperforming conventional methods for different tasks, much effort has been devoted to utilizing DL in various domains. Researchers and developers in the traffic domain have also designed and improved DL models for forecasting tasks such as estimation of traffic speed and time of arrival. However, there exist many challenges in analyzing DL models due to the black-box property of DL models and complexity of traffic data (i.e., spatio-temporal dependencies). Collaborating with domain experts, we design a visual analytics system, AttnAnalyzer, that enables users to explore how DL models make predictions by allowing effective spatio-temporal dependency analysis. The system incorporates dynamic time warping (DTW) and Granger causality tests for computational spatio-temporal dependency analysis while providing map, table, line chart, and pixel views to assist user to perform dependency and model behavior analysis. For the evaluation, we present three case studies showing how AttnAnalyzer can effectively explore model behaviors and improve model performance in two different road networks. We also provide domain expert feedback.
DandelionTouch: High Fidelity Haptic Rendering of Soft Objects in VR by a Swarm of Drones
Sep 22, 2022
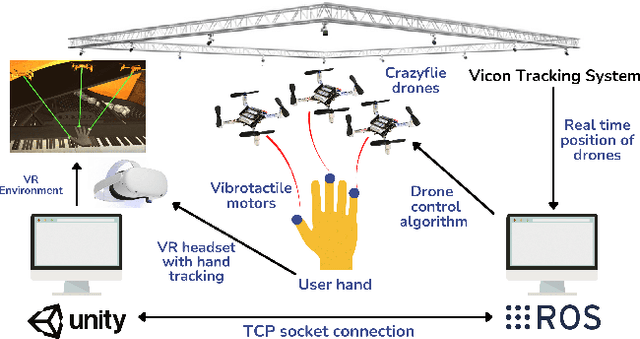
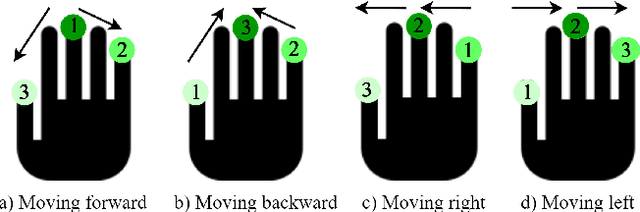
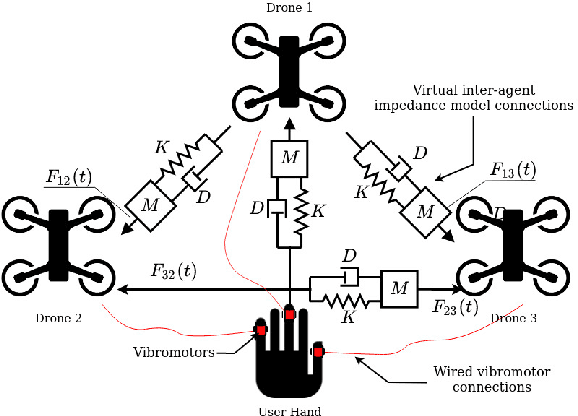
To achieve high fidelity haptic rendering of soft objects in a high mobility virtual environment, we propose a novel haptic display DandelionTouch. The tactile actuators are delivered to the fingertips of the user by a swarm of drones. Users of DandelionTouch are capable of experiencing tactile feedback in a large space that is not limited by the device's working area. Importantly, they will not experience muscle fatigue during long interactions with virtual objects. Hand tracking and swarm control algorithm allow guiding the swarm with hand motions and avoid collisions inside the formation. Several topologies of the impedance connection between swarm units were investigated in this research. The experiment, in which drones performed a point following task on a square trajectory in real-time, revealed that drones connected in a Star topology performed the trajectory with low mean positional error (RMSE decreased by 20.6% in comparison with other impedance topologies and by 40.9% in comparison with potential field-based swarm control). The achieved velocities of the drones in all formations with impedance behavior were 28% higher than for the swarm controlled with the potential field algorithm. Additionally, the perception of several vibrotactile patterns was evaluated in a user study with 7 participants. The study has shown that the proposed combination of temporal delay and frequency modulation allows users to successfully recognize the surface property and motion direction in VR simultaneously (mean recognition rate of 70%, maximum of 93%). DandelionTouch suggests a new type of haptic feedback in VR systems where no hand-held or wearable interface is required.
Branching Time Active Inference with Bayesian Filtering
Dec 14, 2021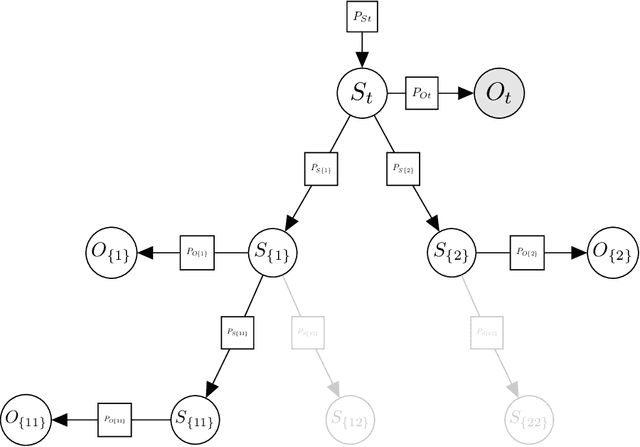
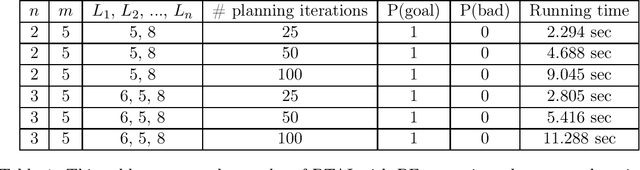
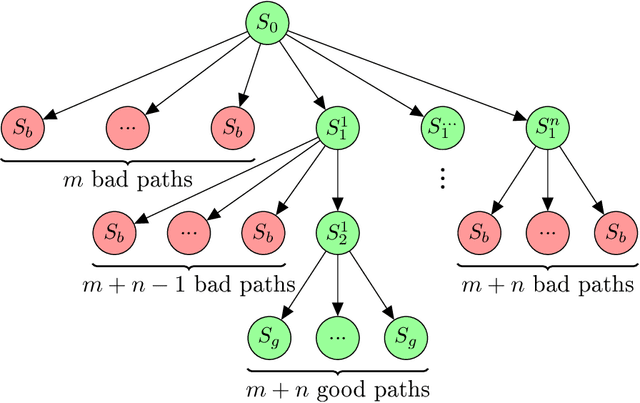
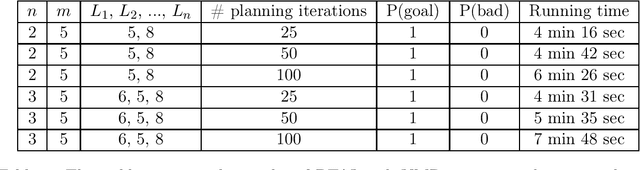
Branching Time Active Inference (Champion et al., 2021b,a) is a framework proposing to look at planning as a form of Bayesian model expansion. Its root can be found in Active Inference (Friston et al., 2016; Da Costa et al., 2020; Champion et al., 2021c), a neuroscientific framework widely used for brain modelling, as well as in Monte Carlo Tree Search (Browne et al., 2012), a method broadly applied in the Reinforcement Learning literature. Up to now, the inference of the latent variables was carried out by taking advantage of the flexibility offered by Variational Message Passing (Winn and Bishop, 2005), an iterative process that can be understood as sending messages along the edges of a factor graph (Forney, 2001). In this paper, we harness the efficiency of an alternative method for inference called Bayesian Filtering (Fox et al., 2003), which does not require the iteration of the update equations until convergence of the Variational Free Energy. Instead, this scheme alternates between two phases: integration of evidence and prediction of future states. Both of those phases can be performed efficiently and this provides a seventy times speed up over the state-of-the-art.
NAAP-440 Dataset and Baseline for Neural Architecture Accuracy Prediction
Sep 15, 2022
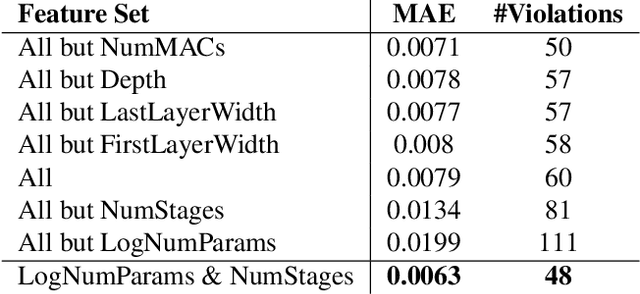
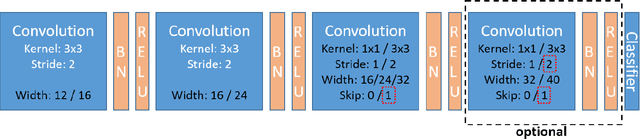
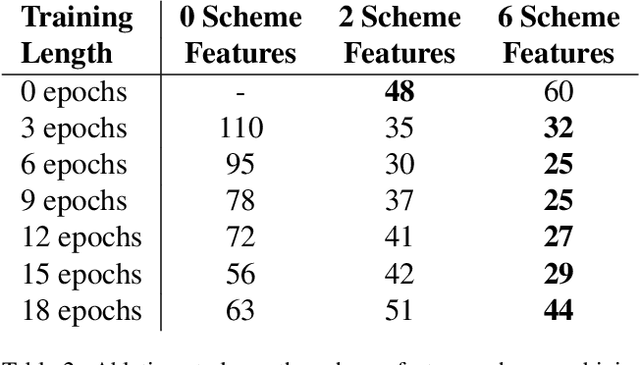
Neural architecture search (NAS) has become a common approach to developing and discovering new neural architectures for different target platforms and purposes. However, scanning the search space is comprised of long training processes of many candidate architectures, which is costly in terms of computational resources and time. Regression algorithms are a common tool to predicting a candidate architecture's accuracy, which can dramatically accelerate the search procedure. We aim at proposing a new baseline that will support the development of regression algorithms that can predict an architecture's accuracy just from its scheme, or by only training it for a minimal number of epochs. Therefore, we introduce the NAAP-440 dataset of 440 neural architectures, which were trained on CIFAR10 using a fixed recipe. Our experiments indicate that by using off-the-shelf regression algorithms and running up to 10% of the training process, not only is it possible to predict an architecture's accuracy rather precisely, but that the values predicted for the architectures also maintain their accuracy order with a minimal number of monotonicity violations. This approach may serve as a powerful tool for accelerating NAS-based studies and thus dramatically increase their efficiency. The dataset and code used in the study have been made public.
Streaming Reconstruction from Non-uniform Samples
Aug 02, 2022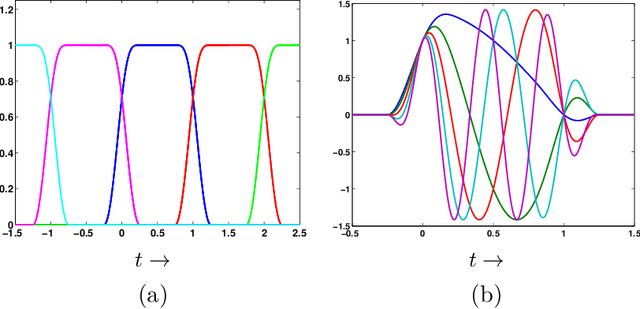
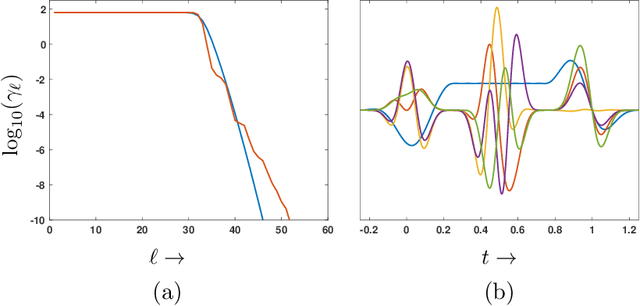
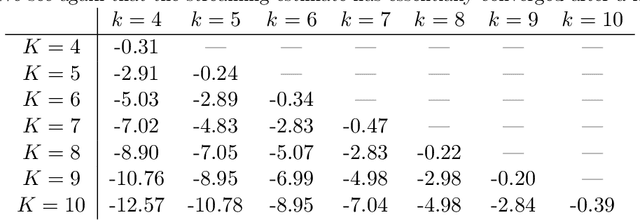
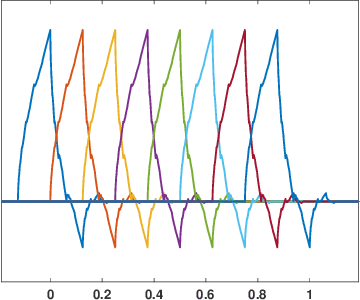
We present an online algorithm for reconstructing a signal from a set of non-uniform samples. By representing the signal using compactly supported basis functions, we show how estimating the expansion coefficients using least-squares can be implemented in a streaming manner: as batches of samples over subsequent time intervals are presented, the algorithm forms an initial estimate of the signal over the sampling interval then updates its estimates over previous intervals. We give conditions under which this reconstruction procedure is stable and show that the least-squares estimates in each interval converge exponentially, meaning that the updates can be performed with finite memory with almost no loss in accuracy. We also discuss how our framework extends to more general types of measurements including time-varying convolution with a compactly supported kernel.
BERT-based Ensemble Approaches for Hate Speech Detection
Sep 15, 2022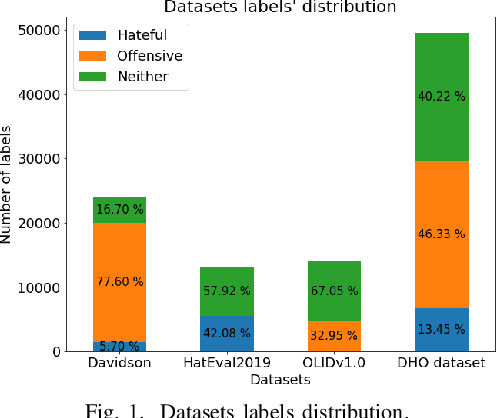
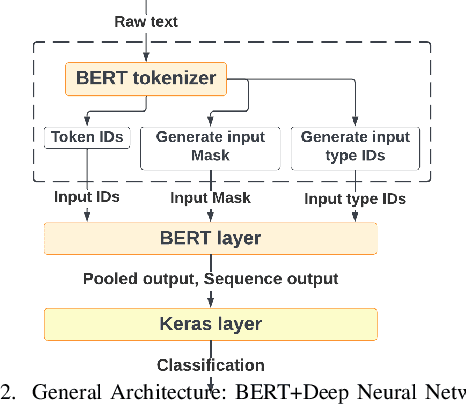
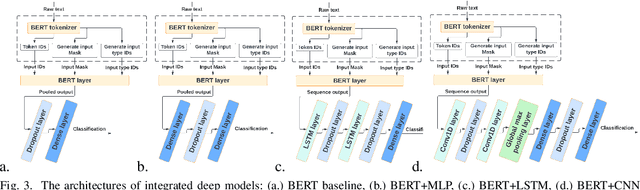
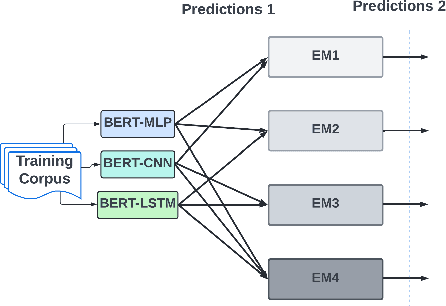
With the freedom of communication provided in online social media, hate speech has increasingly generated. This leads to cyber conflicts affecting social life at the individual and national levels. As a result, hateful content classification is becoming increasingly demanded for filtering hate content before being sent to the social networks. This paper focuses on classifying hate speech in social media using multiple deep models that are implemented by integrating recent transformer-based language models such as BERT, and neural networks. To improve the classification performances, we evaluated with several ensemble techniques, including soft voting, maximum value, hard voting and stacking. We used three publicly available Twitter datasets (Davidson, HatEval2019, OLID) that are generated to identify offensive languages. We fused all these datasets to generate a single dataset (DHO dataset), which is more balanced across different labels, to perform multi-label classification. Our experiments have been held on Davidson dataset and the DHO corpora. The later gave the best overall results, especially F1 macro score, even it required more resources (time execution and memory). The experiments have shown good results especially the ensemble models, where stacking gave F1 score of 97% on Davidson dataset and aggregating ensembles 77% on the DHO dataset.
A Novel Deep Parallel Time-series Relation Network for Fault Diagnosis
Dec 03, 2021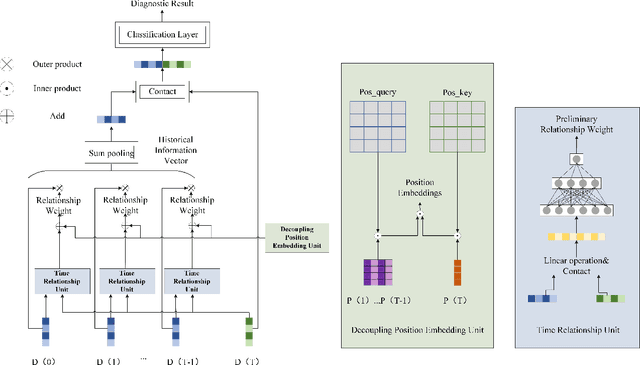

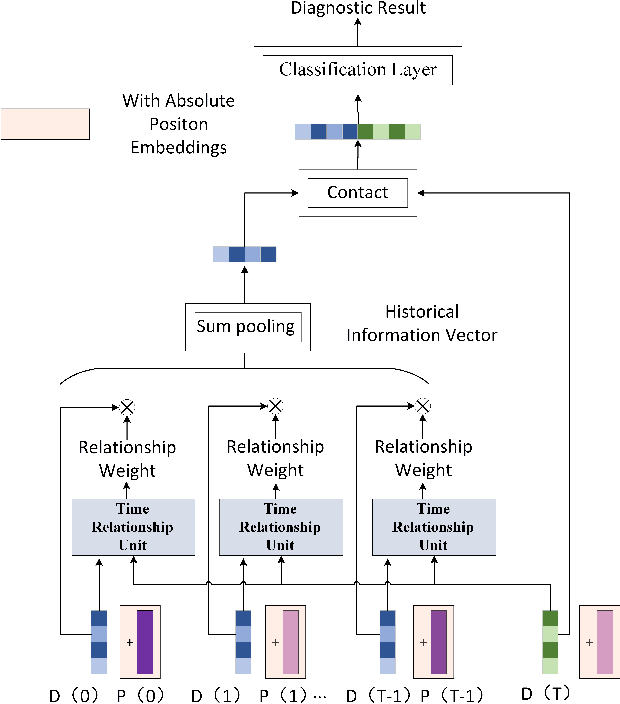

Considering the models that apply the contextual information of time-series data could improve the fault diagnosis performance, some neural network structures such as RNN, LSTM, and GRU were proposed to model the industrial process effectively. However, these models are restricted by their serial computation and hence cannot achieve high diagnostic efficiency. Also the parallel CNN is difficult to implement fault diagnosis in an efficient way because it requires larger convolution kernels or deep structure to achieve long-term feature extraction capabilities. Besides, BERT model applies absolute position embedding to introduce contextual information to the model, which would bring noise to the raw data and therefore cannot be applied to fault diagnosis directly. In order to address the above problems, a fault diagnosis model named deep parallel time-series relation network(\textit{DPTRN}) has been proposed in this paper. There are mainly three advantages for DPTRN: (1) Our proposed time relationship unit is based on full multilayer perceptron(\textit{MLP}) structure, therefore, DPTRN performs fault diagnosis in a parallel way and improves computing efficiency significantly. (2) By improving the absolute position embedding, our novel decoupling position embedding unit could be applied on the fault diagnosis directly and learn contextual information. (3) Our proposed DPTRN has obvious advantage in feature interpretability. Our model outperforms other methods on both TE and KDD-CUP99 datasets which confirms the effectiveness, efficiency and interpretability of the proposed DPTRN model.