 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Ensembles of Reinforcement Learning Agents for Electricity Control
Aug 30, 2022
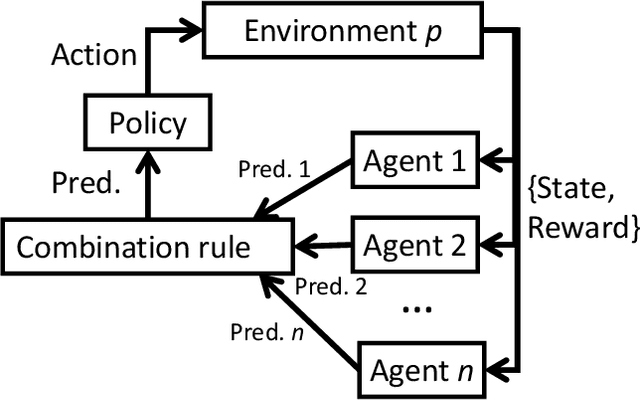
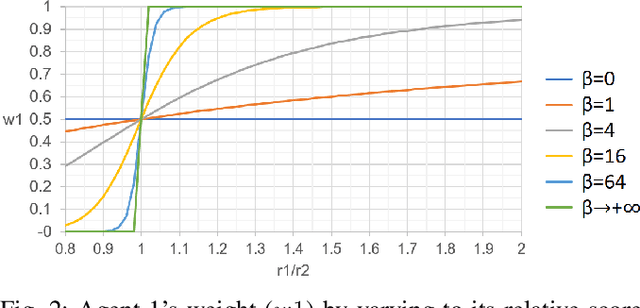
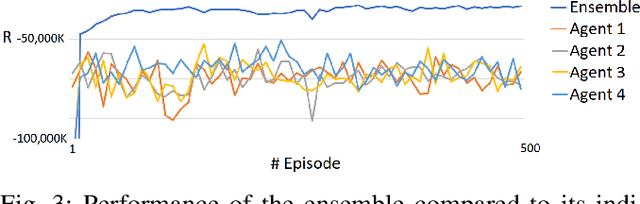
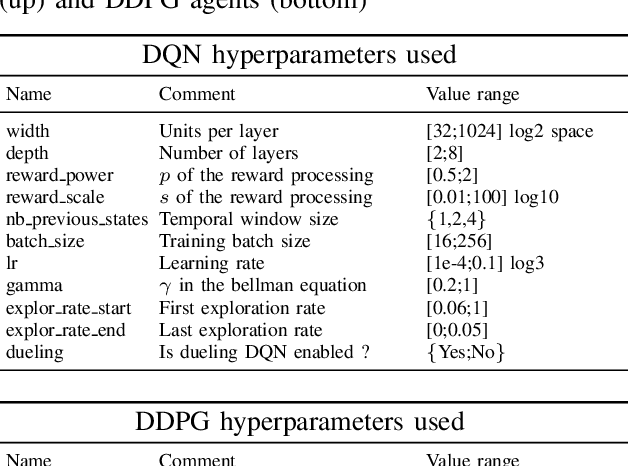
Deep Reinforcement Learning (or just "RL") is gaining popularity for industrial and research applications. However, it still suffers from some key limits slowing down its widespread adoption. Its performance is sensitive to initial conditions and non-determinism. To unlock those challenges, we propose a procedure for building ensembles of RL agents to efficiently build better local decisions toward long-term cumulated rewards. For the first time, hundreds of experiments have been done to compare different ensemble constructions procedures in 2 electricity control environments. We discovered an ensemble of 4 agents improves accumulated rewards by 46%, improves reproducibility by a factor of 3.6, and can naturally and efficiently train and predict in parallel on GPUs and CPUs.
FrameHopper: Selective Processing of Video Frames in Detection-driven Real-Time Video Analytics
Mar 22, 2022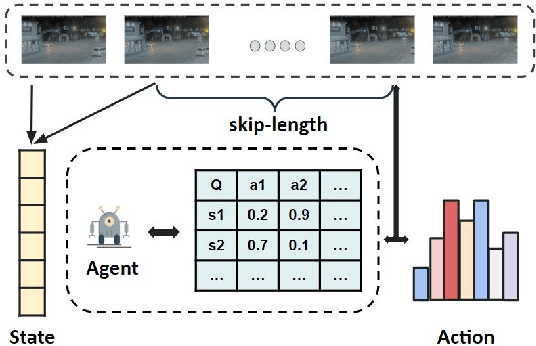
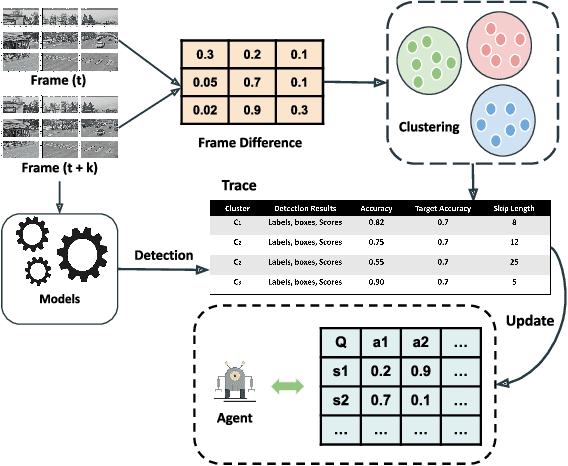
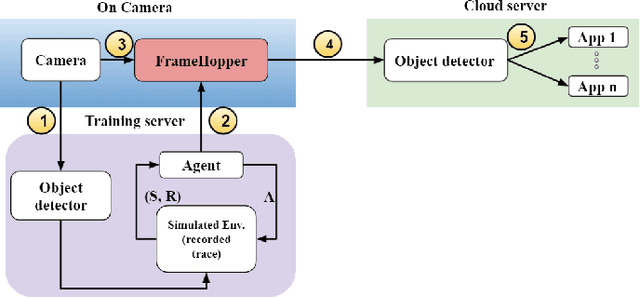

Detection-driven real-time video analytics require continuous detection of objects contained in the video frames using deep learning models like YOLOV3, EfficientDet. However, running these detectors on each and every frame in resource-constrained edge devices is computationally intensive. By taking the temporal correlation between consecutive video frames into account, we note that detection outputs tend to be overlapping in successive frames. Elimination of similar consecutive frames will lead to a negligible drop in performance while offering significant performance benefits by reducing overall computation and communication costs. The key technical questions are, therefore, (a) how to identify which frames to be processed by the object detector, and (b) how many successive frames can be skipped (called skip-length) once a frame is selected to be processed. The overall goal of the process is to keep the error due to skipping frames as small as possible. We introduce a novel error vs processing rate optimization problem with respect to the object detection task that balances between the error rate and the fraction of frames filtering. Subsequently, we propose an off-line Reinforcement Learning (RL)-based algorithm to determine these skip-lengths as a state-action policy of the RL agent from a recorded video and then deploy the agent online for live video streams. To this end, we develop FrameHopper, an edge-cloud collaborative video analytics framework, that runs a lightweight trained RL agent on the camera and passes filtered frames to the server where the object detection model runs for a set of applications. We have tested our approach on a number of live videos captured from real-life scenarios and show that FrameHopper processes only a handful of frames but produces detection results closer to the oracle solution and outperforms recent state-of-the-art solutions in most cases.
Topological Attention for Time Series Forecasting
Jul 19, 2021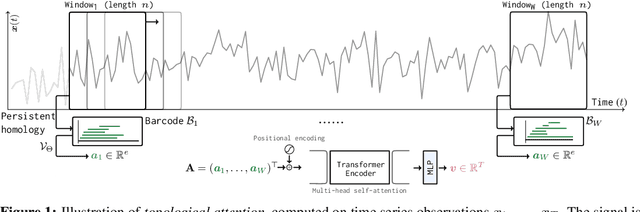
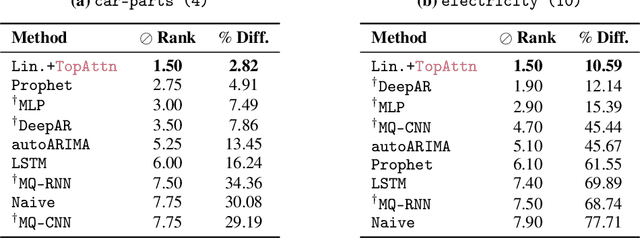
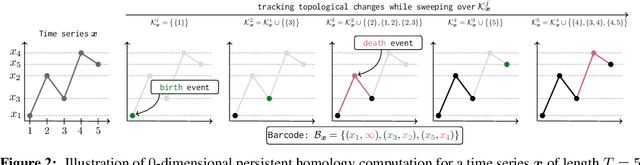
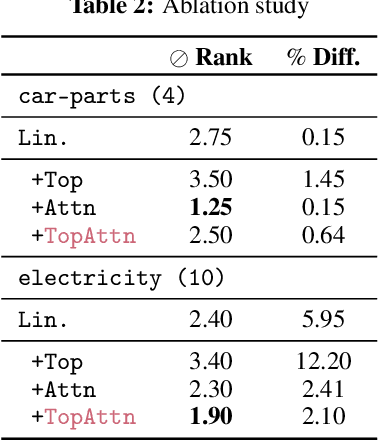
The problem of (point) forecasting $ \textit{univariate} $ time series is considered. Most approaches, ranging from traditional statistical methods to recent learning-based techniques with neural networks, directly operate on raw time series observations. As an extension, we study whether $\textit{local topological properties}$, as captured via persistent homology, can serve as a reliable signal that provides complementary information for learning to forecast. To this end, we propose $\textit{topological attention}$, which allows attending to local topological features within a time horizon of historical data. Our approach easily integrates into existing end-to-end trainable forecasting models, such as $\texttt{N-BEATS}$, and in combination with the latter exhibits state-of-the-art performance on the large-scale M4 benchmark dataset of 100,000 diverse time series from different domains. Ablation experiments, as well as a comparison to a broad range of forecasting methods in a setting where only a single time series is available for training, corroborate the beneficial nature of including local topological information through an attention mechanism.
Branching Time Active Inference: empirical study and complexity class analysis
Nov 22, 2021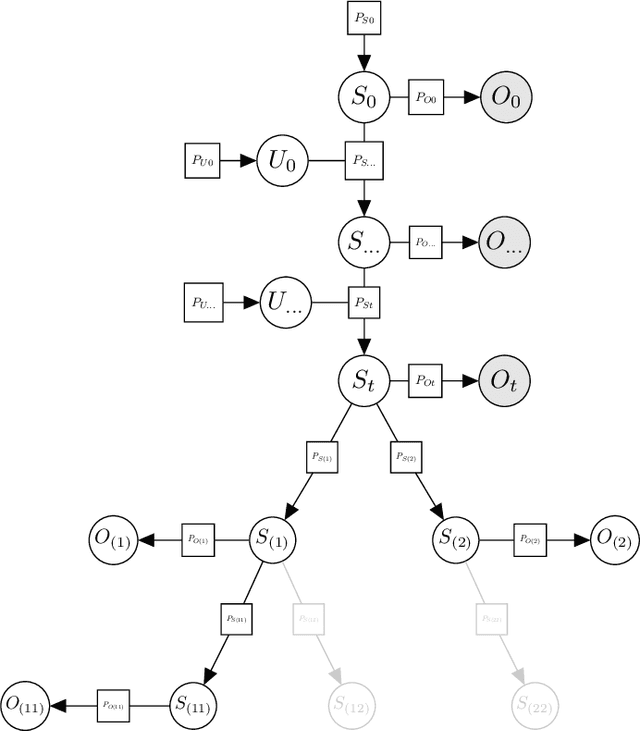
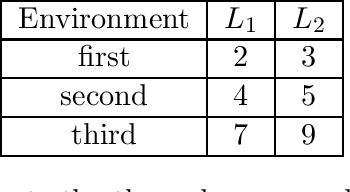
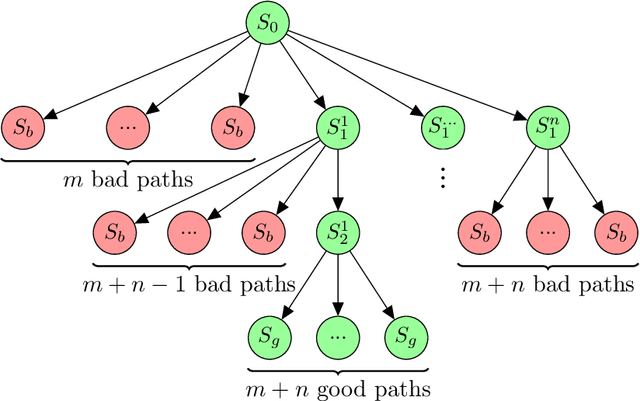
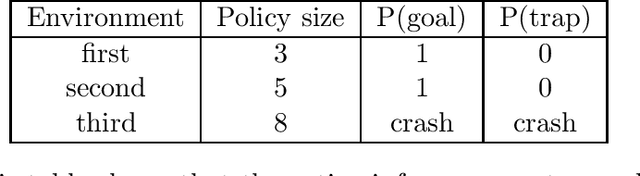
Active inference is a state-of-the-art framework for modelling the brain that explains a wide range of mechanisms such as habit formation, dopaminergic discharge and curiosity. However, recent implementations suffer from an exponential (space and time) complexity class when computing the prior over all the possible policies up to the time horizon. Fountas et al. (2020) used Monte Carlo tree search to address this problem, leading to very good results in two different tasks. Additionally, Champion et al. (2021a) proposed a tree search approach based on structure learning. This was enabled by the development of a variational message passing approach to active inference (Champion et al., 2021b), which enables compositional construction of Bayesian networks for active inference. However, this message passing tree search approach, which we call branching-time active inference (BTAI), has never been tested empirically. In this paper, we present an experimental study of the approach (Champion et al., 2021a) in the context of a maze solving agent. In this context, we show that both improved prior preferences and deeper search help mitigate the vulnerability to local minima. Then, we compare BTAI to standard active inference (AI) on a graph navigation task. We show that for small graphs, both BTAI and AI successfully solve the task. For larger graphs, AI exhibits an exponential (space) complexity class, making the approach intractable. However, BTAI explores the space of policies more efficiently, successfully scaling to larger graphs.
Forensic Dental Age Estimation Using Modified Deep Learning Neural Network
Aug 21, 2022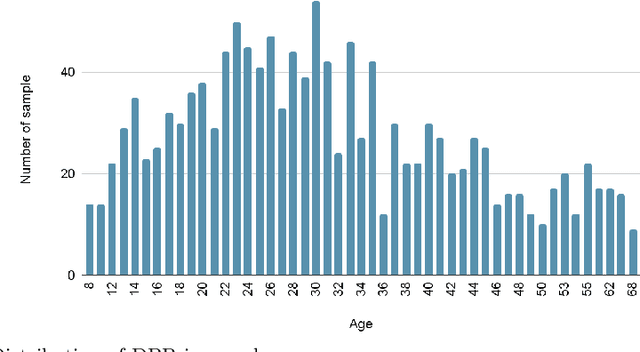
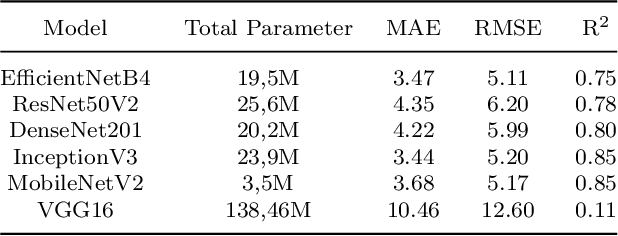
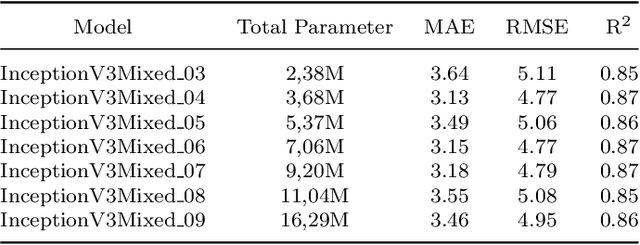
Dental age is one of the most reliable methods to identify an individual's age. By using dental panoramic radiography (DPR) images, physicians and pathologists in forensic sciences try to establish the chronological age of individuals with no valid legal records or registered patients. The current methods in practice demand intensive labor, time, and qualified experts. The development of deep learning algorithms in the field of medical image processing has improved the sensitivity of predicting truth values while reducing the processing speed of imaging time. This study proposed an automated approach to estimate the forensic ages of individuals ranging in age from 8 to 68 using 1,332 DPR images. Initially, experimental analyses were performed with the transfer learning-based models, including InceptionV3, DenseNet201, EfficientNetB4, MobileNetV2, VGG16, and ResNet50V2; and accordingly, the best-performing model, InceptionV3, was modified, and a new neural network model was developed. Reducing the number of the parameters already available in the developed model architecture resulted in a faster and more accurate dental age estimation. The performance metrics of the results attained were as follows: mean absolute error (MAE) was 3.13, root mean square error (RMSE) was 4.77, and correlation coefficient R$^2$ was 87%. It is conceivable to propose the new model as potentially dependable and practical ancillary equipment in forensic sciences and dental medicine.
A Zero-Shot Adaptive Quadcopter Controller
Sep 19, 2022



This paper proposes a universal adaptive controller for quadcopters, which can be deployed zero-shot to quadcopters of very different mass, arm lengths and motor constants, and also shows rapid adaptation to unknown disturbances during runtime. The core algorithmic idea is to learn a single policy that can adapt online at test time not only to the disturbances applied to the drone, but also to the robot dynamics and hardware in the same framework. We achieve this by training a neural network to estimate a latent representation of the robot and environment parameters, which is used to condition the behaviour of the controller, also represented as a neural network. We train both networks exclusively in simulation with the goal of flying the quadcopters to goal positions and avoiding crashes to the ground. We directly deploy the same controller trained in the simulation without any modifications on two quadcopters with differences in mass, inertia, and maximum motor speed of up to 4 times. In addition, we show rapid adaptation to sudden and large disturbances (up to 35.7%) in the mass and inertia of the quadcopters. We perform an extensive evaluation in both simulation and the physical world, where we outperform a state-of-the-art learning-based adaptive controller and a traditional PID controller specifically tuned to each platform individually. Video results can be found at https://dz298.github.io/universal-drone-controller/.
Automated Fidelity Assessment for Strategy Training in Inpatient Rehabilitation using Natural Language Processing
Sep 14, 2022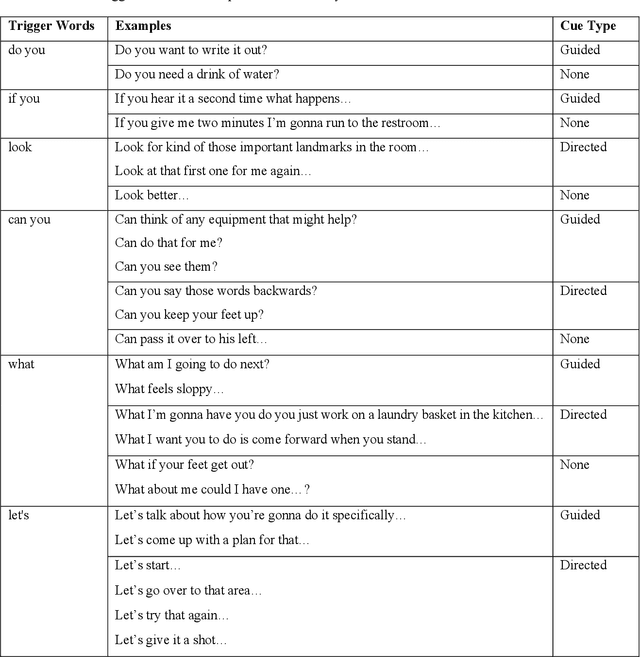
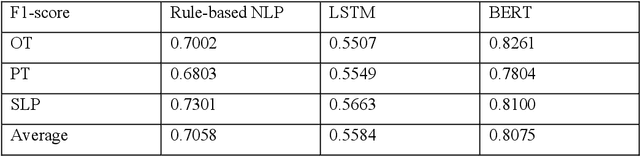
Strategy training is a multidisciplinary rehabilitation approach that teaches skills to reduce disability among those with cognitive impairments following a stroke. Strategy training has been shown in randomized, controlled clinical trials to be a more feasible and efficacious intervention for promoting independence than traditional rehabilitation approaches. A standardized fidelity assessment is used to measure adherence to treatment principles by examining guided and directed verbal cues in video recordings of rehabilitation sessions. Although the fidelity assessment for detecting guided and directed verbal cues is valid and feasible for single-site studies, it can become labor intensive, time consuming, and expensive in large, multi-site pragmatic trials. To address this challenge to widespread strategy training implementation, we leveraged natural language processing (NLP) techniques to automate the strategy training fidelity assessment, i.e., to automatically identify guided and directed verbal cues from video recordings of rehabilitation sessions. We developed a rule-based NLP algorithm, a long-short term memory (LSTM) model, and a bidirectional encoder representation from transformers (BERT) model for this task. The best performance was achieved by the BERT model with a 0.8075 F1-score. The findings from this study hold widespread promise in psychology and rehabilitation intervention research and practice.
Visual Localization and Mapping in Dynamic and Changing Environments
Sep 21, 2022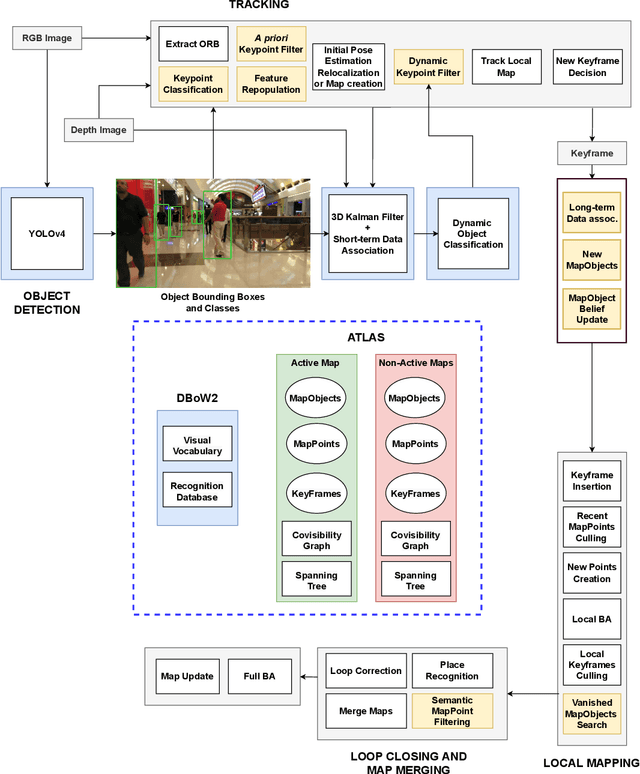
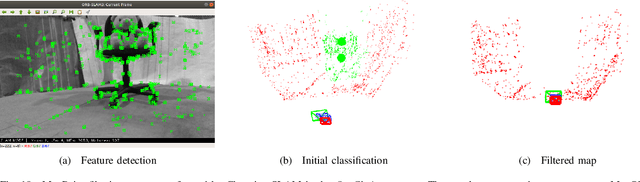
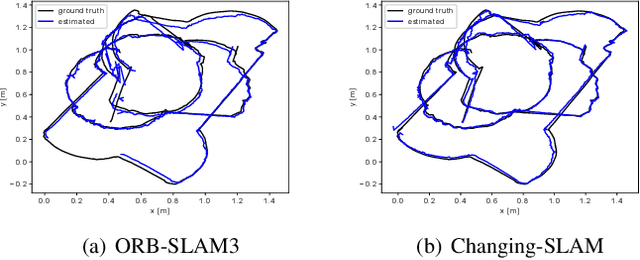
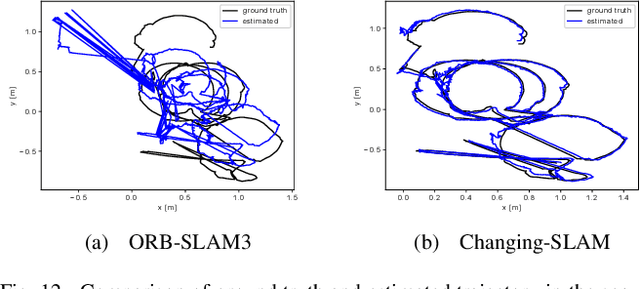
The real-world deployment of fully autonomous mobile robots depends on a robust SLAM (Simultaneous Localization and Mapping) system, capable of handling dynamic environments, where objects are moving in front of the robot, and changing environments, where objects are moved or replaced after the robot has already mapped the scene. This paper presents Changing-SLAM, a method for robust Visual SLAM in both dynamic and changing environments. This is achieved by using a Bayesian filter combined with a long-term data association algorithm. Also, it employs an efficient algorithm for dynamic keypoints filtering based on object detection that correctly identify features inside the bounding box that are not dynamic, preventing a depletion of features that could cause lost tracks. Furthermore, a new dataset was developed with RGB-D data especially designed for the evaluation of changing environments on an object level, called PUC-USP dataset. Six sequences were created using a mobile robot, an RGB-D camera and a motion capture system. The sequences were designed to capture different scenarios that could lead to a tracking failure or a map corruption. To the best of our knowledge, Changing-SLAM is the first Visual SLAM system that is robust to both dynamic and changing environments, not assuming a given camera pose or a known map, being also able to operate in real time. The proposed method was evaluated using benchmark datasets and compared with other state-of-the-art methods, proving to be highly accurate.
Robust DNN Watermarking via Fixed Embedding Weights with Optimized Distribution
Aug 23, 2022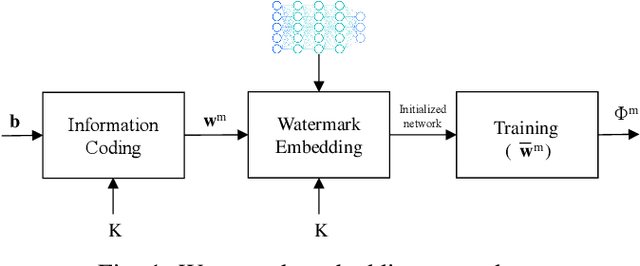
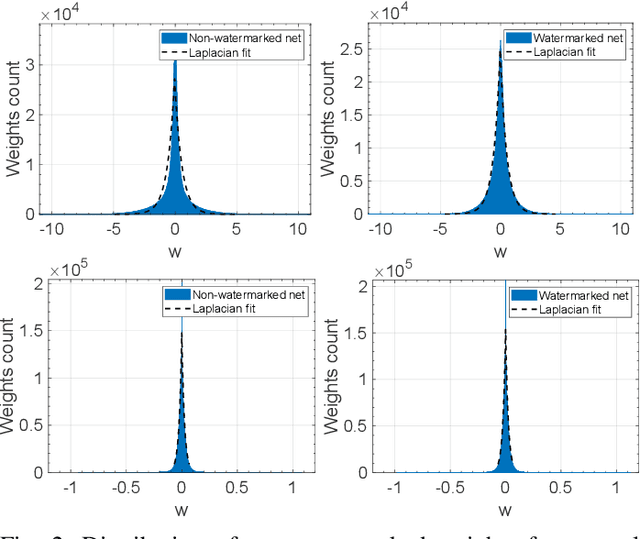
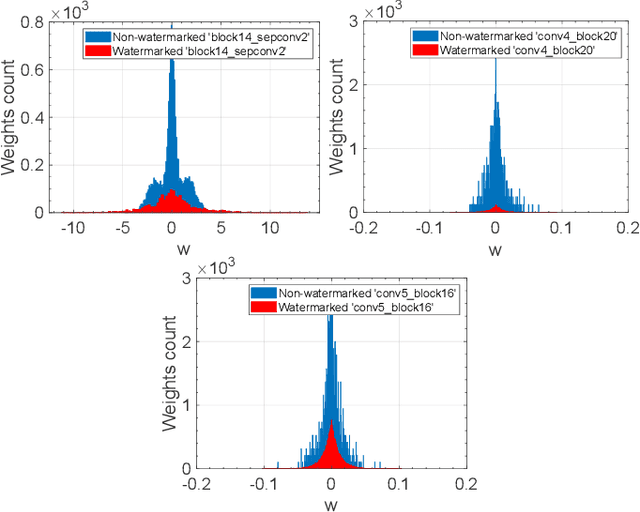
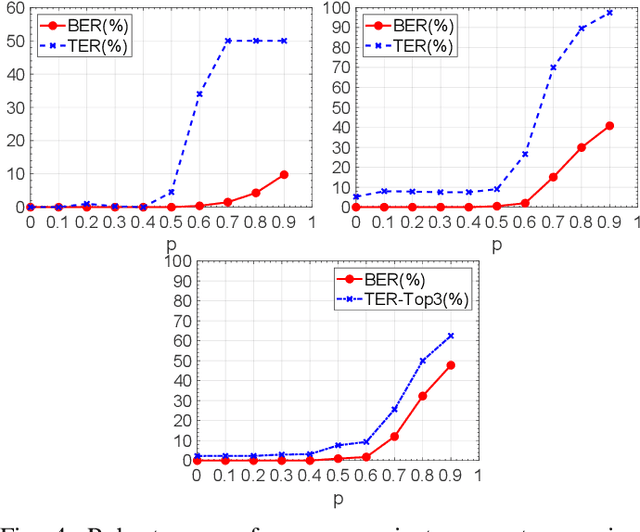
Watermarking has been proposed as a way to protect the Intellectual Property Rights (IPR) of Deep Neural Networks (DNNs) and track their use. Several methods have been proposed that embed the watermark into the trainable parameters of the network (white box watermarking) or into the input-output mappping implemented by the network in correspondence to specific inputs (black box watermarking). In both cases, achieving robustness against fine tuning, model compression and, even more, transfer learning, is one of the most difficult challenges researchers are trying to face with. In this paper, we propose a new white-box, multi-bit watermarking algorithm with strong robustness properties, including retraining for transfer learning. Robustness is achieved thanks to a new information coding strategy according to which the watermark message is spread across a number of fixed weights, whose position depends on a secret key. The weights hosting the watermark are set prior to training, and are left unchanged throughout the entire training procedure. The distribution of the weights carrying out the message is theoretically optimised to make sure that the watermarked weights are indistinguishable from the other weights, while at the same time keeping their amplitude as large as possible to improve robustness against retraining. We carried out several experiments demonstrating the capability of the proposed scheme to provide high payloads with practically no impact on the network accuracy, at the same time retaining excellent robustness against network modifications an re-use, including retraining for transfer learning.
Causal-based Time Series Domain Generalization for Vehicle Intention Prediction
Dec 03, 2021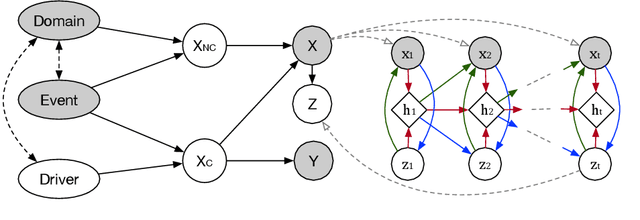



Accurately predicting possible behaviors of traffic participants is an essential capability for autonomous vehicles. Since autonomous vehicles need to navigate in dynamically changing environments, they are expected to make accurate predictions regardless of where they are and what driving circumstances they encountered. Therefore, generalization capability to unseen domains is crucial for prediction models when autonomous vehicles are deployed in the real world. In this paper, we aim to address the domain generalization problem for vehicle intention prediction tasks and a causal-based time series domain generalization (CTSDG) model is proposed. We construct a structural causal model for vehicle intention prediction tasks to learn an invariant representation of input driving data for domain generalization. We further integrate a recurrent latent variable model into our structural causal model to better capture temporal latent dependencies from time-series input data. The effectiveness of our approach is evaluated via real-world driving data. We demonstrate that our proposed method has consistent improvement on prediction accuracy compared to other state-of-the-art domain generalization and behavior prediction methods.