 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Toward Intention Discovery for Early Malice Detection in Bitcoin
Sep 24, 2022
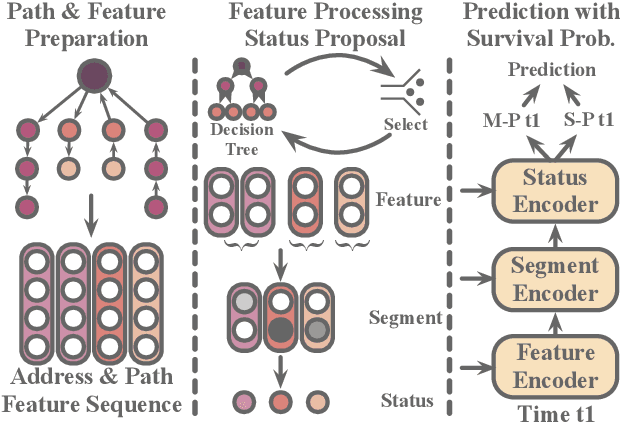
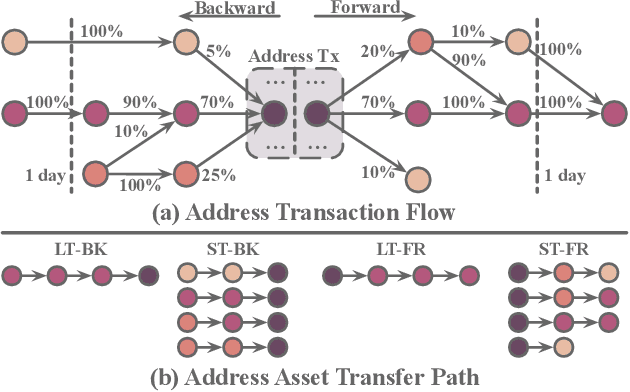
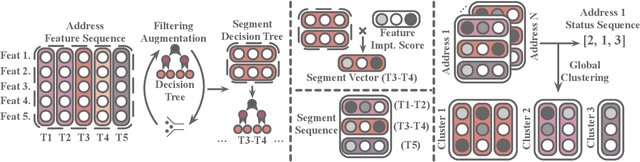
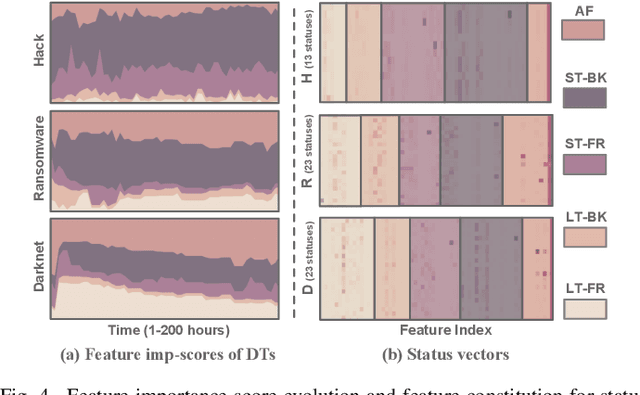
Bitcoin has been subject to illicit activities more often than probably any other financial assets, due to the pseudo-anonymous nature of its transacting entities. An ideal detection model is expected to achieve all the three properties of (I) early detection, (II) good interpretability, and (III) versatility for various illicit activities. However, existing solutions cannot meet all these requirements, as most of them heavily rely on deep learning without satisfying interpretability and are only available for retrospective analysis of a specific illicit type. First, we present asset transfer paths, which aim to describe addresses' early characteristics. Next, with a decision tree based strategy for feature selection and segmentation, we split the entire observation period into different segments and encode each as a segment vector. After clustering all these segment vectors, we get the global status vectors, essentially the basic unit to describe the whole intention. Finally, a hierarchical self-attention predictor predicts the label for the given address in real time. A survival module tells the predictor when to stop and proposes the status sequence, namely intention. % With the type-dependent selection strategy and global status vectors, our model can be applied to detect various illicit activities with strong interpretability. The well-designed predictor and particular loss functions strengthen the model's prediction speed and interpretability one step further. Extensive experiments on three real-world datasets show that our proposed algorithm outperforms state-of-the-art methods. Besides, additional case studies justify our model can not only explain existing illicit patterns but can also find new suspicious characters.
MAGPIE: Machine Automated General Performance Improvement via Evolution of Software
Aug 04, 2022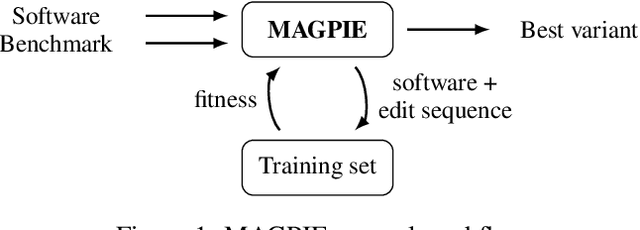
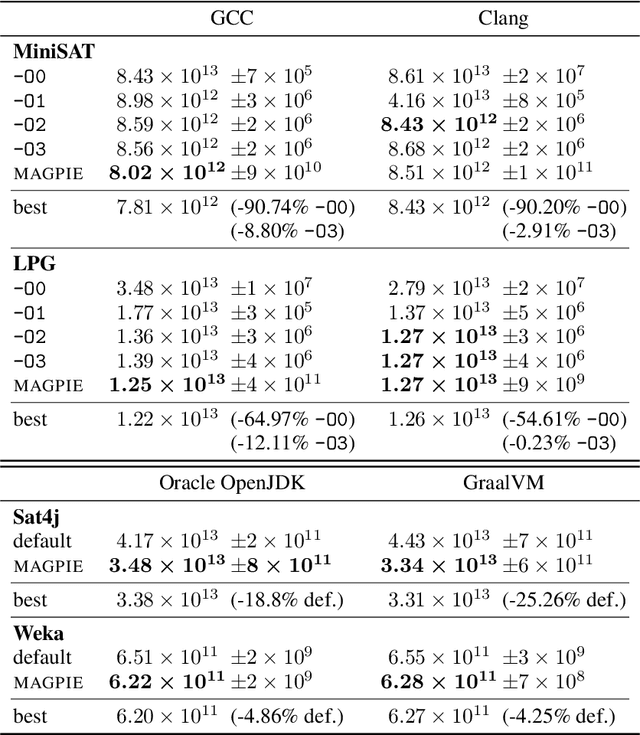
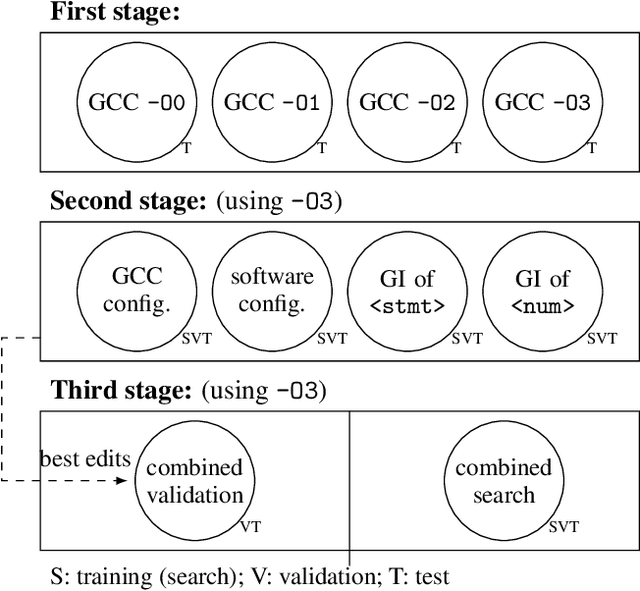
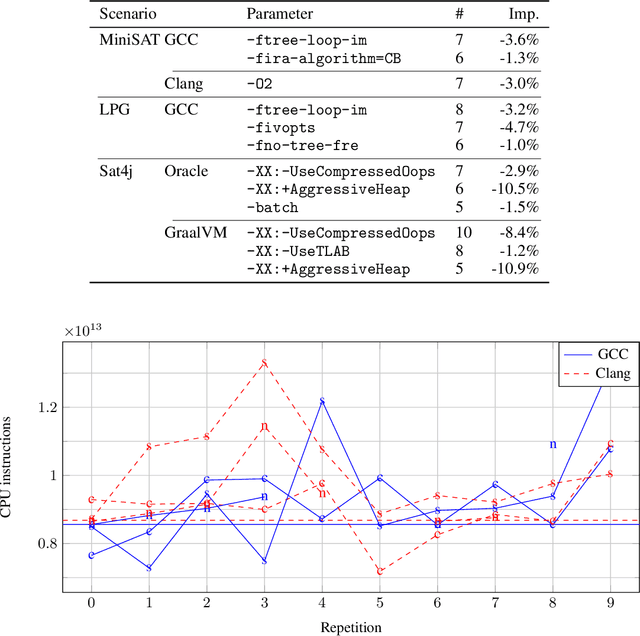
Performance is one of the most important qualities of software. Several techniques have thus been proposed to improve it, such as program transformations, optimisation of software parameters, or compiler flags. Many automated software improvement approaches use similar search strategies to explore the space of possible improvements, yet available tooling only focuses on one approach at a time. This makes comparisons and exploration of interactions of the various types of improvement impractical. We propose MAGPIE, a unified software improvement framework. It provides a common edit sequence based representation that isolates the search process from the specific improvement technique, enabling a much simplified synergistic workflow. We provide a case study using a basic local search to compare compiler optimisation, algorithm configuration, and genetic improvement. We chose running time as our efficiency measure and evaluated our approach on four real-world software, written in C, C++, and Java. Our results show that, used independently, all techniques find significant running time improvements: up to 25% for compiler optimisation, 97% for algorithm configuration, and 61% for evolving source code using genetic improvement. We also show that up to 10% further increase in performance can be obtained with partial combinations of the variants found by the different techniques. Furthermore, the common representation also enables simultaneous exploration of all techniques, providing a competitive alternative to using each technique individually.
Robust Action Governor for Uncertain Piecewise Affine Systems with Non-convex Constraints and Safe Reinforcement Learning
Jul 17, 2022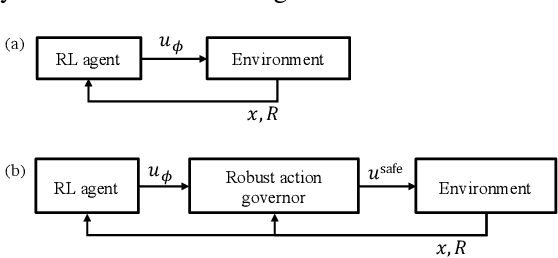
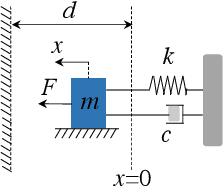
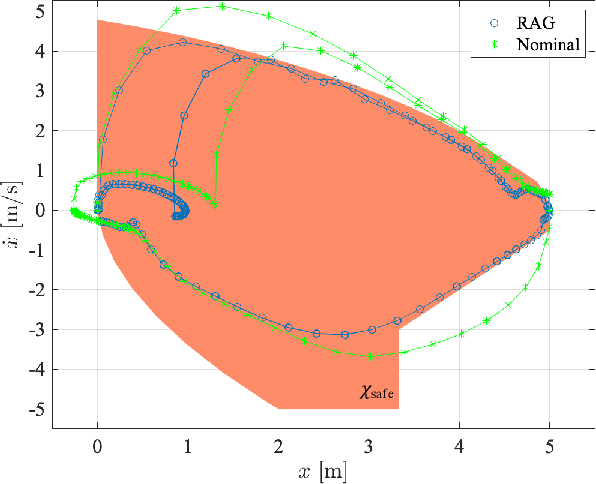
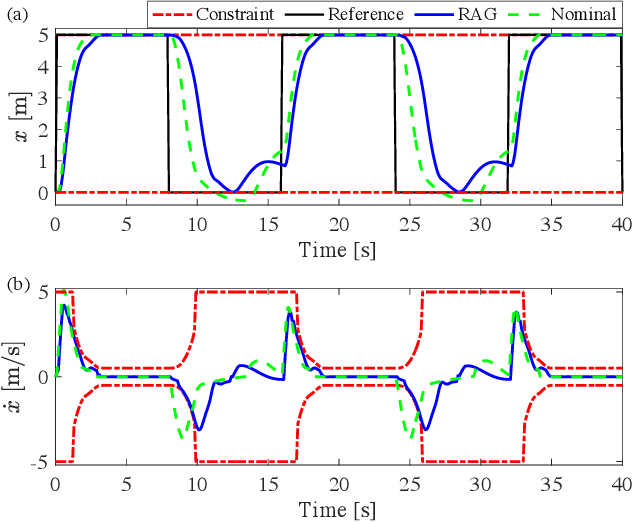
The action governor is an add-on scheme to a nominal control loop that monitors and adjusts the control actions to enforce safety specifications expressed as pointwise-in-time state and control constraints. In this paper, we introduce the Robust Action Governor (RAG) for systems the dynamics of which can be represented using discrete-time Piecewise Affine (PWA) models with both parametric and additive uncertainties and subject to non-convex constraints. We develop the theoretical properties and computational approaches for the RAG. After that, we introduce the use of the RAG for realizing safe Reinforcement Learning (RL), i.e., ensuring all-time constraint satisfaction during online RL exploration-and-exploitation process. This development enables safe real-time evolution of the control policy and adaptation to changes in the operating environment and system parameters (due to aging, damage, etc.). We illustrate the effectiveness of the RAG in constraint enforcement and safe RL using the RAG by considering their applications to a soft-landing problem of a mass-spring-damper system.
Deep Forest with Hashing Screening and Window Screening
Jul 25, 2022
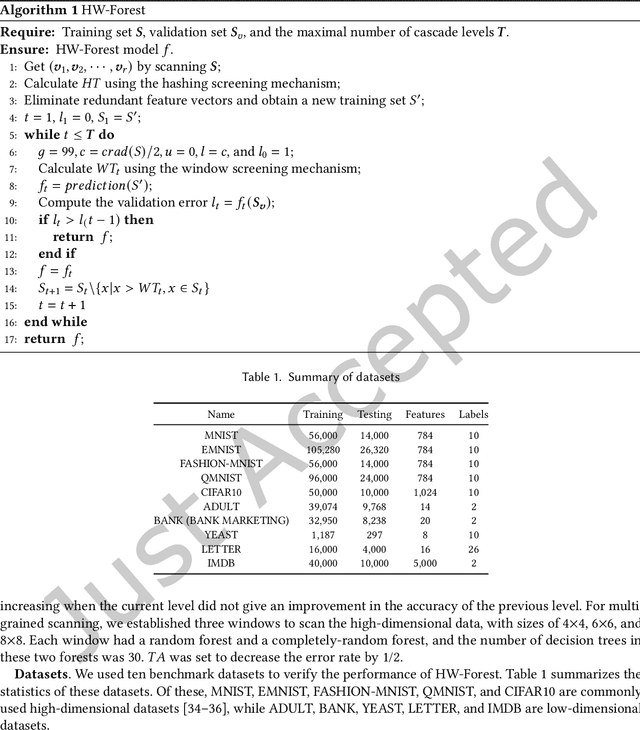
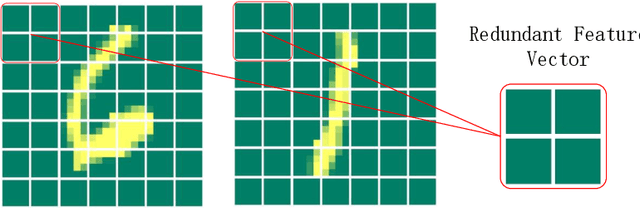
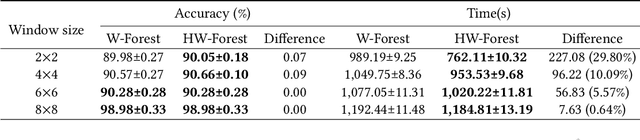
As a novel deep learning model, gcForest has been widely used in various applications. However, the current multi-grained scanning of gcForest produces many redundant feature vectors, and this increases the time cost of the model. To screen out redundant feature vectors, we introduce a hashing screening mechanism for multi-grained scanning and propose a model called HW-Forest which adopts two strategies, hashing screening and window screening. HW-Forest employs perceptual hashing algorithm to calculate the similarity between feature vectors in hashing screening strategy, which is used to remove the redundant feature vectors produced by multi-grained scanning and can significantly decrease the time cost and memory consumption. Furthermore, we adopt a self-adaptive instance screening strategy to improve the performance of our approach, called window screening, which can achieve higher accuracy without hyperparameter tuning on different datasets. Our experimental results show that HW-Forest has higher accuracy than other models, and the time cost is also reduced.
Learning Audio-Visual embedding for Wild Person Verification
Sep 09, 2022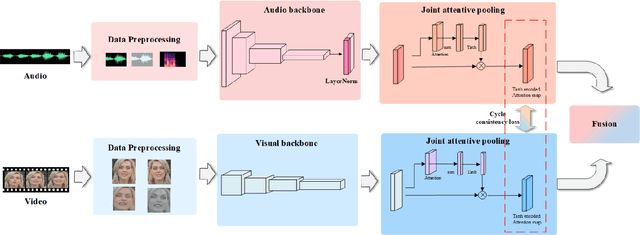
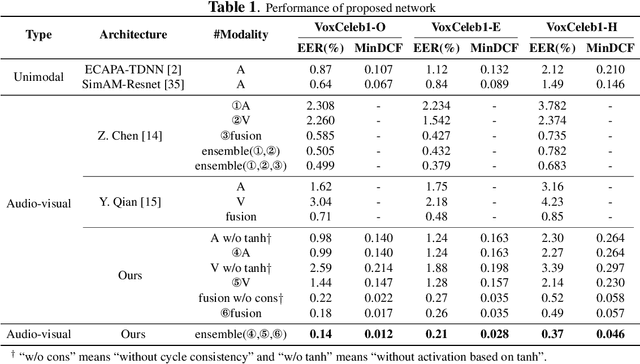
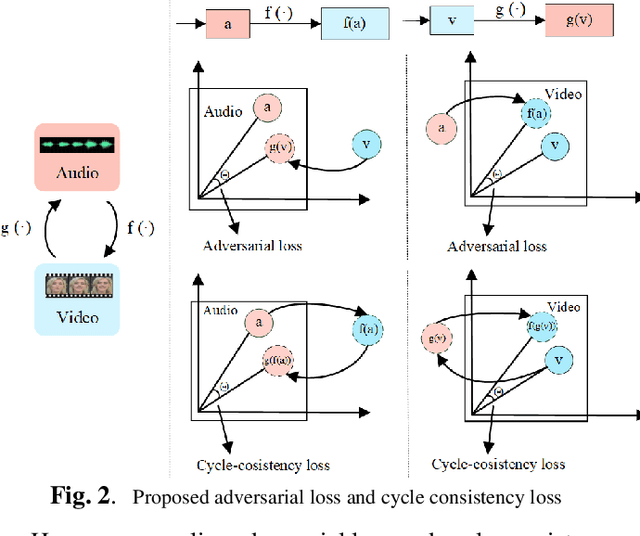
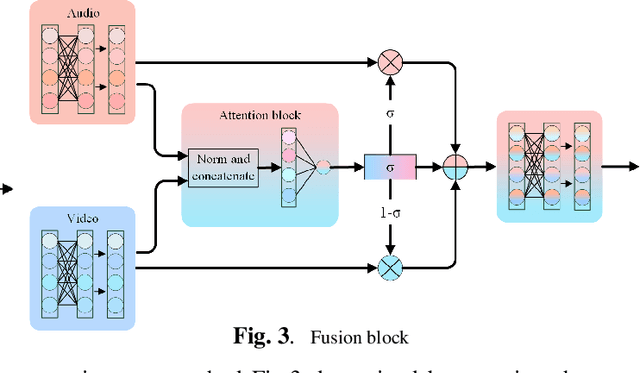
It has already been observed that audio-visual embedding can be extracted from these two modalities to gain robustness for person verification. However, the aggregator that used to generate a single utterance representation from each frame does not seem to be well explored. In this article, we proposed an audio-visual network that considers aggregator from a fusion perspective. We introduced improved attentive statistics pooling for the first time in face verification. Then we find that strong correlation exists between modalities during pooling, so joint attentive pooling is proposed which contains cycle consistency to learn the implicit inter-frame weight. Finally, fuse the modality with a gated attention mechanism. All the proposed models are trained on the VoxCeleb2 dev dataset and the best system obtains 0.18\%, 0.27\%, and 0.49\% EER on three official trail lists of VoxCeleb1 respectively, which is to our knowledge the best-published results for person verification. As an analysis, visualization maps are generated to explain how this system interact between modalities.
Time-Domain Analysis for Resonant Beam Charging and Communications With Delay-Divide Demodulation
Mar 02, 2022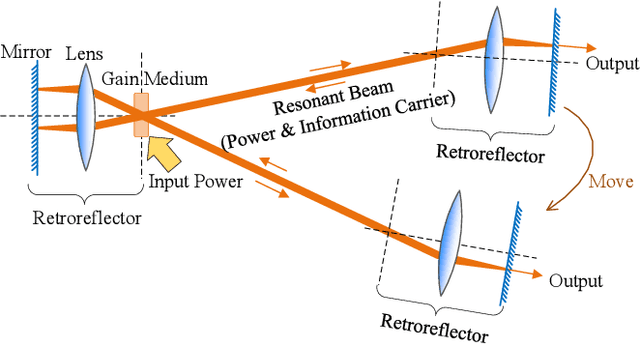
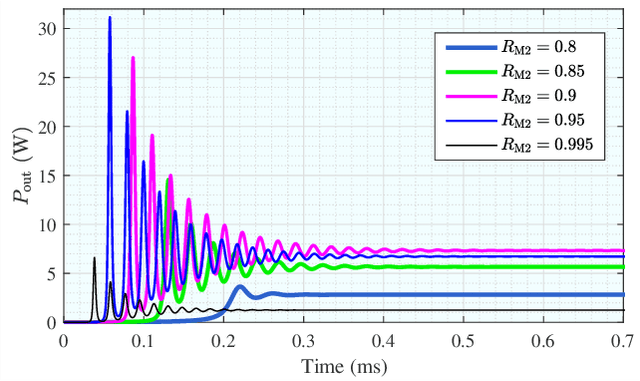
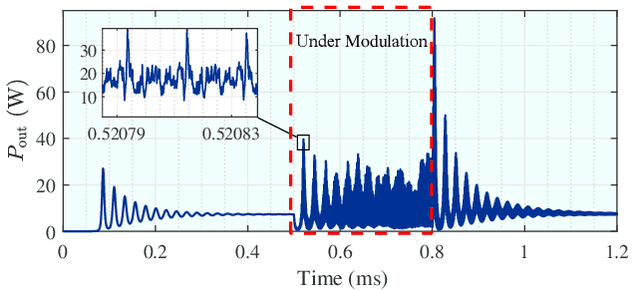
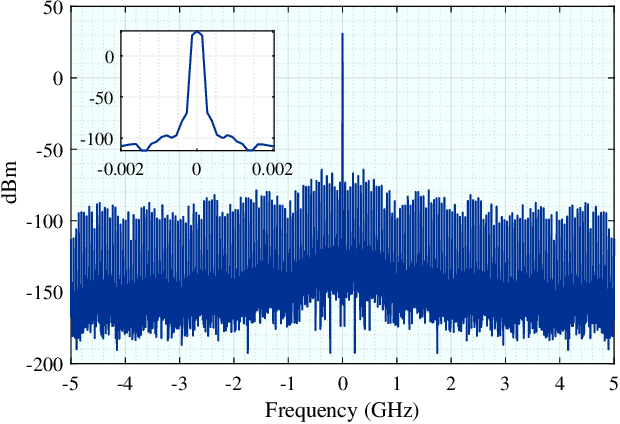
Laser has unique advantages such as abundant spectrum resources and low propagation divergence in wireless charging and wireless communications, compared with radio frequency. Resonant beams, as a kind of intra-cavity laser beams, have been proposed as the carrier of wireless charging and communication, as it has unique features including high power, intrinsic safety, and self-aligned mobility. However, this system has problems such as intra-cavity echo interference and power fluctuation. To study the time-domain behavior of the resonant beam system, we create a simulation algorithm by discretizing the laser rate equations which model the dynamics of the excited atom density in the gain medium and the photon density in the cavity. The simulation results are in good agreement with theoretical calculation. We also propose a delay-divide demodulation method to address the echo interference issue, and use the simulation algorithm to verify its feasibility. The results show that the resonant beam charging and communication system with the proposed demodulator is feasible and performs well. The analysis in this work also helps researchers to deeply understand the behavior of the resonant beam system.
Lightweight Spatial-Channel Adaptive Coordination of Multilevel Refinement Enhancement Network for Image Reconstruction
Sep 17, 2022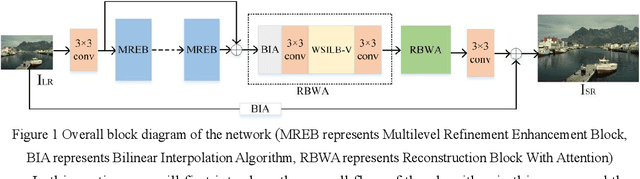
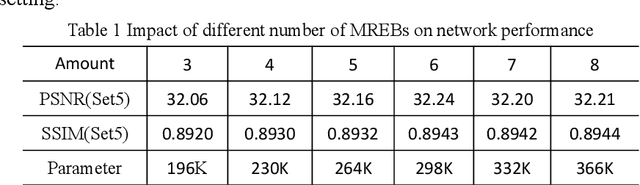
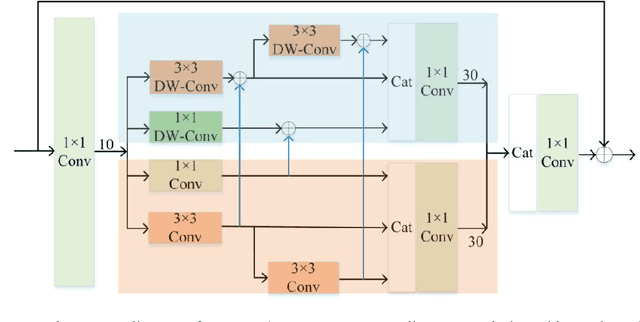
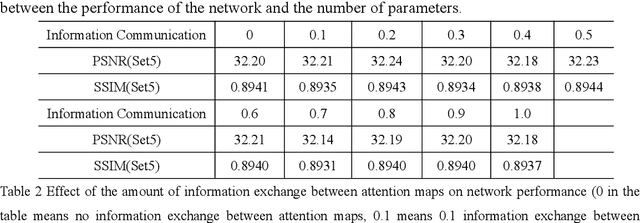
Benefiting from the vigorous development of deep learning, many CNN-based image super-resolution methods have emerged and achieved better results than traditional algorithms. However, it is difficult for most algorithms to adaptively adjust the spatial region and channel features at the same time, let alone the information exchange between them. In addition, the exchange of information between attention modules is even less visible to researchers. To solve these problems, we put forward a lightweight spatial-channel adaptive coordination of multilevel refinement enhancement networks(MREN). Specifically, we construct a space-channel adaptive coordination block, which enables the network to learn the spatial region and channel feature information of interest under different receptive fields. In addition, the information of the corresponding feature processing level between the spatial part and the channel part is exchanged with the help of jump connection to achieve the coordination between the two. We establish a communication bridge between attention modules through a simple linear combination operation, so as to more accurately and continuously guide the network to pay attention to the information of interest. Extensive experiments on several standard test sets have shown that our MREN achieves superior performance over other advanced algorithms with a very small number of parameters and very low computational complexity.
RetiFluidNet: A Self-Adaptive and Multi-Attention Deep Convolutional Network for Retinal OCT Fluid Segmentation
Sep 26, 2022
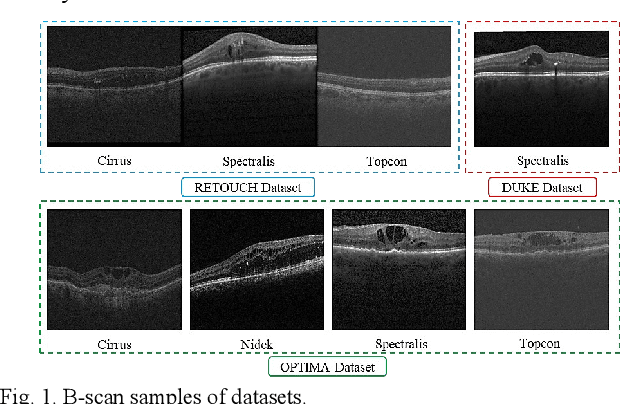
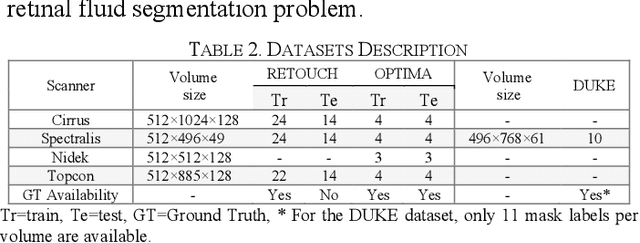
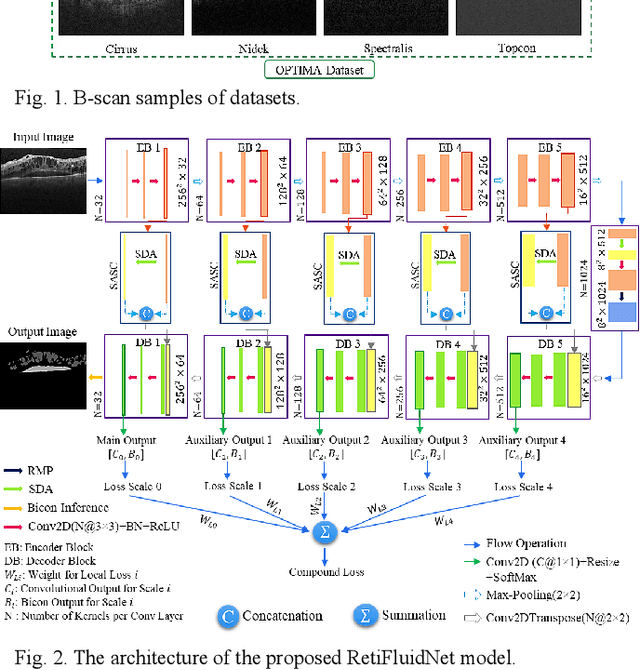
Optical coherence tomography (OCT) helps ophthalmologists assess macular edema, accumulation of fluids, and lesions at microscopic resolution. Quantification of retinal fluids is necessary for OCT-guided treatment management, which relies on a precise image segmentation step. As manual analysis of retinal fluids is a time-consuming, subjective, and error-prone task, there is increasing demand for fast and robust automatic solutions. In this study, a new convolutional neural architecture named RetiFluidNet is proposed for multi-class retinal fluid segmentation. The model benefits from hierarchical representation learning of textural, contextual, and edge features using a new self-adaptive dual-attention (SDA) module, multiple self-adaptive attention-based skip connections (SASC), and a novel multi-scale deep self supervision learning (DSL) scheme. The attention mechanism in the proposed SDA module enables the model to automatically extract deformation-aware representations at different levels, and the introduced SASC paths further consider spatial-channel interdependencies for concatenation of counterpart encoder and decoder units, which improve representational capability. RetiFluidNet is also optimized using a joint loss function comprising a weighted version of dice overlap and edge-preserved connectivity-based losses, where several hierarchical stages of multi-scale local losses are integrated into the optimization process. The model is validated based on three publicly available datasets: RETOUCH, OPTIMA, and DUKE, with comparisons against several baselines. Experimental results on the datasets prove the effectiveness of the proposed model in retinal OCT fluid segmentation and reveal that the suggested method is more effective than existing state-of-the-art fluid segmentation algorithms in adapting to retinal OCT scans recorded by various image scanning instruments.
Virtual grating approach for Monte Carlo simulations of edge illumination-based x-ray phase contrast imaging
Aug 03, 2022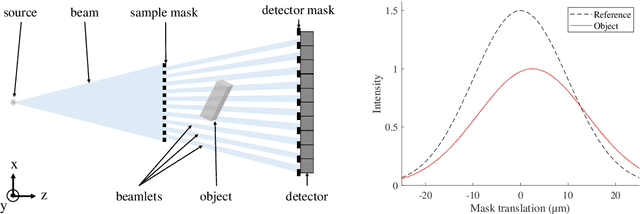
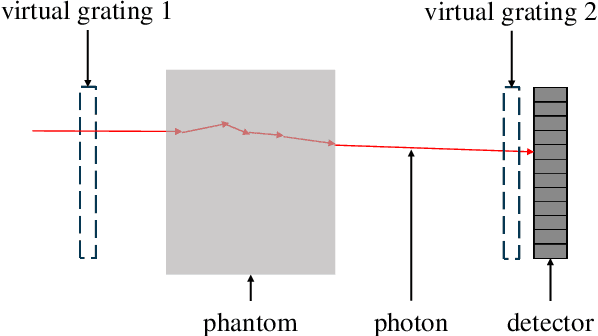
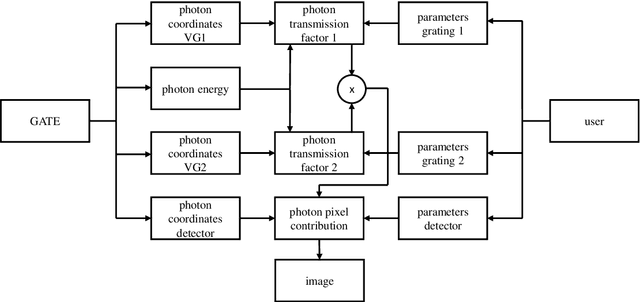
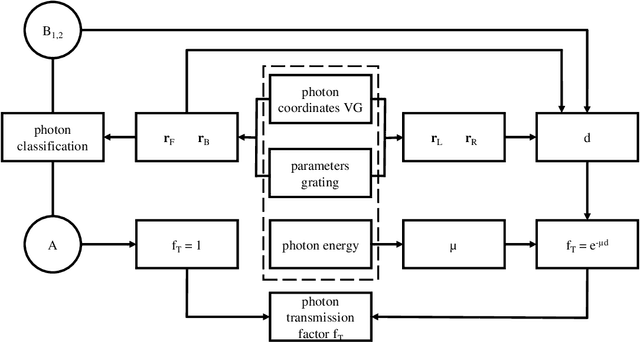
The design of new x-ray phase contrast imaging setups often relies on Monte Carlo simulations for prospective parameter studies. Monte Carlo simulations are known to be accurate but time consuming, leading to long simulation times, especially when many parameter variations are required. This is certainly the case for imaging methods relying on absorbing masks or gratings, with various tunable properties, such as pitch, aperture size, and thickness. In this work, we present the virtual grating approach to overcome this limitation. By replacing the gratings in the simulation with virtual gratings, the parameters of the gratings can be changed after the simulation, thereby significantly reducing the overall simulation time. The method is validated by comparison to explicit grating simulations, followed by representative demonstration cases.
Real-Time Facial Expression Recognition using Facial Landmarks and Neural Networks
Jan 31, 2022


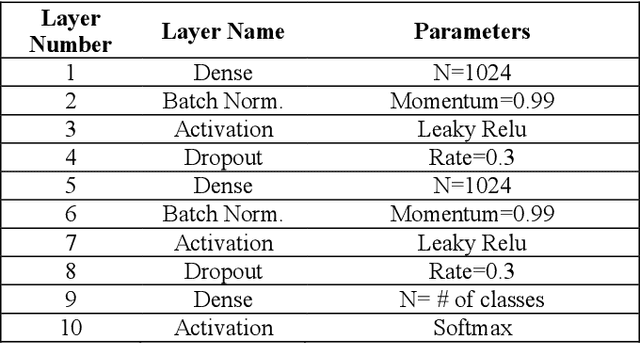
This paper presents a lightweight algorithm for feature extraction, classification of seven different emotions, and facial expression recognition in a real-time manner based on static images of the human face. In this regard, a Multi-Layer Perceptron (MLP) neural network is trained based on the foregoing algorithm. In order to classify human faces, first, some pre-processing is applied to the input image, which can localize and cut out faces from it. In the next step, a facial landmark detection library is used, which can detect the landmarks of each face. Then, the human face is split into upper and lower faces, which enables the extraction of the desired features from each part. In the proposed model, both geometric and texture-based feature types are taken into account. After the feature extraction phase, a normalized vector of features is created. A 3-layer MLP is trained using these feature vectors, leading to 96% accuracy on the test set.