 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vehicle Trajectory Tracking Through Magnetic Sensors
Sep 09, 2022
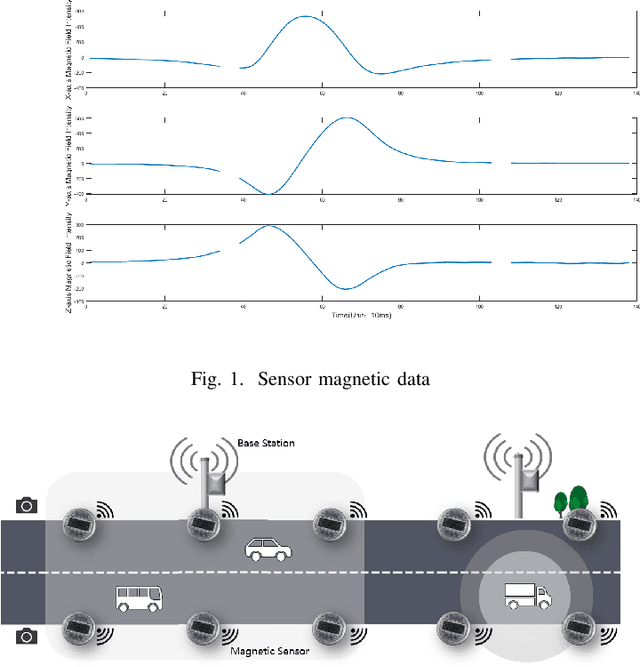
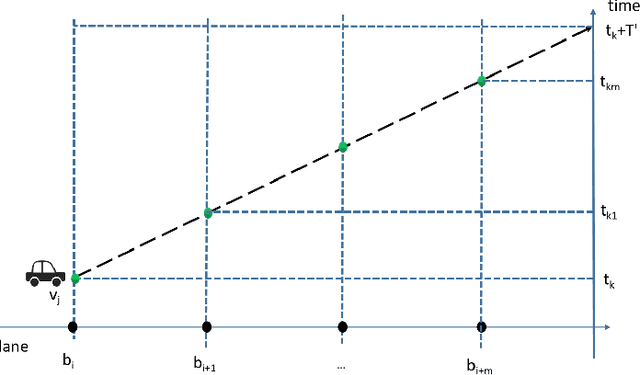
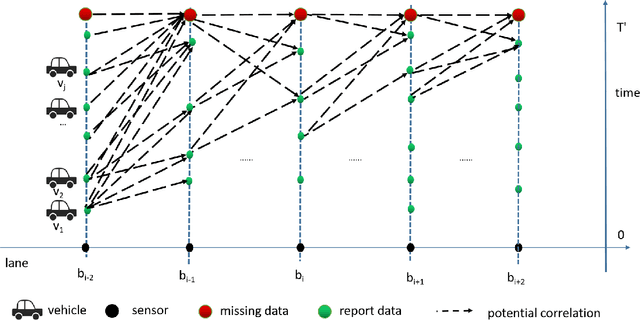
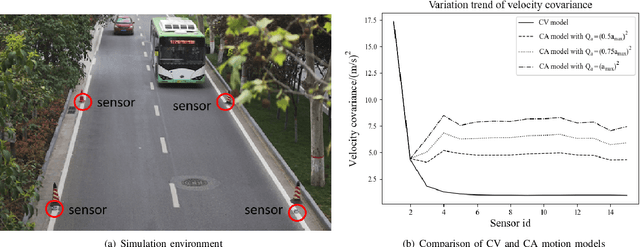
Traffic surveillance is an important issue in Intelligent Transportation Systems(ITS). In this paper, we propose a novel surveillance system to detect and track vehicles using ubiquitously deployed magnetic sensors. That is, multiple magnetic sensors, mounted roadside and along lane boundary lines, are used to track various vehicles. Real-time vehicle detection data are reported from magnetic sensors, collected into data center via base stations, and processed to depict vehicle trajectories including vehicle position, timestamp, speed and type. We first define a vehicle trajectory tracking problem. We then propose a graph-based data association algorithm to track each detected vehicle, and design a related online algorithm framework respectively. We finally validate the performance via both experimental simulation and real-world road test. The experimental results demonstrate that the proposed solution provides a cost-effective solution to capture the driving status of vehicles and on that basis form various traffic safety and efficiency applications.
A Multi-Task Learning Model for Super Resolution of Wireless Channel Characteristics
Sep 09, 2022Channel modeling has always been the core part in communication system design and development, especially in 5G and 6G era. Traditional approaches like stochastic channel modeling and ray-tracing (RT) based channel modeling depend heavily on measurement data or simulation, which are usually expensive and time consuming. In this paper, we propose a novel super resolution (SR) model for generating channel characteristics data. The model is based on multi-task learning (MTL) convolutional neural networks (CNN) with residual connection. Experiments demonstrate that the proposed SR model could achieve excellent performances in mean absolute error and standard deviation of error. Advantages of the proposed model are demonstrated in comparisons with other state-of-the-art deep learning models. Ablation study also proved the necessity of multi-task learning and techniques in model design. The contribution in this paper could be helpful in channel modeling, network optimization, positioning and other wireless channel characteristics related work by largely reducing workload of simulation or measurement.
LL-GNN: Low Latency Graph Neural Networks on FPGAs for Particle Detectors
Sep 28, 2022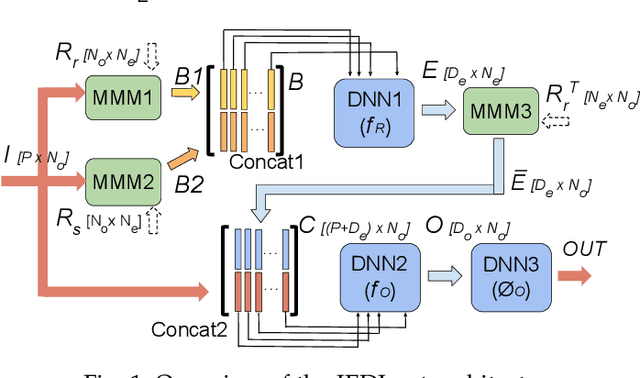
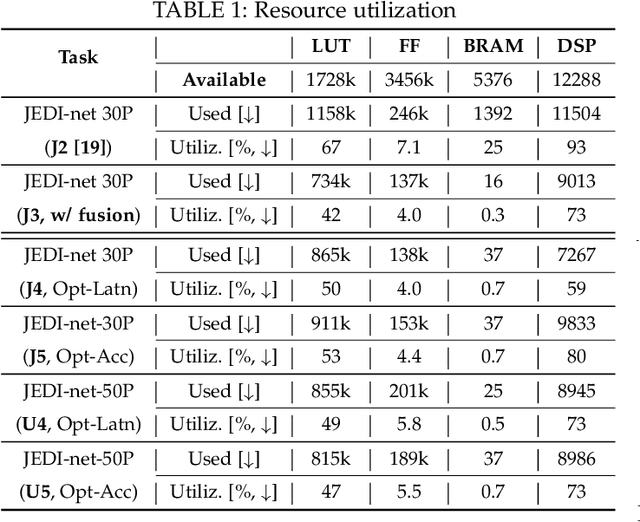
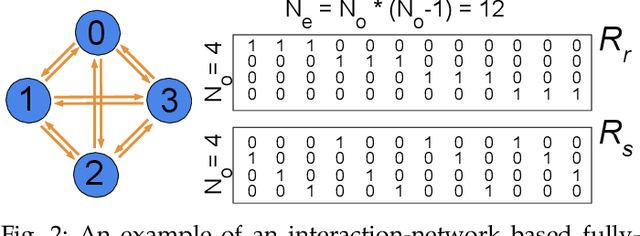
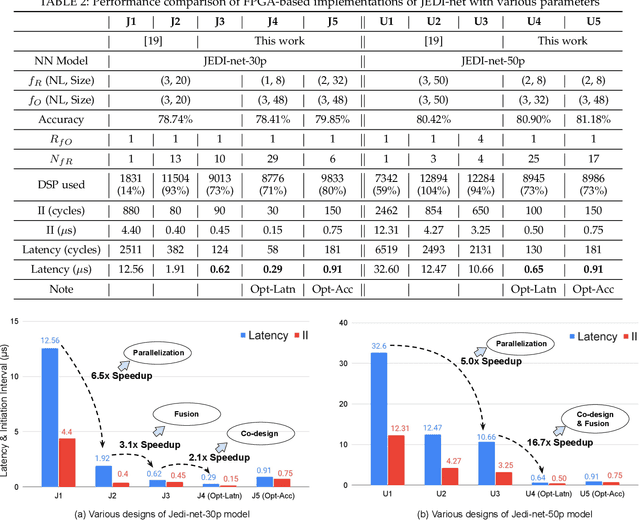
This work proposes a novel reconfigurable architecture for low latency Graph Neural Network (GNN) design specifically for particle detectors. Accelerating GNNs for particle detectors is challenging since it requires sub-microsecond latency to deploy the networks for online event selection in the Level-1 triggers at the CERN Large Hadron Collider experiments. This paper proposes a custom code transformation with strength reduction for the matrix multiplication operations in the interaction-network based GNNs with fully connected graphs, which avoids the costly multiplication. It exploits sparsity patterns as well as binary adjacency matrices, and avoids irregular memory access, leading to a reduction in latency and improvement in hardware efficiency. In addition, we introduce an outer-product based matrix multiplication approach which is enhanced by the strength reduction for low latency design. Also, a fusion step is introduced to further reduce the design latency. Furthermore, an GNN-specific algorithm-hardware co-design approach is presented which not only finds a design with a much better latency but also finds a high accuracy design under a given latency constraint. Finally, a customizable template for this low latency GNN hardware architecture has been designed and open-sourced, which enables the generation of low-latency FPGA designs with efficient resource utilization using a high-level synthesis tool. Evaluation results show that our FPGA implementation is up to 24 times faster and consumes up to 45 times less power than a GPU implementation. Compared to our previous FPGA implementations, this work achieves 6.51 to 16.7 times lower latency. Moreover, the latency of our FPGA design is sufficiently low to enable deployment of GNNs in a sub-microsecond, real-time collider trigger system, enabling it to benefit from improved accuracy.
Robust Action Governor for Uncertain Piecewise Affine Systems with Non-convex Constraints and Safe Reinforcement Learning
Jul 17, 2022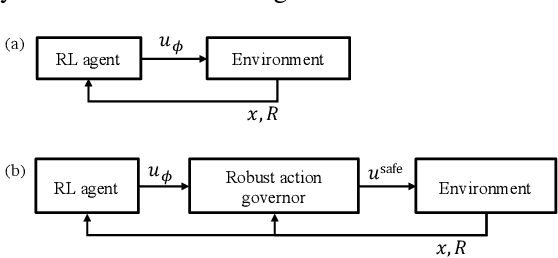
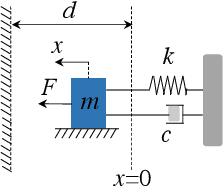
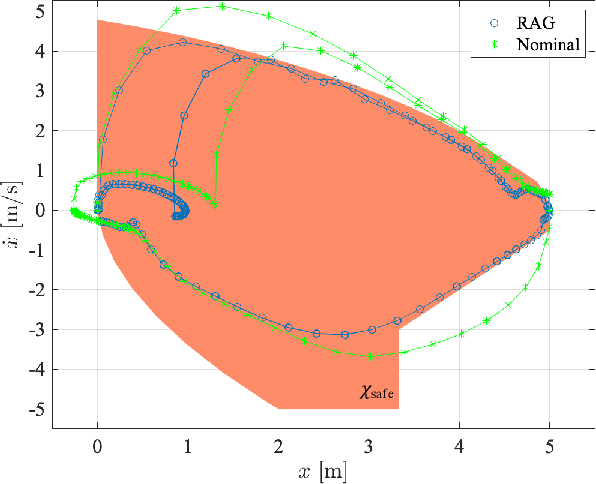
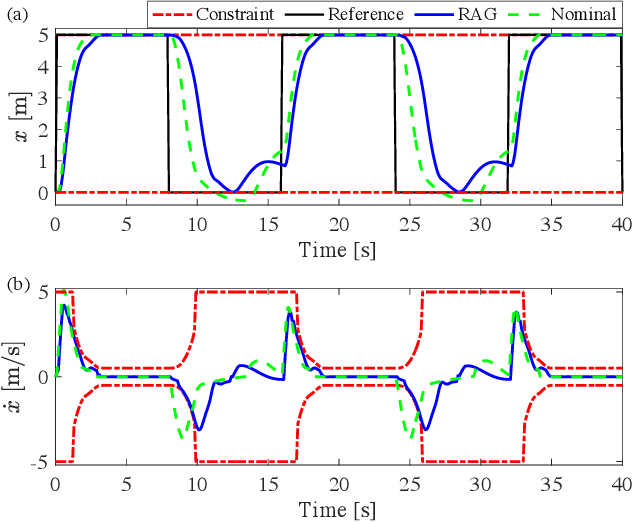
The action governor is an add-on scheme to a nominal control loop that monitors and adjusts the control actions to enforce safety specifications expressed as pointwise-in-time state and control constraints. In this paper, we introduce the Robust Action Governor (RAG) for systems the dynamics of which can be represented using discrete-time Piecewise Affine (PWA) models with both parametric and additive uncertainties and subject to non-convex constraints. We develop the theoretical properties and computational approaches for the RAG. After that, we introduce the use of the RAG for realizing safe Reinforcement Learning (RL), i.e., ensuring all-time constraint satisfaction during online RL exploration-and-exploitation process. This development enables safe real-time evolution of the control policy and adaptation to changes in the operating environment and system parameters (due to aging, damage, etc.). We illustrate the effectiveness of the RAG in constraint enforcement and safe RL using the RAG by considering their applications to a soft-landing problem of a mass-spring-damper system.
MAGPIE: Machine Automated General Performance Improvement via Evolution of Software
Aug 04, 2022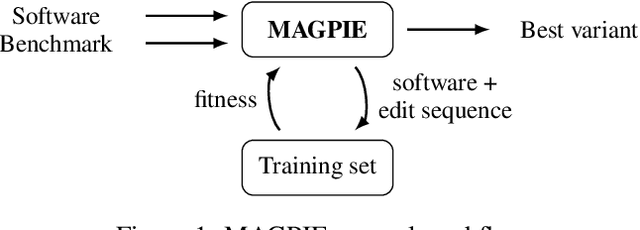
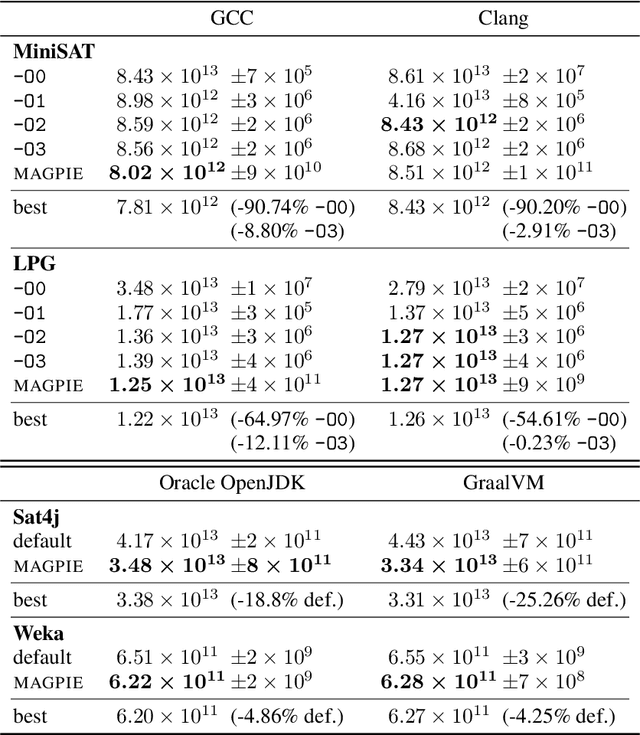
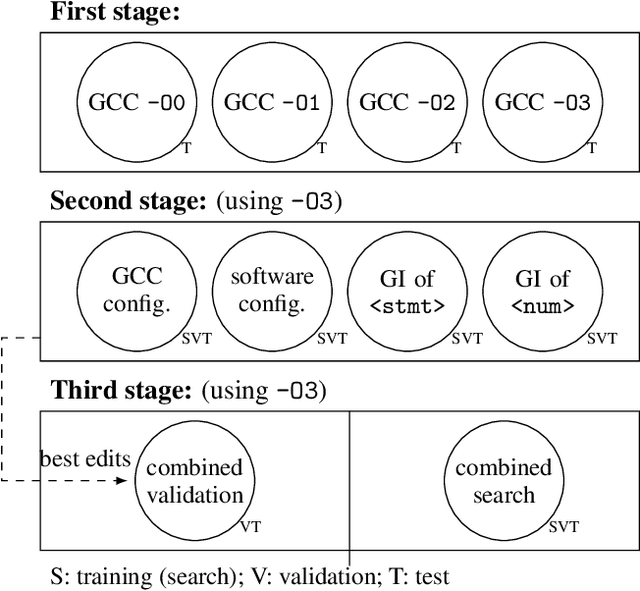
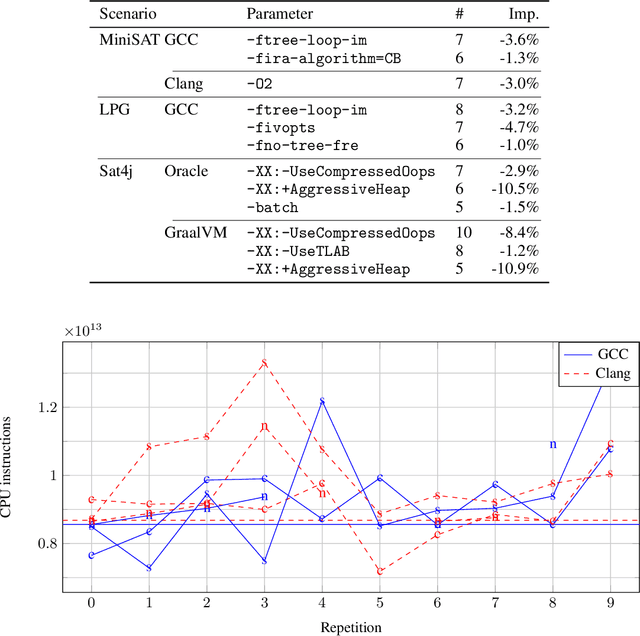
Performance is one of the most important qualities of software. Several techniques have thus been proposed to improve it, such as program transformations, optimisation of software parameters, or compiler flags. Many automated software improvement approaches use similar search strategies to explore the space of possible improvements, yet available tooling only focuses on one approach at a time. This makes comparisons and exploration of interactions of the various types of improvement impractical. We propose MAGPIE, a unified software improvement framework. It provides a common edit sequence based representation that isolates the search process from the specific improvement technique, enabling a much simplified synergistic workflow. We provide a case study using a basic local search to compare compiler optimisation, algorithm configuration, and genetic improvement. We chose running time as our efficiency measure and evaluated our approach on four real-world software, written in C, C++, and Java. Our results show that, used independently, all techniques find significant running time improvements: up to 25% for compiler optimisation, 97% for algorithm configuration, and 61% for evolving source code using genetic improvement. We also show that up to 10% further increase in performance can be obtained with partial combinations of the variants found by the different techniques. Furthermore, the common representation also enables simultaneous exploration of all techniques, providing a competitive alternative to using each technique individually.
Review of data types and model dimensionality for cardiac DTI SMS-related artefact removal
Sep 20, 2022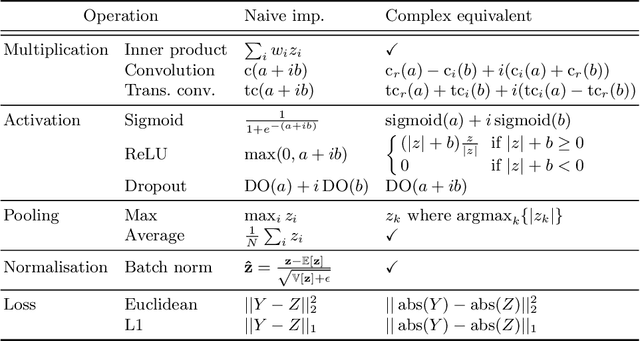
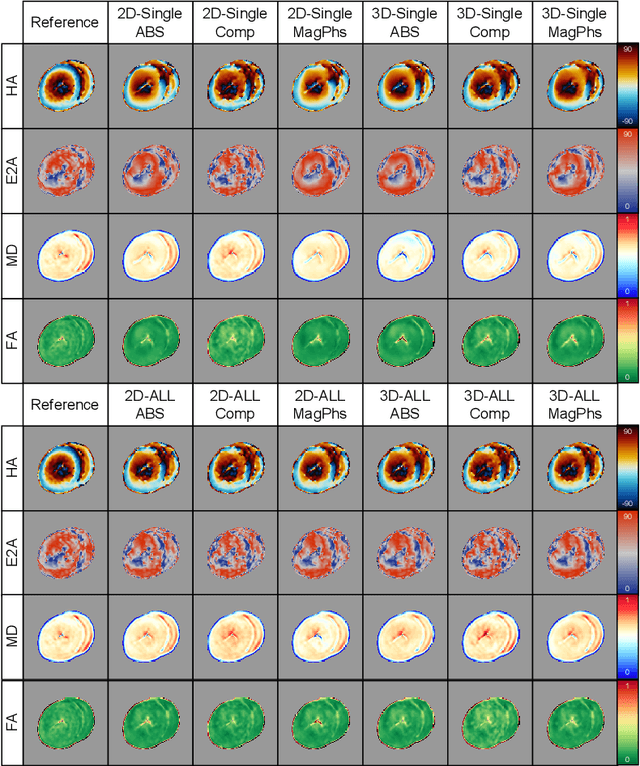
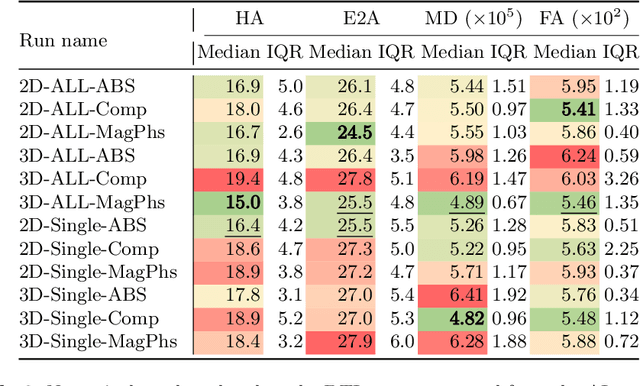
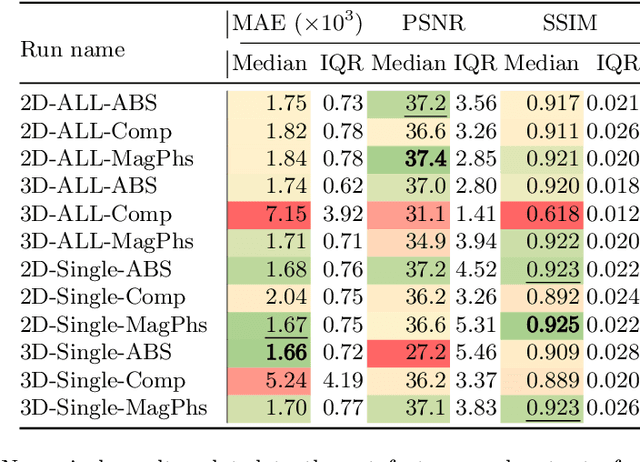
As diffusion tensor imaging (DTI) gains popularity in cardiac imaging due to its unique ability to non-invasively assess the cardiac microstructure, deep learning-based Artificial Intelligence is becoming a crucial tool in mitigating some of its drawbacks, such as the long scan times. As it often happens in fast-paced research environments, a lot of emphasis has been put on showing the capability of deep learning while often not enough time has been spent investigating what input and architectural properties would benefit cardiac DTI acceleration the most. In this work, we compare the effect of several input types (magnitude images vs complex images), multiple dimensionalities (2D vs 3D operations), and multiple input types (single slice vs multi-slice) on the performance of a model trained to remove artefacts caused by a simultaneous multi-slice (SMS) acquisition. Despite our initial intuition, our experiments show that, for a fixed number of parameters, simpler 2D real-valued models outperform their more advanced 3D or complex counterparts. The best performance is although obtained by a real-valued model trained using both the magnitude and phase components of the acquired data. We believe this behaviour to be due to real-valued models making better use of the lower number of parameters, and to 3D models not being able to exploit the spatial information because of the low SMS acceleration factor used in our experiments.
uChecker: Masked Pretrained Language Models as Unsupervised Chinese Spelling Checkers
Sep 15, 2022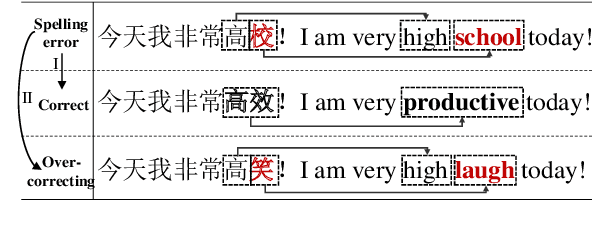


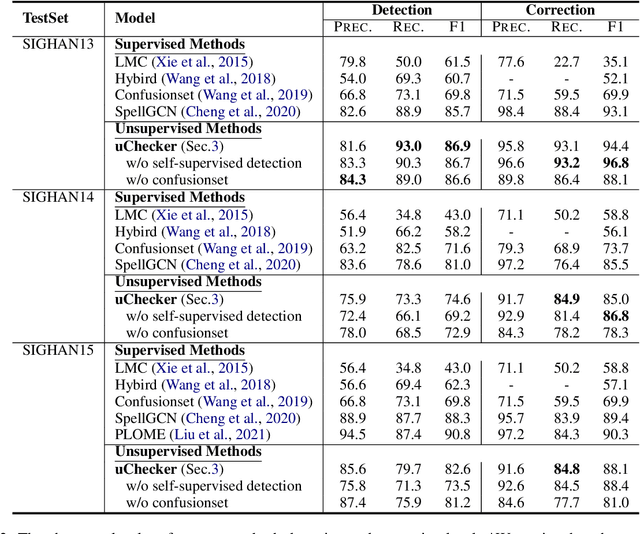
The task of Chinese Spelling Check (CSC) is aiming to detect and correct spelling errors that can be found in the text. While manually annotating a high-quality dataset is expensive and time-consuming, thus the scale of the training dataset is usually very small (e.g., SIGHAN15 only contains 2339 samples for training), therefore supervised-learning based models usually suffer the data sparsity limitation and over-fitting issue, especially in the era of big language models. In this paper, we are dedicated to investigating the \textbf{unsupervised} paradigm to address the CSC problem and we propose a framework named \textbf{uChecker} to conduct unsupervised spelling error detection and correction. Masked pretrained language models such as BERT are introduced as the backbone model considering their powerful language diagnosis capability. Benefiting from the various and flexible MASKing operations, we propose a Confusionset-guided masking strategy to fine-train the masked language model to further improve the performance of unsupervised detection and correction. Experimental results on standard datasets demonstrate the effectiveness of our proposed model uChecker in terms of character-level and sentence-level Accuracy, Precision, Recall, and F1-Measure on tasks of spelling error detection and correction respectively.
Deep Forest with Hashing Screening and Window Screening
Jul 25, 2022
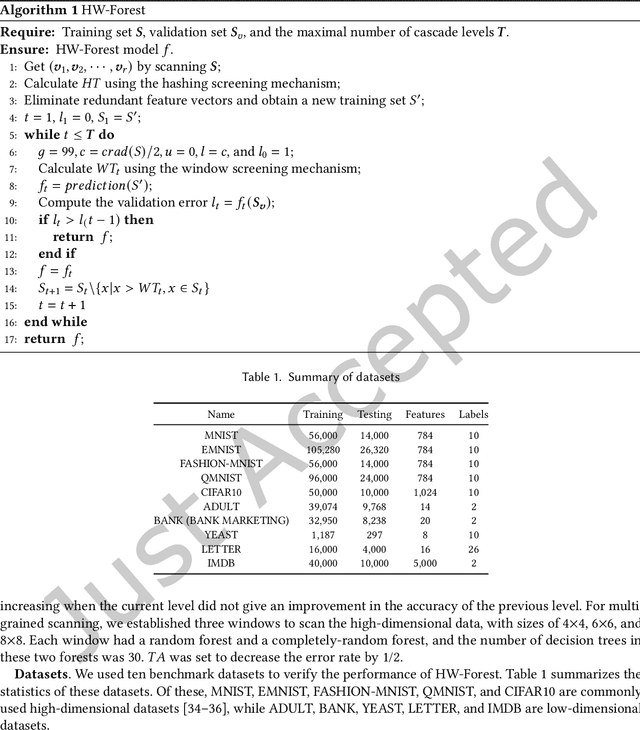
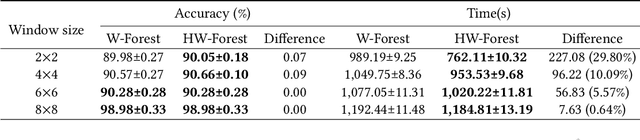
As a novel deep learning model, gcForest has been widely used in various applications. However, the current multi-grained scanning of gcForest produces many redundant feature vectors, and this increases the time cost of the model. To screen out redundant feature vectors, we introduce a hashing screening mechanism for multi-grained scanning and propose a model called HW-Forest which adopts two strategies, hashing screening and window screening. HW-Forest employs perceptual hashing algorithm to calculate the similarity between feature vectors in hashing screening strategy, which is used to remove the redundant feature vectors produced by multi-grained scanning and can significantly decrease the time cost and memory consumption. Furthermore, we adopt a self-adaptive instance screening strategy to improve the performance of our approach, called window screening, which can achieve higher accuracy without hyperparameter tuning on different datasets. Our experimental results show that HW-Forest has higher accuracy than other models, and the time cost is also reduced.
A Combined Model for Noise Reduction of Lung Sound Signals Based on Empirical Mode Decomposition and Artificial Neural Network
Sep 20, 2022
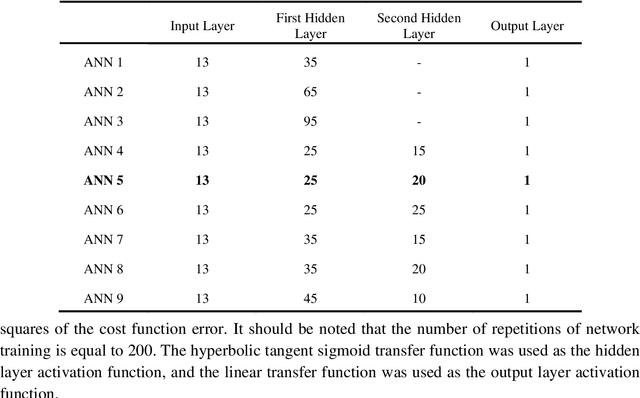
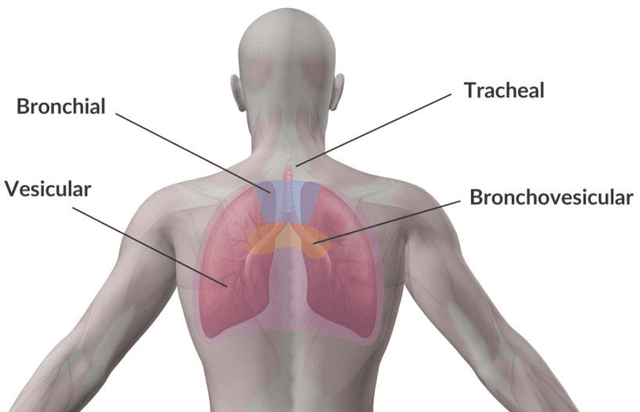
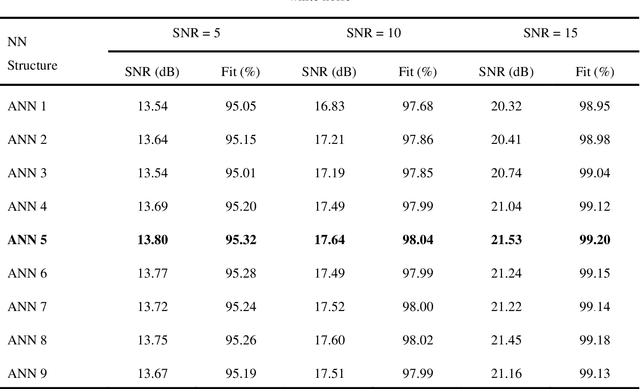
Computer analysis of Lung Sound (LS) signals has been proposed in recent years as a tool to analyze the lungs' status but there have always been main challenges, including the contamination of LS with environmental noises, which come from different sources of unlike intensities. One of the common methods in noise reduction of LS signals is based on thresholding on Discrete Wavelet Transform (DWT) coefficients or Empirical Mode Decomposition (EMD) of the signal, however, in these methods, it is necessary to calculate the SNR value to determine the appropriate threshold for noise removal. To solve this problem, a combined model based on EMD and Artificial Neural Network (ANN) trained with different SNRs (0, 5, 10, 15, and 20dB) is proposed in this research. The model can denoise white and pink noises in the range of -2 to 20dB without thresholding or even estimating SNR, and at the same time, keep the main content of the LS signal well. The proposed method is also compared with the EMD-custom method, and the results obtained from the SNR, and fit criteria indicate the absolute superiority of the proposed method. For example, at SNR = 0dB, the combined method can improve the SNR by 9.41 and 8.23dB for white and pink noises, respectively, while the corresponding values are respectively 5.89 and 4.31dB for the EMD-Custom method.
Learning sparse auto-encoders for green AI image coding
Sep 09, 2022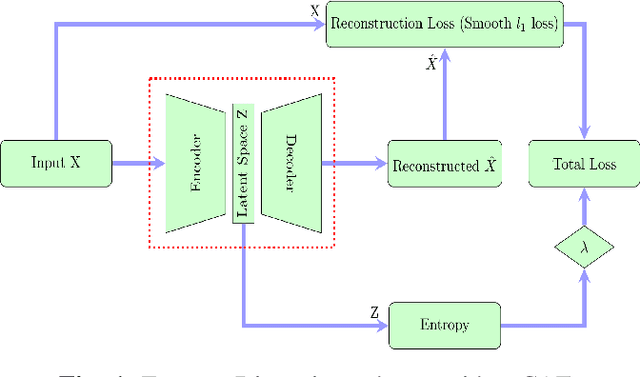
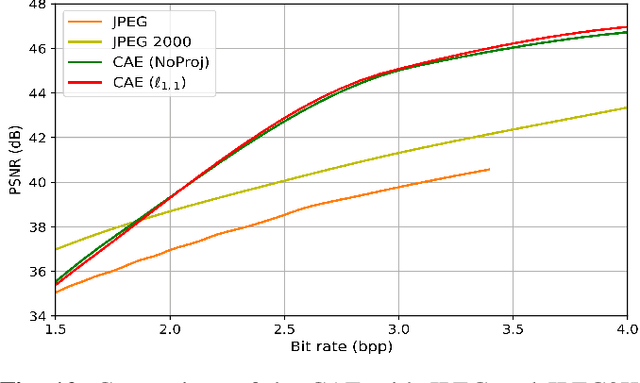
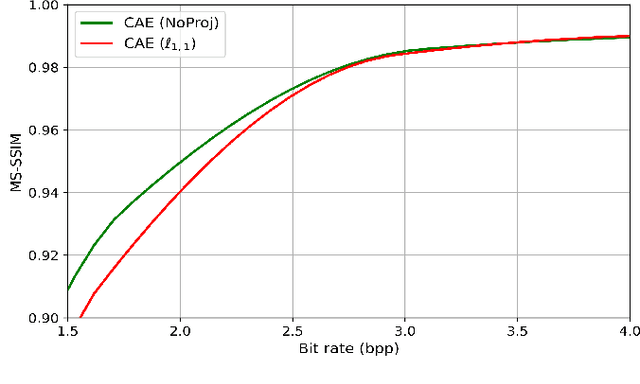

Recently, convolutional auto-encoders (CAE) were introduced for image coding. They achieved performance improvements over the state-of-the-art JPEG2000 method. However, these performances were obtained using massive CAEs featuring a large number of parameters and whose training required heavy computational power.\\ In this paper, we address the problem of lossy image compression using a CAE with a small memory footprint and low computational power usage. In order to overcome the computational cost issue, the majority of the literature uses Lagrangian proximal regularization methods, which are time consuming themselves.\\ In this work, we propose a constrained approach and a new structured sparse learning method. We design an algorithm and test it on three constraints: the classical $\ell_1$ constraint, the $\ell_{1,\infty}$ and the new $\ell_{1,1}$ constraint. Experimental results show that the $\ell_{1,1}$ constraint provides the best structured sparsity, resulting in a high reduction of memory and computational cost, with similar rate-distortion performance as with dense networks.