 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Unified Perspective on Natural Gradient Variational Inference with Gaussian Mixture Models
Sep 23, 2022

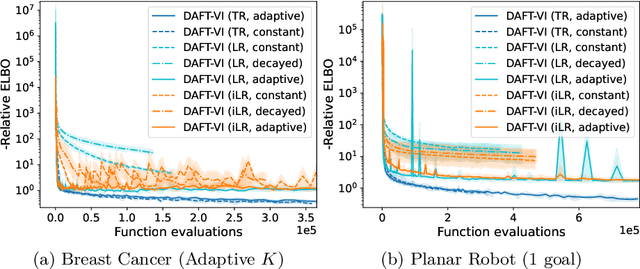
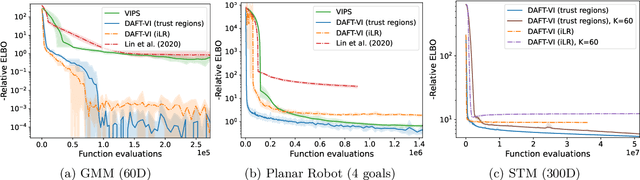
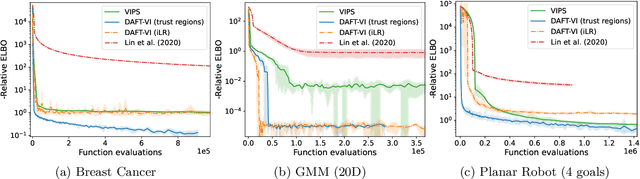
Variational inference with Gaussian mixture models (GMMs) enables learning of highly-tractable yet multi-modal approximations of intractable target distributions. GMMs are particular relevant for problem settings with up to a few hundred dimensions, for example in robotics, for modelling distributions over trajectories or joint distributions. This work focuses on two very effective methods for GMM-based variational inference that both employ independent natural gradient updates for the individual components and the categorical distribution of the weights. We show for the first time, that their derived updates are equivalent, although their practical implementations and theoretical guarantees differ. We identify several design choices that distinguish both approaches, namely with respect to sample selection, natural gradient estimation, stepsize adaptation, and whether trust regions are enforced or the number of components adapted. We perform extensive ablations on these design choices and show that they strongly affect the efficiency of the optimization and the variability of the learned distribution. Based on our insights, we propose a novel instantiation of our generalized framework, that combines first-order natural gradient estimates with trust-regions and component adaption, and significantly outperforms both previous methods in all our experiments.
A Deep Reinforcement Learning-Based Charging Scheduling Approach with Augmented Lagrangian for Electric Vehicle
Sep 20, 2022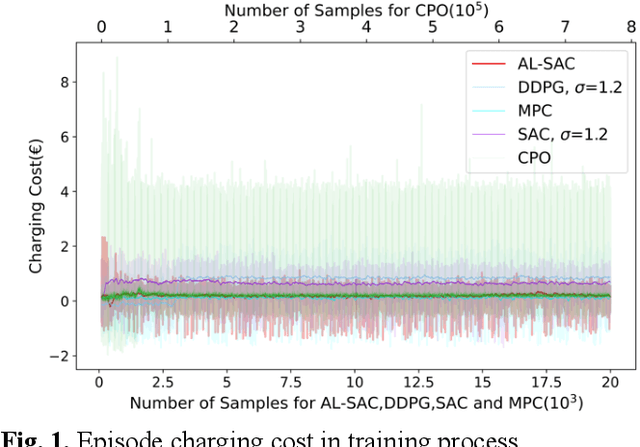
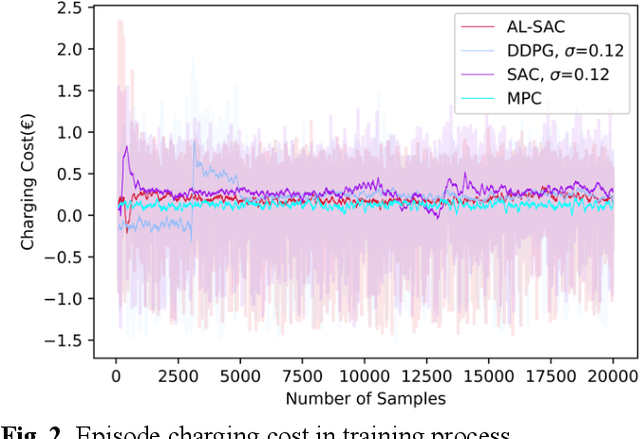
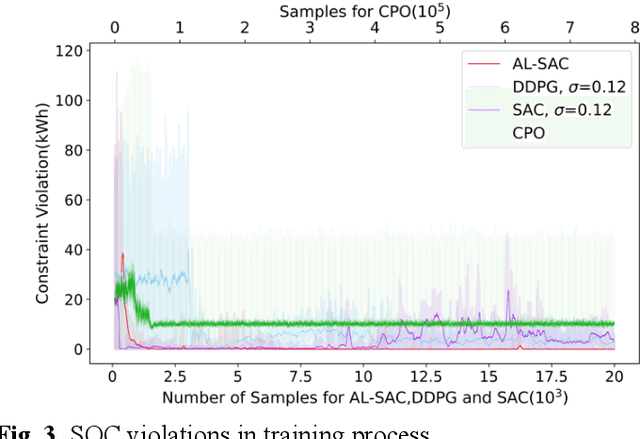
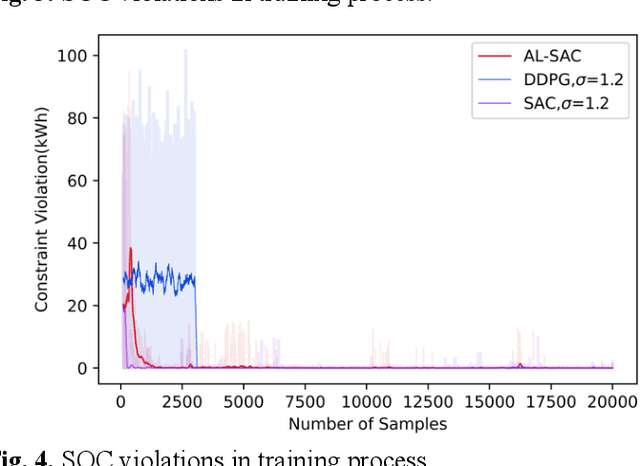
This paper addresses the problem of optimizing charging/discharging schedules of electric vehicles (EVs) when participate in demand response (DR). As there exist uncertainties in EVs' remaining energy, arrival and departure time, and future electricity prices, it is quite difficult to make charging decisions to minimize charging cost while guarantee that the EV's battery state-of-the-charge (SOC) is within certain range. To handle with this dilemma, this paper formulates the EV charging scheduling problem as a constrained Markov decision process (CMDP). By synergistically combining the augmented Lagrangian method and soft actor critic algorithm, a novel safe off-policy reinforcement learning (RL) approach is proposed in this paper to solve the CMDP. The actor network is updated in a policy gradient manner with the Lagrangian value function. A double-critics network is adopted to synchronously estimate the action-value function to avoid overestimation bias. The proposed algorithm does not require strong convexity guarantee of examined problems and is sample efficient. Comprehensive numerical experiments with real-world electricity price demonstrate that our proposed algorithm can achieve high solution optimality and constraints compliance.
Automatic Rule Generation for Time Expression Normalization
Aug 31, 2021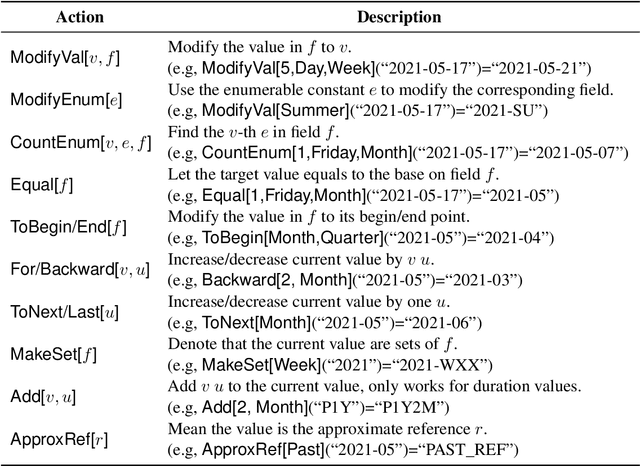
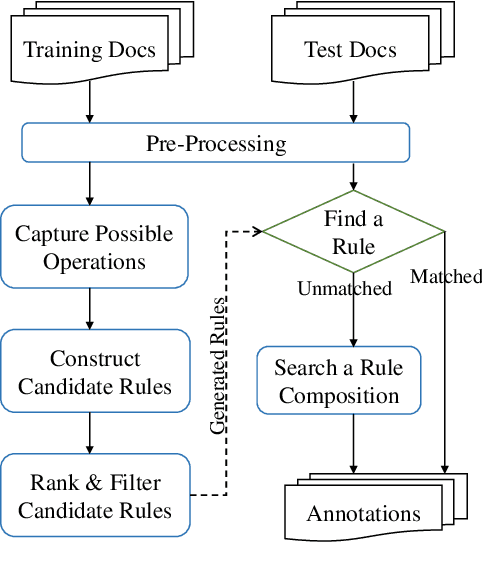

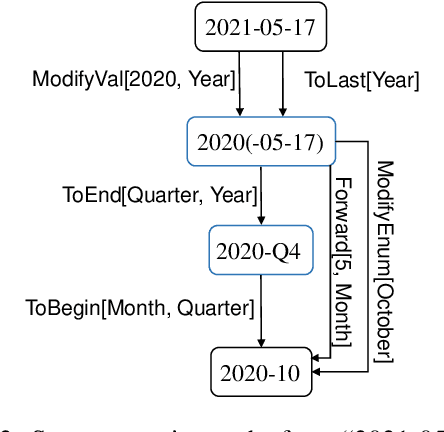
The understanding of time expressions includes two sub-tasks: recognition and normalization. In recent years, significant progress has been made in the recognition of time expressions while research on normalization has lagged behind. Existing SOTA normalization methods highly rely on rules or grammars designed by experts, which limits their performance on emerging corpora, such as social media texts. In this paper, we model time expression normalization as a sequence of operations to construct the normalized temporal value, and we present a novel method called ARTime, which can automatically generate normalization rules from training data without expert interventions. Specifically, ARTime automatically captures possible operation sequences from annotated data and generates normalization rules on time expressions with common surface forms. The experimental results show that ARTime can significantly surpass SOTA methods on the Tweets benchmark, and achieves competitive results with existing expert-engineered rule methods on the TempEval-3 benchmark.
Estimation of Consistent Time Delays in Subsample via Auxiliary-Function-Based Iterative Updates
Mar 23, 2022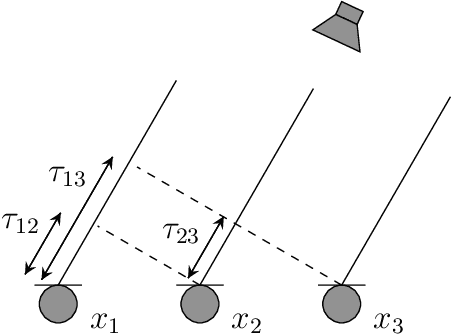
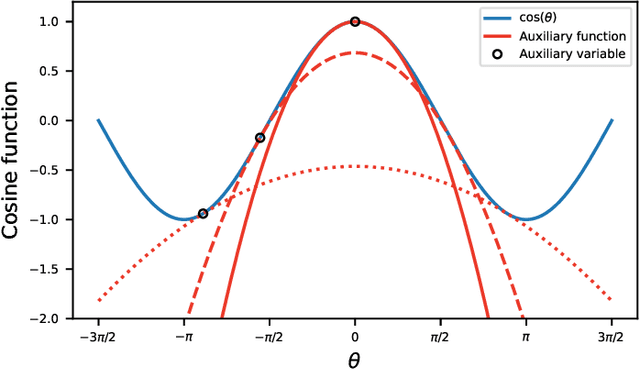
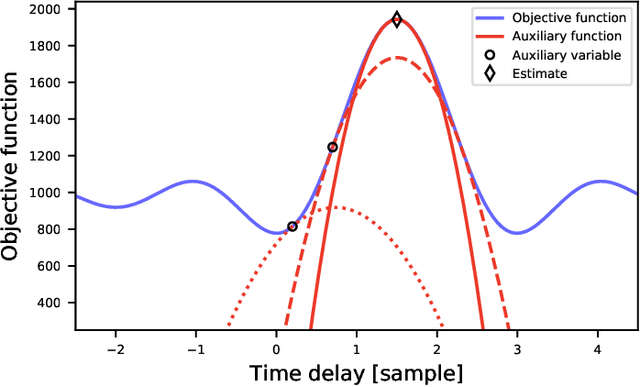
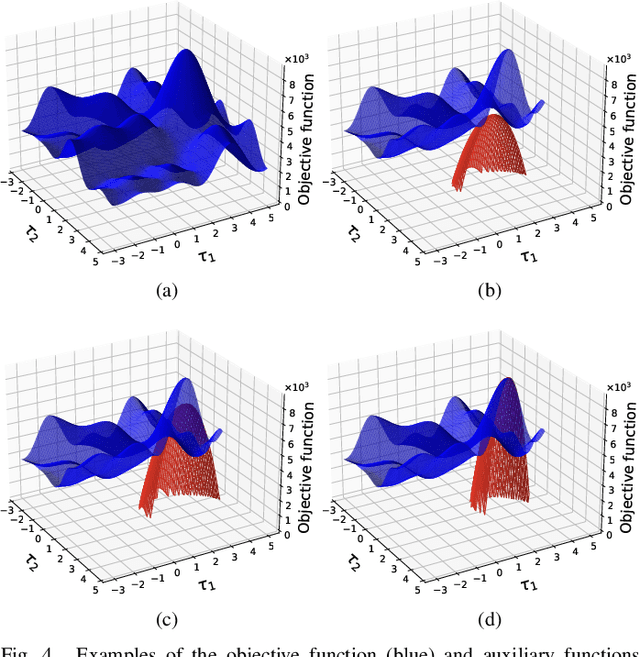
In this paper, we propose a new algorithm for the estimation of multiple time delays (TDs). Since a TD is a fundamental spatial cue for sensor array signal processing techniques, many methods for estimating it have been studied. Most of them, including generalized cross correlation (CC)-based methods, focus on how to estimate a TD between two sensors. These methods can then be easily adapted for multiple TDs by applying them to every pair of a reference sensor and another one. However, these pairwise methods can use only the partial information obtained by the selected sensors, resulting in inconsistent TD estimates and limited estimation accuracy. In contrast, we propose joint optimization of entire TD parameters, where spatial information obtained from all sensors is taken into account. We also introduce a consistent constraint regarding TD parameters to the observation model. We then consider a multidimensional CC (MCC) as the objective function, which is derived on the basis of maximum likelihood estimation. To maximize the MCC, which is a nonconvex function, we derive the auxiliary function for the MCC and design efficient update rules. We additionally estimate the amplitudes of the transfer functions for supporting the TD estimation, where we maximize the Rayleigh quotient under the non-negative constraint. We experimentally analyze essential features of the proposed method and evaluate its effectiveness in TD estimation. Code will be available at https://github.com/onolab-tmu/AuxTDE.
Time-independent Generalization Bounds for SGLD in Non-convex Settings
Nov 25, 2021
We establish generalization error bounds for stochastic gradient Langevin dynamics (SGLD) with constant learning rate under the assumptions of dissipativity and smoothness, a setting that has received increased attention in the sampling/optimization literature. Unlike existing bounds for SGLD in non-convex settings, ours are time-independent and decay to zero as the sample size increases. Using the framework of uniform stability, we establish time-independent bounds by exploiting the Wasserstein contraction property of the Langevin diffusion, which also allows us to circumvent the need to bound gradients using Lipschitz-like assumptions. Our analysis also supports variants of SGLD that use different discretization methods, incorporate Euclidean projections, or use non-isotropic noise.
Enabling Real-time On-chip Audio Super Resolution for Bone Conduction Microphones
Dec 24, 2021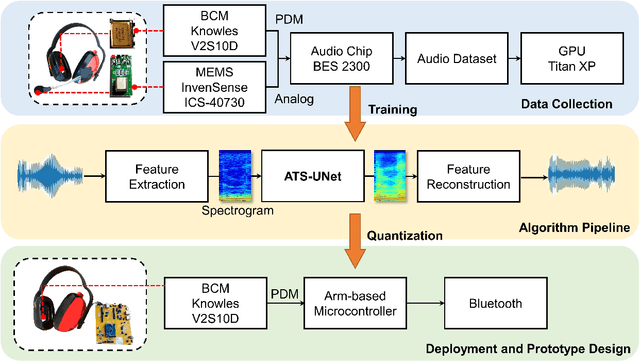
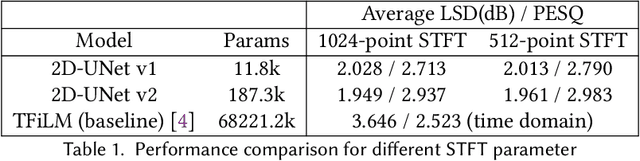
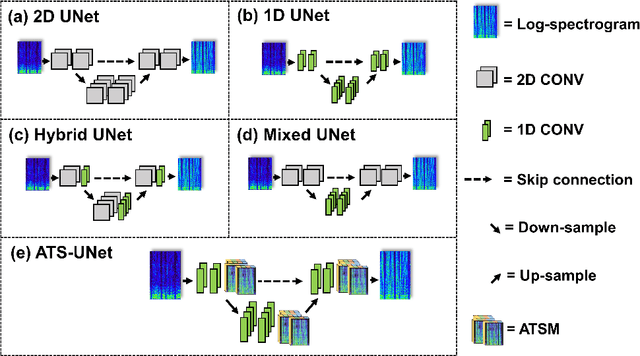
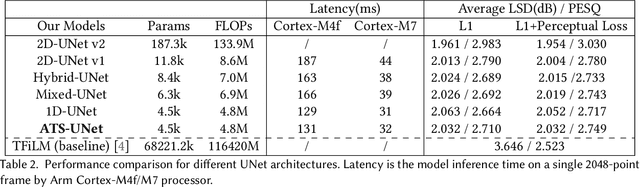
Voice communication using the air conduction microphone in noisy environments suffers from the degradation of speech audibility. Bone conduction microphones (BCM) are robust against ambient noises but suffer from limited effective bandwidth due to their sensing mechanism. Although existing audio super resolution algorithms can recover the high frequency loss to achieve high-fidelity audio, they require considerably more computational resources than available in low-power hearable devices. This paper proposes the first-ever real-time on-chip speech audio super resolution system for BCM. To accomplish this, we built and compared a series of lightweight audio super resolution deep learning models. Among all these models, ATS-UNet is the most cost-efficient because the proposed novel Audio Temporal Shift Module (ATSM) reduces the network's dimensionality while maintaining sufficient temporal features from speech audios. Then we quantized and deployed the ATS-UNet to low-end ARM micro-controller units for real-time embedded prototypes. Evaluation results show that our system achieved real-time inference speed on Cortex-M7 and higher quality than the baseline audio super resolution method. Finally, we conducted a user study with ten experts and ten amateur listeners to evaluate our method's effectiveness to human ears. Both groups perceived a significantly higher speech quality with our method when compared to the solutions with the original BCM or air conduction microphone with cutting-edge noise reduction algorithms.
A simple but strong baseline for online continual learning: Repeated Augmented Rehearsal
Sep 28, 2022
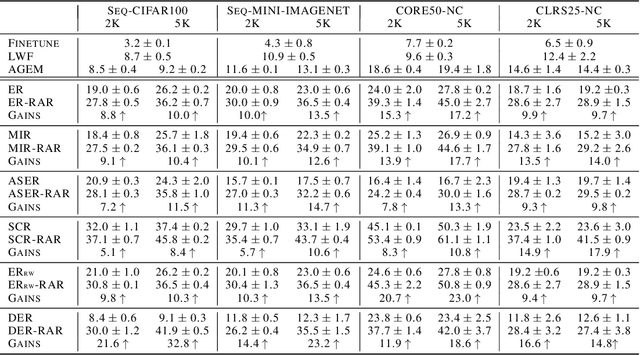
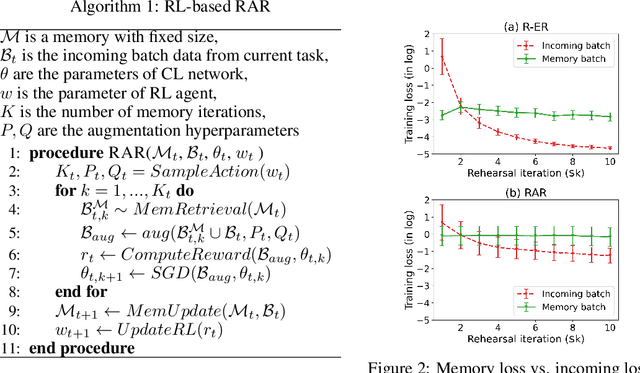
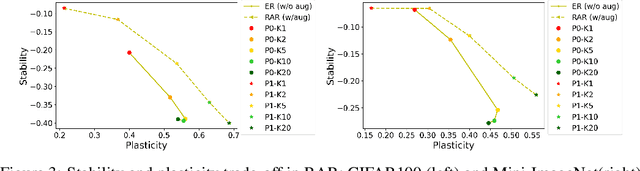
Online continual learning (OCL) aims to train neural networks incrementally from a non-stationary data stream with a single pass through data. Rehearsal-based methods attempt to approximate the observed input distributions over time with a small memory and revisit them later to avoid forgetting. Despite its strong empirical performance, rehearsal methods still suffer from a poor approximation of the loss landscape of past data with memory samples. This paper revisits the rehearsal dynamics in online settings. We provide theoretical insights on the inherent memory overfitting risk from the viewpoint of biased and dynamic empirical risk minimization, and examine the merits and limits of repeated rehearsal. Inspired by our analysis, a simple and intuitive baseline, Repeated Augmented Rehearsal (RAR), is designed to address the underfitting-overfitting dilemma of online rehearsal. Surprisingly, across four rather different OCL benchmarks, this simple baseline outperforms vanilla rehearsal by 9%-17% and also significantly improves state-of-the-art rehearsal-based methods MIR, ASER, and SCR. We also demonstrate that RAR successfully achieves an accurate approximation of the loss landscape of past data and high-loss ridge aversion in its learning trajectory. Extensive ablation studies are conducted to study the interplay between repeated and augmented rehearsal and reinforcement learning (RL) is applied to dynamically adjust the hyperparameters of RAR to balance the stability-plasticity trade-off online.
SR-DCSK Cooperative Communication System with Code Index Modulation: A New Design for 6G New Radios
Aug 27, 2022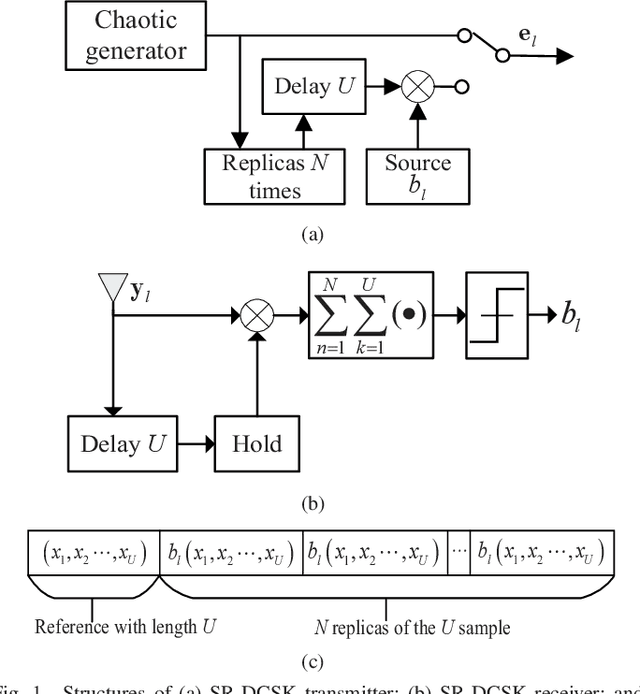
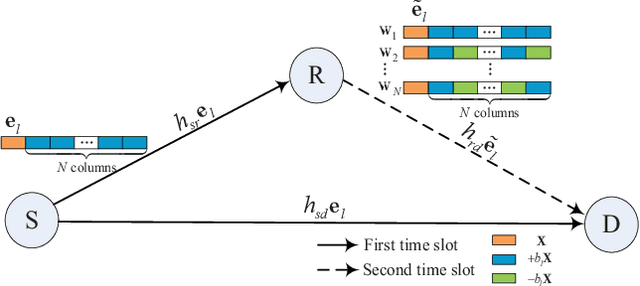
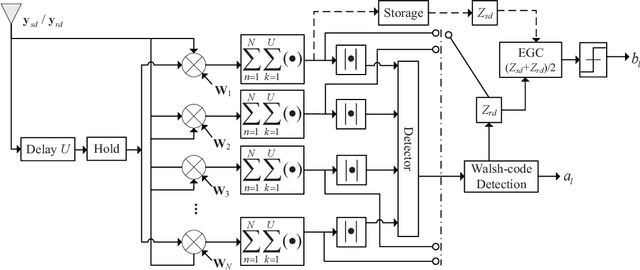
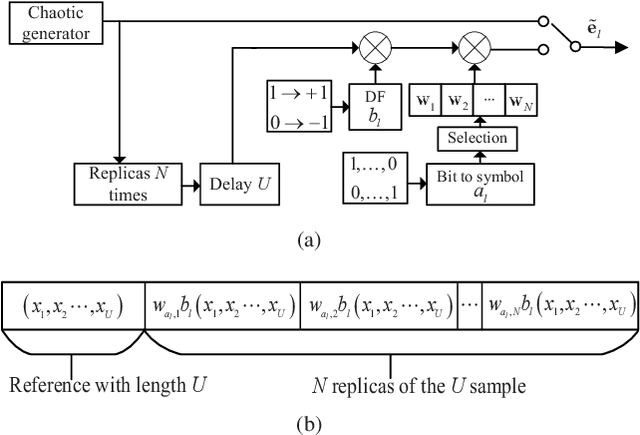
This paper proposes a high-throughput short reference differential chaos shift keying cooperative communication system with the aid of code index modulation, referred to as CIM-SR-DCSK-CC system. In the proposed CIM-SR-DCSK-CC system, the source transmits information bits to both the relay and destination in the first time slot, while the relay not only forwards the source information bits but also sends new information bits to the destination in the second time slot. To be specific, the relay employs an $N$-order Walsh code to carry additional ${{\log }_{2}}N$ information bits, which are superimposed onto the SR-DCSK signal carrying the decoded source information bits. Subsequently, the superimposed signal carrying both the source and relay information bits is transmitted to the destination. Moreover, the theoretical bit error rate (BER) expressions of the proposed CIM-SR-DCSK-CC system are derived over additive white Gaussian noise (AWGN) and multipath Rayleigh fading channels. Compared with the conventional DCSK-CC system and SR-DCSK-CC system, the proposed CIM-SR-DCSK-CC system can significantly improve the throughput without deteriorating any BER performance. As a consequence, the proposed system is very promising for the applications of the 6G-enabled low-power and high-rate communication.
SERF: Interpretable Sleep Staging using Embeddings, Rules, and Features
Sep 25, 2022
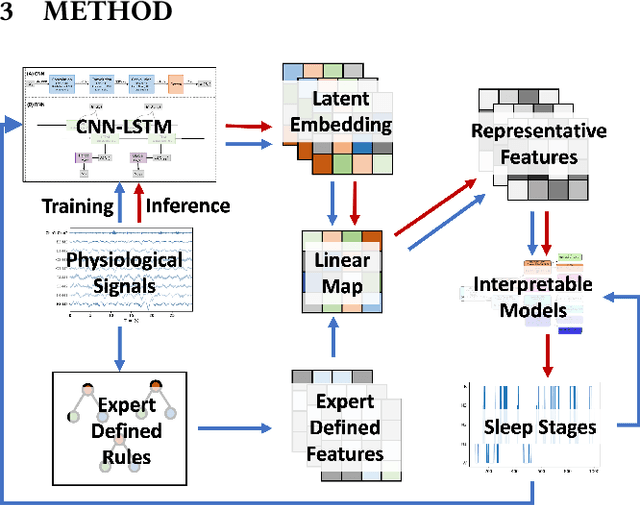
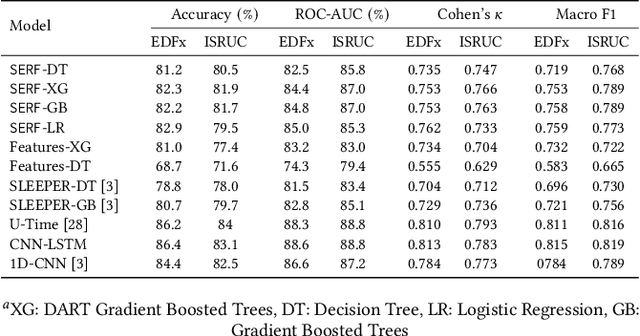
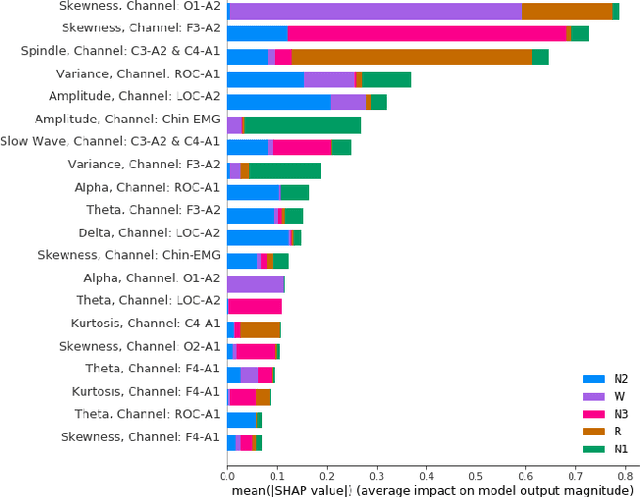
The accuracy of recent deep learning based clinical decision support systems is promising. However, lack of model interpretability remains an obstacle to widespread adoption of artificial intelligence in healthcare. Using sleep as a case study, we propose a generalizable method to combine clinical interpretability with high accuracy derived from black-box deep learning. Clinician-determined sleep stages from polysomnogram (PSG) remain the gold standard for evaluating sleep quality. However, PSG manual annotation by experts is expensive and time-prohibitive. We propose SERF, interpretable Sleep staging using Embeddings, Rules, and Features to read PSG. SERF provides interpretation of classified sleep stages through meaningful features derived from the AASM Manual for the Scoring of Sleep and Associated Events. In SERF, the embeddings obtained from a hybrid of convolutional and recurrent neural networks are transposed to the interpretable feature space. These representative interpretable features are used to train simple models like a shallow decision tree for classification. Model results are validated on two publicly available datasets. SERF surpasses the current state-of-the-art for interpretable sleep staging by 2%. Using Gradient Boosted Trees as the classifier, SERF obtains 0.766 $\kappa$ and 0.870 AUC-ROC, within 2% of the current state-of-the-art black-box models.
Concentration inequalities for correlated network-valued processes with applications to community estimation and changepoint analysis
Aug 02, 2022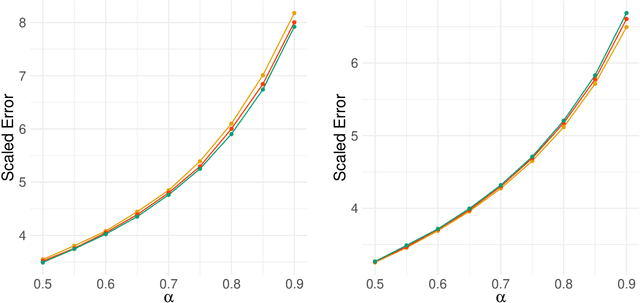
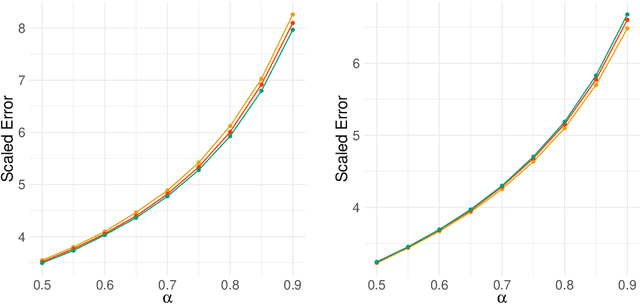
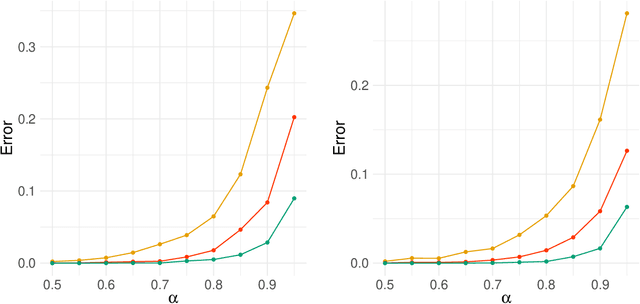
Network-valued time series are currently a common form of network data. However, the study of the aggregate behavior of network sequences generated from network-valued stochastic processes is relatively rare. Most of the existing research focuses on the simple setup where the networks are independent (or conditionally independent) across time, and all edges are updated synchronously at each time step. In this paper, we study the concentration properties of the aggregated adjacency matrix and the corresponding Laplacian matrix associated with network sequences generated from lazy network-valued stochastic processes, where edges update asynchronously, and each edge follows a lazy stochastic process for its updates independent of the other edges. We demonstrate the usefulness of these concentration results in proving consistency of standard estimators in community estimation and changepoint estimation problems. We also conduct a simulation study to demonstrate the effect of the laziness parameter, which controls the extent of temporal correlation, on the accuracy of community and changepoint estimation.