 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TPGNN: Learning High-order Information in Dynamic Graphs via Temporal Propagation
Oct 03, 2022
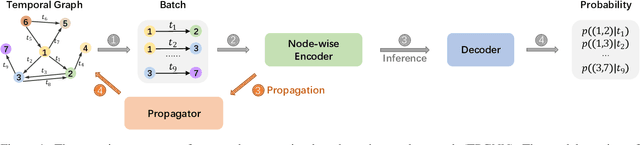
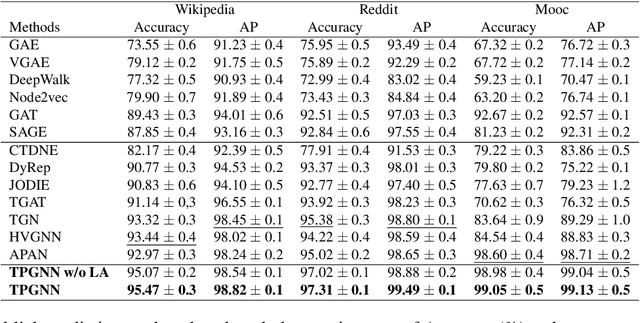
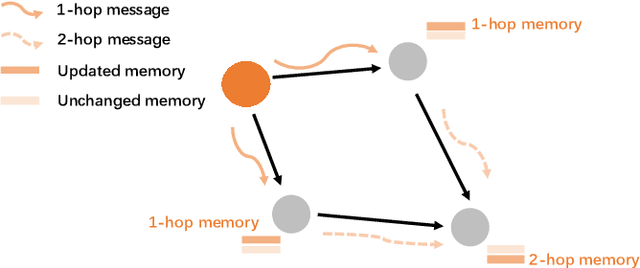

Temporal graph is an abstraction for modeling dynamic systems that consist of evolving interaction elements. In this paper, we aim to solve an important yet neglected problem -- how to learn information from high-order neighbors in temporal graphs? -- to enhance the informativeness and discriminativeness for the learned node representations. We argue that when learning high-order information from temporal graphs, we encounter two challenges, i.e., computational inefficiency and over-smoothing, that cannot be solved by conventional techniques applied on static graphs. To remedy these deficiencies, we propose a temporal propagation-based graph neural network, namely TPGNN. To be specific, the model consists of two distinct components, i.e., propagator and node-wise encoder. The propagator is leveraged to propagate messages from the anchor node to its temporal neighbors within $k$-hop, and then simultaneously update the state of neighborhoods, which enables efficient computation, especially for a deep model. In addition, to prevent over-smoothing, the model compels the messages from $n$-hop neighbors to update the $n$-hop memory vector preserved on the anchor. The node-wise encoder adopts transformer architecture to learn node representations by explicitly learning the importance of memory vectors preserved on the node itself, that is, implicitly modeling the importance of messages from neighbors at different layers, thus mitigating the over-smoothing. Since the encoding process will not query temporal neighbors, we can dramatically save time consumption in inference. Extensive experiments on temporal link prediction and node classification demonstrate the superiority of TPGNN over state-of-the-art baselines in efficiency and robustness.
Statistical Efficiency of Score Matching: The View from Isoperimetry
Oct 03, 2022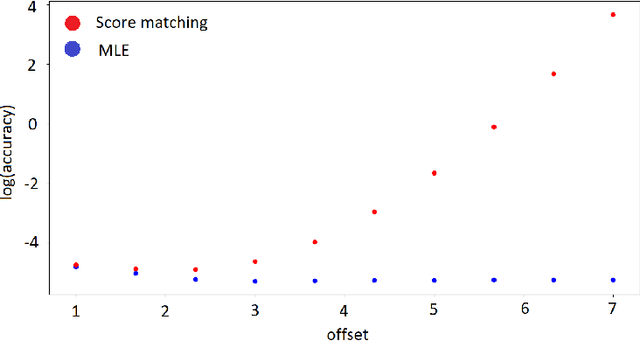
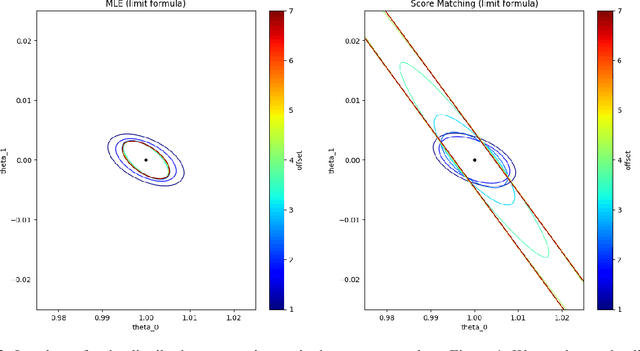
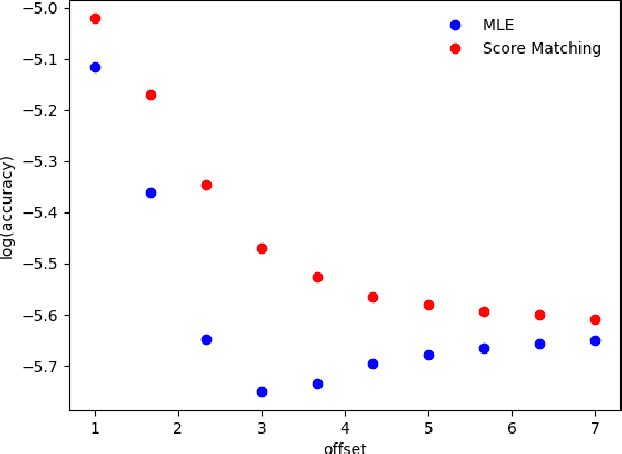
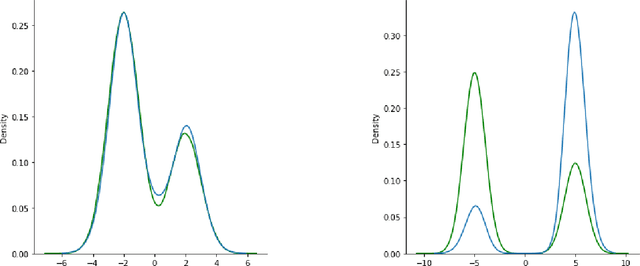
Deep generative models parametrized up to a normalizing constant (e.g. energy-based models) are difficult to train by maximizing the likelihood of the data because the likelihood and/or gradients thereof cannot be explicitly or efficiently written down. Score matching is a training method, whereby instead of fitting the likelihood $\log p(x)$ for the training data, we instead fit the score function $\nabla_x \log p(x)$ -- obviating the need to evaluate the partition function. Though this estimator is known to be consistent, its unclear whether (and when) its statistical efficiency is comparable to that of maximum likelihood -- which is known to be (asymptotically) optimal. We initiate this line of inquiry in this paper, and show a tight connection between statistical efficiency of score matching and the isoperimetric properties of the distribution being estimated -- i.e. the Poincar\'e, log-Sobolev and isoperimetric constant -- quantities which govern the mixing time of Markov processes like Langevin dynamics. Roughly, we show that the score matching estimator is statistically comparable to the maximum likelihood when the distribution has a small isoperimetric constant. Conversely, if the distribution has a large isoperimetric constant -- even for simple families of distributions like exponential families with rich enough sufficient statistics -- score matching will be substantially less efficient than maximum likelihood. We suitably formalize these results both in the finite sample regime, and in the asymptotic regime. Finally, we identify a direct parallel in the discrete setting, where we connect the statistical properties of pseudolikelihood estimation with approximate tensorization of entropy and the Glauber dynamics.
Target Speaker Voice Activity Detection with Transformers and Its Integration with End-to-End Neural Diarization
Aug 27, 2022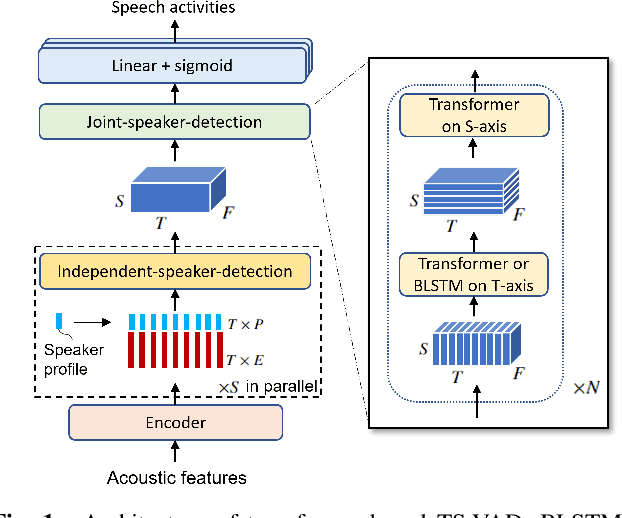
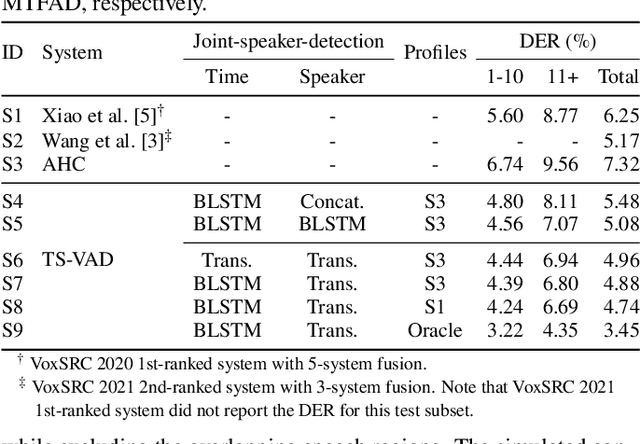
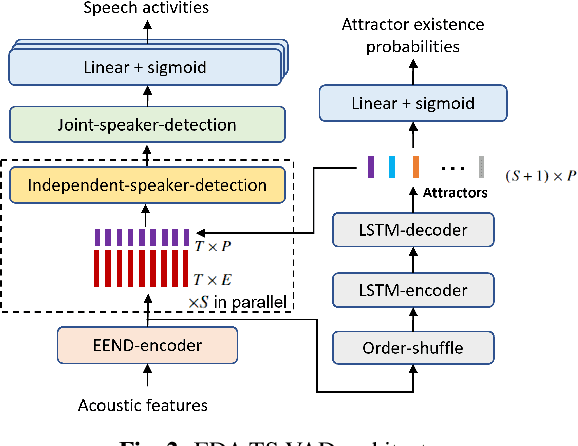
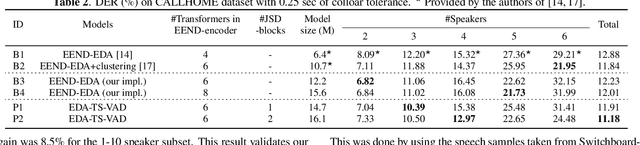
This paper describes a speaker diarization model based on target speaker voice activity detection (TS-VAD) using transformers. To overcome the original TS-VAD model's drawback of being unable to handle an arbitrary number of speakers, we investigate model architectures that use input tensors with variable-length time and speaker dimensions. Transformer layers are applied to the speaker axis to make the model output insensitive to the order of the speaker profiles provided to the TS-VAD model. Time-wise sequential layers are interspersed between these speaker-wise transformer layers to allow the temporal and cross-speaker correlations of the input speech signal to be captured. We also extend a diarization model based on end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) by replacing its dot-product-based speaker detection layer with the transformer-based TS-VAD. Experimental results on VoxConverse show that using the transformers for the cross-speaker modeling reduces the diarization error rate (DER) of TS-VAD by 10.9%, achieving a new state-of-the-art (SOTA) DER of 4.74%. Also, our extended EEND-EDA reduces DER by 6.9% on the CALLHOME dataset relative to the original EEND-EDA with a similar model size, achieving a new SOTA DER of 11.18% under a widely used training data setting.
Using Deep Learning to Improve Early Diagnosis of Pneumonia in Underdeveloped Countries
Oct 10, 2022
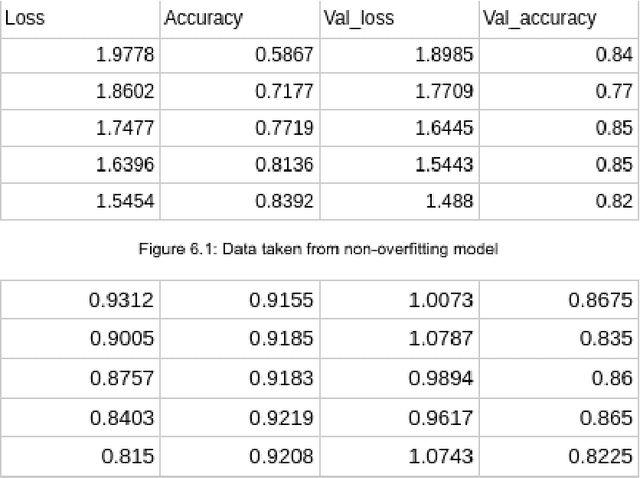
As advancements in technology and medicine are being made, many countries are still unable to access quality medical care due to cost and lack of qualified medical personnel. This discrepancy in healthcare has caused many preventable deaths, either due to lack of detection or lack of care. One of the most prevalent diseases in the world is pneumonia, an infection of the lungs that killed 2.56 million people worldwide in 2017. In this same year, the United States recorded a pneumonia death rate of 15.88 people per 100000 in population, while much of Sub-Saharan Africa, such as Chad and Guinea, experienced death rates of over 150 people per 100000. In sub-Saharan Africa, there is an extreme shortage of doctors and nurses, estimated to be around 2.4 million. The hypothesis being tested is that a deep learning model can receive input in the form of an x-ray and produce a diagnosis with the equivalent accuracy of a physician, compared to a prediagnosed image. The model used in this project is a modified convolutional neural network. The model was trained on a set of 2000 x-ray images that have predetermined normal and abnormal lung findings, and then tested on a set of 400 images that contains evenly split images of pneumonia and healthy lungs. For each computer-run test, data was collected on a base measurement of accuracy, as well as more specific metrics such as specificity and sensitivity. Results show that the algorithm tested was able to accurately identify abnormal lung findings an average of 82.5% of the time. The model achieved a maximum specificity of 98.5% and a maximum sensitivity of 90% separately, and the highest simultaneous values of these two metrics was a sensitivity of 90% and a specificity of 78.5%. This research can be further improved by testing other deep learning models as well as machine learning models to improve the metric scores and chance of correct diagnoses.
Graphing the Future: Activity and Next Active Object Prediction using Graph-based Activity Representations
Sep 12, 2022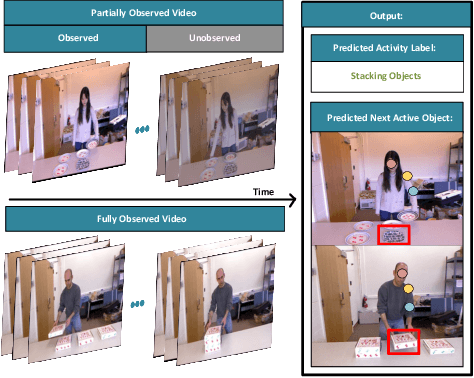

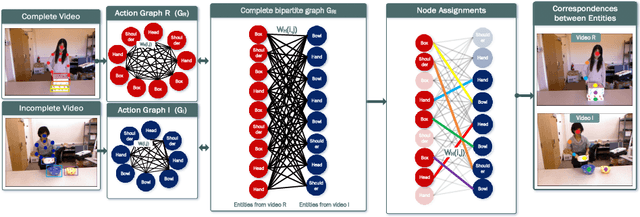
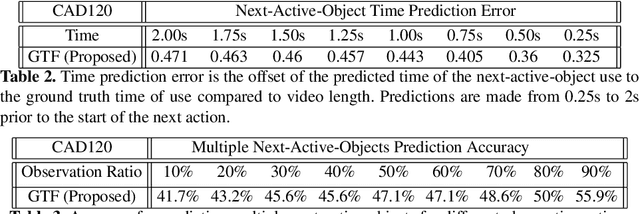
We present a novel approach for the visual prediction of human-object interactions in videos. Rather than forecasting the human and object motion or the future hand-object contact points, we aim at predicting (a)the class of the on-going human-object interaction and (b) the class(es) of the next active object(s) (NAOs), i.e., the object(s) that will be involved in the interaction in the near future as well as the time the interaction will occur. Graph matching relies on the efficient Graph Edit distance (GED) method. The experimental evaluation of the proposed approach was conducted using two well-established video datasets that contain human-object interactions, namely the MSR Daily Activities and the CAD120. High prediction accuracy was obtained for both action prediction and NAO forecasting.
PTSD in the Wild: A Video Database for Studying Post-Traumatic Stress Disorder Recognition in Unconstrained Environments
Sep 28, 2022
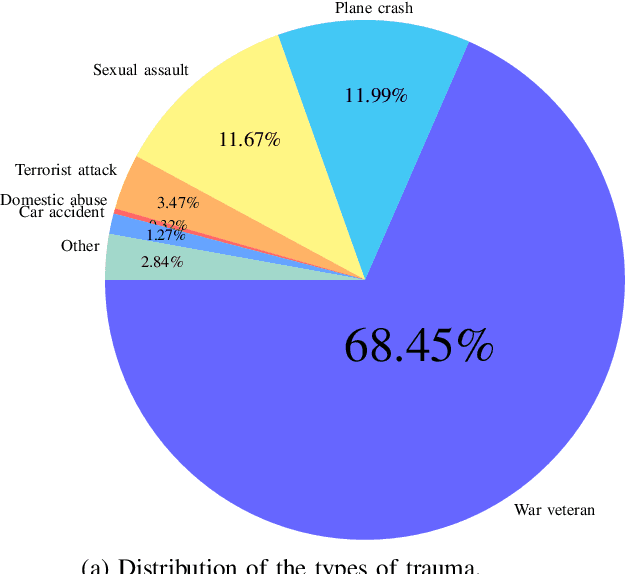
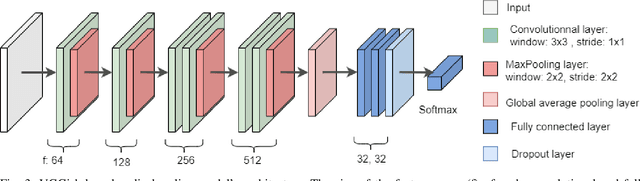
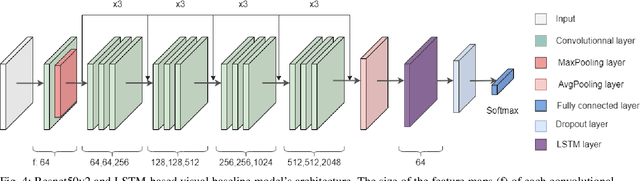
POST-traumatic stress disorder (PTSD) is a chronic and debilitating mental condition that is developed in response to catastrophic life events, such as military combat, sexual assault, and natural disasters. PTSD is characterized by flashbacks of past traumatic events, intrusive thoughts, nightmares, hypervigilance, and sleep disturbance, all of which affect a person's life and lead to considerable social, occupational, and interpersonal dysfunction. The diagnosis of PTSD is done by medical professionals using self-assessment questionnaire of PTSD symptoms as defined in the Diagnostic and Statistical Manual of Mental Disorders (DSM). In this paper, and for the first time, we collected, annotated, and prepared for public distribution a new video database for automatic PTSD diagnosis, called PTSD in the wild dataset. The database exhibits "natural" and big variability in acquisition conditions with different pose, facial expression, lighting, focus, resolution, age, gender, race, occlusions and background. In addition to describing the details of the dataset collection, we provide a benchmark for evaluating computer vision and machine learning based approaches on PTSD in the wild dataset. In addition, we propose and we evaluate a deep learning based approach for PTSD detection in respect to the given benchmark. The proposed approach shows very promising results. Interested researcher can download a copy of PTSD-in-the wild dataset from: http://www.lissi.fr/PTSD-Dataset/
A Unified Perspective on Natural Gradient Variational Inference with Gaussian Mixture Models
Sep 23, 2022
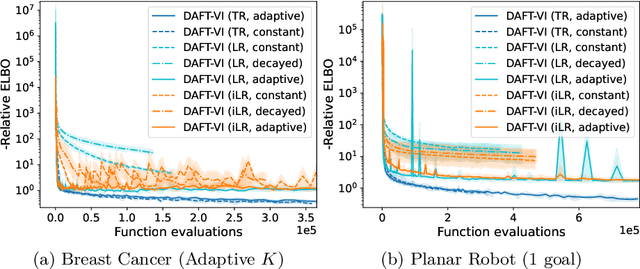
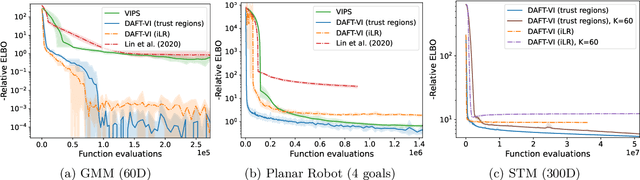
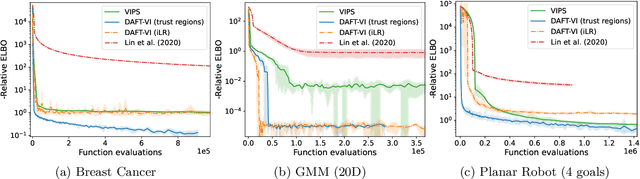
Variational inference with Gaussian mixture models (GMMs) enables learning of highly-tractable yet multi-modal approximations of intractable target distributions. GMMs are particular relevant for problem settings with up to a few hundred dimensions, for example in robotics, for modelling distributions over trajectories or joint distributions. This work focuses on two very effective methods for GMM-based variational inference that both employ independent natural gradient updates for the individual components and the categorical distribution of the weights. We show for the first time, that their derived updates are equivalent, although their practical implementations and theoretical guarantees differ. We identify several design choices that distinguish both approaches, namely with respect to sample selection, natural gradient estimation, stepsize adaptation, and whether trust regions are enforced or the number of components adapted. We perform extensive ablations on these design choices and show that they strongly affect the efficiency of the optimization and the variability of the learned distribution. Based on our insights, we propose a novel instantiation of our generalized framework, that combines first-order natural gradient estimates with trust-regions and component adaption, and significantly outperforms both previous methods in all our experiments.
Joint Optimization of STAR-RIS Assisted UAV Communication Systems
Sep 08, 2022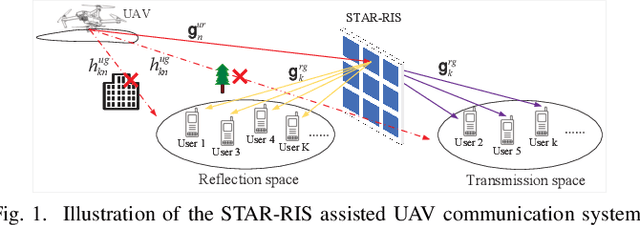
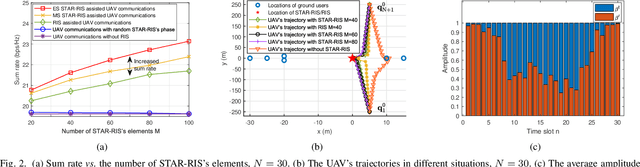
In this letter, we study the simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted unmanned aerial vehicle (UAV) communications. Our goal is to maximize the sum rate of all users by jointly optimizing the STAR-RIS's beamforming vectors, the UAV's trajectory and power allocation. We decompose the formulated non-convex problem into three subproblems and solve them alternately to obtain the solution. Simulations show that: 1) the STAR-RIS achieves a higher sum rate than traditional RIS; 2) to exploit the benefits of STAR-RIS, the UAV's trajectory is closer to STAR-RIS than that of RIS; 3) the energy splitting for reflection and transmission highly depends on the real-time trajectory of UAV.
* 5 pages, 4 figures
A Deep Reinforcement Learning-Based Charging Scheduling Approach with Augmented Lagrangian for Electric Vehicle
Sep 20, 2022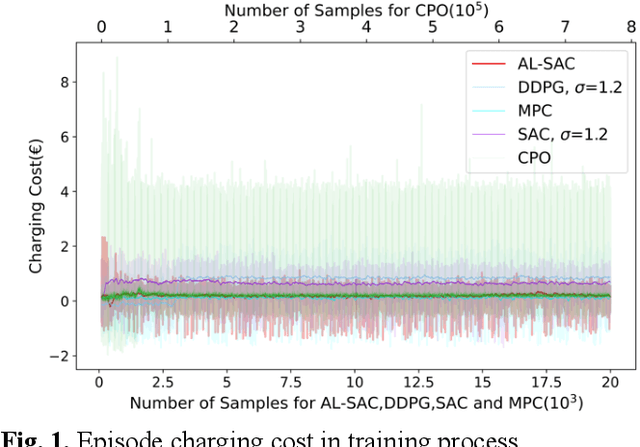
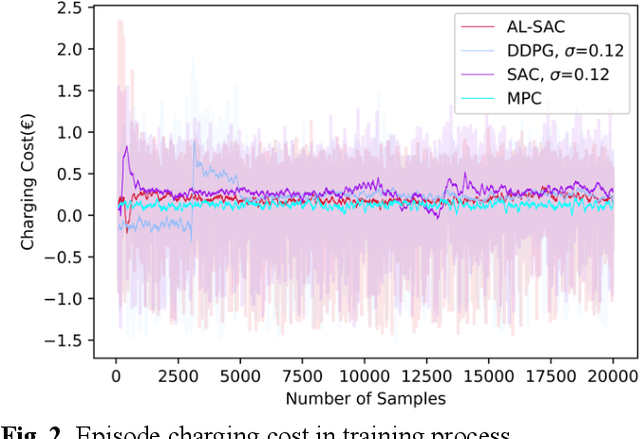
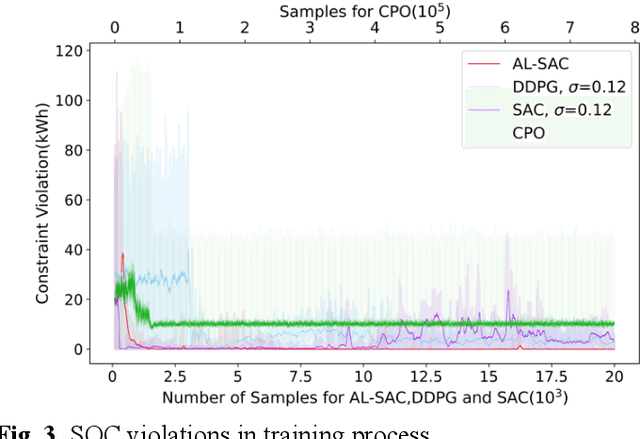
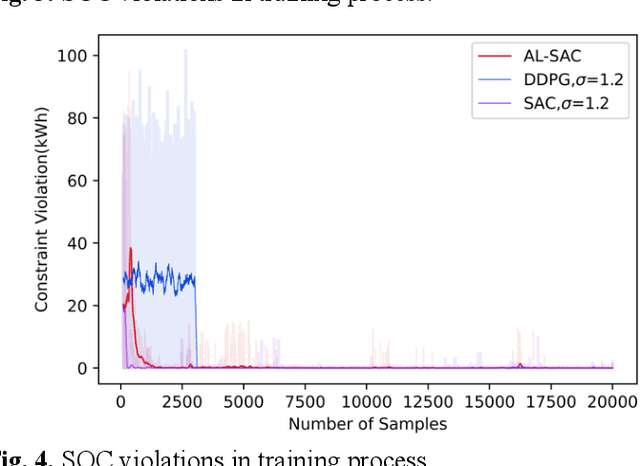
This paper addresses the problem of optimizing charging/discharging schedules of electric vehicles (EVs) when participate in demand response (DR). As there exist uncertainties in EVs' remaining energy, arrival and departure time, and future electricity prices, it is quite difficult to make charging decisions to minimize charging cost while guarantee that the EV's battery state-of-the-charge (SOC) is within certain range. To handle with this dilemma, this paper formulates the EV charging scheduling problem as a constrained Markov decision process (CMDP). By synergistically combining the augmented Lagrangian method and soft actor critic algorithm, a novel safe off-policy reinforcement learning (RL) approach is proposed in this paper to solve the CMDP. The actor network is updated in a policy gradient manner with the Lagrangian value function. A double-critics network is adopted to synchronously estimate the action-value function to avoid overestimation bias. The proposed algorithm does not require strong convexity guarantee of examined problems and is sample efficient. Comprehensive numerical experiments with real-world electricity price demonstrate that our proposed algorithm can achieve high solution optimality and constraints compliance.
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
Jan 18, 2022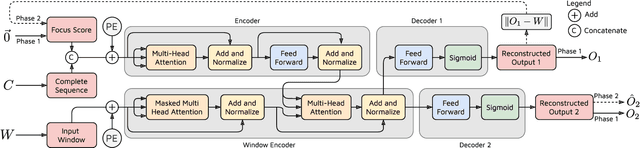
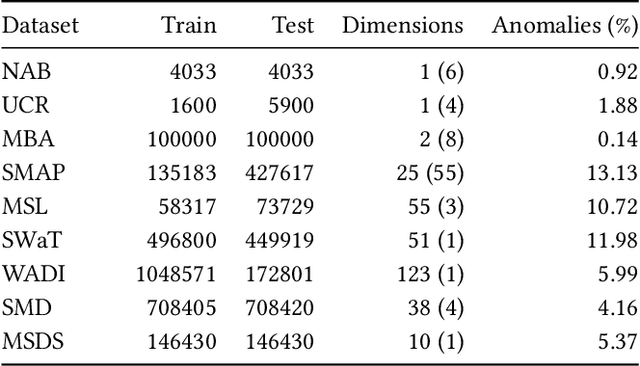
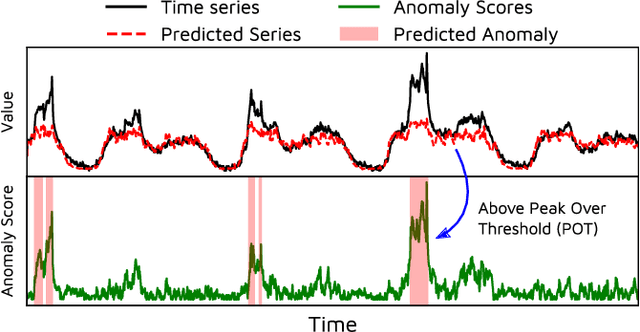
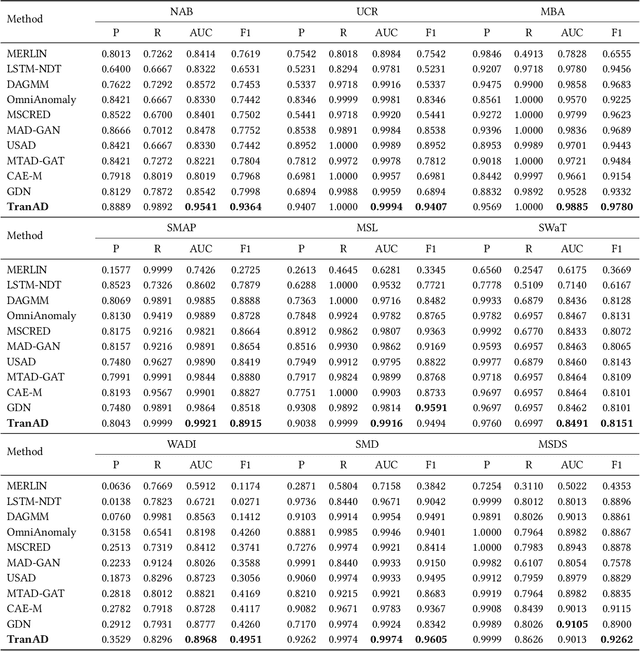
Efficient anomaly detection and diagnosis in multivariate time-series data is of great importance for modern industrial applications. However, building a system that is able to quickly and accurately pinpoint anomalous observations is a challenging problem. This is due to the lack of anomaly labels, high data volatility and the demands of ultra-low inference times in modern applications. Despite the recent developments of deep learning approaches for anomaly detection, only a few of them can address all of these challenges. In this paper, we propose TranAD, a deep transformer network based anomaly detection and diagnosis model which uses attention-based sequence encoders to swiftly perform inference with the knowledge of the broader temporal trends in the data. TranAD uses focus score-based self-conditioning to enable robust multi-modal feature extraction and adversarial training to gain stability. Additionally, model-agnostic meta learning (MAML) allows us to train the model using limited data. Extensive empirical studies on six publicly available datasets demonstrate that TranAD can outperform state-of-the-art baseline methods in detection and diagnosis performance with data and time-efficient training. Specifically, TranAD increases F1 scores by up to 17%, reducing training times by up to 99% compared to the baselines.