 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ever-Evolving Memory by Blending and Refining the Past
Mar 03, 2024
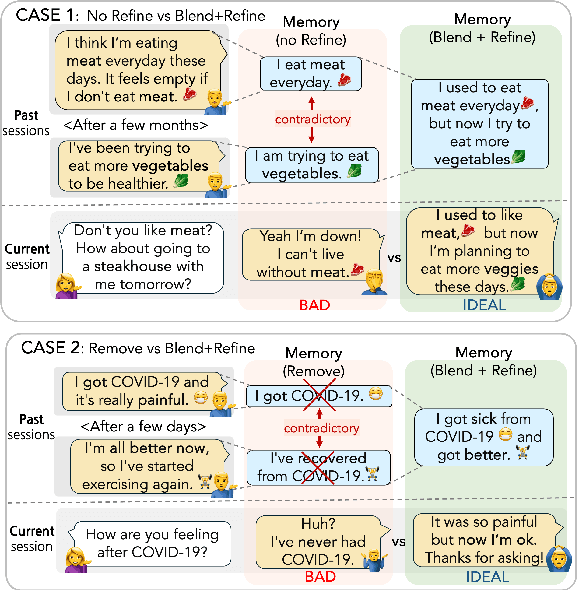
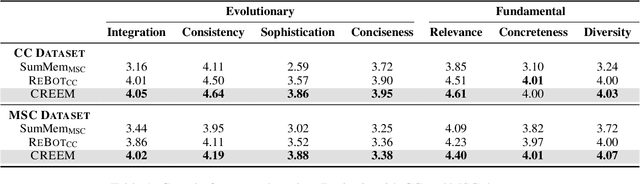
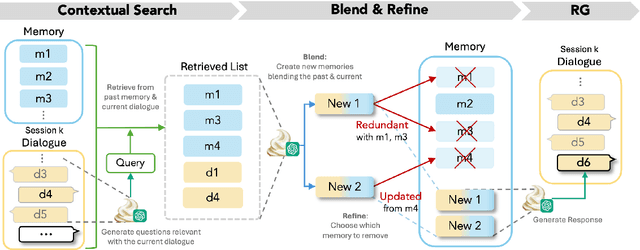
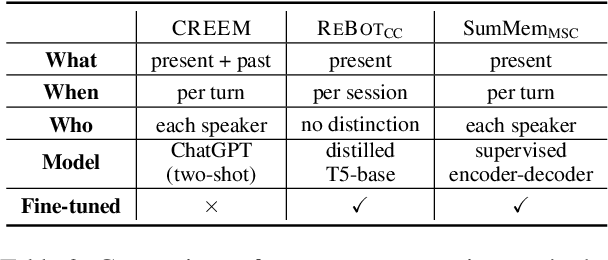
For a human-like chatbot, constructing a long-term memory is crucial. A naive approach for making a memory could be simply listing the summarized dialogue. However, this can lead to problems when the speaker's status change over time and contradictory information gets accumulated. It is important that the memory stays organized to lower the confusion for the response generator. In this paper, we propose a novel memory scheme for long-term conversation, CREEM. Unlike existing approaches that construct memory based solely on current sessions, our proposed model blending past memories during memory formation. Additionally, we introduce refining process to handle redundant or outdated information. This innovative approach seeks for overall improvement and coherence of chatbot responses by ensuring a more informed and dynamically evolving long-term memory.
Probabilistic Forecasting of Irregular Time Series via Conditional Flows
Feb 09, 2024Probabilistic forecasting of irregularly sampled multivariate time series with missing values is an important problem in many fields, including health care, astronomy, and climate. State-of-the-art methods for the task estimate only marginal distributions of observations in single channels and at single timepoints, assuming a fixed-shape parametric distribution. In this work, we propose a novel model, ProFITi, for probabilistic forecasting of irregularly sampled time series with missing values using conditional normalizing flows. The model learns joint distributions over the future values of the time series conditioned on past observations and queried channels and times, without assuming any fixed shape of the underlying distribution. As model components, we introduce a novel invertible triangular attention layer and an invertible non-linear activation function on and onto the whole real line. We conduct extensive experiments on four datasets and demonstrate that the proposed model provides $4$ times higher likelihood over the previously best model.
Consistent and Asymptotically Statistically-Efficient Solution to Camera Motion Estimation
Mar 02, 2024
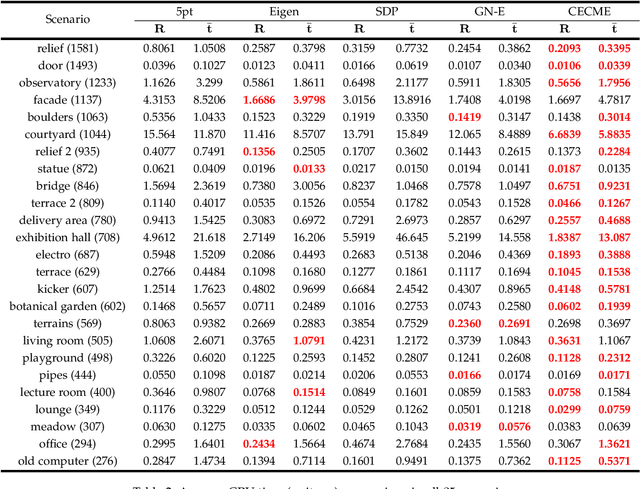
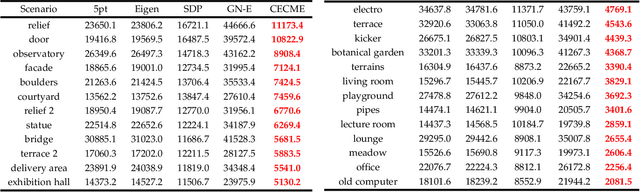
Given 2D point correspondences between an image pair, inferring the camera motion is a fundamental issue in the computer vision community. The existing works generally set out from the epipolar constraint and estimate the essential matrix, which is not optimal in the maximum likelihood (ML) sense. In this paper, we dive into the original measurement model with respect to the rotation matrix and normalized translation vector and formulate the ML problem. We then propose a two-step algorithm to solve it: In the first step, we estimate the variance of measurement noises and devise a consistent estimator based on bias elimination; In the second step, we execute a one-step Gauss-Newton iteration on manifold to refine the consistent estimate. We prove that the proposed estimate owns the same asymptotic statistical properties as the ML estimate: The first is consistency, i.e., the estimate converges to the ground truth as the point number increases; The second is asymptotic efficiency, i.e., the mean squared error of the estimate converges to the theoretical lower bound -- Cramer-Rao bound. In addition, we show that our algorithm has linear time complexity. These appealing characteristics endow our estimator with a great advantage in the case of dense point correspondences. Experiments on both synthetic data and real images demonstrate that when the point number reaches the order of hundreds, our estimator outperforms the state-of-the-art ones in terms of estimation accuracy and CPU time.
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Mar 02, 2024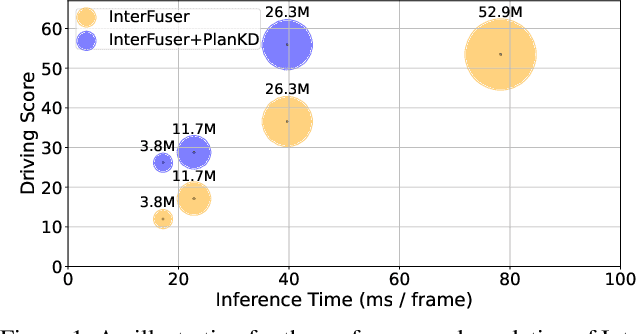
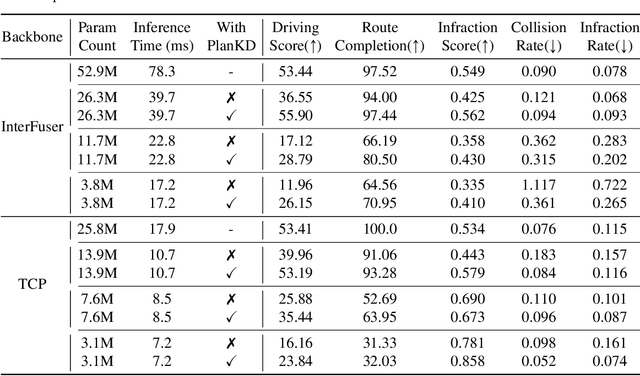
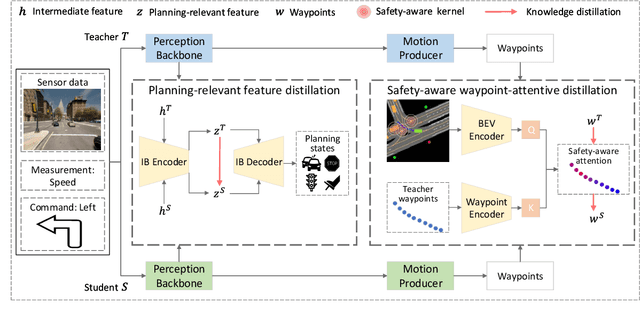
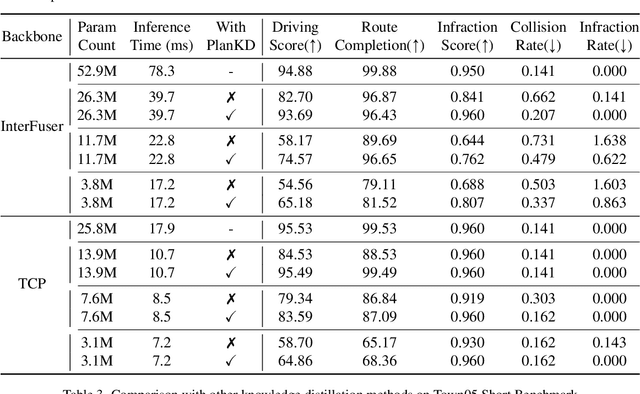
End-to-end motion planning models equipped with deep neural networks have shown great potential for enabling full autonomous driving. However, the oversized neural networks render them impractical for deployment on resource-constrained systems, which unavoidably requires more computational time and resources during reference.To handle this, knowledge distillation offers a promising approach that compresses models by enabling a smaller student model to learn from a larger teacher model. Nevertheless, how to apply knowledge distillation to compress motion planners has not been explored so far. In this paper, we propose PlanKD, the first knowledge distillation framework tailored for compressing end-to-end motion planners. First, considering that driving scenes are inherently complex, often containing planning-irrelevant or even noisy information, transferring such information is not beneficial for the student planner. Thus, we design an information bottleneck based strategy to only distill planning-relevant information, rather than transfer all information indiscriminately. Second, different waypoints in an output planned trajectory may hold varying degrees of importance for motion planning, where a slight deviation in certain crucial waypoints might lead to a collision. Therefore, we devise a safety-aware waypoint-attentive distillation module that assigns adaptive weights to different waypoints based on the importance, to encourage the student to accurately mimic more crucial waypoints, thereby improving overall safety. Experiments demonstrate that our PlanKD can boost the performance of smaller planners by a large margin, and significantly reduce their reference time.
MORBDD: Multiobjective Restricted Binary Decision Diagrams by Learning to Sparsify
Mar 04, 2024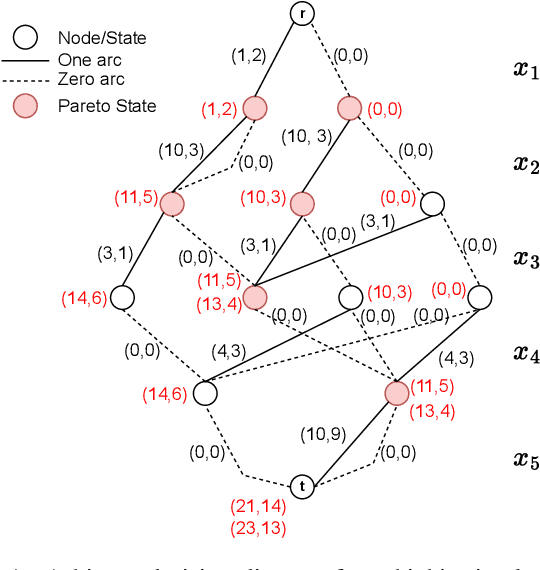

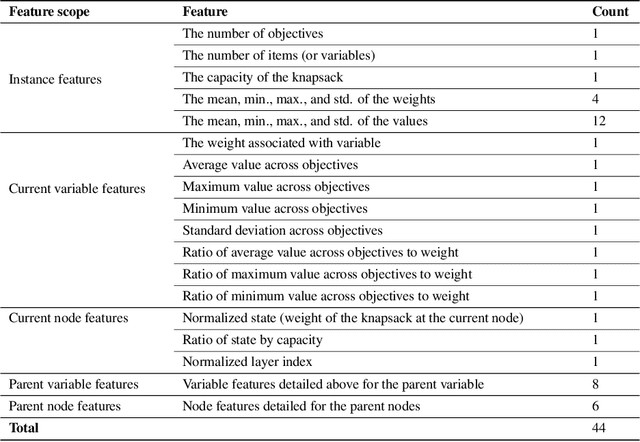
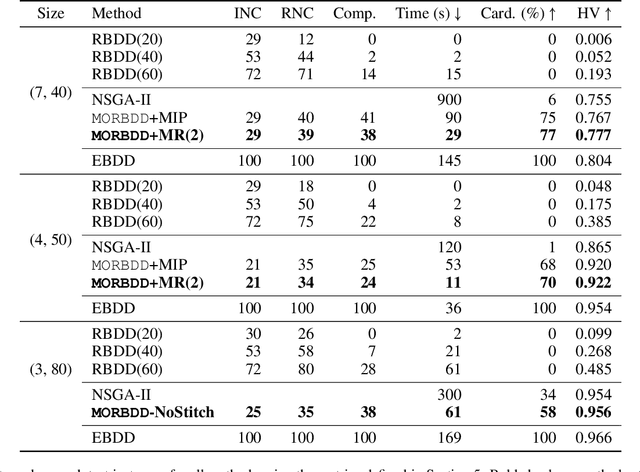
In multicriteria decision-making, a user seeks a set of non-dominated solutions to a (constrained) multiobjective optimization problem, the so-called Pareto frontier. In this work, we seek to bring a state-of-the-art method for exact multiobjective integer linear programming into the heuristic realm. We focus on binary decision diagrams (BDDs) which first construct a graph that represents all feasible solutions to the problem and then traverse the graph to extract the Pareto frontier. Because the Pareto frontier may be exponentially large, enumerating it over the BDD can be time-consuming. We explore how restricted BDDs, which have already been shown to be effective as heuristics for single-objective problems, can be adapted to multiobjective optimization through the use of machine learning (ML). MORBDD, our ML-based BDD sparsifier, first trains a binary classifier to eliminate BDD nodes that are unlikely to contribute to Pareto solutions, then post-processes the sparse BDD to ensure its connectivity via optimization. Experimental results on multiobjective knapsack problems show that MORBDD is highly effective at producing very small restricted BDDs with excellent approximation quality, outperforming width-limited restricted BDDs and the well-known evolutionary algorithm NSGA-II.
PointCore: Efficient Unsupervised Point Cloud Anomaly Detector Using Local-Global Features
Mar 04, 2024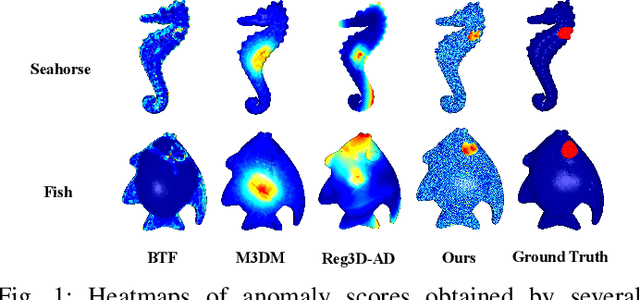
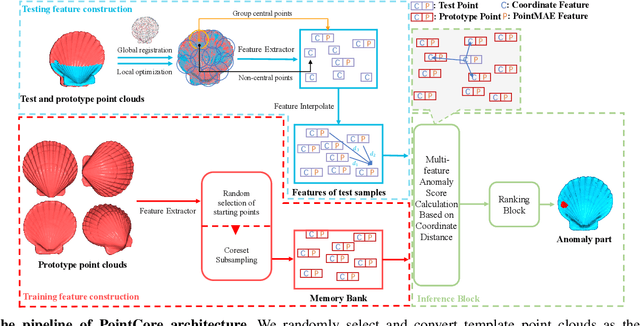
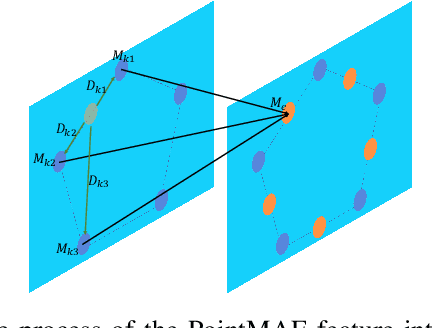
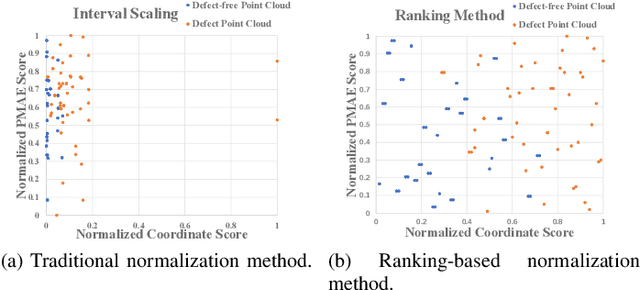
Three-dimensional point cloud anomaly detection that aims to detect anomaly data points from a training set serves as the foundation for a variety of applications, including industrial inspection and autonomous driving. However, existing point cloud anomaly detection methods often incorporate multiple feature memory banks to fully preserve local and global representations, which comes at the high cost of computational complexity and mismatches between features. To address that, we propose an unsupervised point cloud anomaly detection framework based on joint local-global features, termed PointCore. To be specific, PointCore only requires a single memory bank to store local (coordinate) and global (PointMAE) representations and different priorities are assigned to these local-global features, thereby reducing the computational cost and mismatching disturbance in inference. Furthermore, to robust against the outliers, a normalization ranking method is introduced to not only adjust values of different scales to a notionally common scale, but also transform densely-distributed data into a uniform distribution. Extensive experiments on Real3D-AD dataset demonstrate that PointCore achieves competitive inference time and the best performance in both detection and localization as compared to the state-of-the-art Reg3D-AD approach and several competitors.
DragTex: Generative Point-Based Texture Editing on 3D Mesh
Mar 04, 2024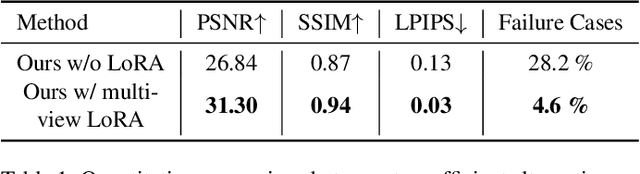
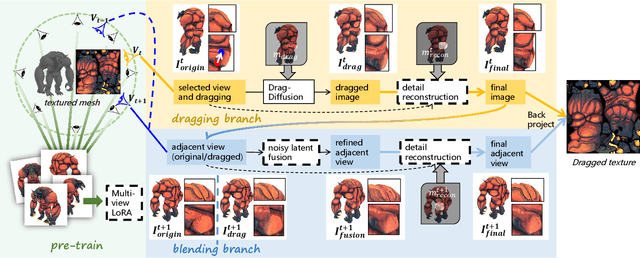


Creating 3D textured meshes using generative artificial intelligence has garnered significant attention recently. While existing methods support text-based generative texture generation or editing on 3D meshes, they often struggle to precisely control pixels of texture images through more intuitive interaction. While 2D images can be edited generatively using drag interaction, applying this type of methods directly to 3D mesh textures still leads to issues such as the lack of local consistency among multiple views, error accumulation and long training times. To address these challenges, we propose a generative point-based 3D mesh texture editing method called DragTex. This method utilizes a diffusion model to blend locally inconsistent textures in the region near the deformed silhouette between different views, enabling locally consistent texture editing. Besides, we fine-tune a decoder to reduce reconstruction errors in the non-drag region, thereby mitigating overall error accumulation. Moreover, we train LoRA using multi-view images instead of training each view individually, which significantly shortens the training time. The experimental results show that our method effectively achieves dragging textures on 3D meshes and generates plausible textures that align with the desired intent of drag interaction.
ICLN: Input Convex Loss Network for Decision Focused Learning
Mar 04, 2024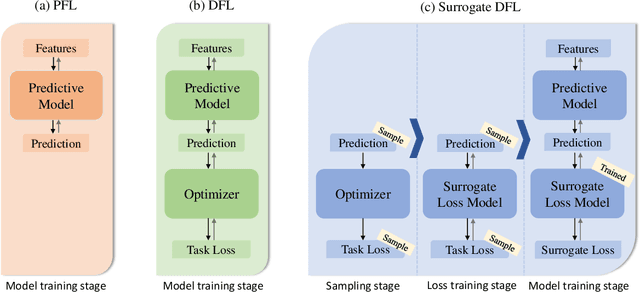

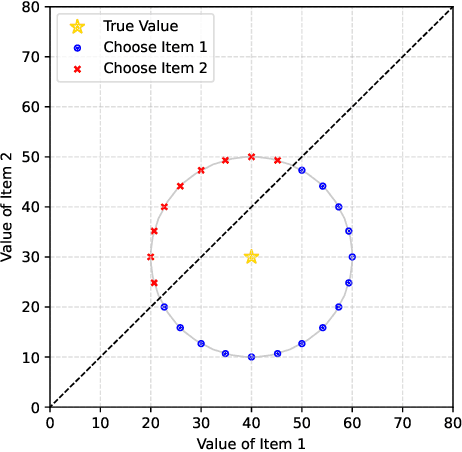
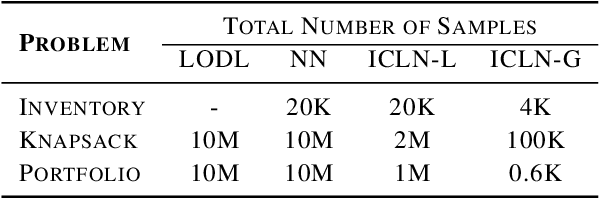
In decision-making problem under uncertainty, predicting unknown parameters is often considered independent of the optimization part. Decision-focused Learning (DFL) is a task-oriented framework to integrate prediction and optimization by adapting predictive model to give better decision for the corresponding task. Here, an inevitable challenge arises when computing gradients of the optimal decision with respect to the parameters. Existing researches cope this issue by smoothly reforming surrogate optimization or construct surrogate loss function that mimic task loss. However, they are applied to restricted optimization domain or build functions in a local manner leading a large computational time. In this paper, we propose Input Convex Loss Network (ICLN), a novel global surrogate loss which can be implemented in a general DFL paradigm. ICLN learns task loss via Input Convex Neural Networks which is guaranteed to be convex for some inputs, while keeping the global structure for the other inputs. This enables ICLN to admit general DFL through only a single surrogate loss without any sense for choosing appropriate parametric forms. We confirm effectiveness and flexibility of ICLN by evaluating our proposed model with three stochastic decision-making problems.
Scaling Up Adaptive Filter Optimizers
Mar 01, 2024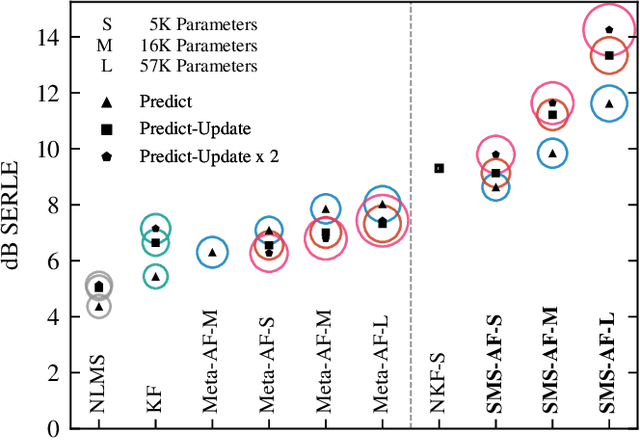
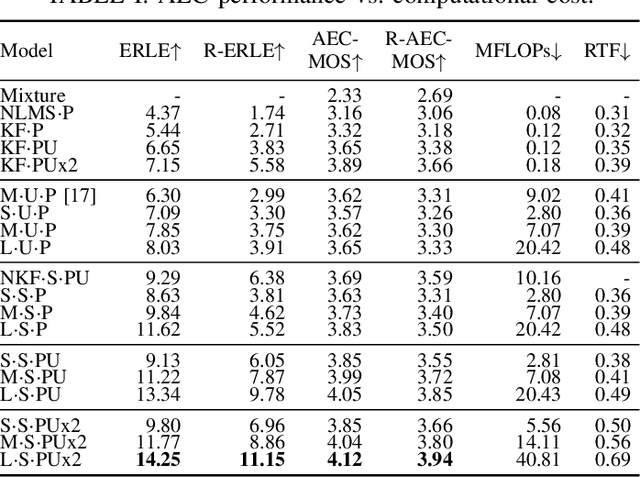
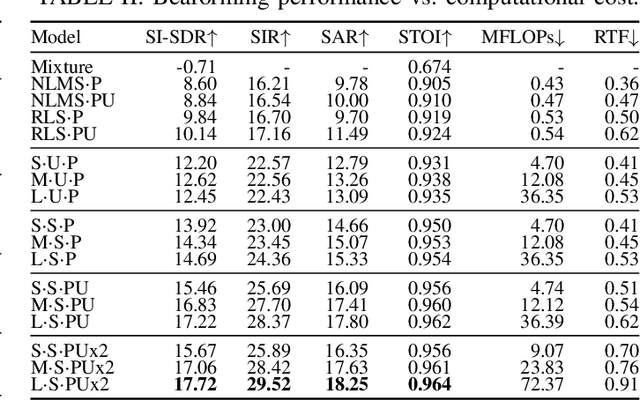
We introduce a new online adaptive filtering method called supervised multi-step adaptive filters (SMS-AF). Our method uses neural networks to control or optimize linear multi-delay or multi-channel frequency-domain filters and can flexibly scale-up performance at the cost of increased compute -- a property rarely addressed in the AF literature, but critical for many applications. To do so, we extend recent work with a set of improvements including feature pruning, a supervised loss, and multiple optimization steps per time-frame. These improvements work in a cohesive manner to unlock scaling. Furthermore, we show how our method relates to Kalman filtering and meta-adaptive filtering, making it seamlessly applicable to a diverse set of AF tasks. We evaluate our method on acoustic echo cancellation (AEC) and multi-channel speech enhancement tasks and compare against several baselines on standard synthetic and real-world datasets. Results show our method performance scales with inference cost and model capacity, yields multi-dB performance gains for both tasks, and is real-time capable on a single CPU core.
Indirectly Parameterized Concrete Autoencoders
Mar 01, 2024
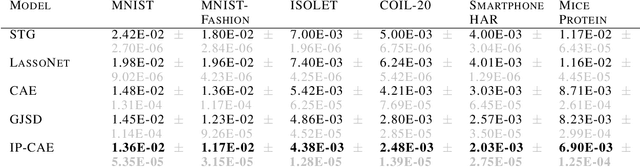
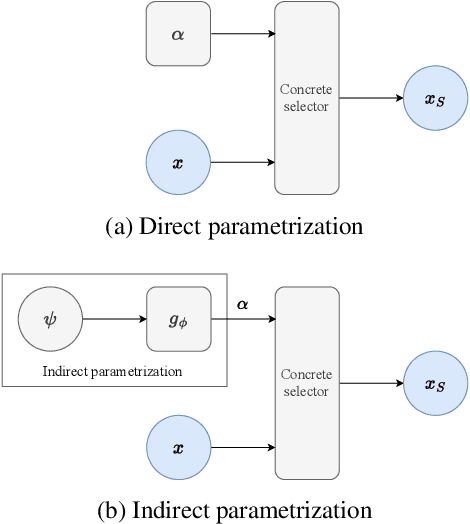

Feature selection is a crucial task in settings where data is high-dimensional or acquiring the full set of features is costly. Recent developments in neural network-based embedded feature selection show promising results across a wide range of applications. Concrete Autoencoders (CAEs), considered state-of-the-art in embedded feature selection, may struggle to achieve stable joint optimization, hurting their training time and generalization. In this work, we identify that this instability is correlated with the CAE learning duplicate selections. To remedy this, we propose a simple and effective improvement: Indirectly Parameterized CAEs (IP-CAEs). IP-CAEs learn an embedding and a mapping from it to the Gumbel-Softmax distributions' parameters. Despite being simple to implement, IP-CAE exhibits significant and consistent improvements over CAE in both generalization and training time across several datasets for reconstruction and classification. Unlike CAE, IP-CAE effectively leverages non-linear relationships and does not require retraining the jointly optimized decoder. Furthermore, our approach is, in principle, generalizable to Gumbel-Softmax distributions beyond feature selection.