 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Networked Time Series Prediction with Incomplete Data
Oct 05, 2021
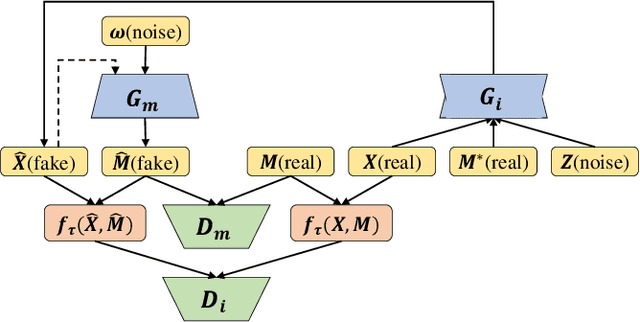
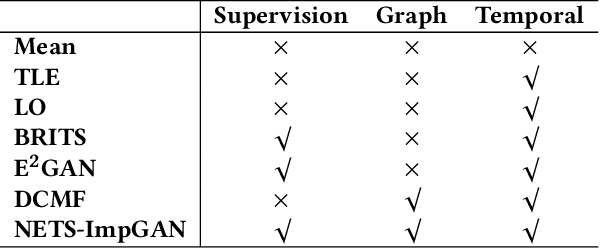
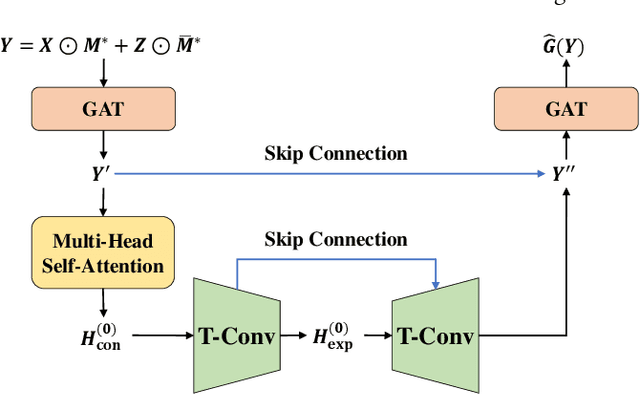
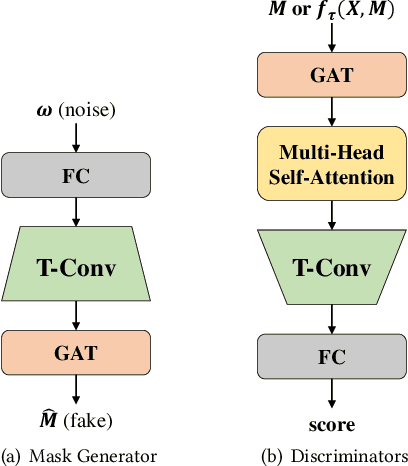
A networked time series (NETS) is a family of time series on a given graph, one for each node. It has found a wide range of applications from intelligent transportation, environment monitoring to mobile network management. An important task in such applications is to predict the future values of a NETS based on its historical values and the underlying graph. Most existing methods require complete data for training. However, in real-world scenarios, it is not uncommon to have missing data due to sensor malfunction, incomplete sensing coverage, etc. In this paper, we study the problem of NETS prediction with incomplete data. We propose NETS-ImpGAN, a novel deep learning framework that can be trained on incomplete data with missing values in both history and future. Furthermore, we propose novel Graph Temporal Attention Networks by incorporating the attention mechanism to capture both inter-time series correlations and temporal correlations. We conduct extensive experiments on three real-world datasets under different missing patterns and missing rates. The experimental results show that NETS-ImpGAN outperforms existing methods except when data exhibit very low variance, in which case NETS-ImpGAN still achieves competitive performance.
4DenoiseNet: Adverse Weather Denoising from Adjacent Point Clouds
Sep 15, 2022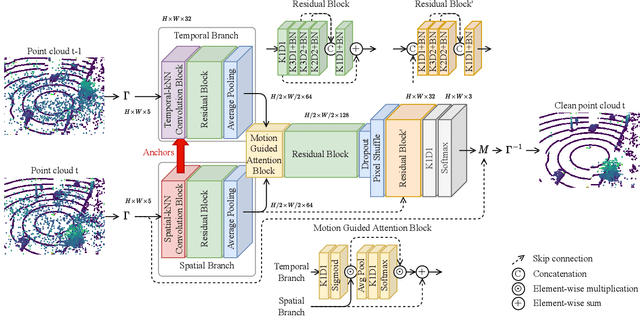
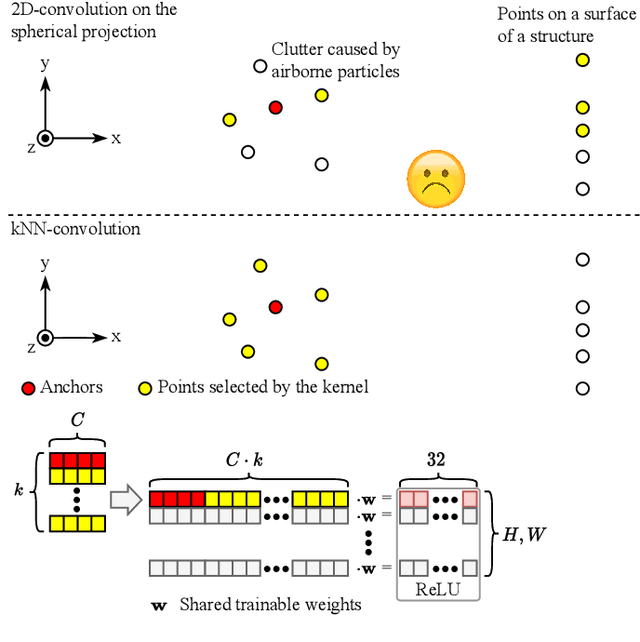
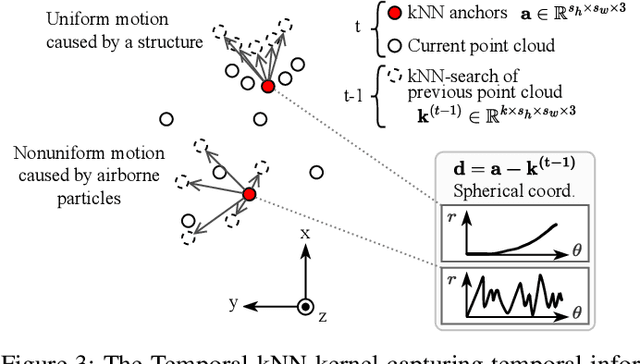
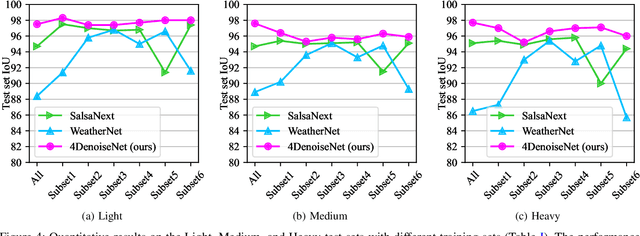
Reliable point cloud data is essential for perception tasks \textit{e.g.} in robotics and autonomous driving applications. Adverse weather causes a specific type of noise to light detection and ranging (LiDAR) sensor data, which degrades the quality of the point clouds significantly. To address this issue, this letter presents a novel point cloud adverse weather denoising deep learning algorithm (4DenoiseNet). Our algorithm takes advantage of the time dimension unlike deep learning adverse weather denoising methods in the literature. It performs about 10\% better in terms of intersection over union metric compared to the previous work and is more computationally efficient. These results are achieved on our novel SnowyKITTI dataset, which has over 40000 adverse weather annotated point clouds. Moreover, strong qualitative results on the Canadian Adverse Driving Conditions dataset indicate good generalizability to domain shifts and to different sensor intrinsics.
Social-Inverse: Inverse Decision-making of Social Contagion Management with Task Migrations
Sep 21, 2022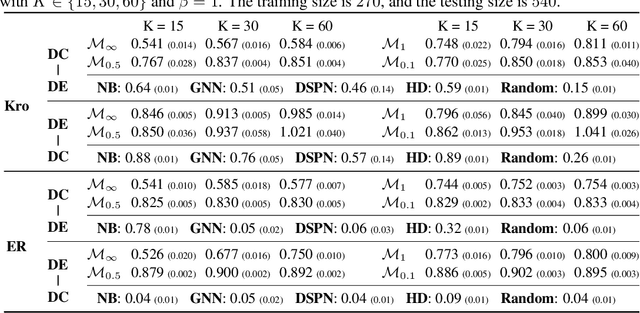
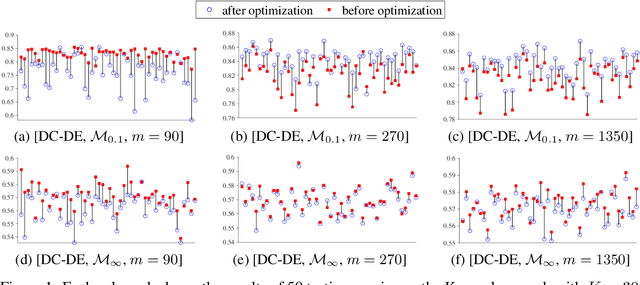
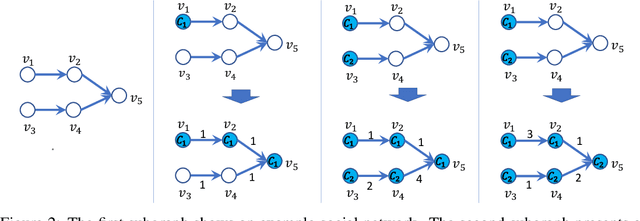
Considering two decision-making tasks $A$ and $B$, each of which wishes to compute an effective \textit{decision} $Y$ for a given \textit{query} $X$, {can we solve task $B$ by using query-decision pairs $(X, Y)$ of $A$ without knowing the latent decision-making model?} Such problems, called \textit{inverse decision-making with task migrations}, are of interest in that the complex and stochastic nature of real-world applications often prevents the agent from completely knowing the underlying system. In this paper, we introduce such a new problem with formal formulations and present a generic framework for addressing decision-making tasks in social contagion management. On the theory side, we present a generalization analysis for justifying the learning performance of our framework. In empirical studies, we perform a sanity check and compare the presented method with other possible learning-based and graph-based methods. We have acquired promising experimental results, confirming for the first time that it is possible to solve one decision-making task by using the solutions associated with another one.
The Far-/Near-Field Beam Squint and Solutions for THz Intelligent Reflecting Surface Communications
Aug 26, 2022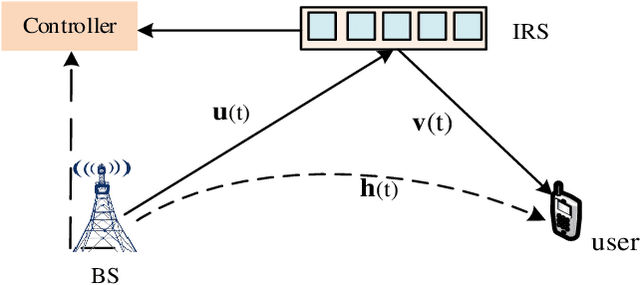
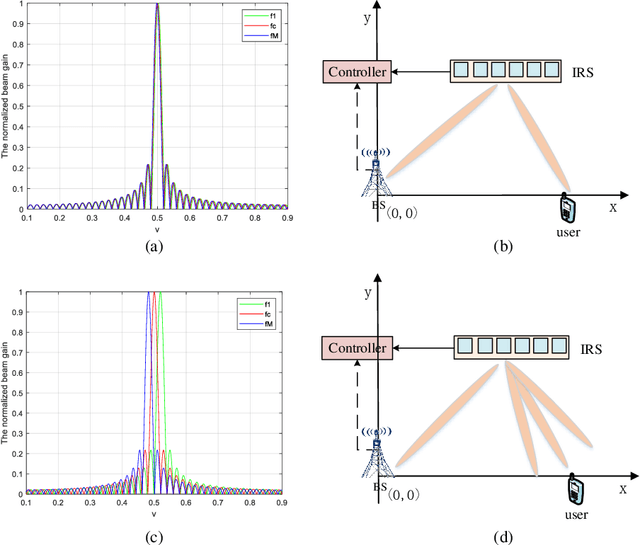
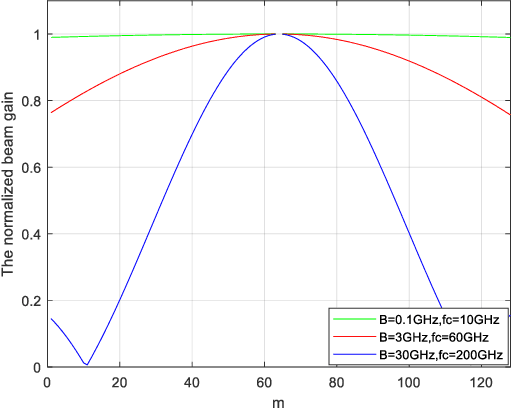
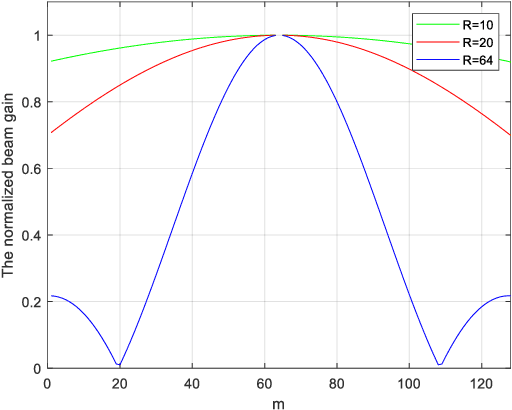
Terahertz (THz) and intelligent reflecting surface (IRS) have been regarded as two promising technologies to improve the capacity and coverage for future 6G networks. Generally, IRS is usually equipped with large-scale elements when implemented at THz frequency. In this case, the near-field model and beam squint should be considered. Therefore, in this paper, we investigate the far-field and near-field beam squint problems in THz IRS communications for the first time. The far-field and near-field channel models are constructed based on the different electromagnetic radiation characteristics. Next, we first analyze the far-field beam squint and its effect for the beam gain based on the cascaded base station (BS)-IRS-user channel model, and then the near-field case is studied. To overcome the far-field and near-field beam squint effects, we propose to apply delay adjustable metasurface (DAM) to IRS, and develop a scheme of optimizing the reflecting phase shifts and time delays of IRS elements, which effectively eliminates the beam gain loss caused by beam squint. Finally, simulations are conducted to demonstrate the effectiveness of our proposed schemes in combating the near and far field beam squint.
Graph-Based Active Machine Learning Method for Diverse and Novel Antimicrobial Peptides Generation and Selection
Sep 18, 2022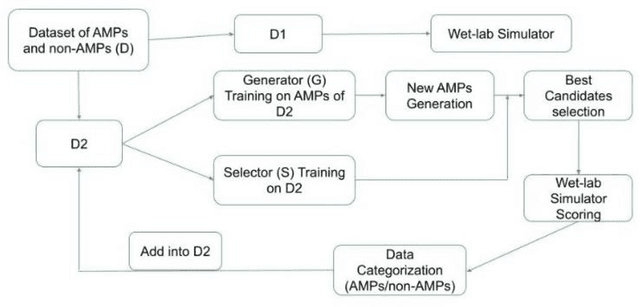

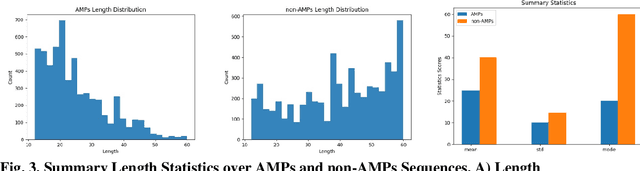
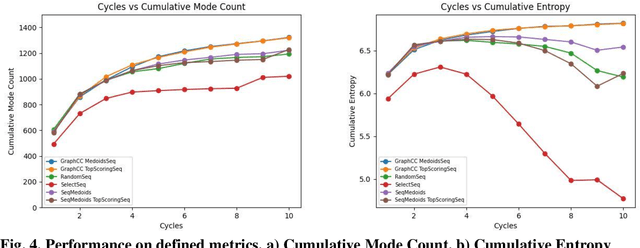
As antibiotic-resistant bacterial strains are rapidly spreading worldwide, infections caused by these strains are emerging as a global crisis causing the death of millions of people every year. Antimicrobial Peptides (AMPs) are one of the candidates to tackle this problem because of their potential diversity, and ability to favorably modulate the host immune response. However, large-scale screening of new AMP candidates is expensive, time-consuming, and now affordable in developing countries, which need the treatments the most. In this work, we propose a novel active machine learning-based framework that statistically minimizes the number of wet-lab experiments needed to design new AMPs, while ensuring a high diversity and novelty of generated AMPs sequences, in multi-rounds of wet-lab AMP screening settings. Combining recurrent neural network models and a graph-based filter (GraphCC), our proposed approach delivers novel and diverse candidates and demonstrates better performances according to our defined metrics.
Assessment of cognitive characteristics in intelligent systems and predictive ability
Sep 16, 2022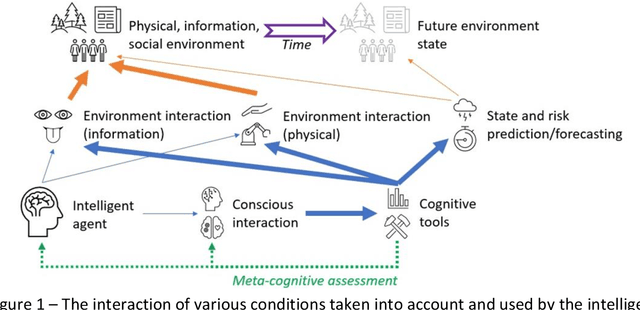
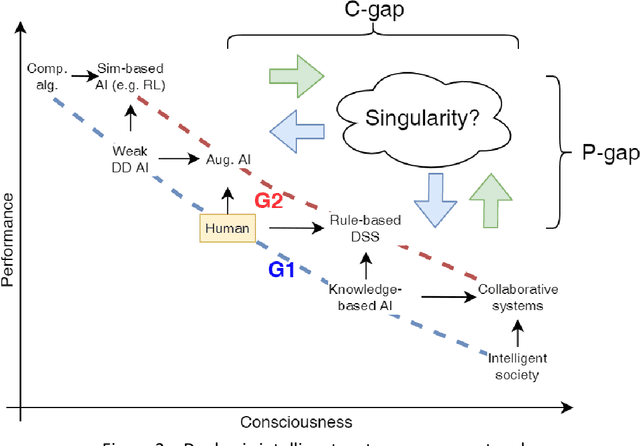
The article proposes a universal dual-axis intelligent systems assessment scale. The scale considers the properties of intelligent systems within the environmental context, which develops over time. In contrast to the frequent consideration of the 'mind' of artificial intelligent systems on a scale from 'weak' to 'strong', we highlight the modulating influences of anticipatory ability on their 'brute force'. In addition, the complexity, the 'weight' of the cognitive task and the ability to critically assess it beforehand determine the actual set of cognitive tools, the use of which provides the best result in these conditions. In fact, the presence of 'common sense' options is what connects the ability to solve a problem with the correct use of such an ability itself. The degree of 'correctness' and 'adequacy' is determined by the combination of a suitable solution with the temporal characteristics of the event, phenomenon, object or subject under study.
Real-Time GPU-Accelerated Machine Learning Based Multiuser Detection for 5G and Beyond
Jan 14, 2022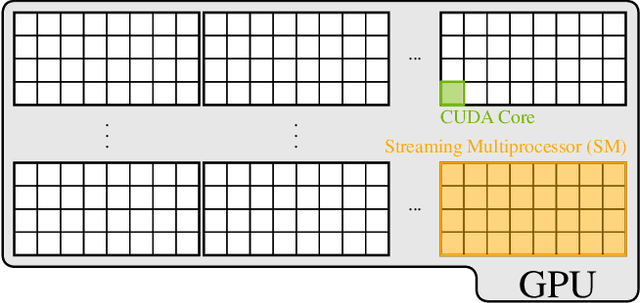

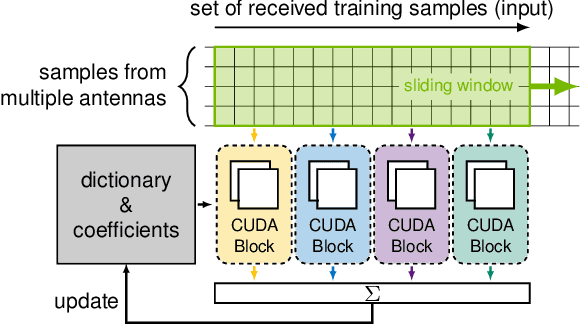
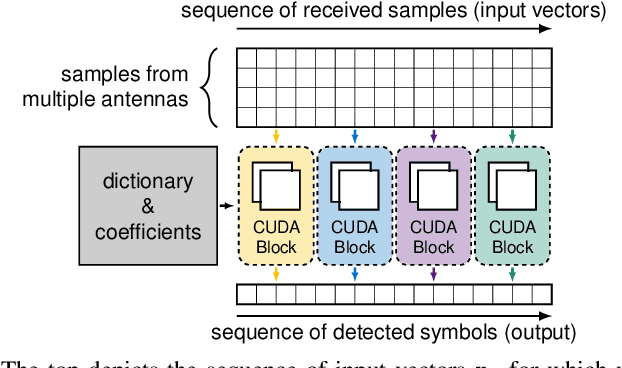
Adaptive partial linear beamforming meets the need of 5G and future 6G applications for high flexibility and adaptability. Choosing an appropriate tradeoff between conflicting goals opens the recently proposed multiuser (MU) detection method. Due to their high spatial resolution, nonlinear beamforming filters can significantly outperform linear approaches in stationary scenarios with massive connectivity. However, a dramatic decrease in performance can be expected in high mobility scenarios because they are very susceptible to changes in the wireless channel. The robustness of linear filters is required, considering these changes. One way to respond appropriately is to use online machine learning algorithms. The theory of algorithms based on the adaptive projected subgradient method (APSM) is rich, and they promise accurate tracking capabilities in dynamic wireless environments. However, one of the main challenges comes from the real-time implementation of these algorithms, which involve projections on time-varying closed convex sets. While the projection operations are relatively simple, their vast number poses a challenge in ultralow latency (ULL) applications where latency constraints must be satisfied in every radio frame. Taking non-orthogonal multiple access (NOMA) systems as an example, this paper explores the acceleration of APSM-based algorithms through massive parallelization. The result is a GPU-accelerated real-time implementation of an orthogonal frequency-division multiplexing (OFDM)-based transceiver that enables detection latency of less than one millisecond and therefore complies with the requirements of 5G and beyond. To meet the stringent physical layer latency requirements, careful co-design of hardware and software is essential, especially in virtualized wireless systems with hardware accelerators.
Predicting Performances of Mutual Funds using Deep Learning and Ensemble Techniques
Sep 18, 2022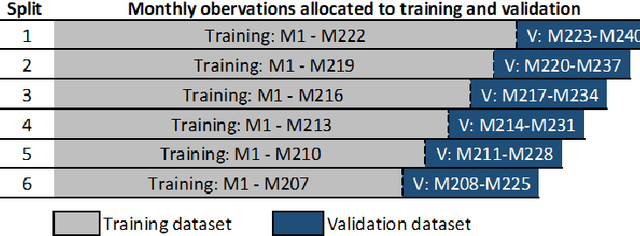
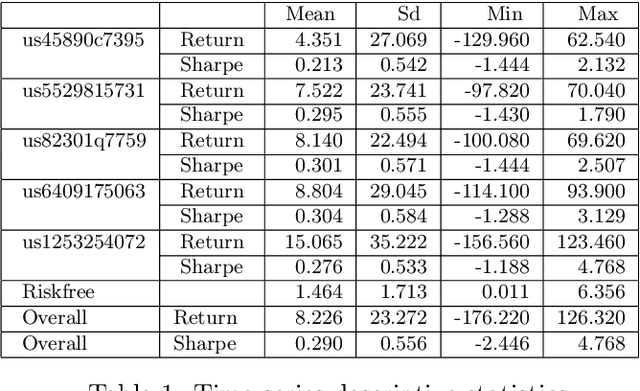
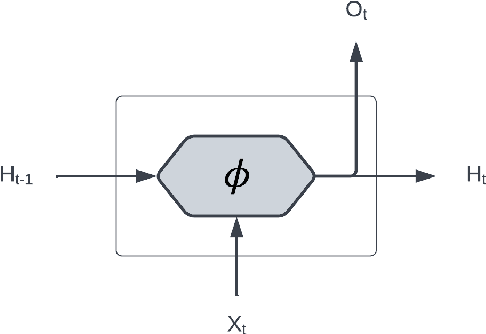
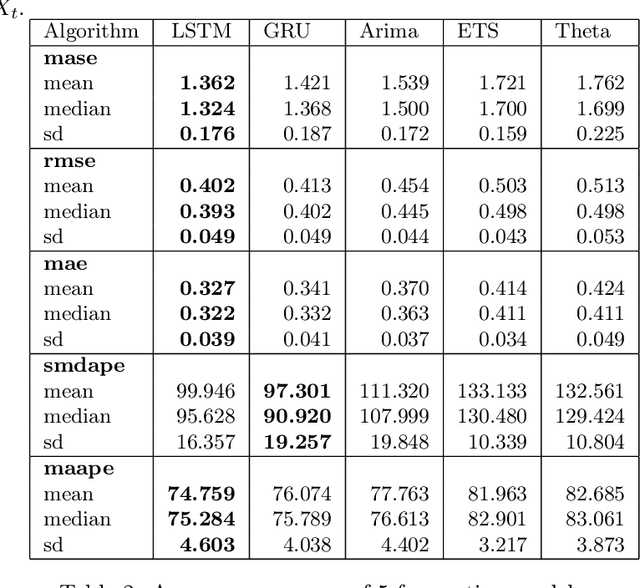
Predicting fund performance is beneficial to both investors and fund managers, and yet is a challenging task. In this paper, we have tested whether deep learning models can predict fund performance more accurately than traditional statistical techniques. Fund performance is typically evaluated by the Sharpe ratio, which represents the risk-adjusted performance to ensure meaningful comparability across funds. We calculated the annualised Sharpe ratios based on the monthly returns time series data for more than 600 open-end mutual funds investing in listed large-cap equities in the United States. We find that long short-term memory (LSTM) and gated recurrent units (GRUs) deep learning methods, both trained with modern Bayesian optimization, provide higher accuracy in forecasting funds' Sharpe ratios than traditional statistical ones. An ensemble method, which combines forecasts from LSTM and GRUs, achieves the best performance of all models. There is evidence to say that deep learning and ensembling offer promising solutions in addressing the challenge of fund performance forecasting.
PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement
Mar 04, 2022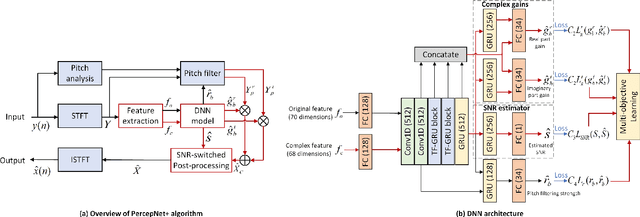
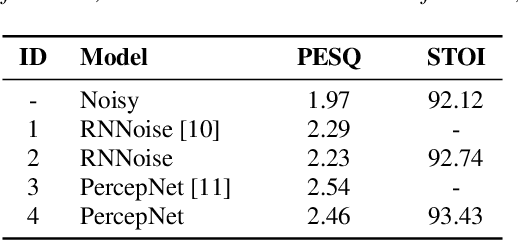
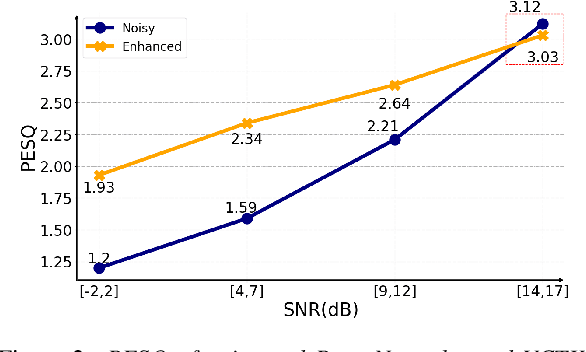
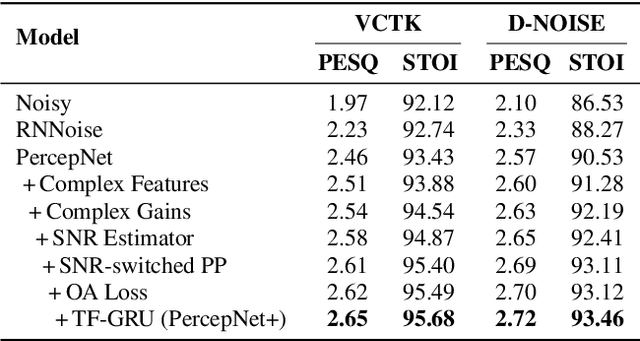
PercepNet, a recent extension of the RNNoise, an efficient, high-quality and real-time full-band speech enhancement technique, has shown promising performance in various public deep noise suppression tasks. This paper proposes a new approach, named PercepNet+, to further extend the PercepNet with four significant improvements. First, we introduce a phase-aware structure to leverage the phase information into PercepNet, by adding the complex features and complex subband gains as the deep network input and output respectively. Then, a signal-to-noise ratio (SNR) estimator and an SNR switched post-processing are specially designed to alleviate the over attenuation (OA) that appears in high SNR conditions of the original PercepNet. Moreover, the GRU layer is replaced by TF-GRU to model both temporal and frequency dependencies. Finally, we propose to integrate the loss of complex subband gain, SNR, pitch filtering strength, and an OA loss in a multi-objective learning manner to further improve the speech enhancement performance. Experimental results show that, the proposed PercepNet+ outperforms the original PercepNet significantly in terms of both PESQ and STOI, without increasing the model size too much.
A Fourier Approach to Mixture Learning
Oct 05, 2022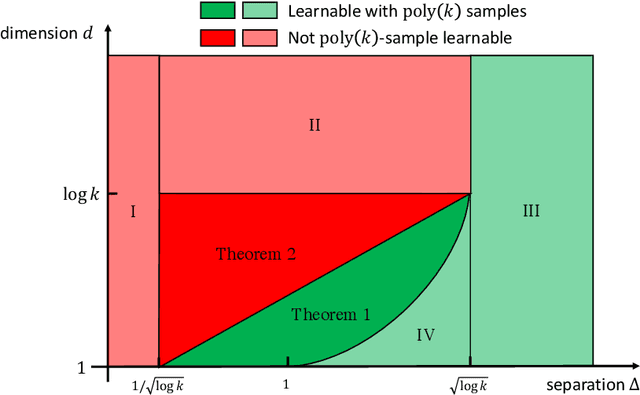

We revisit the problem of learning mixtures of spherical Gaussians. Given samples from mixture $\frac{1}{k}\sum_{j=1}^{k}\mathcal{N}(\mu_j, I_d)$, the goal is to estimate the means $\mu_1, \mu_2, \ldots, \mu_k \in \mathbb{R}^d$ up to a small error. The hardness of this learning problem can be measured by the separation $\Delta$ defined as the minimum distance between all pairs of means. Regev and Vijayaraghavan (2017) showed that with $\Delta = \Omega(\sqrt{\log k})$ separation, the means can be learned using $\mathrm{poly}(k, d)$ samples, whereas super-polynomially many samples are required if $\Delta = o(\sqrt{\log k})$ and $d = \Omega(\log k)$. This leaves open the low-dimensional regime where $d = o(\log k)$. In this work, we give an algorithm that efficiently learns the means in $d = O(\log k/\log\log k)$ dimensions under separation $d/\sqrt{\log k}$ (modulo doubly logarithmic factors). This separation is strictly smaller than $\sqrt{\log k}$, and is also shown to be necessary. Along with the results of Regev and Vijayaraghavan (2017), our work almost pins down the critical separation threshold at which efficient parameter learning becomes possible for spherical Gaussian mixtures. More generally, our algorithm runs in time $\mathrm{poly}(k)\cdot f(d, \Delta, \epsilon)$, and is thus fixed-parameter tractable in parameters $d$, $\Delta$ and $\epsilon$. Our approach is based on estimating the Fourier transform of the mixture at carefully chosen frequencies, and both the algorithm and its analysis are simple and elementary. Our positive results can be easily extended to learning mixtures of non-Gaussian distributions, under a mild condition on the Fourier spectrum of the distribution.