 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalized Wasserstein Dice Loss, Test-time Augmentation, and Transformers for the BraTS 2021 challenge
Dec 24, 2021
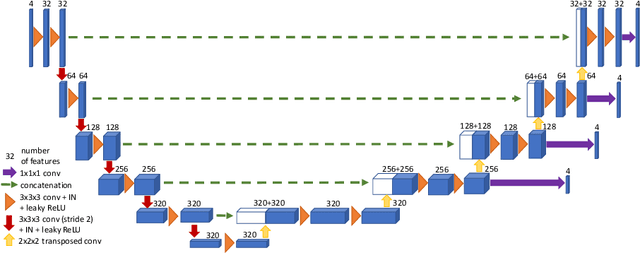
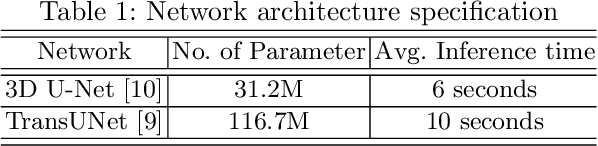
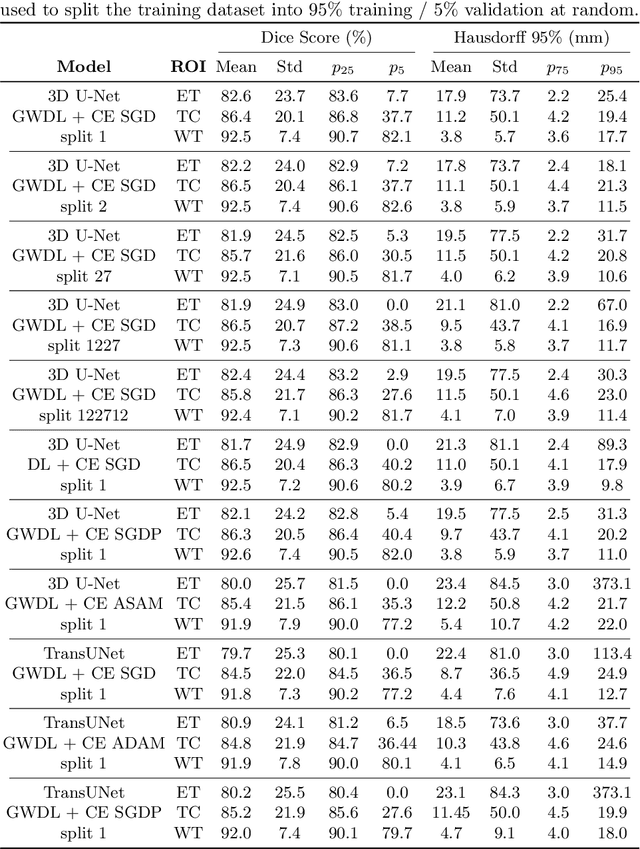
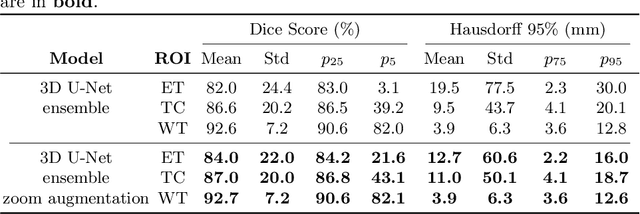
Brain tumor segmentation from multiple Magnetic Resonance Imaging (MRI) modalities is a challenging task in medical image computation. The main challenges lie in the generalizability to a variety of scanners and imaging protocols. In this paper, we explore strategies to increase model robustness without increasing inference time. Towards this aim, we explore finding a robust ensemble from models trained using different losses, optimizers, and train-validation data split. Importantly, we explore the inclusion of a transformer in the bottleneck of the U-Net architecture. While we find transformer in the bottleneck performs slightly worse than the baseline U-Net in average, the generalized Wasserstein Dice loss consistently produces superior results. Further, we adopt an efficient test time augmentation strategy for faster and robust inference. Our final ensemble of seven 3D U-Nets with test-time augmentation produces an average dice score of 89.4% and an average Hausdorff 95% distance of 10.0 mm when evaluated on the BraTS 2021 testing dataset. Our code and trained models are publicly available at https://github.com/LucasFidon/TRABIT_BraTS2021.
Convergence of the mini-batch SIHT algorithm
Sep 29, 2022The Iterative Hard Thresholding (IHT) algorithm has been considered extensively as an effective deterministic algorithm for solving sparse optimizations. The IHT algorithm benefits from the information of the batch (full) gradient at each point and this information is a crucial key for the convergence analysis of the generated sequence. However, this strength becomes a weakness when it comes to machine learning and high dimensional statistical applications because calculating the batch gradient at each iteration is computationally expensive or impractical. Fortunately, in these applications the objective function has a summation structure that can be taken advantage of to approximate the batch gradient by the stochastic mini-batch gradient. In this paper, we study the mini-batch Stochastic IHT (SIHT) algorithm for solving the sparse optimizations. As opposed to previous works where increasing and variable mini-batch size is necessary for derivation, we fix the mini-batch size according to a lower bound that we derive and show our work. To prove stochastic convergence of the objective value function we first establish a critical sparse stochastic gradient descent property. Using this stochastic gradient descent property we show that the sequence generated by the stochastic mini-batch SIHT is a supermartingale sequence and converges with probability one. Unlike previous work we do not assume the function to be a restricted strongly convex. To the best of our knowledge, in the regime of sparse optimization, this is the first time in the literature that it is shown that the sequence of the stochastic function values converges with probability one by fixing the mini-batch size for all steps.
An Adaptive Observer for Uncertain Linear Time-Varying Systems with Unknown Additive Perturbations
Dec 10, 2021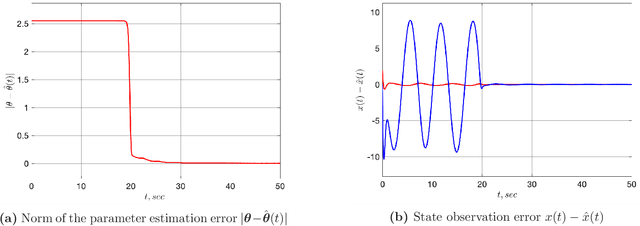
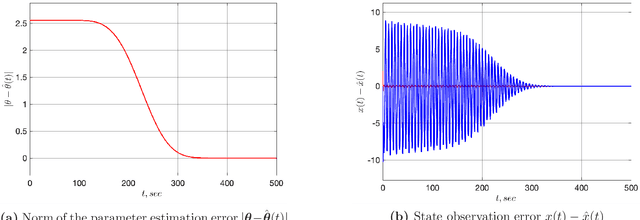
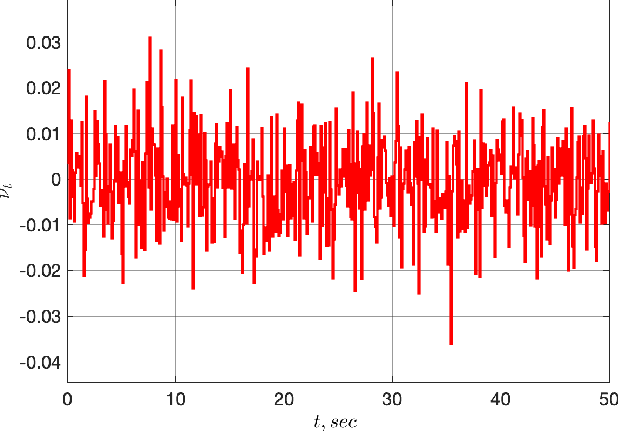
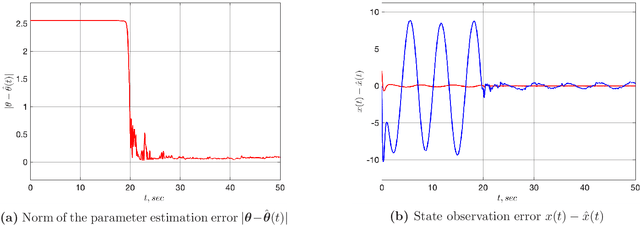
In this paper we are interested in the problem of adaptive state observation of linear time-varying (LTV) systems where the system and the input matrices depend on unknown time-varying parameters. It is assumed that these parameters satisfy some known LTV dynamics, but with unknown initial conditions. Moreover, the state equation is perturbed by an additive signal generated from an exosystem with uncertain constant parameters. Our main contribution is to propose a globally convergent state observer that requires only a weak excitation assumption on the system.
Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement
Mar 30, 2022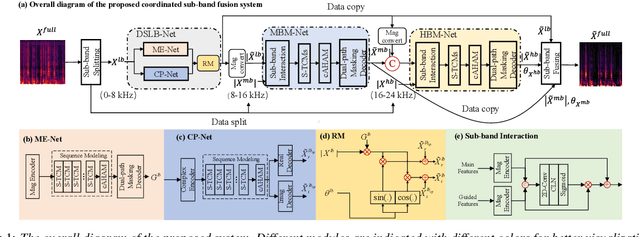
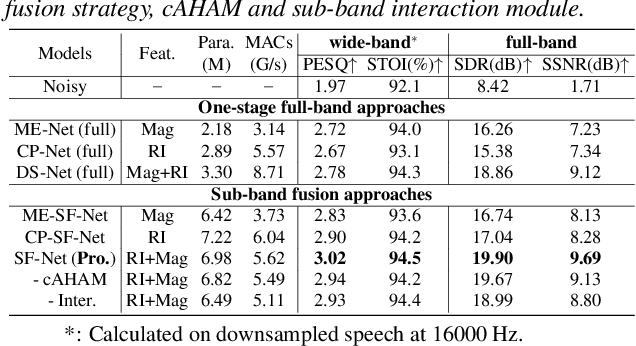
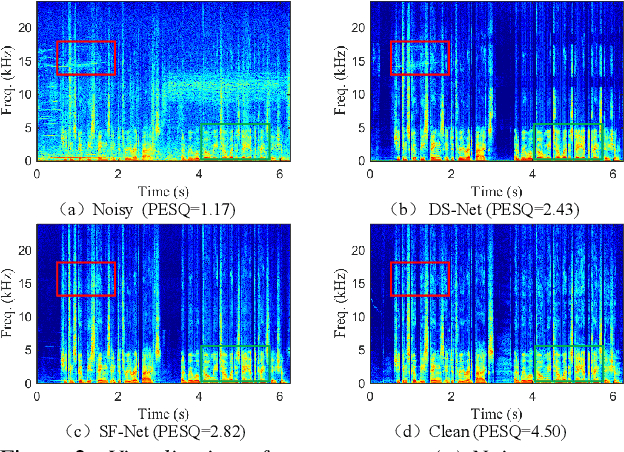
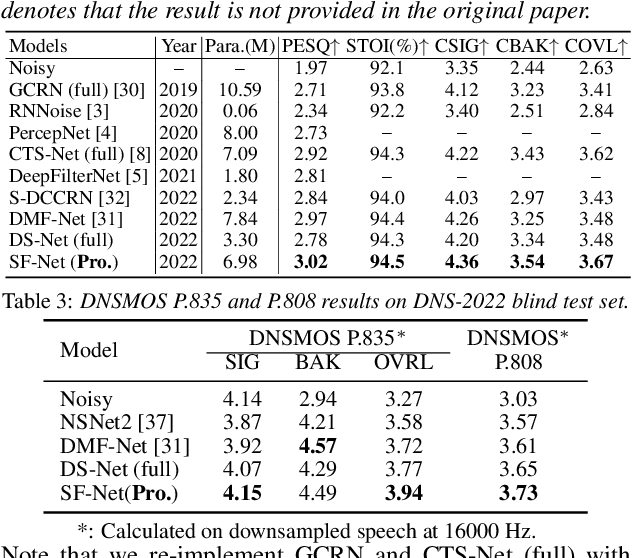
Due to the high computational complexity to model more frequency bands, it is still intractable to conduct real-time full-band speech enhancement based on deep neural networks. Recent studies typically utilize the compressed perceptually motivated features with relatively low frequency resolution to filter the full-band spectrum by one-stage networks, leading to limited speech quality improvements. In this paper, we propose a coordinated sub-band fusion network for full-band speech enhancement, which aims to recover the low- (0-8 kHz), middle- (8-16 kHz), and high-band (16-24 kHz) in a step-wise manner. Specifically, a dual-stream network is first pretrained to recover the low-band complex spectrum, and another two sub-networks are designed as the middle- and high-band noise suppressors in the magnitude-only domain. To fully capitalize on the information intercommunication, we employ a sub-band interaction module to provide external knowledge guidance across different frequency bands. Extensive experiments show that the proposed method yields consistent performance advantages over state-of-the-art full-band baselines.
Robust and Efficient Depth-based Obstacle Avoidance for Autonomous Miniaturized UAVs
Aug 26, 2022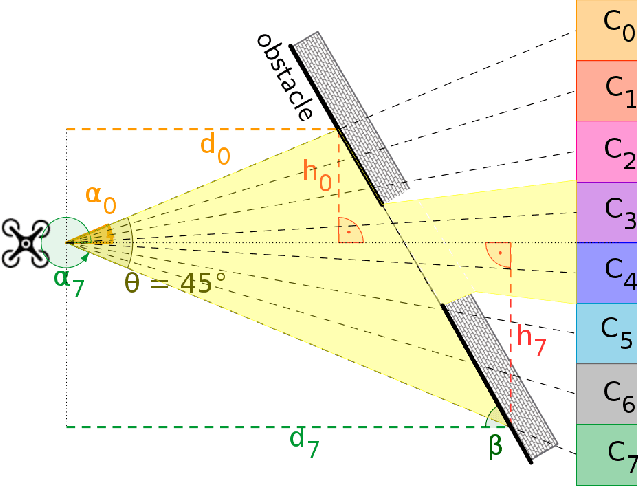
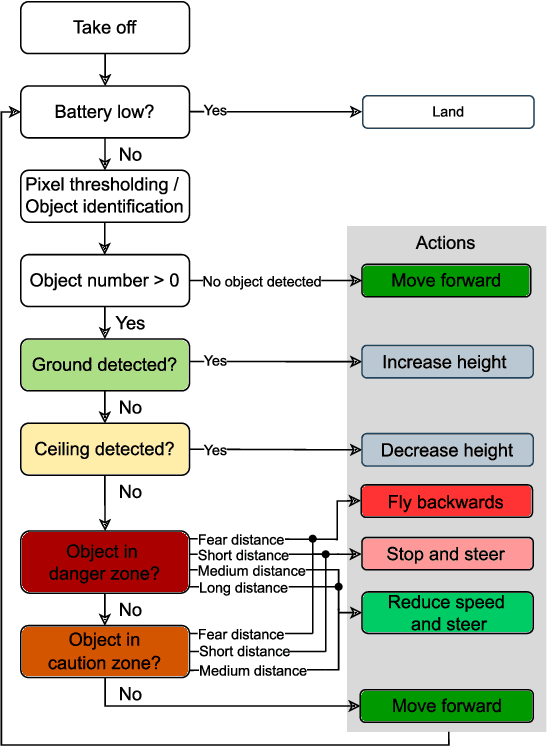
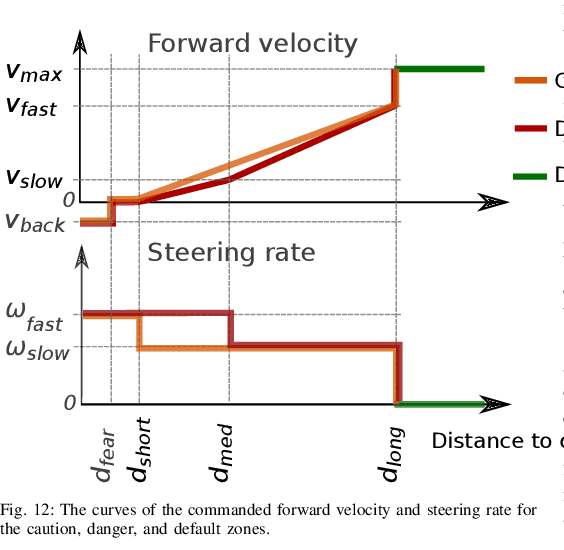
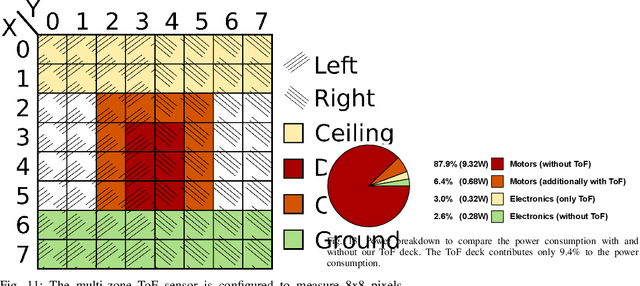
Nano-size drones hold enormous potential to explore unknown and complex environments. Their small size makes them agile and safe for operation close to humans and allows them to navigate through narrow spaces. However, their tiny size and payload restrict the possibilities for on-board computation and sensing, making fully autonomous flight extremely challenging. The first step towards full autonomy is reliable obstacle avoidance, which has proven to be technically challenging by itself in a generic indoor environment. Current approaches utilize vision-based or 1-dimensional sensors to support nano-drone perception algorithms. This work presents a lightweight obstacle avoidance system based on a novel millimeter form factor 64 pixels multi-zone Time-of-Flight (ToF) sensor and a generalized model-free control policy. Reported in-field tests are based on the Crazyflie 2.1, extended by a custom multi-zone ToF deck, featuring a total flight mass of 35g. The algorithm only uses 0.3% of the on-board processing power (210uS execution time) with a frame rate of 15fps, providing an excellent foundation for many future applications. Less than 10% of the total drone power is needed to operate the proposed perception system, including both lifting and operating the sensor. The presented autonomous nano-size drone reaches 100% reliability at 0.5m/s in a generic and previously unexplored indoor environment. The proposed system is released open-source with an extensive dataset including ToF and gray-scale camera data, coupled with UAV position ground truth from motion capture.
Incremental Learning in Diagonal Linear Networks
Aug 31, 2022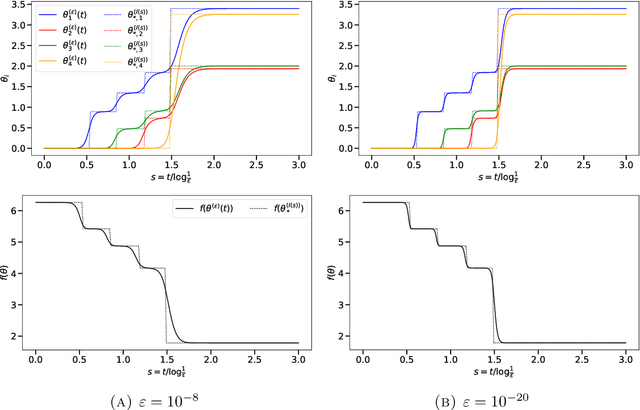
Diagonal linear networks (DLNs) are a toy simplification of artificial neural networks; they consist in a quadratic reparametrization of linear regression inducing a sparse implicit regularization. In this paper, we describe the trajectory of the gradient flow of DLNs in the limit of small initialization. We show that incremental learning is effectively performed in the limit: coordinates are successively activated, while the iterate is the minimizer of the loss constrained to have support on the active coordinates only. This shows that the sparse implicit regularization of DLNs decreases with time. This work is restricted to the underparametrized regime with anti-correlated features for technical reasons.
Uncertainty-aware Perception Models for Off-road Autonomous Unmanned Ground Vehicles
Sep 22, 2022
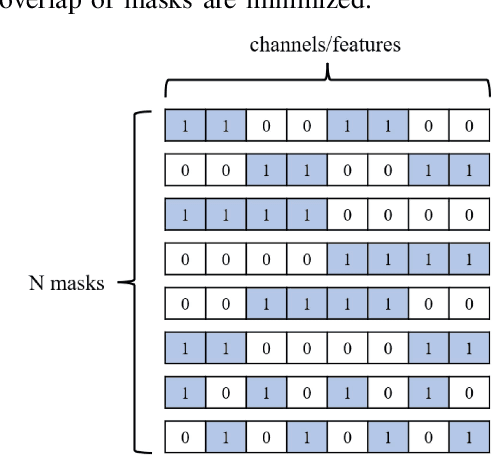
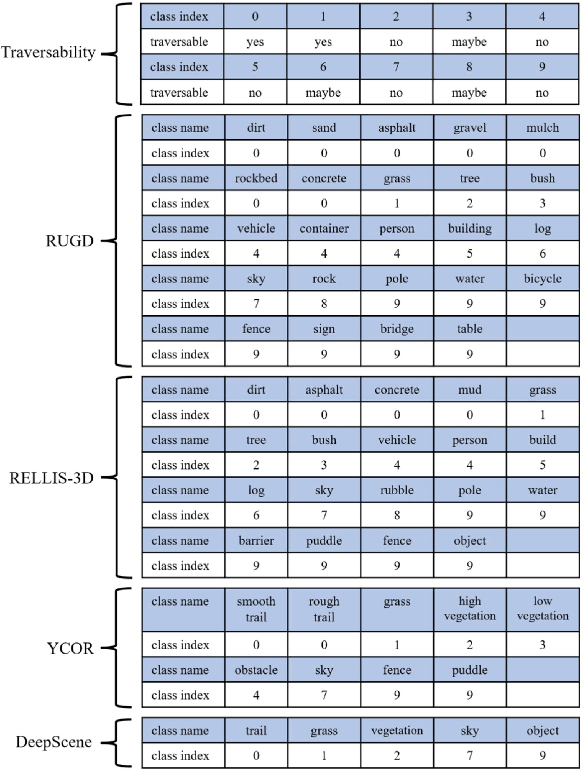
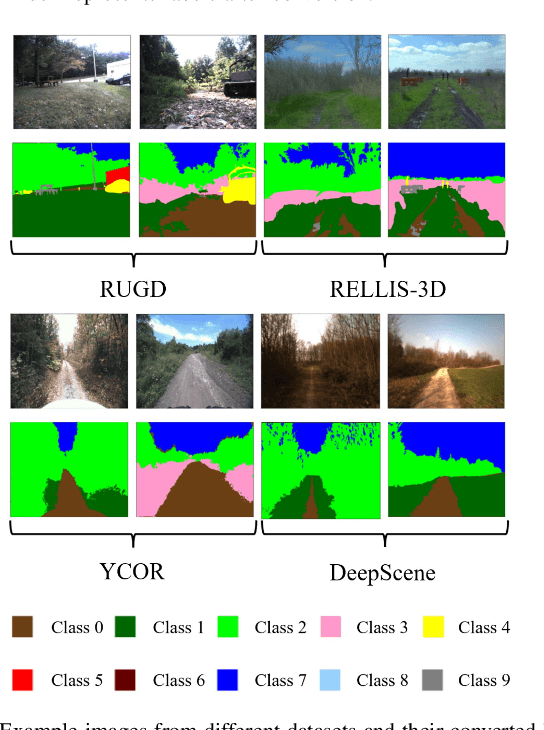
Off-road autonomous unmanned ground vehicles (UGVs) are being developed for military and commercial use to deliver crucial supplies in remote locations, help with mapping and surveillance, and to assist war-fighters in contested environments. Due to complexity of the off-road environments and variability in terrain, lighting conditions, diurnal and seasonal changes, the models used to perceive the environment must handle a lot of input variability. Current datasets used to train perception models for off-road autonomous navigation lack of diversity in seasons, locations, semantic classes, as well as time of day. We test the hypothesis that model trained on a single dataset may not generalize to other off-road navigation datasets and new locations due to the input distribution drift. Additionally, we investigate how to combine multiple datasets to train a semantic segmentation-based environment perception model and we show that training the model to capture uncertainty could improve the model performance by a significant margin. We extend the Masksembles approach for uncertainty quantification to the semantic segmentation task and compare it with Monte Carlo Dropout and standard baselines. Finally, we test the approach against data collected from a UGV platform in a new testing environment. We show that the developed perception model with uncertainty quantification can be feasibly deployed on an UGV to support online perception and navigation tasks.
The Face of Affective Disorders
Aug 04, 2022
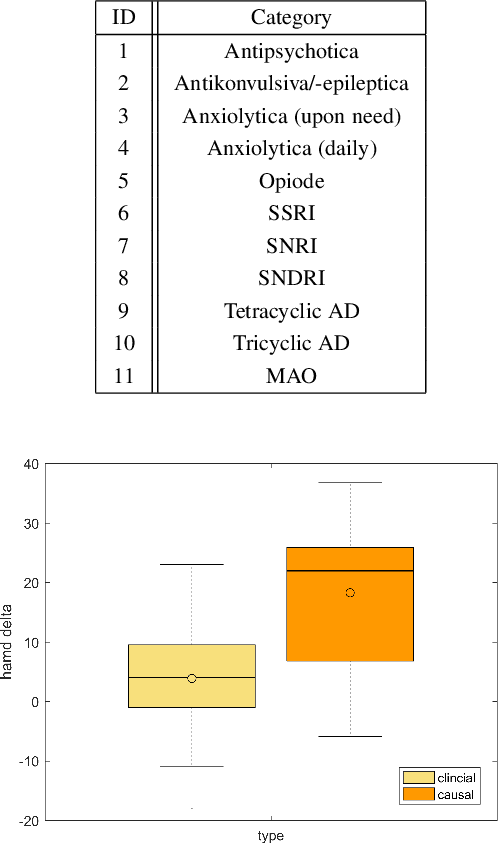
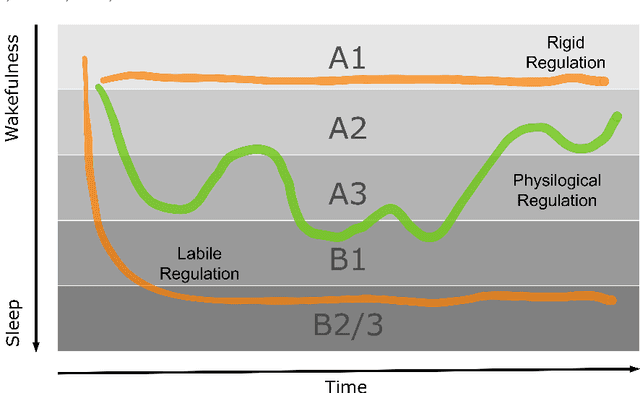
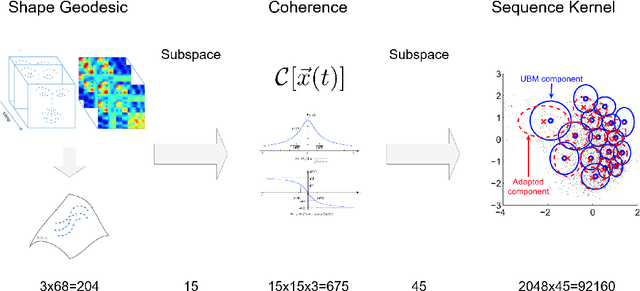
We study the statistical properties of facial behaviour altered by the regulation of brain arousal in the clinical domain of psychiatry. The underlying mechanism is linked to the empirical interpretation of the vigilance continuum as behavioral surrogate measurement for certain states of mind. We name the presented measurement in the sense of the classical scalp based obtrusive sensors Opto Electronic Encephalography (OEG) which relies solely on modern camera based real-time signal processing and computer vision. Based upon a stochastic representation as coherence of the face dynamics, reflecting the hemifacial asymmetry in emotion expressions, we demonstrate an almost flawless distinction between patients and healthy controls as well as between the mental disorders depression and schizophrenia and the symptom severity. In contrast to the standard diagnostic process, which is time-consuming, subjective and does not incorporate neurobiological data such as real-time face dynamics, the objective stochastic modeling of the affective responsiveness only requires a few minutes of video-based facial recordings. We also highlight the potential of the methodology as a causal inference model in transdiagnostic analysis to predict the outcome of pharmacological treatment. All results are obtained on a clinical longitudinal data collection with an amount of 100 patients and 50 controls.
Parameter-Efficient Finetuning for Robust Continual Multilingual Learning
Sep 14, 2022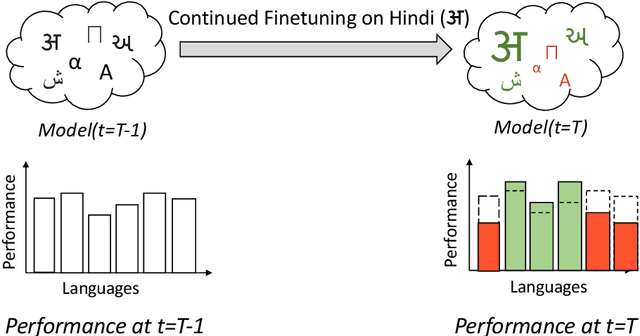

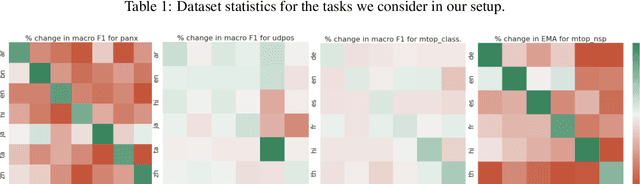
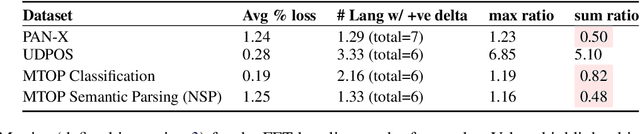
NLU systems deployed in the real world are expected to be regularly updated by retraining or finetuning the underlying neural network on new training examples accumulated over time. In our work, we focus on the multilingual setting where we would want to further finetune a multilingual model on new training data for the same NLU task on which the aforementioned model has already been trained for. We show that under certain conditions, naively updating the multilingual model can lead to losses in performance over a subset of languages although the aggregated performance metric shows an improvement. We establish this phenomenon over four tasks belonging to three task families (token-level, sentence-level and seq2seq) and find that the baseline is far from ideal for the setting at hand. We then build upon recent advances in parameter-efficient finetuning to develop novel finetuning pipelines that allow us to jointly minimize catastrophic forgetting while encouraging positive cross-lingual transfer, hence improving the spread of gains over different languages while reducing the losses incurred in this setup.
Online Whole-body Motion Planning for Quadrotor using Multi-resolution Search
Sep 14, 2022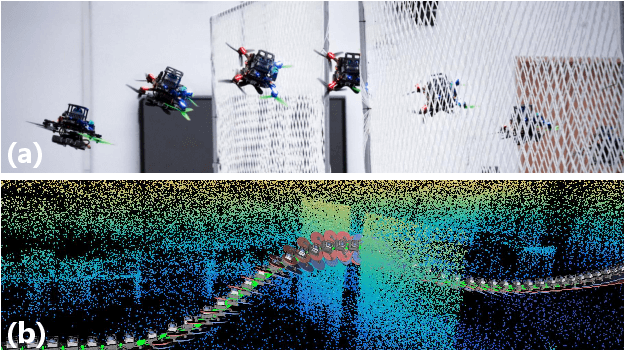
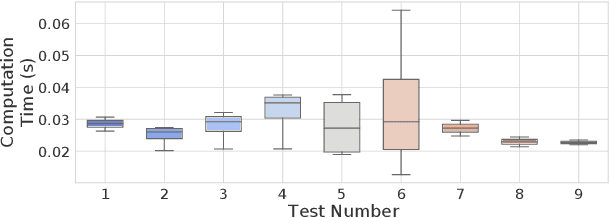
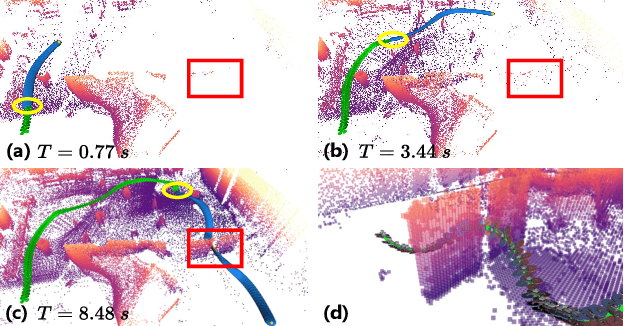
In this paper, we address the problem of online quadrotor whole-body motion planning (SE(3) planning) in unknown and unstructured environments. We propose a novel multi-resolution search method, which discovers narrow areas requiring full pose planning and normal areas requiring only position planning. As a consequence, a quadrotor planning problem is decomposed into several SE(3) (if necessary) and R^3 sub-problems. To fly through the discovered narrow areas, a carefully designed corridor generation strategy for narrow areas is proposed, which significantly increases the planning success rate. The overall problem decomposition and hierarchical planning framework substantially accelerate the planning process, making it possible to work online with fully onboard sensing and computation in unknown environments. Extensive simulation benchmark comparisons show that the proposed method has an order of magnitude faster than the state-of-the-art methods in computation time while maintaining high planning success rate. The proposed method is finally integrated into a LiDAR-based autonomous quadrotor, and various real-world experiments in unknown and unstructured environments are conducted to demonstrate the outstanding performance of the proposed method.